 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The EarlyBIRD Catches the Bug: On Exploiting Early Layers of Encoder Models for More Efficient Code Classification
May 08, 2023
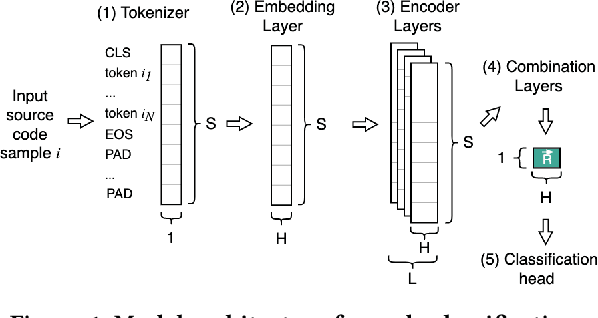
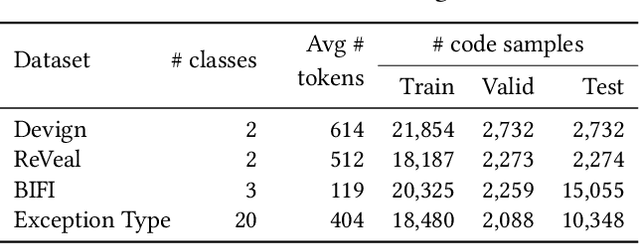
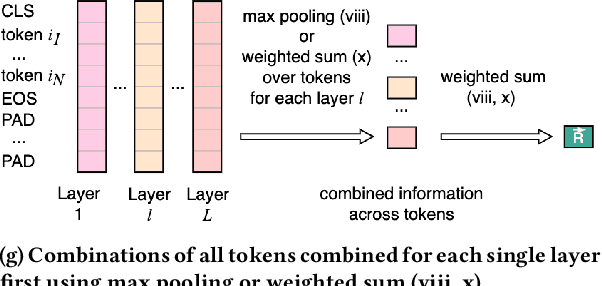
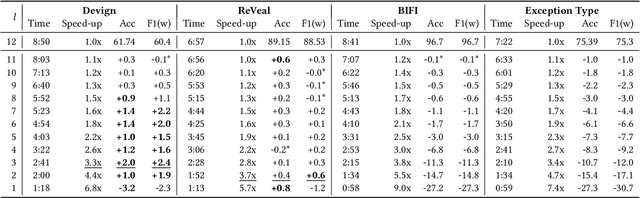
The use of modern Natural Language Processing (NLP) techniques has shown to be beneficial for software engineering tasks, such as vulnerability detection and type inference. However, training deep NLP models requires significant computational resources. This paper explores techniques that aim at achieving the best usage of resources and available information in these models. We propose a generic approach, EarlyBIRD, to build composite representations of code from the early layers of a pre-trained transformer model. We empirically investigate the viability of this approach on the CodeBERT model by comparing the performance of 12 strategies for creating composite representations with the standard practice of only using the last encoder layer. Our evaluation on four datasets shows that several early layer combinations yield better performance on defect detection, and some combinations improve multi-class classification. More specifically, we obtain a +2 average improvement of detection accuracy on Devign with only 3 out of 12 layers of CodeBERT and a 3.3x speed-up of fine-tuning. These findings show that early layers can be used to obtain better results using the same resources, as well as to reduce resource usage during fine-tuning and inference.
Rotational Slippage Prediction from Segmentation of Tactile Images
May 08, 2023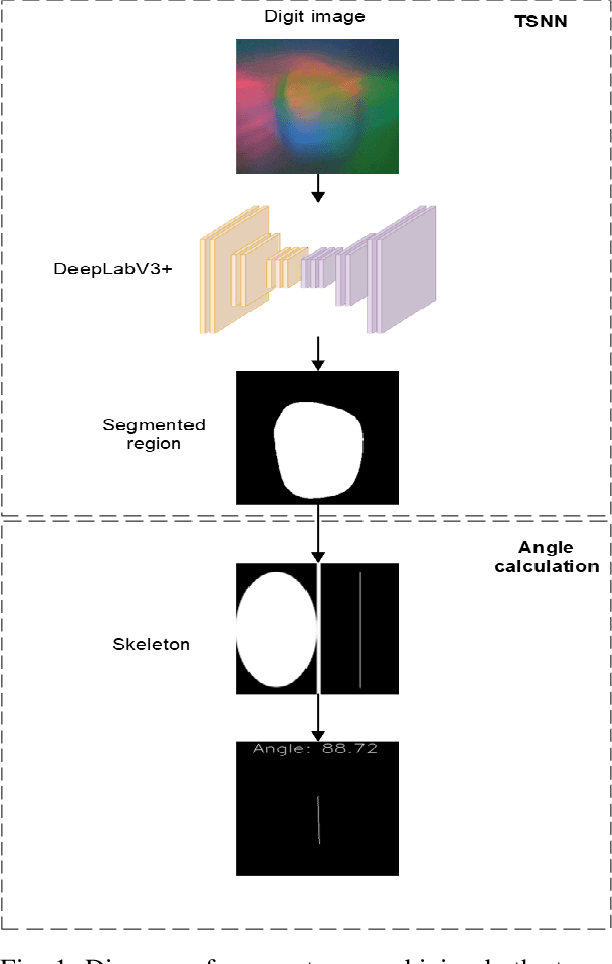

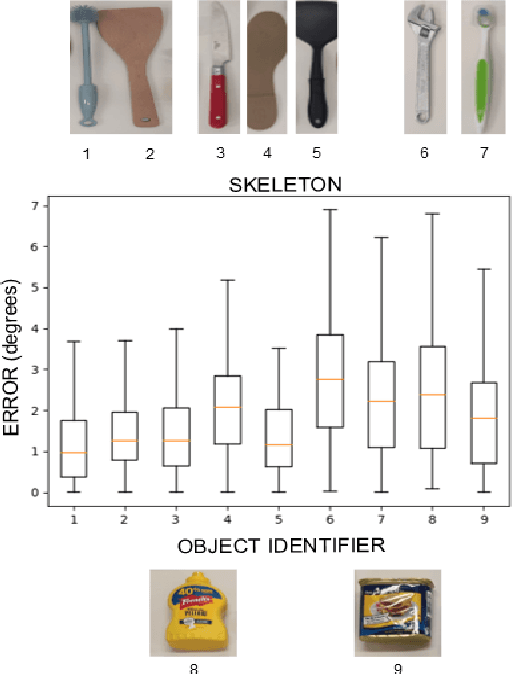
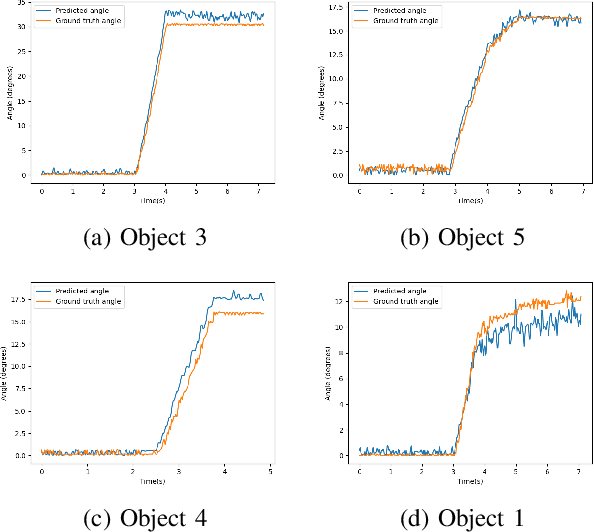
Adding tactile sensors to a robotic system is becoming a common practice to achieve more complex manipulation skills than those robotics systems that only use external cameras to manipulate objects. The key of tactile sensors is that they provide extra information about the physical properties of the grasping. In this paper, we implemented a system to predict and quantify the rotational slippage of objects in hand using the vision-based tactile sensor known as Digit. Our system comprises a neural network that obtains the segmented contact region (object-sensor), to later calculate the slippage rotation angle from this region using a thinning algorithm. Besides, we created our own tactile segmentation dataset, which is the first one in the literature as far as we are concerned, to train and evaluate our neural network, obtaining results of 95% and 91% in Dice and IoU metrics. In real-scenario experiments, our system is able to predict rotational slippage with a maximum mean rotational error of 3 degrees with previously unseen objects. Thus, our system can be used to prevent an object from falling due to its slippage.
The Emerging Artificial Intelligence Protocol for Hierarchical Information Network
Feb 22, 2023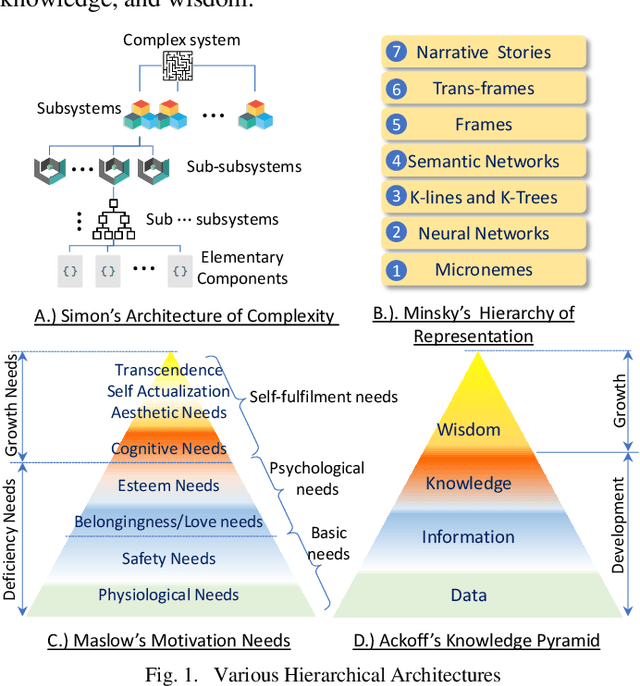
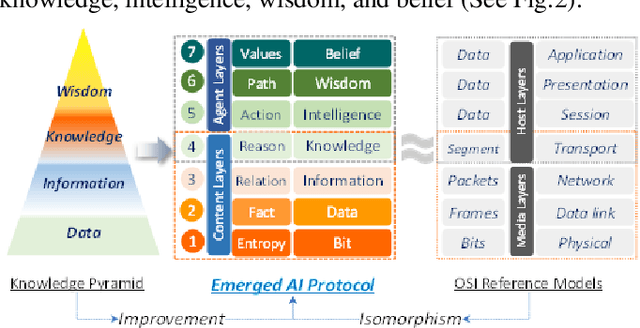


The recent development of artificial intelligence enables a machine to achieve a human level of intelligence. Problem-solving and decision-making are two mental abilities to measure human intelligence. Many scholars have proposed different models. However, there is a gap in establishing an AI-oriented hierarchical model with a multilevel abstraction. This study proposes a novel model known as the emerged AI protocol that consists of seven distinct layers capable of providing an optimal and explainable solution for a given problem.
* 6 pages, 4 figures, 1 table
Multi-View Graph Representation Learning for Answering Hybrid Numerical Reasoning Question
May 05, 2023
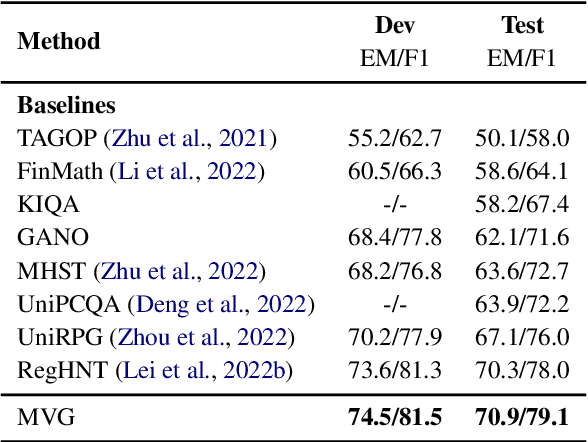
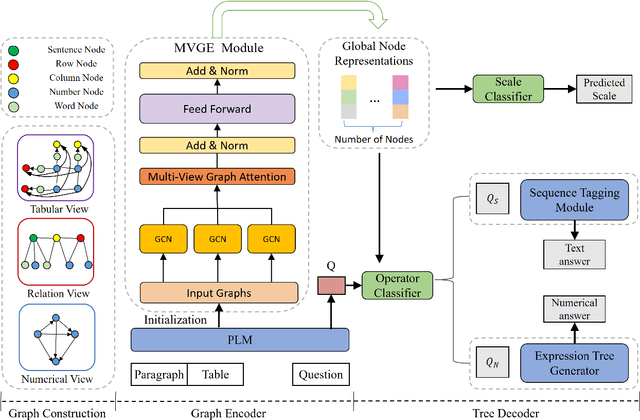
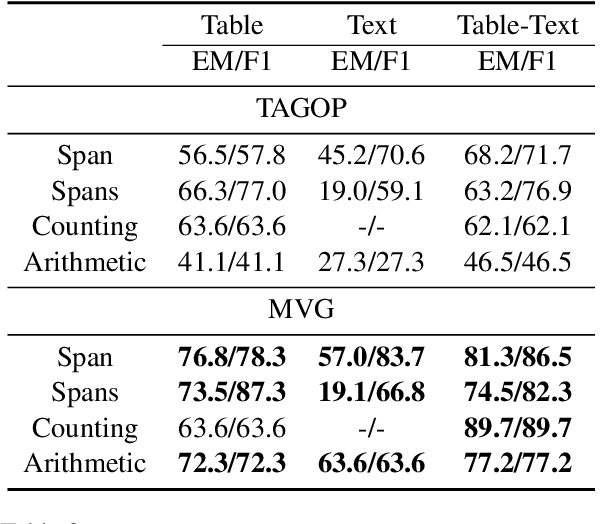
Hybrid question answering (HybridQA) over the financial report contains both textual and tabular data, and requires the model to select the appropriate evidence for the numerical reasoning task. Existing methods based on encoder-decoder framework employ a expression tree-based decoder to solve numerical reasoning problems. However, encoders rely more on Machine Reading Comprehension (MRC) methods, which take table serialization and text splicing as input, damaging the granularity relationship between table and text as well as the spatial structure information of table itself. In order to solve these problems, the paper proposes a Multi-View Graph (MVG) Encoder to take the relations among the granularity into account and capture the relations from multiple view. By utilizing MVGE as a module, we constuct Tabular View, Relation View and Numerical View which aim to retain the original characteristics of the hybrid data. We validate our model on the publicly available table-text hybrid QA benchmark (TAT-QA) and outperform the state-of-the-art model.
Is dataset condensation a silver bullet for healthcare data sharing?
May 05, 2023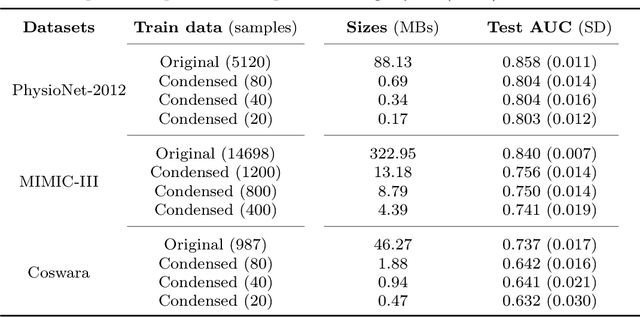
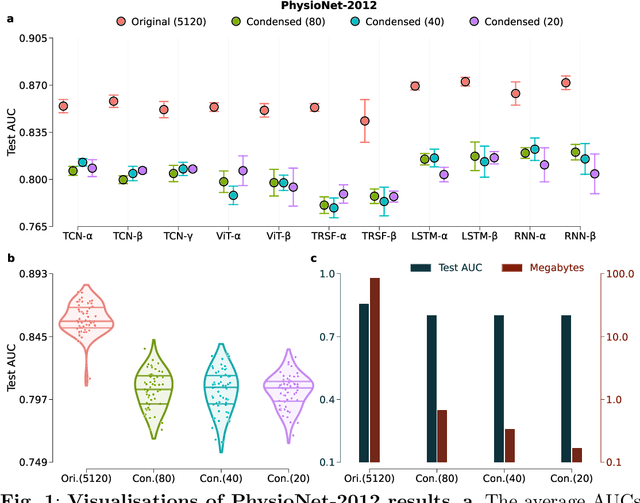
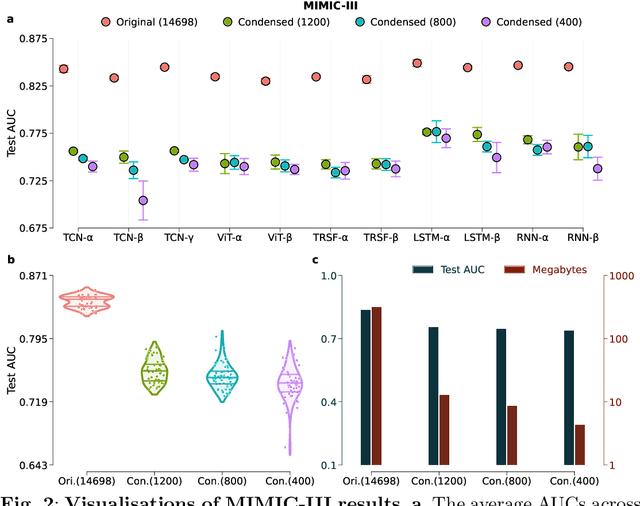
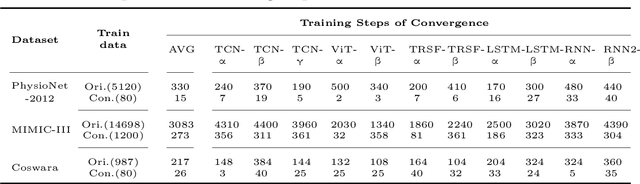
Safeguarding personal information is paramount for healthcare data sharing, a challenging issue without any silver bullet thus far. We study the prospect of a recent deep-learning advent, dataset condensation (DC), in sharing healthcare data for AI research, and the results are promising. The condensed data abstracts original records and irreversibly conceals individual-level knowledge to achieve a bona fide de-identification, which permits free sharing. Moreover, the original deep-learning utilities are well preserved in the condensed data with compressed volume and accelerated model convergences. In PhysioNet-2012, a condensed dataset of 20 samples can orient deep models attaining 80.3% test AUC of mortality prediction (versus 85.8% of 5120 original records), an inspiring discovery generalised to MIMIC-III and Coswara datasets. We also interpret the inhere privacy protections of DC through theoretical analysis and empirical evidence. Dataset condensation opens a new gate to sharing healthcare data for AI research with multiple desirable traits.
Blind identification of Ambisonic reduced room impulse response
May 05, 2023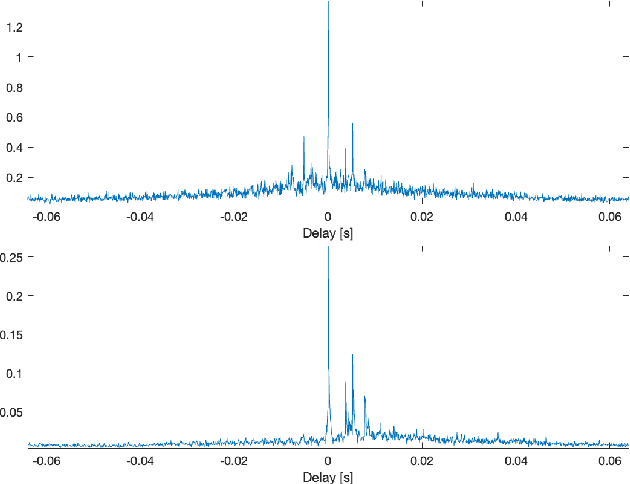
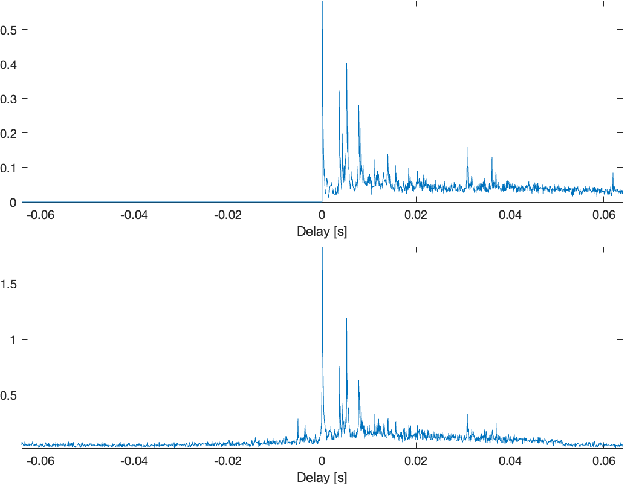
Recently proposed Generalized Time-domain Velocity Vector (GTVV) is a generalization of relative room impulse response in spherical harmonic (aka Ambisonic) domain that allows for blind estimation of early-echo parameters: the directions and relative delays of individual reflections. However, the derived closed-form expression of GTVV mandates few assumptions to hold, most important being that the impulse response of the reference signal needs to be a minimum-phase filter. In practice, the reference is obtained by spatial filtering towards the Direction-of-Arrival of the source, and the aforementioned condition is bounded by the performance of the applied beamformer (and thus, by the Ambisonic array order). In the present work, we suggest to circumvent this problem by properly modelling the GTVV time series, which permits not only to relax the initial assumptions, but also to extract the information therein is a more consistent and efficient manner, entering the realm of blind system identification. Experiments using measured room impulse responses confirm the effectiveness of the proposed approach.
Physics-Informed Localized Learning for Advection-Diffusion-Reaction Systems
May 05, 2023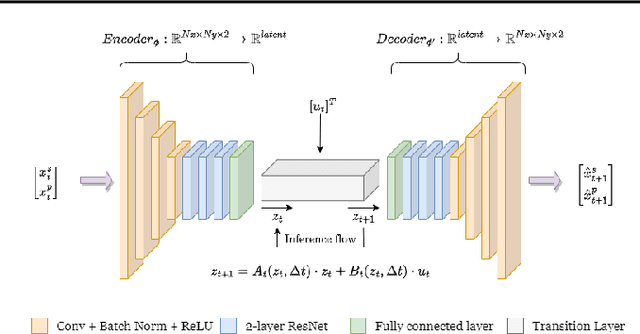
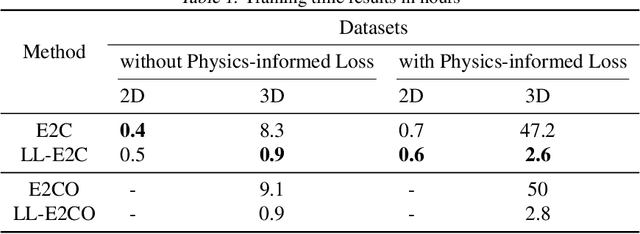

The global push for new energy solutions, such as Geothermal, and Carbon Capture and Sequestration initiatives has thrust new demands upon the current state-of the-art subsurface fluid simulators. The requirement to be able to simulate a large order of reservoir states simultaneously in a short period of time has opened the door of opportunity for the application of machine learning techniques for surrogate modelling. We propose a novel physics-informed and boundary conditions-aware Localized Learning method which extends the Embed-to-Control (E2C) and Embed-to-Control and Observed (E2CO) models to learn local representations of global state variables in an Advection-Diffusion Reaction system. We show that our model trained on reservoir simulation data is able to predict future states of the system, given a set of controls, to a great deal of accuracy with only a fraction of the available information, while also reducing training times significantly compared to the original E2C and E2CO models.
Deep Metric Multi-View Hashing for Multimedia Retrieval
Apr 13, 2023
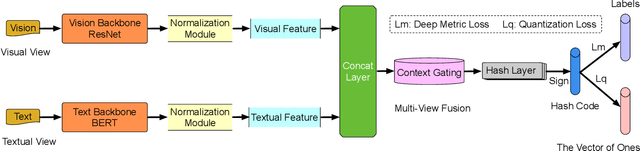
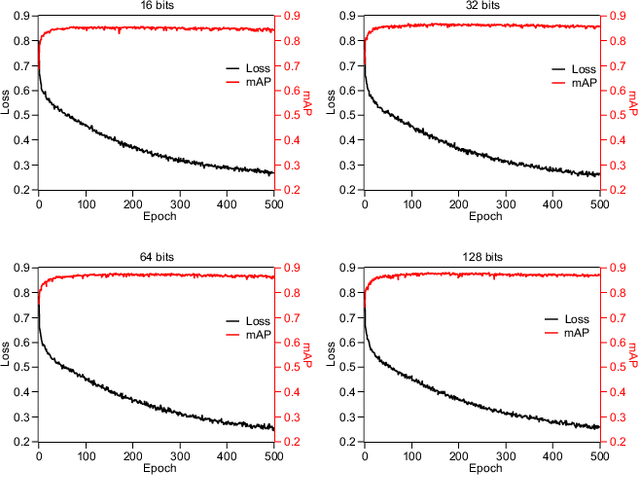
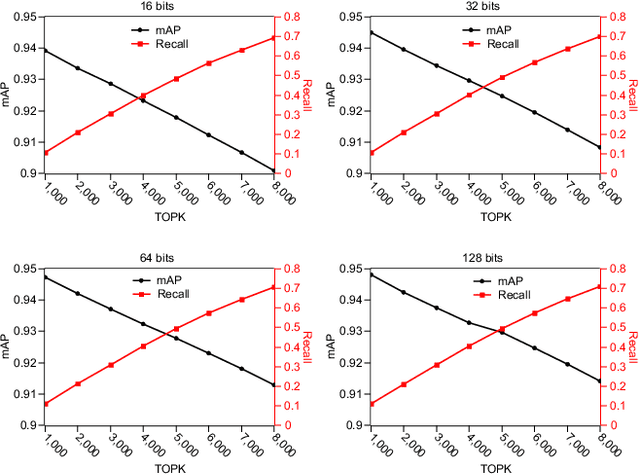
Learning the hash representation of multi-view heterogeneous data is an important task in multimedia retrieval. However, existing methods fail to effectively fuse the multi-view features and utilize the metric information provided by the dissimilar samples, leading to limited retrieval precision. Current methods utilize weighted sum or concatenation to fuse the multi-view features. We argue that these fusion methods cannot capture the interaction among different views. Furthermore, these methods ignored the information provided by the dissimilar samples. We propose a novel deep metric multi-view hashing (DMMVH) method to address the mentioned problems. Extensive empirical evidence is presented to show that gate-based fusion is better than typical methods. We introduce deep metric learning to the multi-view hashing problems, which can utilize metric information of dissimilar samples. On the MIR-Flickr25K, MS COCO, and NUS-WIDE, our method outperforms the current state-of-the-art methods by a large margin (up to 15.28 mean Average Precision (mAP) improvement).
Speaker Profiling in Multiparty Conversations
Apr 19, 2023
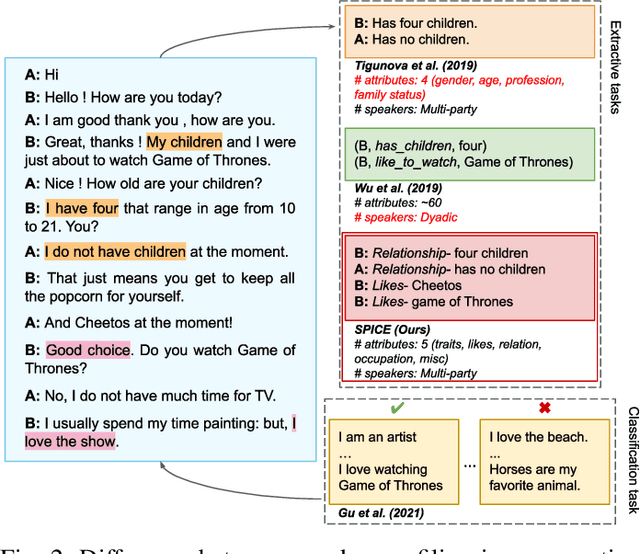


In conversational settings, individuals exhibit unique behaviors, rendering a one-size-fits-all approach insufficient for generating responses by dialogue agents. Although past studies have aimed to create personalized dialogue agents using speaker persona information, they have relied on the assumption that the speaker's persona is already provided. However, this assumption is not always valid, especially when it comes to chatbots utilized in industries like banking, hotel reservations, and airline bookings. This research paper aims to fill this gap by exploring the task of Speaker Profiling in Conversations (SPC). The primary objective of SPC is to produce a summary of persona characteristics for each individual speaker present in a dialogue. To accomplish this, we have divided the task into three subtasks: persona discovery, persona-type identification, and persona-value extraction. Given a dialogue, the first subtask aims to identify all utterances that contain persona information. Subsequently, the second task evaluates these utterances to identify the type of persona information they contain, while the third subtask identifies the specific persona values for each identified type. To address the task of SPC, we have curated a new dataset named SPICE, which comes with specific labels. We have evaluated various baselines on this dataset and benchmarked it with a new neural model, SPOT, which we introduce in this paper. Furthermore, we present a comprehensive analysis of SPOT, examining the limitations of individual modules both quantitatively and qualitatively.
Hyperspectral Image Super-Resolution via Dual-domain Network Based on Hybrid Convolution
Apr 20, 2023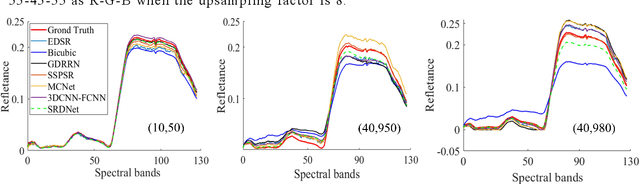
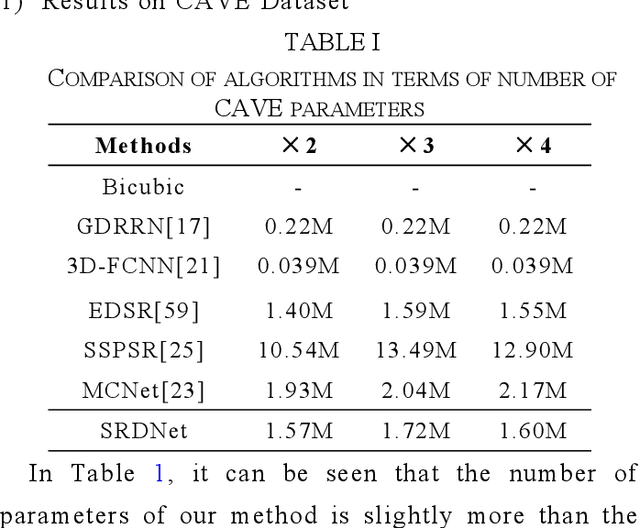
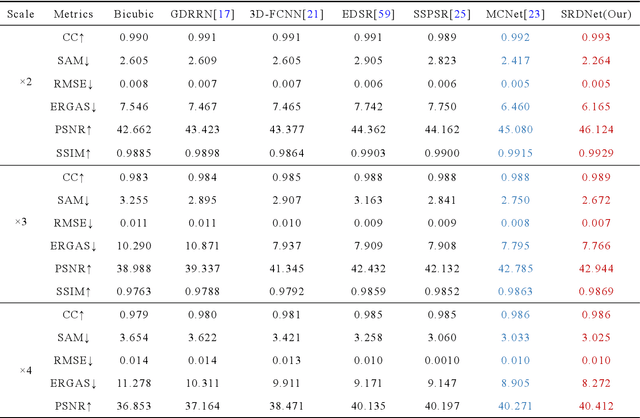
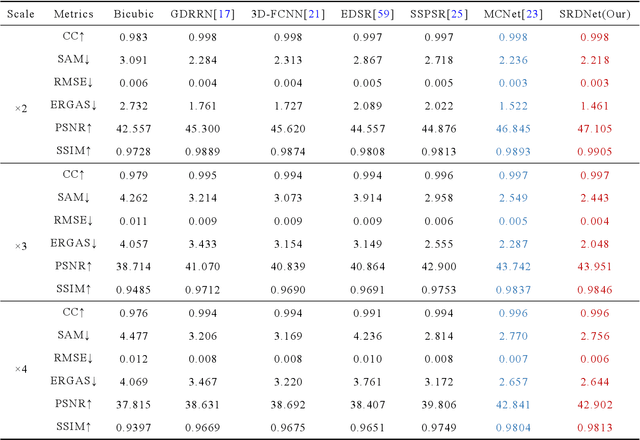
Since the number of incident energies is limited, it is difficult to directly acquire hyperspectral images (HSI) with high spatial resolution. Considering the high dimensionality and correlation of HSI, super-resolution (SR) of HSI remains a challenge in the absence of auxiliary high-resolution images. Furthermore, it is very important to extract the spatial features effectively and make full use of the spectral information. This paper proposes a novel HSI super-resolution algorithm, termed dual-domain network based on hybrid convolution (SRDNet). Specifically, a dual-domain network is designed to fully exploit the spatial-spectral and frequency information among the hyper-spectral data. To capture inter-spectral self-similarity, a self-attention learning mechanism (HSL) is devised in the spatial domain. Meanwhile the pyramid structure is applied to increase the acceptance field of attention, which further reinforces the feature representation ability of the network. Moreover, to further improve the perceptual quality of HSI, a frequency loss(HFL) is introduced to optimize the model in the frequency domain. The dynamic weighting mechanism drives the network to gradually refine the generated frequency and excessive smoothing caused by spatial loss. Finally, In order to better fully obtain the mapping relationship between high-resolution space and low-resolution space, a hybrid module of 2D and 3D units with progressive upsampling strategy is utilized in our method. Experiments on a widely used benchmark dataset illustrate that the proposed SRDNet method enhances the texture information of HSI and is superior to state-of-the-art methods.