 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Gym-preCICE: Reinforcement Learning Environments for Active Flow Control
May 03, 2023
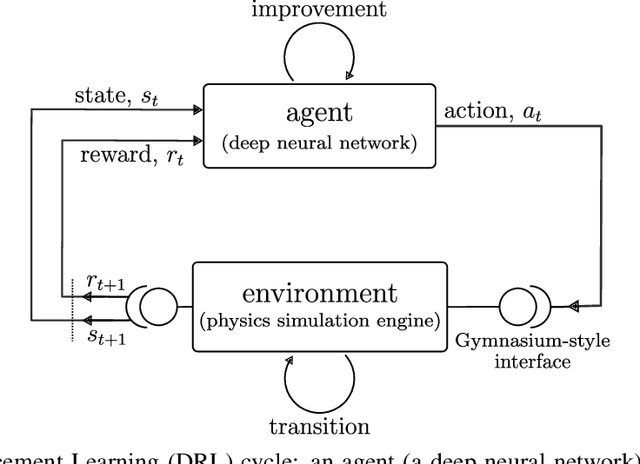
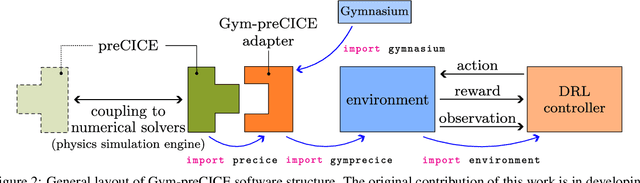
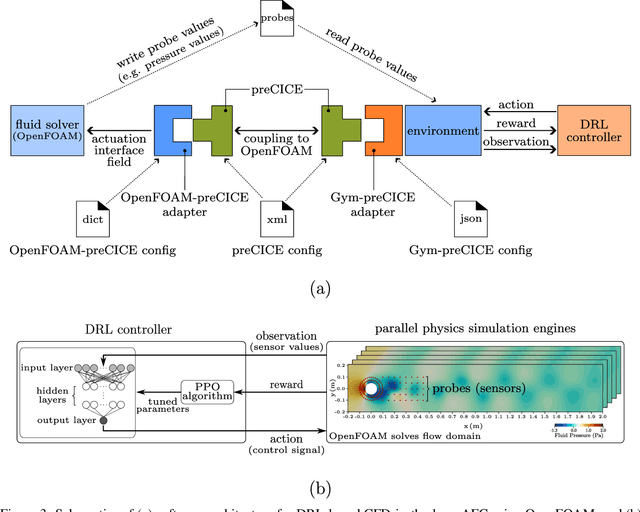
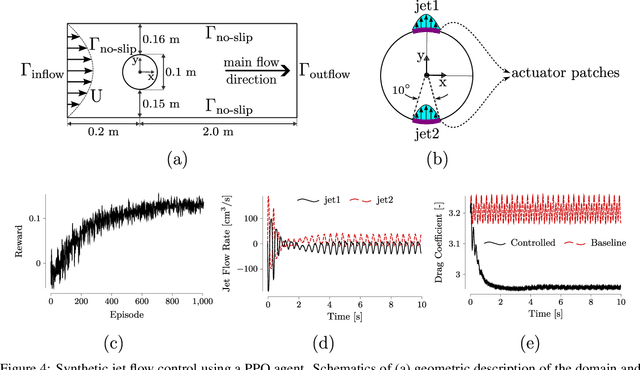
Active flow control (AFC) involves manipulating fluid flow over time to achieve a desired performance or efficiency. AFC, as a sequential optimisation task, can benefit from utilising Reinforcement Learning (RL) for dynamic optimisation. In this work, we introduce Gym-preCICE, a Python adapter fully compliant with Gymnasium (formerly known as OpenAI Gym) API to facilitate designing and developing RL environments for single- and multi-physics AFC applications. In an actor-environment setting, Gym-preCICE takes advantage of preCICE, an open-source coupling library for partitioned multi-physics simulations, to handle information exchange between a controller (actor) and an AFC simulation environment. The developed framework results in a seamless non-invasive integration of realistic physics-based simulation toolboxes with RL algorithms. Gym-preCICE provides a framework for designing RL environments to model AFC tasks, as well as a playground for applying RL algorithms in various AFC-related engineering applications.
Training Natural Language Processing Models on Encrypted Text for Enhanced Privacy
May 03, 2023With the increasing use of cloud-based services for training and deploying machine learning models, data privacy has become a major concern. This is particularly important for natural language processing (NLP) models, which often process sensitive information such as personal communications and confidential documents. In this study, we propose a method for training NLP models on encrypted text data to mitigate data privacy concerns while maintaining similar performance to models trained on non-encrypted data. We demonstrate our method using two different architectures, namely Doc2Vec+XGBoost and Doc2Vec+LSTM, and evaluate the models on the 20 Newsgroups dataset. Our results indicate that both encrypted and non-encrypted models achieve comparable performance, suggesting that our encryption method is effective in preserving data privacy without sacrificing model accuracy. In order to replicate our experiments, we have provided a Colab notebook at the following address: https://t.ly/lR-TP
FreMAE: Fourier Transform Meets Masked Autoencoders for Medical Image Segmentation
Apr 21, 2023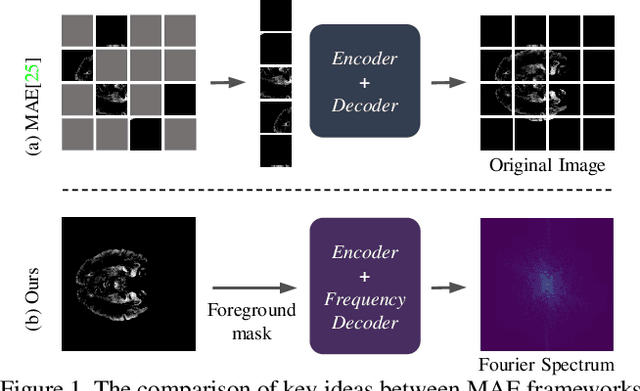
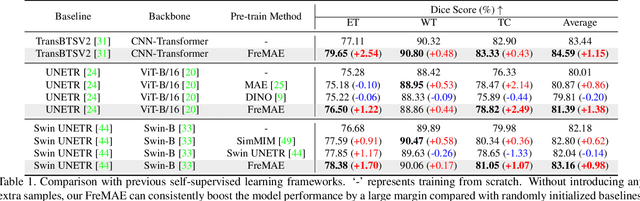
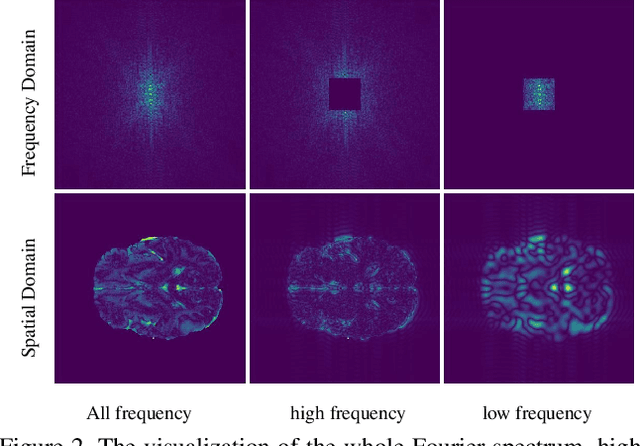
The research community has witnessed the powerful potential of self-supervised Masked Image Modeling (MIM), which enables the models capable of learning visual representation from unlabeled data. In this paper, to incorporate both the crucial global structural information and local details for dense prediction tasks, we alter the perspective to the frequency domain and present a new MIM-based framework named FreMAE for self-supervised pre-training for medical image segmentation. Based on the observations that the detailed structural information mainly lies in the high-frequency components and the high-level semantics are abundant in the low-frequency counterparts, we further incorporate multi-stage supervision to guide the representation learning during the pre-training phase. Extensive experiments on three benchmark datasets show the superior advantage of our proposed FreMAE over previous state-of-the-art MIM methods. Compared with various baselines trained from scratch, our FreMAE could consistently bring considerable improvements to the model performance. To the best our knowledge, this is the first attempt towards MIM with Fourier Transform in medical image segmentation.
Hybrid Deepfake Detection Utilizing MLP and LSTM
Apr 21, 2023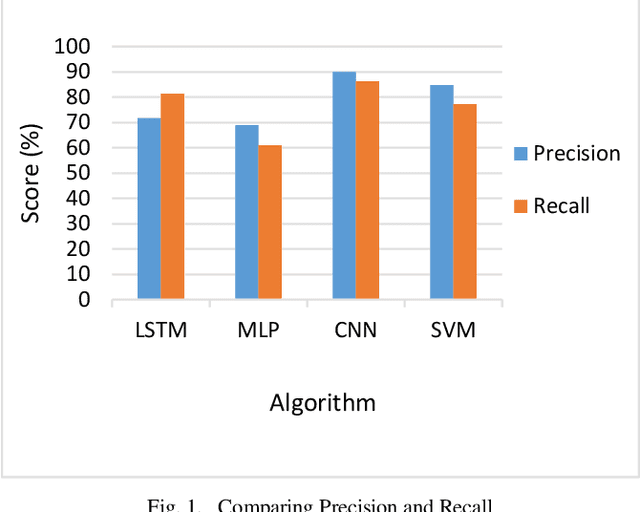
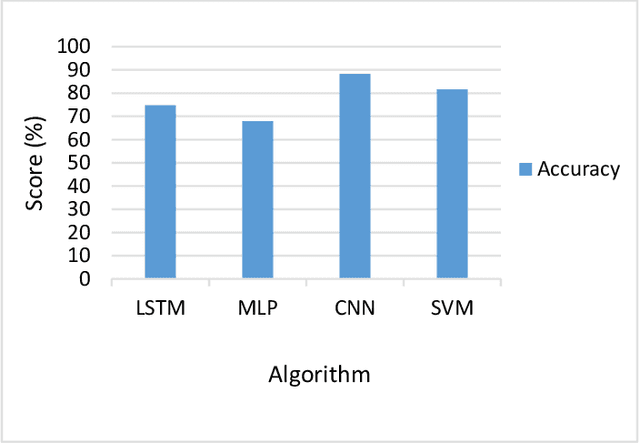
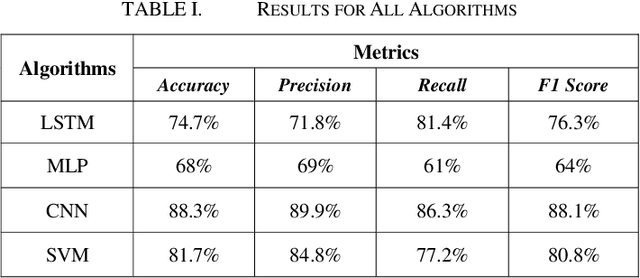
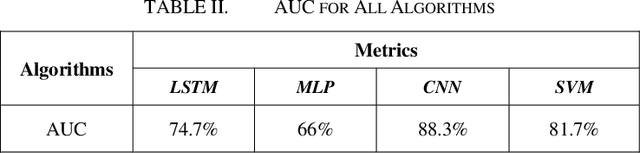
The growing reliance of society on social media for authentic information has done nothing but increase over the past years. This has only raised the potential consequences of the spread of misinformation. One of the growing methods in popularity is to deceive users using a deepfake. A deepfake is an invention that has come with the latest technological advancements, which enables nefarious online users to replace their face with a computer generated, synthetic face of numerous powerful members of society. Deepfake images and videos now provide the means to mimic important political and cultural figures to spread massive amounts of false information. Models that can detect these deepfakes to prevent the spread of misinformation are now of tremendous necessity. In this paper, we propose a new deepfake detection schema utilizing two deep learning algorithms: long short term memory and multilayer perceptron. We evaluate our model using a publicly available dataset named 140k Real and Fake Faces to detect images altered by a deepfake with accuracies achieved as high as 74.7%
Voxel-wise classification for porosity investigation of additive manufactured parts with 3D unsupervised and (deeply) supervised neural networks
May 13, 2023
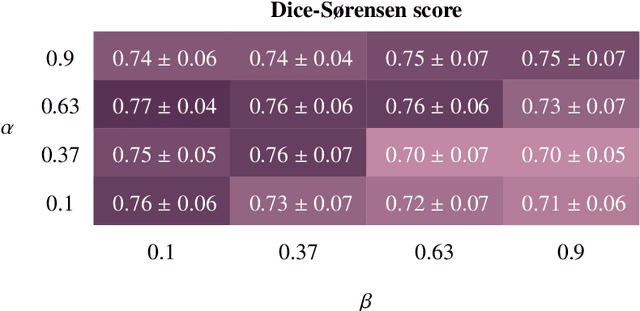


Additive Manufacturing (AM) has emerged as a manufacturing process that allows the direct production of samples from digital models. To ensure that quality standards are met in all manufactured samples of a batch, X-ray computed tomography (X-CT) is often used combined with automated anomaly detection. For the latter, deep learning (DL) anomaly detection techniques are increasingly, as they can be trained to be robust to the material being analysed and resilient towards poor image quality. Unfortunately, most recent and popular DL models have been developed for 2D image processing, thereby disregarding valuable volumetric information. This study revisits recent supervised (UNet, UNet++, UNet 3+, MSS-UNet) and unsupervised (VAE, ceVAE, gmVAE, vqVAE) DL models for porosity analysis of AM samples from X-CT images and extends them to accept 3D input data with a 3D-patch pipeline for lower computational requirements, improved efficiency and generalisability. The supervised models were trained using the Focal Tversky loss to address class imbalance that arises from the low porosity in the training datasets. The output of the unsupervised models is post-processed to reduce misclassifications caused by their inability to adequately represent the object surface. The findings were cross-validated in a 5-fold fashion and include: a performance benchmark of the DL models, an evaluation of the post-processing algorithm, an evaluation of the effect of training supervised models with the output of unsupervised models. In a final performance benchmark on a test set with poor image quality, the best performing supervised model was MSS-UNet with an average precision of 0.808 $\pm$ 0.013, while the best unsupervised model was the post-processed ceVAE with 0.935 $\pm$ 0.001. The VAE/ceVAE models demonstrated superior capabilities, particularly when leveraging post-processing techniques.
Language models can generate molecules, materials, and protein binding sites directly in three dimensions as XYZ, CIF, and PDB files
May 09, 2023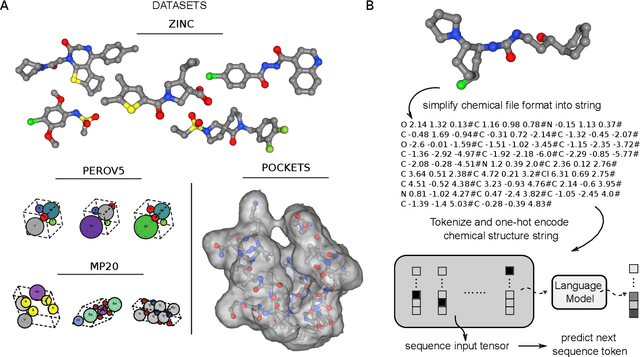
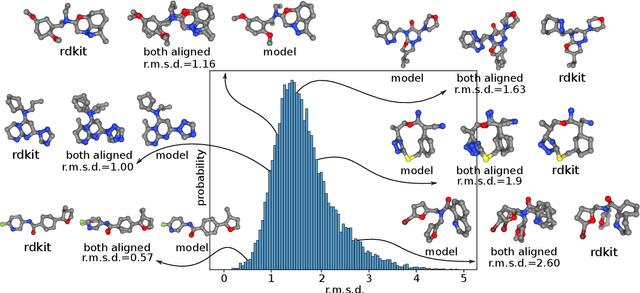
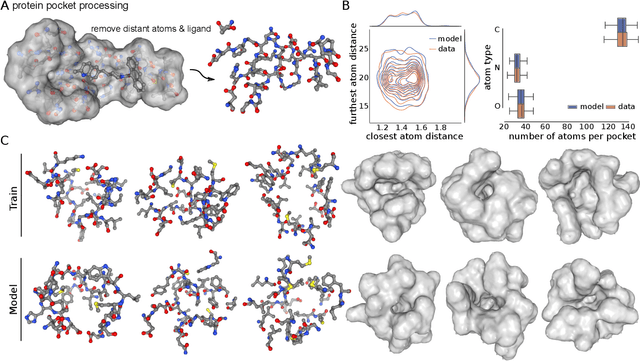
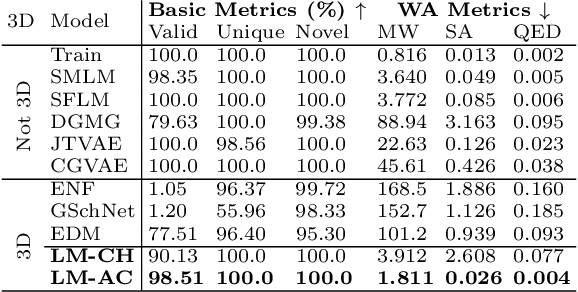
Language models are powerful tools for molecular design. Currently, the dominant paradigm is to parse molecular graphs into linear string representations that can easily be trained on. This approach has been very successful, however, it is limited to chemical structures that can be completely represented by a graph -- like organic molecules -- while materials and biomolecular structures like protein binding sites require a more complete representation that includes the relative positioning of their atoms in space. In this work, we show how language models, without any architecture modifications, trained using next-token prediction -- can generate novel and valid structures in three dimensions from various substantially different distributions of chemical structures. In particular, we demonstrate that language models trained directly on sequences derived directly from chemical file formats like XYZ files, Crystallographic Information files (CIFs), or Protein Data Bank files (PDBs) can directly generate molecules, crystals, and protein binding sites in three dimensions. Furthermore, despite being trained on chemical file sequences -- language models still achieve performance comparable to state-of-the-art models that use graph and graph-derived string representations, as well as other domain-specific 3D generative models. In doing so, we demonstrate that it is not necessary to use simplified molecular representations to train chemical language models -- that they are powerful generative models capable of directly exploring chemical space in three dimensions for very different structures.
Turning Privacy-preserving Mechanisms against Federated Learning
May 09, 2023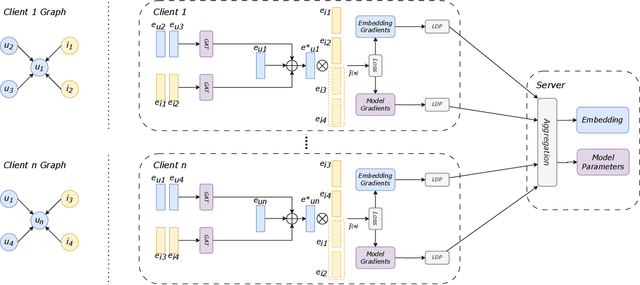
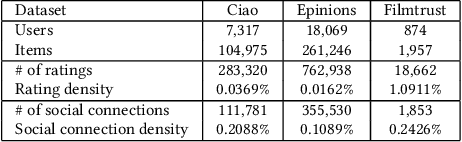
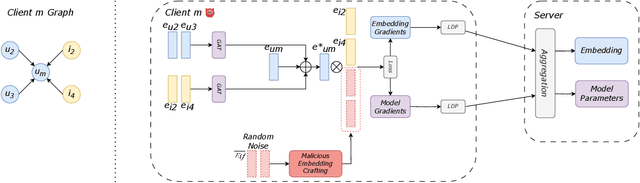
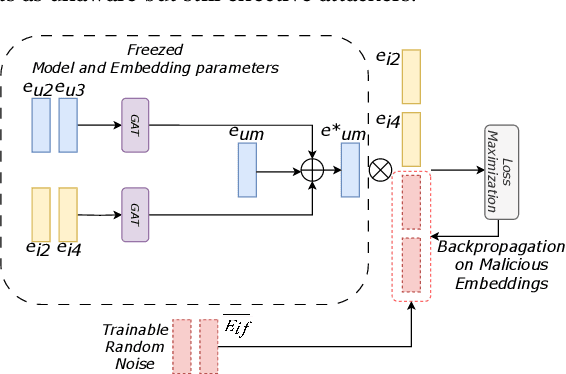
Recently, researchers have successfully employed Graph Neural Networks (GNNs) to build enhanced recommender systems due to their capability to learn patterns from the interaction between involved entities. In addition, previous studies have investigated federated learning as the main solution to enable a native privacy-preserving mechanism for the construction of global GNN models without collecting sensitive data into a single computation unit. Still, privacy issues may arise as the analysis of local model updates produced by the federated clients can return information related to sensitive local data. For this reason, experts proposed solutions that combine federated learning with Differential Privacy strategies and community-driven approaches, which involve combining data from neighbor clients to make the individual local updates less dependent on local sensitive data. In this paper, we identify a crucial security flaw in such a configuration, and we design an attack capable of deceiving state-of-the-art defenses for federated learning. The proposed attack includes two operating modes, the first one focusing on convergence inhibition (Adversarial Mode), and the second one aiming at building a deceptive rating injection on the global federated model (Backdoor Mode). The experimental results show the effectiveness of our attack in both its modes, returning on average 60% performance detriment in all the tests on Adversarial Mode and fully effective backdoors in 93% of cases for the tests performed on Backdoor Mode.
Ranking & Reweighting Improves Group Distributional Robustness
May 09, 2023
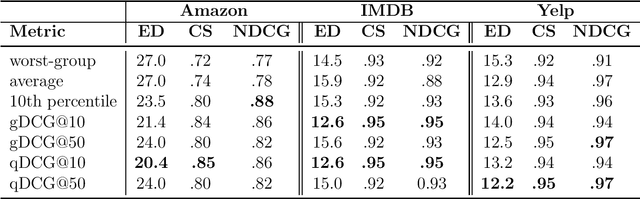
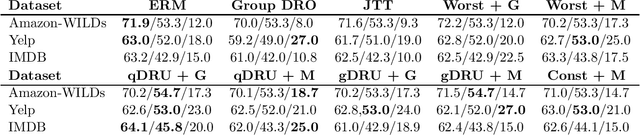
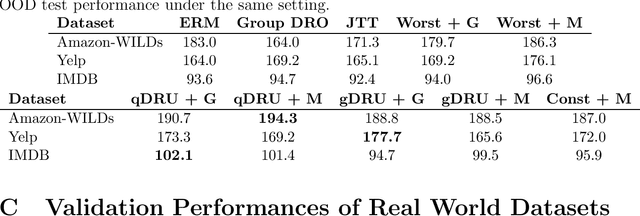
Recent work has shown that standard training via empirical risk minimization (ERM) can produce models that achieve high accuracy on average but low accuracy on underrepresented groups due to the prevalence of spurious features. A predominant approach to tackle this group robustness problem minimizes the worst group error (akin to a minimax strategy) on the training data, hoping it will generalize well on the testing data. However, this is often suboptimal, especially when the out-of-distribution (OOD) test data contains previously unseen groups. Inspired by ideas from the information retrieval and learning-to-rank literature, this paper first proposes to use Discounted Cumulative Gain (DCG) as a metric of model quality for facilitating better hyperparameter tuning and model selection. Being a ranking-based metric, DCG weights multiple poorly-performing groups (instead of considering just the group with the worst performance). As a natural next step, we build on our results to propose a ranking-based training method called Discounted Rank Upweighting (DRU), which differentially reweights a ranked list of poorly-performing groups in the training data to learn models that exhibit strong OOD performance on the test data. Results on several synthetic and real-world datasets highlight the superior generalization ability of our group-ranking-based (akin to soft-minimax) approach in selecting and learning models that are robust to group distributional shifts.
Robust Beamforming Design for RIS-aided Cell-free Systems with CSI Uncertainties and Capacity-limited Backhaul
May 09, 2023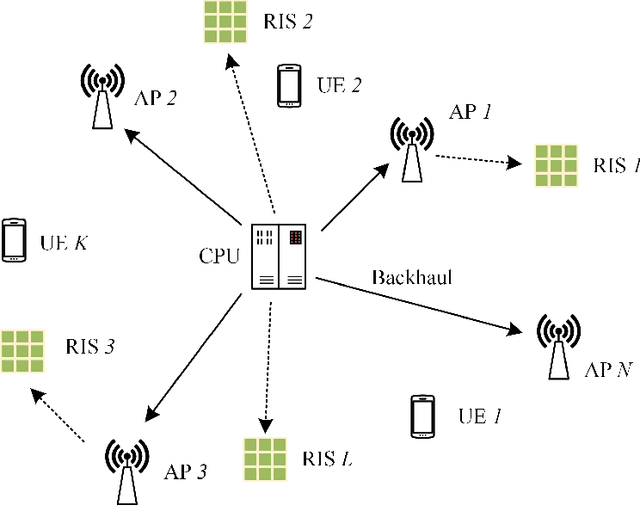
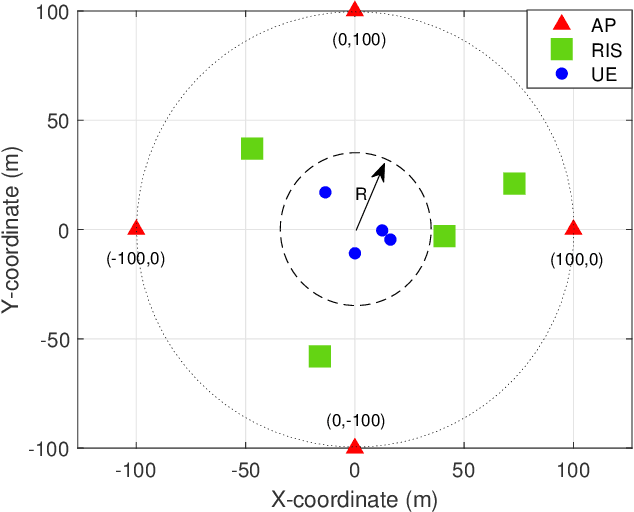
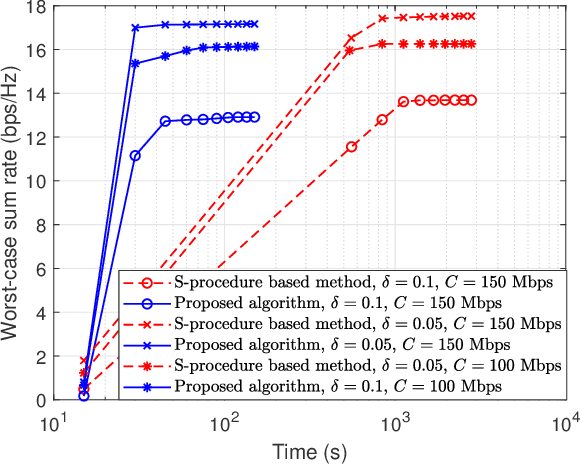
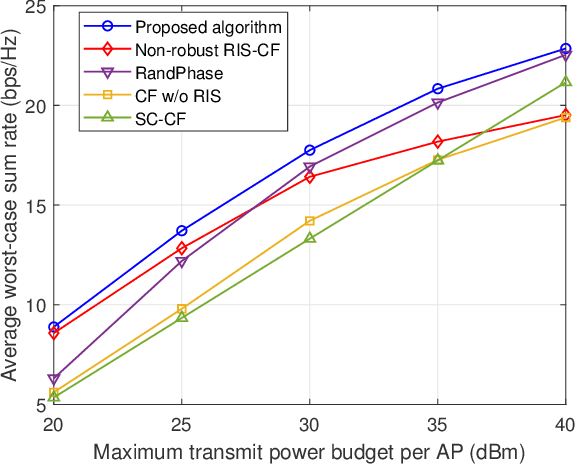
In this paper, we consider the robust beamforming design in a reconfigurable intelligent surface (RIS)-aided cell-free (CF) system considering the channel state information (CSI) uncertainties of both the direct channels and cascaded channels at the transmitter with capacity-limited backhaul. We jointly optimize the precoding at the access points (APs) and the phase shifts at multiple RISs to maximize the worst-case sum rate of the CF system subject to the constraints of maximum transmit power of APs, unit-modulus phase shifts, limited backhaul capacity, and bounded CSI errors. By applying a series of transformations, the non-smoothness and semi-infinite constraints are tackled in a low-complexity manner that facilitates the design of an alternating optimization (AO)-based iterative algorithm. The proposed algorithm divides the considered problem into two subproblems. For the RIS phase shifts optimization subproblem, we exploit the penalty convex-concave procedure (P-CCP) to obtain a stationary solution and achieve effective initialization. For precoding optimization subproblem, successive convex approximation (SCA) is adopted with a convergence guarantee to a Karush-Kuhn-Tucker (KKT) solution. Numerical results demonstrate the effectiveness of the proposed robust beamforming design, which achieves superior performance with low complexity. Moreover, the importance of RIS phase shift optimization for robustness and the advantages of distributed RISs in the CF system are further highlighted.
Communication-Robust Multi-Agent Learning by Adaptable Auxiliary Multi-Agent Adversary Generation
May 09, 2023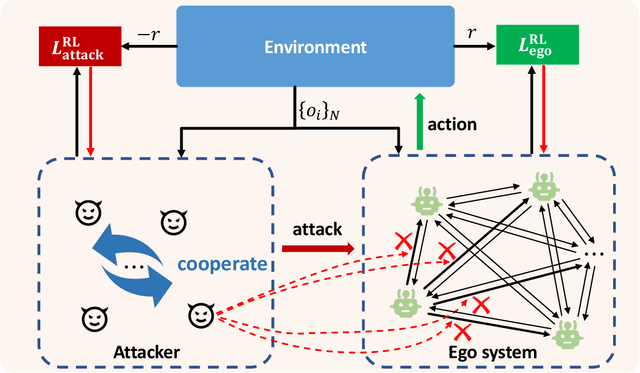
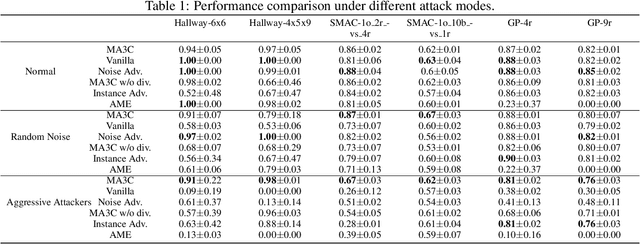
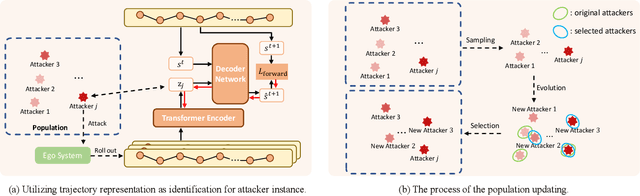
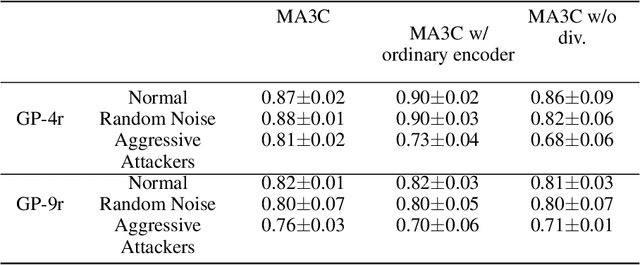
Communication can promote coordination in cooperative Multi-Agent Reinforcement Learning (MARL). Nowadays, existing works mainly focus on improving the communication efficiency of agents, neglecting that real-world communication is much more challenging as there may exist noise or potential attackers. Thus the robustness of the communication-based policies becomes an emergent and severe issue that needs more exploration. In this paper, we posit that the ego system trained with auxiliary adversaries may handle this limitation and propose an adaptable method of Multi-Agent Auxiliary Adversaries Generation for robust Communication, dubbed MA3C, to obtain a robust communication-based policy. In specific, we introduce a novel message-attacking approach that models the learning of the auxiliary attacker as a cooperative problem under a shared goal to minimize the coordination ability of the ego system, with which every information channel may suffer from distinct message attacks. Furthermore, as naive adversarial training may impede the generalization ability of the ego system, we design an attacker population generation approach based on evolutionary learning. Finally, the ego system is paired with an attacker population and then alternatively trained against the continuously evolving attackers to improve its robustness, meaning that both the ego system and the attackers are adaptable. Extensive experiments on multiple benchmarks indicate that our proposed MA3C provides comparable or better robustness and generalization ability than other baselines.