 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Machine-Learned Invertible Coarse Graining for Multiscale Molecular Modeling
May 02, 2023
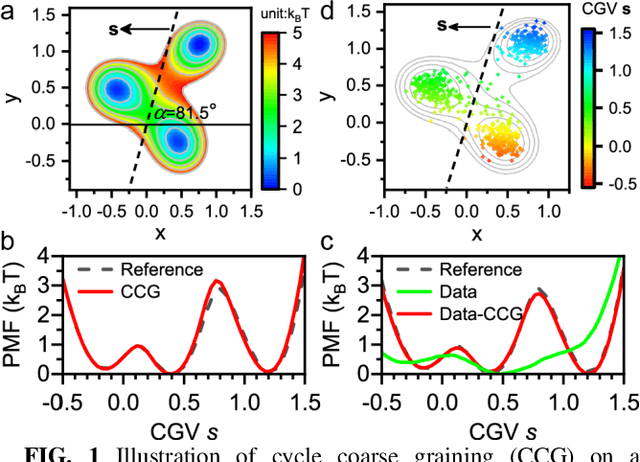
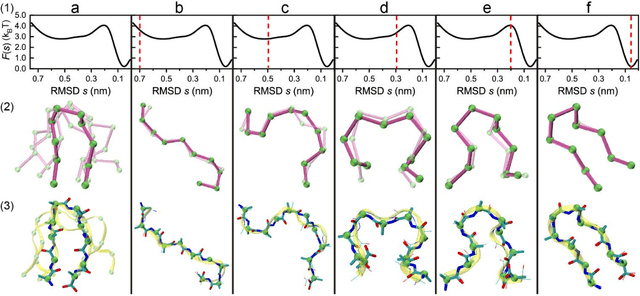
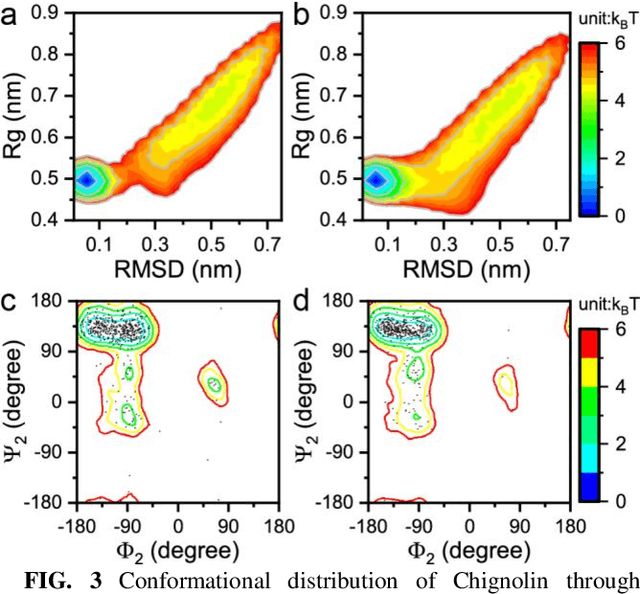
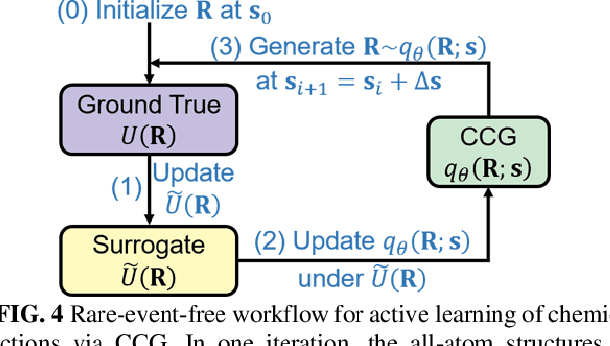
Multiscale molecular modeling is widely applied in scientific research of molecular properties over large time and length scales. Two specific challenges are commonly present in multiscale modeling, provided that information between the coarse and fine representations of molecules needs to be properly exchanged: One is to construct coarse grained (CG) models by passing information from the fine to coarse levels; the other is to restore finer molecular details given CG configurations. Although these two problems are commonly addressed independently, in this work, we present a theory connecting them, and develop a methodology called Cycle Coarse Graining (CCG) to solve both problems in a unified manner. In CCG, reconstruction can be achieved via a tractable optimization process, leading to a general method to retrieve fine details from CG simulations, which in turn, delivers a new solution to the CG problem, yielding an efficient way to calculate free energies in a rare-event-free manner. CCG thus provides a systematic way for multiscale molecular modeling, where the finer details of CG simulations can be efficiently retrieved, and the CG models can be improved consistently.
StructGPT: A General Framework for Large Language Model to Reason over Structured Data
May 16, 2023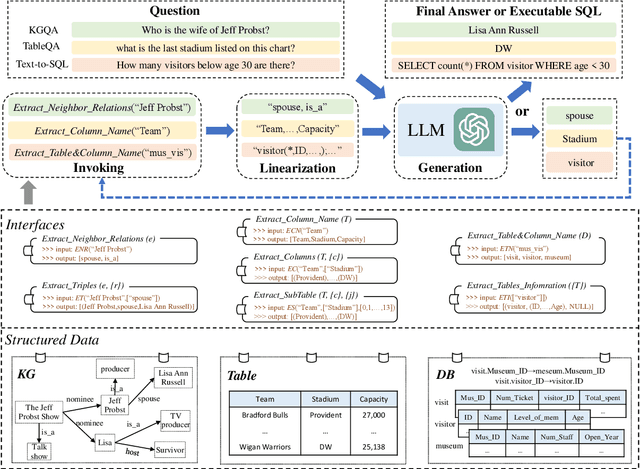
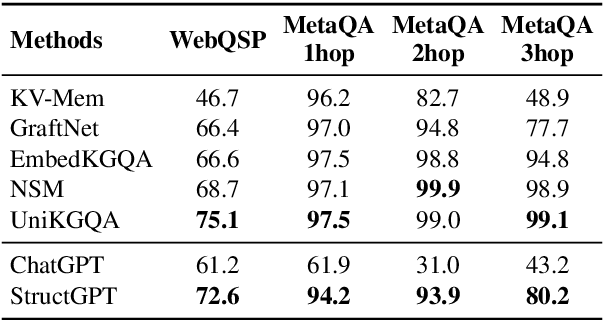
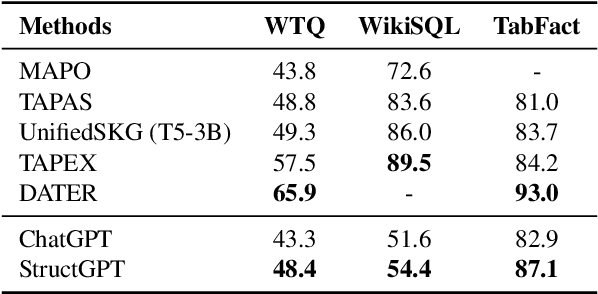
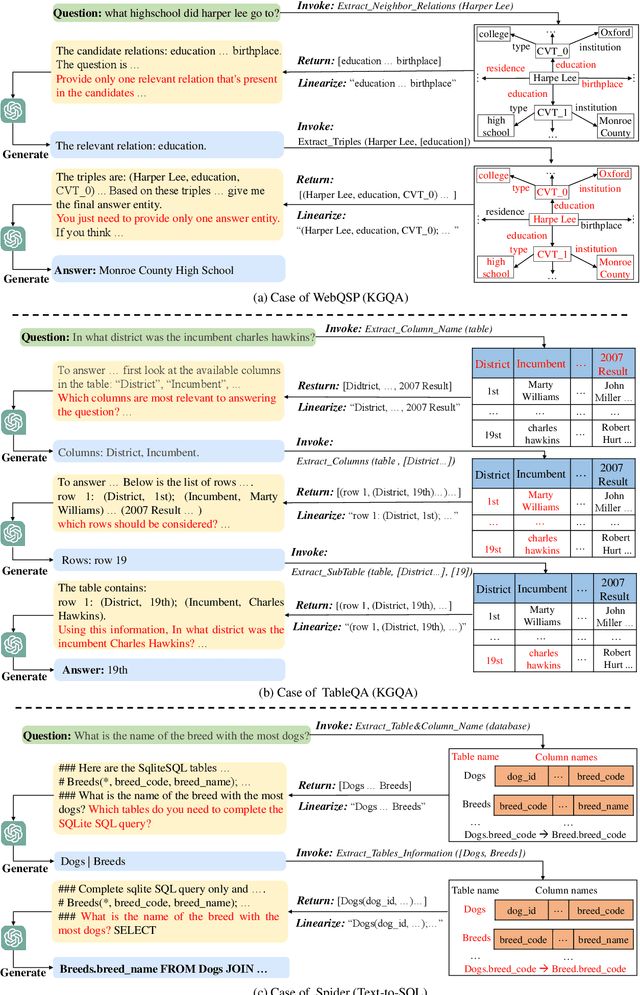
In this paper, we study how to improve the zero-shot reasoning ability of large language models~(LLMs) over structured data in a unified way. Inspired by the study on tool augmentation for LLMs, we develop an \emph{Iterative Reading-then-Reasoning~(IRR)} approach for solving question answering tasks based on structured data, called \textbf{StructGPT}. In our approach, we construct the specialized function to collect relevant evidence from structured data (\ie \emph{reading}), and let LLMs concentrate the reasoning task based on the collected information (\ie \emph{reasoning}). Specially, we propose an \emph{invoking-linearization-generation} procedure to support LLMs in reasoning on the structured data with the help of the external interfaces. By iterating this procedures with provided interfaces, our approach can gradually approach the target answer to a given query. Extensive experiments conducted on three types of structured data demonstrate the effectiveness of our approach, which can significantly boost the performance of ChatGPT and achieve comparable performance against the full-data supervised-tuning baselines. Our codes and data are publicly available at~\url{https://github.com/RUCAIBox/StructGPT}.
Evaluation of self-supervised pre-training for automatic infant movement classification using wearable movement sensors
May 16, 2023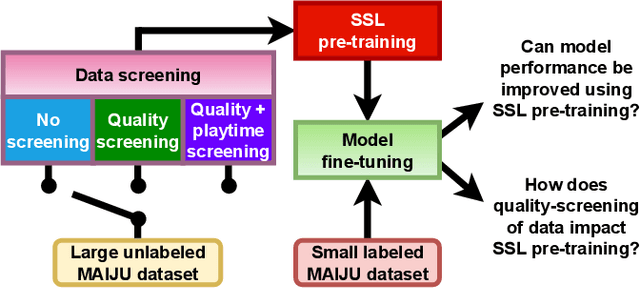
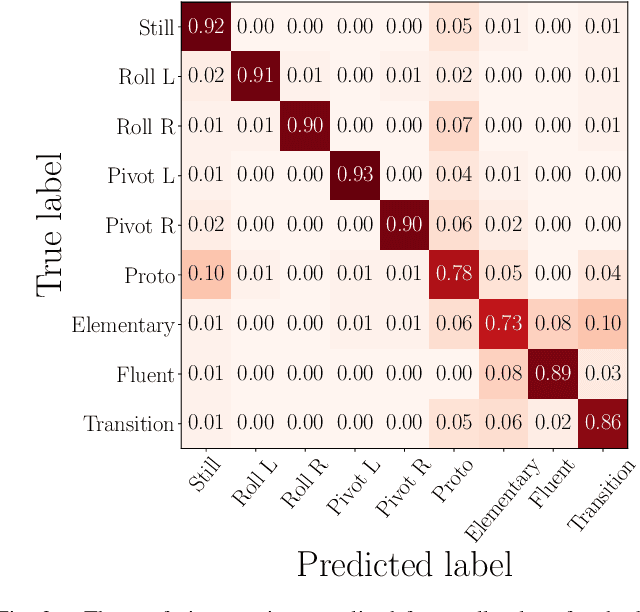
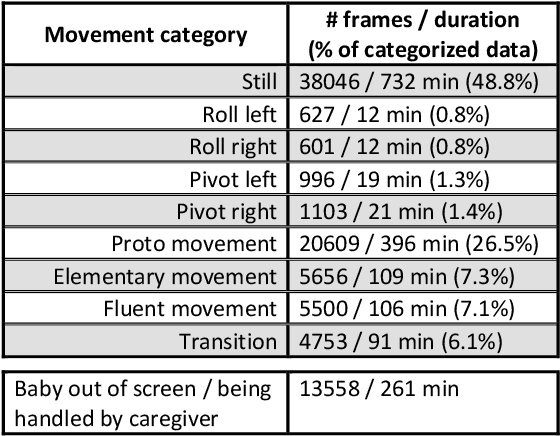
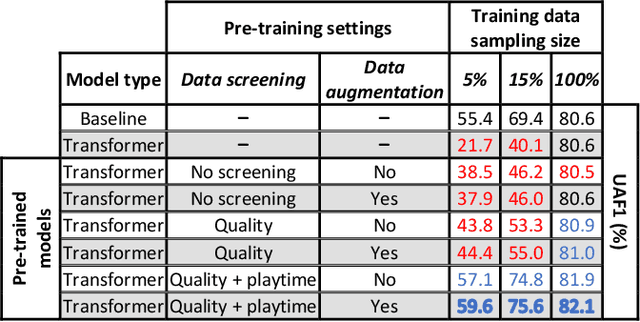
The recently-developed infant wearable MAIJU provides a means to automatically evaluate infants' motor performance in an objective and scalable manner in out-of-hospital settings. This information could be used for developmental research and to support clinical decision-making, such as detection of developmental problems and guiding of their therapeutic interventions. MAIJU-based analyses rely fully on the classification of infant's posture and movement; it is hence essential to study ways to increase the accuracy of such classifications, aiming to increase the reliability and robustness of the automated analysis. Here, we investigated how self-supervised pre-training improves performance of the classifiers used for analyzing MAIJU recordings, and we studied whether performance of the classifier models is affected by context-selective quality-screening of pre-training data to exclude periods of little infant movement or with missing sensors. Our experiments show that i) pre-training the classifier with unlabeled data leads to a robust accuracy increase of subsequent classification models, and ii) selecting context-relevant pre-training data leads to substantial further improvements in the classifier performance.
Sequence-to-Sequence Pre-training with Unified Modality Masking for Visual Document Understanding
May 16, 2023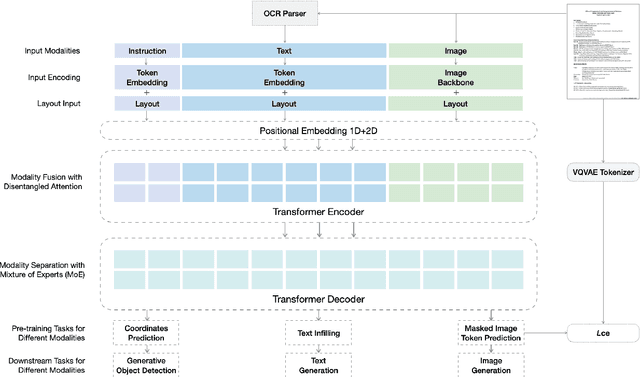
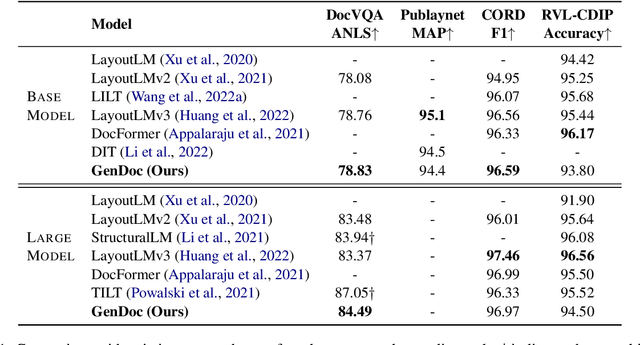


This paper presents GenDoc, a general sequence-to-sequence document understanding model pre-trained with unified masking across three modalities: text, image, and layout. The proposed model utilizes an encoder-decoder architecture, which allows for increased adaptability to a wide range of downstream tasks with diverse output formats, in contrast to the encoder-only models commonly employed in document understanding. In addition to the traditional text infilling task used in previous encoder-decoder models, our pre-training extends to include tasks of masked image token prediction and masked layout prediction. We also design modality-specific instruction and adopt both disentangled attention and the mixture-of-modality-experts strategy to effectively capture the information leveraged by each modality. Evaluation of the proposed model through extensive experiments on several downstream tasks in document understanding demonstrates its ability to achieve superior or competitive performance compared to state-of-the-art approaches. Our analysis further suggests that GenDoc is more robust than the encoder-only models in scenarios where the OCR quality is imperfect.
Automatic learning algorithm selection for classification via convolutional neural networks
May 16, 2023
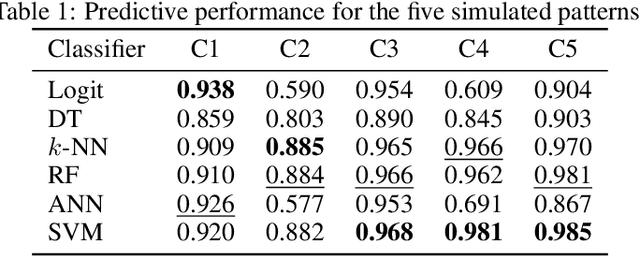
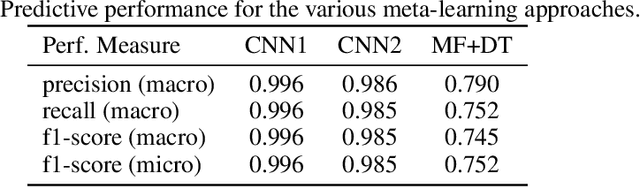
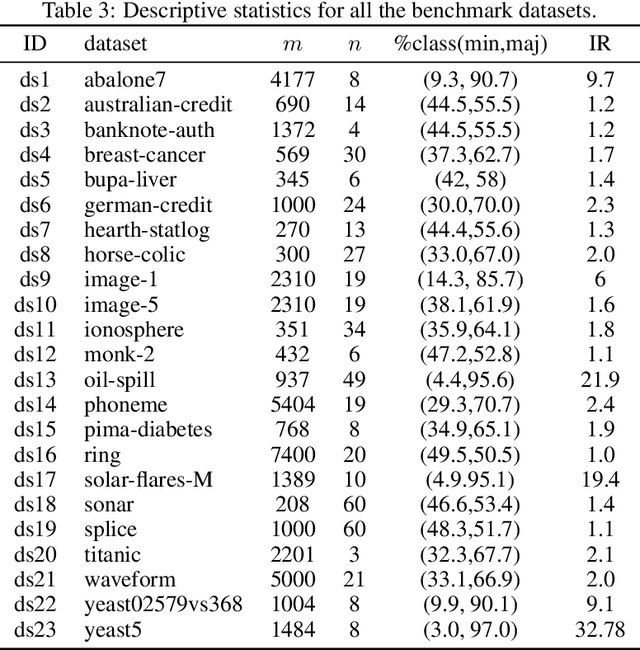
As in any other task, the process of building machine learning models can benefit from prior experience. Meta-learning for classifier selection gains knowledge from characteristics of different datasets and/or previous performance of machine learning techniques to make better decisions for the current modeling process. Meta-learning approaches first collect meta-data that describe this prior experience and then use it as input for an algorithm selection model. In this paper, however, we propose an automatic learning scheme in which we train convolutional networks directly with the information of tabular datasets for binary classification. The goal of this study is to learn the inherent structure of the data without identifying meta-features. Experiments with simulated datasets show that the proposed approach achieves nearly perfect performance in identifying linear and nonlinear patterns, outperforming the traditional two-step method based on meta-features. The proposed method is then applied to real-world datasets, making suggestions about the best classifiers that can be considered based on the structure of the data.
ROI-based Deep Image Compression with Swin Transformers
May 12, 2023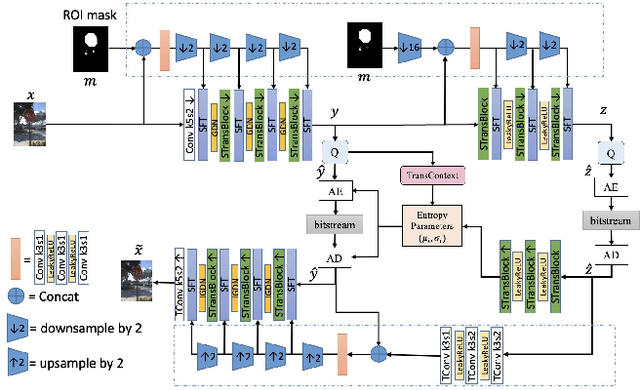

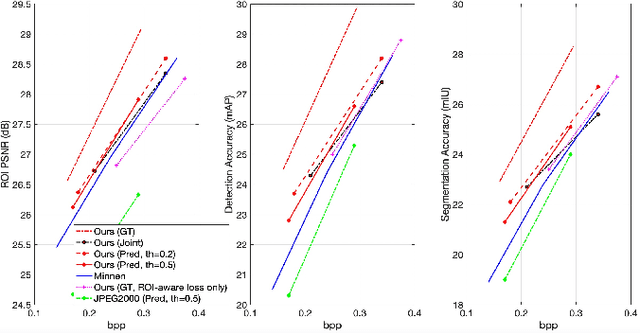

Encoding the Region Of Interest (ROI) with better quality than the background has many applications including video conferencing systems, video surveillance and object-oriented vision tasks. In this paper, we propose a ROI-based image compression framework with Swin transformers as main building blocks for the autoencoder network. The binary ROI mask is integrated into different layers of the network to provide spatial information guidance. Based on the ROI mask, we can control the relative importance of the ROI and non-ROI by modifying the corresponding Lagrange multiplier $ \lambda $ for different regions. Experimental results show our model achieves higher ROI PSNR than other methods and modest average PSNR for human evaluation. When tested on models pre-trained with original images, it has superior object detection and instance segmentation performance on the COCO validation dataset.
An Enhanced Sampling-Based Method With Modified Next-Best View Strategy For 2D Autonomous Robot Exploration
May 08, 2023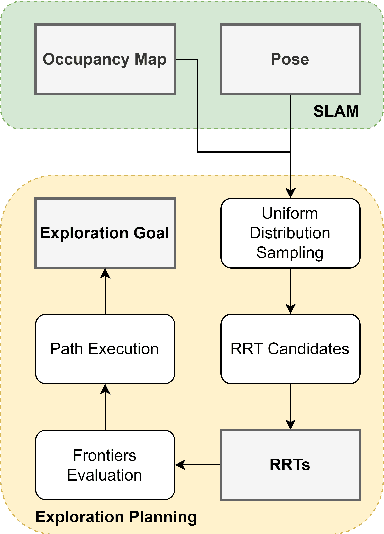
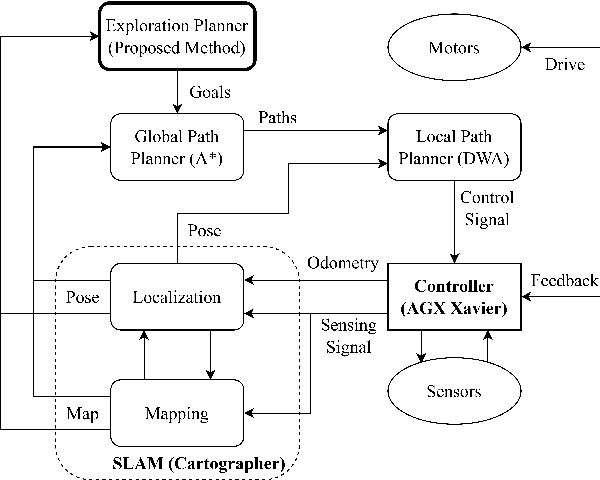
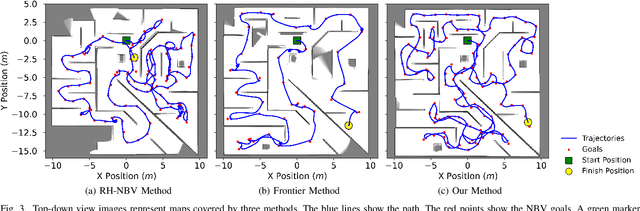
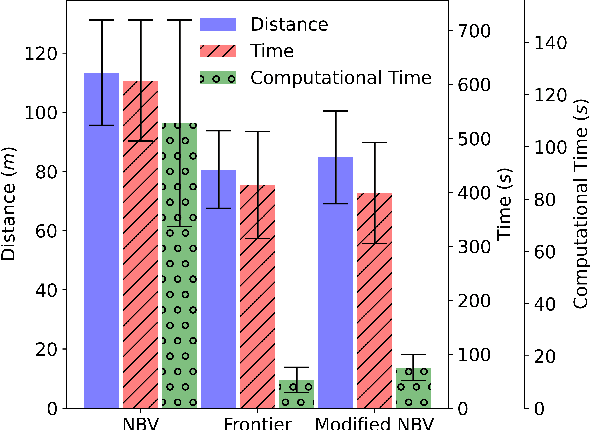
Autonomous exploration is a new technology in the field of robotics that has found widespread application due to its objective to help robots independently localize, scan maps, and navigate any terrain without human control. Up to present, the sampling-based exploration strategies have been the most effective for aerial and ground vehicles equipped with depth sensors producing three-dimensional point clouds. Those methods utilize the sampling task to choose random points or make samples based on Rapidly-exploring Random Trees (RRT). Then, they decide on frontiers or Next Best Views (NBV) with useful volumetric information. However, most state-of-the-art sampling-based methodology is challenging to implement in two-dimensional robots due to the lack of environmental knowledge, thus resulting in a bad volumetric gain for evaluating random destinations. This study proposed an enhanced sampling-based solution for indoor robot exploration to decide Next Best View (NBV) in 2D environments. Our method makes RRT until have the endpoints as frontiers and evaluates those with the enhanced utility function. The volumetric information obtained from environments was estimated using non-uniform distribution to determine cells that are occupied and have an uncertain probability. Compared to the sampling-based Frontier Detection and Receding Horizon NBV approaches, the methodology executed performed better in Gazebo platform-simulated environments, achieving a significantly larger explored area, with the average distance and time traveled being reduced. Moreover, the operated proposed method on an author-built 2D robot exploring the entire natural environment confirms that the method is effective and applicable in real-world scenarios.
Efficient Online Decision Tree Learning with Active Feature Acquisition
May 03, 2023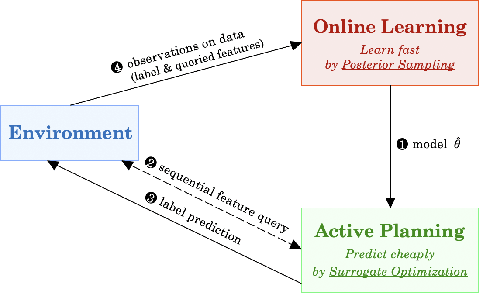



Constructing decision trees online is a classical machine learning problem. Existing works often assume that features are readily available for each incoming data point. However, in many real world applications, both feature values and the labels are unknown a priori and can only be obtained at a cost. For example, in medical diagnosis, doctors have to choose which tests to perform (i.e., making costly feature queries) on a patient in order to make a diagnosis decision (i.e., predicting labels). We provide a fresh perspective to tackle this practical challenge. Our framework consists of an active planning oracle embedded in an online learning scheme for which we investigate several information acquisition functions. Specifically, we employ a surrogate information acquisition function based on adaptive submodularity to actively query feature values with a minimal cost, while using a posterior sampling scheme to maintain a low regret for online prediction. We demonstrate the efficiency and effectiveness of our framework via extensive experiments on various real-world datasets. Our framework also naturally adapts to the challenging setting of online learning with concept drift and is shown to be competitive with baseline models while being more flexible.
Transcending Grids: Point Clouds and Surface Representations Powering Neurological Processing
May 17, 2023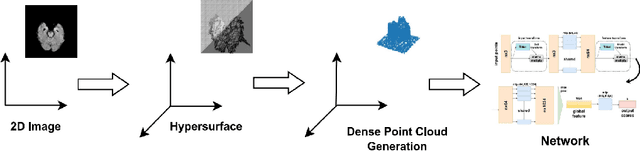
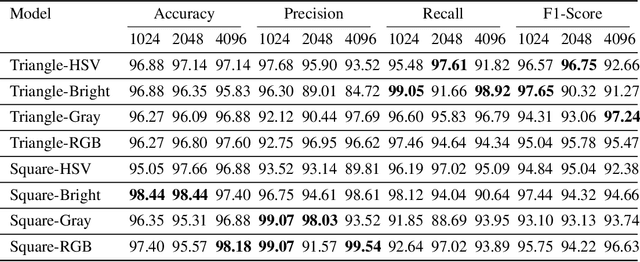
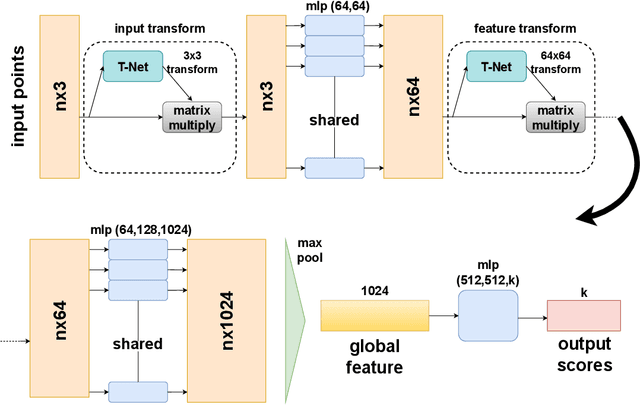
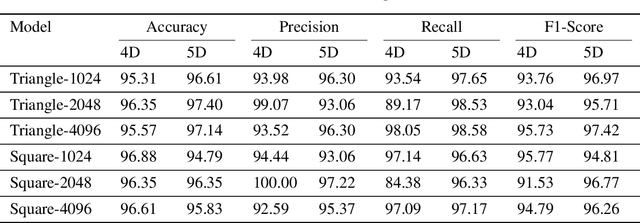
In healthcare, accurately classifying medical images is vital, but conventional methods often hinge on medical data with a consistent grid structure, which may restrict their overall performance. Recent medical research has been focused on tweaking the architectures to attain better performance without giving due consideration to the representation of data. In this paper, we present a novel approach for transforming grid based data into its higher dimensional representations, leveraging unstructured point cloud data structures. We first generate a sparse point cloud from an image by integrating pixel color information as spatial coordinates. Next, we construct a hypersurface composed of points based on the image dimensions, with each smooth section within this hypersurface symbolizing a specific pixel location. Polygonal face construction is achieved using an adjacency tensor. Finally, a dense point cloud is generated by densely sampling the constructed hypersurface, with a focus on regions of higher detail. The effectiveness of our approach is demonstrated on a publicly accessible brain tumor dataset, achieving significant improvements over existing classification techniques. This methodology allows the extraction of intricate details from the original image, opening up new possibilities for advanced image analysis and processing tasks.
Knowledge Graph Completion Models are Few-shot Learners: An Empirical Study of Relation Labeling in E-commerce with LLMs
May 17, 2023
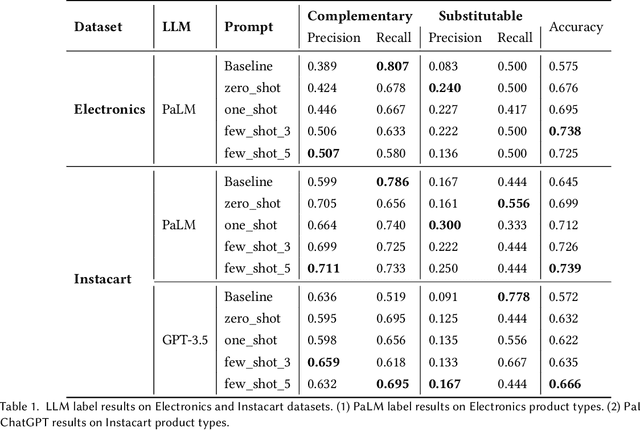
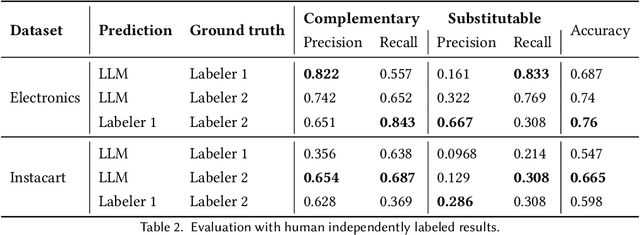
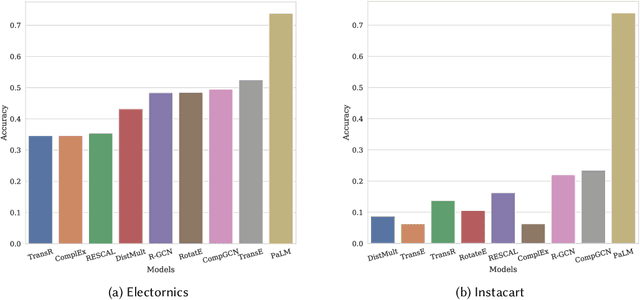
Knowledge Graphs (KGs) play a crucial role in enhancing e-commerce system performance by providing structured information about entities and their relationships, such as complementary or substitutable relations between products or product types, which can be utilized in recommender systems. However, relation labeling in KGs remains a challenging task due to the dynamic nature of e-commerce domains and the associated cost of human labor. Recently, breakthroughs in Large Language Models (LLMs) have shown surprising results in numerous natural language processing tasks. In this paper, we conduct an empirical study of LLMs for relation labeling in e-commerce KGs, investigating their powerful learning capabilities in natural language and effectiveness in predicting relations between product types with limited labeled data. We evaluate various LLMs, including PaLM and GPT-3.5, on benchmark datasets, demonstrating their ability to achieve competitive performance compared to humans on relation labeling tasks using just 1 to 5 labeled examples per relation. Additionally, we experiment with different prompt engineering techniques to examine their impact on model performance. Our results show that LLMs significantly outperform existing KG completion models in relation labeling for e-commerce KGs and exhibit performance strong enough to replace human labeling.