 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Decker: Double Check with Heterogeneous Knowledge for Commonsense Fact Verification
May 10, 2023


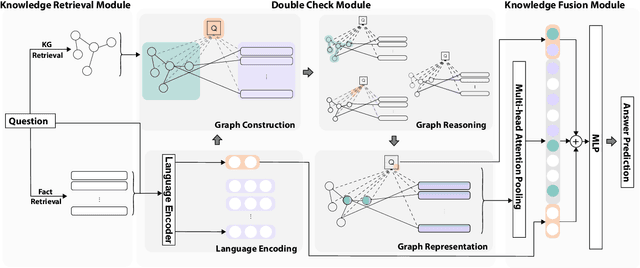
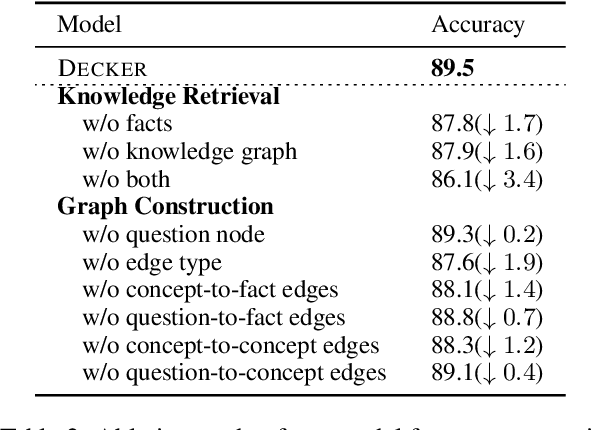
Commonsense fact verification, as a challenging branch of commonsense question-answering (QA), aims to verify through facts whether a given commonsense claim is correct or not. Answering commonsense questions necessitates a combination of knowledge from various levels. However, existing studies primarily rest on grasping either unstructured evidence or potential reasoning paths from structured knowledge bases, yet failing to exploit the benefits of heterogeneous knowledge simultaneously. In light of this, we propose Decker, a commonsense fact verification model that is capable of bridging heterogeneous knowledge by uncovering latent relationships between structured and unstructured knowledge. Experimental results on two commonsense fact verification benchmark datasets, CSQA2.0 and CREAK demonstrate the effectiveness of our Decker and further analysis verifies its capability to seize more precious information through reasoning.
Extracting Complex Named Entities in Legal Documents via Weakly Supervised Object Detection
May 10, 2023
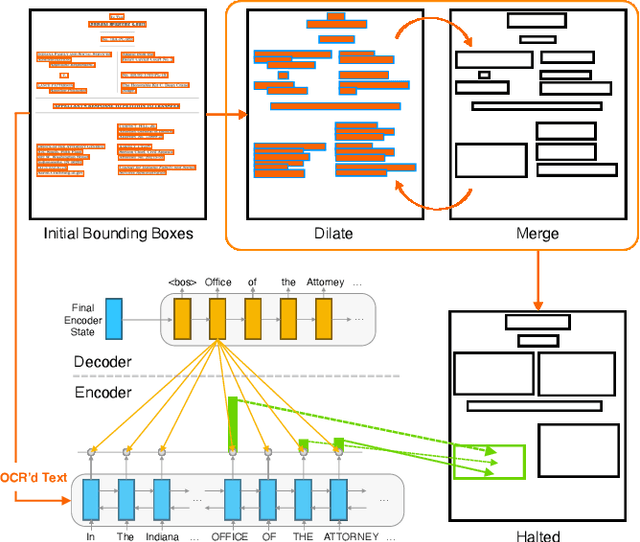
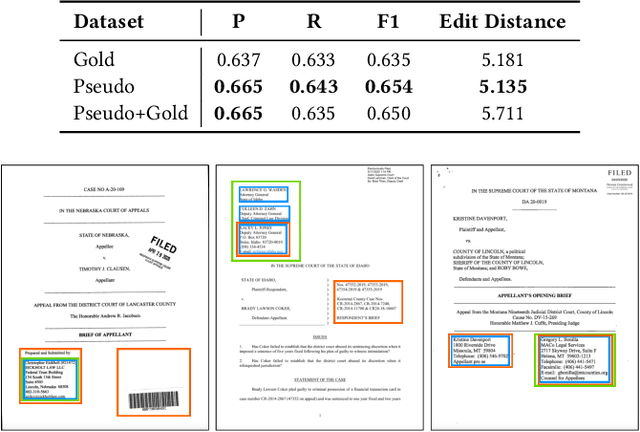
Accurate Named Entity Recognition (NER) is crucial for various information retrieval tasks in industry. However, despite significant progress in traditional NER methods, the extraction of Complex Named Entities remains a relatively unexplored area. In this paper, we propose a novel system that combines object detection for Document Layout Analysis (DLA) with weakly supervised learning to address the challenge of extracting discontinuous complex named entities in legal documents. Notably, to the best of our knowledge, this is the first work to apply weak supervision to DLA. Our experimental results show that the model trained solely on pseudo labels outperforms the supervised baseline when gold-standard data is limited, highlighting the effectiveness of our proposed approach in reducing the dependency on annotated data.
Empowering Language Model with Guided Knowledge Fusion for Biomedical Document Re-ranking
May 07, 2023
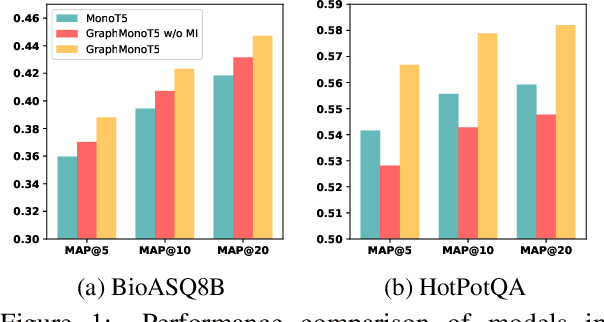
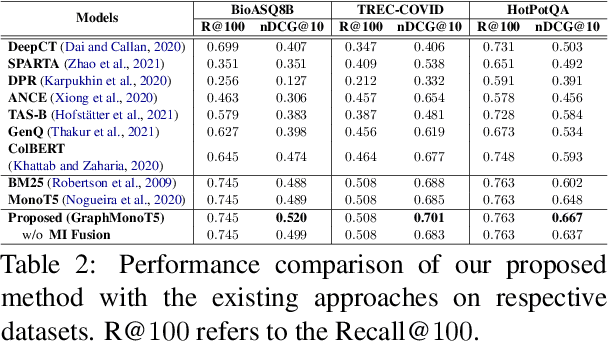
Pre-trained language models (PLMs) have proven to be effective for document re-ranking task. However, they lack the ability to fully interpret the semantics of biomedical and health-care queries and often rely on simplistic patterns for retrieving documents. To address this challenge, we propose an approach that integrates knowledge and the PLMs to guide the model toward effectively capturing information from external sources and retrieving the correct documents. We performed comprehensive experiments on two biomedical and open-domain datasets that show that our approach significantly improves vanilla PLMs and other existing approaches for document re-ranking task.
Multi-scale Transformer-based Network for Emotion Recognition from Multi Physiological Signals
May 08, 2023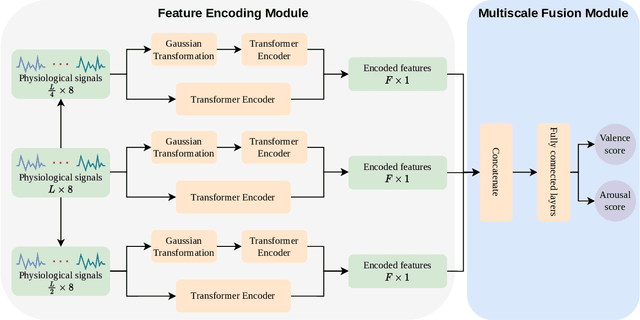
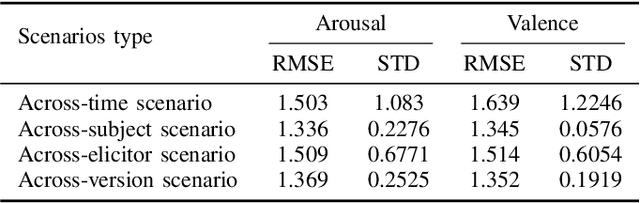
This paper presents an efficient Multi-scale Transformer-based approach for the task of Emotion recognition from Physiological data, which has gained widespread attention in the research community due to the vast amount of information that can be extracted from these signals using modern sensors and machine learning techniques. Our approach involves applying a Multi-modal technique combined with scaling data to establish the relationship between internal body signals and human emotions. Additionally, we utilize Transformer and Gaussian Transformation techniques to improve signal encoding effectiveness and overall performance. Our model achieves decent results on the CASE dataset of the EPiC competition, with an RMSE score of 1.45.
Touch and deformation perception of soft manipulators with capacitive e-skins and deep learning
May 02, 2023
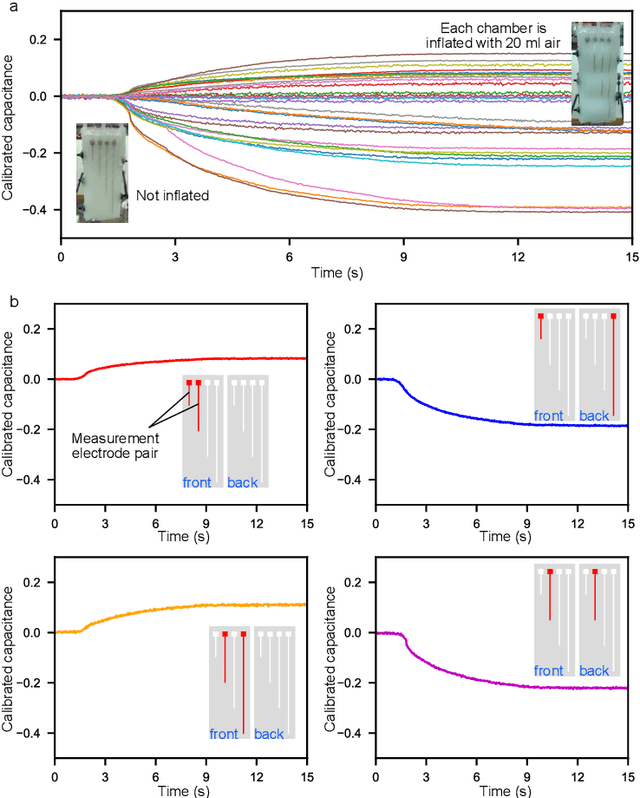
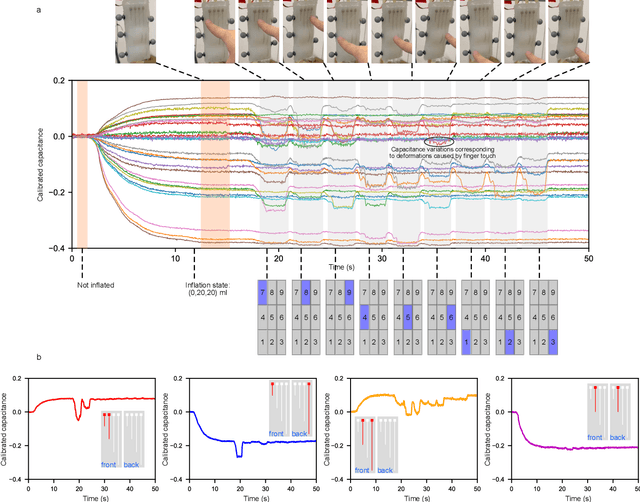
Tactile sensing in soft robots remains particularly challenging because of the coupling between contact and deformation information which the sensor is subject to during actuation and interaction with the environment. This often results in severe interference and makes disentangling tactile sensing and geometric deformation difficult. To address this problem, this paper proposes a soft capacitive e-skin with a sparse electrode distribution and deep learning for information decoupling. Our approach successfully separates tactile sensing from geometric deformation, enabling touch recognition on a soft pneumatic actuator subject to both internal (actuation) and external (manual handling) forces. Using a multi-layer perceptron, the proposed e-skin achieves 99.88\% accuracy in touch recognition across a range of deformations. When complemented with prior knowledge, a transformer-based architecture effectively tracks the deformation of the soft actuator. The average distance error in positional reconstruction of the manipulator is as low as 2.905$\pm$2.207 mm, even under operative conditions with different inflation states and physical contacts which lead to additional signal variations and consequently interfere with deformation tracking. These findings represent a tangible way forward in the development of e-skins that can endow soft robots with proprioception and exteroception.
CARLA-BSP: a simulated dataset with pedestrians
Apr 29, 2023
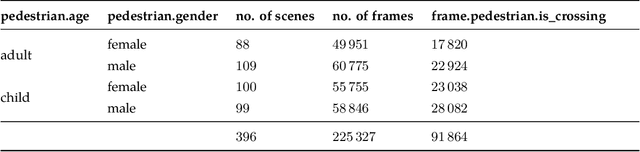
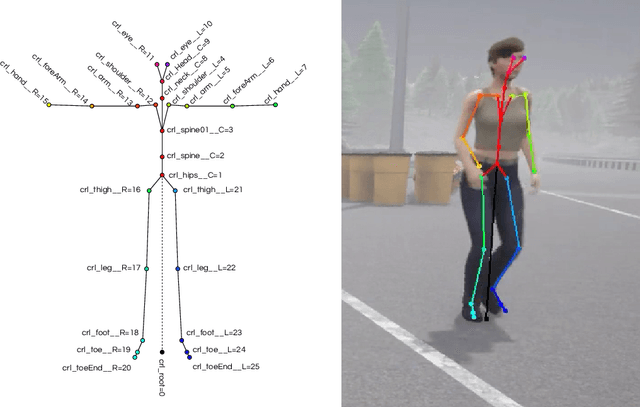
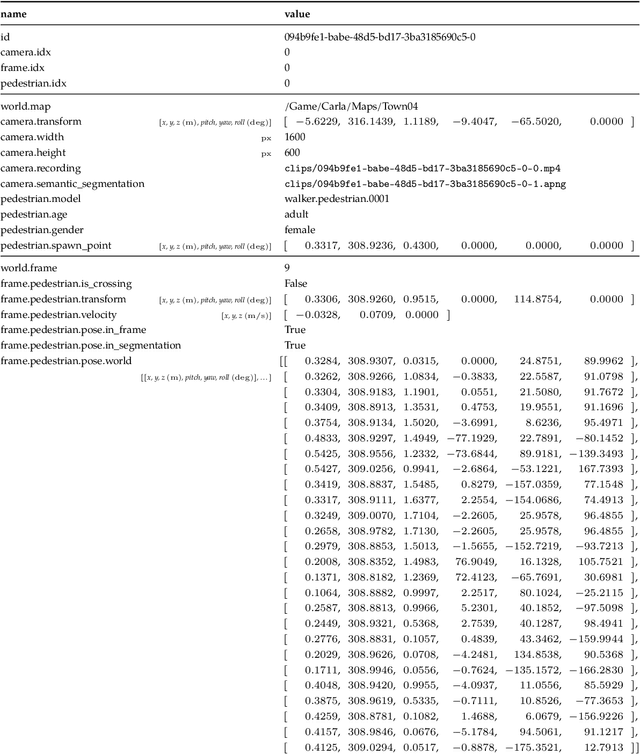
We present a sample dataset featuring pedestrians generated using the ARCANE framework, a new framework for generating datasets in CARLA (0.9.13). We provide use cases for pedestrian detection, autoencoding, pose estimation, and pose lifting. We also showcase baseline results. For more information, visit https://project-arcane.eu/.
Bridging the Domain Gap: Self-Supervised 3D Scene Understanding with Foundation Models
May 16, 2023
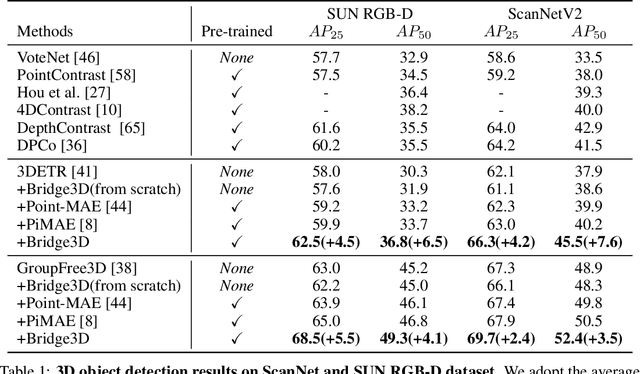
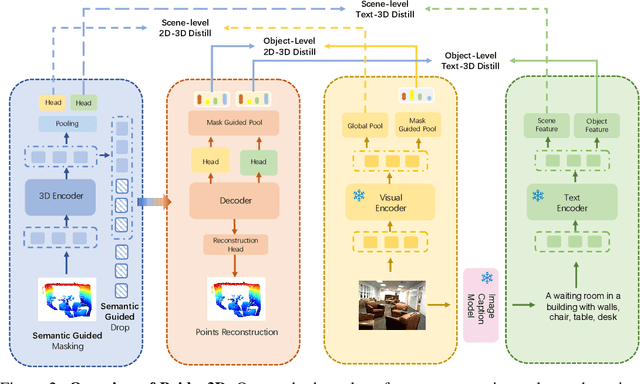
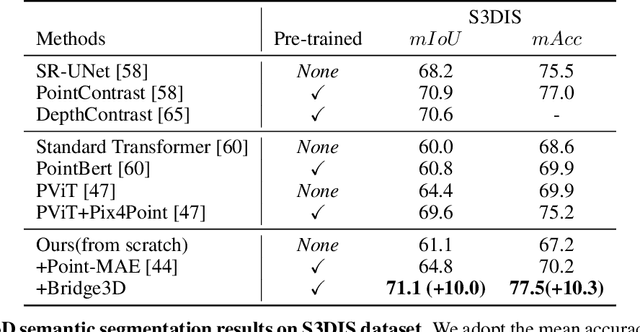
Foundation models have made significant strides in 2D and language tasks such as image segmentation, object detection, and visual-language understanding. Nevertheless, their potential to enhance 3D scene representation learning remains largely untapped due to the domain gap. In this paper, we propose an innovative methodology Bridge3D to address this gap, pre-training 3D models using features, semantic masks, and captions sourced from foundation models. Specifically, our approach utilizes semantic masks from these models to guide the masking and reconstruction process in the masked autoencoder. This strategy enables the network to concentrate more on foreground objects, thereby enhancing 3D representation learning. Additionally, we bridge the 3D-text gap at the scene level by harnessing image captioning foundation models. To further facilitate knowledge distillation from well-learned 2D and text representations to the 3D model, we introduce a novel method that employs foundation models to generate highly accurate object-level masks and semantic text information at the object level. Our approach notably outshines state-of-the-art methods in 3D object detection and semantic segmentation tasks. For instance, on the ScanNet dataset, our method surpasses the previous state-of-the-art method, PiMAE, by a significant margin of 5.3%.
Exploring the Landscape of Machine Unlearning: A Comprehensive Survey and Taxonomy
May 16, 2023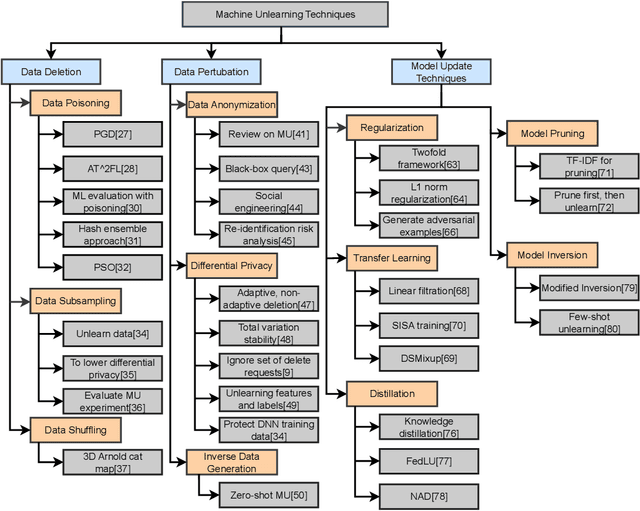
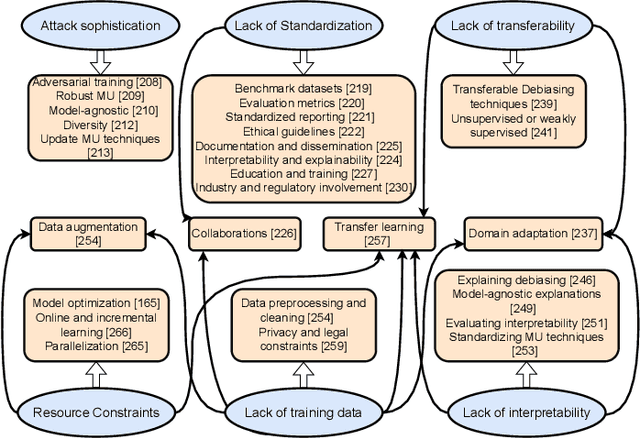

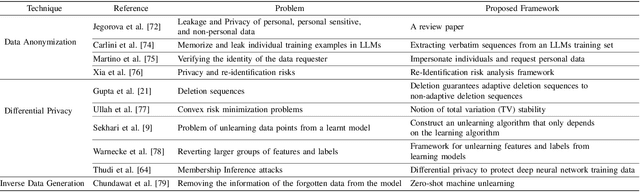
Machine unlearning (MU) is gaining increasing attention due to the need to remove or modify predictions made by machine learning (ML) models. While training models have become more efficient and accurate, the importance of unlearning previously learned information has become increasingly significant in fields such as privacy, security, and fairness. This paper presents a comprehensive survey of MU, covering current state-of-the-art techniques and approaches, including data deletion, perturbation, and model updates. In addition, commonly used metrics and datasets are also presented. The paper also highlights the challenges that need to be addressed, including attack sophistication, standardization, transferability, interpretability, training data, and resource constraints. The contributions of this paper include discussions about the potential benefits of MU and its future directions. Additionally, the paper emphasizes the need for researchers and practitioners to continue exploring and refining unlearning techniques to ensure that ML models can adapt to changing circumstances while maintaining user trust. The importance of unlearning is further highlighted in making Artificial Intelligence (AI) more trustworthy and transparent, especially with the increasing importance of AI in various domains that involve large amounts of personal user data.
Learning Dynamic Point Cloud Compression via Hierarchical Inter-frame Block Matching
May 16, 2023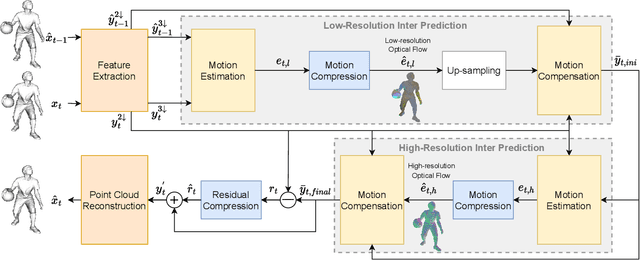
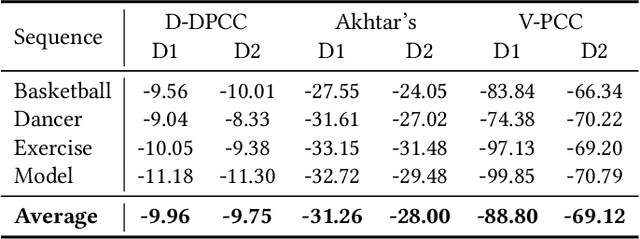
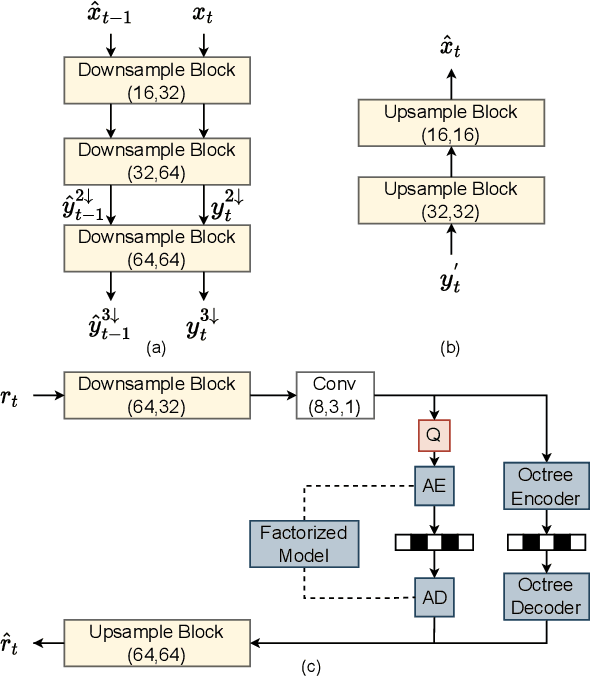
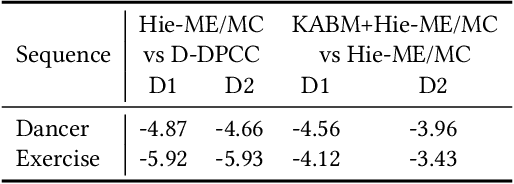
3D dynamic point cloud (DPC) compression relies on mining its temporal context, which faces significant challenges due to DPC's sparsity and non-uniform structure. Existing methods are limited in capturing sufficient temporal dependencies. Therefore, this paper proposes a learning-based DPC compression framework via hierarchical block-matching-based inter-prediction module to compensate and compress the DPC geometry in latent space. Specifically, we propose a hierarchical motion estimation and motion compensation (Hie-ME/MC) framework for flexible inter-prediction, which dynamically selects the granularity of optical flow to encapsulate the motion information accurately. To improve the motion estimation efficiency of the proposed inter-prediction module, we further design a KNN-attention block matching (KABM) network that determines the impact of potential corresponding points based on the geometry and feature correlation. Finally, we compress the residual and the multi-scale optical flow with a fully-factorized deep entropy model. The experiment result on the MPEG-specified Owlii Dynamic Human Dynamic Point Cloud (Owlii) dataset shows that our framework outperforms the previous state-of-the-art methods and the MPEG standard V-PCC v18 in inter-frame low-delay mode.
Growing and Serving Large Open-domain Knowledge Graphs
May 16, 2023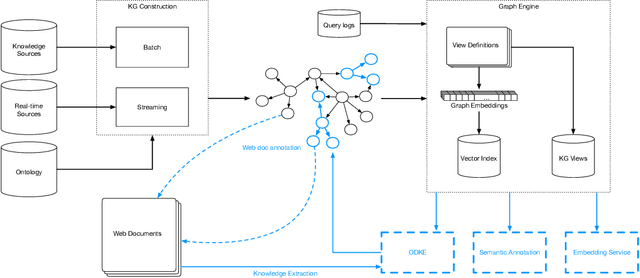
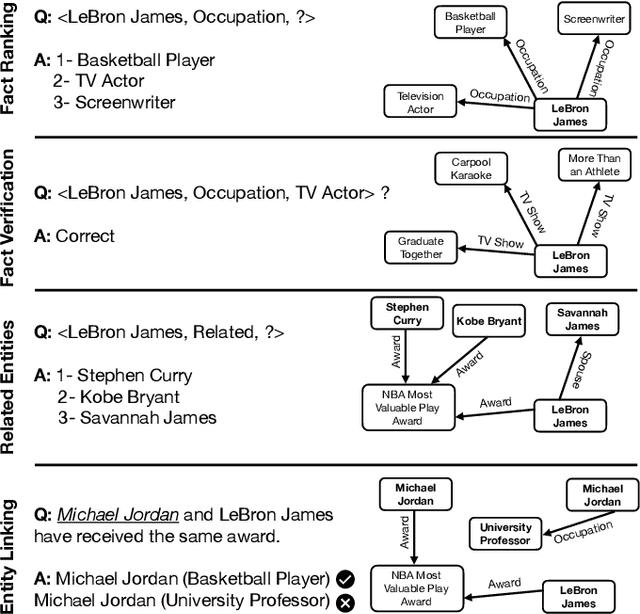
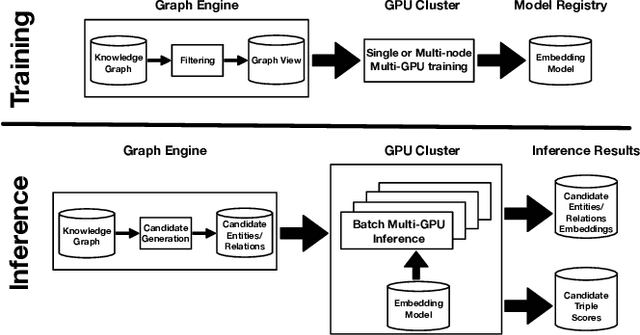
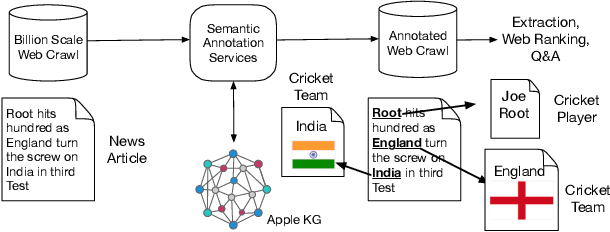
Applications of large open-domain knowledge graphs (KGs) to real-world problems pose many unique challenges. In this paper, we present extensions to Saga our platform for continuous construction and serving of knowledge at scale. In particular, we describe a pipeline for training knowledge graph embeddings that powers key capabilities such as fact ranking, fact verification, a related entities service, and support for entity linking. We then describe how our platform, including graph embeddings, can be leveraged to create a Semantic Annotation service that links unstructured Web documents to entities in our KG. Semantic annotation of the Web effectively expands our knowledge graph with edges to open-domain Web content which can be used in various search and ranking problems. Finally, we leverage annotated Web documents to drive Open-domain Knowledge Extraction. This targeted extraction framework identifies important coverage issues in the KG, then finds relevant data sources for target entities on the Web and extracts missing information to enrich the KG. Finally, we describe adaptations to our knowledge platform needed to construct and serve private personal knowledge on-device. This includes private incremental KG construction, cross-device knowledge sync, and global knowledge enrichment.