 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DNN-Compressed Domain Visual Recognition with Feature Adaptation
May 13, 2023
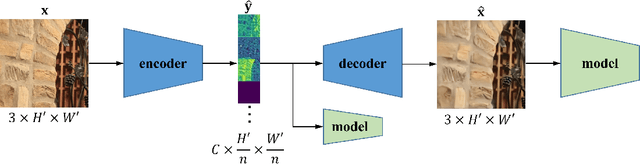
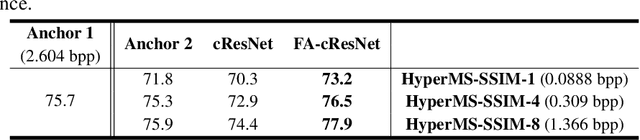
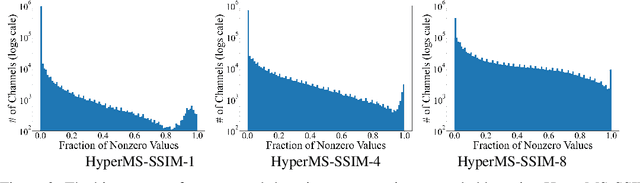

Learning-based image compression was shown to achieve a competitive performance with state-of-the-art transform-based codecs. This motivated the development of new learning-based visual compression standards such as JPEG-AI. Of particular interest to these emerging standards is the development of learning-based image compression systems targeting both humans and machines. This paper is concerned with learning-based compression schemes whose compressed-domain representations can be utilized to perform visual processing and computer vision tasks directly in the compressed domain. In our work, we adopt a learning-based compressed-domain classification framework for performing visual recognition using the compressed-domain latent representation at varying bit-rates. We propose a novel feature adaptation module integrating a lightweight attention model to adaptively emphasize and enhance the key features within the extracted channel-wise information. Also, we design an adaptation training strategy to utilize the pretrained pixel-domain weights. For comparison, in addition to the performance results that are obtained using our proposed latent-based compressed-domain method, we also present performance results using compressed but fully decoded images in the pixel domain as well as original uncompressed images. The obtained performance results show that our proposed compressed-domain classification model can distinctly outperform the existing compressed-domain classification models, and that it can also yield similar accuracy results with a much higher computational efficiency as compared to the pixel-domain models that are trained using fully decoded images.
GSB: Group Superposition Binarization for Vision Transformer with Limited Training Samples
May 13, 2023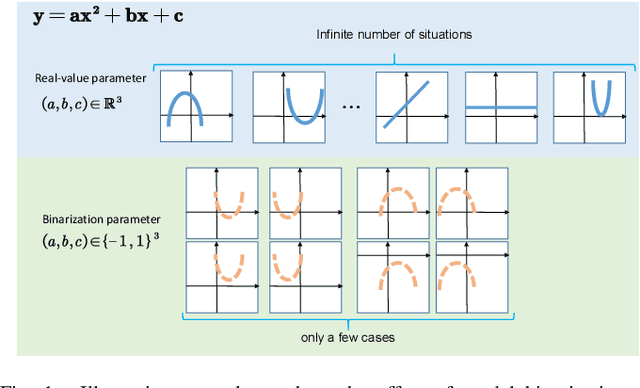
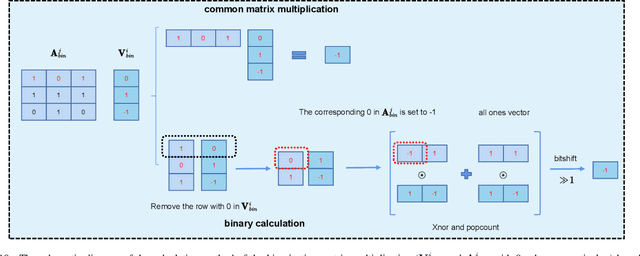
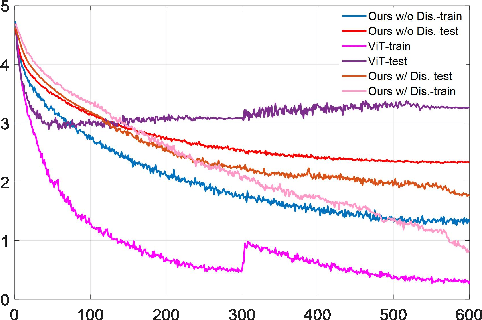
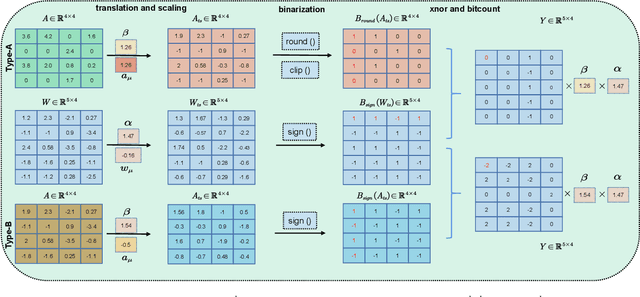
Affected by the massive amount of parameters, ViT usually suffers from serious overfitting problems with a relatively limited number of training samples. In addition, ViT generally demands heavy computing resources, which limit its deployment on resource-constrained devices. As a type of model-compression method,model binarization is potentially a good choice to solve the above problems. Compared with the full-precision one, the model with the binarization method replaces complex tensor multiplication with simple bit-wise binary operations and represents full-precision model parameters and activations with only 1-bit ones, which potentially solves the problem of model size and computational complexity, respectively. In this paper, we find that the decline of the accuracy of the binary ViT model is mainly due to the information loss of the Attention module and the Value vector. Therefore, we propose a novel model binarization technique, called Group Superposition Binarization (GSB), to deal with these issues. Furthermore, in order to further improve the performance of the binarization model, we have investigated the gradient calculation procedure in the binarization process and derived more proper gradient calculation equations for GSB to reduce the influence of gradient mismatch. Then, the knowledge distillation technique is introduced to alleviate the performance degradation caused by model binarization. Experiments on three datasets with limited numbers of training samples demonstrate that the proposed GSB model achieves state-of-the-art performance among the binary quantization schemes and exceeds its full-precision counterpart on some indicators.
Large Language Models in Ambulatory Devices for Home Health Diagnostics: A case study of Sickle Cell Anemia Management
May 05, 2023This study investigates the potential of an ambulatory device that incorporates Large Language Models (LLMs) in cadence with other specialized ML models to assess anemia severity in sickle cell patients in real time. The device would rely on sensor data that measures angiogenic material levels to assess anemia severity, providing real-time information to patients and clinicians to reduce the frequency of vaso-occlusive crises because of the early detection of anemia severity, allowing for timely interventions and potentially reducing the likelihood of serious complications. The main challenges in developing such a device are the creation of a reliable non-invasive tool for angiogenic level assessment, a biophysics model and the practical consideration of an LLM communicating with emergency personnel on behalf of an incapacitated patient. A possible system is proposed, and the limitations of this approach are discussed.
Segmentation of fundus vascular images based on a dual-attention mechanism
May 05, 2023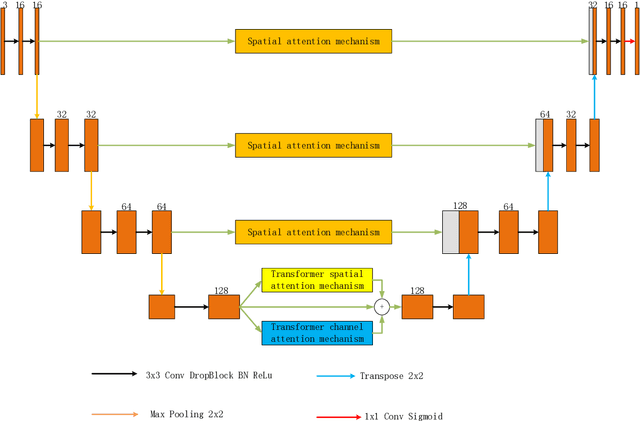
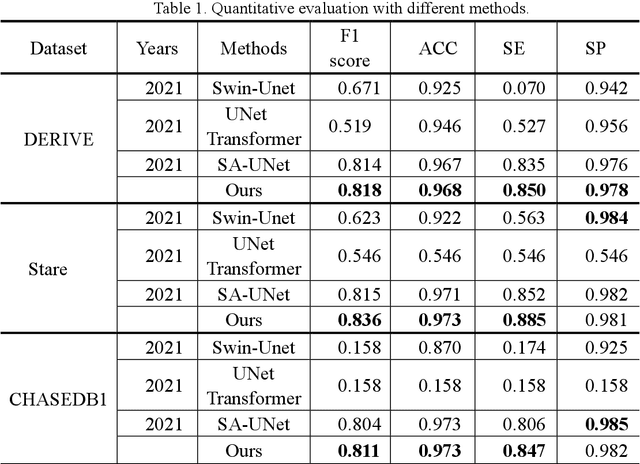
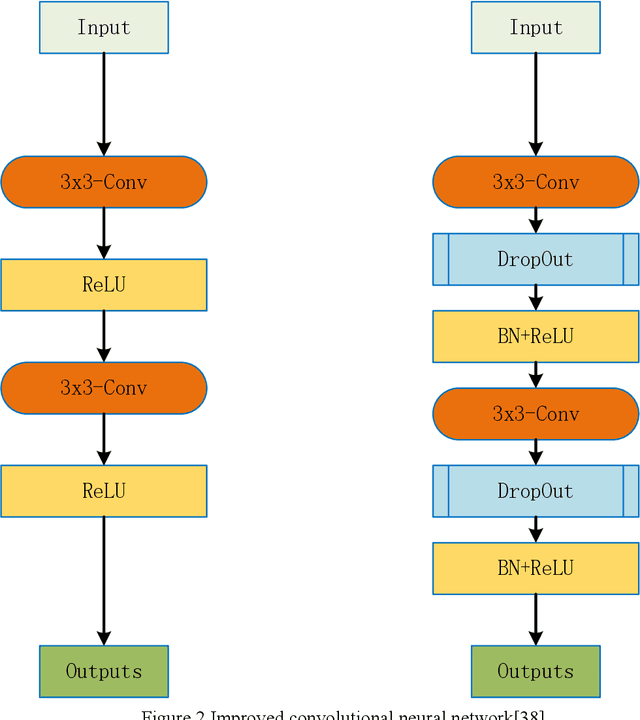
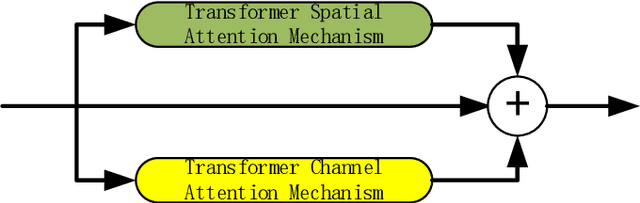
Accurately segmenting blood vessels in retinal fundus images is crucial in the early screening, diagnosing, and evaluating some ocular diseases. However, significant light variations and non-uniform contrast in these images make segmentation quite challenging. Thus, this paper employ an attention fusion mechanism that combines the channel attention and spatial attention mechanisms constructed by Transformer to extract information from retinal fundus images in both spatial and channel dimensions. To eliminate noise from the encoder image, a spatial attention mechanism is introduced in the skip connection. Moreover, a Dropout layer is employed to randomly discard some neurons, which can prevent overfitting of the neural network and improve its generalization performance. Experiments were conducted on publicly available datasets DERIVE, STARE, and CHASEDB1. The results demonstrate that our method produces satisfactory results compared to some recent retinal fundus image segmentation algorithms.
HabitatDyn Dataset: Dynamic Object Detection to Kinematics Estimation
Apr 21, 2023

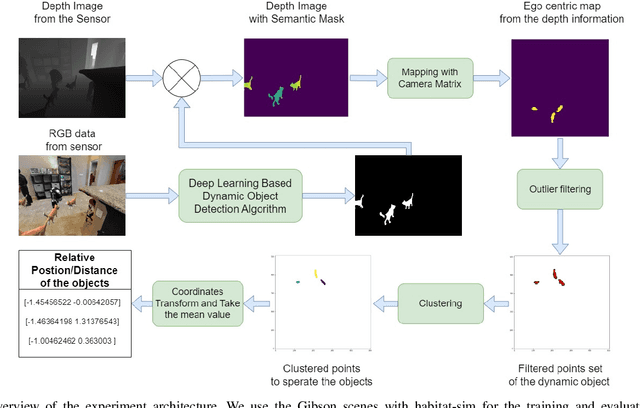
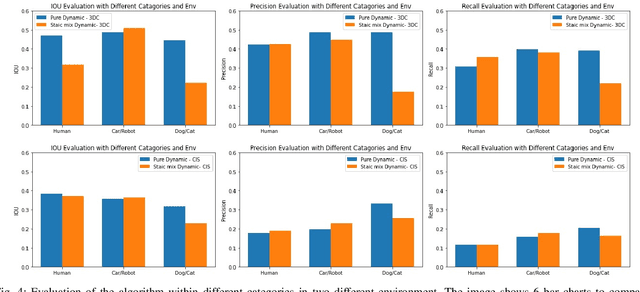
The advancement of computer vision and machine learning has made datasets a crucial element for further research and applications. However, the creation and development of robots with advanced recognition capabilities are hindered by the lack of appropriate datasets. Existing image or video processing datasets are unable to accurately depict observations from a moving robot, and they do not contain the kinematics information necessary for robotic tasks. Synthetic data, on the other hand, are cost-effective to create and offer greater flexibility for adapting to various applications. Hence, they are widely utilized in both research and industry. In this paper, we propose the dataset HabitatDyn, which contains both synthetic RGB videos, semantic labels, and depth information, as well as kinetics information. HabitatDyn was created from the perspective of a mobile robot with a moving camera, and contains 30 scenes featuring six different types of moving objects with varying velocities. To demonstrate the usability of our dataset, two existing algorithms are used for evaluation and an approach to estimate the distance between the object and camera is implemented based on these segmentation methods and evaluated through the dataset. With the availability of this dataset, we aspire to foster further advancements in the field of mobile robotics, leading to more capable and intelligent robots that can navigate and interact with their environments more effectively. The code is publicly available at https://github.com/ignc-research/HabitatDyn.
APR: Online Distant Point Cloud Registration Through Aggregated Point Cloud Reconstruction
May 08, 2023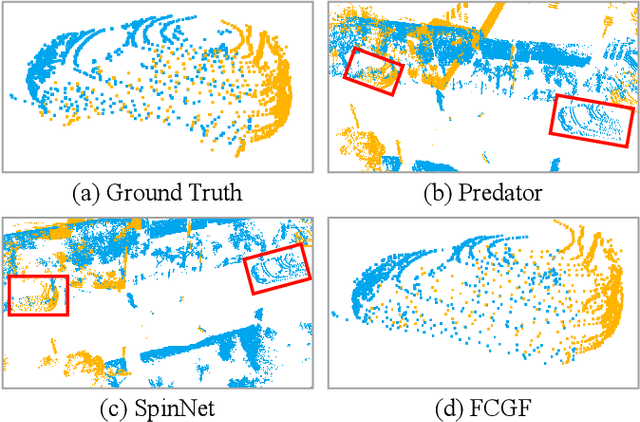
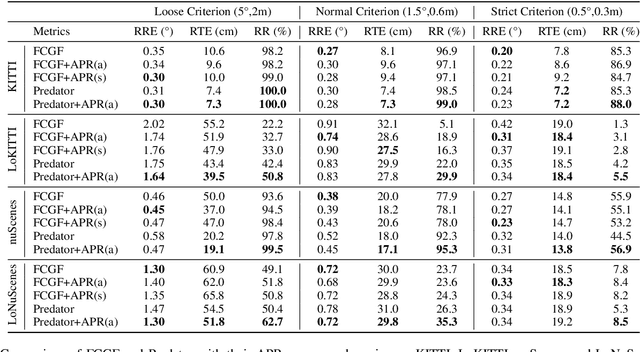
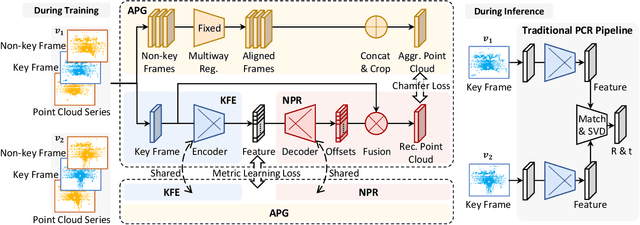
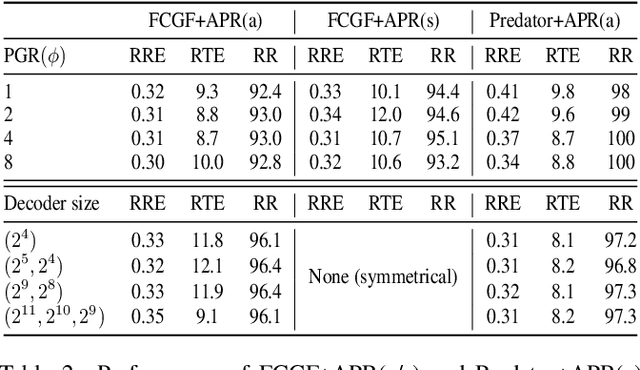
For many driving safety applications, it is of great importance to accurately register LiDAR point clouds generated on distant moving vehicles. However, such point clouds have extremely different point density and sensor perspective on the same object, making registration on such point clouds very hard. In this paper, we propose a novel feature extraction framework, called APR, for online distant point cloud registration. Specifically, APR leverages an autoencoder design, where the autoencoder reconstructs a denser aggregated point cloud with several frames instead of the original single input point cloud. Our design forces the encoder to extract features with rich local geometry information based on one single input point cloud. Such features are then used for online distant point cloud registration. We conduct extensive experiments against state-of-the-art (SOTA) feature extractors on KITTI and nuScenes datasets. Results show that APR outperforms all other extractors by a large margin, increasing average registration recall of SOTA extractors by 7.1% on LoKITTI and 4.6% on LoNuScenes. Code is available at https://github.com/liuQuan98/APR.
SkillQG: Learning to Generate Question for Reading Comprehension Assessment
May 08, 2023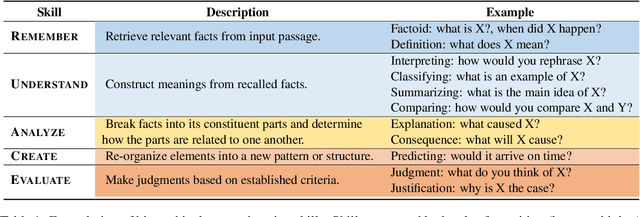
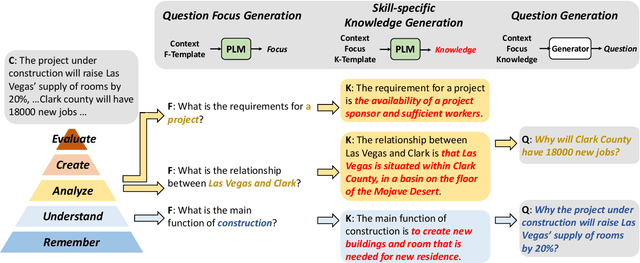
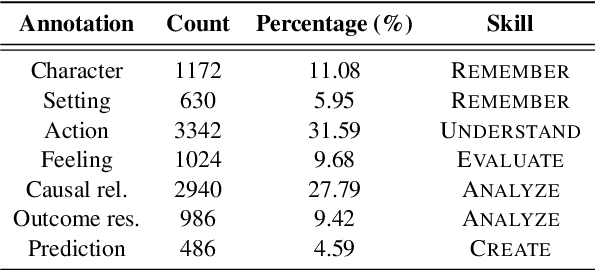
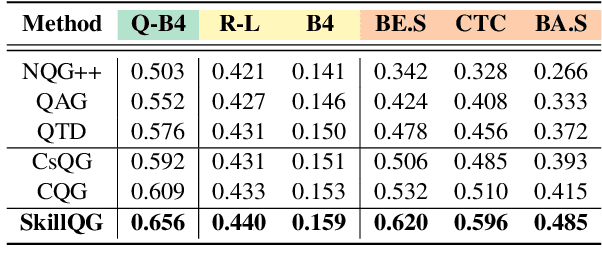
We present $\textbf{$\texttt{SkillQG}$}$: a question generation framework with controllable comprehension types for assessing and improving machine reading comprehension models. Existing question generation systems widely differentiate questions by $\textit{literal}$ information such as question words and answer types to generate semantically relevant questions for a given context. However, they rarely consider the $\textit{comprehension}$ nature of questions, i.e. the different comprehension capabilities embodied by different questions. In comparison, our $\texttt{SkillQG}$ is able to tailor a fine-grained assessment and improvement to the capabilities of question answering models built on it. Specifically, we first frame the comprehension type of questions based on a hierarchical skill-based schema, then formulate $\texttt{SkillQG}$ as a skill-conditioned question generator. Furthermore, to improve the controllability of generation, we augment the input text with question focus and skill-specific knowledge, which are constructed by iteratively prompting the pre-trained language models. Empirical results demonstrate that $\texttt{SkillQG}$ outperforms baselines in terms of quality, relevance, and skill-controllability while showing a promising performance boost in downstream question answering task.
Recognizing Entity Types via Properties
Apr 24, 2023The mainstream approach to the development of ontologies is merging ontologies encoding different information, where one of the major difficulties is that the heterogeneity motivates the ontology merging but also limits high-quality merging performance. Thus, the entity type (etype) recognition task is proposed to deal with such heterogeneity, aiming to infer the class of entities and etypes by exploiting the information encoded in ontologies. In this paper, we introduce a property-based approach that allows recognizing etypes on the basis of the properties used to define them. From an epistemological point of view, it is in fact properties that characterize entities and etypes, and this definition is independent of the specific labels and hierarchical schemas used to define them. The main contribution consists of a set of property-based metrics for measuring the contextual similarity between etypes and entities, and a machine learning-based etype recognition algorithm exploiting the proposed similarity metrics. Compared with the state-of-the-art, the experimental results show the validity of the similarity metrics and the superiority of the proposed etype recognition algorithm.
Towards Generalized Open Information Extraction
Nov 29, 2022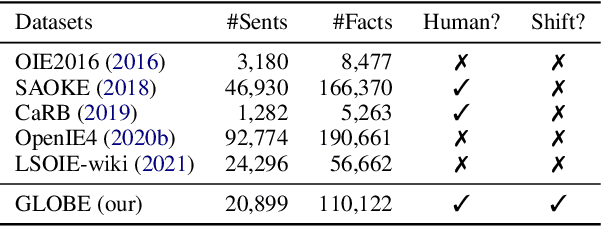
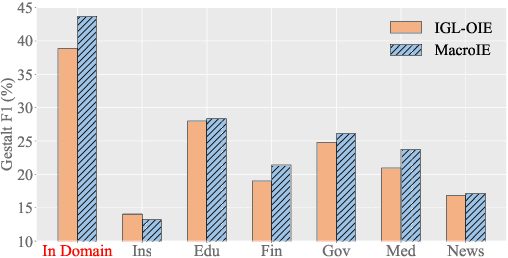
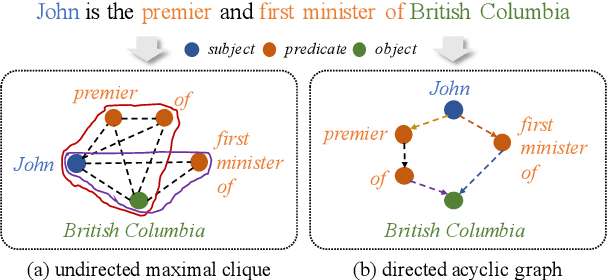
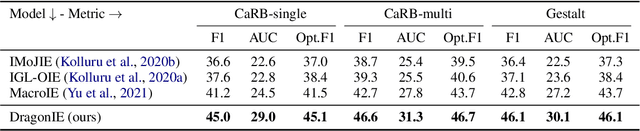
Open Information Extraction (OpenIE) facilitates the open-domain discovery of textual facts. However, the prevailing solutions evaluate OpenIE models on in-domain test sets aside from the training corpus, which certainly violates the initial task principle of domain-independence. In this paper, we propose to advance OpenIE towards a more realistic scenario: generalizing over unseen target domains with different data distributions from the source training domains, termed Generalized OpenIE. For this purpose, we first introduce GLOBE, a large-scale human-annotated multi-domain OpenIE benchmark, to examine the robustness of recent OpenIE models to domain shifts, and the relative performance degradation of up to 70% implies the challenges of generalized OpenIE. Then, we propose DragonIE, which explores a minimalist graph expression of textual fact: directed acyclic graph, to improve the OpenIE generalization. Extensive experiments demonstrate that DragonIE beats the previous methods in both in-domain and out-of-domain settings by as much as 6.0% in F1 score absolutely, but there is still ample room for improvement.
Image Captioners Sometimes Tell More Than Images They See
May 04, 2023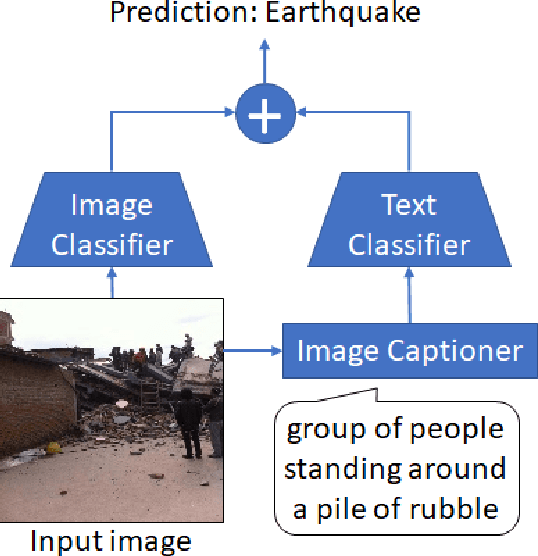
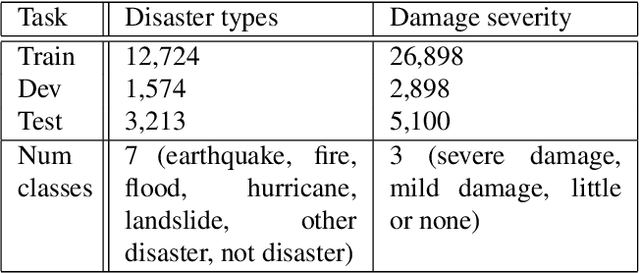

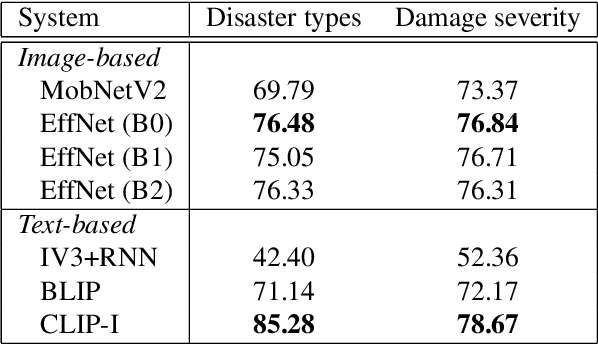
Image captioning, a.k.a. "image-to-text," which generates descriptive text from given images, has been rapidly developing throughout the era of deep learning. To what extent is the information in the original image preserved in the descriptive text generated by an image captioner? To answer that question, we have performed experiments involving the classification of images from descriptive text alone, without referring to the images at all, and compared results with those from standard image-based classifiers. We have evaluate several image captioning models with respect to a disaster image classification task, CrisisNLP, and show that descriptive text classifiers can sometimes achieve higher accuracy than standard image-based classifiers. Further, we show that fusing an image-based classifier with a descriptive text classifier can provide improvement in accuracy.