 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Zero-shot Item-based Recommendation via Multi-task Product Knowledge Graph Pre-Training
May 12, 2023
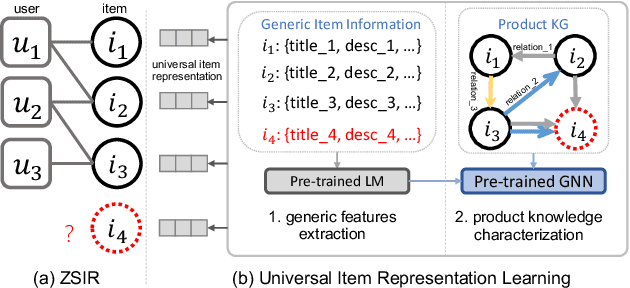
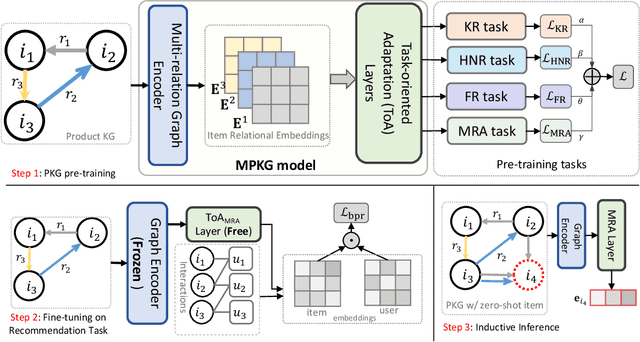

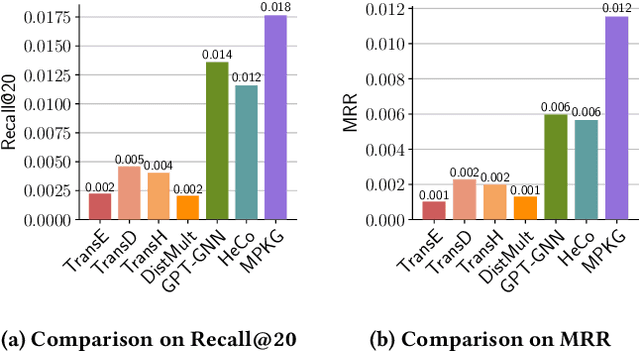
Existing recommender systems face difficulties with zero-shot items, i.e. items that have no historical interactions with users during the training stage. Though recent works extract universal item representation via pre-trained language models (PLMs), they ignore the crucial item relationships. This paper presents a novel paradigm for the Zero-Shot Item-based Recommendation (ZSIR) task, which pre-trains a model on product knowledge graph (PKG) to refine the item features from PLMs. We identify three challenges for pre-training PKG, which are multi-type relations in PKG, semantic divergence between item generic information and relations and domain discrepancy from PKG to downstream ZSIR task. We address the challenges by proposing four pre-training tasks and novel task-oriented adaptation (ToA) layers. Moreover, this paper discusses how to fine-tune the model on new recommendation task such that the ToA layers are adapted to ZSIR task. Comprehensive experiments on 18 markets dataset are conducted to verify the effectiveness of the proposed model in both knowledge prediction and ZSIR task.
Meta-Optimization for Higher Model Generalizability in Single-Image Depth Prediction
May 12, 2023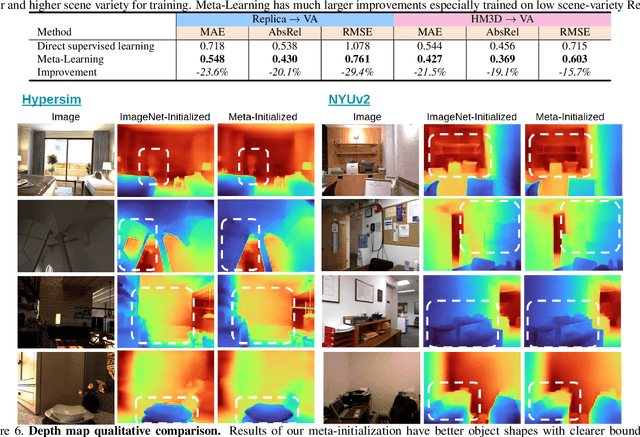
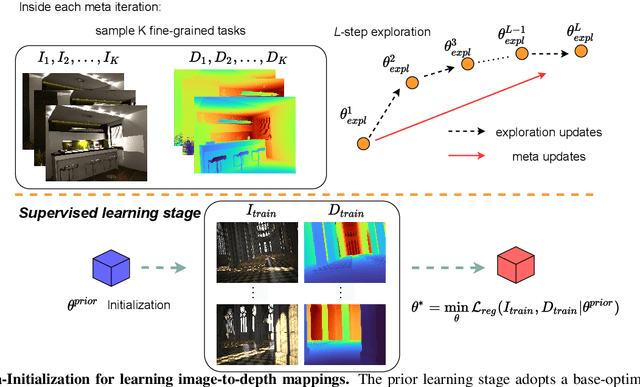
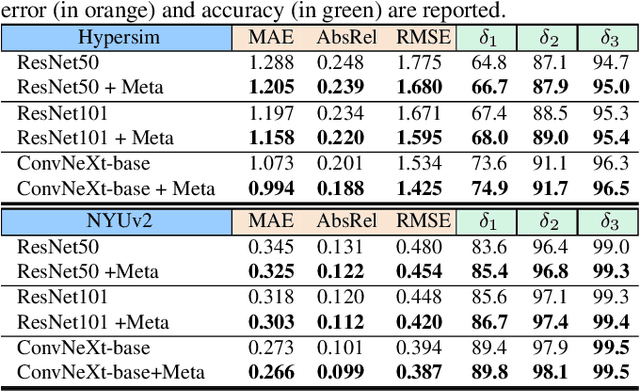
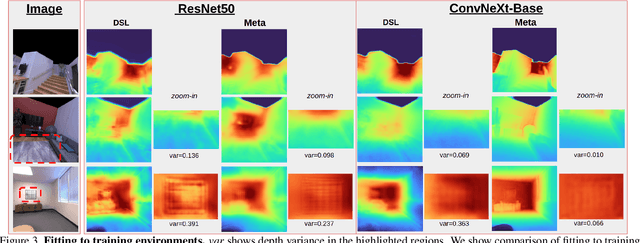
Model generalizability to unseen datasets, concerned with in-the-wild robustness, is less studied for indoor single-image depth prediction. We leverage gradient-based meta-learning for higher generalizability on zero-shot cross-dataset inference. Unlike the most-studied image classification in meta-learning, depth is pixel-level continuous range values, and mappings from each image to depth vary widely across environments. Thus no explicit task boundaries exist. We instead propose fine-grained task that treats each RGB-D pair as a task in our meta-optimization. We first show meta-learning on limited data induces much better prior (max +29.4\%). Using meta-learned weights as initialization for following supervised learning, without involving extra data or information, it consistently outperforms baselines without the method. Compared to most indoor-depth methods that only train/ test on a single dataset, we propose zero-shot cross-dataset protocols, closely evaluate robustness, and show consistently higher generalizability and accuracy by our meta-initialization. The work at the intersection of depth and meta-learning potentially drives both research streams to step closer to practical use.
Diffusion-based Signal Refiner for Speech Separation
May 12, 2023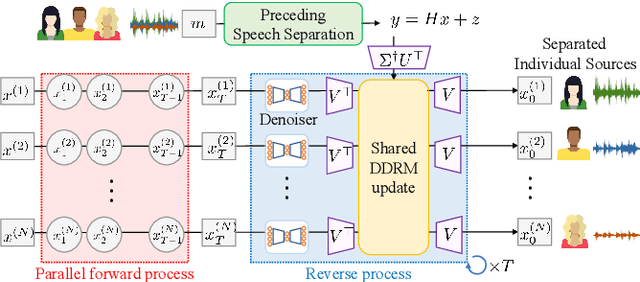
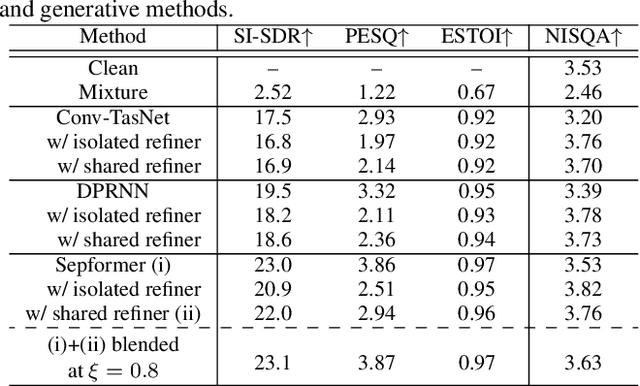
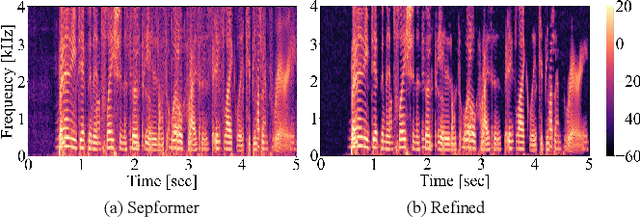
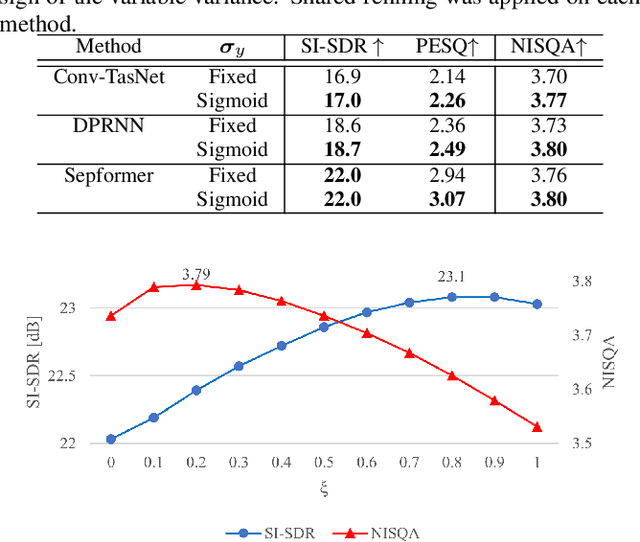
We have developed a diffusion-based speech refiner that improves the reference-free perceptual quality of the audio predicted by preceding single-channel speech separation models. Although modern deep neural network-based speech separation models have show high performance in reference-based metrics, they often produce perceptually unnatural artifacts. The recent advancements made to diffusion models motivated us to tackle this problem by restoring the degraded parts of initial separations with a generative approach. Utilizing the denoising diffusion restoration model (DDRM) as a basis, we propose a shared DDRM-based refiner that generates samples conditioned on the global information of preceding outputs from arbitrary speech separation models. We experimentally show that our refiner can provide a clearer harmonic structure of speech and improves the reference-free metric of perceptual quality for arbitrary preceding model architectures. Furthermore, we tune the variance of the measurement noise based on preceding outputs, which results in higher scores in both reference-free and reference-based metrics. The separation quality can also be further improved by blending the discriminative and generative outputs.
Multi-legged matter transport: a framework for locomotion on noisy landscapes
May 08, 2023While the transport of matter by wheeled vehicles or legged robots can be guaranteed in engineered landscapes like roads or rails, locomotion prediction in complex environments like collapsed buildings or crop fields remains challenging. Inspired by principles of information transmission which allow signals to be reliably transmitted over noisy channels, we develop a ``matter transport" framework demonstrating that non-inertial locomotion can be provably generated over ``noisy" rugose landscapes (heterogeneities on the scale of locomotor dimensions). Experiments confirm that sufficient spatial redundancy in the form of serially-connected legged robots leads to reliable transport on such terrain without requiring sensing and control. Further analogies from communication theory coupled to advances in gaits (coding) and sensor-based feedback control (error detection/correction) can lead to agile locomotion in complex terradynamic regimes.
Distilled Mid-Fusion Transformer Networks for Multi-Modal Human Activity Recognition
May 05, 2023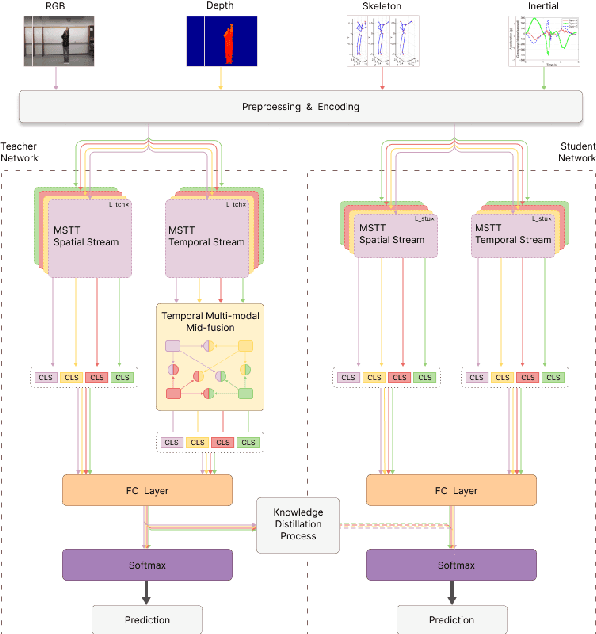
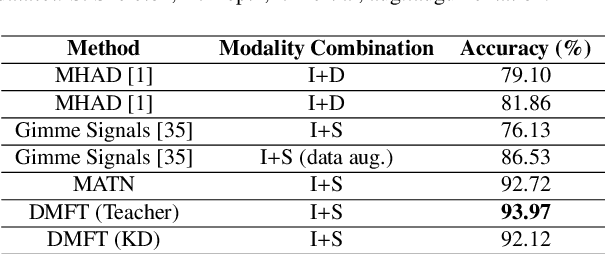
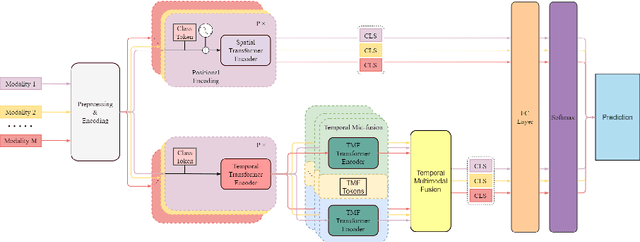
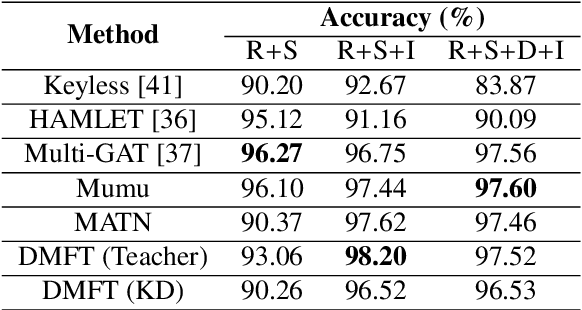
Human Activity Recognition is an important task in many human-computer collaborative scenarios, whilst having various practical applications. Although uni-modal approaches have been extensively studied, they suffer from data quality and require modality-specific feature engineering, thus not being robust and effective enough for real-world deployment. By utilizing various sensors, Multi-modal Human Activity Recognition could utilize the complementary information to build models that can generalize well. While deep learning methods have shown promising results, their potential in extracting salient multi-modal spatial-temporal features and better fusing complementary information has not been fully explored. Also, reducing the complexity of the multi-modal approach for edge deployment is another problem yet to resolve. To resolve the issues, a knowledge distillation-based Multi-modal Mid-Fusion approach, DMFT, is proposed to conduct informative feature extraction and fusion to resolve the Multi-modal Human Activity Recognition task efficiently. DMFT first encodes the multi-modal input data into a unified representation. Then the DMFT teacher model applies an attentive multi-modal spatial-temporal transformer module that extracts the salient spatial-temporal features. A temporal mid-fusion module is also proposed to further fuse the temporal features. Then the knowledge distillation method is applied to transfer the learned representation from the teacher model to a simpler DMFT student model, which consists of a lite version of the multi-modal spatial-temporal transformer module, to produce the results. Evaluation of DMFT was conducted on two public multi-modal human activity recognition datasets with various state-of-the-art approaches. The experimental results demonstrate that the model achieves competitive performance in terms of effectiveness, scalability, and robustness.
A unified information-theoretic model of EEG signatures of human language processing
Dec 16, 2022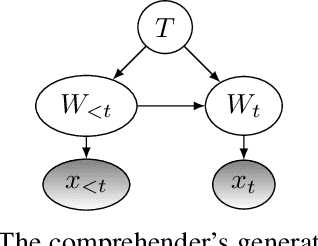

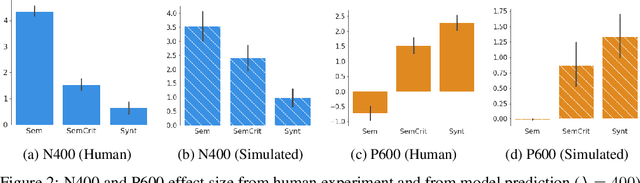

We advance an information-theoretic model of human language processing in the brain, in which incoming linguistic input is processed at two levels, in terms of a heuristic interpretation and in terms of error correction. We propose that these two kinds of information processing have distinct electroencephalographic signatures, corresponding to the well-documented N400 and P600 components of language-related event-related potentials (ERPs). Formally, we show that the information content (surprisal) of a word in context can be decomposed into two quantities: (A) heuristic surprise, which signals processing difficulty of word given its inferred context, and corresponds with the N400 signal; and (B) discrepancy signal, which reflects divergence between the true context and the inferred context, and corresponds to the P600 signal. Both of these quantities can be estimated using modern NLP techniques. We validate our theory by successfully simulating ERP patterns elicited by a variety of linguistic manipulations in previously-reported experimental data from Ryskin et al. (2021). Our theory is in principle compatible with traditional cognitive theories assuming a `good-enough' heuristic interpretation stage, but with precise information-theoretic formulation.
Disentangled Multi-Fidelity Deep Bayesian Active Learning
May 07, 2023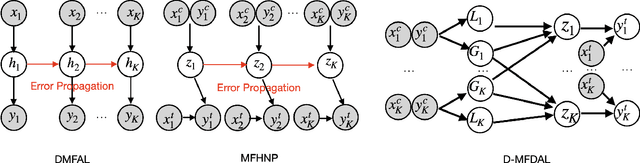
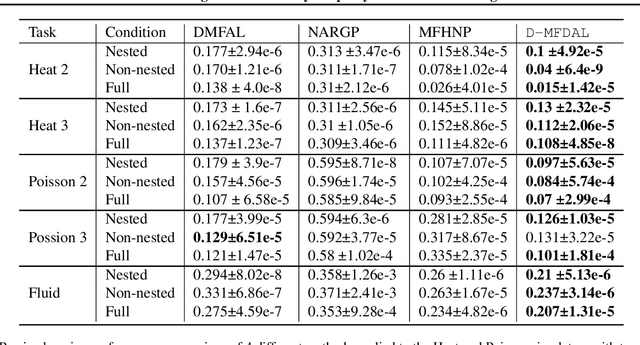
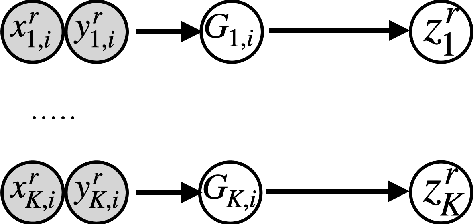
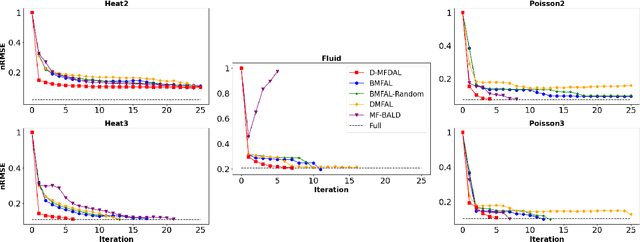
To balance quality and cost, various domain areas of science and engineering run simulations at multiple levels of sophistication. Multi-fidelity active learning aims to learn a direct mapping from input parameters to simulation outputs by actively acquiring data from multiple fidelity levels. However, existing approaches based on Gaussian processes are hardly scalable to high-dimensional data. Other deep learning-based methods use the hierarchical structure, which only supports passing information from low-fidelity to high-fidelity. This approach also leads to the undesirable propagation of errors from low-fidelity representations to high-fidelity ones. We propose a novel disentangled deep Bayesian learning framework for multi-fidelity active learning, that learns the surrogate models conditioned on the distribution of functions at multiple fidelities.
Inferring Local Structure from Pairwise Correlations
May 07, 2023
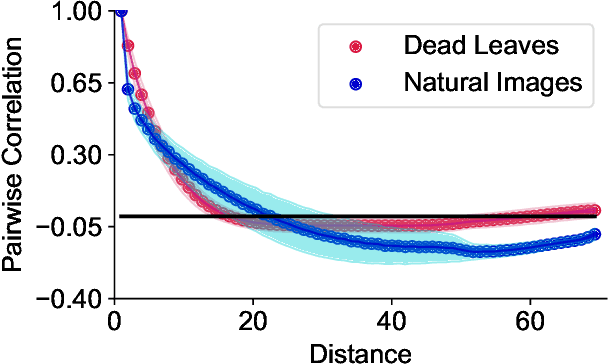
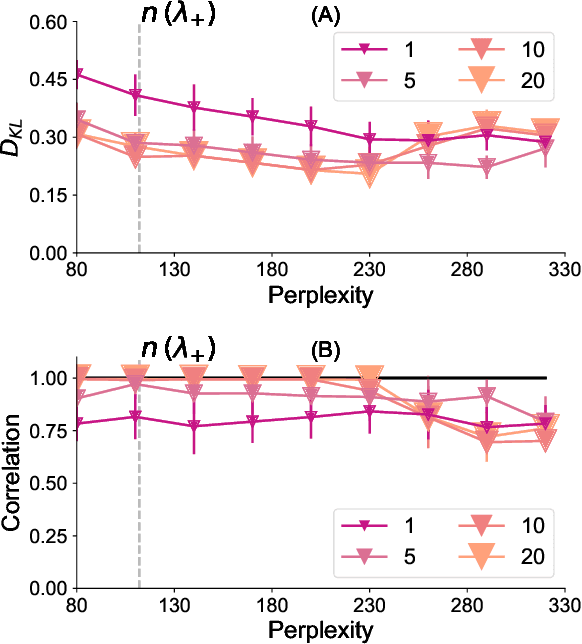
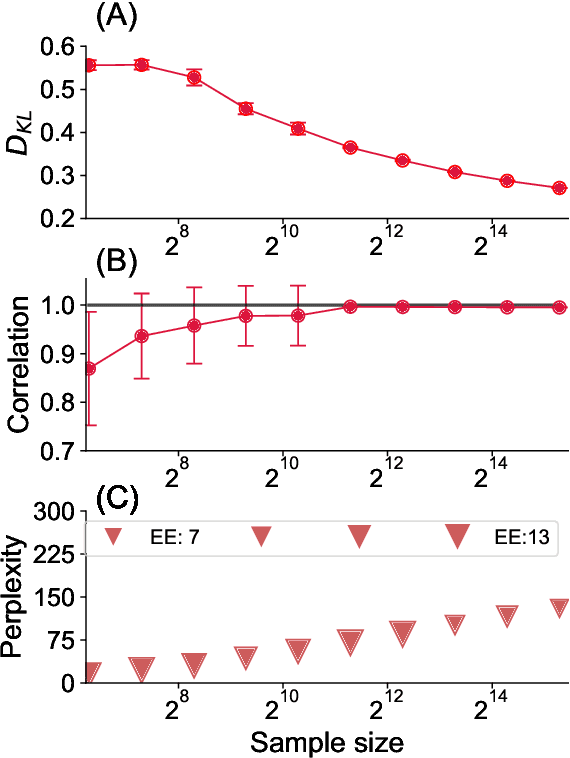
To construct models of large, multivariate complex systems, such as those in biology, one needs to constrain which variables are allowed to interact. This can be viewed as detecting ``local'' structures among the variables. In the context of a simple toy model of 2D natural and synthetic images, we show that pairwise correlations between the variables -- even when severely undersampled -- provide enough information to recover local relations, including the dimensionality of the data, and to reconstruct arrangement of pixels in fully scrambled images. This proves to be successful even though higher order interaction structures are present in our data. We build intuition behind the success, which we hope might contribute to modeling complex, multivariate systems and to explaining the success of modern attention-based machine learning approaches.
Explaining dark matter halo density profiles with neural networks
May 04, 2023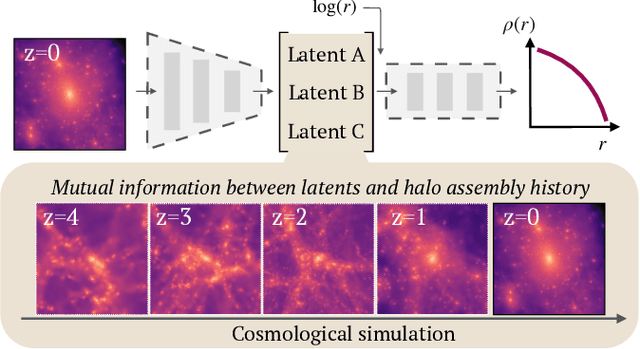
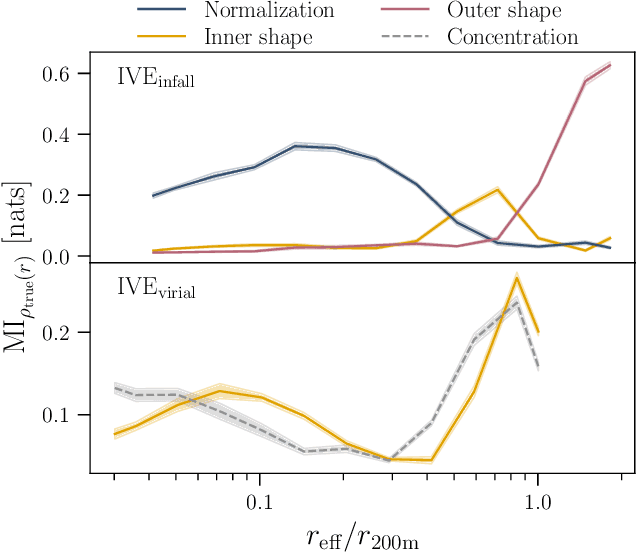
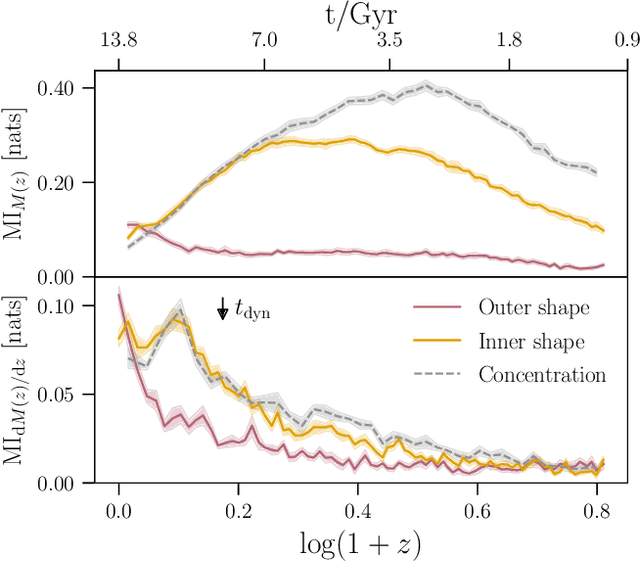
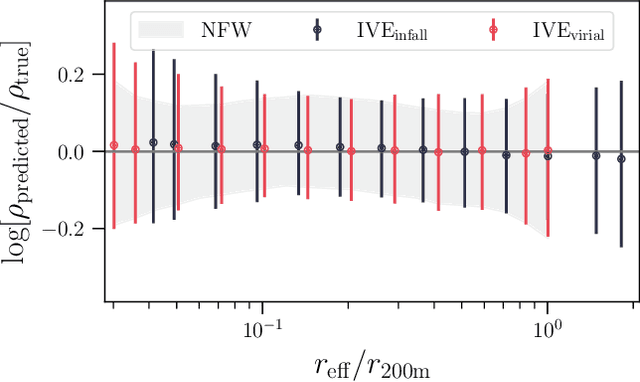
We use explainable neural networks to connect the evolutionary history of dark matter halos with their density profiles. The network captures independent factors of variation in the density profiles within a low-dimensional representation, which we physically interpret using mutual information. Without any prior knowledge of the halos' evolution, the network recovers the known relation between the early time assembly and the inner profile, and discovers that the profile beyond the virial radius is described by a single parameter capturing the most recent mass accretion rate. The results illustrate the potential for machine-assisted scientific discovery in complicated astrophysical datasets.
Train Your Own GNN Teacher: Graph-Aware Distillation on Textual Graphs
Apr 20, 2023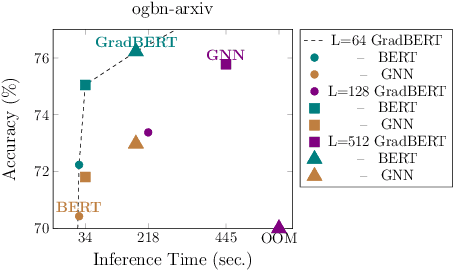
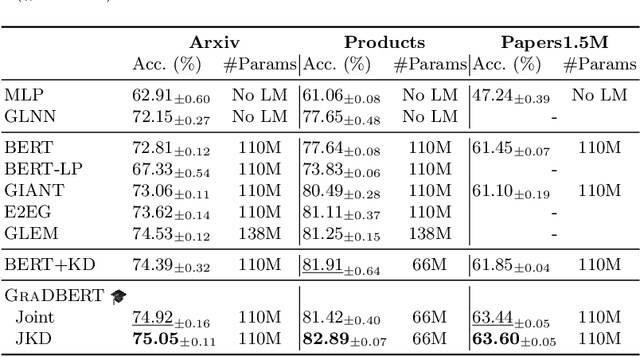
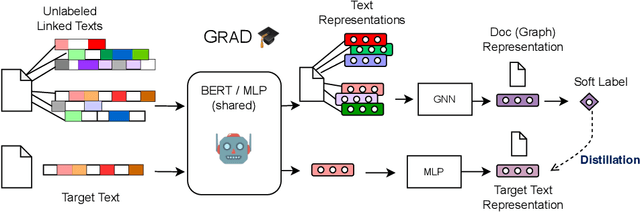
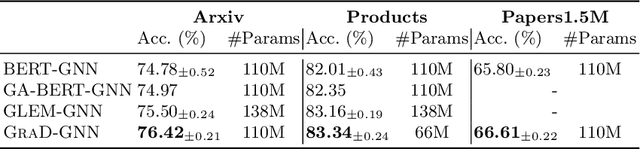
How can we learn effective node representations on textual graphs? Graph Neural Networks (GNNs) that use Language Models (LMs) to encode textual information of graphs achieve state-of-the-art performance in many node classification tasks. Yet, combining GNNs with LMs has not been widely explored for practical deployments due to its scalability issues. In this work, we tackle this challenge by developing a Graph-Aware Distillation framework (GRAD) to encode graph structures into an LM for graph-free, fast inference. Different from conventional knowledge distillation, GRAD jointly optimizes a GNN teacher and a graph-free student over the graph's nodes via a shared LM. This encourages the graph-free student to exploit graph information encoded by the GNN teacher while at the same time, enables the GNN teacher to better leverage textual information from unlabeled nodes. As a result, the teacher and the student models learn from each other to improve their overall performance. Experiments in eight node classification benchmarks in both transductive and inductive settings showcase GRAD's superiority over existing distillation approaches for textual graphs.