 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CatFLW: Cat Facial Landmarks in the Wild Dataset
May 07, 2023
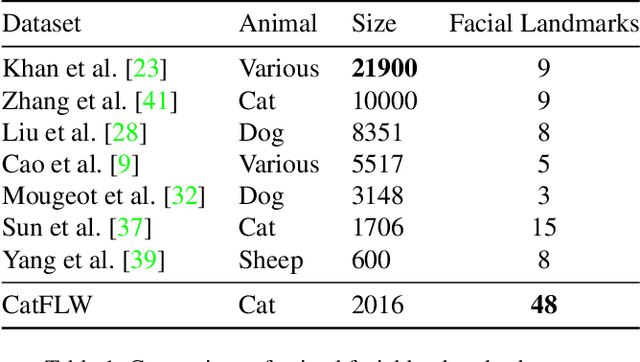


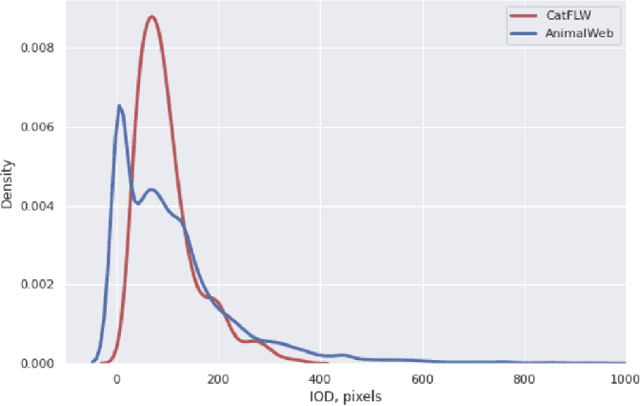
Animal affective computing is a quickly growing field of research, where only recently first efforts to go beyond animal tracking into recognizing their internal states, such as pain and emotions, have emerged. In most mammals, facial expressions are an important channel for communicating information about these states. However, unlike the human domain, there is an acute lack of datasets that make automation of facial analysis of animals feasible. This paper aims to fill this gap by presenting a dataset called Cat Facial Landmarks in the Wild (CatFLW) which contains 2016 images of cat faces in different environments and conditions, annotated with 48 facial landmarks specifically chosen for their relationship with underlying musculature, and relevance to cat-specific facial Action Units (CatFACS). To the best of our knowledge, this dataset has the largest amount of cat facial landmarks available. In addition, we describe a semi-supervised (human-in-the-loop) method of annotating images with landmarks, used for creating this dataset, which significantly reduces the annotation time and could be used for creating similar datasets for other animals. The dataset is available on request.
MrTF: Model Refinery for Transductive Federated Learning
May 07, 2023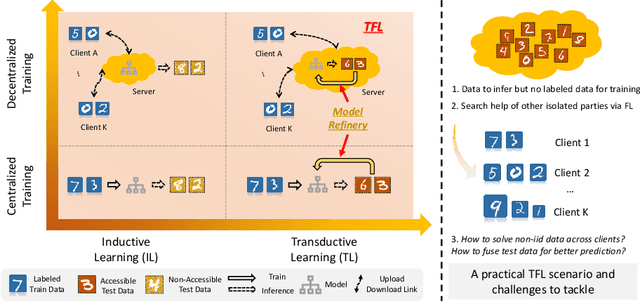
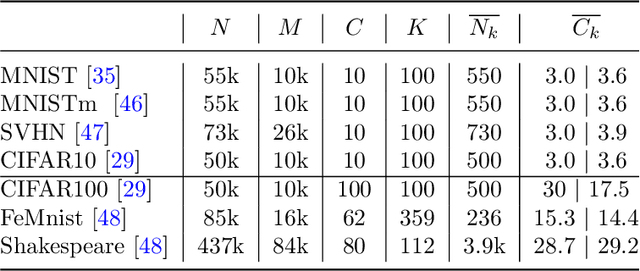
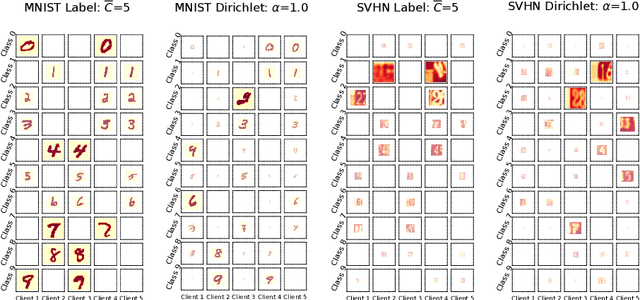
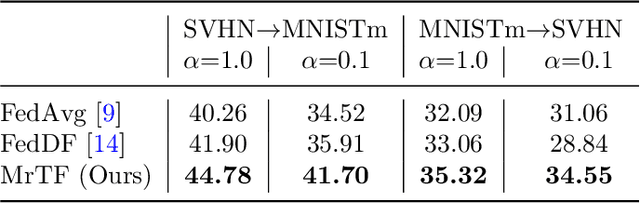
We consider a real-world scenario in which a newly-established pilot project needs to make inferences for newly-collected data with the help of other parties under privacy protection policies. Current federated learning (FL) paradigms are devoted to solving the data heterogeneity problem without considering the to-be-inferred data. We propose a novel learning paradigm named transductive federated learning (TFL) to simultaneously consider the structural information of the to-be-inferred data. On the one hand, the server could use the pre-available test samples to refine the aggregated models for robust model fusion, which tackles the data heterogeneity problem in FL. On the other hand, the refinery process incorporates test samples into training and could generate better predictions in a transductive manner. We propose several techniques including stabilized teachers, rectified distillation, and clustered label refinery to facilitate the model refinery process. Abundant experimental studies verify the superiorities of the proposed \underline{M}odel \underline{r}efinery framework for \underline{T}ransductive \underline{F}ederated learning (MrTF). The source code is available at \url{https://github.com/lxcnju/MrTF}.
Simulation of Dynamic Environments for SLAM
May 07, 2023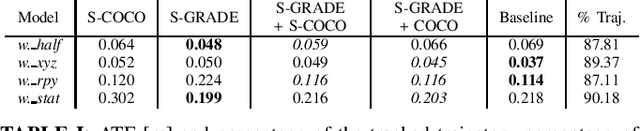
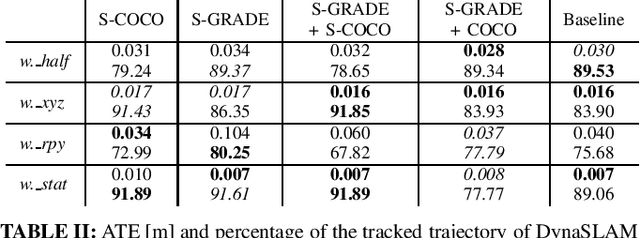
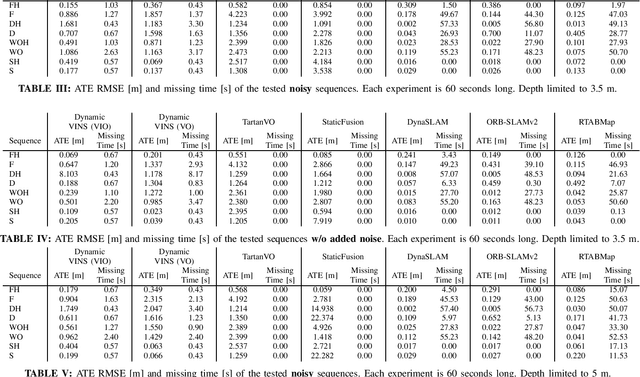

Simulation engines are widely adopted in robotics. However, they lack either full simulation control, ROS integration, realistic physics, or photorealism. Recently, synthetic data generation and realistic rendering has advanced tasks like target tracking and human pose estimation. However, when focusing on vision applications, there is usually a lack of information like sensor measurements or time continuity. On the other hand, simulations for most robotics tasks are performed in (semi)static environments, with specific sensors and low visual fidelity. To solve this, we introduced in our previous work a fully customizable framework for generating realistic animated dynamic environments (GRADE) [1]. We use GRADE to generate an indoor dynamic environment dataset and then compare multiple SLAM algorithms on different sequences. By doing that, we show how current research over-relies on known benchmarks, failing to generalize. Our tests with refined YOLO and Mask R-CNN models provide further evidence that additional research in dynamic SLAM is necessary. The code, results, and generated data are provided as open-source at https://eliabntt.github.io/grade-rrSimulation of Dynamic Environments for SLAM
The Training Process of Many Deep Networks Explores the Same Low-Dimensional Manifold
May 02, 2023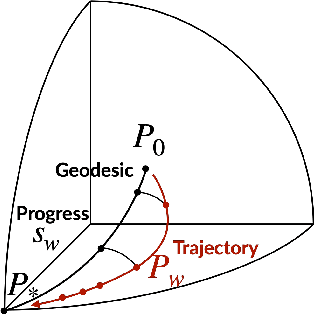
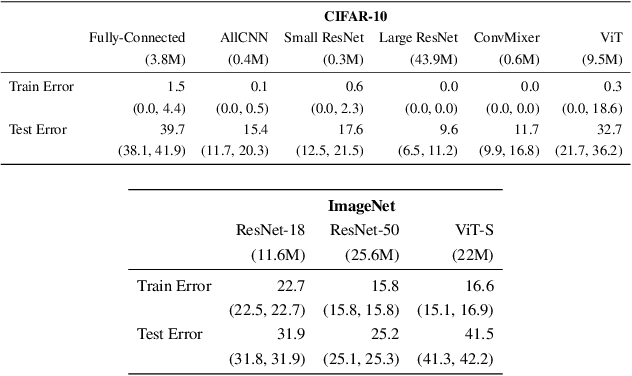
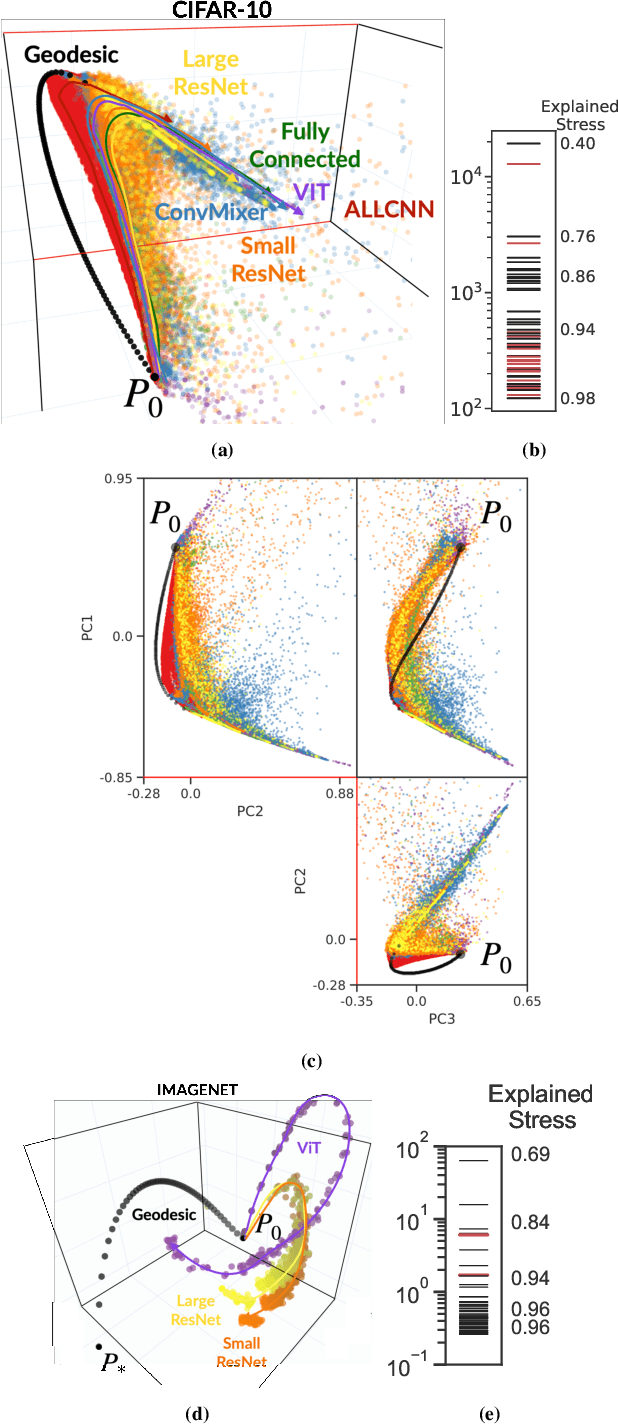
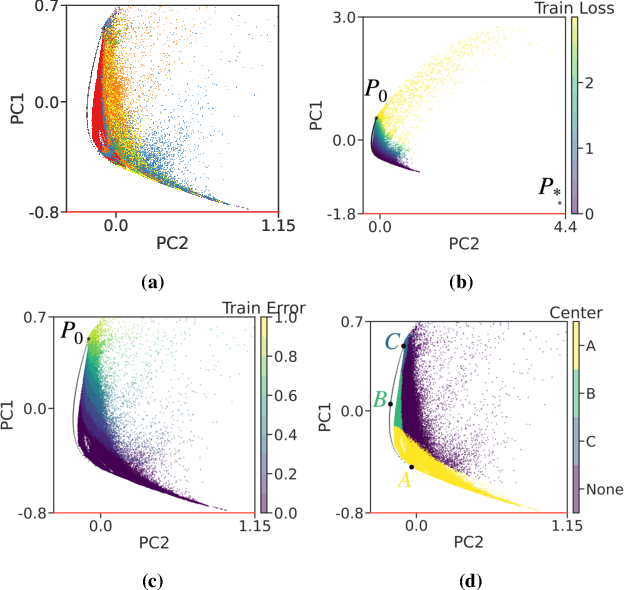
We develop information-geometric techniques to analyze the trajectories of the predictions of deep networks during training. By examining the underlying high-dimensional probabilistic models, we reveal that the training process explores an effectively low-dimensional manifold. Networks with a wide range of architectures, sizes, trained using different optimization methods, regularization techniques, data augmentation techniques, and weight initializations lie on the same manifold in the prediction space. We study the details of this manifold to find that networks with different architectures follow distinguishable trajectories but other factors have a minimal influence; larger networks train along a similar manifold as that of smaller networks, just faster; and networks initialized at very different parts of the prediction space converge to the solution along a similar manifold.
Sparse Dense Fusion for 3D Object Detection
Apr 09, 2023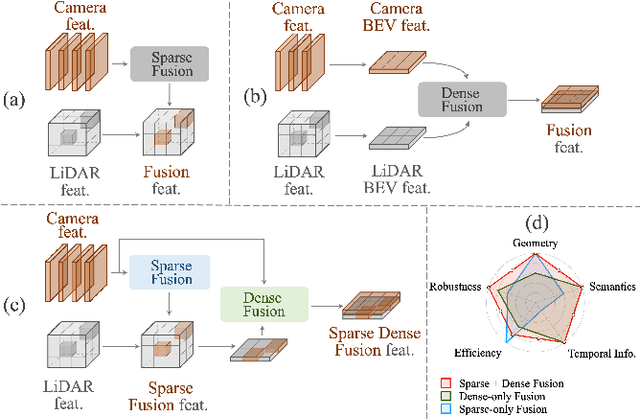
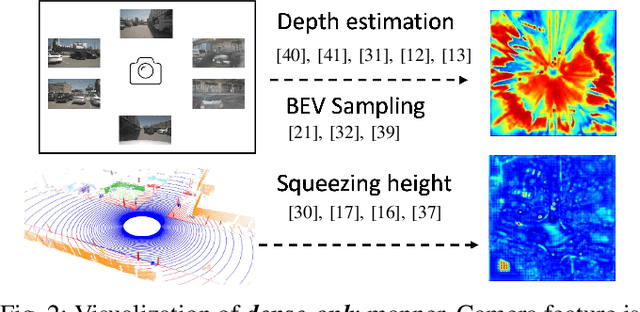

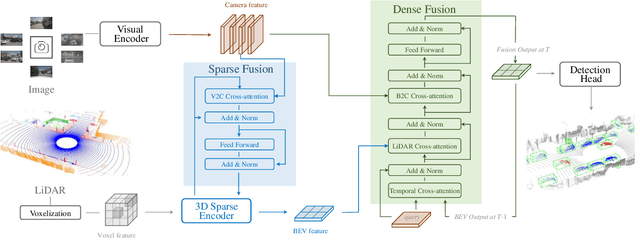
With the prevalence of multimodal learning, camera-LiDAR fusion has gained popularity in 3D object detection. Although multiple fusion approaches have been proposed, they can be classified into either sparse-only or dense-only fashion based on the feature representation in the fusion module. In this paper, we analyze them in a common taxonomy and thereafter observe two challenges: 1) sparse-only solutions preserve 3D geometric prior and yet lose rich semantic information from the camera, and 2) dense-only alternatives retain the semantic continuity but miss the accurate geometric information from LiDAR. By analyzing these two formulations, we conclude that the information loss is inevitable due to their design scheme. To compensate for the information loss in either manner, we propose Sparse Dense Fusion (SDF), a complementary framework that incorporates both sparse-fusion and dense-fusion modules via the Transformer architecture. Such a simple yet effective sparse-dense fusion structure enriches semantic texture and exploits spatial structure information simultaneously. Through our SDF strategy, we assemble two popular methods with moderate performance and outperform baseline by 4.3% in mAP and 2.5% in NDS, ranking first on the nuScenes benchmark. Extensive ablations demonstrate the effectiveness of our method and empirically align our analysis.
Injecting Spatial Information for Monaural Speech Enhancement via Knowledge Distillation
Dec 02, 2022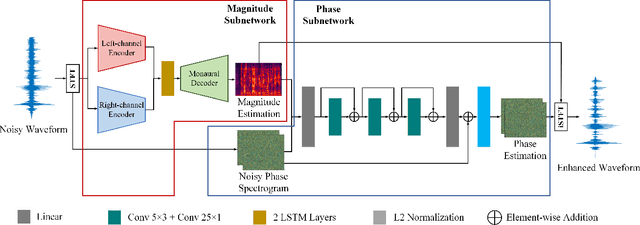
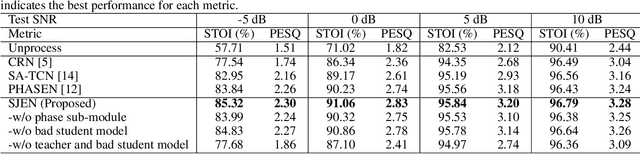
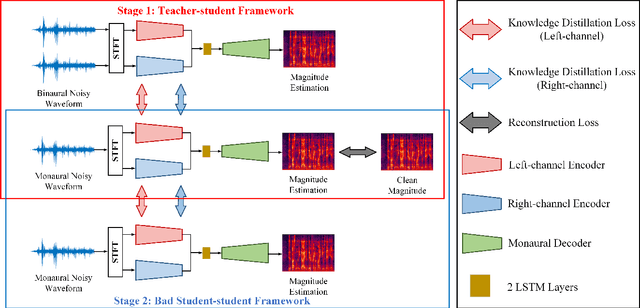
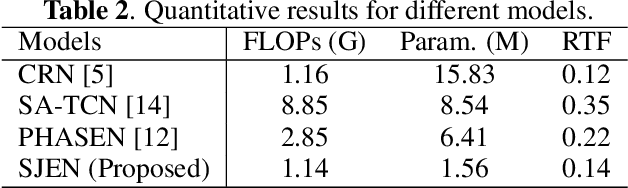
Monaural speech enhancement (SE) provides a versatile and cost-effective approach to SE tasks by utilizing recordings from a single microphone. However, the monaural SE lags performance behind multi-channel SE as the monaural SE methods are unable to extract spatial information from one-channel recordings, which greatly limits their application scenarios. To address this issue, we inject spatial information into the monaural SE model and propose a knowledge distillation strategy to enable the monaural SE model to learn binaural speech features from the binaural SE model, which makes monaural SE model possible to reconstruct higher intelligibility and quality enhanced speeches under low signal-to-noise ratio (SNR) conditions. Extensive experiments show that our proposed monaural SE model by injecting spatial information via knowledge distillation achieves favorable performance against other monaural SE models with fewer parameters.
InPars-v2: Large Language Models as Efficient Dataset Generators for Information Retrieval
Jan 14, 2023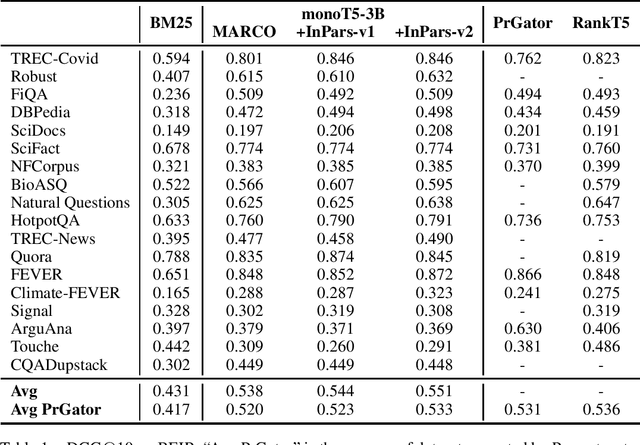
Recently, InPars introduced a method to efficiently use large language models (LLMs) in information retrieval tasks: via few-shot examples, an LLM is induced to generate relevant queries for documents. These synthetic query-document pairs can then be used to train a retriever. However, InPars and, more recently, Promptagator, rely on proprietary LLMs such as GPT-3 and FLAN to generate such datasets. In this work we introduce InPars-v2, a dataset generator that uses open-source LLMs and existing powerful rerankers to select synthetic query-document pairs for training. A simple BM25 retrieval pipeline followed by a monoT5 reranker finetuned on InPars-v2 data achieves new state-of-the-art results on the BEIR benchmark. To allow researchers to further improve our method, we open source the code, synthetic data, and finetuned models: https://github.com/zetaalphavector/inPars/tree/master/tpu
Joint Beam Scheduling and Power Allocation for SWIPT in Mixed Near- and Far-Field Channels
Apr 24, 2023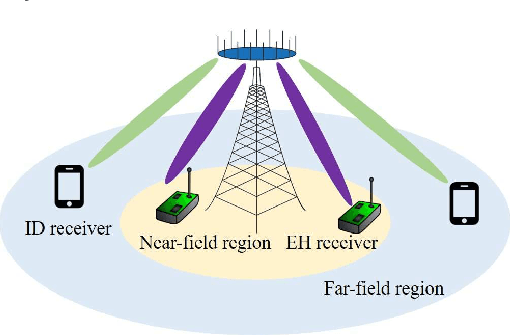
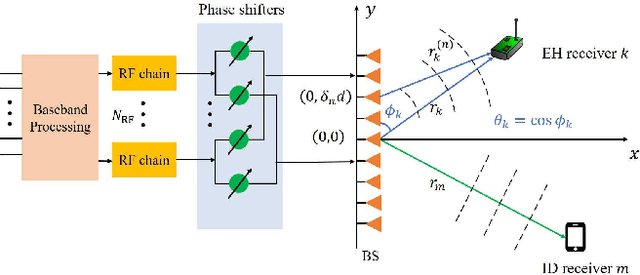
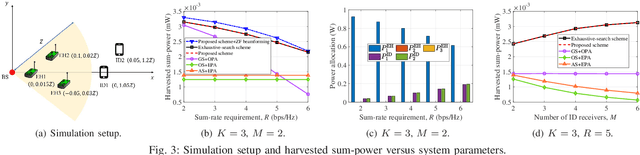
Extremely large-scale array (XL-array) has emerged as a promising technology to enhance the spectrum efficiency and spatial resolution in future wireless networks, leading to a fundamental paradigm shift from conventional far-field communications towards the new near-field communications. Different from the existing works that mostly considered simultaneous wireless information and power transfer (SWIPT) in the far field, we consider in this paper a new and practical scenario, called mixed near- and far-field SWIPT, in which energy harvesting (EH) and information decoding (ID) receivers are located in the near- and far-field regions of the XL-array base station (BS), respectively. Specifically, we formulate an optimization problem to maximize the weighted sum-power harvested at all EH receivers by jointly designing the BS beam scheduling and power allocation, under the constraints on the ID sum-rate and BS transmit power. To solve this nonconvex optimization problem, an efficient algorithm is proposed to obtain a suboptimal solution by leveraging the binary variable elimination and successive convex approximation methods. Numerical results demonstrate that our proposed joint design achieves substantial performance gain over other benchmark schemes.
Reinforcement Learning with Partial Parametric Model Knowledge
Apr 26, 2023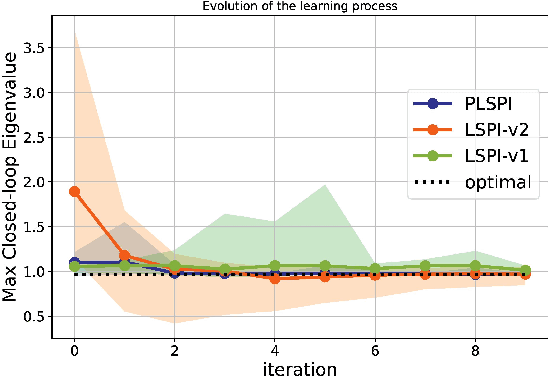
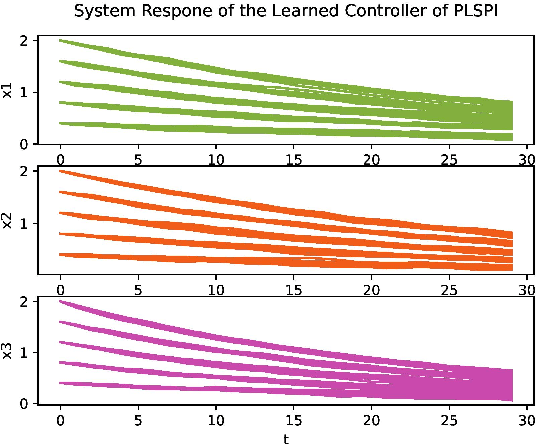
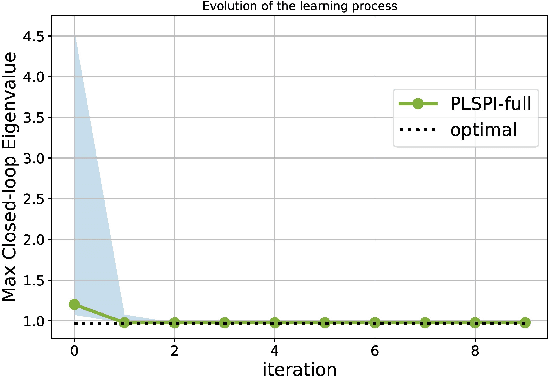
We adapt reinforcement learning (RL) methods for continuous control to bridge the gap between complete ignorance and perfect knowledge of the environment. Our method, Partial Knowledge Least Squares Policy Iteration (PLSPI), takes inspiration from both model-free RL and model-based control. It uses incomplete information from a partial model and retains RL's data-driven adaption towards optimal performance. The linear quadratic regulator provides a case study; numerical experiments demonstrate the effectiveness and resulting benefits of the proposed method.
Riesz networks: scale invariant neural networks in a single forward pass
May 08, 2023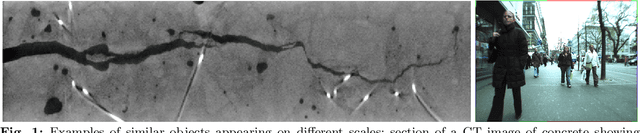
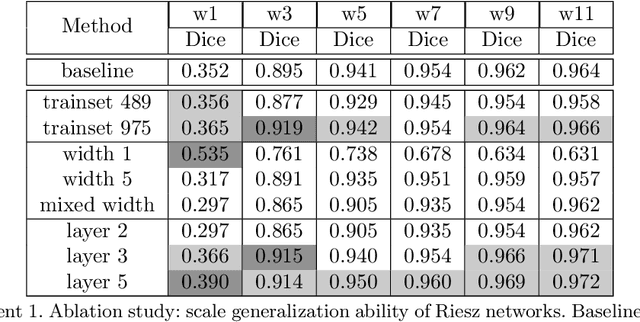

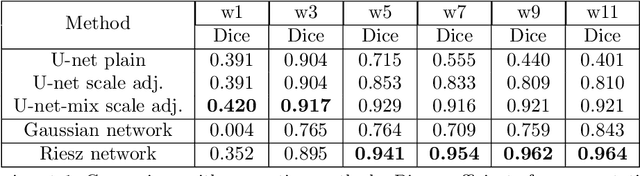
Scale invariance of an algorithm refers to its ability to treat objects equally independently of their size. For neural networks, scale invariance is typically achieved by data augmentation. However, when presented with a scale far outside the range covered by the training set, neural networks may fail to generalize. Here, we introduce the Riesz network, a novel scale invariant neural network. Instead of standard 2d or 3d convolutions for combining spatial information, the Riesz network is based on the Riesz transform which is a scale equivariant operation. As a consequence, this network naturally generalizes to unseen or even arbitrary scales in a single forward pass. As an application example, we consider detecting and segmenting cracks in tomographic images of concrete. In this context, 'scale' refers to the crack thickness which may vary strongly even within the same sample. To prove its scale invariance, the Riesz network is trained on one fixed crack width. We then validate its performance in segmenting simulated and real tomographic images featuring a wide range of crack widths. An additional experiment is carried out on the MNIST Large Scale data set.