 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Constrained Environment Optimization for Prioritized Multi-Agent Navigation
May 18, 2023
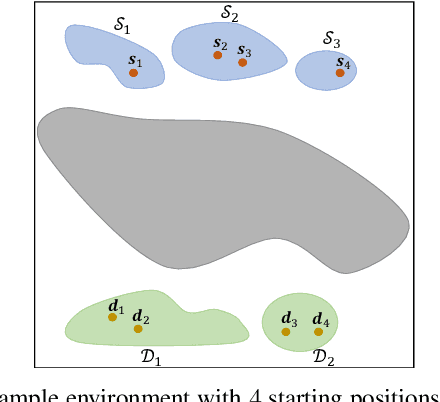
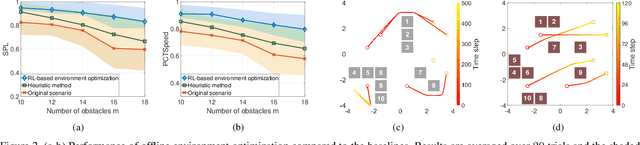
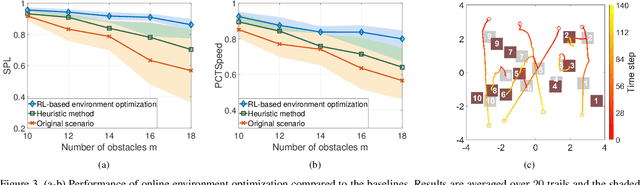
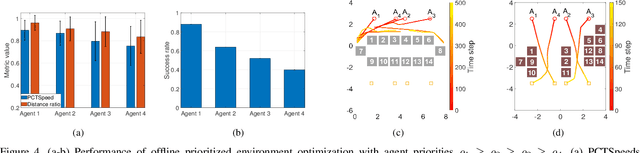
Traditional approaches to the design of multi-agent navigation algorithms consider the environment as a fixed constraint, despite the influence of spatial constraints on agents' performance. Yet hand-designing conducive environment layouts is inefficient and potentially expensive. The goal of this paper is to consider the environment as a decision variable in a system-level optimization problem, where both agent performance and environment cost are incorporated. Towards this end, we propose novel problems of unprioritized and prioritized environment optimization, where the former considers agents unbiasedly and the latter accounts for agent priorities. We show, through formal proofs, under which conditions the environment can change while guaranteeing completeness (i.e., all agents reach goals), and analyze the role of agent priorities in the environment optimization. We proceed to impose real-world constraints on the environment optimization and formulate it mathematically as a constrained stochastic optimization problem. Since the relation between agents, environment and performance is challenging to model, we leverage reinforcement learning to develop a model-free solution and a primal-dual mechanism to handle constraints. Distinct information processing architectures are integrated for various implementation scenarios, including online/offline optimization and discrete/continuous environment. Numerical results corroborate the theory and demonstrate the validity and adaptability of our approach.
PETAL: Physics Emulation Through Averaged Linearizations for Solving Inverse Problems
May 18, 2023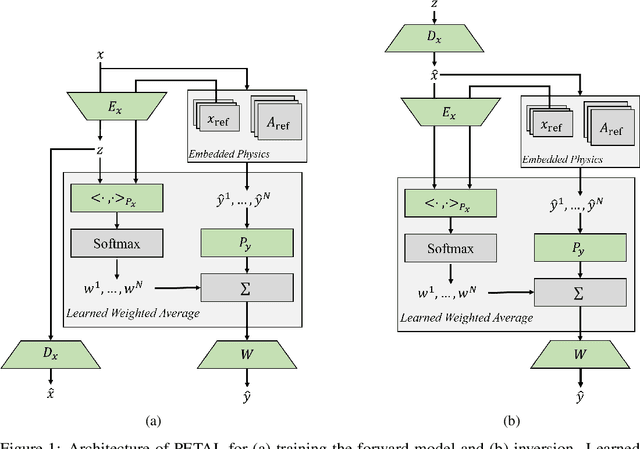
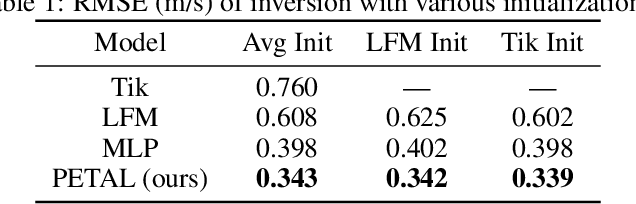
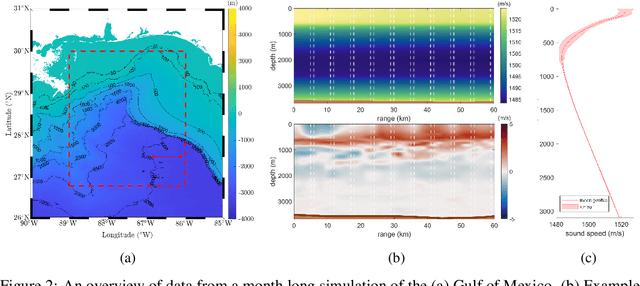

Inverse problems describe the task of recovering an underlying signal of interest given observables. Typically, the observables are related via some non-linear forward model applied to the underlying unknown signal. Inverting the non-linear forward model can be computationally expensive, as it often involves computing and inverting a linearization at a series of estimates. Rather than inverting the physics-based model, we instead train a surrogate forward model (emulator) and leverage modern auto-grad libraries to solve for the input within a classical optimization framework. Current methods to train emulators are done in a black box supervised machine learning fashion and fail to take advantage of any existing knowledge of the forward model. In this article, we propose a simple learned weighted average model that embeds linearizations of the forward model around various reference points into the model itself, explicitly incorporating known physics. Grounding the learned model with physics based linearizations improves the forward modeling accuracy and provides richer physics based gradient information during the inversion process leading to more accurate signal recovery. We demonstrate the efficacy on an ocean acoustic tomography (OAT) example that aims to recover ocean sound speed profile (SSP) variations from acoustic observations (e.g. eigenray arrival times) within simulation of ocean dynamics in the Gulf of Mexico.
A Lexical-aware Non-autoregressive Transformer-based ASR Model
May 18, 2023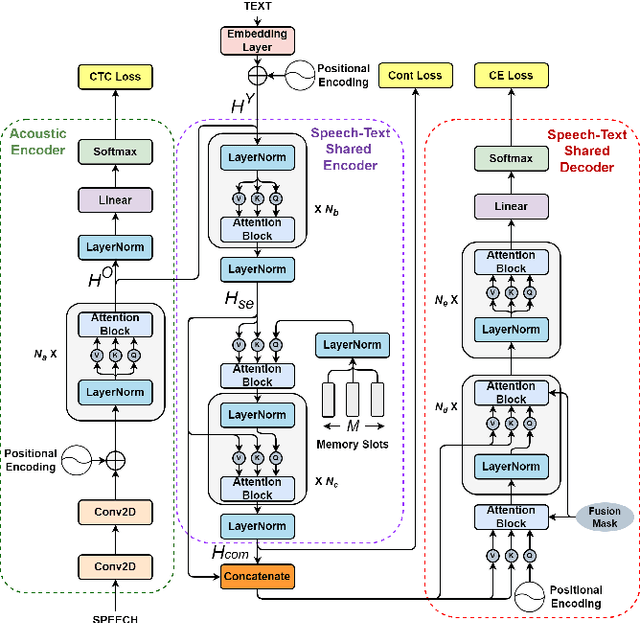
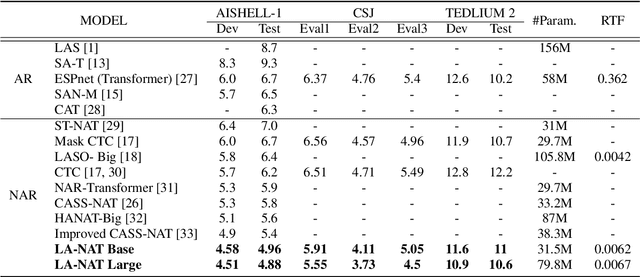
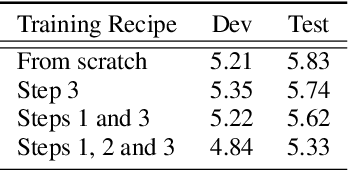
Non-autoregressive automatic speech recognition (ASR) has become a mainstream of ASR modeling because of its fast decoding speed and satisfactory result. To further boost the performance, relaxing the conditional independence assumption and cascading large-scaled pre-trained models are two active research directions. In addition to these strategies, we propose a lexical-aware non-autoregressive Transformer-based (LA-NAT) ASR framework, which consists of an acoustic encoder, a speech-text shared encoder, and a speech-text shared decoder. The acoustic encoder is used to process the input speech features as usual, and the speech-text shared encoder and decoder are designed to train speech and text data simultaneously. By doing so, LA-NAT aims to make the ASR model aware of lexical information, so the resulting model is expected to achieve better results by leveraging the learned linguistic knowledge. A series of experiments are conducted on the AISHELL-1, CSJ, and TEDLIUM 2 datasets. According to the experiments, the proposed LA-NAT can provide superior results than other recently proposed non-autoregressive ASR models. In addition, LA-NAT is a relatively compact model than most non-autoregressive ASR models, and it is about 58 times faster than the classic autoregressive model.
Rate-Adaptive Coding Mechanism for Semantic Communications With Multi-Modal Data
May 18, 2023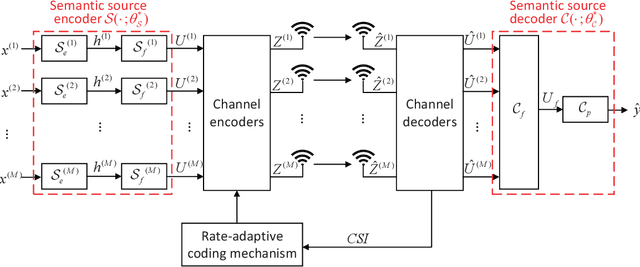
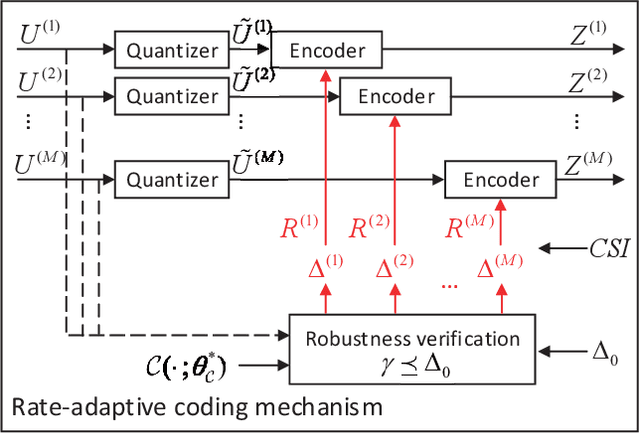
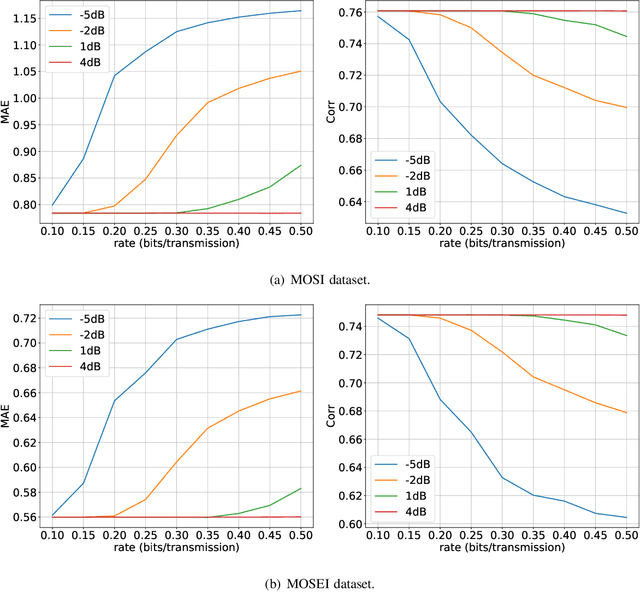
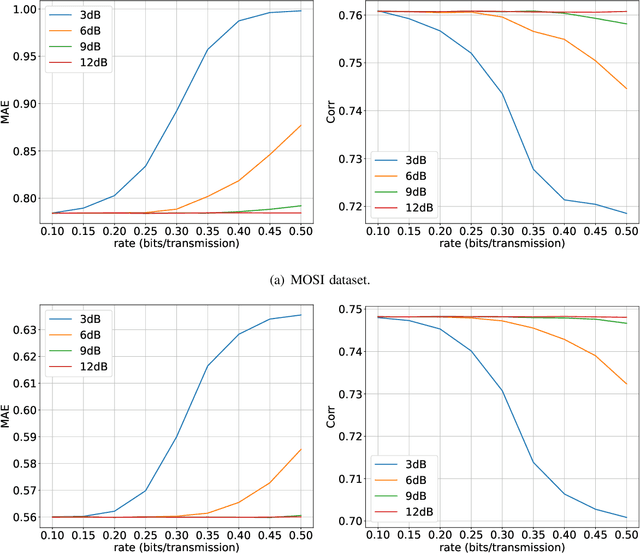
Recently, the ever-increasing demand for bandwidth in multi-modal communication systems requires a paradigm shift. Powered by deep learning, semantic communications are applied to multi-modal scenarios to boost communication efficiency and save communication resources. However, the existing end-to-end neural network (NN) based framework without the channel encoder/decoder is incompatible with modern digital communication systems. Moreover, most end-to-end designs are task-specific and require re-design and re-training for new tasks, which limits their applications. In this paper, we propose a distributed multi-modal semantic communication framework incorporating the conventional channel encoder/decoder. We adopt NN-based semantic encoder and decoder to extract correlated semantic information contained in different modalities, including speech, text, and image. Based on the proposed framework, we further establish a general rate-adaptive coding mechanism for various types of multi-modal semantic tasks. In particular, we utilize unequal error protection based on semantic importance, which is derived by evaluating the distortion bound of each modality. We further formulate and solve an optimization problem that aims at minimizing inference delay while maintaining inference accuracy for semantic tasks. Numerical results show that the proposed mechanism fares better than both conventional communication and existing semantic communication systems in terms of task performance, inference delay, and deployment complexity.
Learning Differentially Private Probabilistic Models for Privacy-Preserving Image Generation
May 18, 2023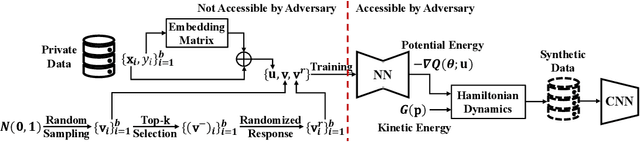
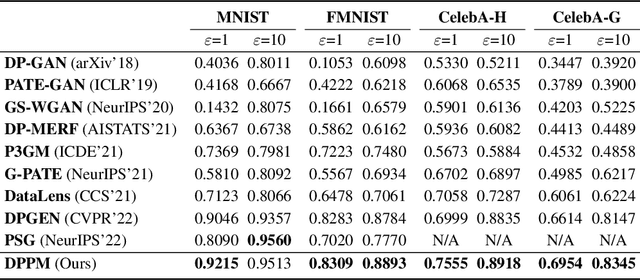
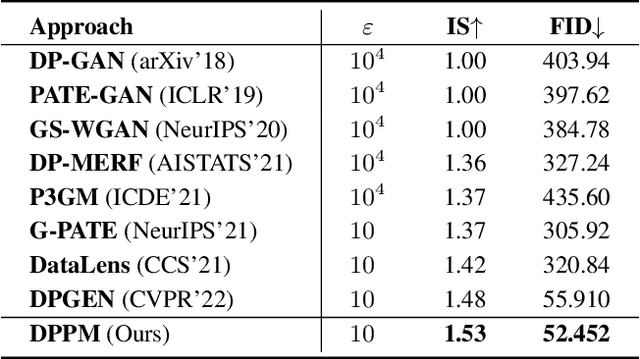

A number of deep models trained on high-quality and valuable images have been deployed in practical applications, which may pose a leakage risk of data privacy. Learning differentially private generative models can sidestep this challenge through indirect data access. However, such differentially private generative models learned by existing approaches can only generate images with a low-resolution of less than 128x128, hindering the widespread usage of generated images in downstream training. In this work, we propose learning differentially private probabilistic models (DPPM) to generate high-resolution images with differential privacy guarantee. In particular, we first train a model to fit the distribution of the training data and make it satisfy differential privacy by performing a randomized response mechanism during training process. Then we perform Hamiltonian dynamics sampling along with the differentially private movement direction predicted by the trained probabilistic model to obtain the privacy-preserving images. In this way, it is possible to apply these images to different downstream tasks while protecting private information. Notably, compared to other state-of-the-art differentially private generative approaches, our approach can generate images up to 256x256 with remarkable visual quality and data utility. Extensive experiments show the effectiveness of our approach.
MTLSegFormer: Multi-task Learning with Transformers for Semantic Segmentation in Precision Agriculture
May 04, 2023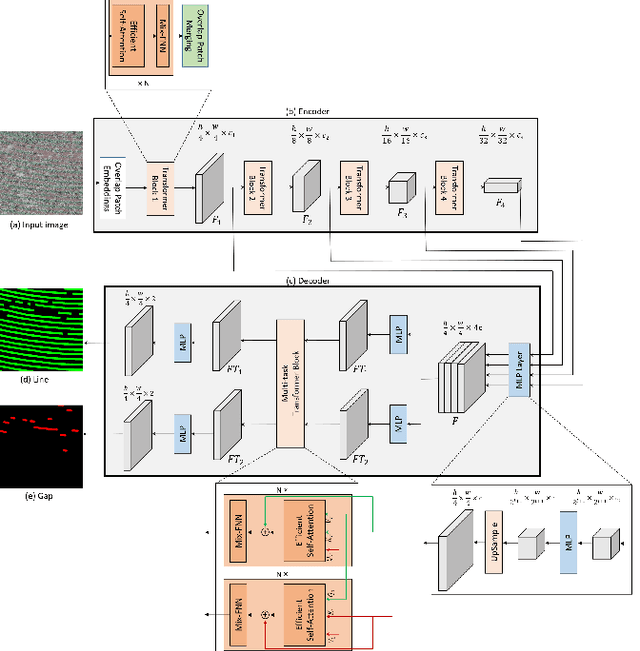
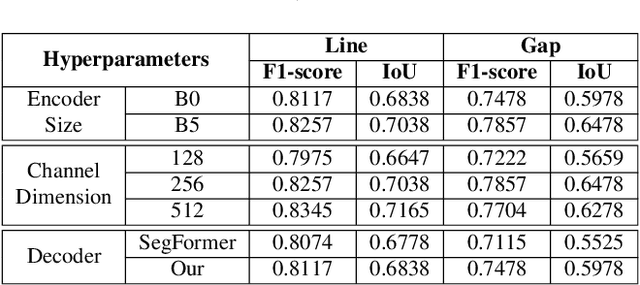

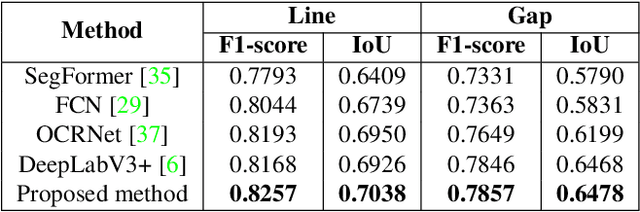
Multi-task learning has proven to be effective in improving the performance of correlated tasks. Most of the existing methods use a backbone to extract initial features with independent branches for each task, and the exchange of information between the branches usually occurs through the concatenation or sum of the feature maps of the branches. However, this type of information exchange does not directly consider the local characteristics of the image nor the level of importance or correlation between the tasks. In this paper, we propose a semantic segmentation method, MTLSegFormer, which combines multi-task learning and attention mechanisms. After the backbone feature extraction, two feature maps are learned for each task. The first map is proposed to learn features related to its task, while the second map is obtained by applying learned visual attention to locally re-weigh the feature maps of the other tasks. In this way, weights are assigned to local regions of the image of other tasks that have greater importance for the specific task. Finally, the two maps are combined and used to solve a task. We tested the performance in two challenging problems with correlated tasks and observed a significant improvement in accuracy, mainly in tasks with high dependence on the others.
Prompt-ICM: A Unified Framework towards Image Coding for Machines with Task-driven Prompts
May 04, 2023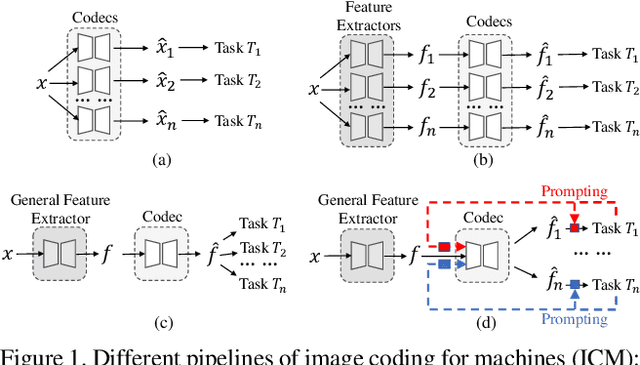
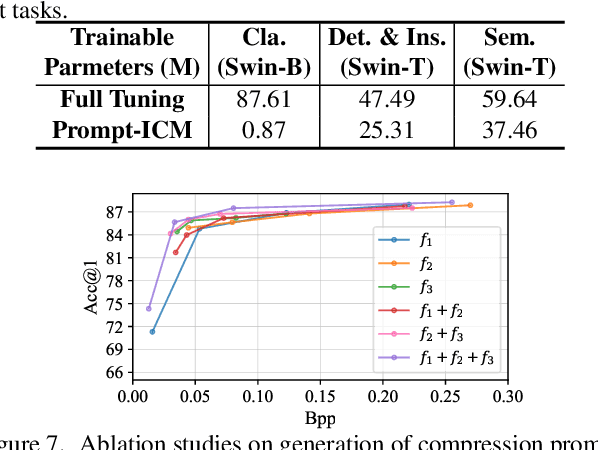
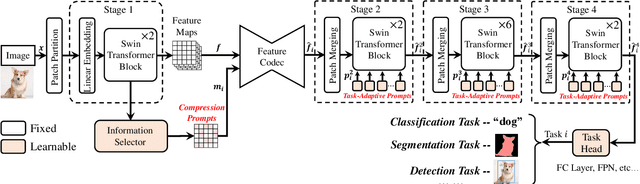

Image coding for machines (ICM) aims to compress images to support downstream AI analysis instead of human perception. For ICM, developing a unified codec to reduce information redundancy while empowering the compressed features to support various vision tasks is very important, which inevitably faces two core challenges: 1) How should the compression strategy be adjusted based on the downstream tasks? 2) How to well adapt the compressed features to different downstream tasks? Inspired by recent advances in transferring large-scale pre-trained models to downstream tasks via prompting, in this work, we explore a new ICM framework, termed Prompt-ICM. To address both challenges by carefully learning task-driven prompts to coordinate well the compression process and downstream analysis. Specifically, our method is composed of two core designs: a) compression prompts, which are implemented as importance maps predicted by an information selector, and used to achieve different content-weighted bit allocations during compression according to different downstream tasks; b) task-adaptive prompts, which are instantiated as a few learnable parameters specifically for tuning compressed features for the specific intelligent task. Extensive experiments demonstrate that with a single feature codec and a few extra parameters, our proposed framework could efficiently support different kinds of intelligent tasks with much higher coding efficiency.
QLoRA: Efficient Finetuning of Quantized LLMs
May 23, 2023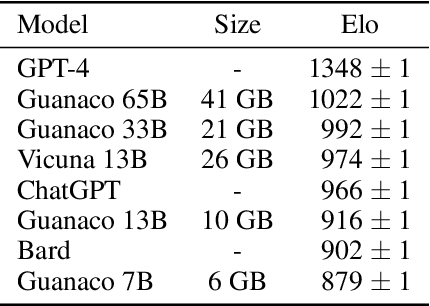
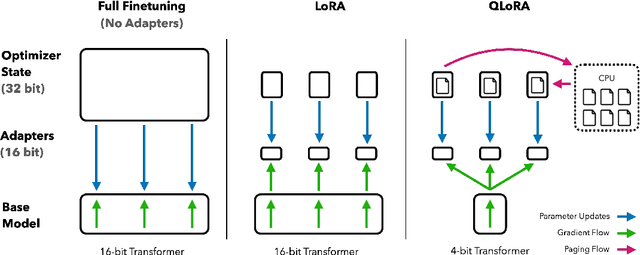
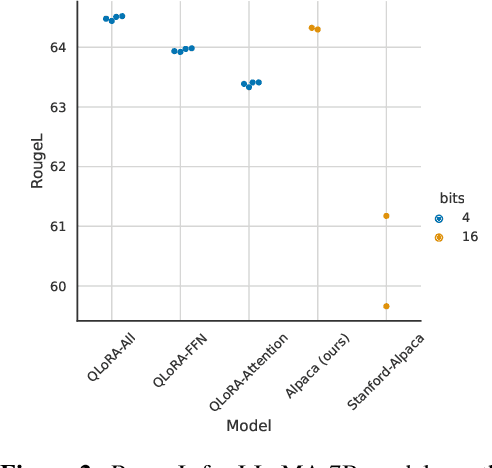
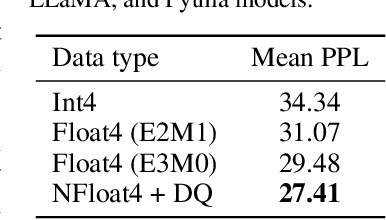
We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters~(LoRA). Our best model family, which we name Guanaco, outperforms all previous openly released models on the Vicuna benchmark, reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of finetuning on a single GPU. QLoRA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights (b) double quantization to reduce the average memory footprint by quantizing the quantization constants, and (c) paged optimziers to manage memory spikes. We use QLoRA to finetune more than 1,000 models, providing a detailed analysis of instruction following and chatbot performance across 8 instruction datasets, multiple model types (LLaMA, T5), and model scales that would be infeasible to run with regular finetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA finetuning on a small high-quality dataset leads to state-of-the-art results, even when using smaller models than the previous SoTA. We provide a detailed analysis of chatbot performance based on both human and GPT-4 evaluations showing that GPT-4 evaluations are a cheap and reasonable alternative to human evaluation. Furthermore, we find that current chatbot benchmarks are not trustworthy to accurately evaluate the performance levels of chatbots. A lemon-picked analysis demonstrates where Guanaco fails compared to ChatGPT. We release all of our models and code, including CUDA kernels for 4-bit training.
Prototype Adaption and Projection for Few- and Zero-shot 3D Point Cloud Semantic Segmentation
May 23, 2023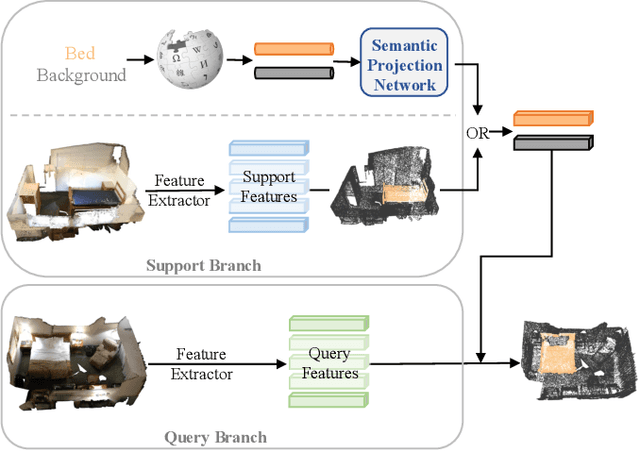
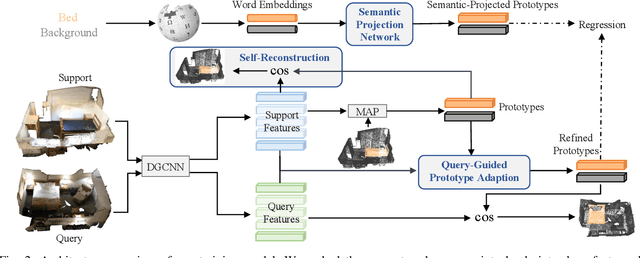
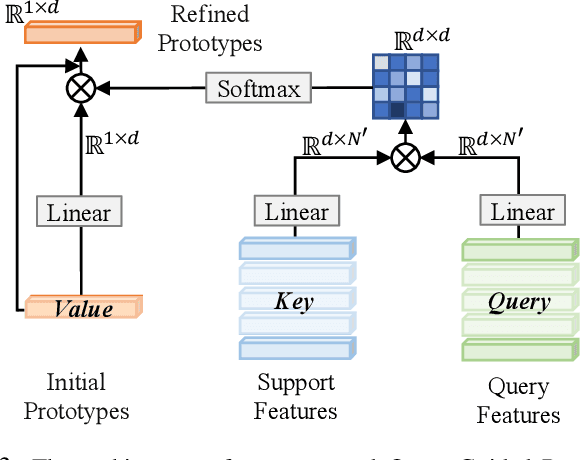
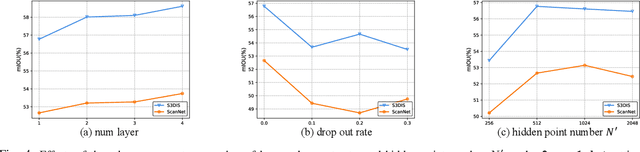
In this work, we address the challenging task of few-shot and zero-shot 3D point cloud semantic segmentation. The success of few-shot semantic segmentation in 2D computer vision is mainly driven by the pre-training on large-scale datasets like imagenet. The feature extractor pre-trained on large-scale 2D datasets greatly helps the 2D few-shot learning. However, the development of 3D deep learning is hindered by the limited volume and instance modality of datasets due to the significant cost of 3D data collection and annotation. This results in less representative features and large intra-class feature variation for few-shot 3D point cloud segmentation. As a consequence, directly extending existing popular prototypical methods of 2D few-shot classification/segmentation into 3D point cloud segmentation won't work as well as in 2D domain. To address this issue, we propose a Query-Guided Prototype Adaption (QGPA) module to adapt the prototype from support point clouds feature space to query point clouds feature space. With such prototype adaption, we greatly alleviate the issue of large feature intra-class variation in point cloud and significantly improve the performance of few-shot 3D segmentation. Besides, to enhance the representation of prototypes, we introduce a Self-Reconstruction (SR) module that enables prototype to reconstruct the support mask as well as possible. Moreover, we further consider zero-shot 3D point cloud semantic segmentation where there is no support sample. To this end, we introduce category words as semantic information and propose a semantic-visual projection model to bridge the semantic and visual spaces. Our proposed method surpasses state-of-the-art algorithms by a considerable 7.90% and 14.82% under the 2-way 1-shot setting on S3DIS and ScanNet benchmarks, respectively. Code is available at https://github.com/heshuting555/PAP-FZS3D.
Supervised Multi-Regional Segmentation Machine Learning Architecture for Digital Twin Applications in Coastal Regions
May 23, 2023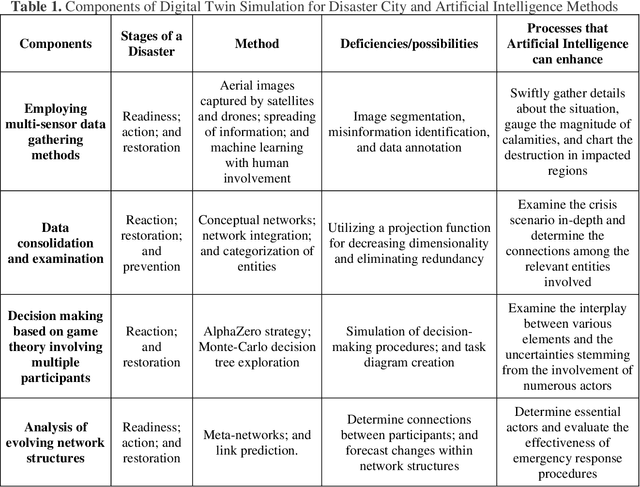
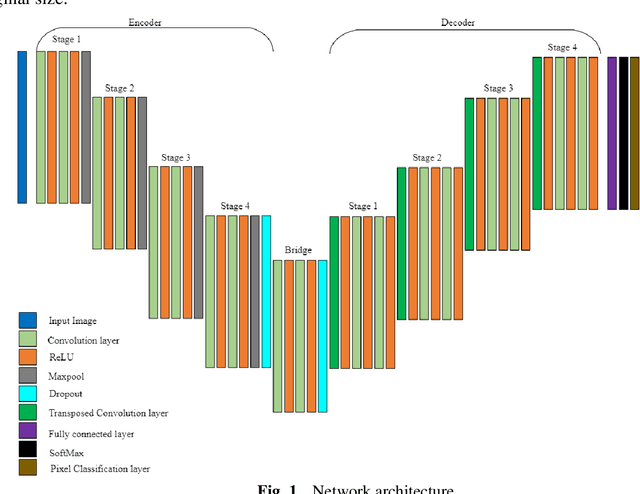
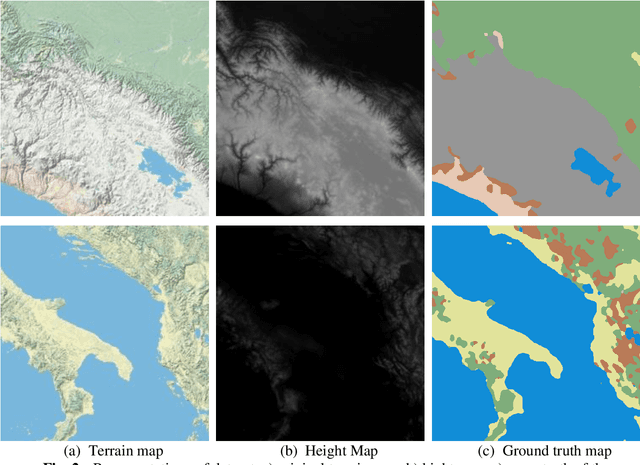
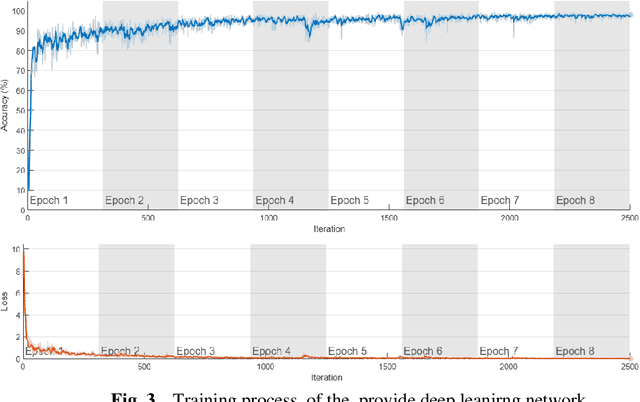
This study explores the use of a digital twin model and deep learning method to build a global terrain and altitude map based on USGS information. The goal is to artistically represent various landforms while incorporating precise elevation modifications in the terrain map and encoding land height in the altitude map. A random selection of 5000 segments from the worldwide map guarantees the inclusion of significant characteristics in the subsets, with rescaling according to latitude accounting for distortions caused by map projection. The process of generating segmentation maps involves using unsupervised clustering and classification methods, segmenting the terrain into seven groups: Water, Grassland, Forest, Hills, Desert, Mountain, and Tundra. Each group is assigned a unique color, and median filtering is used to improve map characteristics. Random parameters are added to provide diversity and avoid duplication in overlapping image sets. The U-Net network is deployed for the segmentation task, with training conducted on the seven terrain classes. Cross-validation is carried out every 10 epochs to gauge the model's performance. The segmentation maps produced accurately categorize the terrain, as evidenced by the ROC curve and AUC values. The main goal of this research is to create a digital twin model of Florida's coastal area. This is achieved through the application of deep learning methods and satellite imagery from Google Earth, resulting in a detailed depiction of the coast of Florida. The digital twin acts as both a physical and a simulation model of the area, emphasizing its capability to capture and replicate real-world locations. The model effectively creates a global terrain and altitude map with precise segmentation and capture of important land features. The results confirm the effectiveness of the digital twin, especially in depicting Florida's coastline.