 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cross-View Hierarchy Network for Stereo Image Super-Resolution
Apr 13, 2023
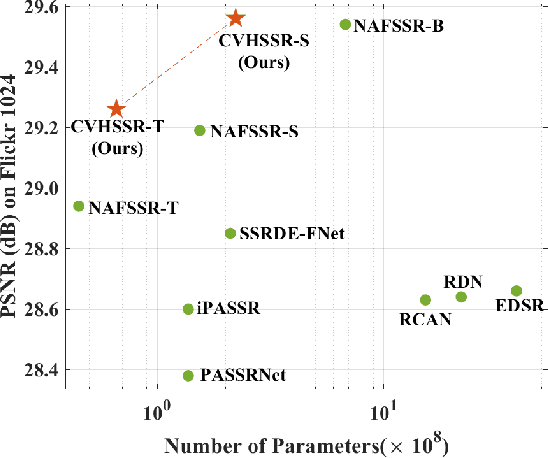
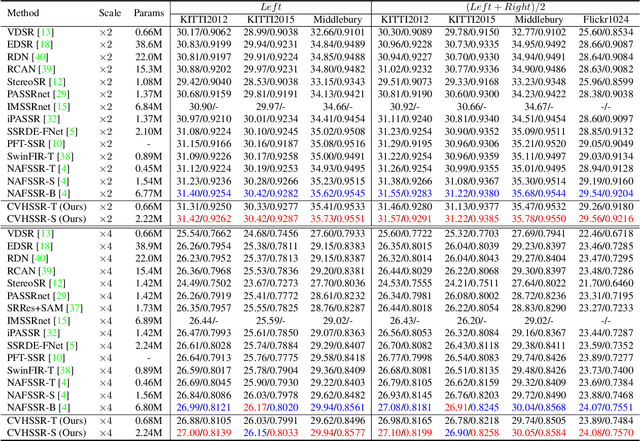
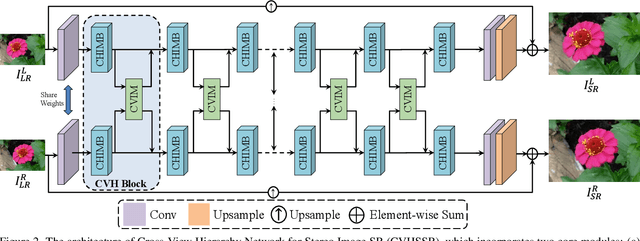
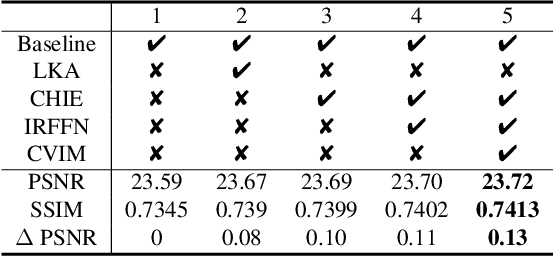
Stereo image super-resolution aims to improve the quality of high-resolution stereo image pairs by exploiting complementary information across views. To attain superior performance, many methods have prioritized designing complex modules to fuse similar information across views, yet overlooking the importance of intra-view information for high-resolution reconstruction. It also leads to problems of wrong texture in recovered images. To address this issue, we explore the interdependencies between various hierarchies from intra-view and propose a novel method, named Cross-View-Hierarchy Network for Stereo Image Super-Resolution (CVHSSR). Specifically, we design a cross-hierarchy information mining block (CHIMB) that leverages channel attention and large kernel convolution attention to extract both global and local features from the intra-view, enabling the efficient restoration of accurate texture details. Additionally, a cross-view interaction module (CVIM) is proposed to fuse similar features from different views by utilizing cross-view attention mechanisms, effectively adapting to the binocular scene. Extensive experiments demonstrate the effectiveness of our method. CVHSSR achieves the best stereo image super-resolution performance than other state-of-the-art methods while using fewer parameters. The source code and pre-trained models are available at https://github.com/AlexZou14/CVHSSR.
Personalized Federated Learning via Gradient Modulation for Heterogeneous Text Summarization
Apr 23, 2023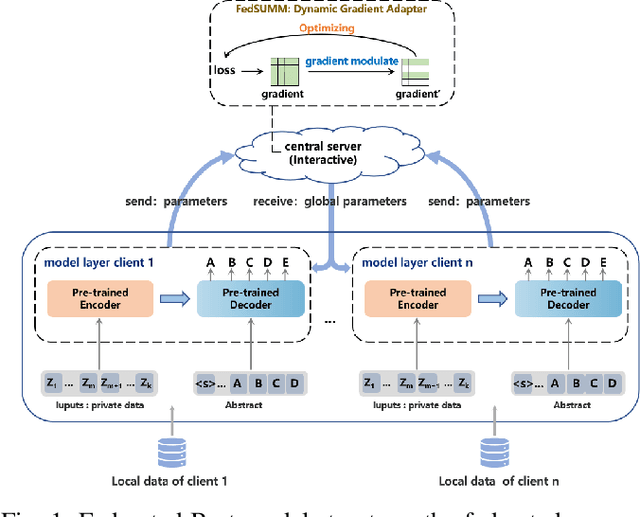
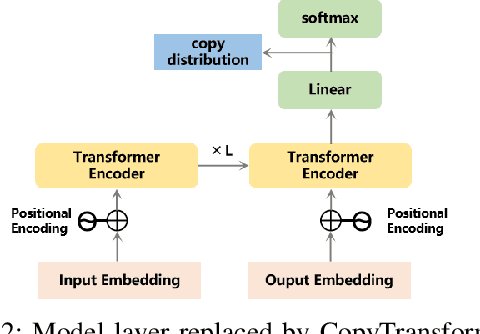
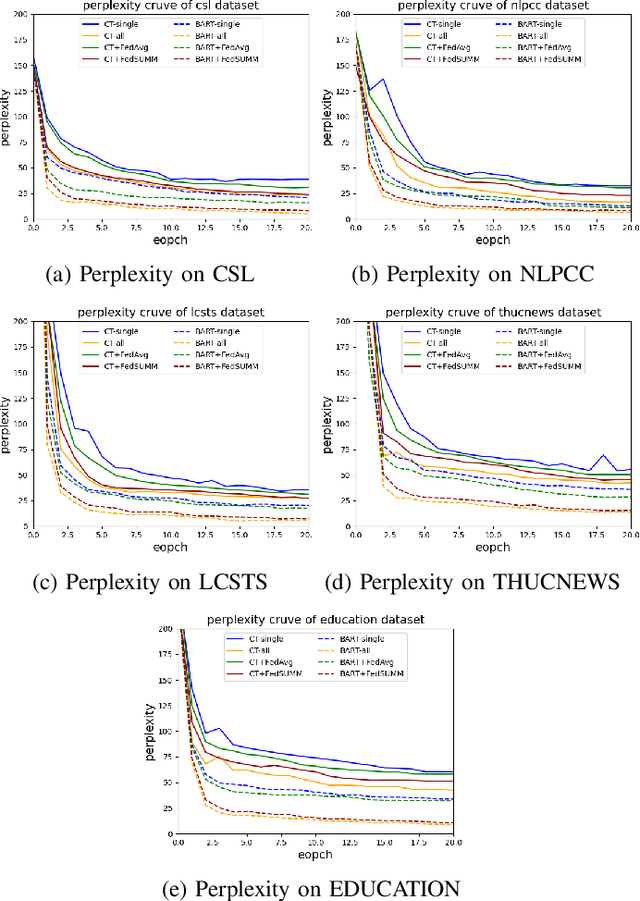
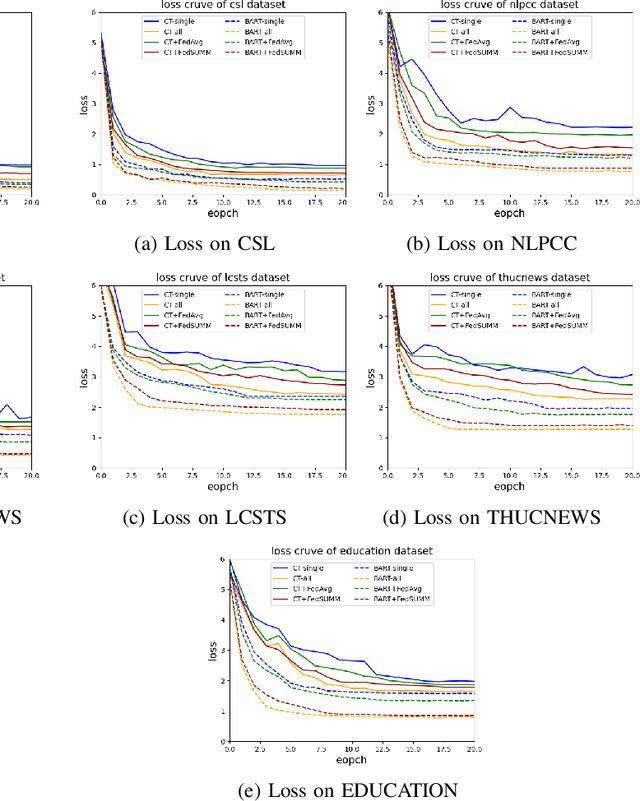
Text summarization is essential for information aggregation and demands large amounts of training data. However, concerns about data privacy and security limit data collection and model training. To eliminate this concern, we propose a federated learning text summarization scheme, which allows users to share the global model in a cooperative learning manner without sharing raw data. Personalized federated learning (PFL) balances personalization and generalization in the process of optimizing the global model, to guide the training of local models. However, multiple local data have different distributions of semantics and context, which may cause the local model to learn deviated semantic and context information. In this paper, we propose FedSUMM, a dynamic gradient adapter to provide more appropriate local parameters for local model. Simultaneously, FedSUMM uses differential privacy to prevent parameter leakage during distributed training. Experimental evidence verifies FedSUMM can achieve faster model convergence on PFL algorithm for task-specific text summarization, and the method achieves superior performance for different optimization metrics for text summarization.
IslamicPCQA: A Dataset for Persian Multi-hop Complex Question Answering in Islamic Text Resources
Apr 23, 2023Nowadays, one of the main challenges for Question Answering Systems is to answer complex questions using various sources of information. Multi-hop questions are a type of complex questions that require multi-step reasoning to answer. In this article, the IslamicPCQA dataset is introduced. This is the first Persian dataset for answering complex questions based on non-structured information sources and consists of 12,282 question-answer pairs extracted from 9 Islamic encyclopedias. This dataset has been created inspired by the HotpotQA English dataset approach, which was customized to suit the complexities of the Persian language. Answering questions in this dataset requires more than one paragraph and reasoning. The questions are not limited to any prior knowledge base or ontology, and to provide robust reasoning ability, the dataset also includes supporting facts and key sentences. The prepared dataset covers a wide range of Islamic topics and aims to facilitate answering complex Persian questions within this subject matter
A Byte Sequence is Worth an Image: CNN for File Fragment Classification Using Bit Shift and n-Gram Embeddings
Apr 14, 2023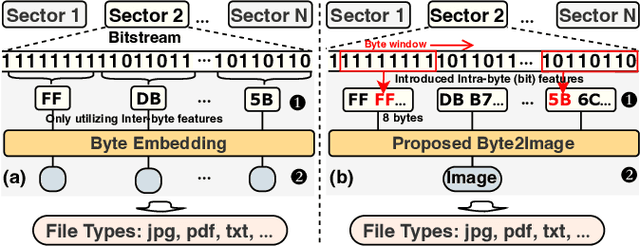
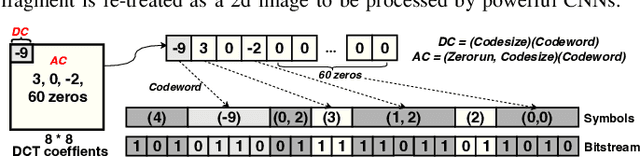
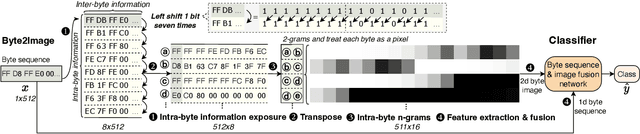
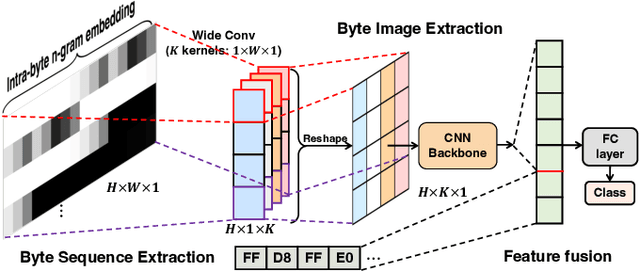
File fragment classification (FFC) on small chunks of memory is essential in memory forensics and Internet security. Existing methods mainly treat file fragments as 1d byte signals and utilize the captured inter-byte features for classification, while the bit information within bytes, i.e., intra-byte information, is seldom considered. This is inherently inapt for classifying variable-length coding files whose symbols are represented as the variable number of bits. Conversely, we propose Byte2Image, a novel data augmentation technique, to introduce the neglected intra-byte information into file fragments and re-treat them as 2d gray-scale images, which allows us to capture both inter-byte and intra-byte correlations simultaneously through powerful convolutional neural networks (CNNs). Specifically, to convert file fragments to 2d images, we employ a sliding byte window to expose the neglected intra-byte information and stack their n-gram features row by row. We further propose a byte sequence \& image fusion network as a classifier, which can jointly model the raw 1d byte sequence and the converted 2d image to perform FFC. Experiments on FFT-75 dataset validate that our proposed method can achieve notable accuracy improvements over state-of-the-art methods in nearly all scenarios. The code will be released at https://github.com/wenyang001/Byte2Image.
Multi-Prompt with Depth Partitioned Cross-Modal Learning
May 10, 2023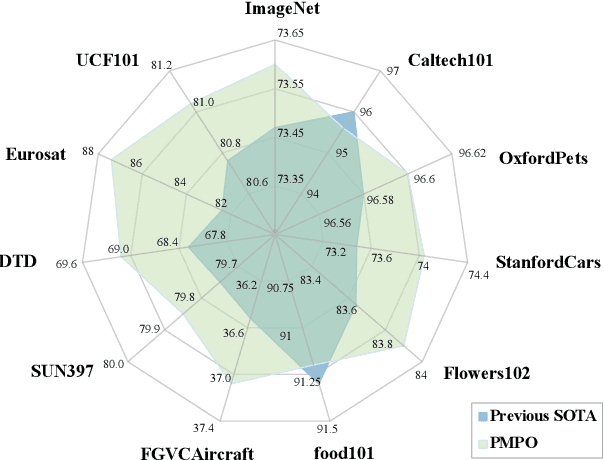
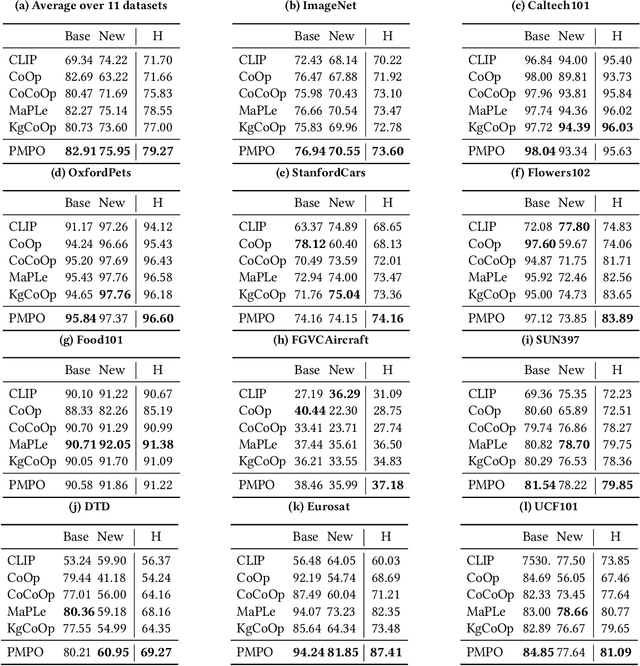

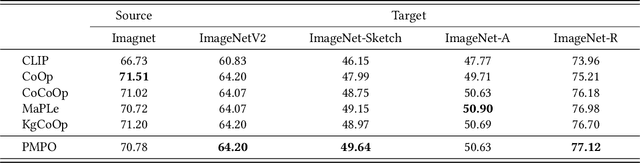
In recent years, soft prompt learning methods have been proposed to fine-tune large-scale vision-language pre-trained models for various downstream tasks. These methods typically combine learnable textual tokens with class tokens as input for models with frozen parameters. However, they often employ a single prompt to describe class contexts, failing to capture categories' diverse attributes adequately. This study introduces the Partitioned Multi-modal Prompt (PMPO), a multi-modal prompting technique that extends the soft prompt from a single learnable prompt to multiple prompts. Our method divides the visual encoder depths and connects learnable prompts to the separated visual depths, enabling different prompts to capture the hierarchical contextual depths of visual representations. Furthermore, to maximize the advantages of multi-prompt learning, we incorporate prior information from manually designed templates and learnable multi-prompts, thus improving the generalization capabilities of our approach. We evaluate the effectiveness of our approach on three challenging tasks: new class generalization, cross-dataset evaluation, and domain generalization. For instance, our method achieves a $79.28$ harmonic mean, averaged over 11 diverse image recognition datasets ($+7.62$ compared to CoOp), demonstrating significant competitiveness compared to state-of-the-art prompting methods.
Waterberry Farms: A Novel Benchmark For Informative Path Planning
May 10, 2023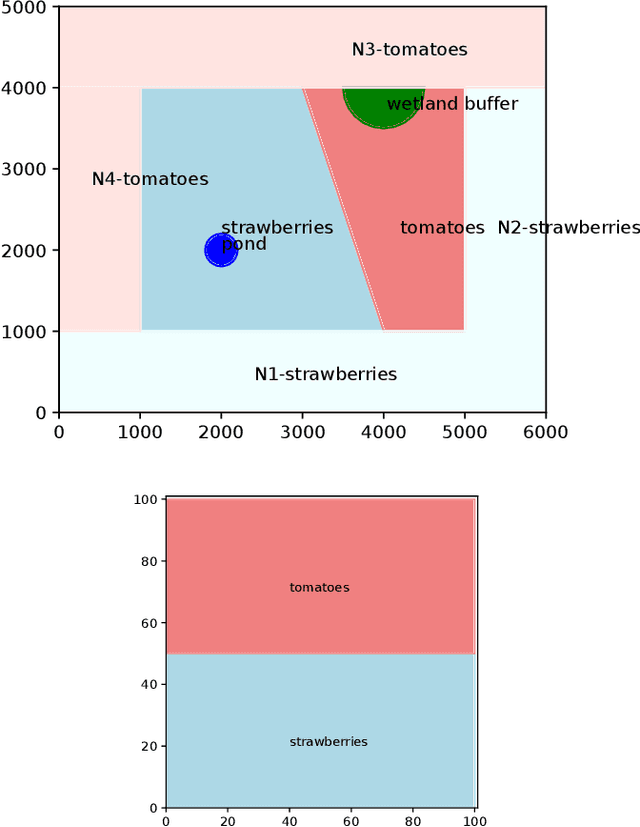
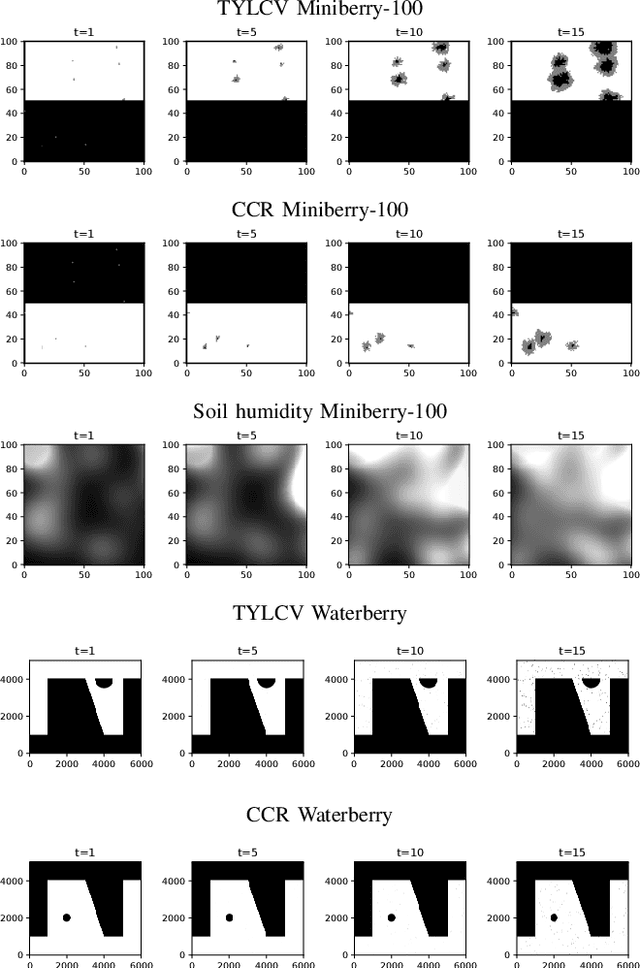

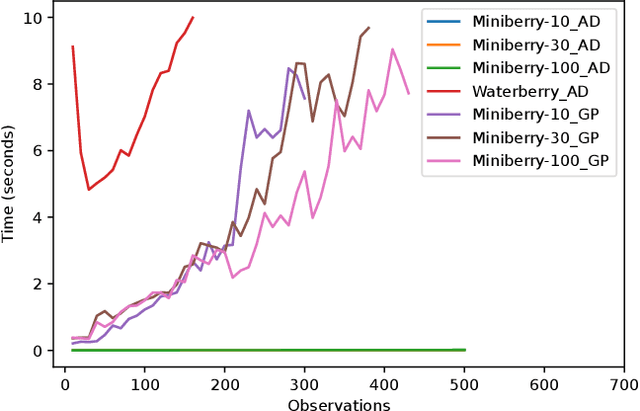
Recent developments in robotic and sensor hardware make data collection with mobile robots (ground or aerial) feasible and affordable to a wide population of users. The newly emergent applications, such as precision agriculture, weather damage assessment, or personal home security often do not satisfy the simplifying assumptions made by previous research: the explored areas have complex shapes and obstacles, multiple phenomena need to be sensed and estimated simultaneously and the measured quantities might change during observations. The future progress of path planning and estimation algorithms requires a new generation of benchmarks that provide representative environments and scoring methods that capture the demands of these applications. This paper describes the Waterberry Farms benchmark (WBF) that models a precision agriculture application at a Florida farm growing multiple crop types. The benchmark captures the dynamic nature of the spread of plant diseases and variations of soil humidity while the scoring system measures the performance of a given combination of a movement policy and an information model estimator. By benchmarking several examples of representative path planning and estimator algorithms, we demonstrate WBF's ability to provide insight into their properties and quantify future progress.
q2d: Turning Questions into Dialogs to Teach Models How to Search
Apr 27, 2023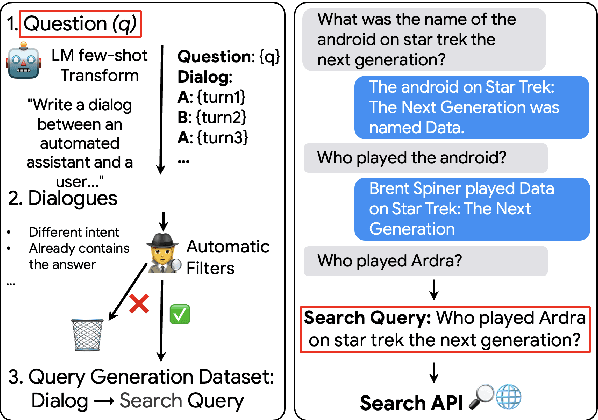


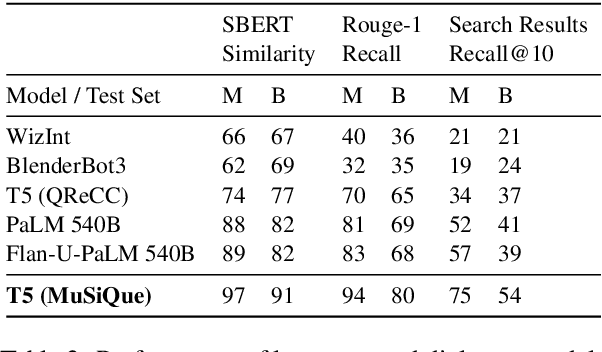
One of the exciting capabilities of recent language models for dialog is their ability to independently search for relevant information to ground a given dialog response. However, obtaining training data to teach models how to issue search queries is time and resource consuming. In this work, we propose q2d: an automatic data generation pipeline that generates information-seeking dialogs from questions. We prompt a large language model (PaLM) to create conversational versions of question answering datasets, and use it to improve query generation models that communicate with external search APIs to ground dialog responses. Unlike previous approaches which relied on human written dialogs with search queries, our method allows to automatically generate query-based grounded dialogs with better control and scale. Our experiments demonstrate that: (1) For query generation on the QReCC dataset, models trained on our synthetically-generated data achieve 90%--97% of the performance of models trained on the human-generated data; (2) We can successfully generate data for training dialog models in new domains without any existing dialog data as demonstrated on the multi-hop MuSiQue and Bamboogle QA datasets. (3) We perform a thorough analysis of the generated dialogs showing that humans find them of high quality and struggle to distinguish them from human-written dialogs.
Controllable One-Shot Face Video Synthesis With Semantic Aware Prior
Apr 27, 2023
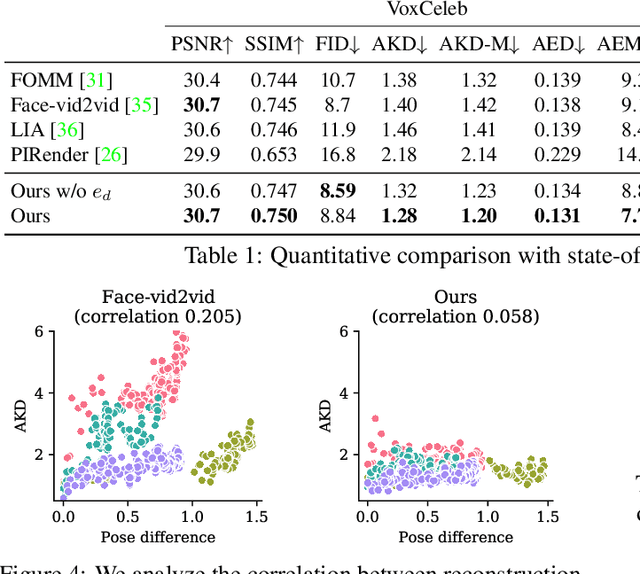
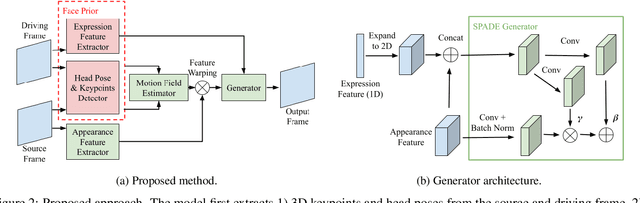
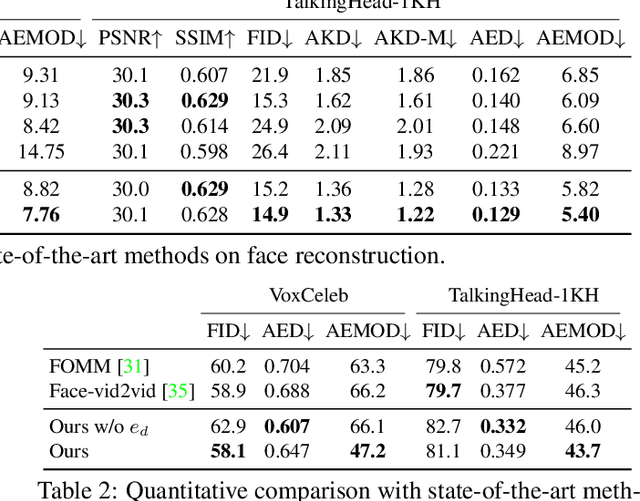
The one-shot talking-head synthesis task aims to animate a source image to another pose and expression, which is dictated by a driving frame. Recent methods rely on warping the appearance feature extracted from the source, by using motion fields estimated from the sparse keypoints, that are learned in an unsupervised manner. Due to their lightweight formulation, they are suitable for video conferencing with reduced bandwidth. However, based on our study, current methods suffer from two major limitations: 1) unsatisfactory generation quality in the case of large head poses and the existence of observable pose misalignment between the source and the first frame in driving videos. 2) fail to capture fine yet critical face motion details due to the lack of semantic understanding and appropriate face geometry regularization. To address these shortcomings, we propose a novel method that leverages the rich face prior information, the proposed model can generate face videos with improved semantic consistency (improve baseline by $7\%$ in average keypoint distance) and expression-preserving (outperform baseline by $15 \%$ in average emotion embedding distance) under equivalent bandwidth. Additionally, incorporating such prior information provides us with a convenient interface to achieve highly controllable generation in terms of both pose and expression.
Multi-scale Adaptive Fusion Network for Hyperspectral Image Denoising
Apr 19, 2023

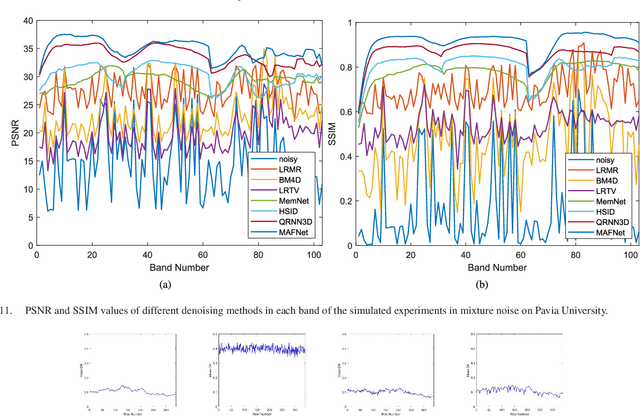
Removing the noise and improving the visual quality of hyperspectral images (HSIs) is challenging in academia and industry. Great efforts have been made to leverage local, global or spectral context information for HSI denoising. However, existing methods still have limitations in feature interaction exploitation among multiple scales and rich spectral structure preservation. In view of this, we propose a novel solution to investigate the HSI denoising using a Multi-scale Adaptive Fusion Network (MAFNet), which can learn the complex nonlinear mapping between clean and noisy HSI. Two key components contribute to improving the hyperspectral image denoising: A progressively multiscale information aggregation network and a co-attention fusion module. Specifically, we first generate a set of multiscale images and feed them into a coarse-fusion network to exploit the contextual texture correlation. Thereafter, a fine fusion network is followed to exchange the information across the parallel multiscale subnetworks. Furthermore, we design a co-attention fusion module to adaptively emphasize informative features from different scales, and thereby enhance the discriminative learning capability for denoising. Extensive experiments on synthetic and real HSI datasets demonstrate that the proposed MAFNet has achieved better denoising performance than other state-of-the-art techniques. Our codes are available at \verb'https://github.com/summitgao/MAFNet'.
Decadal Temperature Prediction via Chaotic Behavior Tracking
Apr 19, 2023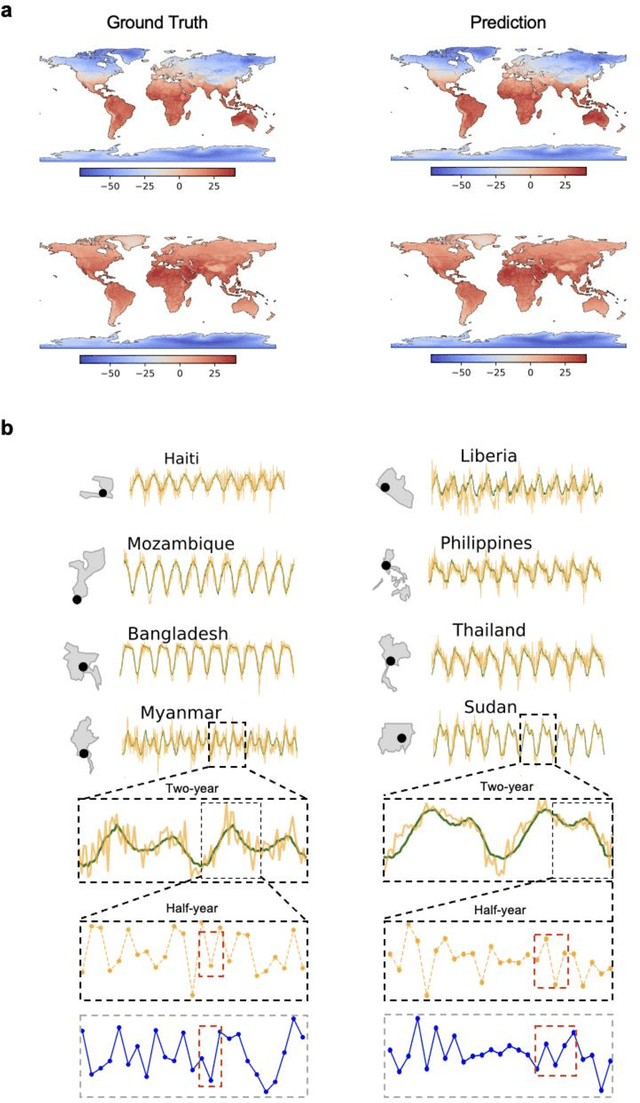
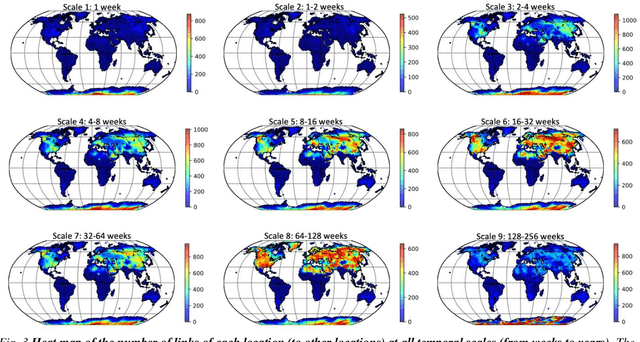
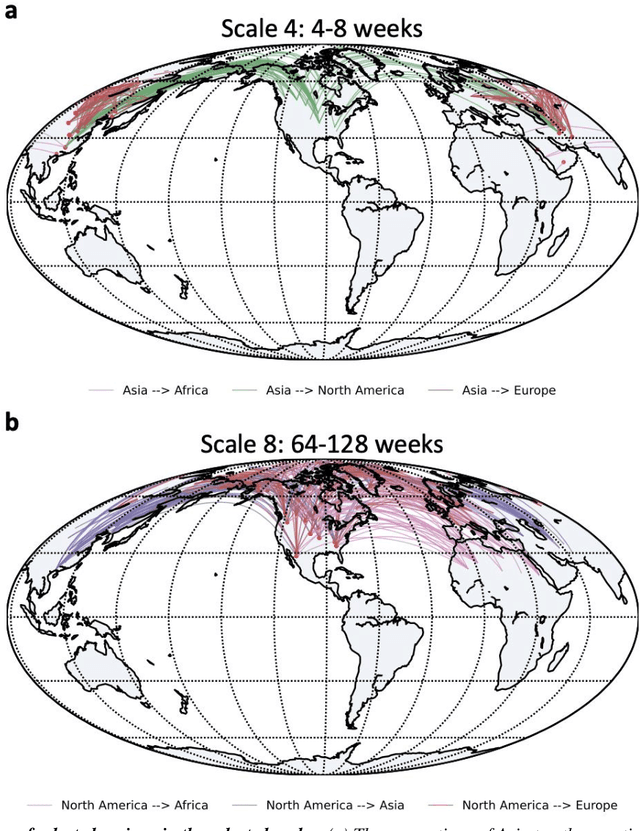
Decadal temperature prediction provides crucial information for quantifying the expected effects of future climate changes and thus informs strategic planning and decision-making in various domains. However, such long-term predictions are extremely challenging, due to the chaotic nature of temperature variations. Moreover, the usefulness of existing simulation-based and machine learning-based methods for this task is limited because initial simulation or prediction errors increase exponentially over time. To address this challenging task, we devise a novel prediction method involving an information tracking mechanism that aims to track and adapt to changes in temperature dynamics during the prediction phase by providing probabilistic feedback on the prediction error of the next step based on the current prediction. We integrate this information tracking mechanism, which can be considered as a model calibrator, into the objective function of our method to obtain the corrections needed to avoid error accumulation. Our results show the ability of our method to accurately predict global land-surface temperatures over a decadal range. Furthermore, we demonstrate that our results are meaningful in a real-world context: the temperatures predicted using our method are consistent with and can be used to explain the well-known teleconnections within and between different continents.