 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RetroMAE-2: Duplex Masked Auto-Encoder For Pre-Training Retrieval-Oriented Language Models
May 04, 2023
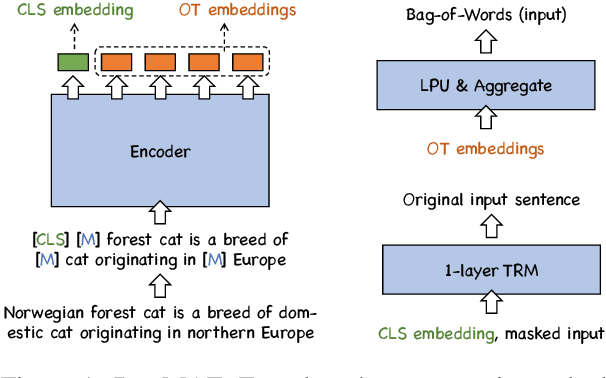
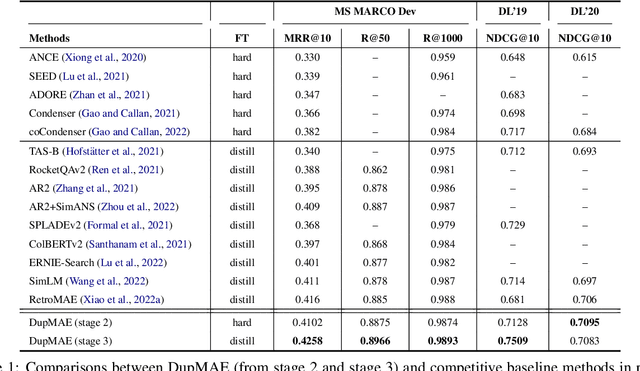
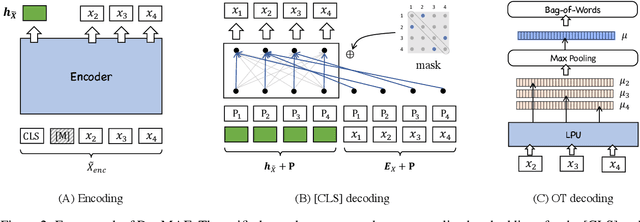
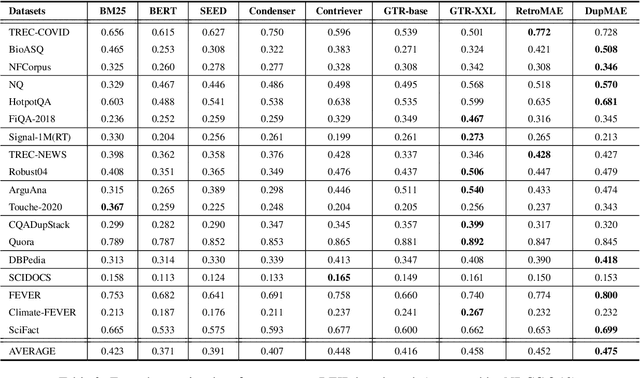
To better support information retrieval tasks such as web search and open-domain question answering, growing effort is made to develop retrieval-oriented language models, e.g., RetroMAE and many others. Most of the existing works focus on improving the semantic representation capability for the contextualized embedding of the [CLS] token. However, recent study shows that the ordinary tokens besides [CLS] may provide extra information, which help to produce a better representation effect. As such, it's necessary to extend the current methods where all contextualized embeddings can be jointly pre-trained for the retrieval tasks. In this work, we propose a novel pre-training method called Duplex Masked Auto-Encoder, a.k.a. DupMAE. It is designed to improve the quality of semantic representation where all contextualized embeddings of the pre-trained model can be leveraged. It takes advantage of two complementary auto-encoding tasks: one reconstructs the input sentence on top of the [CLS] embedding; the other one predicts the bag-of-words feature of the input sentence based on the ordinary tokens' embeddings. The two tasks are jointly conducted to train a unified encoder, where the whole contextualized embeddings are aggregated in a compact way to produce the final semantic representation. DupMAE is simple but empirically competitive: it substantially improves the pre-trained model's representation capability and transferability, where superior retrieval performances can be achieved on popular benchmarks, like MS MARCO and BEIR.
Investigating Glyph Phonetic Information for Chinese Spell Checking: What Works and What's Next
Dec 18, 2022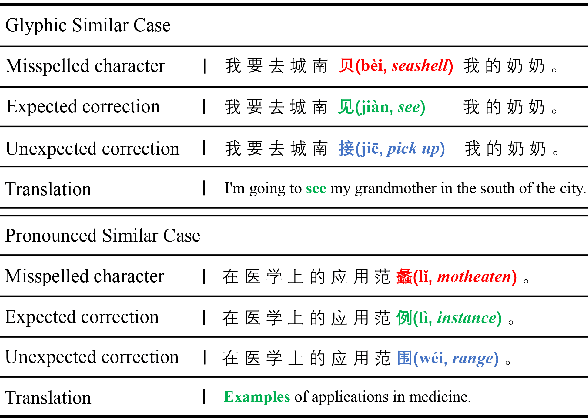
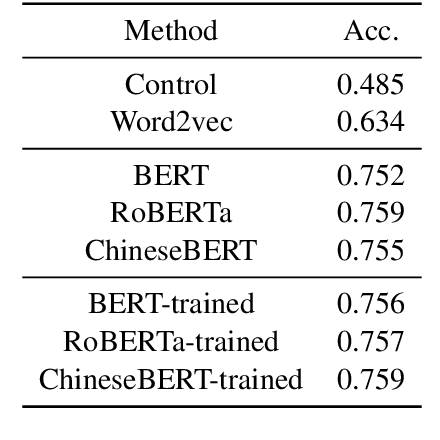
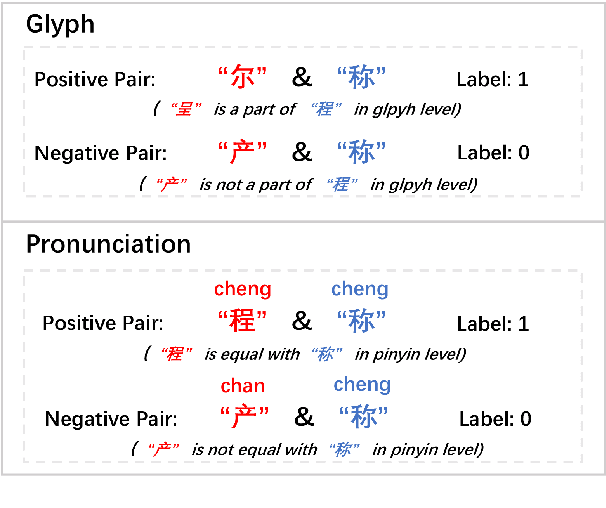
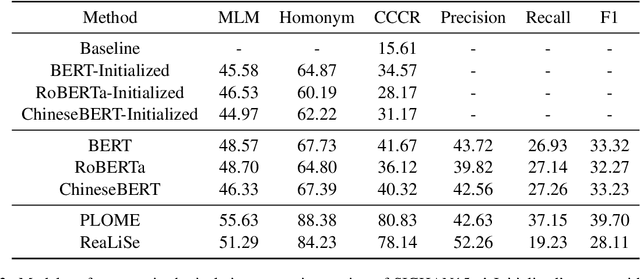
While pre-trained Chinese language models have demonstrated impressive performance on a wide range of NLP tasks, the Chinese Spell Checking (CSC) task remains a challenge. Previous research has explored using information such as glyphs and phonetics to improve the ability to distinguish misspelled characters, with good results. However, the generalization ability of these models is not well understood: it is unclear whether they incorporate glyph-phonetic information and, if so, whether this information is fully utilized. In this paper, we aim to better understand the role of glyph-phonetic information in the CSC task and suggest directions for improvement. Additionally, we propose a new, more challenging, and practical setting for testing the generalizability of CSC models. All code is made publicly available.
Much Ado About Gender: Current Practices and Future Recommendations for Appropriate Gender-Aware Information Access
Jan 13, 2023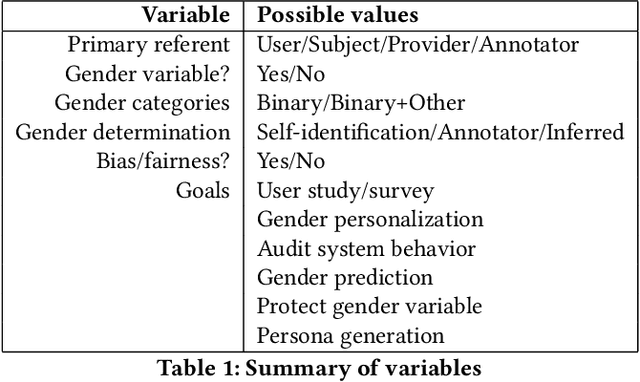
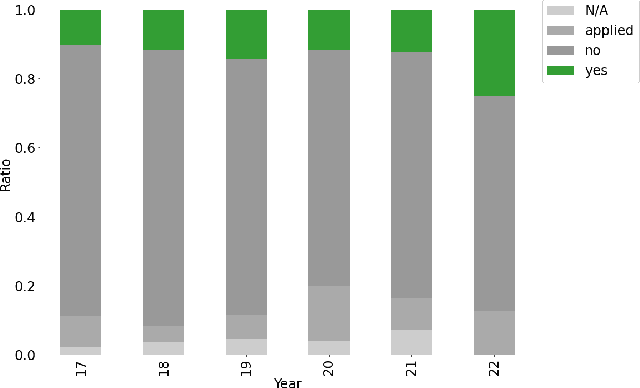
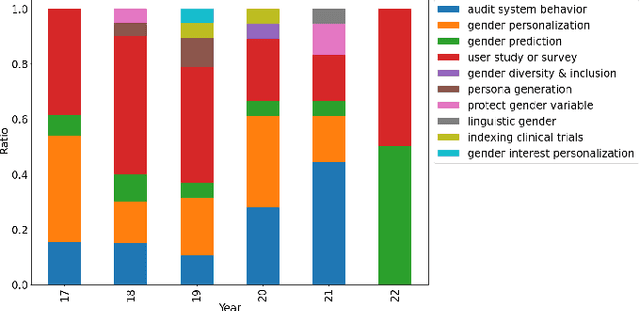
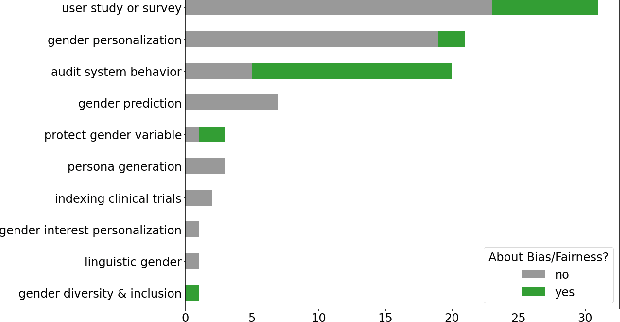
Information access research (and development) sometimes makes use of gender, whether to report on the demographics of participants in a user study, as inputs to personalized results or recommendations, or to make systems gender-fair, amongst other purposes. This work makes a variety of assumptions about gender, however, that are not necessarily aligned with current understandings of what gender is, how it should be encoded, and how a gender variable should be ethically used. In this work, we present a systematic review of papers on information retrieval and recommender systems that mention gender in order to document how gender is currently being used in this field. We find that most papers mentioning gender do not use an explicit gender variable, but most of those that do either focus on contextualizing results of model performance, personalizing a system based on assumptions of user gender, or auditing a model's behavior for fairness or other privacy-related issues. Moreover, most of the papers we review rely on a binary notion of gender, even if they acknowledge that gender cannot be split into two categories. We connect these findings with scholarship on gender theory and recent work on gender in human-computer interaction and natural language processing. We conclude by making recommendations for ethical and well-grounded use of gender in building and researching information access systems.
On the Hidden Mystery of OCR in Large Multimodal Models
May 13, 2023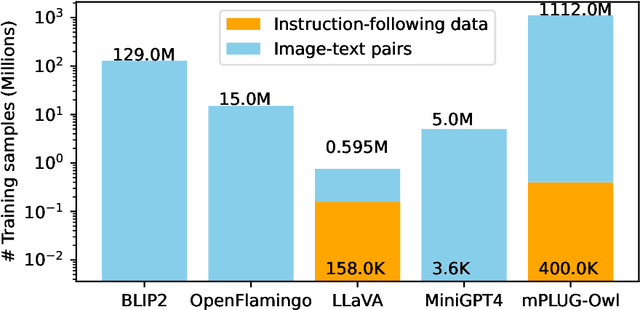
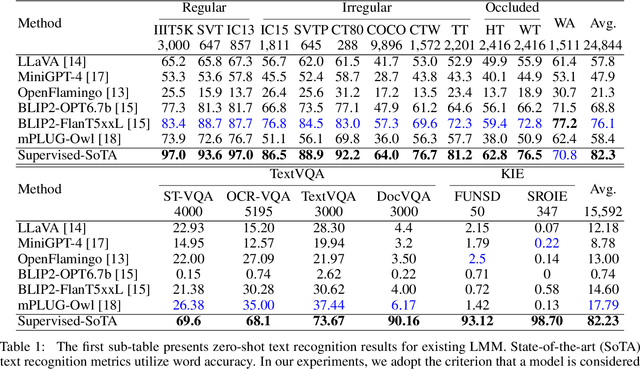
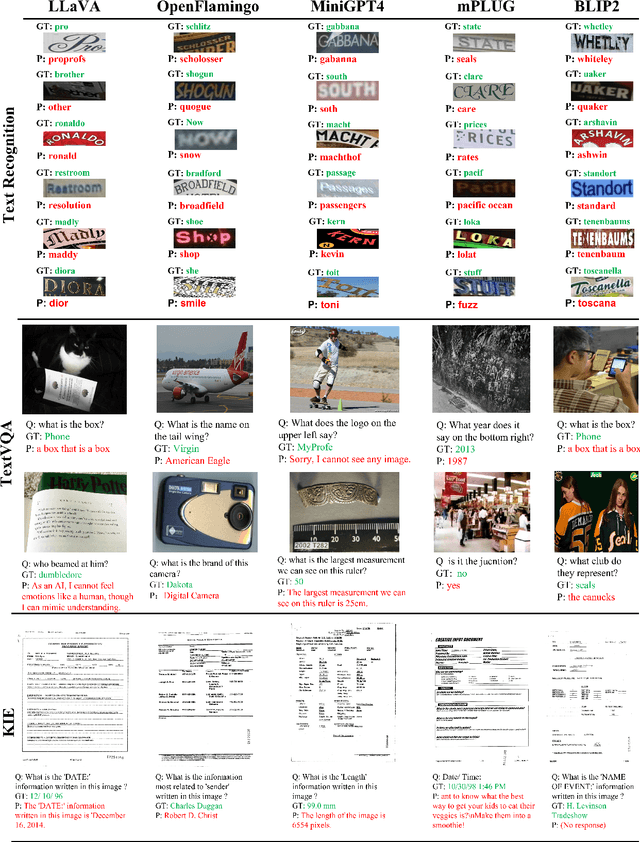
Large models have recently played a dominant role in natural language processing and multimodal vision-language learning. It remains less explored about their efficacy in text-related visual tasks. We conducted a comprehensive study of existing publicly available multimodal models, evaluating their performance in text recognition, text-based visual question answering, and key information extraction. Our findings reveal strengths and weaknesses in these models, which primarily rely on semantic understanding for word recognition and exhibit inferior perception of individual character shapes. They also display indifference towards text length and have limited capabilities in detecting fine-grained features in images. Consequently, these results demonstrate that even the current most powerful large multimodal models cannot match domain-specific methods in traditional text tasks and face greater challenges in more complex tasks. Most importantly, the baseline results showcased in this study could provide a foundational framework for the conception and assessment of innovative strategies targeted at enhancing zero-shot multimodal techniques. Evaluation pipeline will be available at https://github.com/Yuliang-Liu/MultimodalOCR.
QVoice: Arabic Speech Pronunciation Learning Application
May 09, 2023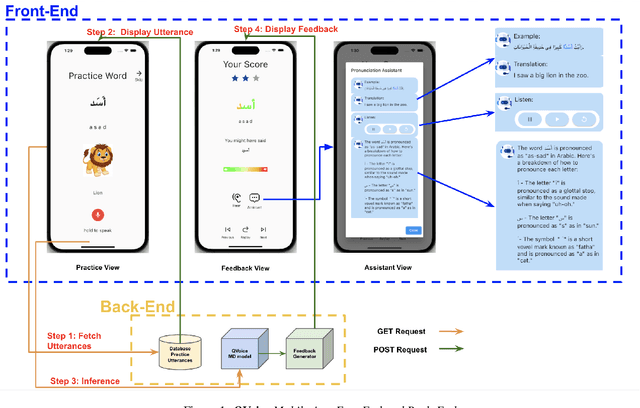
This paper introduces a novel Arabic pronunciation learning application QVoice, powered with end-to-end mispronunciation detection and feedback generator module. The application is designed to support non-native Arabic speakers in enhancing their pronunciation skills, while also helping native speakers mitigate any potential influence from regional dialects on their Modern Standard Arabic (MSA) pronunciation. QVoice employs various learning cues to aid learners in comprehending meaning, drawing connections with their existing knowledge of English language, and offers detailed feedback for pronunciation correction, along with contextual examples showcasing word usage. The learning cues featured in QVoice encompass a wide range of meaningful information, such as visualizations of phrases/words and their translations, as well as phonetic transcriptions and transliterations. QVoice provides pronunciation feedback at the character level and assesses performance at the word level.
* 2 pages, Accepted InterSpeech23 Show & Tell Demo Session
Measuring Rule-based LTLf Process Specifications: A Probabilistic Data-driven Approach
May 09, 2023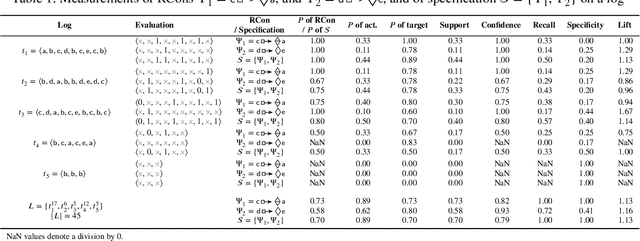
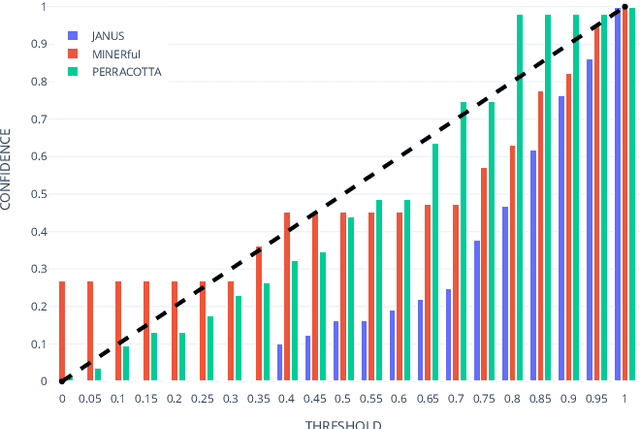

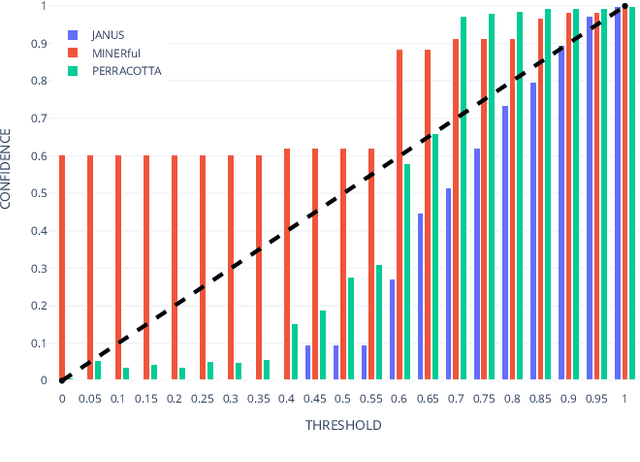
Declarative process specifications define the behavior of processes by means of rules based on Linear Temporal Logic on Finite Traces (LTLf). In a mining context, these specifications are inferred from, and checked on, multi-sets of runs recorded by information systems (namely, event logs). To this end, being able to gauge the degree to which process data comply with a specification is key. However, existing mining and verification techniques analyze the rules in isolation, thereby disregarding their interplay. In this paper, we introduce a framework to devise probabilistic measures for declarative process specifications. Thereupon, we propose a technique that measures the degree of satisfaction of specifications over event logs. To assess our approach, we conduct an evaluation with real-world data, evidencing its applicability in discovery, checking, and drift detection contexts.
Using Spatio-Temporal Dual-Stream Network with Self-Supervised Learning for Lung Tumor Classification on Radial Probe Endobronchial Ultrasound Video
May 07, 2023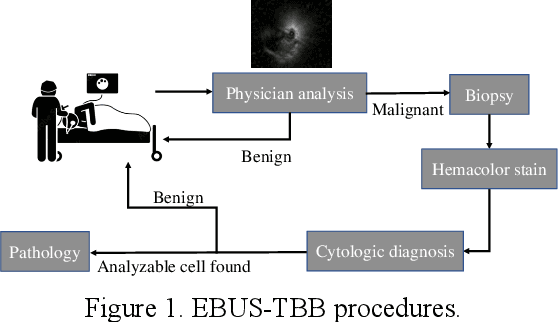
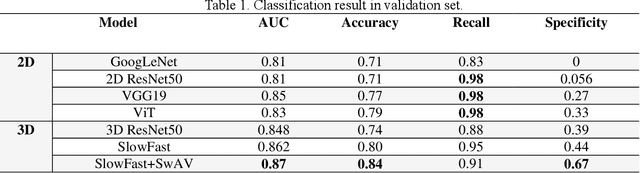
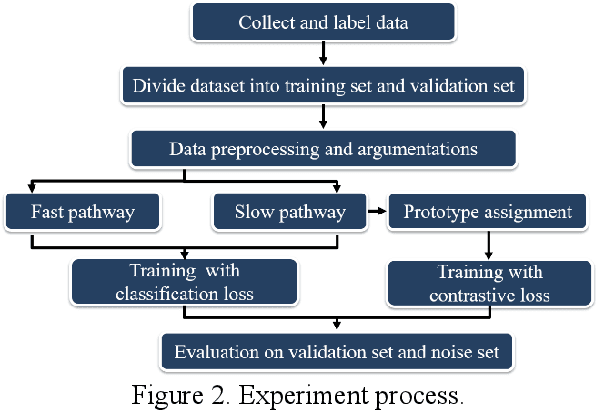
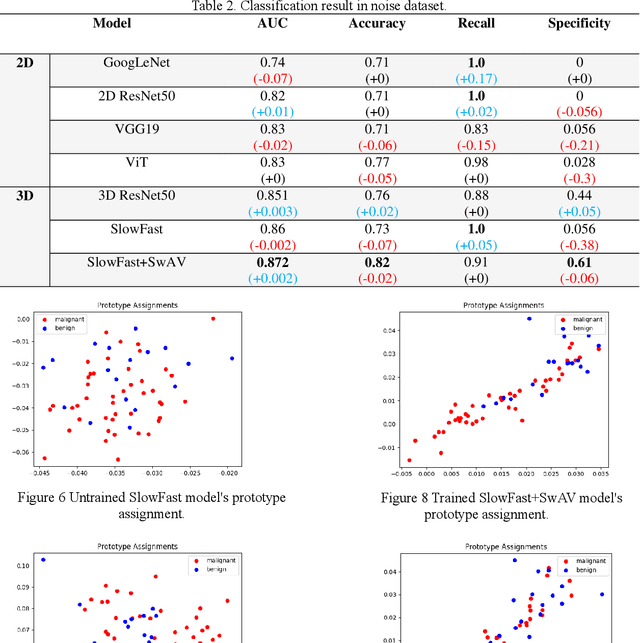
The purpose of this study is to develop a computer-aided diagnosis system for classifying benign and malignant lung lesions, and to assist physicians in real-time analysis of radial probe endobronchial ultrasound (EBUS) videos. During the biopsy process of lung cancer, physicians use real-time ultrasound images to find suitable lesion locations for sampling. However, most of these images are difficult to classify and contain a lot of noise. Previous studies have employed 2D convolutional neural networks to effectively differentiate between benign and malignant lung lesions, but doctors still need to manually select good-quality images, which can result in additional labor costs. In addition, the 2D neural network has no ability to capture the temporal information of the ultrasound video, so it is difficult to obtain the relationship between the features of the continuous images. This study designs an automatic diagnosis system based on a 3D neural network, uses the SlowFast architecture as the backbone to fuse temporal and spatial features, and uses the SwAV method of contrastive learning to enhance the noise robustness of the model. The method we propose includes the following advantages, such as (1) using clinical ultrasound films as model input, thereby reducing the need for high-quality image selection by physicians, (2) high-accuracy classification of benign and malignant lung lesions can assist doctors in clinical diagnosis and reduce the time and risk of surgery, and (3) the capability to classify well even in the presence of significant image noise. The AUC, accuracy, precision, recall and specificity of our proposed method on the validation set reached 0.87, 83.87%, 86.96%, 90.91% and 66.67%, respectively. The results have verified the importance of incorporating temporal information and the effectiveness of using the method of contrastive learning on feature extraction.
Phase-Retrieval with Incomplete Autocorrelations Using Deep Convolutional Autoencoders
Apr 18, 2023

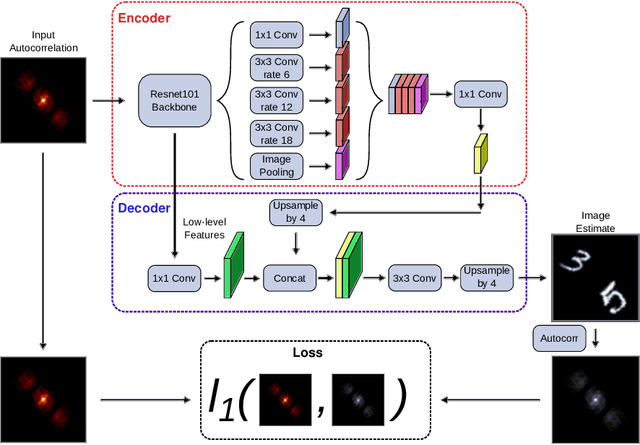
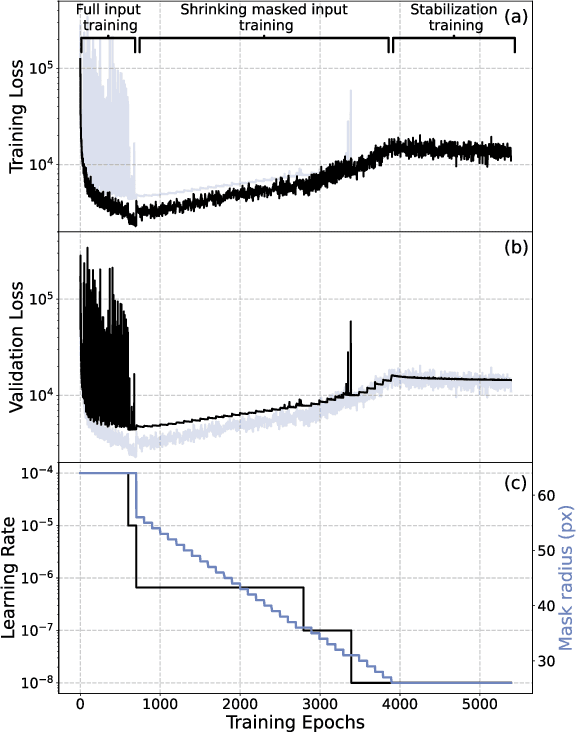
Phase-retrieval techniques aim to recover the original signal from just the modulus of its Fourier transform, which is usually much easier to measure than its phase, but the standard iterative techniques tend to fail if only part of the modulus information is available. We show that a neural network can be trained to perform phase retrieval using only incomplete information, and we discuss advantages and limitations of this approach.
Joint Analog Encoder Design for Multi-Task Oriented Wireless Communication
May 07, 2023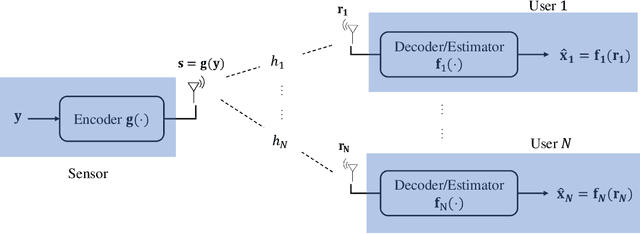
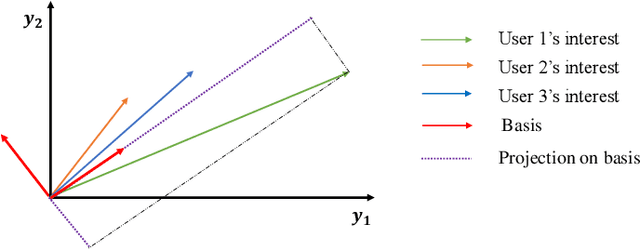
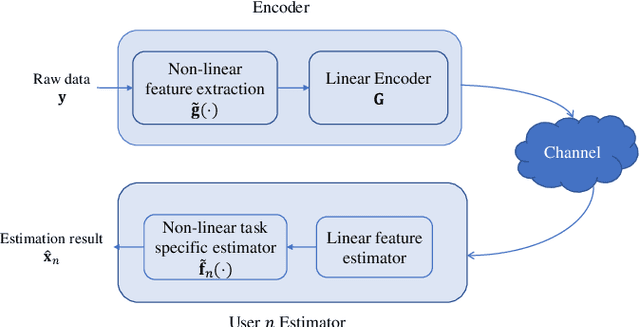
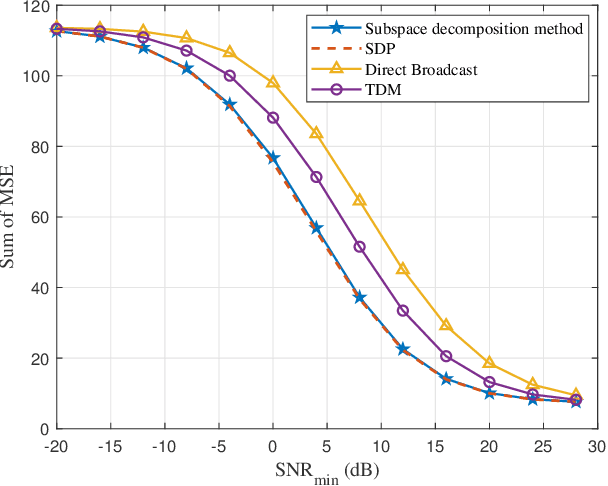
In this paper we study multi-task oriented communication system via studying analog encoding method for multiple estimation tasks. The basic idea is to utilize the correlation among interested information required by different tasks and the feature of broadcast channel. For linear estimation tasks, we provide a low complexity algorithm for multi-user multi-task system based on orthogonal decomposition of subspaces. It is proved to be the optimal solution in some special cases, and for general cases, numerical results also show significant improvements over baseline methods. Further, we make a trial to migrate above method to neural networks based non-linear estimation tasks, and it also shows improvement in energy efficiency.
HashCC: Lightweight Method to Improve the Quality of the Camera-less NeRF Scene Generation
May 07, 2023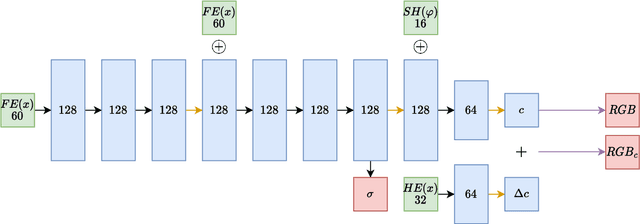
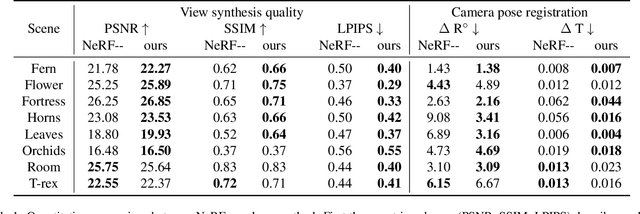
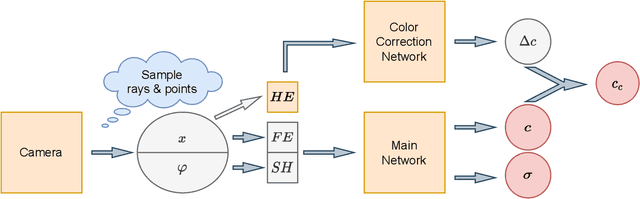
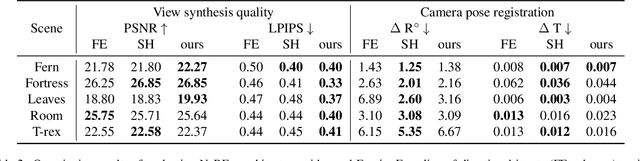
Neural Radiance Fields has become a prominent method of scene generation via view synthesis. A critical requirement for the original algorithm to learn meaningful scene representation is camera pose information for each image in a data set. Current approaches try to circumnavigate this assumption with moderate success, by learning approximate camera positions alongside learning neural representations of a scene. This requires complicated camera models, causing a long and complicated training process, or results in a lack of texture and sharp details in rendered scenes. In this work we introduce Hash Color Correction (HashCC) -- a lightweight method for improving Neural Radiance Fields rendered image quality, applicable also in situations where camera positions for a given set of images are unknown.