 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Metrics for Bayesian Optimal Experiment Design under Model Misspecification
Apr 17, 2023
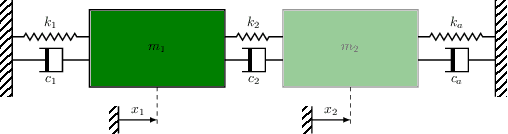
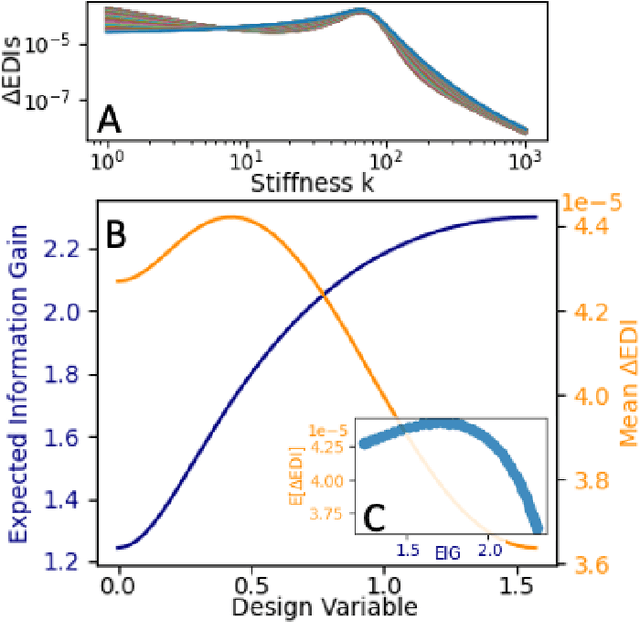
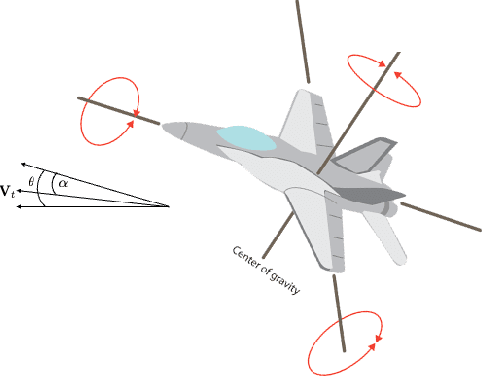
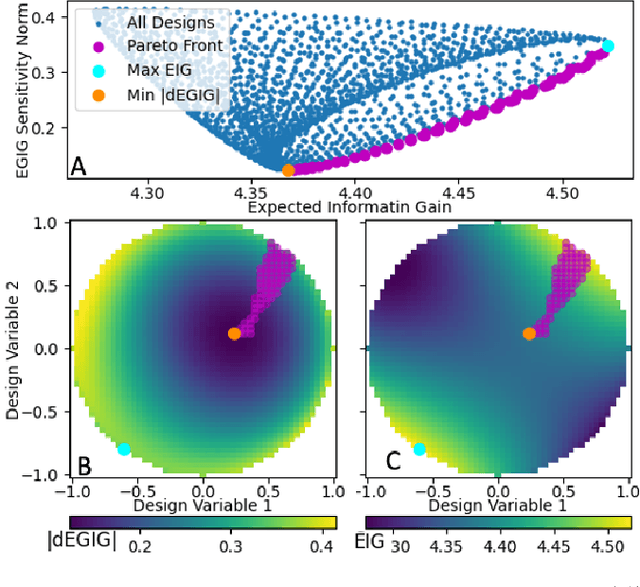
The conventional approach to Bayesian decision-theoretic experiment design involves searching over possible experiments to select a design that maximizes the expected value of a specified utility function. The expectation is over the joint distribution of all unknown variables implied by the statistical model that will be used to analyze the collected data. The utility function defines the objective of the experiment where a common utility function is the information gain. This article introduces an expanded framework for this process, where we go beyond the traditional Expected Information Gain criteria and introduce the Expected General Information Gain which measures robustness to the model discrepancy and Expected Discriminatory Information as a criterion to quantify how well an experiment can detect model discrepancy. The functionality of the framework is showcased through its application to a scenario involving a linearized spring mass damper system and an F-16 model where the model discrepancy is taken into account while doing Bayesian optimal experiment design.
Learning Geometry-aware Representations by Sketching
Apr 17, 2023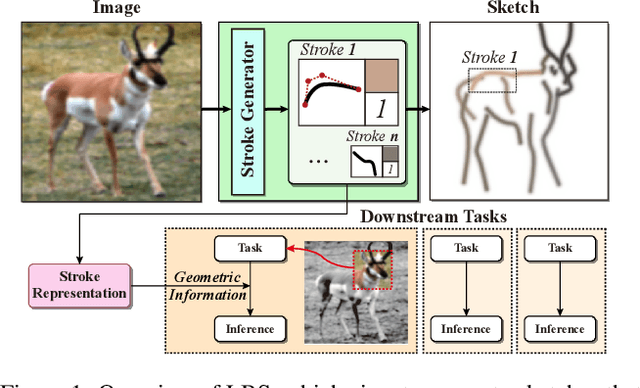
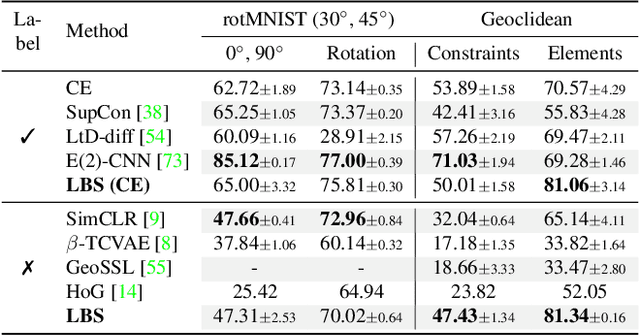
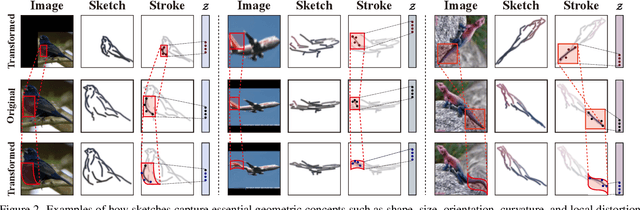
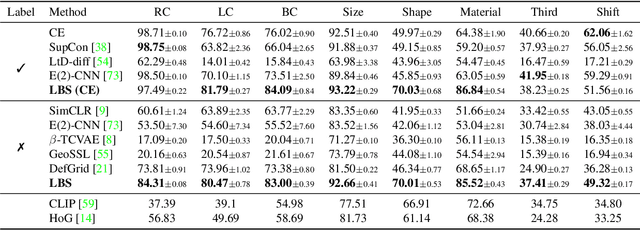
Understanding geometric concepts, such as distance and shape, is essential for understanding the real world and also for many vision tasks. To incorporate such information into a visual representation of a scene, we propose learning to represent the scene by sketching, inspired by human behavior. Our method, coined Learning by Sketching (LBS), learns to convert an image into a set of colored strokes that explicitly incorporate the geometric information of the scene in a single inference step without requiring a sketch dataset. A sketch is then generated from the strokes where CLIP-based perceptual loss maintains a semantic similarity between the sketch and the image. We show theoretically that sketching is equivariant with respect to arbitrary affine transformations and thus provably preserves geometric information. Experimental results show that LBS substantially improves the performance of object attribute classification on the unlabeled CLEVR dataset, domain transfer between CLEVR and STL-10 datasets, and for diverse downstream tasks, confirming that LBS provides rich geometric information.
Masked Reconstruction Contrastive Learning with Information Bottleneck Principle
Nov 15, 2022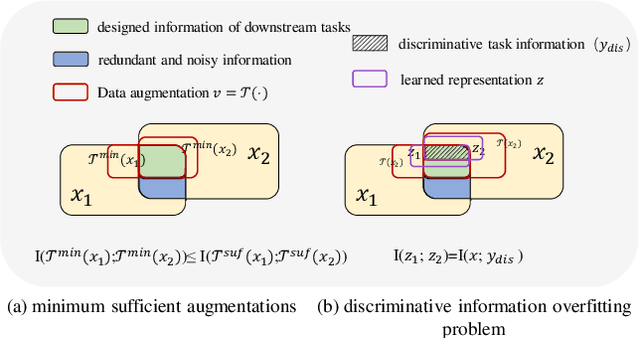
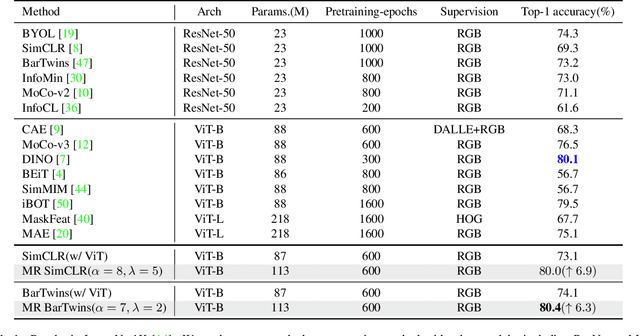
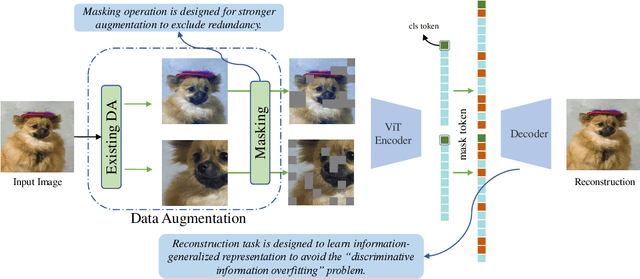
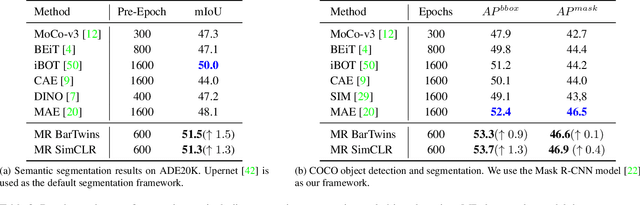
Contrastive learning (CL) has shown great power in self-supervised learning due to its ability to capture insight correlations among large-scale data. Current CL models are biased to learn only the ability to discriminate positive and negative pairs due to the discriminative task setting. However, this bias would lead to ignoring its sufficiency for other downstream tasks, which we call the discriminative information overfitting problem. In this paper, we propose to tackle the above problems from the aspect of the Information Bottleneck (IB) principle, further pushing forward the frontier of CL. Specifically, we present a new perspective that CL is an instantiation of the IB principle, including information compression and expression. We theoretically analyze the optimal information situation and demonstrate that minimum sufficient augmentation and information-generalized representation are the optimal requirements for achieving maximum compression and generalizability to downstream tasks. Therefore, we propose the Masked Reconstruction Contrastive Learning~(MRCL) model to improve CL models. For implementation in practice, MRCL utilizes the masking operation for stronger augmentation, further eliminating redundant and noisy information. In order to alleviate the discriminative information overfitting problem effectively, we employ the reconstruction task to regularize the discriminative task. We conduct comprehensive experiments and show the superiority of the proposed model on multiple tasks, including image classification, semantic segmentation and objective detection.
Beyond the Safeguards: Exploring the Security Risks of ChatGPT
May 13, 2023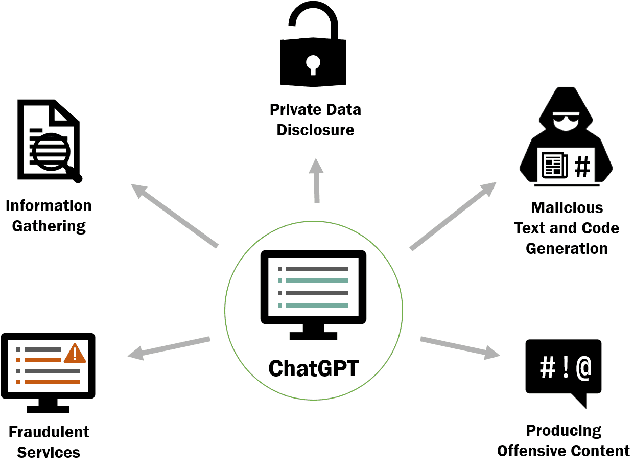
The increasing popularity of large language models (LLMs) such as ChatGPT has led to growing concerns about their safety, security risks, and ethical implications. This paper aims to provide an overview of the different types of security risks associated with ChatGPT, including malicious text and code generation, private data disclosure, fraudulent services, information gathering, and producing unethical content. We present an empirical study examining the effectiveness of ChatGPT's content filters and explore potential ways to bypass these safeguards, demonstrating the ethical implications and security risks that persist in LLMs even when protections are in place. Based on a qualitative analysis of the security implications, we discuss potential strategies to mitigate these risks and inform researchers, policymakers, and industry professionals about the complex security challenges posed by LLMs like ChatGPT. This study contributes to the ongoing discussion on the ethical and security implications of LLMs, underscoring the need for continued research in this area.
Squeeze Excitation Embedded Attention UNet for Brain Tumor Segmentation
May 13, 2023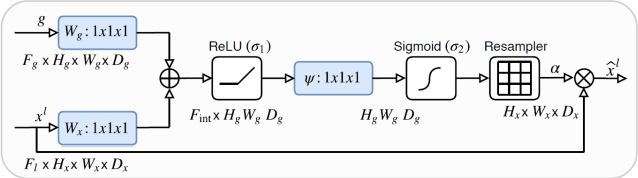

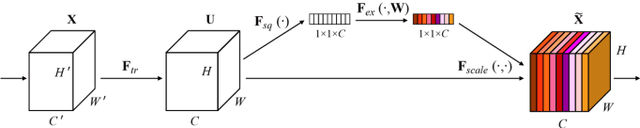
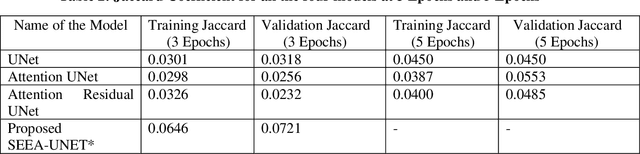
Deep Learning based techniques have gained significance over the past few years in the field of medicine. They are used in various applications such as classifying medical images, segmentation and identification. The existing architectures such as UNet, Attention UNet and Attention Residual UNet are already currently existing methods for the same application of brain tumor segmentation, but none of them address the issue of how to extract the features in channel level. In this paper, we propose a new architecture called Squeeze Excitation Embedded Attention UNet (SEEA-UNet), this architecture has both Attention UNet and Squeeze Excitation Network for better results and predictions, this is used mainly because to get information at both Spatial and channel levels. The proposed model was compared with the existing architectures based on the comparison it was found out that for lesser number of epochs trained, the proposed model performed better. Binary focal loss and Jaccard Coefficient were used to monitor the model's performance.
Rethinking the Open-Loop Evaluation of End-to-End Autonomous Driving in nuScenes
May 17, 2023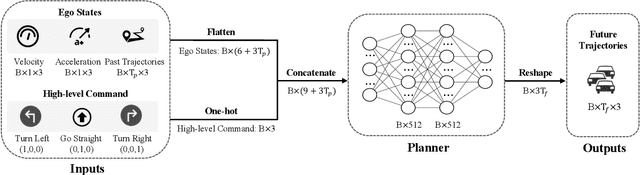
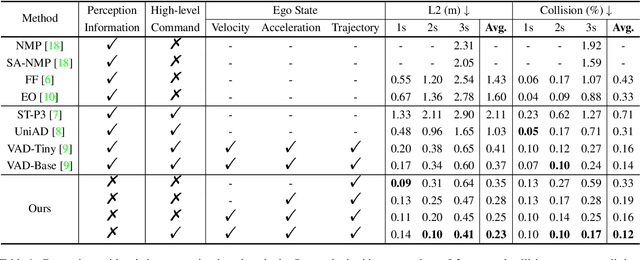
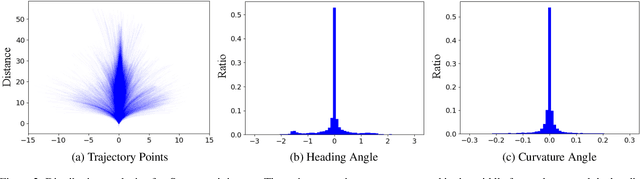
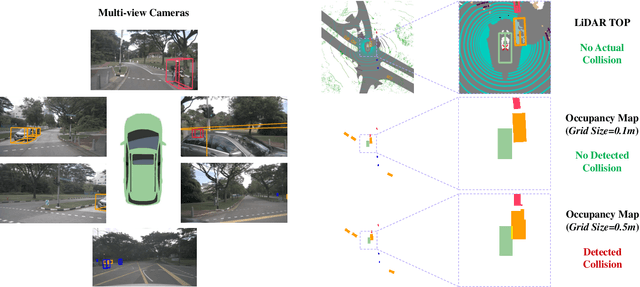
Modern autonomous driving systems are typically divided into three main tasks: perception, prediction, and planning. The planning task involves predicting the trajectory of the ego vehicle based on inputs from both internal intention and the external environment, and manipulating the vehicle accordingly. Most existing works evaluate their performance on the nuScenes dataset using the L2 error and collision rate between the predicted trajectories and the ground truth. In this paper, we reevaluate these existing evaluation metrics and explore whether they accurately measure the superiority of different methods. Specifically, we design an MLP-based method that takes raw sensor data (e.g., past trajectory, velocity, etc.) as input and directly outputs the future trajectory of the ego vehicle, without using any perception or prediction information such as camera images or LiDAR. Surprisingly, such a simple method achieves state-of-the-art end-to-end planning performance on the nuScenes dataset, reducing the average L2 error by about 30%. We further conduct in-depth analysis and provide new insights into the factors that are critical for the success of the planning task on nuScenes dataset. Our observation also indicates that we need to rethink the current open-loop evaluation scheme of end-to-end autonomous driving in nuScenes. Codes are available at https://github.com/E2E-AD/AD-MLP.
Towards Robust Probabilistic Modeling on SO(3) via Rotation Laplace Distribution
May 17, 2023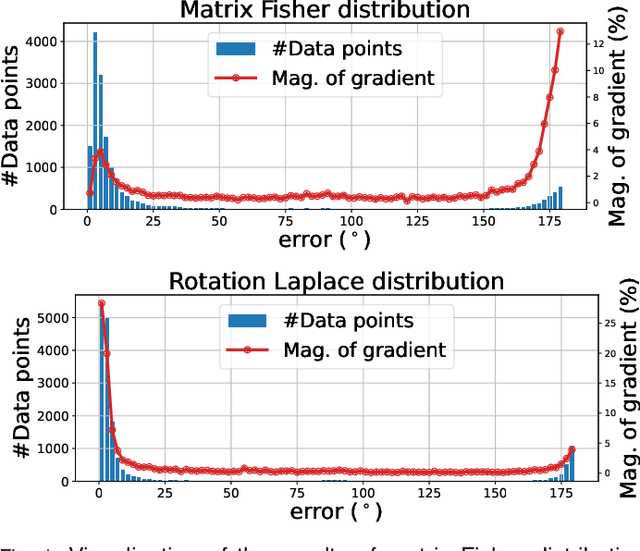
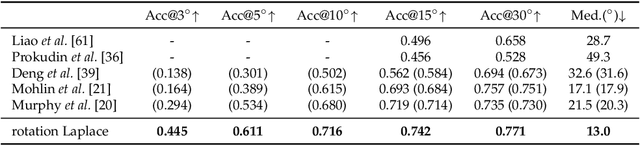

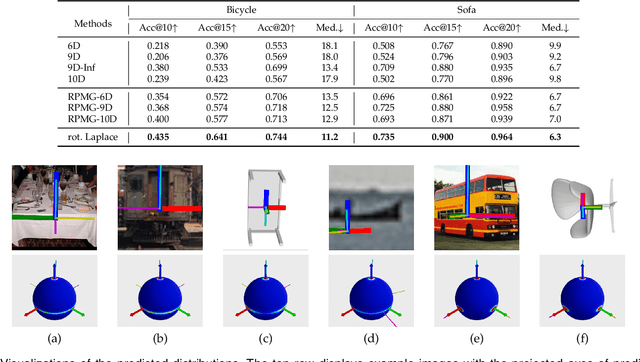
Estimating the 3DoF rotation from a single RGB image is an important yet challenging problem. As a popular approach, probabilistic rotation modeling additionally carries prediction uncertainty information, compared to single-prediction rotation regression. For modeling probabilistic distribution over SO(3), it is natural to use Gaussian-like Bingham distribution and matrix Fisher, however they are shown to be sensitive to outlier predictions, e.g. $180^\circ$ error and thus are unlikely to converge with optimal performance. In this paper, we draw inspiration from multivariate Laplace distribution and propose a novel rotation Laplace distribution on SO(3). Our rotation Laplace distribution is robust to the disturbance of outliers and enforces much gradient to the low-error region that it can improve. In addition, we show that our method also exhibits robustness to small noises and thus tolerates imperfect annotations. With this benefit, we demonstrate its advantages in semi-supervised rotation regression, where the pseudo labels are noisy. To further capture the multi-modal rotation solution space for symmetric objects, we extend our distribution to rotation Laplace mixture model and demonstrate its effectiveness. Our extensive experiments show that our proposed distribution and the mixture model achieve state-of-the-art performance in all the rotation regression experiments over both probabilistic and non-probabilistic baselines.
CLIP-GCD: Simple Language Guided Generalized Category Discovery
May 17, 2023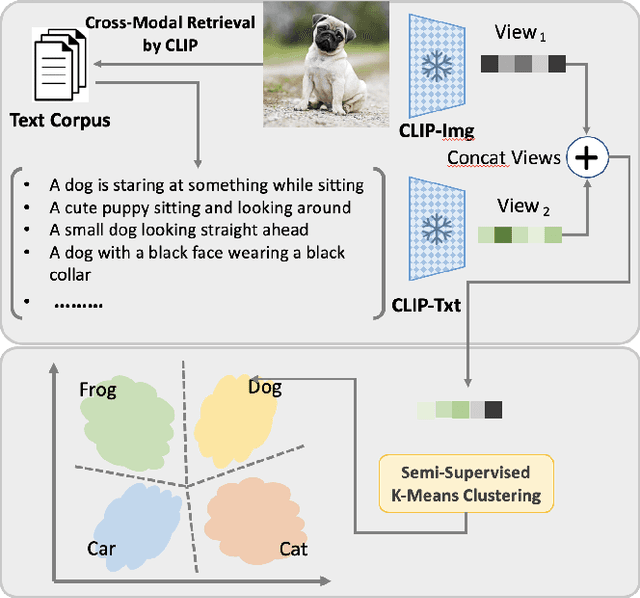
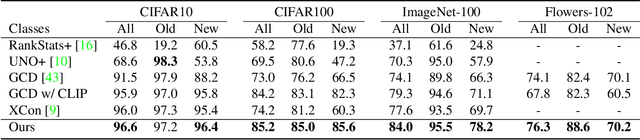
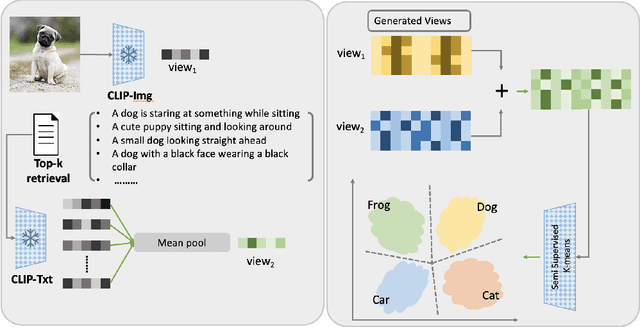
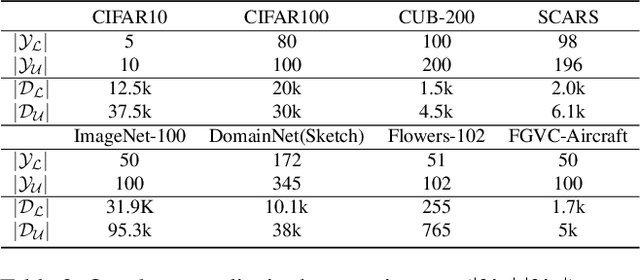
Generalized Category Discovery (GCD) requires a model to both classify known categories and cluster unknown categories in unlabeled data. Prior methods leveraged self-supervised pre-training combined with supervised fine-tuning on the labeled data, followed by simple clustering methods. In this paper, we posit that such methods are still prone to poor performance on out-of-distribution categories, and do not leverage a key ingredient: Semantic relationships between object categories. We therefore propose to leverage multi-modal (vision and language) models, in two complementary ways. First, we establish a strong baseline by replacing uni-modal features with CLIP, inspired by its zero-shot performance. Second, we propose a novel retrieval-based mechanism that leverages CLIP's aligned vision-language representations by mining text descriptions from a text corpus for the labeled and unlabeled set. We specifically use the alignment between CLIP's visual encoding of the image and textual encoding of the corpus to retrieve top-k relevant pieces of text and incorporate their embeddings to perform joint image+text semi-supervised clustering. We perform rigorous experimentation and ablations (including on where to retrieve from, how much to retrieve, and how to combine information), and validate our results on several datasets including out-of-distribution domains, demonstrating state-of-art results.
Dynamic Structural Brain Network Construction by Hierarchical Prototype Embedding GCN using T1-MRI
May 17, 2023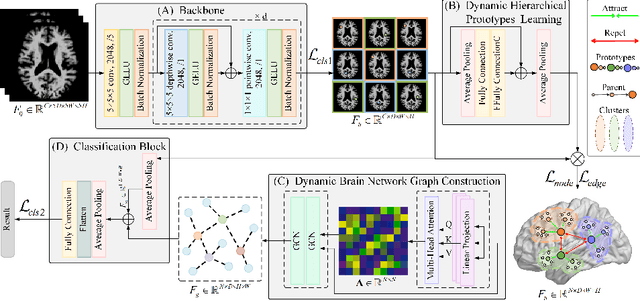
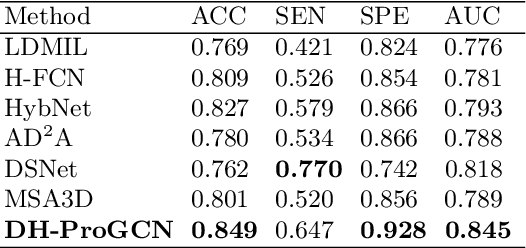
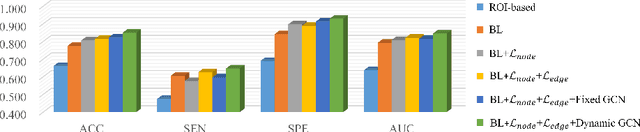
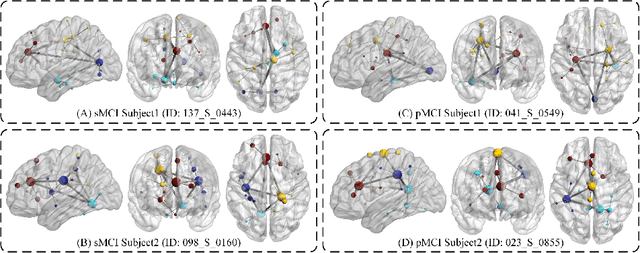
Constructing structural brain networks using T1-weighted magnetic resonance imaging (T1-MRI) presents a significant challenge due to the lack of direct regional connectivity information. Current methods with T1-MRI rely on predefined regions or isolated pretrained location modules to obtain atrophic regions, which neglects individual specificity. Besides, existing methods capture global structural context only on the whole-image-level, which weaken correlation between regions and the hierarchical distribution nature of brain connectivity.We hereby propose a novel dynamic structural brain network construction method based on T1-MRI, which can dynamically localize critical regions and constrain the hierarchical distribution among them for constructing dynamic structural brain network. Specifically, we first cluster spatially-correlated channel and generate several critical brain regions as prototypes. Further, we introduce a contrastive loss function to constrain the prototypes distribution, which embed the hierarchical brain semantic structure into the latent space. Self-attention and GCN are then used to dynamically construct hierarchical correlations of critical regions for brain network and explore the correlation, respectively. Our method is evaluated on ADNI-1 and ADNI-2 databases for mild cognitive impairment (MCI) conversion prediction, and acheive the state-of-the-art (SOTA) performance. Our source code is available at http://github.com/*******.
Dual Semantic Knowledge Composed Multimodal Dialog Systems
May 17, 2023
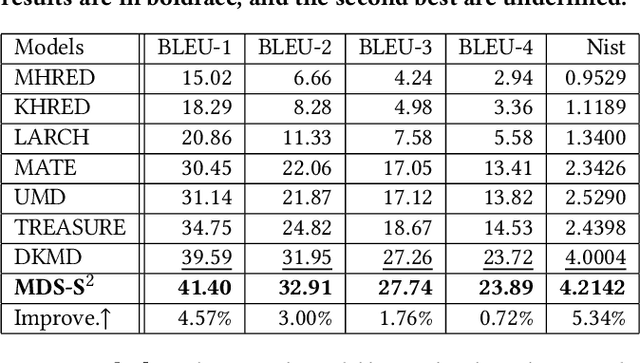
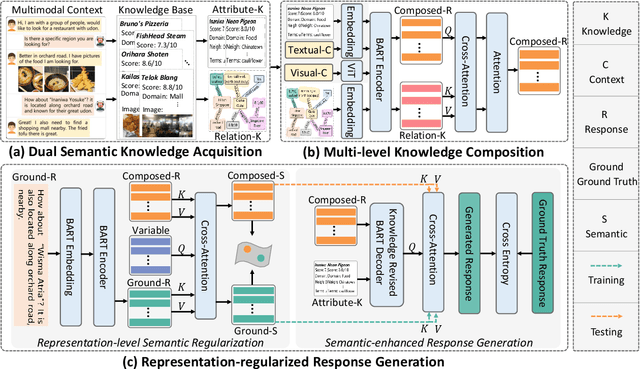
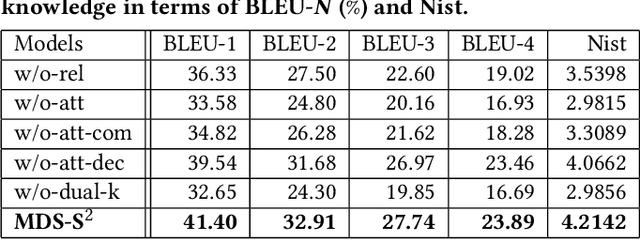
Textual response generation is an essential task for multimodal task-oriented dialog systems.Although existing studies have achieved fruitful progress, they still suffer from two critical limitations: 1) focusing on the attribute knowledge but ignoring the relation knowledge that can reveal the correlations between different entities and hence promote the response generation}, and 2) only conducting the cross-entropy loss based output-level supervision but lacking the representation-level regularization. To address these limitations, we devise a novel multimodal task-oriented dialog system (named MDS-S2). Specifically, MDS-S2 first simultaneously acquires the context related attribute and relation knowledge from the knowledge base, whereby the non-intuitive relation knowledge is extracted by the n-hop graph walk. Thereafter, considering that the attribute knowledge and relation knowledge can benefit the responding to different levels of questions, we design a multi-level knowledge composition module in MDS-S2 to obtain the latent composed response representation. Moreover, we devise a set of latent query variables to distill the semantic information from the composed response representation and the ground truth response representation, respectively, and thus conduct the representation-level semantic regularization. Extensive experiments on a public dataset have verified the superiority of our proposed MDS-S2. We have released the codes and parameters to facilitate the research community.