 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
VAKTA-SETU: A Speech-to-Speech Machine Translation Service in Select Indic Languages
May 21, 2023
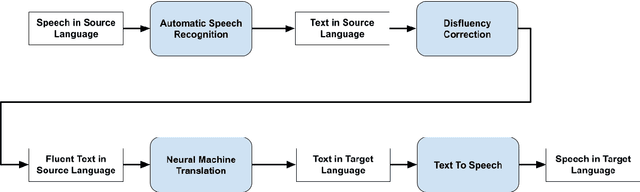
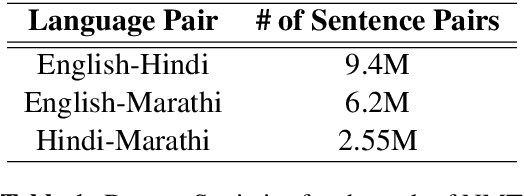
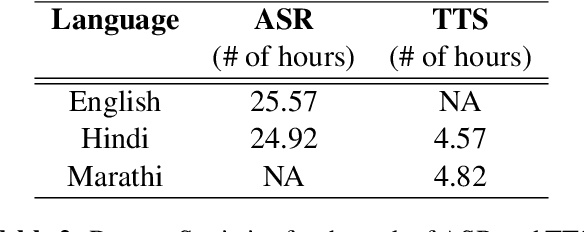

In this work, we present our deployment-ready Speech-to-Speech Machine Translation (SSMT) system for English-Hindi, English-Marathi, and Hindi-Marathi language pairs. We develop the SSMT system by cascading Automatic Speech Recognition (ASR), Disfluency Correction (DC), Machine Translation (MT), and Text-to-Speech Synthesis (TTS) models. We discuss the challenges faced during the research and development stage and the scalable deployment of the SSMT system as a publicly accessible web service. On the MT part of the pipeline too, we create a Text-to-Text Machine Translation (TTMT) service in all six translation directions involving English, Hindi, and Marathi. To mitigate data scarcity, we develop a LaBSE-based corpus filtering tool to select high-quality parallel sentences from a noisy pseudo-parallel corpus for training the TTMT system. All the data used for training the SSMT and TTMT systems and the best models are being made publicly available. Users of our system are (a) Govt. of India in the context of its new education policy (NEP), (b) tourists who criss-cross the multilingual landscape of India, (c) Indian Judiciary where a leading cause of the pendency of cases (to the order of 10 million as on date) is the translation of case papers, (d) farmers who need weather and price information and so on. We also share the feedback received from various stakeholders when our SSMT and TTMT systems were demonstrated in large public events.
HIINT: Historical, Intra- and Inter- personal Dynamics Modeling with Cross-person Memory Transformer
May 21, 2023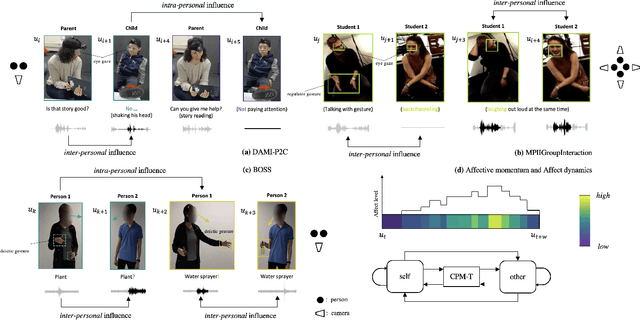
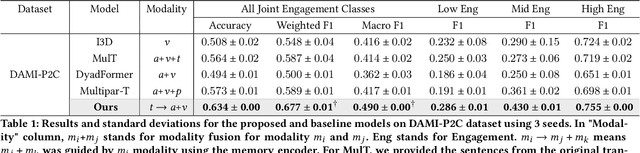
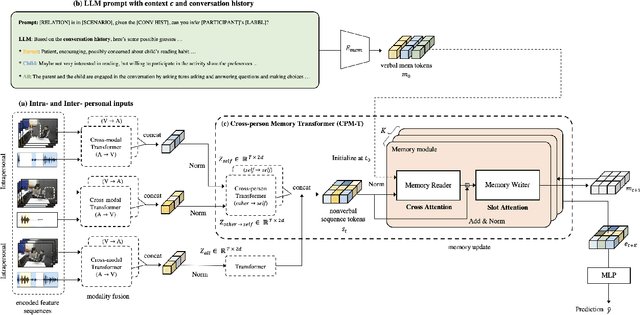
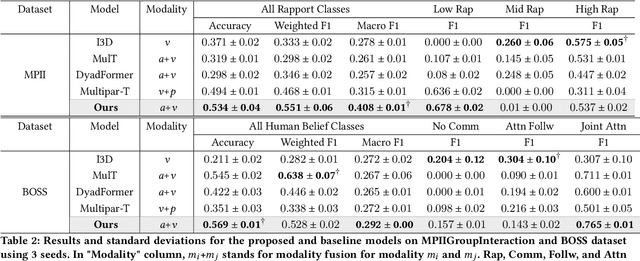
Accurately modeling affect dynamics, which refers to the changes and fluctuations in emotions and affective displays during human conversations, is crucial for understanding human interactions. By analyzing affect dynamics, we can gain insights into how people communicate, respond to different situations, and form relationships. However, modeling affect dynamics is challenging due to contextual factors, such as the complex and nuanced nature of interpersonal relationships, the situation, and other factors that influence affective displays. To address this challenge, we propose a Cross-person Memory Transformer (CPM-T) framework which is able to explicitly model affective dynamics (intrapersonal and interpersonal influences) by identifying verbal and non-verbal cues, and with a large language model to utilize the pre-trained knowledge and perform verbal reasoning. The CPM-T framework maintains memory modules to store and update the contexts within the conversation window, enabling the model to capture dependencies between earlier and later parts of a conversation. Additionally, our framework employs cross-modal attention to effectively align information from multi-modalities and leverage cross-person attention to align behaviors in multi-party interactions. We evaluate the effectiveness and generalizability of our approach on three publicly available datasets for joint engagement, rapport, and human beliefs prediction tasks. Remarkably, the CPM-T framework outperforms baseline models in average F1-scores by up to 7.3%, 9.3%, and 2.0% respectively. Finally, we demonstrate the importance of each component in the framework via ablation studies with respect to multimodal temporal behavior.
Learning Joint 2D & 3D Diffusion Models for Complete Molecule Generation
May 21, 2023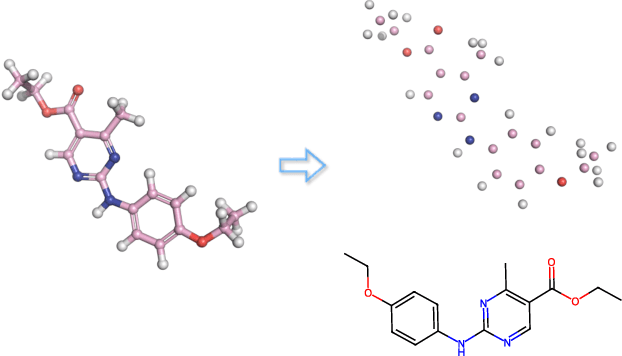
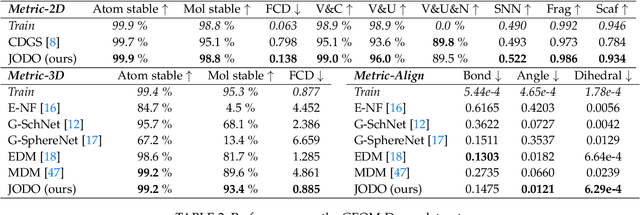
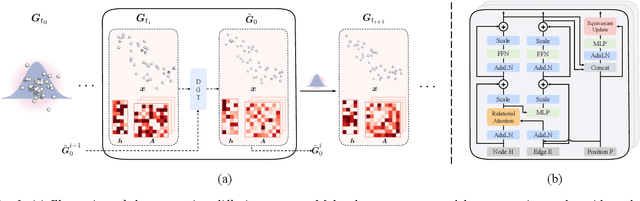
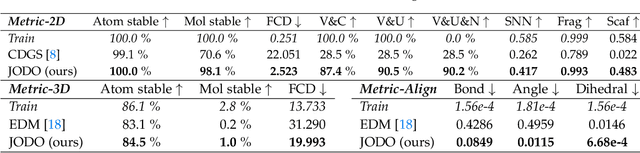
Designing new molecules is essential for drug discovery and material science. Recently, deep generative models that aim to model molecule distribution have made promising progress in narrowing down the chemical research space and generating high-fidelity molecules. However, current generative models only focus on modeling either 2D bonding graphs or 3D geometries, which are two complementary descriptors for molecules. The lack of ability to jointly model both limits the improvement of generation quality and further downstream applications. In this paper, we propose a new joint 2D and 3D diffusion model (JODO) that generates complete molecules with atom types, formal charges, bond information, and 3D coordinates. To capture the correlation between molecular graphs and geometries in the diffusion process, we develop a Diffusion Graph Transformer to parameterize the data prediction model that recovers the original data from noisy data. The Diffusion Graph Transformer interacts node and edge representations based on our relational attention mechanism, while simultaneously propagating and updating scalar features and geometric vectors. Our model can also be extended for inverse molecular design targeting single or multiple quantum properties. In our comprehensive evaluation pipeline for unconditional joint generation, the results of the experiment show that JODO remarkably outperforms the baselines on the QM9 and GEOM-Drugs datasets. Furthermore, our model excels in few-step fast sampling, as well as in inverse molecule design and molecular graph generation. Our code is provided in https://github.com/GRAPH-0/JODO.
Interactive Natural Language Processing
May 22, 2023
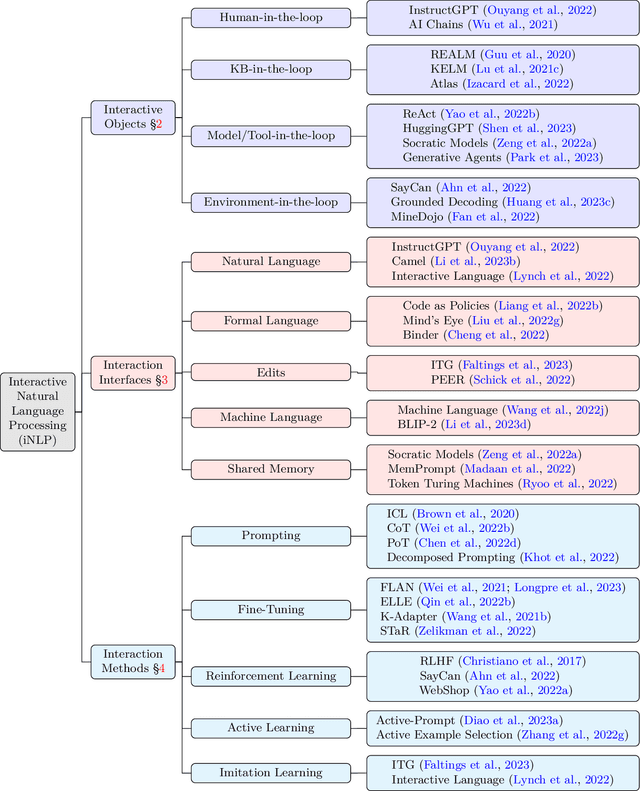
Interactive Natural Language Processing (iNLP) has emerged as a novel paradigm within the field of NLP, aimed at addressing limitations in existing frameworks while aligning with the ultimate goals of artificial intelligence. This paradigm considers language models as agents capable of observing, acting, and receiving feedback iteratively from external entities. Specifically, language models in this context can: (1) interact with humans for better understanding and addressing user needs, personalizing responses, aligning with human values, and improving the overall user experience; (2) interact with knowledge bases for enriching language representations with factual knowledge, enhancing the contextual relevance of responses, and dynamically leveraging external information to generate more accurate and informed responses; (3) interact with models and tools for effectively decomposing and addressing complex tasks, leveraging specialized expertise for specific subtasks, and fostering the simulation of social behaviors; and (4) interact with environments for learning grounded representations of language, and effectively tackling embodied tasks such as reasoning, planning, and decision-making in response to environmental observations. This paper offers a comprehensive survey of iNLP, starting by proposing a unified definition and framework of the concept. We then provide a systematic classification of iNLP, dissecting its various components, including interactive objects, interaction interfaces, and interaction methods. We proceed to delve into the evaluation methodologies used in the field, explore its diverse applications, scrutinize its ethical and safety issues, and discuss prospective research directions. This survey serves as an entry point for researchers who are interested in this rapidly evolving area and offers a broad view of the current landscape and future trajectory of iNLP.
Optimality Principles in Spacecraft Neural Guidance and Control
May 22, 2023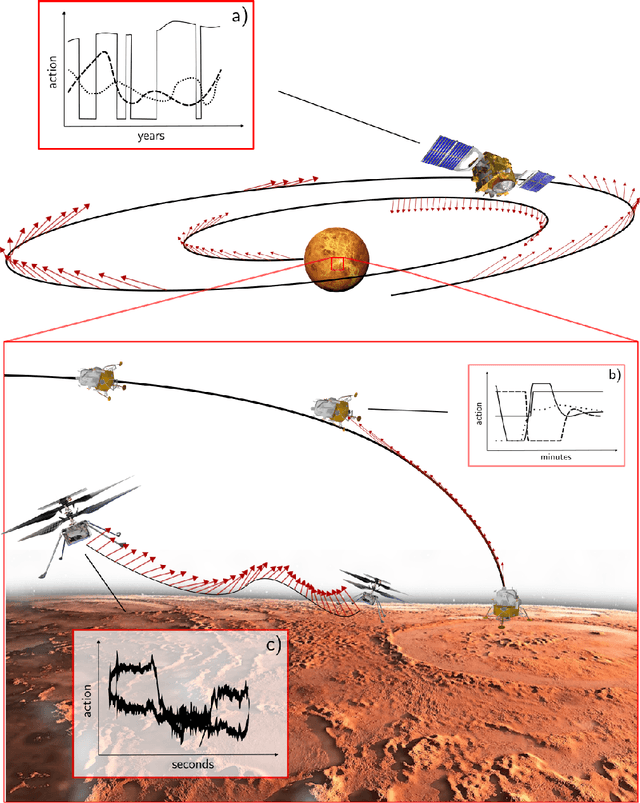

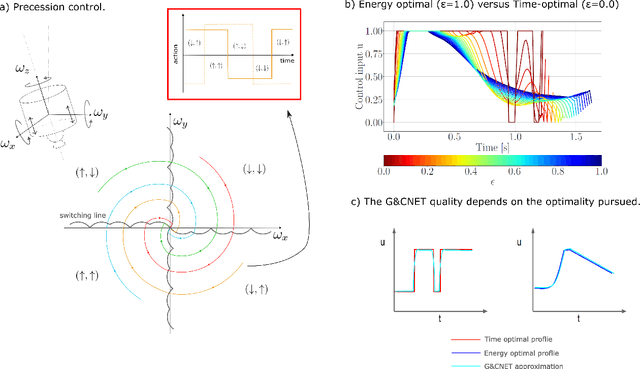
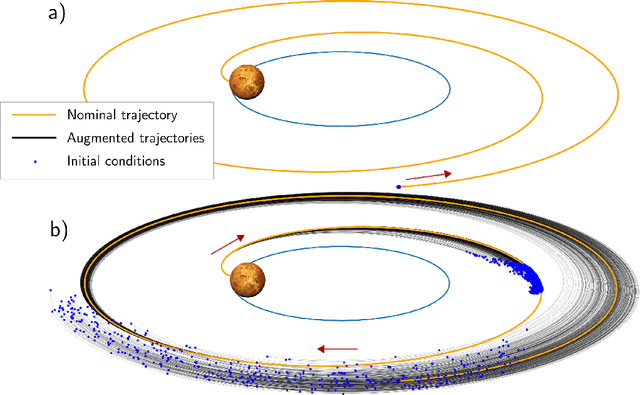
Spacecraft and drones aimed at exploring our solar system are designed to operate in conditions where the smart use of onboard resources is vital to the success or failure of the mission. Sensorimotor actions are thus often derived from high-level, quantifiable, optimality principles assigned to each task, utilizing consolidated tools in optimal control theory. The planned actions are derived on the ground and transferred onboard where controllers have the task of tracking the uploaded guidance profile. Here we argue that end-to-end neural guidance and control architectures (here called G&CNets) allow transferring onboard the burden of acting upon these optimality principles. In this way, the sensor information is transformed in real time into optimal plans thus increasing the mission autonomy and robustness. We discuss the main results obtained in training such neural architectures in simulation for interplanetary transfers, landings and close proximity operations, highlighting the successful learning of optimality principles by the neural model. We then suggest drone racing as an ideal gym environment to test these architectures on real robotic platforms, thus increasing confidence in their utilization on future space exploration missions. Drone racing shares with spacecraft missions both limited onboard computational capabilities and similar control structures induced from the optimality principle sought, but it also entails different levels of uncertainties and unmodelled effects. Furthermore, the success of G&CNets on extremely resource-restricted drones illustrates their potential to bring real-time optimal control within reach of a wider variety of robotic systems, both in space and on Earth.
Augmenting Passage Representations with Query Generation for Enhanced Cross-Lingual Dense Retrieval
May 06, 2023
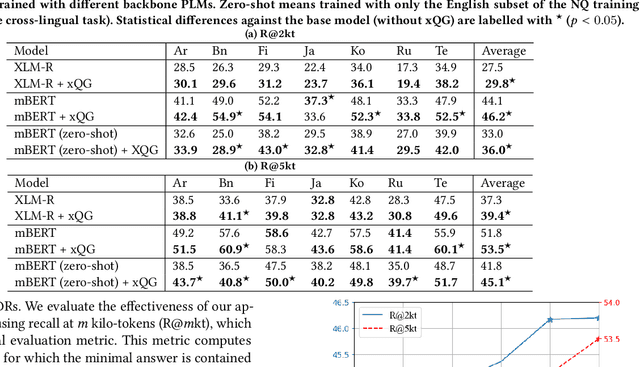
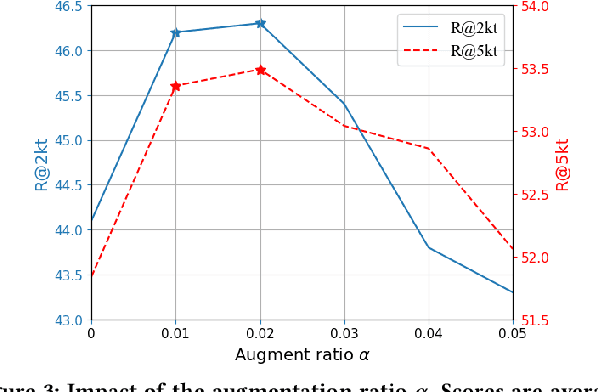
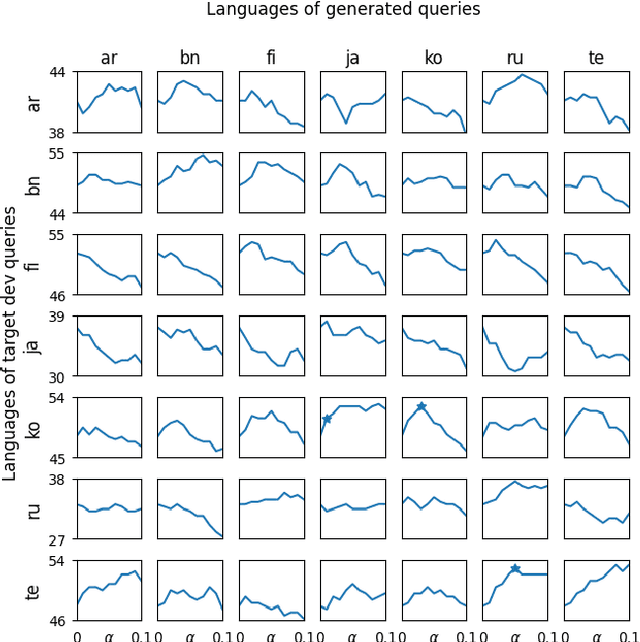
Effective cross-lingual dense retrieval methods that rely on multilingual pre-trained language models (PLMs) need to be trained to encompass both the relevance matching task and the cross-language alignment task. However, cross-lingual data for training is often scarcely available. In this paper, rather than using more cross-lingual data for training, we propose to use cross-lingual query generation to augment passage representations with queries in languages other than the original passage language. These augmented representations are used at inference time so that the representation can encode more information across the different target languages. Training of a cross-lingual query generator does not require additional training data to that used for the dense retriever. The query generator training is also effective because the pre-training task for the generator (T5 text-to-text training) is very similar to the fine-tuning task (generation of a query). The use of the generator does not increase query latency at inference and can be combined with any cross-lingual dense retrieval method. Results from experiments on a benchmark cross-lingual information retrieval dataset show that our approach can improve the effectiveness of existing cross-lingual dense retrieval methods. Implementation of our methods, along with all generated query files are made publicly available at https://github.com/ielab/xQG4xDR.
Unlocking Low-Light-Rainy Image Restoration by Pairwise Degradation Feature Vector Guidance
May 06, 2023
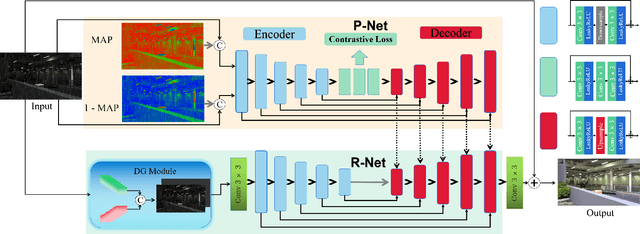

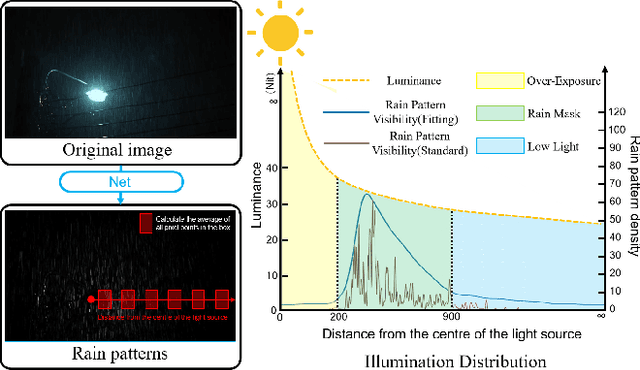
Rain in the dark is a common natural phenomenon. Photos captured in such a condition significantly impact the performance of various nighttime activities, such as autonomous driving, surveillance systems, and night photography. While existing methods designed for low-light enhancement or deraining show promising performance, they have limitations in simultaneously addressing the task of brightening low light and removing rain. Furthermore, using a cascade approach, such as ``deraining followed by low-light enhancement'' or vice versa, may lead to difficult-to-handle rain patterns or excessively blurred and overexposed images. To overcome these limitations, we propose an end-to-end network called $L^{2}RIRNet$ which can jointly handle low-light enhancement and deraining. Our network mainly includes a Pairwise Degradation Feature Vector Extraction Network (P-Net) and a Restoration Network (R-Net). P-Net can learn degradation feature vectors on the dark and light areas separately, using contrastive learning to guide the image restoration process. The R-Net is responsible for restoring the image. We also introduce an effective Fast Fourier - ResNet Detail Guidance Module (FFR-DG) that initially guides image restoration using detail image that do not contain degradation information but focus on texture detail information. Additionally, we contribute a dataset containing synthetic and real-world low-light-rainy images. Extensive experiments demonstrate that our $L^{2}RIRNet$ outperforms existing methods in both synthetic and complex real-world scenarios.
CEMFormer: Learning to Predict Driver Intentions from In-Cabin and External Cameras via Spatial-Temporal Transformers
May 13, 2023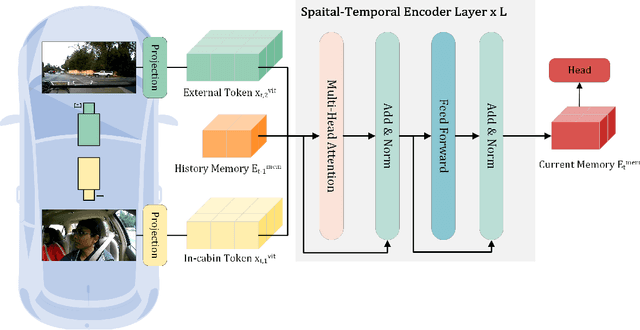
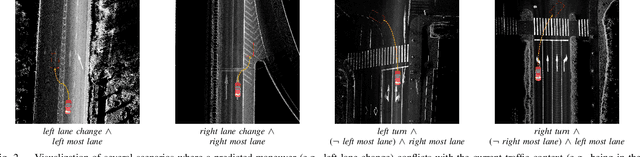
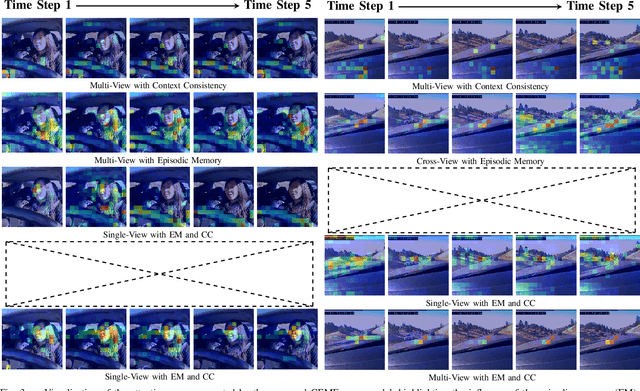
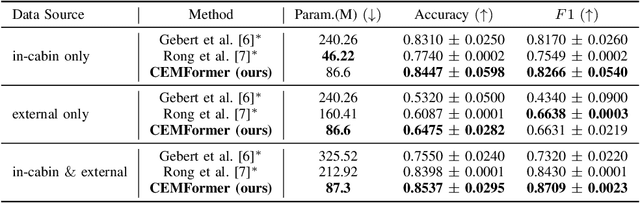
Driver intention prediction seeks to anticipate drivers' actions by analyzing their behaviors with respect to surrounding traffic environments. Existing approaches primarily focus on late-fusion techniques, and neglect the importance of maintaining consistency between predictions and prevailing driving contexts. In this paper, we introduce a new framework called Cross-View Episodic Memory Transformer (CEMFormer), which employs spatio-temporal transformers to learn unified memory representations for an improved driver intention prediction. Specifically, we develop a spatial-temporal encoder to integrate information from both in-cabin and external camera views, along with episodic memory representations to continuously fuse historical data. Furthermore, we propose a novel context-consistency loss that incorporates driving context as an auxiliary supervision signal to improve prediction performance. Comprehensive experiments on the Brain4Cars dataset demonstrate that CEMFormer consistently outperforms existing state-of-the-art methods in driver intention prediction.
StructGPT: A General Framework for Large Language Model to Reason over Structured Data
May 16, 2023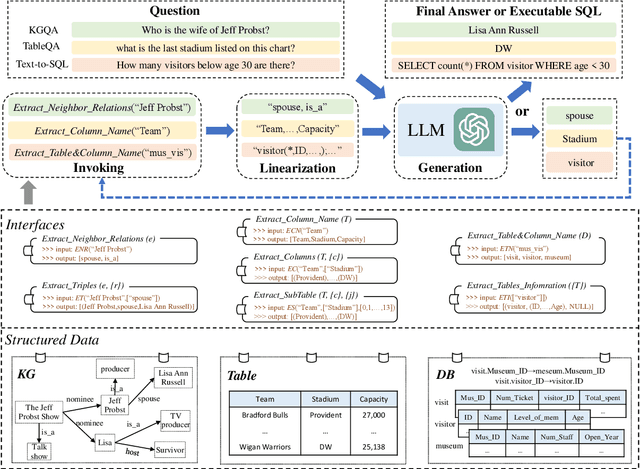
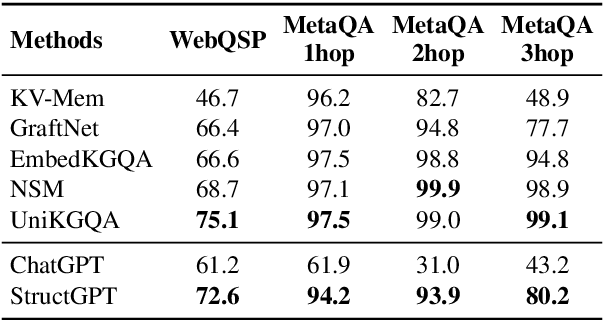
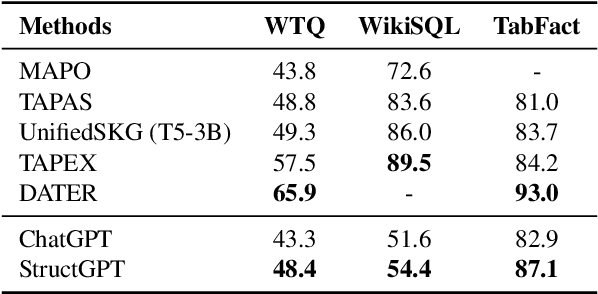
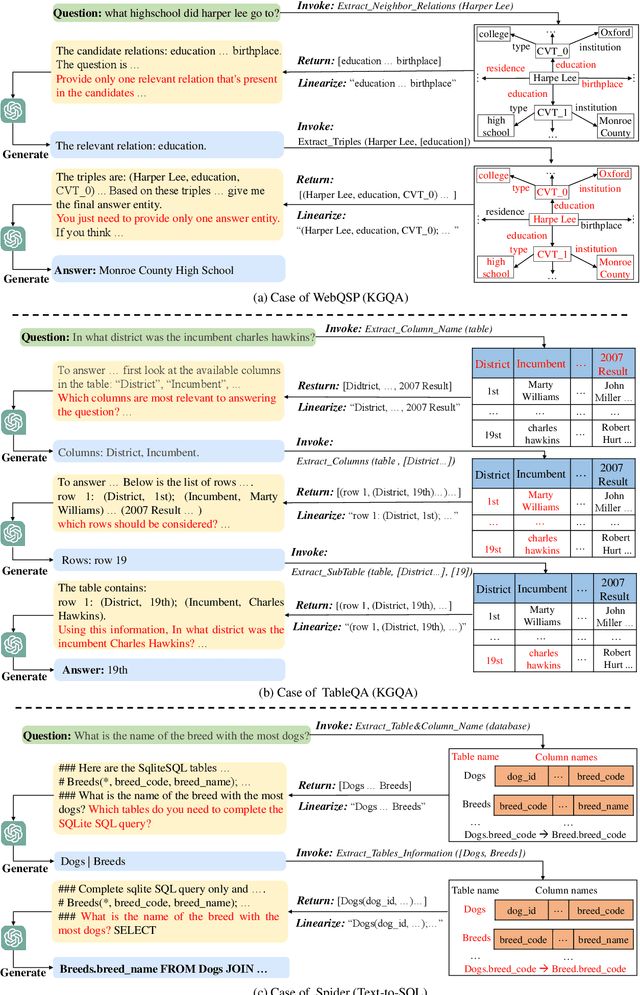
In this paper, we study how to improve the zero-shot reasoning ability of large language models~(LLMs) over structured data in a unified way. Inspired by the study on tool augmentation for LLMs, we develop an \emph{Iterative Reading-then-Reasoning~(IRR)} approach for solving question answering tasks based on structured data, called \textbf{StructGPT}. In our approach, we construct the specialized function to collect relevant evidence from structured data (\ie \emph{reading}), and let LLMs concentrate the reasoning task based on the collected information (\ie \emph{reasoning}). Specially, we propose an \emph{invoking-linearization-generation} procedure to support LLMs in reasoning on the structured data with the help of the external interfaces. By iterating this procedures with provided interfaces, our approach can gradually approach the target answer to a given query. Extensive experiments conducted on three types of structured data demonstrate the effectiveness of our approach, which can significantly boost the performance of ChatGPT and achieve comparable performance against the full-data supervised-tuning baselines. Our codes and data are publicly available at~\url{https://github.com/RUCAIBox/StructGPT}.
Evaluation of self-supervised pre-training for automatic infant movement classification using wearable movement sensors
May 16, 2023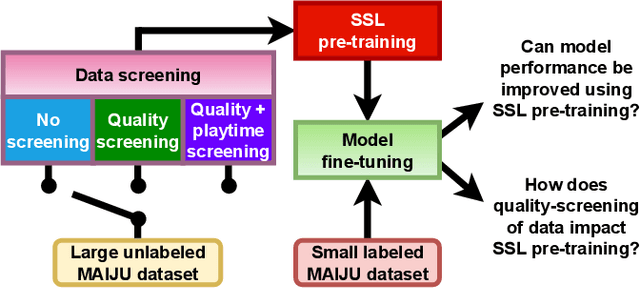
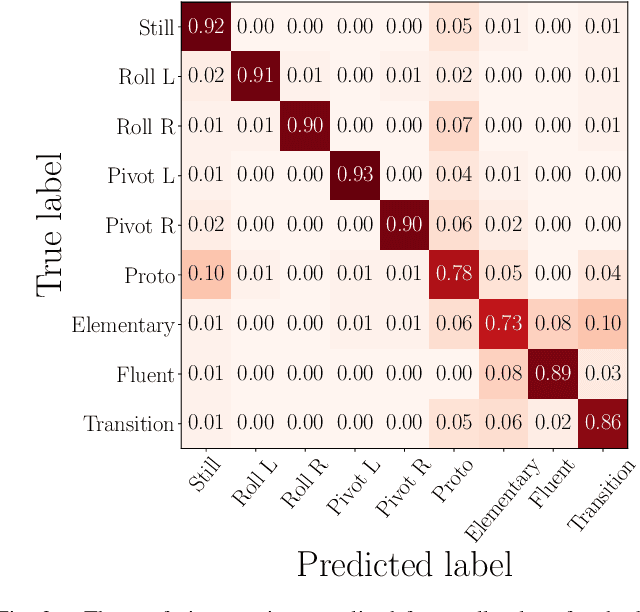
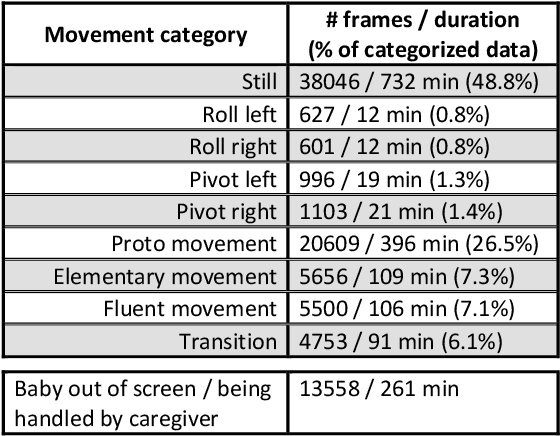
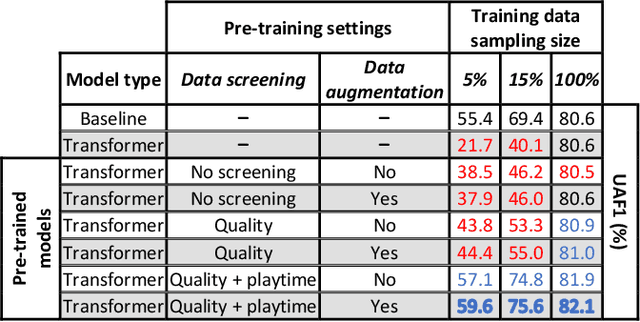
The recently-developed infant wearable MAIJU provides a means to automatically evaluate infants' motor performance in an objective and scalable manner in out-of-hospital settings. This information could be used for developmental research and to support clinical decision-making, such as detection of developmental problems and guiding of their therapeutic interventions. MAIJU-based analyses rely fully on the classification of infant's posture and movement; it is hence essential to study ways to increase the accuracy of such classifications, aiming to increase the reliability and robustness of the automated analysis. Here, we investigated how self-supervised pre-training improves performance of the classifiers used for analyzing MAIJU recordings, and we studied whether performance of the classifier models is affected by context-selective quality-screening of pre-training data to exclude periods of little infant movement or with missing sensors. Our experiments show that i) pre-training the classifier with unlabeled data leads to a robust accuracy increase of subsequent classification models, and ii) selecting context-relevant pre-training data leads to substantial further improvements in the classifier performance.