 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
APR: Online Distant Point Cloud Registration Through Aggregated Point Cloud Reconstruction
May 04, 2023
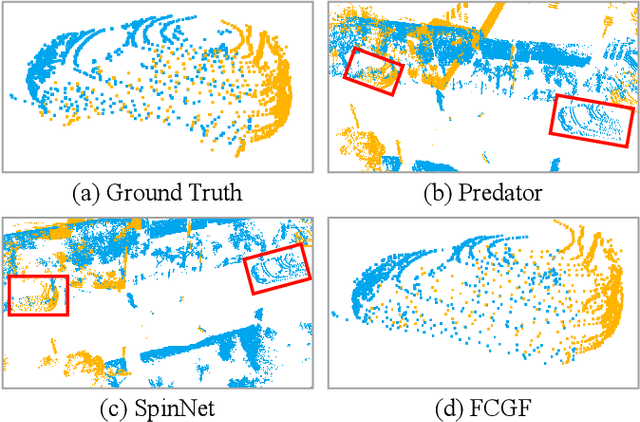
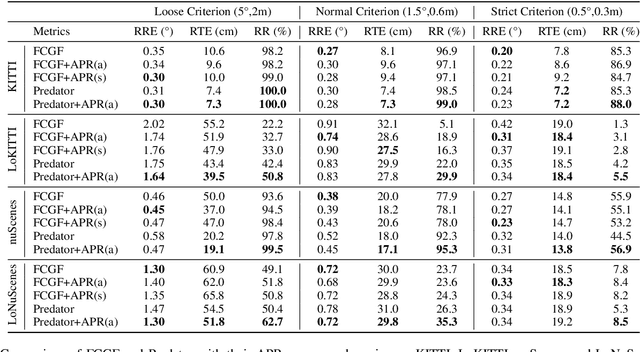
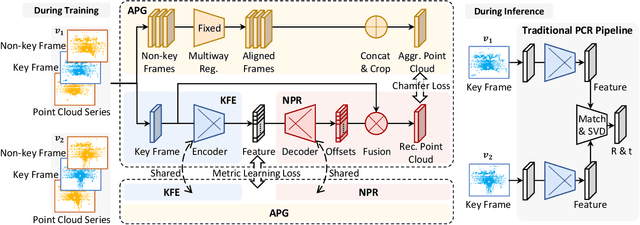
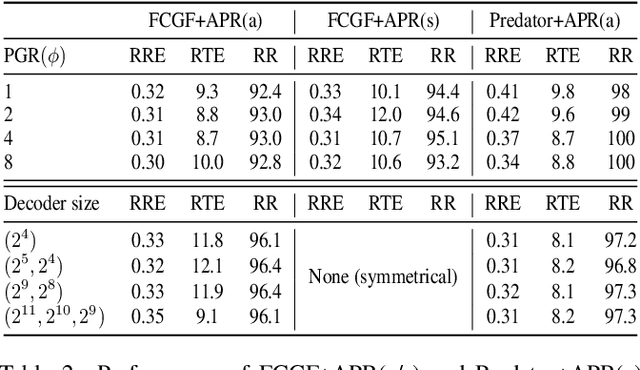
For many driving safety applications, it is of great importance to accurately register LiDAR point clouds generated on distant moving vehicles. However, such point clouds have extremely different point density and sensor perspective on the same object, making registration on such point clouds very hard. In this paper, we propose a novel feature extraction framework, called APR, for online distant point cloud registration. Specifically, APR leverages an autoencoder design, where the autoencoder reconstructs a denser aggregated point cloud with several frames instead of the original single input point cloud. Our design forces the encoder to extract features with rich local geometry information based on one single input point cloud. Such features are then used for online distant point cloud registration. We conduct extensive experiments against state-of-the-art (SOTA) feature extractors on KITTI and nuScenes datasets. Results show that APR outperforms all other extractors by a large margin, increasing average registration recall of SOTA extractors by 7.1% on LoKITTI and 4.6% on LoNuScenes.
Mining fMRI Dynamics with Parcellation Prior for Brain Disease Diagnosis
May 04, 2023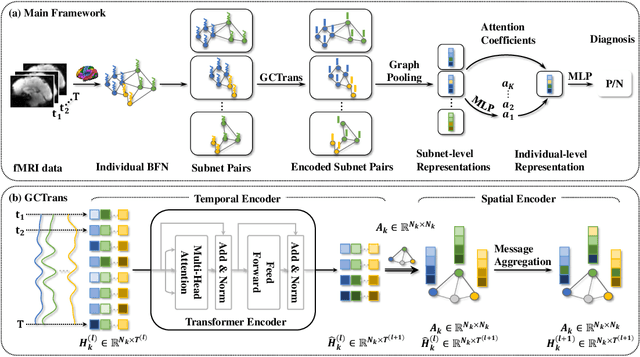
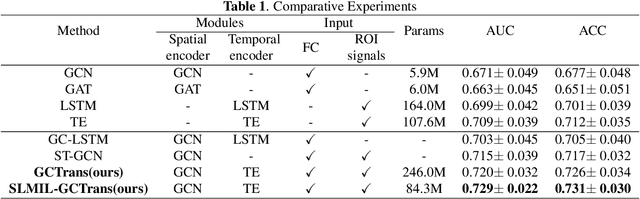
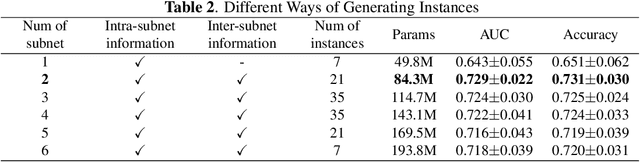
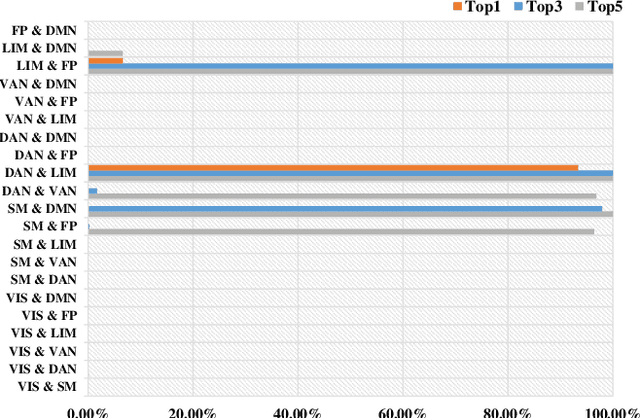
To characterize atypical brain dynamics under diseases, prevalent studies investigate functional magnetic resonance imaging (fMRI). However, most of the existing analyses compress rich spatial-temporal information as the brain functional networks (BFNs) and directly investigate the whole-brain network without neurological priors about functional subnetworks. We thus propose a novel graph learning framework to mine fMRI signals with topological priors from brain parcellation for disease diagnosis. Specifically, we 1) detect diagnosis-related temporal features using a "Transformer" for a higher-level BFN construction, and process it with a following graph convolutional network, and 2) apply an attention-based multiple instance learning strategy to emphasize the disease-affected subnetworks to further enhance the diagnosis performance and interpretability. Experiments demonstrate higher effectiveness of our method than compared methods in the diagnosis of early mild cognitive impairment. More importantly, our method is capable of localizing crucial brain subnetworks during the diagnosis, providing insights into the pathogenic source of mild cognitive impairment.
G-MATT: Single-step Retrosynthesis Prediction using Molecular Grammar Tree Transformer
May 04, 2023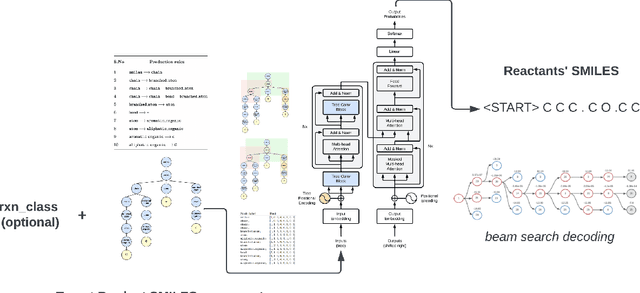
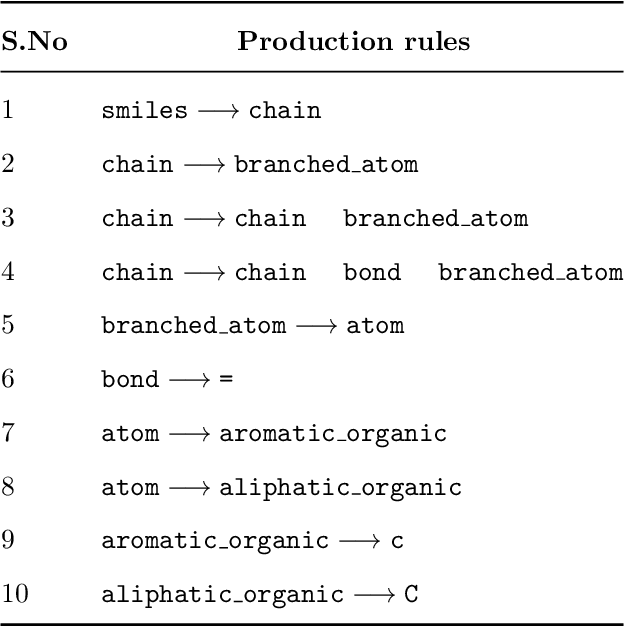
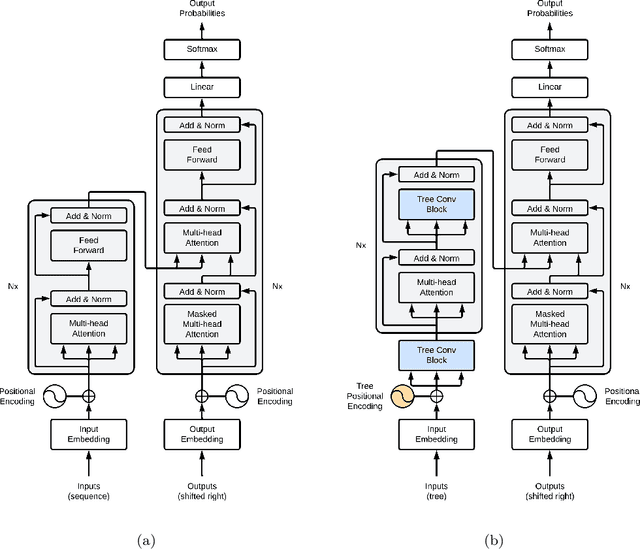

In recent years, several reaction templates-based and template-free approaches have been reported for single-step retrosynthesis prediction. Even though many of these approaches perform well from traditional data-driven metrics standpoint, there is a disconnect between model architectures used and underlying chemistry principles governing retrosynthesis. Here, we propose a novel chemistry-aware retrosynthesis prediction framework that combines powerful data-driven models with chemistry knowledge. We report a tree-to-sequence transformer architecture based on hierarchical SMILES grammar trees as input containing underlying chemistry information that is otherwise ignored by models based on purely SMILES-based representations. The proposed framework, grammar-based molecular attention tree transformer (G-MATT), achieves significant performance improvements compared to baseline retrosynthesis models. G-MATT achieves a top-1 accuracy of 51% (top-10 accuracy of 79.1%), invalid rate of 1.5%, and bioactive similarity rate of 74.8%. Further analyses based on attention maps demonstrate G-MATT's ability to preserve chemistry knowledge without having to use extremely complex model architectures.
MMRDN: Consistent Representation for Multi-View Manipulation Relationship Detection in Object-Stacked Scenes
Apr 25, 2023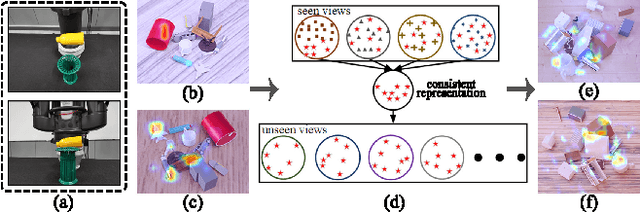
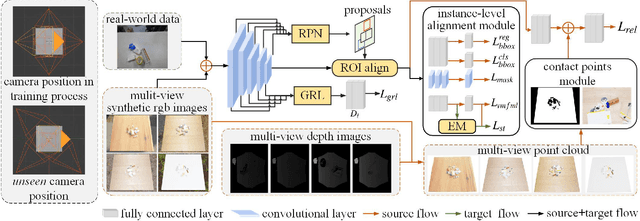
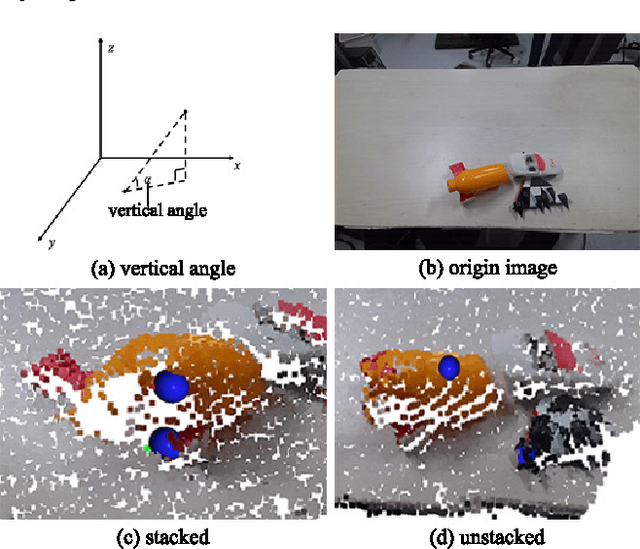
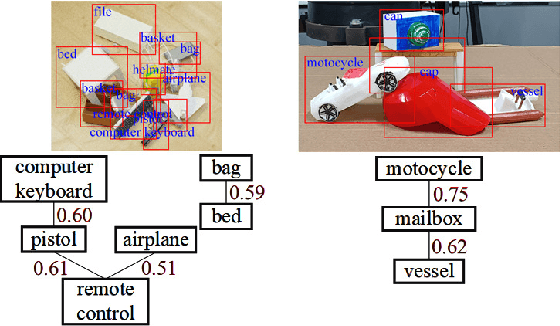
Manipulation relationship detection (MRD) aims to guide the robot to grasp objects in the right order, which is important to ensure the safety and reliability of grasping in object stacked scenes. Previous works infer manipulation relationship by deep neural network trained with data collected from a predefined view, which has limitation in visual dislocation in unstructured environments. Multi-view data provide more comprehensive information in space, while a challenge of multi-view MRD is domain shift. In this paper, we propose a novel multi-view fusion framework, namely multi-view MRD network (MMRDN), which is trained by 2D and 3D multi-view data. We project the 2D data from different views into a common hidden space and fit the embeddings with a set of Von-Mises-Fisher distributions to learn the consistent representations. Besides, taking advantage of position information within the 3D data, we select a set of $K$ Maximum Vertical Neighbors (KMVN) points from the point cloud of each object pair, which encodes the relative position of these two objects. Finally, the features of multi-view 2D and 3D data are concatenated to predict the pairwise relationship of objects. Experimental results on the challenging REGRAD dataset show that MMRDN outperforms the state-of-the-art methods in multi-view MRD tasks. The results also demonstrate that our model trained by synthetic data is capable to transfer to real-world scenarios.
MG-ShopDial: A Multi-Goal Conversational Dataset for e-Commerce
Apr 25, 2023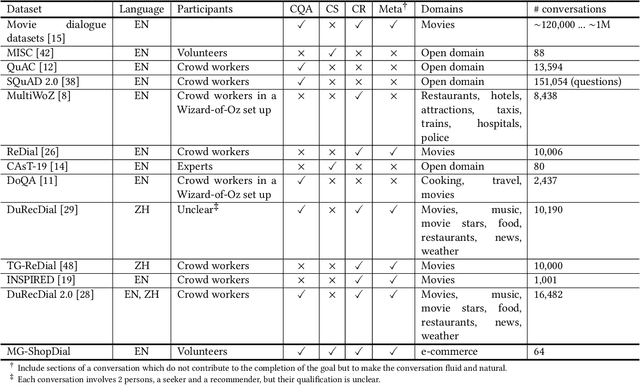

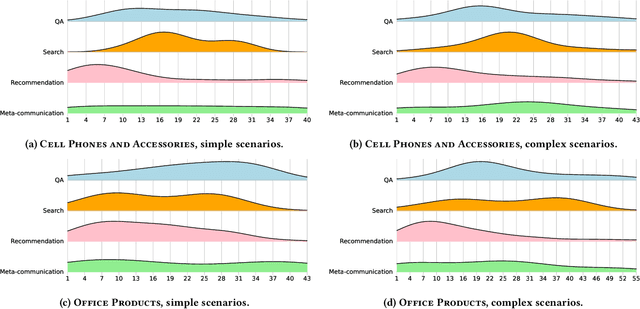
Conversational systems can be particularly effective in supporting complex information seeking scenarios with evolving information needs. Finding the right products on an e-commerce platform is one such scenario, where a conversational agent would need to be able to provide search capabilities over the item catalog, understand and make recommendations based on the user's preferences, and answer a range of questions related to items and their usage. Yet, existing conversational datasets do not fully support the idea of mixing different conversational goals (i.e., search, recommendation, and question answering) and instead focus on a single goal. To address this, we introduce MG-ShopDial: a dataset of conversations mixing different goals in the domain of e-commerce. Specifically, we make the following contributions. First, we develop a coached human-human data collection protocol where each dialogue participant is given a set of instructions, instead of a specific script or answers to choose from. Second, we implement a data collection tool to facilitate the collection of multi-goal conversations via a web chat interface, using the above protocol. Third, we create the MG-ShopDial collection, which contains 64 high-quality dialogues with a total of 2,196 utterances for e-commerce scenarios of varying complexity. The dataset is additionally annotated with both intents and goals on the utterance level. Finally, we present an analysis of this dataset and identify multi-goal conversational patterns.
FreMAE: Fourier Transform Meets Masked Autoencoders for Medical Image Segmentation
Apr 21, 2023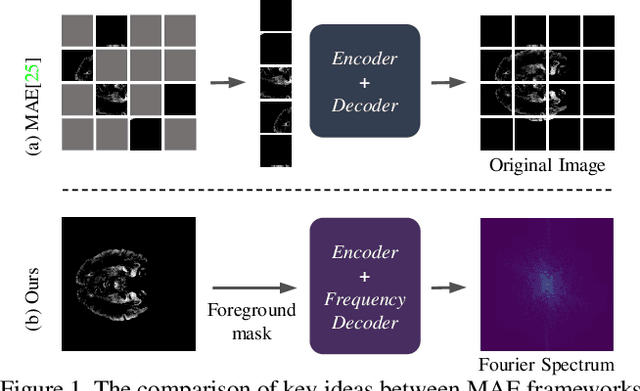
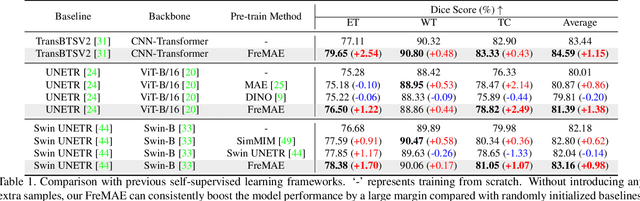
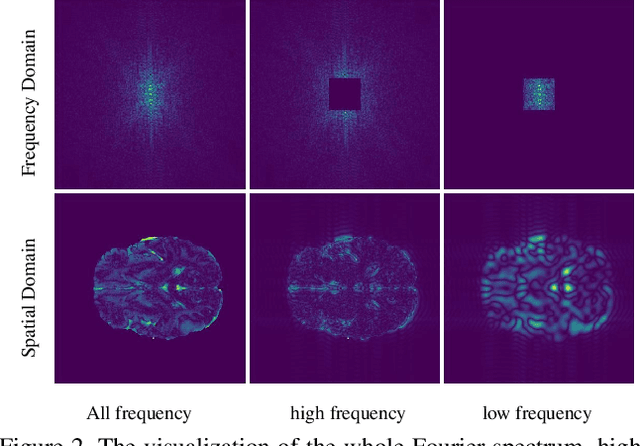
The research community has witnessed the powerful potential of self-supervised Masked Image Modeling (MIM), which enables the models capable of learning visual representation from unlabeled data. In this paper, to incorporate both the crucial global structural information and local details for dense prediction tasks, we alter the perspective to the frequency domain and present a new MIM-based framework named FreMAE for self-supervised pre-training for medical image segmentation. Based on the observations that the detailed structural information mainly lies in the high-frequency components and the high-level semantics are abundant in the low-frequency counterparts, we further incorporate multi-stage supervision to guide the representation learning during the pre-training phase. Extensive experiments on three benchmark datasets show the superior advantage of our proposed FreMAE over previous state-of-the-art MIM methods. Compared with various baselines trained from scratch, our FreMAE could consistently bring considerable improvements to the model performance. To the best our knowledge, this is the first attempt towards MIM with Fourier Transform in medical image segmentation.
Hybrid Deepfake Detection Utilizing MLP and LSTM
Apr 21, 2023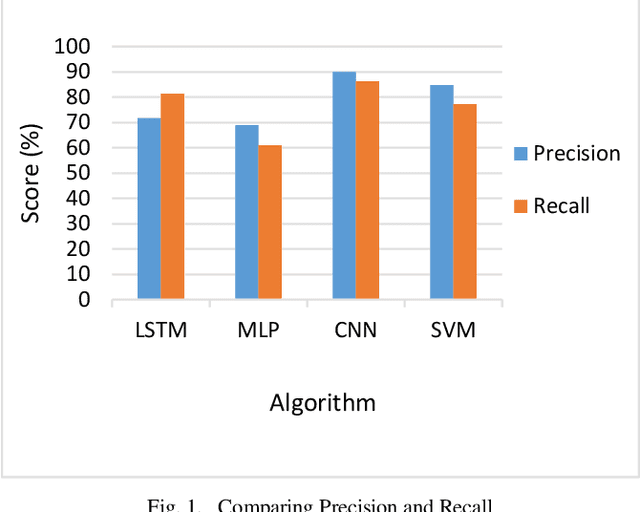
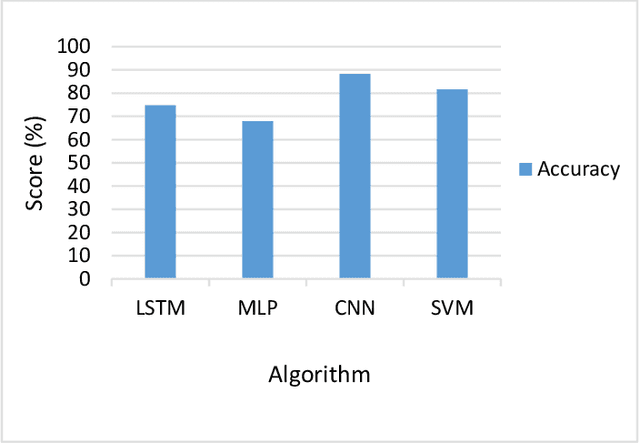
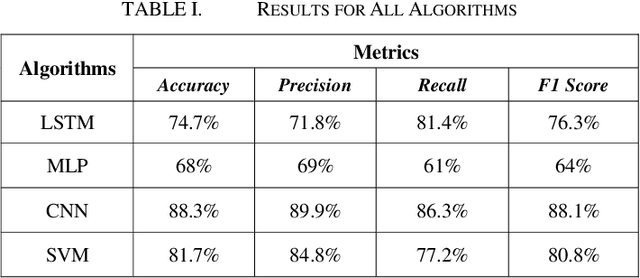
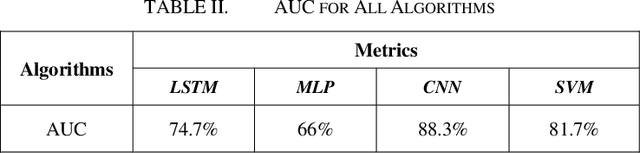
The growing reliance of society on social media for authentic information has done nothing but increase over the past years. This has only raised the potential consequences of the spread of misinformation. One of the growing methods in popularity is to deceive users using a deepfake. A deepfake is an invention that has come with the latest technological advancements, which enables nefarious online users to replace their face with a computer generated, synthetic face of numerous powerful members of society. Deepfake images and videos now provide the means to mimic important political and cultural figures to spread massive amounts of false information. Models that can detect these deepfakes to prevent the spread of misinformation are now of tremendous necessity. In this paper, we propose a new deepfake detection schema utilizing two deep learning algorithms: long short term memory and multilayer perceptron. We evaluate our model using a publicly available dataset named 140k Real and Fake Faces to detect images altered by a deepfake with accuracies achieved as high as 74.7%
Distributed Leader Follower Formation Control of Mobile Robots based on Bioinspired Neural Dynamics and Adaptive Sliding Innovation Filter
May 03, 2023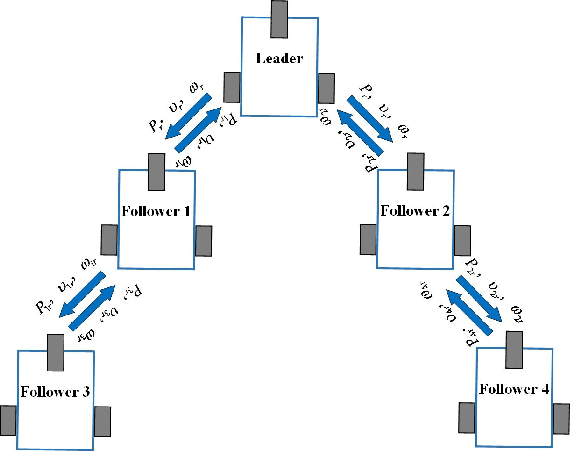
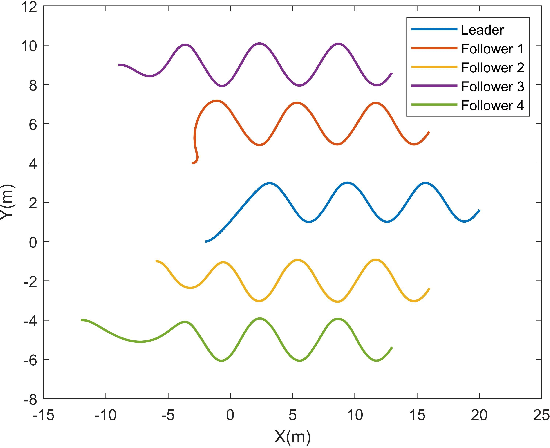
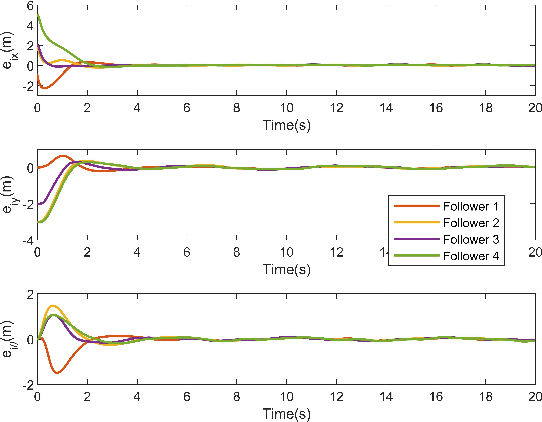
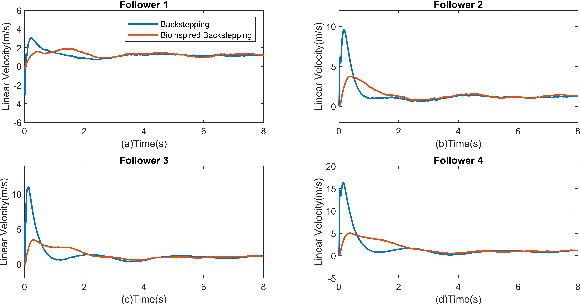
This paper investigated the distributed leader follower formation control problem for multiple differentially driven mobile robots. A distributed estimator is first introduced and it only requires the state information from each follower itself and its neighbors. Then, we propose a bioinspired neural dynamic based backstepping and sliding mode control hybrid formation control method with proof of its stability. The proposed control strategy resolves the impractical speed jump issue that exists in the conventional backstepping design. Additionally, considering the system and measurement noises, the proposed control strategy not only removes the chattering issue existing in the conventional sliding mode control but also provides smooth control input with extra robustness. After that, an adaptive sliding innovation filter is integrated with the proposed control to provide accurate state estimates that are robust to modeling uncertainties. Finally, we performed multiple simulations to demonstrate the efficiency and effectiveness of the proposed formation control strategy.
Training Natural Language Processing Models on Encrypted Text for Enhanced Privacy
May 03, 2023With the increasing use of cloud-based services for training and deploying machine learning models, data privacy has become a major concern. This is particularly important for natural language processing (NLP) models, which often process sensitive information such as personal communications and confidential documents. In this study, we propose a method for training NLP models on encrypted text data to mitigate data privacy concerns while maintaining similar performance to models trained on non-encrypted data. We demonstrate our method using two different architectures, namely Doc2Vec+XGBoost and Doc2Vec+LSTM, and evaluate the models on the 20 Newsgroups dataset. Our results indicate that both encrypted and non-encrypted models achieve comparable performance, suggesting that our encryption method is effective in preserving data privacy without sacrificing model accuracy. In order to replicate our experiments, we have provided a Colab notebook at the following address: https://t.ly/lR-TP
Gym-preCICE: Reinforcement Learning Environments for Active Flow Control
May 03, 2023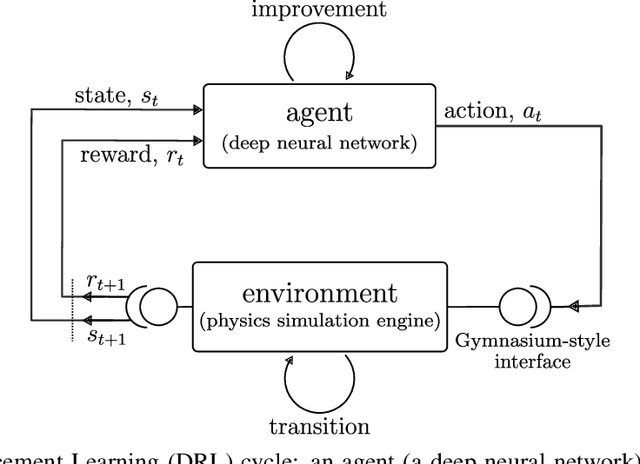
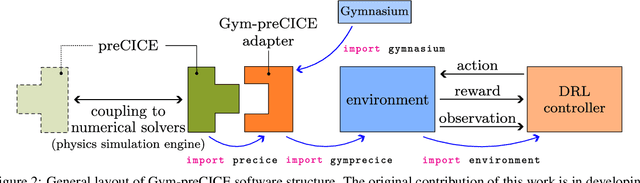
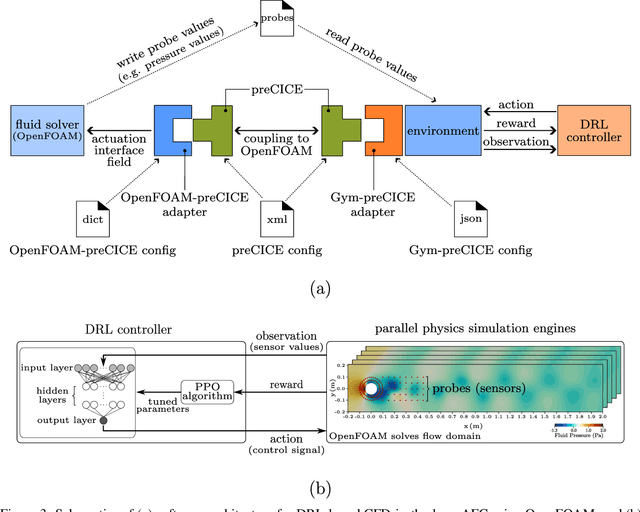
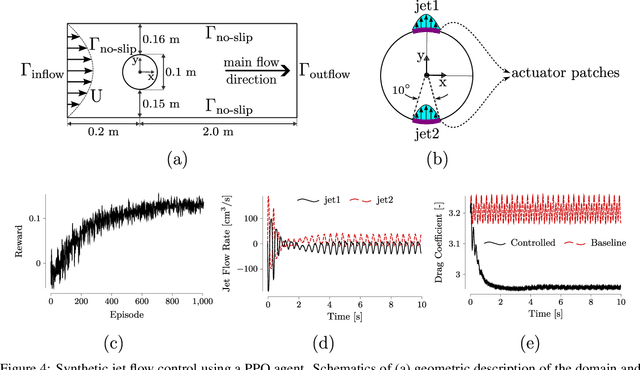
Active flow control (AFC) involves manipulating fluid flow over time to achieve a desired performance or efficiency. AFC, as a sequential optimisation task, can benefit from utilising Reinforcement Learning (RL) for dynamic optimisation. In this work, we introduce Gym-preCICE, a Python adapter fully compliant with Gymnasium (formerly known as OpenAI Gym) API to facilitate designing and developing RL environments for single- and multi-physics AFC applications. In an actor-environment setting, Gym-preCICE takes advantage of preCICE, an open-source coupling library for partitioned multi-physics simulations, to handle information exchange between a controller (actor) and an AFC simulation environment. The developed framework results in a seamless non-invasive integration of realistic physics-based simulation toolboxes with RL algorithms. Gym-preCICE provides a framework for designing RL environments to model AFC tasks, as well as a playground for applying RL algorithms in various AFC-related engineering applications.