 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Poly Kernel Inception Network for Remote Sensing Detection
Mar 20, 2024
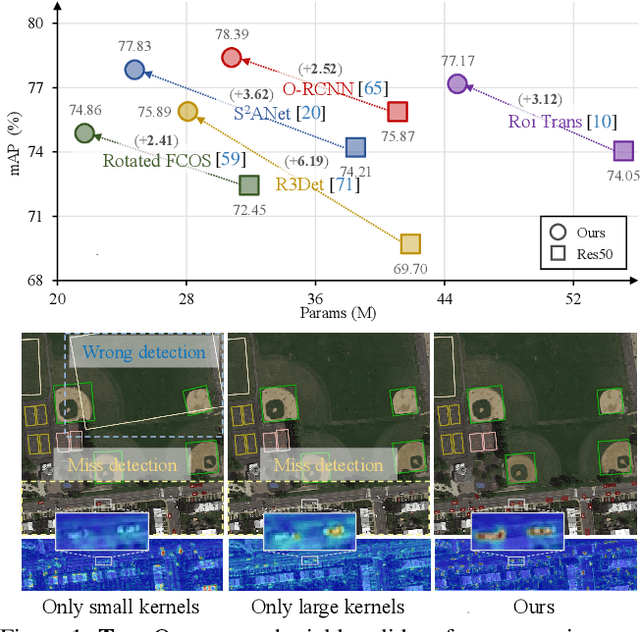
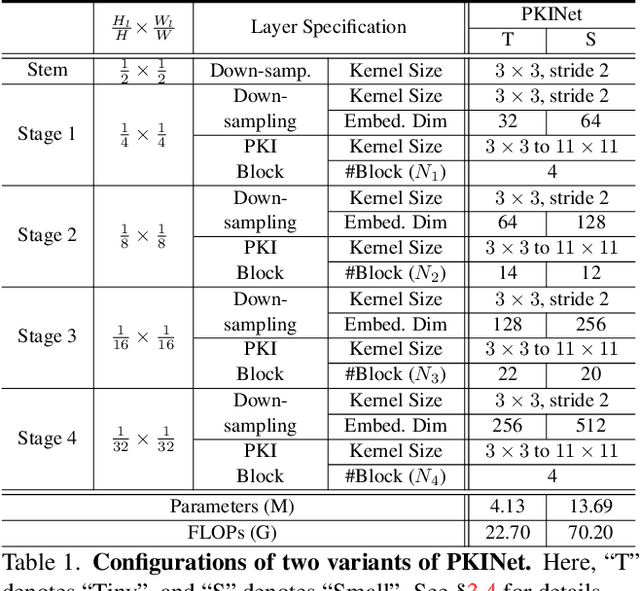
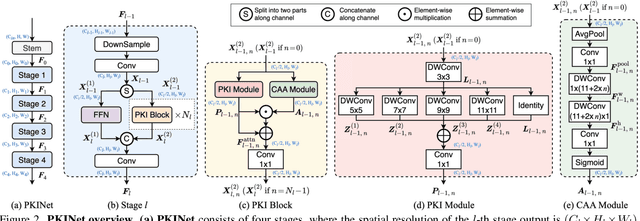
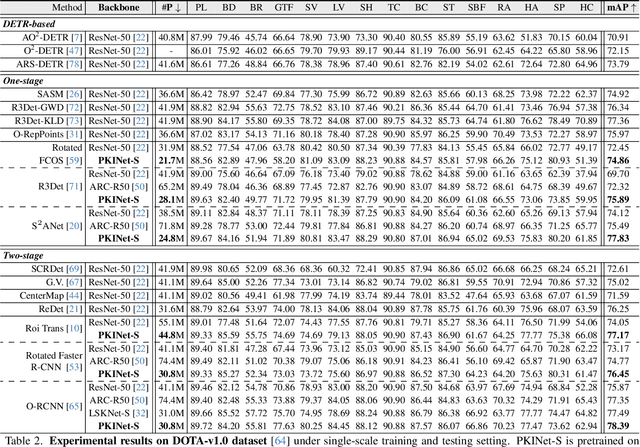
Object detection in remote sensing images (RSIs) often suffers from several increasing challenges, including the large variation in object scales and the diverse-ranging context. Prior methods tried to address these challenges by expanding the spatial receptive field of the backbone, either through large-kernel convolution or dilated convolution. However, the former typically introduces considerable background noise, while the latter risks generating overly sparse feature representations. In this paper, we introduce the Poly Kernel Inception Network (PKINet) to handle the above challenges. PKINet employs multi-scale convolution kernels without dilation to extract object features of varying scales and capture local context. In addition, a Context Anchor Attention (CAA) module is introduced in parallel to capture long-range contextual information. These two components work jointly to advance the performance of PKINet on four challenging remote sensing detection benchmarks, namely DOTA-v1.0, DOTA-v1.5, HRSC2016, and DIOR-R.
Bootstrapping Reinforcement Learning with Imitation for Vision-Based Agile Flight
Mar 18, 2024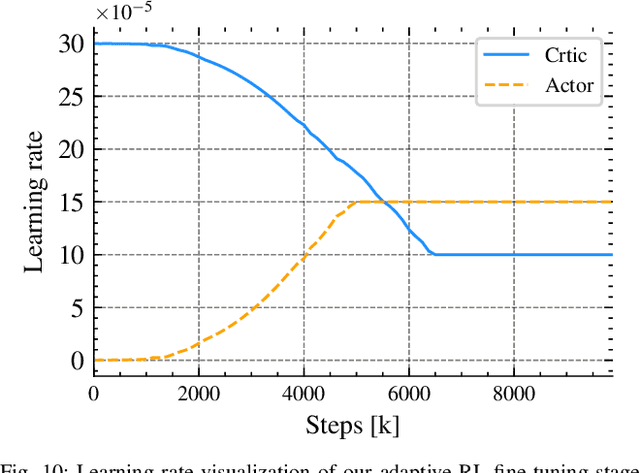
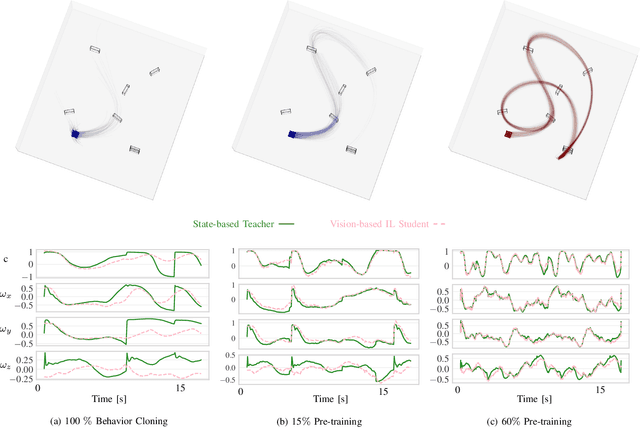


We combine the effectiveness of Reinforcement Learning (RL) and the efficiency of Imitation Learning (IL) in the context of vision-based, autonomous drone racing. We focus on directly processing visual input without explicit state estimation. While RL offers a general framework for learning complex controllers through trial and error, it faces challenges regarding sample efficiency and computational demands due to the high dimensionality of visual inputs. Conversely, IL demonstrates efficiency in learning from visual demonstrations but is limited by the quality of those demonstrations and faces issues like covariate shift. To overcome these limitations, we propose a novel training framework combining RL and IL's advantages. Our framework involves three stages: initial training of a teacher policy using privileged state information, distilling this policy into a student policy using IL, and performance-constrained adaptive RL fine-tuning. Our experiments in both simulated and real-world environments demonstrate that our approach achieves superior performance and robustness than IL or RL alone in navigating a quadrotor through a racing course using only visual information without explicit state estimation.
FLex: Joint Pose and Dynamic Radiance Fields Optimization for Stereo Endoscopic Videos
Mar 18, 2024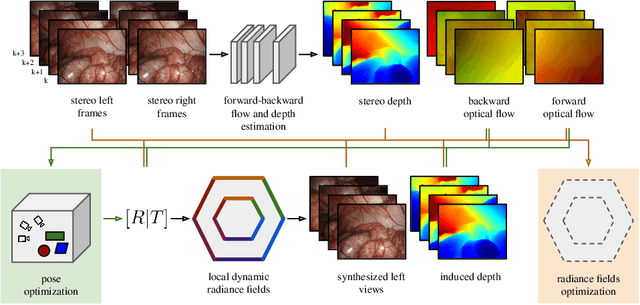
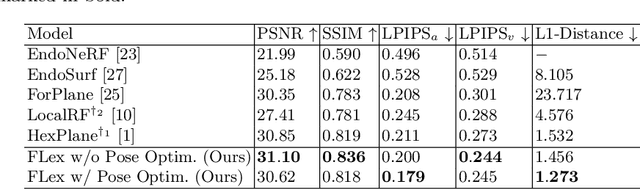
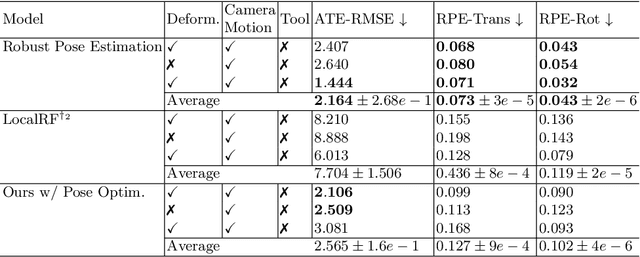
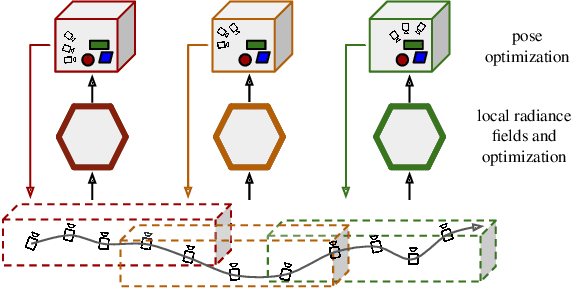
Reconstruction of endoscopic scenes is an important asset for various medical applications, from post-surgery analysis to educational training. Neural rendering has recently shown promising results in endoscopic reconstruction with deforming tissue. However, the setup has been restricted to a static endoscope, limited deformation, or required an external tracking device to retrieve camera pose information of the endoscopic camera. With FLex we adress the challenging setup of a moving endoscope within a highly dynamic environment of deforming tissue. We propose an implicit scene separation into multiple overlapping 4D neural radiance fields (NeRFs) and a progressive optimization scheme jointly optimizing for reconstruction and camera poses from scratch. This improves the ease-of-use and allows to scale reconstruction capabilities in time to process surgical videos of 5,000 frames and more; an improvement of more than ten times compared to the state of the art while being agnostic to external tracking information. Extensive evaluations on the StereoMIS dataset show that FLex significantly improves the quality of novel view synthesis while maintaining competitive pose accuracy.
CRS-Diff: Controllable Generative Remote Sensing Foundation Model
Mar 18, 2024
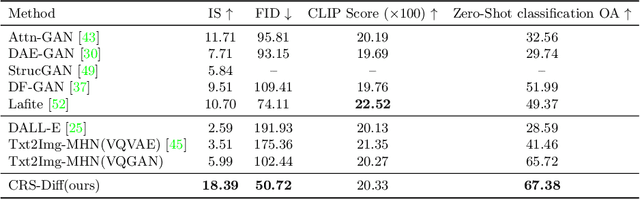
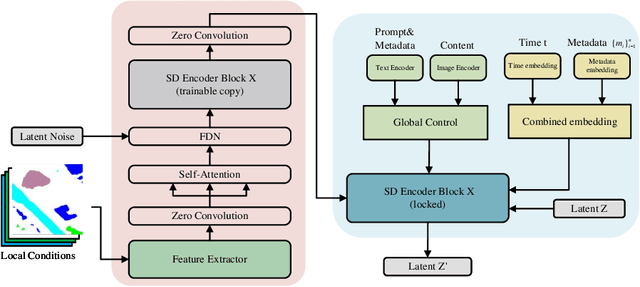
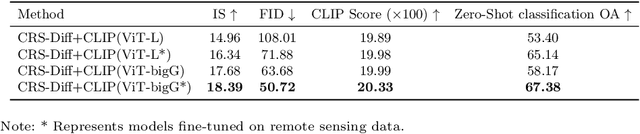
The emergence of diffusion models has revolutionized the field of image generation, providing new methods for creating high-quality, high-resolution images across various applications. However, the potential of these models for generating domain-specific images, particularly remote sensing (RS) images, remains largely untapped. RS images that are notable for their high resolution, extensive coverage, and rich information content, bring new challenges that general diffusion models may not adequately address. This paper proposes CRS-Diff, a pioneering diffusion modeling framework specifically tailored for generating remote sensing imagery, leveraging the inherent advantages of diffusion models while integrating advanced control mechanisms to ensure that the imagery is not only visually clear but also enriched with geographic and temporal information. The model integrates global and local control inputs, enabling precise combinations of generation conditions to refine the generation process. A comprehensive evaluation of CRS-Diff has demonstrated its superior capability to generate RS imagery both in a single condition and multiple conditions compared with previous methods in terms of image quality and diversity.
EMIE-MAP: Large-Scale Road Surface Reconstruction Based on Explicit Mesh and Implicit Encoding
Mar 18, 2024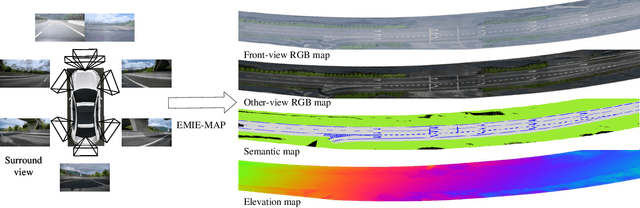

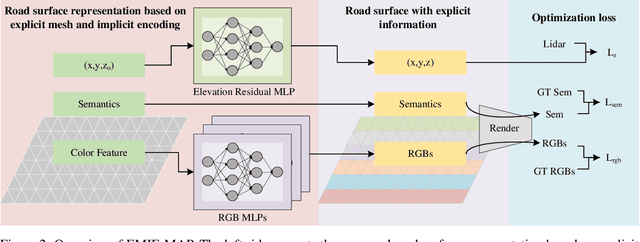

Road surface reconstruction plays a vital role in autonomous driving systems, enabling road lane perception and high-precision mapping. Recently, neural implicit encoding has achieved remarkable results in scene representation, particularly in the realistic rendering of scene textures. However, it faces challenges in directly representing geometric information for large-scale scenes. To address this, we propose EMIE-MAP, a novel method for large-scale road surface reconstruction based on explicit mesh and implicit encoding. The road geometry is represented using explicit mesh, where each vertex stores implicit encoding representing the color and semantic information. To overcome the difficulty in optimizing road elevation, we introduce a trajectory-based elevation initialization and an elevation residual learning method based on Multi-Layer Perceptron (MLP). Additionally, by employing implicit encoding and multi-camera color MLPs decoding, we achieve separate modeling of scene physical properties and camera characteristics, allowing surround-view reconstruction compatible with different camera models. Our method achieves remarkable road surface reconstruction performance in a variety of real-world challenging scenarios.
HAC: Hash-grid Assisted Context for 3D Gaussian Splatting Compression
Mar 21, 2024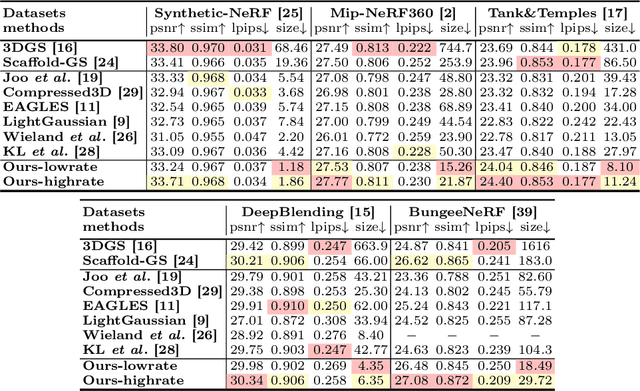
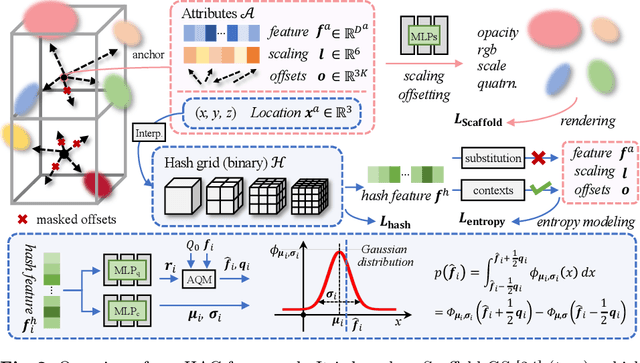

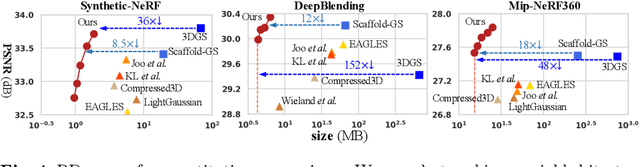
3D Gaussian Splatting (3DGS) has emerged as a promising framework for novel view synthesis, boasting rapid rendering speed with high fidelity. However, the substantial Gaussians and their associated attributes necessitate effective compression techniques. Nevertheless, the sparse and unorganized nature of the point cloud of Gaussians (or anchors in our paper) presents challenges for compression. To address this, we make use of the relations between the unorganized anchors and the structured hash grid, leveraging their mutual information for context modeling, and propose a Hash-grid Assisted Context (HAC) framework for highly compact 3DGS representation. Our approach introduces a binary hash grid to establish continuous spatial consistencies, allowing us to unveil the inherent spatial relations of anchors through a carefully designed context model. To facilitate entropy coding, we utilize Gaussian distributions to accurately estimate the probability of each quantized attribute, where an adaptive quantization module is proposed to enable high-precision quantization of these attributes for improved fidelity restoration. Additionally, we incorporate an adaptive masking strategy to eliminate invalid Gaussians and anchors. Importantly, our work is the pioneer to explore context-based compression for 3DGS representation, resulting in a remarkable size reduction of over $75\times$ compared to vanilla 3DGS, while simultaneously improving fidelity, and achieving over $11\times$ size reduction over SOTA 3DGS compression approach Scaffold-GS. Our code is available here: https://github.com/YihangChen-ee/HAC
Ranking Distillation for Open-Ended Video Question Answering with Insufficient Labels
Mar 21, 2024
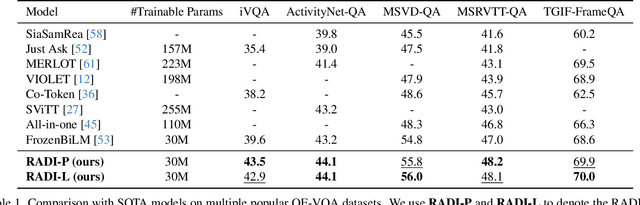
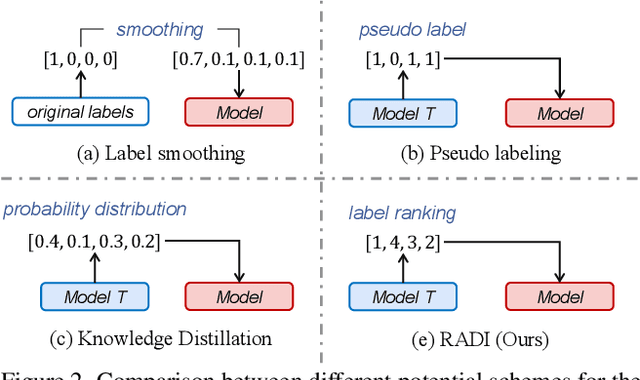
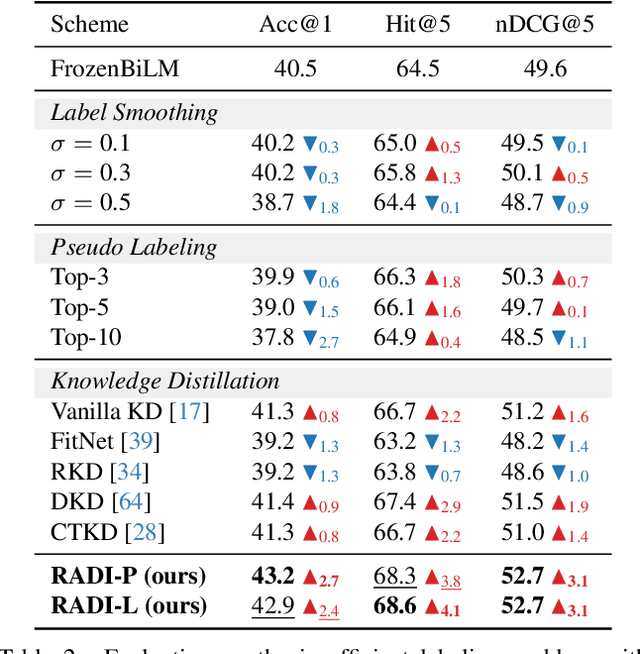
This paper focuses on open-ended video question answering, which aims to find the correct answers from a large answer set in response to a video-related question. This is essentially a multi-label classification task, since a question may have multiple answers. However, due to annotation costs, the labels in existing benchmarks are always extremely insufficient, typically one answer per question. As a result, existing works tend to directly treat all the unlabeled answers as negative labels, leading to limited ability for generalization. In this work, we introduce a simple yet effective ranking distillation framework (RADI) to mitigate this problem without additional manual annotation. RADI employs a teacher model trained with incomplete labels to generate rankings for potential answers, which contain rich knowledge about label priority as well as label-associated visual cues, thereby enriching the insufficient labeling information. To avoid overconfidence in the imperfect teacher model, we further present two robust and parameter-free ranking distillation approaches: a pairwise approach which introduces adaptive soft margins to dynamically refine the optimization constraints on various pairwise rankings, and a listwise approach which adopts sampling-based partial listwise learning to resist the bias in teacher ranking. Extensive experiments on five popular benchmarks consistently show that both our pairwise and listwise RADIs outperform state-of-the-art methods. Further analysis demonstrates the effectiveness of our methods on the insufficient labeling problem.
Editing Knowledge Representation of Language Lodel via Rephrased Prefix Prompts
Mar 21, 2024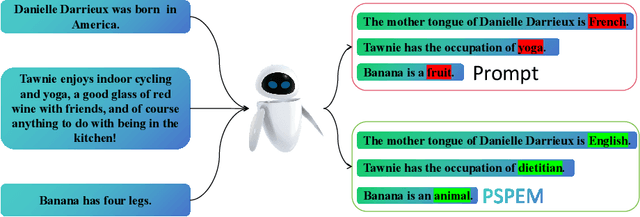
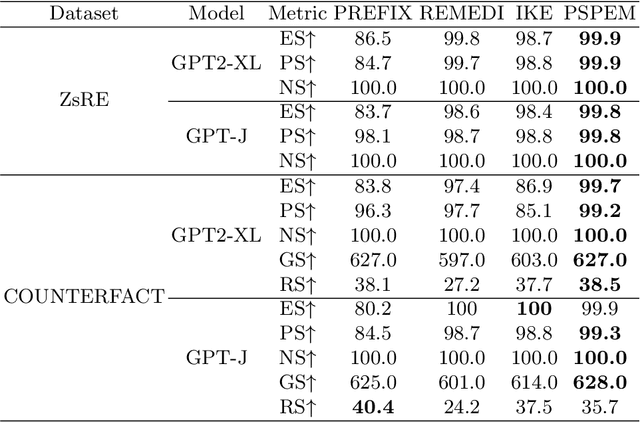
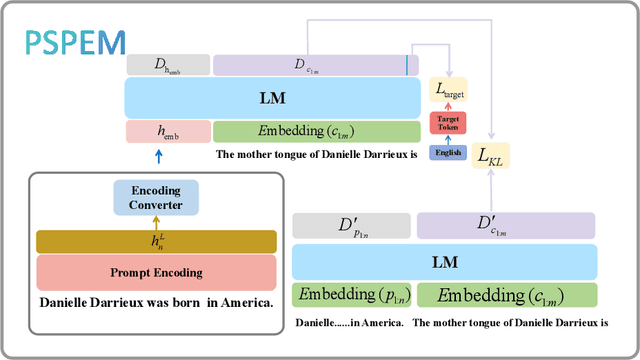
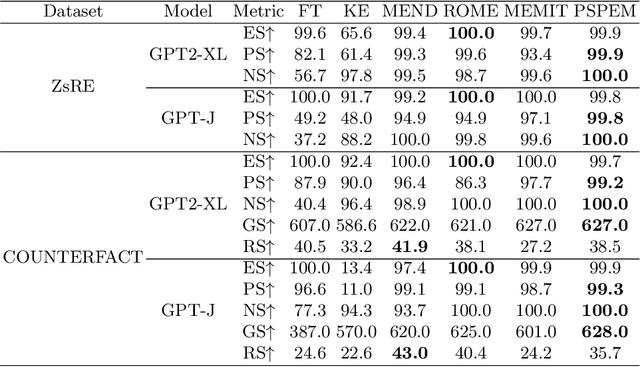
Neural language models (LMs) have been extensively trained on vast corpora to store factual knowledge about various aspects of the world described in texts. Current technologies typically employ knowledge editing methods or specific prompts to modify LM outputs. However, existing knowledge editing methods are costly and inefficient, struggling to produce appropriate text. Additionally, prompt engineering is opaque and requires significant effort to find suitable prompts. To address these issues, we introduce a new method called PSPEM (Prefix Soft Prompt Editing Method), that can be used for a lifetime with just one training. It resolves the inefficiencies and generalizability issues in knowledge editing methods and overcomes the opacity of prompt engineering by automatically seeking optimal soft prompts. Specifically, PSPEM utilizes a prompt encoder and an encoding converter to refine key information in prompts and uses prompt alignment techniques to guide model generation, ensuring text consistency and adherence to the intended structure and content, thereby maintaining an optimal balance between efficiency and accuracy. We have validated the effectiveness of PSPEM through knowledge editing and attribute inserting. On the COUNTERFACT dataset, PSPEM achieved nearly 100\% editing accuracy and demonstrated the highest level of fluency. We further analyzed the similarities between PSPEM and original prompts and their impact on the model's internals. The results indicate that PSPEM can serve as an alternative to original prompts, supporting the model in effective editing.
EventDance: Unsupervised Source-free Cross-modal Adaptation for Event-based Object Recognition
Mar 21, 2024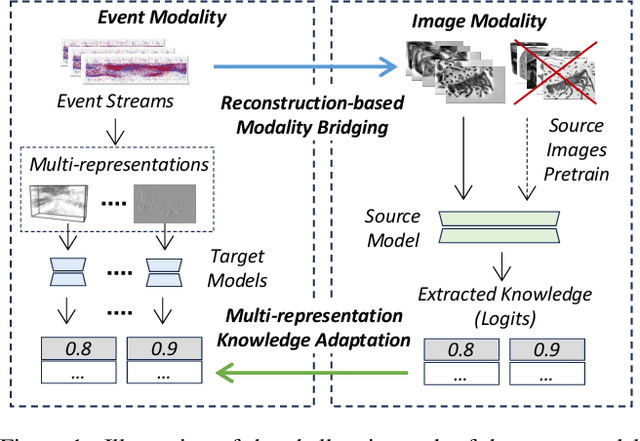
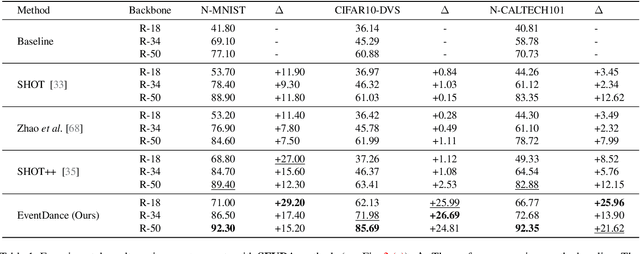

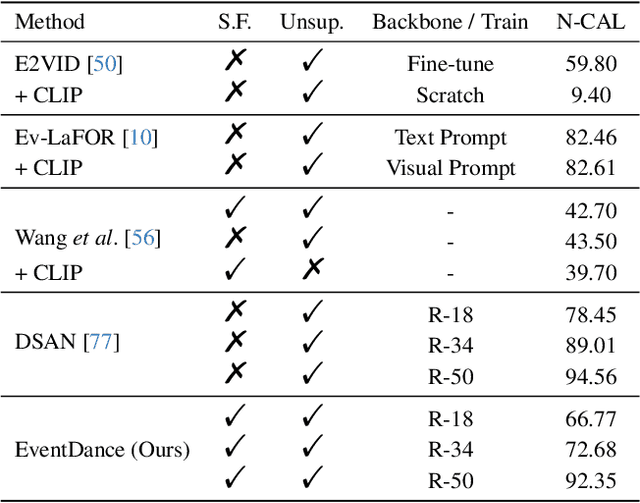
In this paper, we make the first attempt at achieving the cross-modal (i.e., image-to-events) adaptation for event-based object recognition without accessing any labeled source image data owning to privacy and commercial issues. Tackling this novel problem is non-trivial due to the novelty of event cameras and the distinct modality gap between images and events. In particular, as only the source model is available, a hurdle is how to extract the knowledge from the source model by only using the unlabeled target event data while achieving knowledge transfer. To this end, we propose a novel framework, dubbed EventDance for this unsupervised source-free cross-modal adaptation problem. Importantly, inspired by event-to-video reconstruction methods, we propose a reconstruction-based modality bridging (RMB) module, which reconstructs intensity frames from events in a self-supervised manner. This makes it possible to build up the surrogate images to extract the knowledge (i.e., labels) from the source model. We then propose a multi-representation knowledge adaptation (MKA) module that transfers the knowledge to target models learning events with multiple representation types for fully exploring the spatiotemporal information of events. The two modules connecting the source and target models are mutually updated so as to achieve the best performance. Experiments on three benchmark datasets with two adaption settings show that EventDance is on par with prior methods utilizing the source data.
MathVerse: Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems?
Mar 21, 2024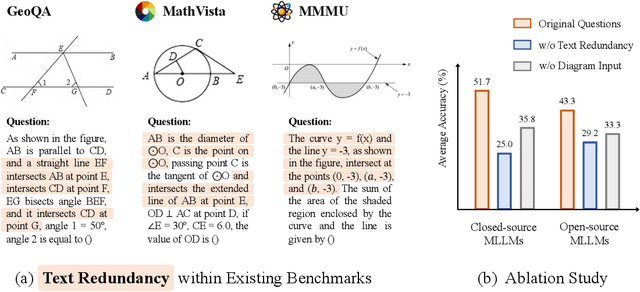

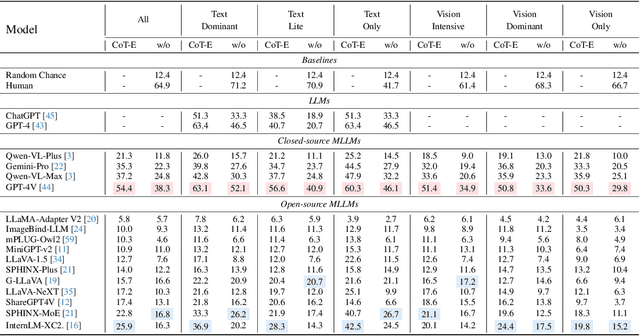
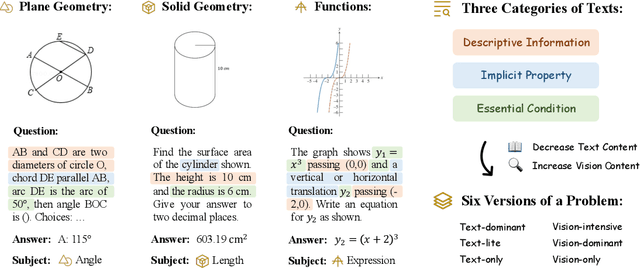
The remarkable progress of Multi-modal Large Language Models (MLLMs) has garnered unparalleled attention, due to their superior performance in visual contexts. However, their capabilities in visual math problem-solving remain insufficiently evaluated and understood. We investigate current benchmarks to incorporate excessive visual content within textual questions, which potentially assist MLLMs in deducing answers without truly interpreting the input diagrams. To this end, we introduce MathVerse, an all-around visual math benchmark designed for an equitable and in-depth evaluation of MLLMs. We meticulously collect 2,612 high-quality, multi-subject math problems with diagrams from publicly available sources. Each problem is then transformed by human annotators into six distinct versions, each offering varying degrees of information content in multi-modality, contributing to 15K test samples in total. This approach allows MathVerse to comprehensively assess whether and how much MLLMs can truly understand the visual diagrams for mathematical reasoning. In addition, we propose a Chain-of-Thought (CoT) evaluation strategy for a fine-grained assessment of the output answers. Rather than naively judging True or False, we employ GPT-4(V) to adaptively extract crucial reasoning steps, and then score each step with detailed error analysis, which can reveal the intermediate CoT reasoning quality by MLLMs. We hope the MathVerse benchmark may provide unique insights to guide the future development of MLLMs. Project page: https://mathverse-cuhk.github.io