 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Decadal Temperature Prediction via Chaotic Behavior Tracking
Apr 19, 2023
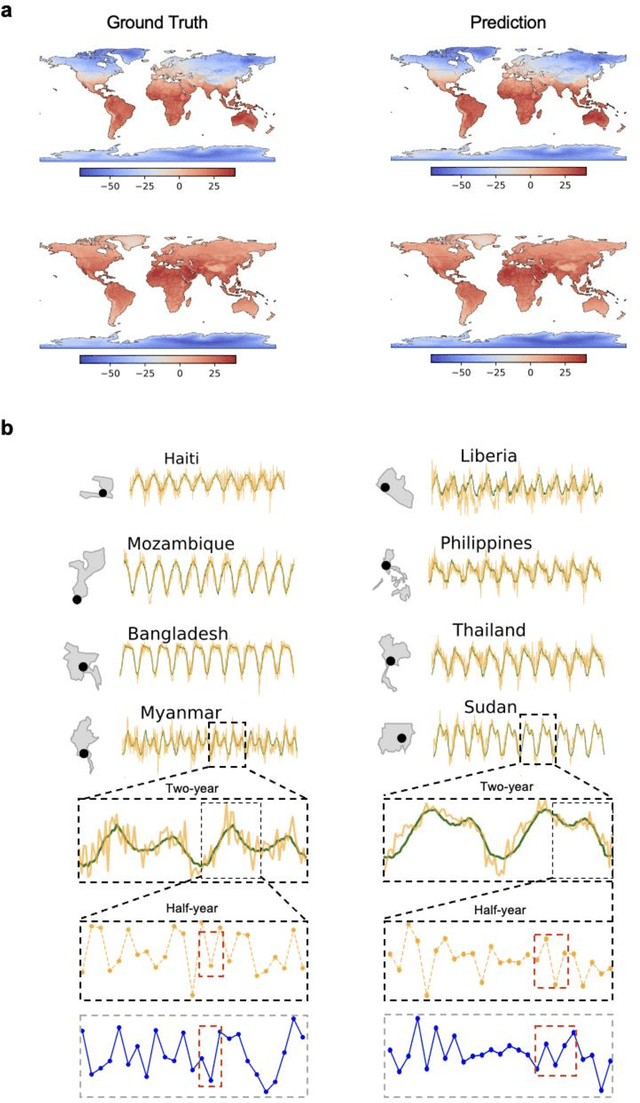
Decadal temperature prediction provides crucial information for quantifying the expected effects of future climate changes and thus informs strategic planning and decision-making in various domains. However, such long-term predictions are extremely challenging, due to the chaotic nature of temperature variations. Moreover, the usefulness of existing simulation-based and machine learning-based methods for this task is limited because initial simulation or prediction errors increase exponentially over time. To address this challenging task, we devise a novel prediction method involving an information tracking mechanism that aims to track and adapt to changes in temperature dynamics during the prediction phase by providing probabilistic feedback on the prediction error of the next step based on the current prediction. We integrate this information tracking mechanism, which can be considered as a model calibrator, into the objective function of our method to obtain the corrections needed to avoid error accumulation. Our results show the ability of our method to accurately predict global land-surface temperatures over a decadal range. Furthermore, we demonstrate that our results are meaningful in a real-world context: the temperatures predicted using our method are consistent with and can be used to explain the well-known teleconnections within and between different continents.
PointCMP: Contrastive Mask Prediction for Self-supervised Learning on Point Cloud Videos
May 06, 2023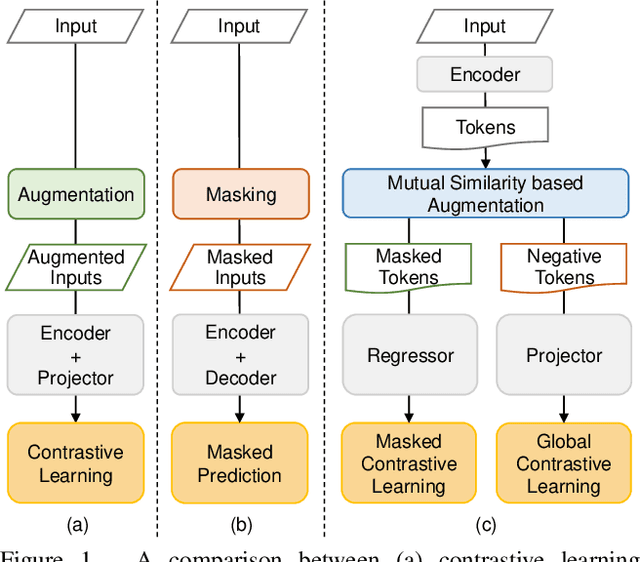
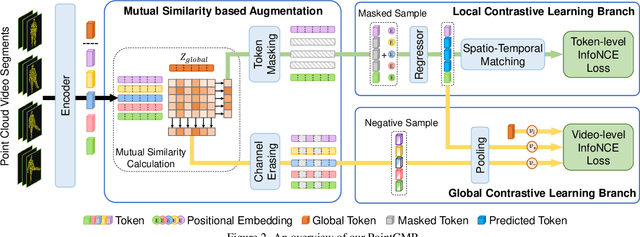

Self-supervised learning can extract representations of good quality from solely unlabeled data, which is appealing for point cloud videos due to their high labelling cost. In this paper, we propose a contrastive mask prediction (PointCMP) framework for self-supervised learning on point cloud videos. Specifically, our PointCMP employs a two-branch structure to achieve simultaneous learning of both local and global spatio-temporal information. On top of this two-branch structure, a mutual similarity based augmentation module is developed to synthesize hard samples at the feature level. By masking dominant tokens and erasing principal channels, we generate hard samples to facilitate learning representations with better discrimination and generalization performance. Extensive experiments show that our PointCMP achieves the state-of-the-art performance on benchmark datasets and outperforms existing full-supervised counterparts. Transfer learning results demonstrate the superiority of the learned representations across different datasets and tasks.
A Minimal Approach for Natural Language Action Space in Text-based Games
May 06, 2023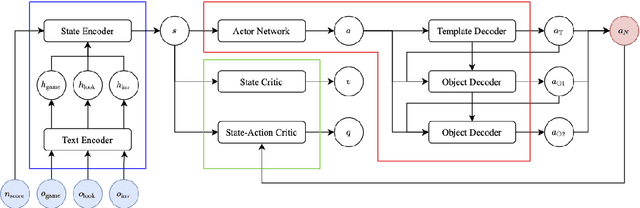
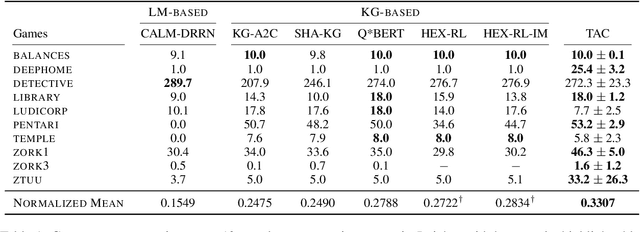


Text-based games (TGs) are language-based interactive environments for reinforcement learning. While language models (LMs) and knowledge graphs (KGs) are commonly used for handling large action space in TGs, it is unclear whether these techniques are necessary or overused. In this paper, we revisit the challenge of exploring the action space in TGs and propose $ \epsilon$-admissible exploration, a minimal approach of utilizing admissible actions, for training phase. Additionally, we present a text-based actor-critic (TAC) agent that produces textual commands for game, solely from game observations, without requiring any KG or LM. Our method, on average across 10 games from Jericho, outperforms strong baselines and state-of-the-art agents that use LM and KG. Our approach highlights that a much lighter model design, with a fresh perspective on utilizing the information within the environments, suffices for an effective exploration of exponentially large action spaces.
Toucha11y: Making Inaccessible Public Touchscreens Accessible
May 06, 2023
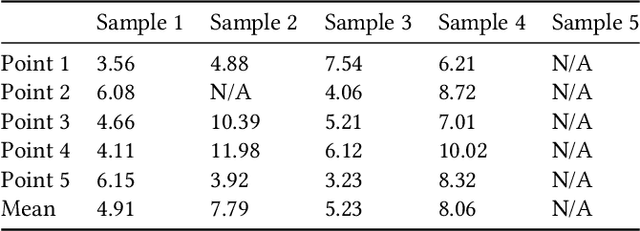
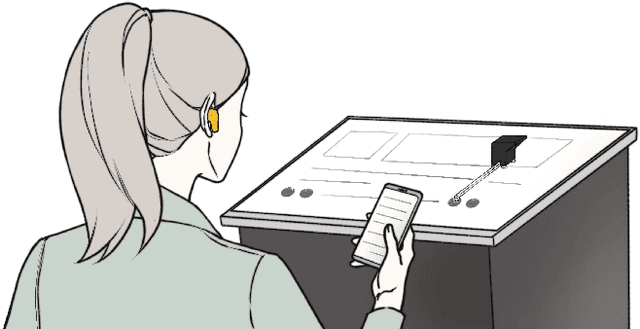
Despite their growing popularity, many public kiosks with touchscreens are inaccessible to blind people. Toucha11y is a working prototype that allows blind users to use existing inaccessible touchscreen kiosks independently and with little effort. Toucha11y consists of a mechanical bot that can be instrumented to an arbitrary touchscreen kiosk by a blind user and a companion app on their smartphone. The bot, once attached to a touchscreen, will recognize its content, retrieve the corresponding information from a database, and render it on the user's smartphone. As a result, a blind person can use the smartphone's built-in accessibility features to access content and make selections. The mechanical bot will detect and activate the corresponding touchscreen interface. We present the system design of Toucha11y along with a series of technical evaluations. Through a user study, we found out that Toucha11y could help blind users operate inaccessible touchscreen devices.
Multi-View MOOC Quality Evaluation via Information-Aware Graph Representation Learning
Jan 01, 2023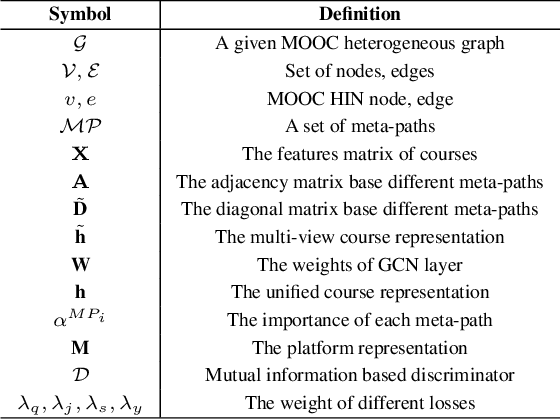
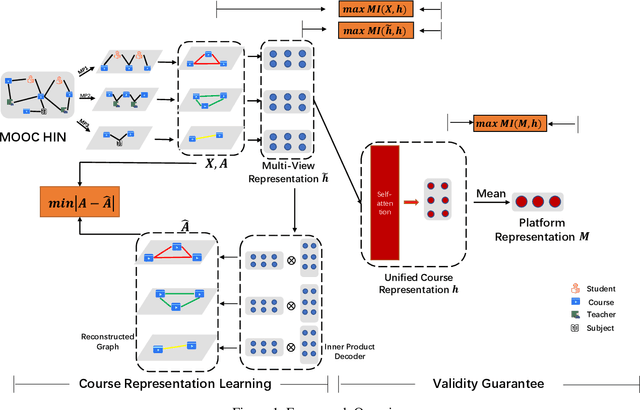

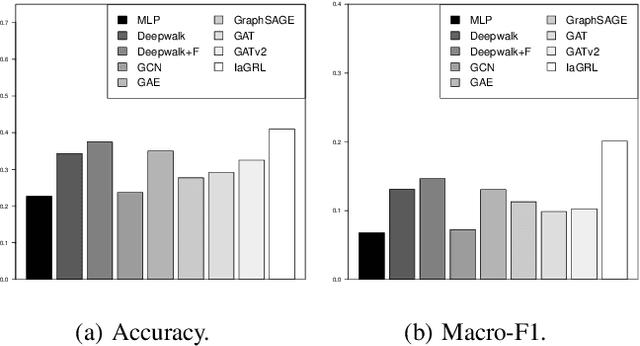
In this paper, we study the problem of MOOC quality evaluation which is essential for improving the course materials, promoting students' learning efficiency, and benefiting user services. While achieving promising performances, current works still suffer from the complicated interactions and relationships of entities in MOOC platforms. To tackle the challenges, we formulate the problem as a course representation learning task-based and develop an Information-aware Graph Representation Learning(IaGRL) for multi-view MOOC quality evaluation. Specifically, We first build a MOOC Heterogeneous Network (HIN) to represent the interactions and relationships among entities in MOOC platforms. And then we decompose the MOOC HIN into multiple single-relation graphs based on meta-paths to depict the multi-view semantics of courses. The course representation learning can be further converted to a multi-view graph representation task. Different from traditional graph representation learning, the learned course representations are expected to match the following three types of validity: (1) the agreement on expressiveness between the raw course portfolio and the learned course representations; (2) the consistency between the representations in each view and the unified representations; (3) the alignment between the course and MOOC platform representations. Therefore, we propose to exploit mutual information for preserving the validity of course representations. We conduct extensive experiments over real-world MOOC datasets to demonstrate the effectiveness of our proposed method.
TIER-A: Denoising Learning Framework for Information Extraction
Nov 13, 2022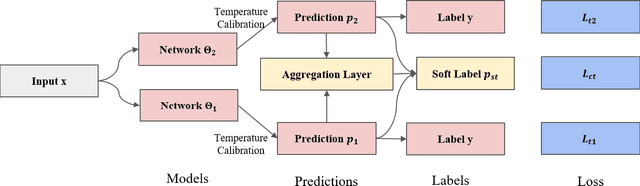

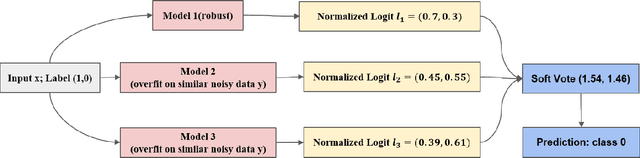
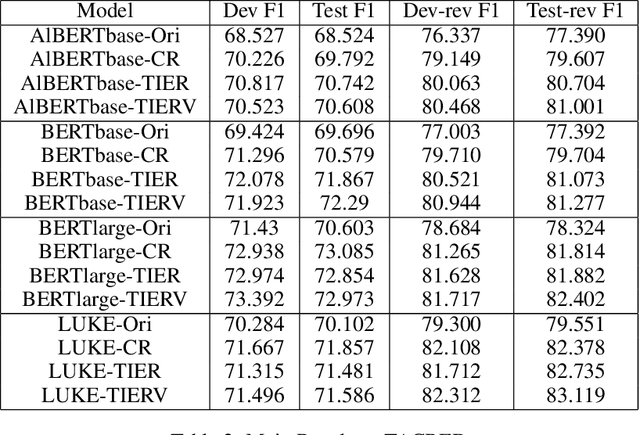
With the development of deep neural language models, great progress has been made in information extraction recently. However, deep learning models often overfit on noisy data points, leading to poor performance. In this work, we examine the role of information entropy in the overfitting process and draw a key insight that overfitting is a process of overconfidence and entropy decreasing. Motivated by such properties, we propose a simple yet effective co-regularization joint-training framework TIER-A, Aggregation Joint-training Framework with Temperature Calibration and Information Entropy Regularization. Our framework consists of several neural models with identical structures. These models are jointly trained and we avoid overfitting by introducing temperature and information entropy regularization. Extensive experiments on two widely-used but noisy datasets, TACRED and CoNLL03, demonstrate the correctness of our assumption and the effectiveness of our framework.
Large Language Models Can Be Used To Effectively Scale Spear Phishing Campaigns
May 12, 2023Recent progress in artificial intelligence (AI), particularly in the domain of large language models (LLMs), has resulted in powerful and versatile dual-use systems. Indeed, cognition can be put towards a wide variety of tasks, some of which can result in harm. This study investigates how LLMs can be used for spear phishing, a form of cybercrime that involves manipulating targets into divulging sensitive information. I first explore LLMs' ability to assist with the reconnaissance and message generation stages of a successful spear phishing attack, where I find that advanced LLMs are capable of improving cybercriminals' efficiency during these stages. To explore how LLMs can be used to scale spear phishing campaigns, I then create unique spear phishing messages for over 600 British Members of Parliament using OpenAI's GPT-3.5 and GPT-4 models. My findings reveal that these messages are not only realistic but also cost-effective, with each email costing only a fraction of a cent to generate. Next, I demonstrate how basic prompt engineering can circumvent safeguards installed in LLMs by the reinforcement learning from human feedback fine-tuning process, highlighting the need for more robust governance interventions aimed at preventing misuse. To address these evolving risks, I propose two potential solutions: structured access schemes, such as application programming interfaces, and LLM-based defensive systems.
Versatile Audio-Visual Learning for Handling Single and Multi Modalities in Emotion Regression and Classification Tasks
May 12, 2023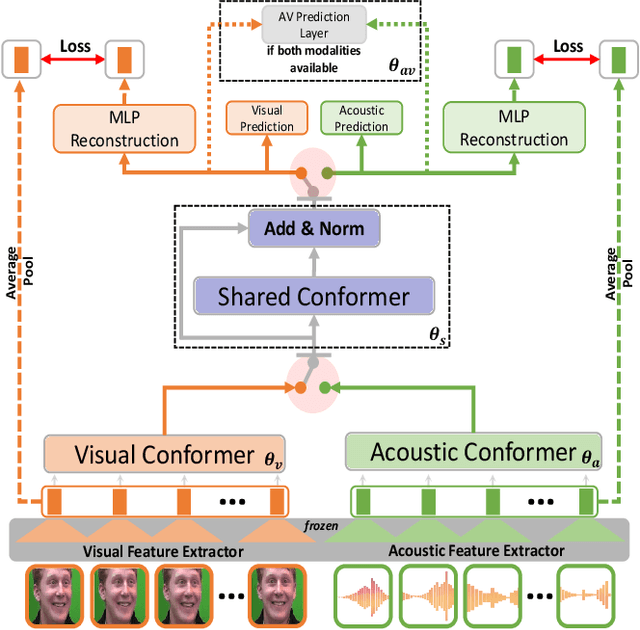
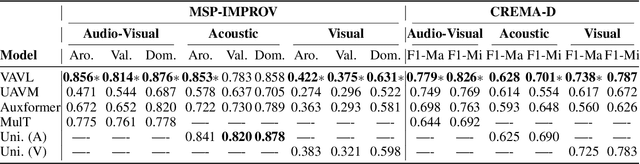
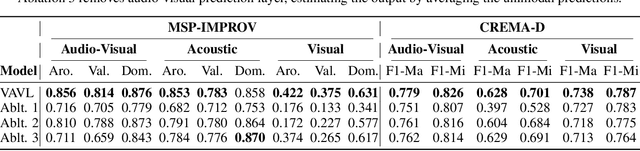
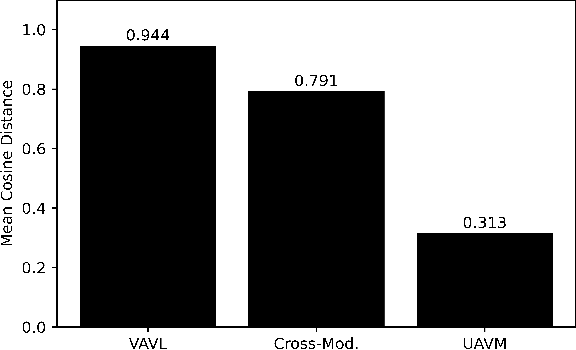
Most current audio-visual emotion recognition models lack the flexibility needed for deployment in practical applications. We envision a multimodal system that works even when only one modality is available and can be implemented interchangeably for either predicting emotional attributes or recognizing categorical emotions. Achieving such flexibility in a multimodal emotion recognition system is difficult due to the inherent challenges in accurately interpreting and integrating varied data sources. It is also a challenge to robustly handle missing or partial information while allowing direct switch between regression and classification tasks. This study proposes a \emph{versatile audio-visual learning} (VAVL) framework for handling unimodal and multimodal systems for emotion regression and emotion classification tasks. We implement an audio-visual framework that can be trained even when audio and visual paired data is not available for part of the training set (i.e., audio only or only video is present). We achieve this effective representation learning with audio-visual shared layers, residual connections over shared layers, and a unimodal reconstruction task. Our experimental results reveal that our architecture significantly outperforms strong baselines on both the CREMA-D and MSP-IMPROV corpora. Notably, VAVL attains a new state-of-the-art performance in the emotional attribute prediction task on the MSP-IMPROV corpus. Code available at: https://github.com/ilucasgoncalves/VAVL
An assessment of measuring local levels of homelessness through proxy social media signals
May 15, 2023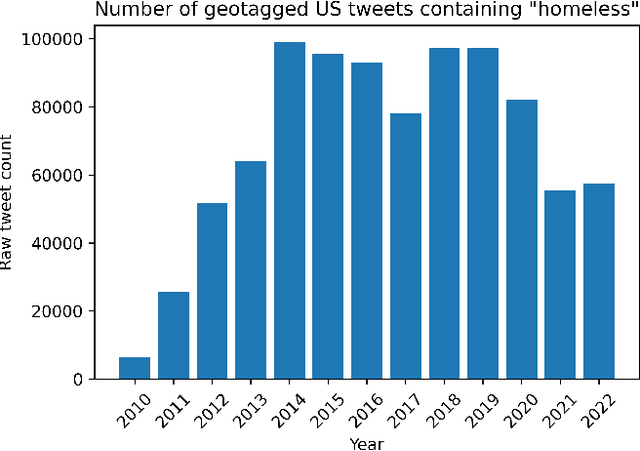
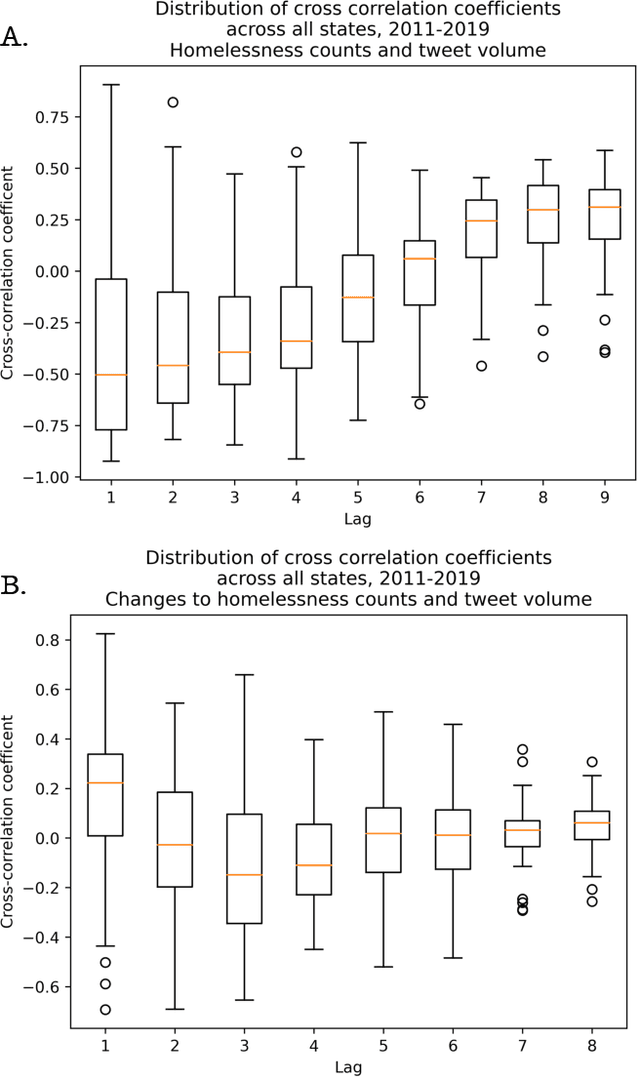
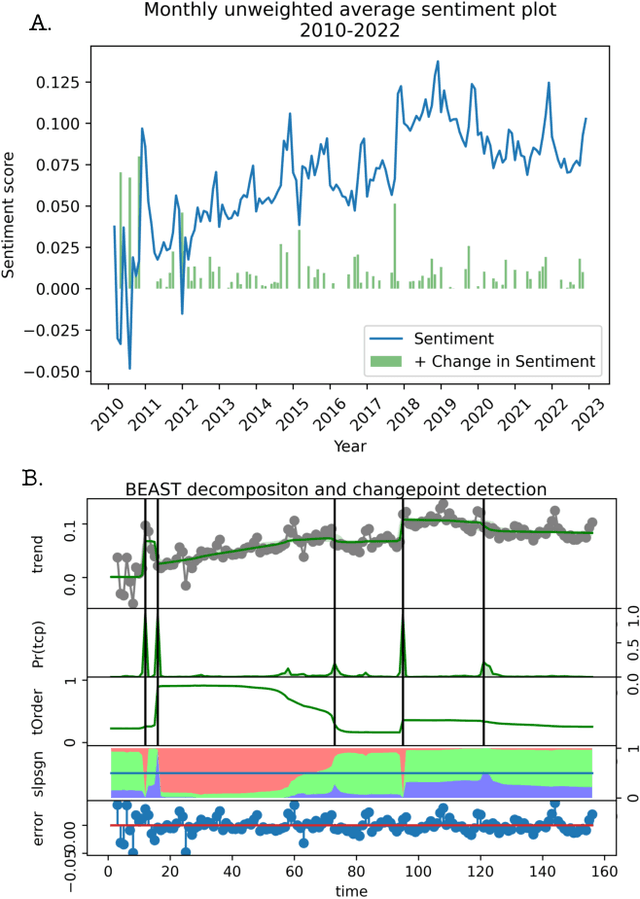
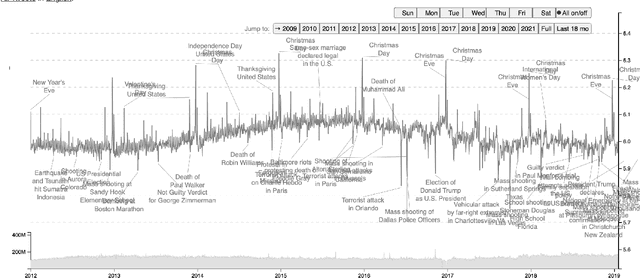
Recent studies suggest social media activity can function as a proxy for measures of state-level public health, detectable through natural language processing. We present results of our efforts to apply this approach to estimate homelessness at the state level throughout the US during the period 2010-2019 and 2022 using a dataset of roughly 1 million geotagged tweets containing the substring ``homeless.'' Correlations between homelessness-related tweet counts and ranked per capita homelessness volume, but not general-population densities, suggest a relationship between the likelihood of Twitter users to personally encounter or observe homelessness in their everyday lives and their likelihood to communicate about it online. An increase to the log-odds of ``homeless'' appearing in an English-language tweet, as well as an acceleration in the increase in average tweet sentiment, suggest that tweets about homelessness are also affected by trends at the nation-scale. Additionally, changes to the lexical content of tweets over time suggest that reversals to the polarity of national or state-level trends may be detectable through an increase in political or service-sector language over the semantics of charity or direct appeals. An analysis of user account type also revealed changes to Twitter-use patterns by accounts authored by individuals versus entities that may provide an additional signal to confirm changes to homelessness density in a given jurisdiction. While a computational approach to social media analysis may provide a low-cost, real-time dataset rich with information about nationwide and localized impacts of homelessness and homelessness policy, we find that practical issues abound, limiting the potential of social media as a proxy to complement other measures of homelessness.
HabitatDyn Dataset: Dynamic Object Detection to Kinematics Estimation
Apr 21, 2023

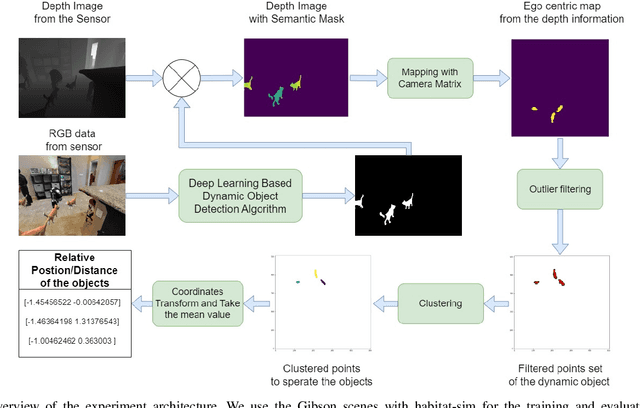
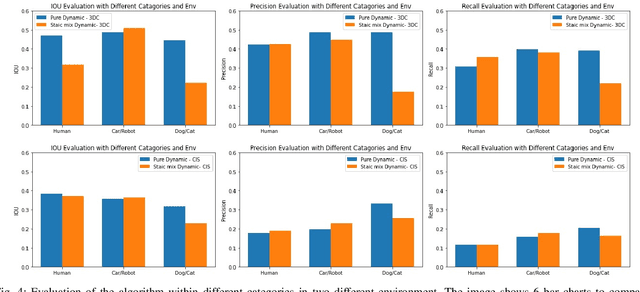
The advancement of computer vision and machine learning has made datasets a crucial element for further research and applications. However, the creation and development of robots with advanced recognition capabilities are hindered by the lack of appropriate datasets. Existing image or video processing datasets are unable to accurately depict observations from a moving robot, and they do not contain the kinematics information necessary for robotic tasks. Synthetic data, on the other hand, are cost-effective to create and offer greater flexibility for adapting to various applications. Hence, they are widely utilized in both research and industry. In this paper, we propose the dataset HabitatDyn, which contains both synthetic RGB videos, semantic labels, and depth information, as well as kinetics information. HabitatDyn was created from the perspective of a mobile robot with a moving camera, and contains 30 scenes featuring six different types of moving objects with varying velocities. To demonstrate the usability of our dataset, two existing algorithms are used for evaluation and an approach to estimate the distance between the object and camera is implemented based on these segmentation methods and evaluated through the dataset. With the availability of this dataset, we aspire to foster further advancements in the field of mobile robotics, leading to more capable and intelligent robots that can navigate and interact with their environments more effectively. The code is publicly available at https://github.com/ignc-research/HabitatDyn.