 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Better Contrastive View from Radiologist's Gaze
May 15, 2023
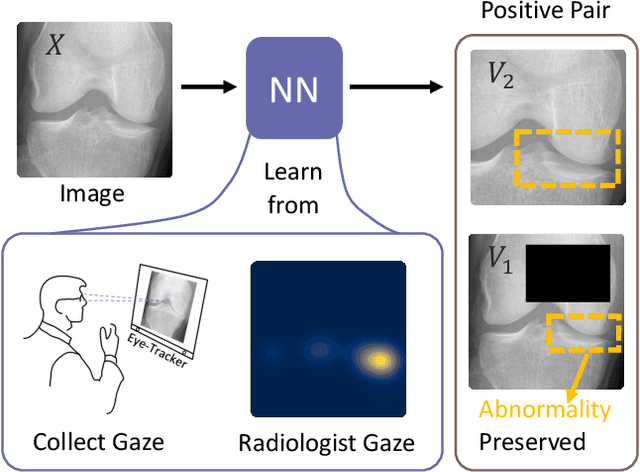
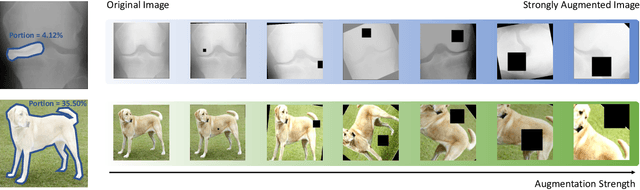
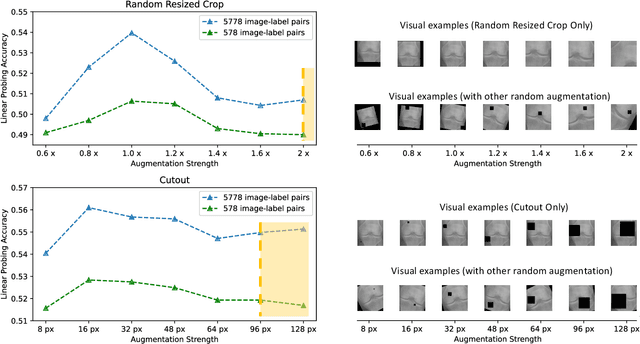
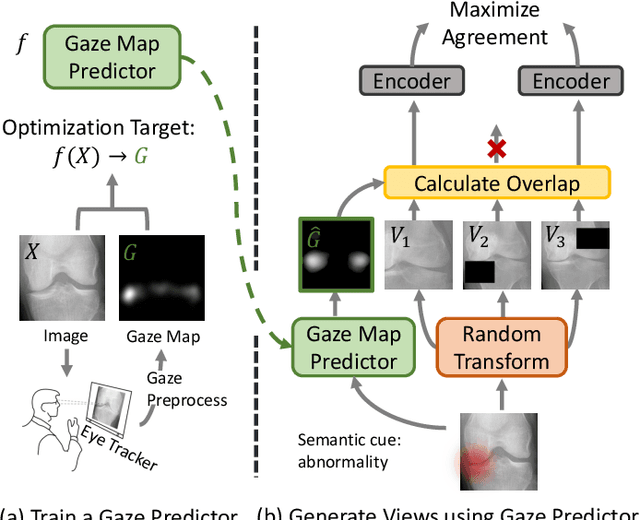
Recent self-supervised contrastive learning methods greatly benefit from the Siamese structure that aims to minimizing distances between positive pairs. These methods usually apply random data augmentation to input images, expecting the augmented views of the same images to be similar and positively paired. However, random augmentation may overlook image semantic information and degrade the quality of augmented views in contrastive learning. This issue becomes more challenging in medical images since the abnormalities related to diseases can be tiny, and are easy to be corrupted (e.g., being cropped out) in the current scheme of random augmentation. In this work, we first demonstrate that, for widely-used X-ray images, the conventional augmentation prevalent in contrastive pre-training can affect the performance of the downstream diagnosis or classification tasks. Then, we propose a novel augmentation method, i.e., FocusContrast, to learn from radiologists' gaze in diagnosis and generate contrastive views for medical images with guidance from radiologists' visual attention. Specifically, we track the gaze movement of radiologists and model their visual attention when reading to diagnose X-ray images. The learned model can predict visual attention of the radiologists given a new input image, and further guide the attention-aware augmentation that hardly neglects the disease-related abnormalities. As a plug-and-play and framework-agnostic module, FocusContrast consistently improves state-of-the-art contrastive learning methods of SimCLR, MoCo, and BYOL by 4.0~7.0% in classification accuracy on a knee X-ray dataset.
HIORE: Leveraging High-order Interactions for Unified Entity Relation Extraction
May 07, 2023
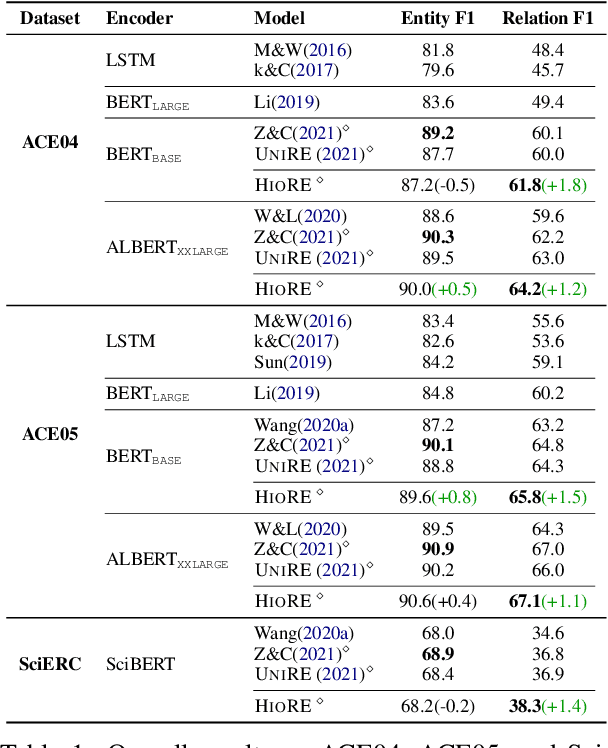
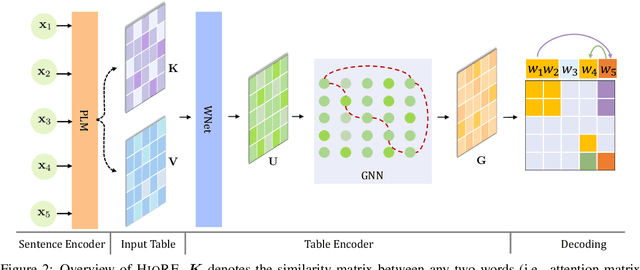
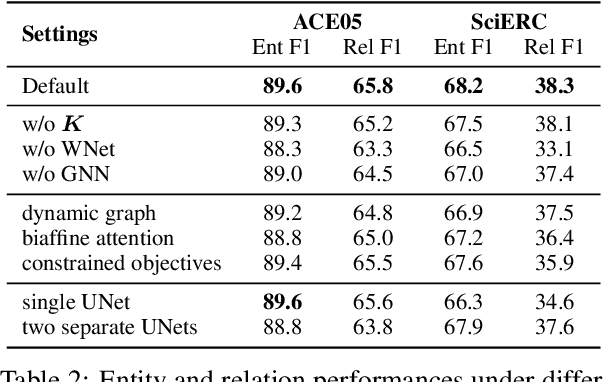
Entity relation extraction consists of two sub-tasks: entity recognition and relation extraction. Existing methods either tackle these two tasks separately or unify them with word-by-word interactions. In this paper, we propose HIORE, a new method for unified entity relation extraction. The key insight is to leverage the high-order interactions, i.e., the complex association among word pairs, which contains richer information than the first-order word-by-word interactions. For this purpose, we first devise a W-shape DNN (WNet) to capture coarse-level high-order connections. Then, we build a heuristic high-order graph and further calibrate the representations with a graph neural network (GNN). Experiments on three benchmarks (ACE04, ACE05, SciERC) show that HIORE achieves the state-of-the-art performance on relation extraction and an improvement of 1.1~1.8 F1 points over the prior best unified model.
PanFlowNet: A Flow-Based Deep Network for Pan-sharpening
May 16, 2023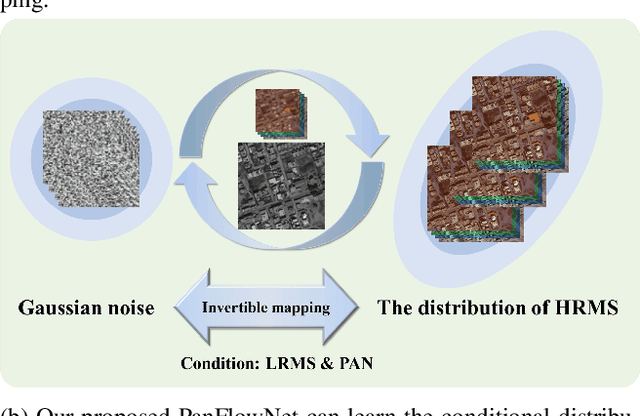
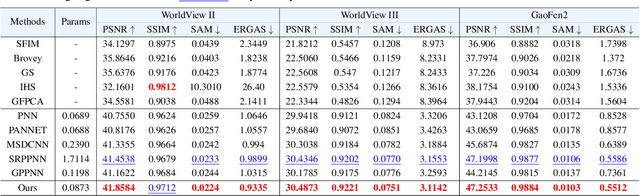
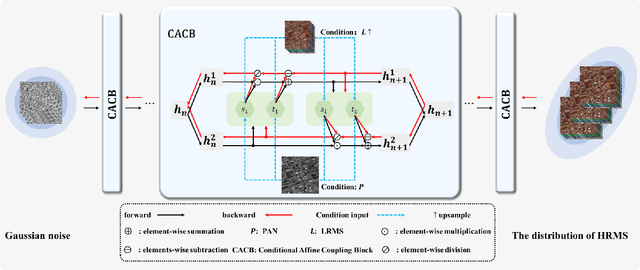
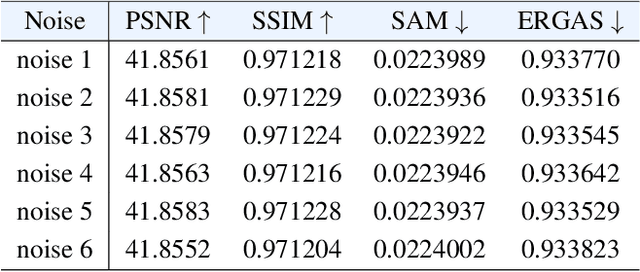
Pan-sharpening aims to generate a high-resolution multispectral (HRMS) image by integrating the spectral information of a low-resolution multispectral (LRMS) image with the texture details of a high-resolution panchromatic (PAN) image. It essentially inherits the ill-posed nature of the super-resolution (SR) task that diverse HRMS images can degrade into an LRMS image. However, existing deep learning-based methods recover only one HRMS image from the LRMS image and PAN image using a deterministic mapping, thus ignoring the diversity of the HRMS image. In this paper, to alleviate this ill-posed issue, we propose a flow-based pan-sharpening network (PanFlowNet) to directly learn the conditional distribution of HRMS image given LRMS image and PAN image instead of learning a deterministic mapping. Specifically, we first transform this unknown conditional distribution into a given Gaussian distribution by an invertible network, and the conditional distribution can thus be explicitly defined. Then, we design an invertible Conditional Affine Coupling Block (CACB) and further build the architecture of PanFlowNet by stacking a series of CACBs. Finally, the PanFlowNet is trained by maximizing the log-likelihood of the conditional distribution given a training set and can then be used to predict diverse HRMS images. The experimental results verify that the proposed PanFlowNet can generate various HRMS images given an LRMS image and a PAN image. Additionally, the experimental results on different kinds of satellite datasets also demonstrate the superiority of our PanFlowNet compared with other state-of-the-art methods both visually and quantitatively.
Blind Image Quality Assessment via Transformer Predicted Error Map and Perceptual Quality Token
May 16, 2023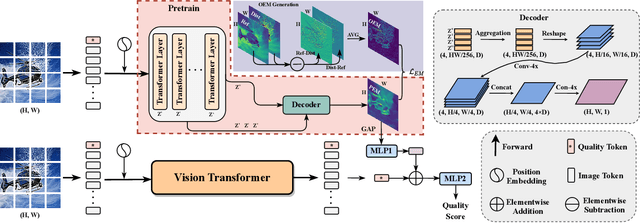
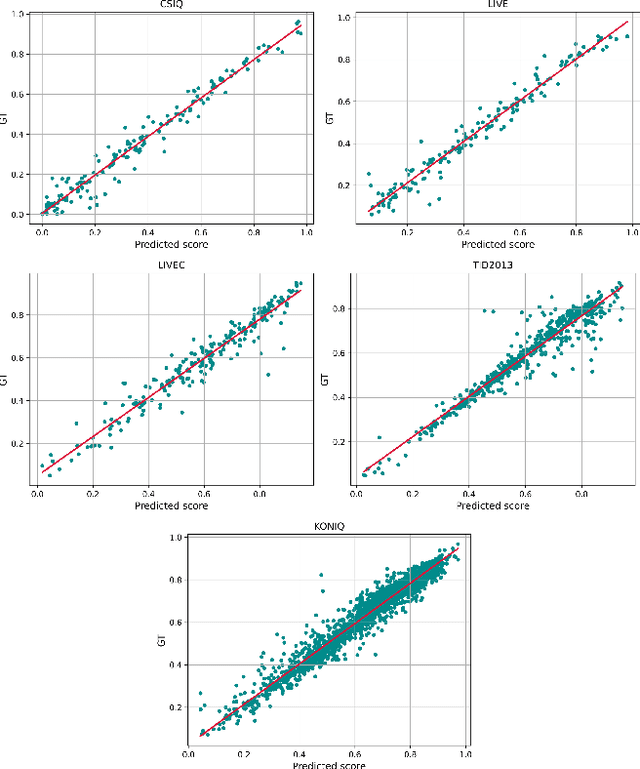

Image quality assessment is a fundamental problem in the field of image processing, and due to the lack of reference images in most practical scenarios, no-reference image quality assessment (NR-IQA), has gained increasing attention recently. With the development of deep learning technology, many deep neural network-based NR-IQA methods have been developed, which try to learn the image quality based on the understanding of database information. Currently, Transformer has achieved remarkable progress in various vision tasks. Since the characteristics of the attention mechanism in Transformer fit the global perceptual impact of artifacts perceived by a human, Transformer is thus well suited for image quality assessment tasks. In this paper, we propose a Transformer based NR-IQA model using a predicted objective error map and perceptual quality token. Specifically, we firstly generate the predicted error map by pre-training one model consisting of a Transformer encoder and decoder, in which the objective difference between the distorted and the reference images is used as supervision. Then, we freeze the parameters of the pre-trained model and design another branch using the vision Transformer to extract the perceptual quality token for feature fusion with the predicted error map. Finally, the fused features are regressed to the final image quality score. Extensive experiments have shown that our proposed method outperforms the current state-of-the-art in both authentic and synthetic image databases. Moreover, the attentional map extracted by the perceptual quality token also does conform to the characteristics of the human visual system.
Applying Machine Learning Analysis for Software Quality Test
May 16, 2023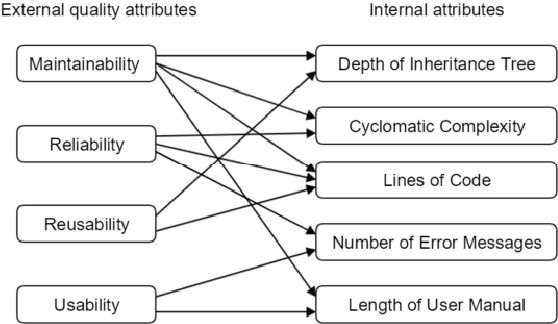
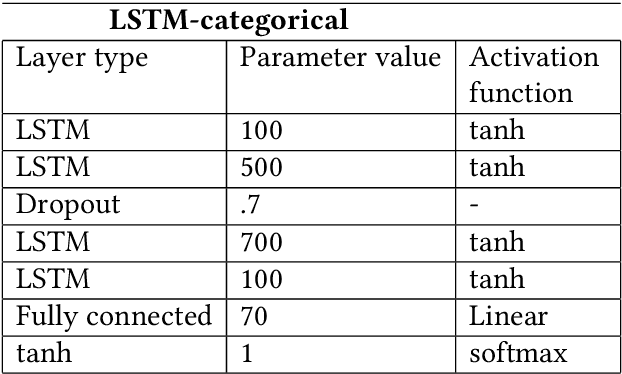
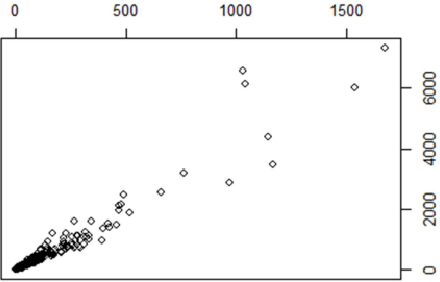
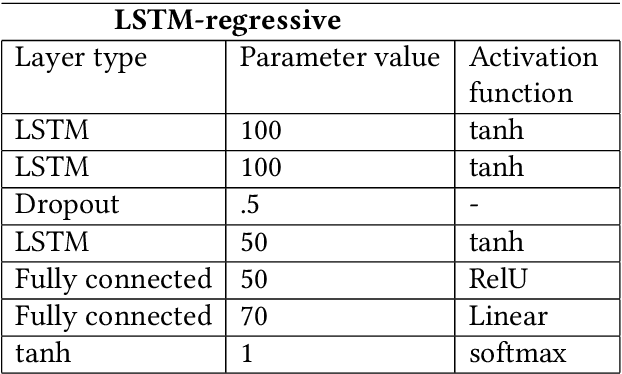
One of the biggest expense in software development is the maintenance. Therefore, it is critical to comprehend what triggers maintenance and if it may be predicted. Numerous research have demonstrated that specific methods of assessing the complexity of created programs may produce useful prediction models to ascertain the possibility of maintenance due to software failures. As a routine it is performed prior to the release, and setting up the models frequently calls for certain, object-oriented software measurements. It is not always the case that software developers have access to these measurements. In this paper, the machine learning is applied on the available data to calculate the cumulative software failure levels. A technique to forecast a software`s residual defectiveness using machine learning can be looked into as a solution to the challenge of predicting residual flaws. Software metrics and defect data were separated out of the static source code repository. Static code is used to create software metrics, and reported bugs in the repository are used to gather defect information. By using a correlation method, metrics that had no connection to the defect data were removed. This makes it possible to analyze all the data without pausing the programming process. Large, sophisticated software`s primary issue is that it is impossible to control everything manually, and the cost of an error can be quite expensive. Developers may miss errors during testing as a consequence, which will raise maintenance costs. Finding a method to accurately forecast software defects is the overall objective.
* 16 pages, 5 figures and 14 tables
Constructing a Knowledge Graph from Textual Descriptions of Software Vulnerabilities in the National Vulnerability Database
Apr 30, 2023
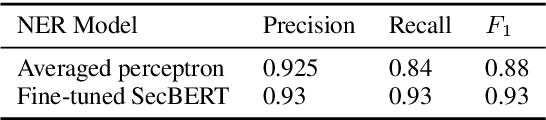

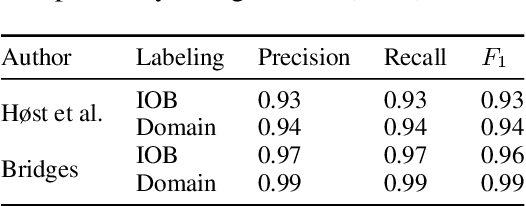
Knowledge graphs have shown promise for several cybersecurity tasks, such as vulnerability assessment and threat analysis. In this work, we present a new method for constructing a vulnerability knowledge graph from information in the National Vulnerability Database (NVD). Our approach combines named entity recognition (NER), relation extraction (RE), and entity prediction using a combination of neural models, heuristic rules, and knowledge graph embeddings. We demonstrate how our method helps to fix missing entities in knowledge graphs used for cybersecurity and evaluate the performance.
Energy-Efficient Lane Changes Planning and Control for Connected Autonomous Vehicles on Urban Roads
Apr 17, 2023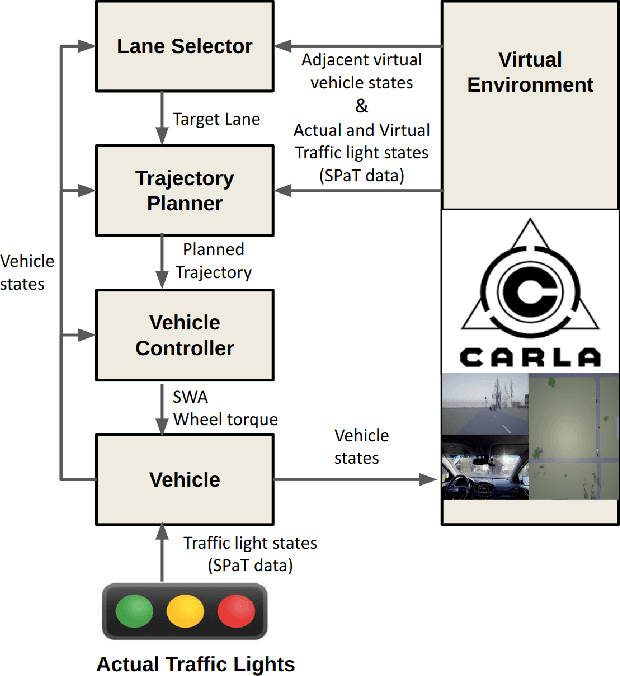
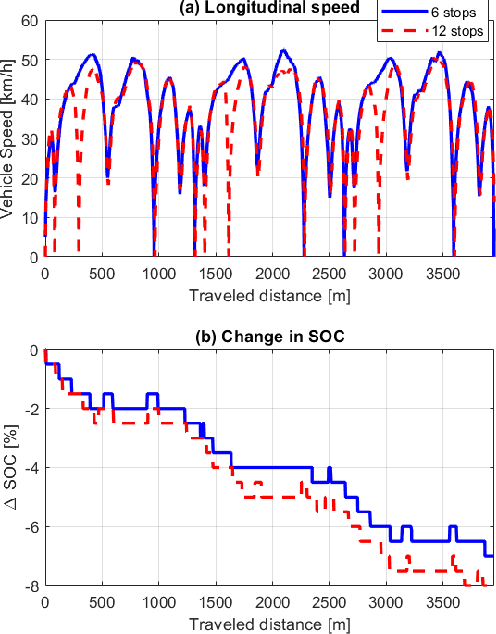
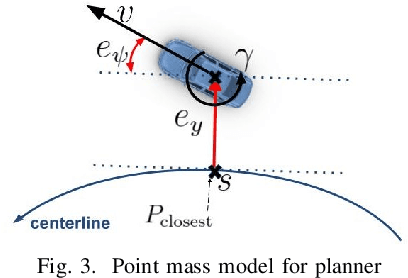
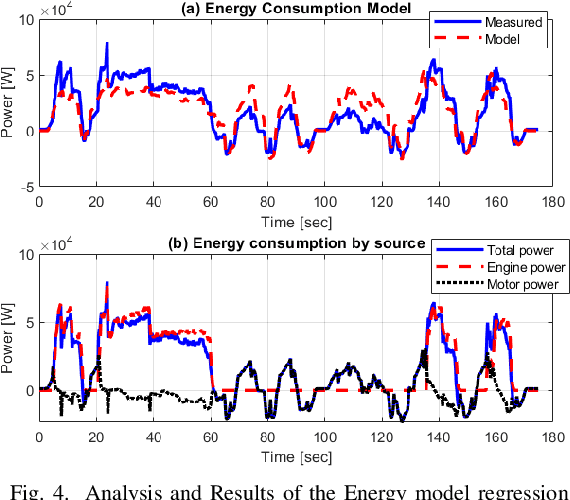
This paper presents a novel energy-efficient motion planning algorithm for Connected Autonomous Vehicles (CAVs) on urban roads. The approach consists of two components: a decision-making algorithm and an optimization-based trajectory planner. The decision-making algorithm leverages Signal Phase and Timing (SPaT) information from connected traffic lights to select a lane with the aim of reducing energy consumption. The algorithm is based on a heuristic rule which is learned from human driving data. The optimization-based trajectory planner generates a safe, smooth, and energy-efficient trajectory toward the selected lane. The proposed strategy is experimentally evaluated in a Vehicle-in-the-Loop (VIL) setting, where a real test vehicle receives SPaT information from both actual and virtual traffic lights and autonomously drives on a testing site, while the surrounding vehicles are simulated. The results demonstrate that the use of SPaT information in autonomous driving leads to improved energy efficiency, with the proposed strategy saving 37.1% energy consumption compared to a lane-keeping algorithm.
Self-Supervised Video Representation Learning via Latent Time Navigation
May 10, 2023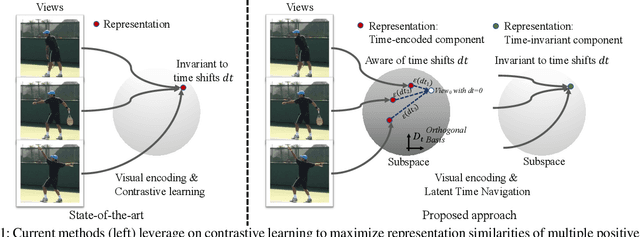
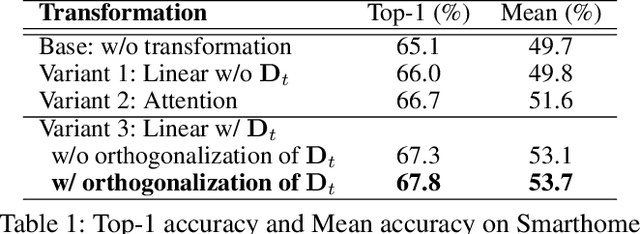
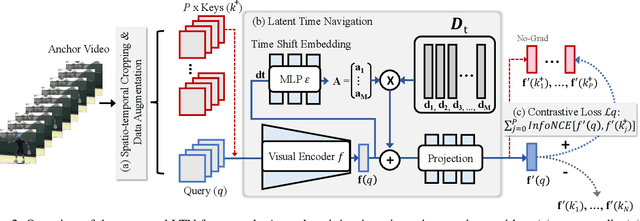
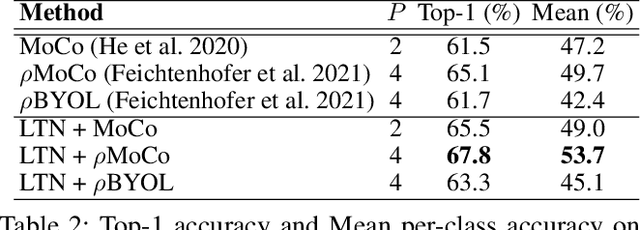
Self-supervised video representation learning aimed at maximizing similarity between different temporal segments of one video, in order to enforce feature persistence over time. This leads to loss of pertinent information related to temporal relationships, rendering actions such as `enter' and `leave' to be indistinguishable. To mitigate this limitation, we propose Latent Time Navigation (LTN), a time-parameterized contrastive learning strategy that is streamlined to capture fine-grained motions. Specifically, we maximize the representation similarity between different video segments from one video, while maintaining their representations time-aware along a subspace of the latent representation code including an orthogonal basis to represent temporal changes. Our extensive experimental analysis suggests that learning video representations by LTN consistently improves performance of action classification in fine-grained and human-oriented tasks (e.g., on Toyota Smarthome dataset). In addition, we demonstrate that our proposed model, when pre-trained on Kinetics-400, generalizes well onto the unseen real world video benchmark datasets UCF101 and HMDB51, achieving state-of-the-art performance in action recognition.
Mobile Image Restoration via Prior Quantization
May 10, 2023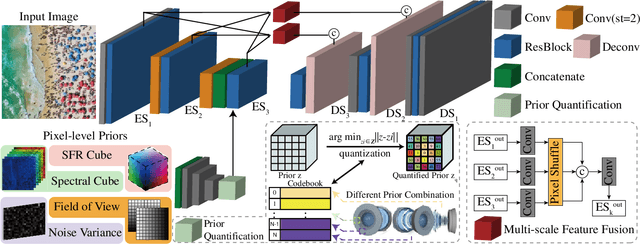
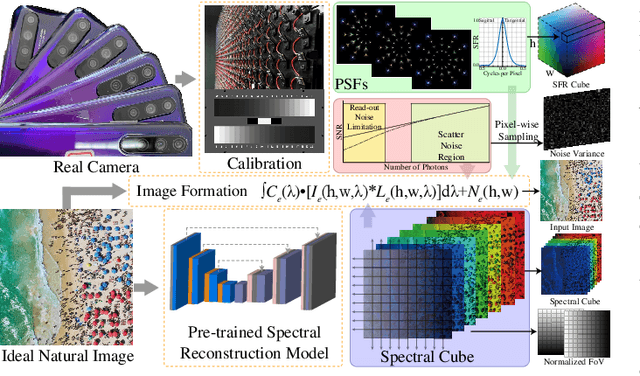

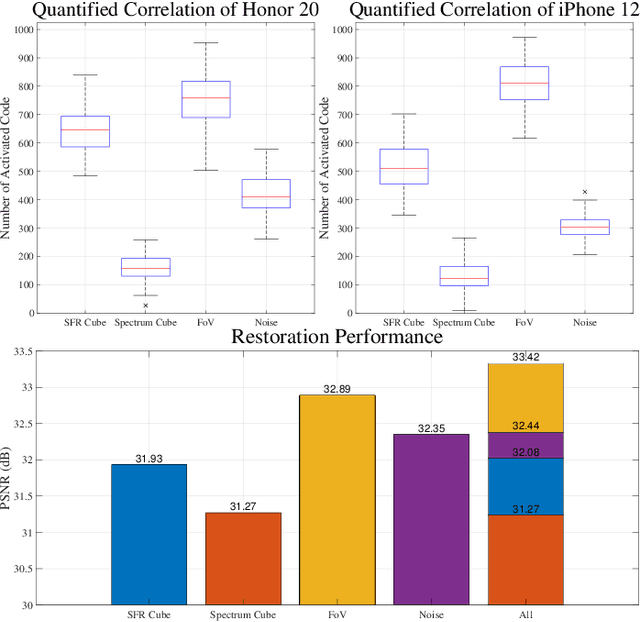
In digital images, the performance of optical aberration is a multivariate degradation, where the spectral of the scene, the lens imperfections, and the field of view together contribute to the results. Besides eliminating it at the hardware level, the post-processing system, which utilizes various prior information, is significant for correction. However, due to the content differences among priors, the pipeline that aligns these factors shows limited efficiency and unoptimized restoration. Here, we propose a prior quantization model to correct the optical aberrations in image processing systems. To integrate these messages, we encode various priors into a latent space and quantify them by the learnable codebooks. After quantization, the prior codes are fused with the image restoration branch to realize targeted optical aberration correction. Comprehensive experiments demonstrate the flexibility of the proposed method and validate its potential to accomplish targeted restoration for a specific camera. Furthermore, our model promises to analyze the correlation between the various priors and the optical aberration of devices, which is helpful for joint soft-hardware design.
Multi-stage Progressive Reasoning for Dunhuang Murals Inpainting
May 10, 2023
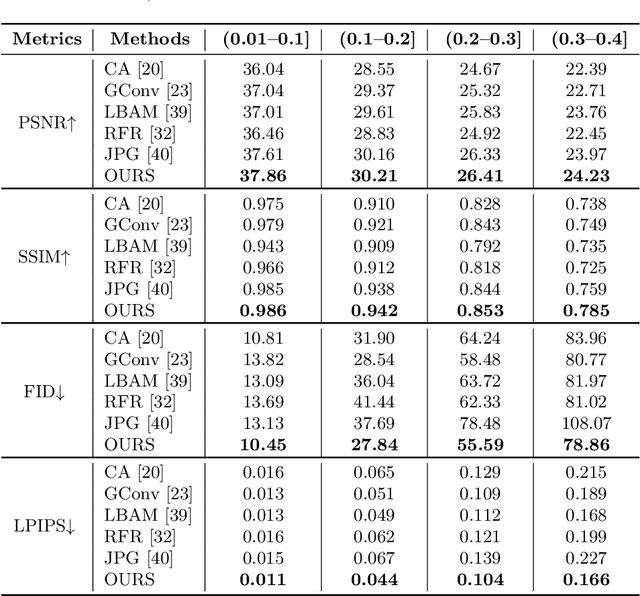

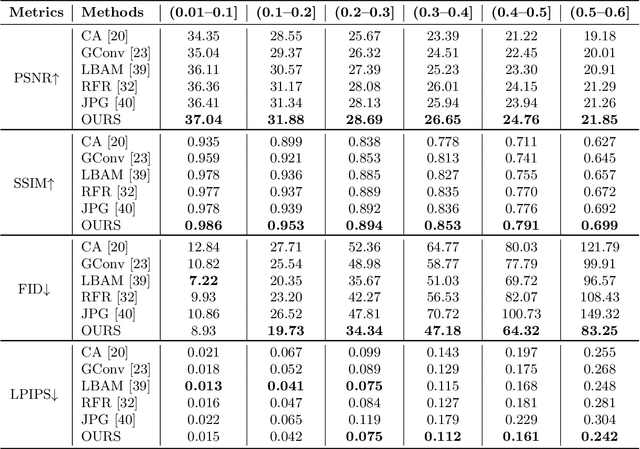
Dunhuang murals suffer from fading, breakage, surface brittleness and extensive peeling affected by prolonged environmental erosion. Image inpainting techniques are widely used in the field of digital mural inpainting. Generally speaking, for mural inpainting tasks with large area damage, it is challenging for any image inpainting method. In this paper, we design a multi-stage progressive reasoning network (MPR-Net) containing global to local receptive fields for murals inpainting. This network is capable of recursively inferring the damage boundary and progressively tightening the regional texture constraints. Moreover, to adaptively fuse plentiful information at various scales of murals, a multi-scale feature aggregation module (MFA) is designed to empower the capability to select the significant features. The execution of the model is similar to the process of a mural restorer (i.e., inpainting the structure of the damaged mural globally first and then adding the local texture details further). Our method has been evaluated through both qualitative and quantitative experiments, and the results demonstrate that it outperforms state-of-the-art image inpainting methods.