 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Collaborative Plan Acquisition through Theory of Mind Modeling in Situated Dialogue
May 18, 2023

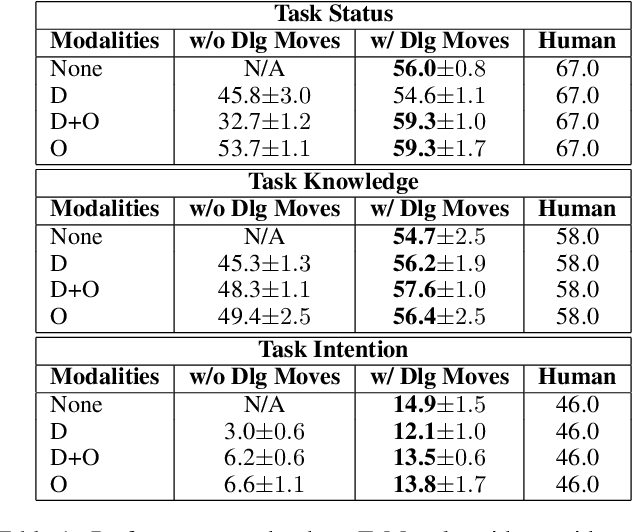
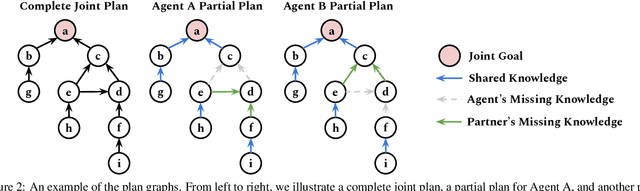
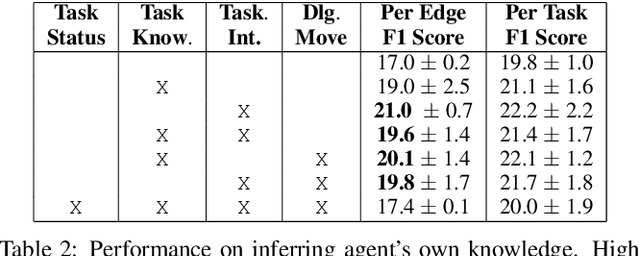
Collaborative tasks often begin with partial task knowledge and incomplete initial plans from each partner. To complete these tasks, agents need to engage in situated communication with their partners and coordinate their partial plans towards a complete plan to achieve a joint task goal. While such collaboration seems effortless in a human-human team, it is highly challenging for human-AI collaboration. To address this limitation, this paper takes a step towards collaborative plan acquisition, where humans and agents strive to learn and communicate with each other to acquire a complete plan for joint tasks. Specifically, we formulate a novel problem for agents to predict the missing task knowledge for themselves and for their partners based on rich perceptual and dialogue history. We extend a situated dialogue benchmark for symmetric collaborative tasks in a 3D blocks world and investigate computational strategies for plan acquisition. Our empirical results suggest that predicting the partner's missing knowledge is a more viable approach than predicting one's own. We show that explicit modeling of the partner's dialogue moves and mental states produces improved and more stable results than without. These results provide insight for future AI agents that can predict what knowledge their partner is missing and, therefore, can proactively communicate such information to help their partner acquire such missing knowledge toward a common understanding of joint tasks.
Taxonomy of AISecOps Threat Modeling for Cloud Based Medical Chatbots
May 18, 2023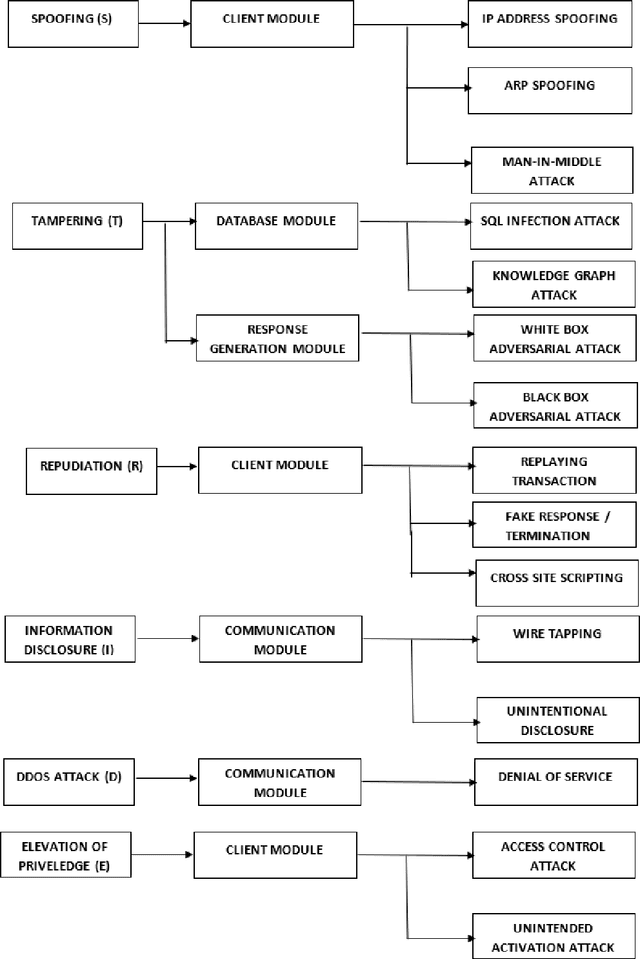
Artificial Intelligence (AI) is playing a vital role in all aspects of technology including cyber security. Application of Conversational AI like the chatbots are also becoming very popular in the medical field to provide timely and immediate medical assistance to patients in need. As medical chatbots deal with a lot of sensitive information, the security of these chatbots is crucial. To secure the confidentiality, integrity, and availability of cloud-hosted assets like these, medical chatbots can be monitored using AISecOps (Artificial Intelligence for Secure IT Operations). AISecOPs is an emerging field that integrates three different but interrelated domains like the IT operation, AI, and security as one domain, where the expertise from all these three domains are used cohesively to secure the cyber assets. It considers cloud operations and security in a holistic framework to collect the metrics required to assess the security threats and train the AI models to take immediate actions. This work is focused on applying the STRIDE threat modeling framework to model the possible threats involved in each component of the chatbot to enable the automatic threat detection using the AISecOps techniques. This threat modeling framework is tailored to the medical chatbots that involves sensitive data sharing but could also be applied for chatbots used in other sectors like the financial services, public sector, and government sectors that are concerned with security and compliance.
Multi-grained Hypergraph Interest Modeling for Conversational Recommendation
May 04, 2023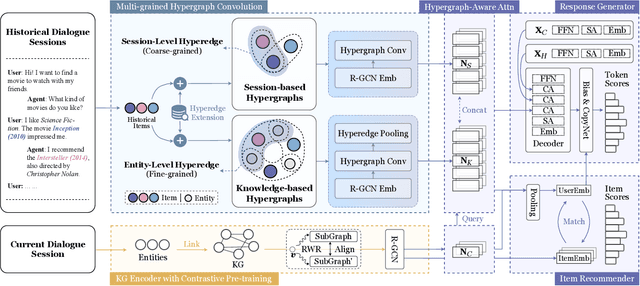

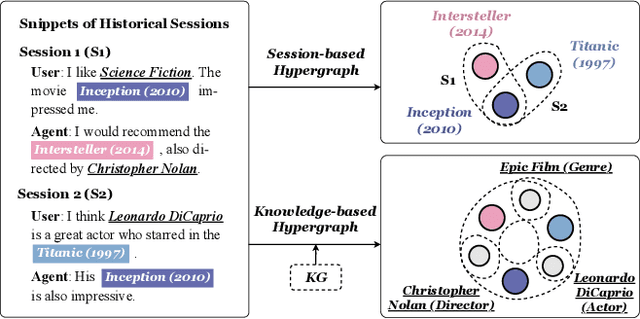
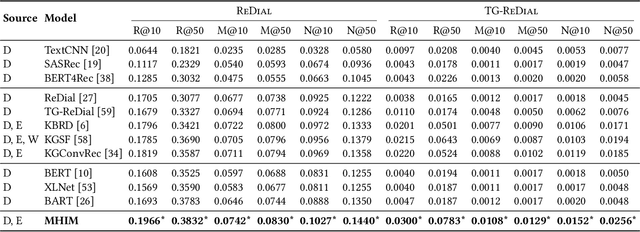
Conversational recommender system (CRS) interacts with users through multi-turn dialogues in natural language, which aims to provide high-quality recommendations for user's instant information need. Although great efforts have been made to develop effective CRS, most of them still focus on the contextual information from the current dialogue, usually suffering from the data scarcity issue. Therefore, we consider leveraging historical dialogue data to enrich the limited contexts of the current dialogue session. In this paper, we propose a novel multi-grained hypergraph interest modeling approach to capture user interest beneath intricate historical data from different perspectives. As the core idea, we employ hypergraph to represent complicated semantic relations underlying historical dialogues. In our approach, we first employ the hypergraph structure to model users' historical dialogue sessions and form a session-based hypergraph, which captures coarse-grained, session-level relations. Second, to alleviate the issue of data scarcity, we use an external knowledge graph and construct a knowledge-based hypergraph considering fine-grained, entity-level semantics. We further conduct multi-grained hypergraph convolution on the two kinds of hypergraphs, and utilize the enhanced representations to develop interest-aware CRS. Extensive experiments on two benchmarks ReDial and TG-ReDial validate the effectiveness of our approach on both recommendation and conversation tasks. Code is available at: https://github.com/RUCAIBox/MHIM.
Gene Set Summarization using Large Language Models
May 21, 2023
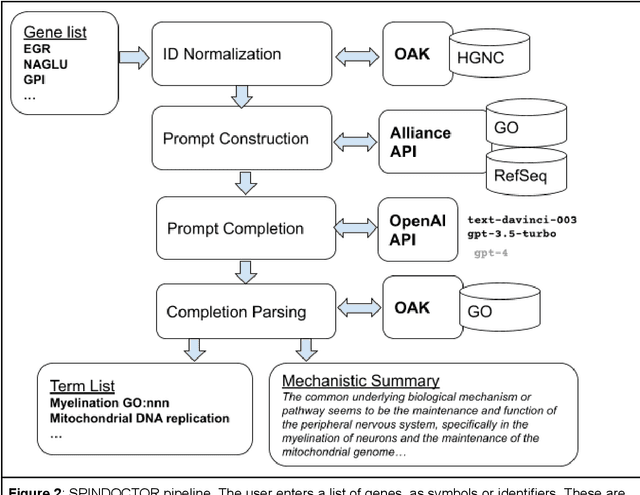
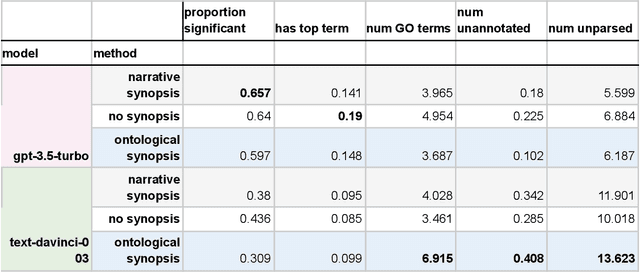
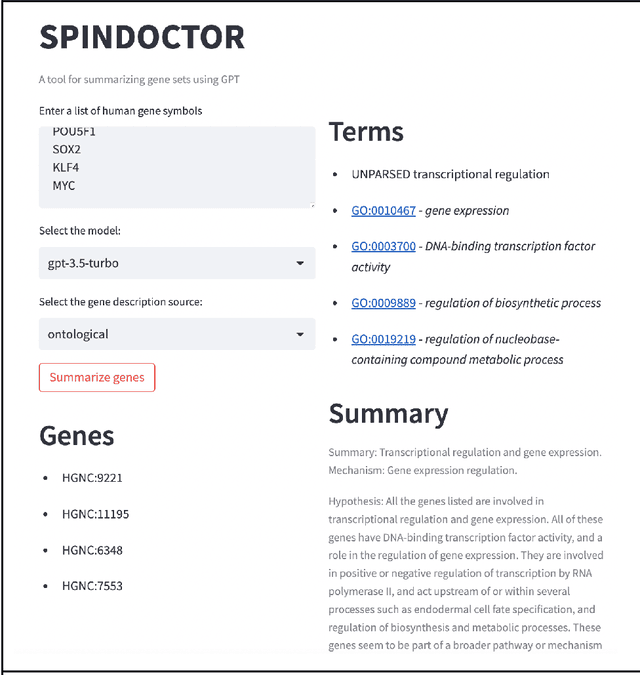
Molecular biologists frequently interpret gene lists derived from high-throughput experiments and computational analysis. This is typically done as a statistical enrichment analysis that measures the over- or under-representation of biological function terms associated with genes or their properties, based on curated assertions from a knowledge base (KB) such as the Gene Ontology (GO). Interpreting gene lists can also be framed as a textual summarization task, enabling the use of Large Language Models (LLMs), potentially utilizing scientific texts directly and avoiding reliance on a KB. We developed SPINDOCTOR (Structured Prompt Interpolation of Natural Language Descriptions of Controlled Terms for Ontology Reporting), a method that uses GPT models to perform gene set function summarization as a complement to standard enrichment analysis. This method can use different sources of gene functional information: (1) structured text derived from curated ontological KB annotations, (2) ontology-free narrative gene summaries, or (3) direct model retrieval. We demonstrate that these methods are able to generate plausible and biologically valid summary GO term lists for gene sets. However, GPT-based approaches are unable to deliver reliable scores or p-values and often return terms that are not statistically significant. Crucially, these methods were rarely able to recapitulate the most precise and informative term from standard enrichment, likely due to an inability to generalize and reason using an ontology. Results are highly nondeterministic, with minor variations in prompt resulting in radically different term lists. Our results show that at this point, LLM-based methods are unsuitable as a replacement for standard term enrichment analysis and that manual curation of ontological assertions remains necessary.
MaGIC: Multi-modality Guided Image Completion
May 19, 2023
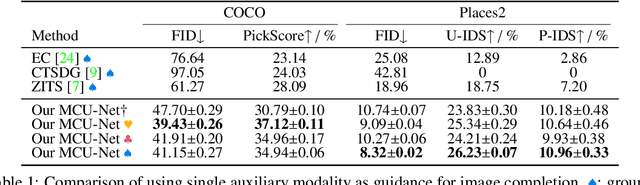
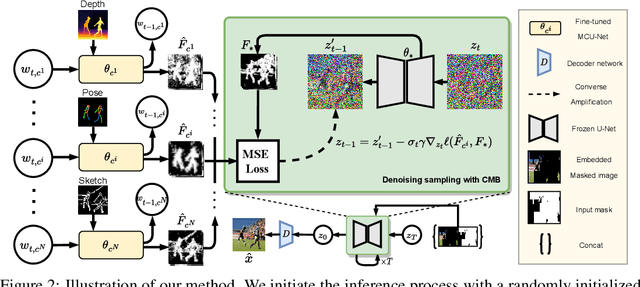
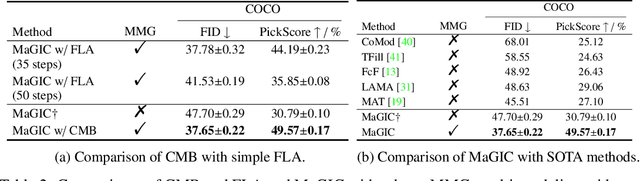
The vanilla image completion approaches are sensitive to the large missing regions due to limited available reference information for plausible generation. To mitigate this, existing methods incorporate the extra cue as a guidance for image completion. Despite improvements, these approaches are often restricted to employing a single modality (e.g., segmentation or sketch maps), which lacks scalability in leveraging multi-modality for more plausible completion. In this paper, we propose a novel, simple yet effective method for Multi-modal Guided Image Completion, dubbed MaGIC, which not only supports a wide range of single modality as the guidance (e.g., text, canny edge, sketch, segmentation, reference image, depth, and pose), but also adapts to arbitrarily customized combination of these modalities (i.e., arbitrary multi-modality) for image completion. For building MaGIC, we first introduce a modality-specific conditional U-Net (MCU-Net) that injects single-modal signal into a U-Net denoiser for single-modal guided image completion. Then, we devise a consistent modality blending (CMB) method to leverage modality signals encoded in multiple learned MCU-Nets through gradient guidance in latent space. Our CMB is training-free, and hence avoids the cumbersome joint re-training of different modalities, which is the secret of MaGIC to achieve exceptional flexibility in accommodating new modalities for completion. Experiments show the superiority of MaGIC over state-of-arts and its generalization to various completion tasks including in/out-painting and local editing. Our project with code and models is available at yeates.github.io/MaGIC-Page/.
GSB: Group Superposition Binarization for Vision Transformer with Limited Training Samples
May 19, 2023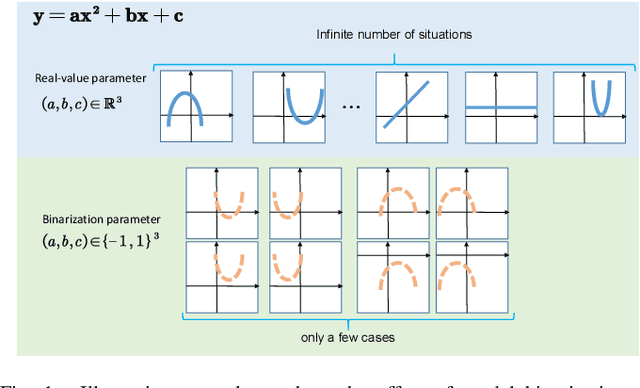
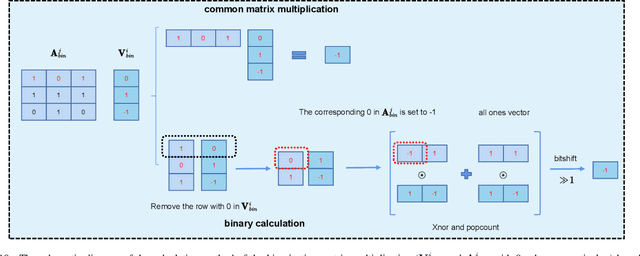
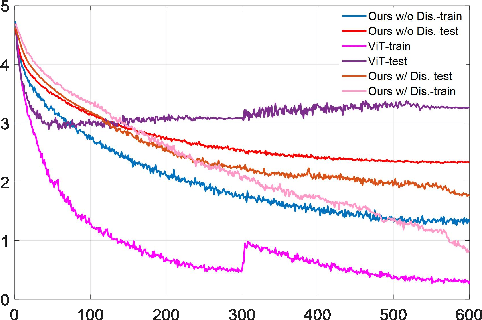
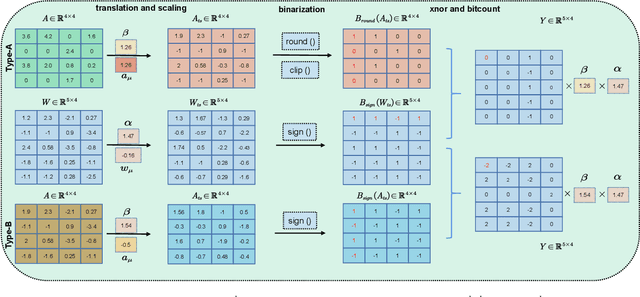
Affected by the massive amount of parameters, ViT usually suffers from serious overfitting problems with a relatively limited number of training samples. In addition, ViT generally demands heavy computing resources, which limit its deployment on resource-constrained devices. As a type of model-compression method,model binarization is potentially a good choice to solve the above problems. Compared with the full-precision one, the model with the binarization method replaces complex tensor multiplication with simple bit-wise binary operations and represents full-precision model parameters and activations with only 1-bit ones, which potentially solves the problem of model size and computational complexity, respectively. In this paper, we find that the decline of the accuracy of the binary ViT model is mainly due to the information loss of the Attention module and the Value vector. Therefore, we propose a novel model binarization technique, called Group Superposition Binarization (GSB), to deal with these issues. Furthermore, in order to further improve the performance of the binarization model, we have investigated the gradient calculation procedure in the binarization process and derived more proper gradient calculation equations for GSB to reduce the influence of gradient mismatch. Then, the knowledge distillation technique is introduced to alleviate the performance degradation caused by model binarization. Experiments on three datasets with limited numbers of training samples demonstrate that the proposed GSB model achieves state-of-the-art performance among the binary quantization schemes and exceeds its full-precision counterpart on some indicators.
Learning Global-aware Kernel for Image Harmonization
May 19, 2023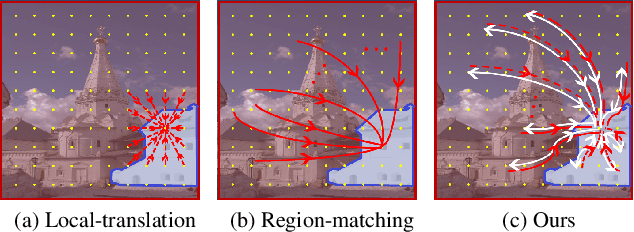
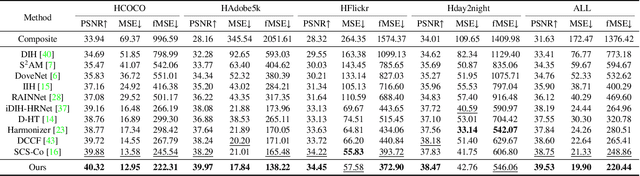

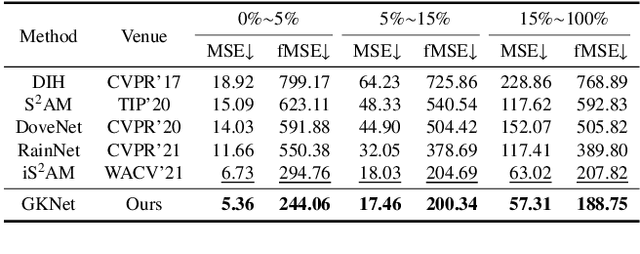
Image harmonization aims to solve the visual inconsistency problem in composited images by adaptively adjusting the foreground pixels with the background as references. Existing methods employ local color transformation or region matching between foreground and background, which neglects powerful proximity prior and independently distinguishes fore-/back-ground as a whole part for harmonization. As a result, they still show a limited performance across varied foreground objects and scenes. To address this issue, we propose a novel Global-aware Kernel Network (GKNet) to harmonize local regions with comprehensive consideration of long-distance background references. Specifically, GKNet includes two parts, \ie, harmony kernel prediction and harmony kernel modulation branches. The former includes a Long-distance Reference Extractor (LRE) to obtain long-distance context and Kernel Prediction Blocks (KPB) to predict multi-level harmony kernels by fusing global information with local features. To achieve this goal, a novel Selective Correlation Fusion (SCF) module is proposed to better select relevant long-distance background references for local harmonization. The latter employs the predicted kernels to harmonize foreground regions with both local and global awareness. Abundant experiments demonstrate the superiority of our method for image harmonization over state-of-the-art methods, \eg, achieving 39.53dB PSNR that surpasses the best counterpart by +0.78dB $\uparrow$; decreasing fMSE/MSE by 11.5\%$\downarrow$/6.7\%$\downarrow$ compared with the SoTA method. Code will be available at \href{https://github.com/XintianShen/GKNet}{here}.
Receding Horizon Control on the Broadcast of Information in Stochastic Networks
Dec 19, 2022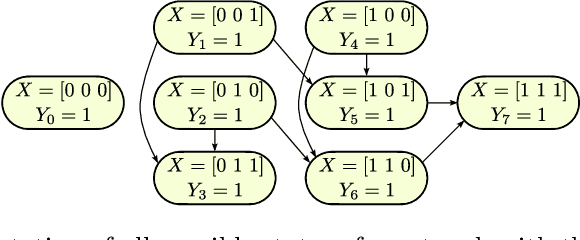
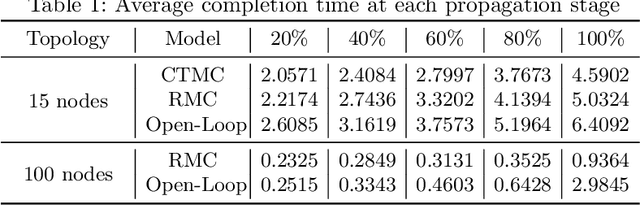
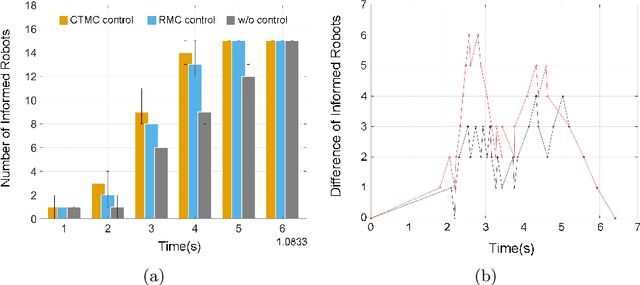
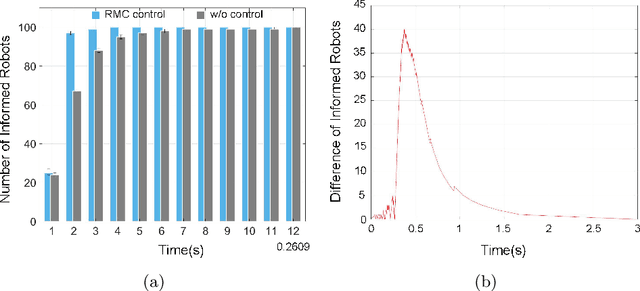
This paper focuses on the broadcast of information on robot networks with stochastic network interconnection topologies. Problematic communication networks are almost unavoidable in areas where we wish to deploy multi-robotic systems, usually due to a lack of environmental consistency, accessibility, and structure. We tackle this problem by modeling the broadcast of information in a multi-robot communication network as a stochastic process with random arrival times, which can be produced by irregular robot movements, wireless attenuation, and other environmental factors. Using this model, we provide and analyze a receding horizon control strategy to control the statistics of the information broadcast. The resulting strategy compels the robots to re-direct their communication resources to different neighbors according to the current propagation process to fulfill global broadcast requirements. Based on this method, we provide an approach to compute the expected time to broadcast the message to all nodes. Numerical examples are provided to illustrate the results.
On Pitfalls of $\textit{RemOve-And-Retrain}$: Data Processing Inequality Perspective
May 11, 2023

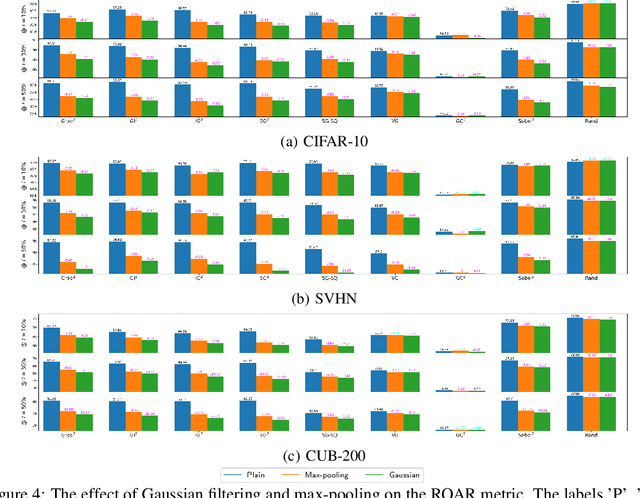
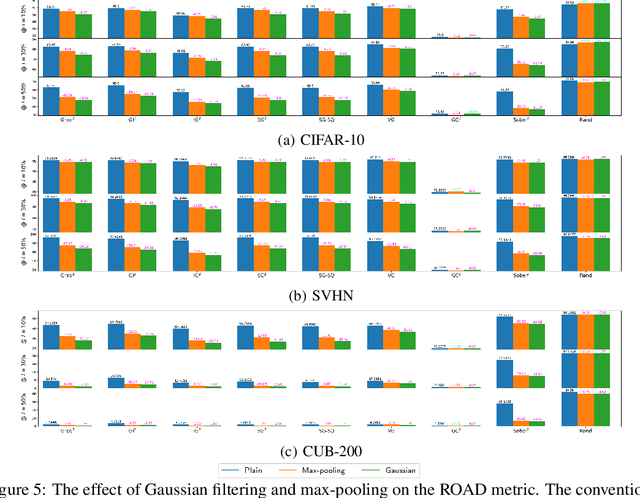
Approaches for appraising feature importance approximations, alternatively referred to as attribution methods, have been established across an extensive array of contexts. The development of resilient techniques for performance benchmarking constitutes a critical concern in the sphere of explainable deep learning. This study scrutinizes the dependability of the RemOve-And-Retrain (ROAR) procedure, which is prevalently employed for gauging the performance of feature importance estimates. The insights gleaned from our theoretical foundation and empirical investigations reveal that attributions containing lesser information about the decision function may yield superior results in ROAR benchmarks, contradicting the original intent of ROAR. This occurrence is similarly observed in the recently introduced variant RemOve-And-Debias (ROAD), and we posit a persistent pattern of blurriness bias in ROAR attribution metrics. Our findings serve as a warning against indiscriminate use on ROAR metrics. The code is available as open source.
Data quality dimensions for fair AI
May 11, 2023


AI systems are not intrinsically neutral and biases trickle in any type of technological tool. In particular when dealing with people, AI algorithms reflect technical errors originating with mislabeled data. As they feed wrong and discriminatory classifications, perpetuating structural racism and marginalization, these systems are not systematically guarded against bias. In this article we consider the problem of bias in AI systems from the point of view of Information Quality dimensions. We illustrate potential improvements of a bias mitigation tool in gender classification errors, referring to two typically difficult contexts: the classification of non-binary individuals and the classification of transgender individuals. The identification of data quality dimensions to implement in bias mitigation tool may help achieve more fairness. Hence, we propose to consider this issue in terms of completeness, consistency, timeliness and reliability, and offer some theoretical results.