 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Privacy-Preserving Collaborative Chinese Text Recognition with Federated Learning
May 09, 2023
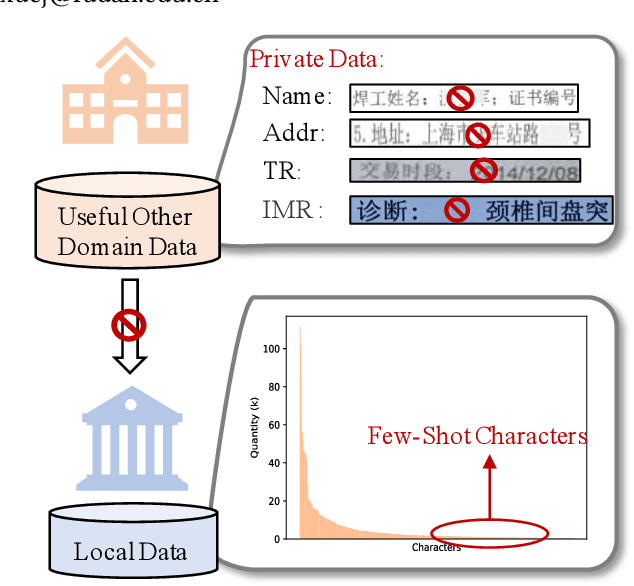

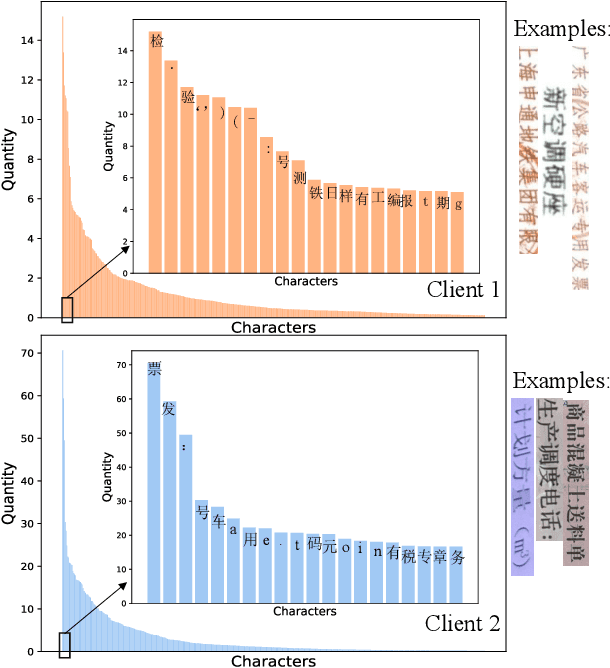
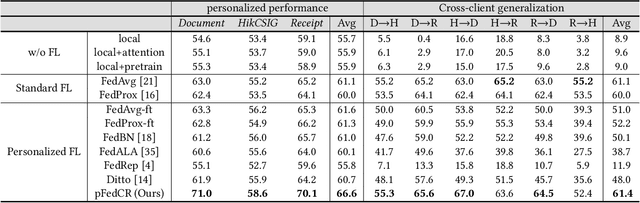
In Chinese text recognition, to compensate for the insufficient local data and improve the performance of local few-shot character recognition, it is often necessary for one organization to collect a large amount of data from similar organizations. However, due to the natural presence of private information in text data, different organizations are unwilling to share private data, such as addresses and phone numbers. Therefore, it becomes increasingly important to design a privacy-preserving collaborative training framework for the Chinese text recognition task. In this paper, we introduce personalized federated learning (pFL) into the Chinese text recognition task and propose the pFedCR algorithm, which significantly improves the model performance of each client (organization) without sharing private data. Specifically, based on CRNN, to handle the non-iid problem of client data, we add several attention layers to the model and design a two-stage training approach for the client. In addition, we fine-tune the output layer of the model using a virtual dataset on the server, mitigating the problem of character imbalance in Chinese documents. The proposed approach is validated on public benchmarks and two self-built real-world industrial scenario datasets. The experimental results show that the pFedCR algorithm can improve the performance of local personalized models while also improving their generalization performance on other client data domains. Compared to local training within an organization, pFedCR improves model performance by about 20%. Compared to other state-of-the-art personalized federated learning methods, pFedCR improves performance by 6%~8%. Moreover, through federated learning, pFedCR can correct erroneous information in the ground truth.
Transfer of knowledge among instruments in automatic music transcription
Apr 30, 2023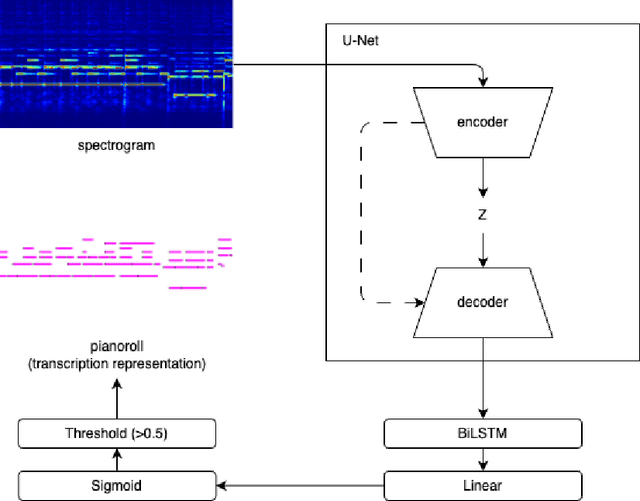
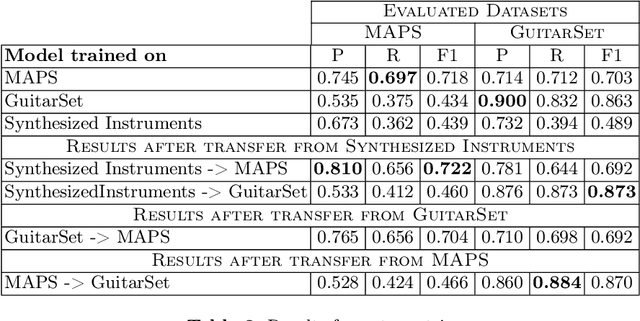
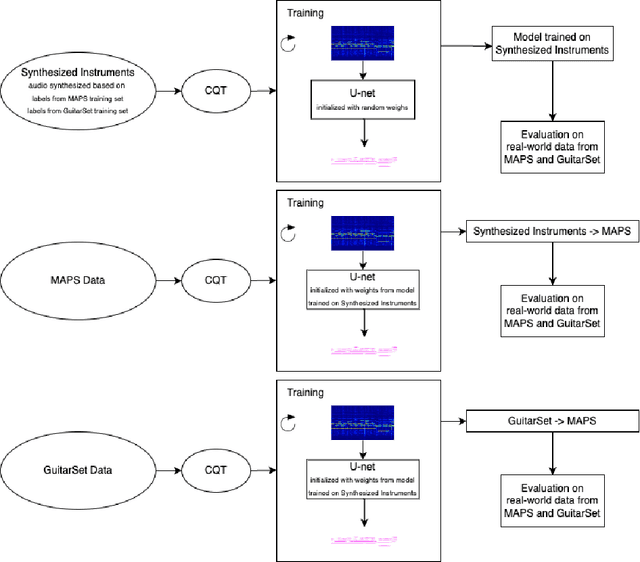
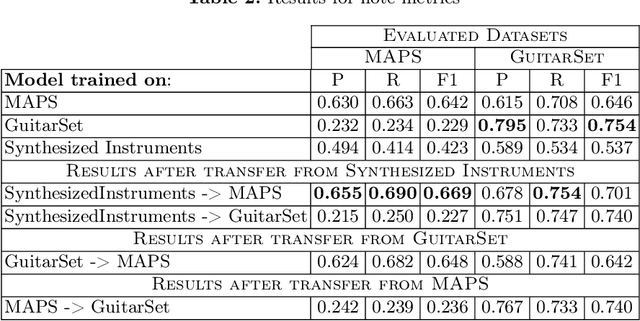
Automatic music transcription (AMT) is one of the most challenging tasks in the music information retrieval domain. It is the process of converting an audio recording of music into a symbolic representation containing information about the notes, chords, and rhythm. Current research in this domain focuses on developing new models based on transformer architecture or using methods to perform semi-supervised training, which gives outstanding results, but the computational cost of training such models is enormous. This work shows how to employ easily generated synthesized audio data produced by software synthesizers to train a universal model. It is a good base for further transfer learning to quickly adapt transcription model for other instruments. Achieved results prove that using synthesized data for training may be a good base for pretraining general-purpose models, where the task of transcription is not focused on one instrument.
ASDL: A Unified Interface for Gradient Preconditioning in PyTorch
May 08, 2023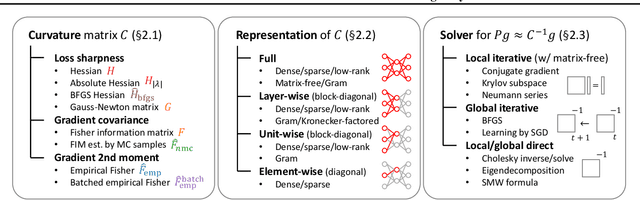


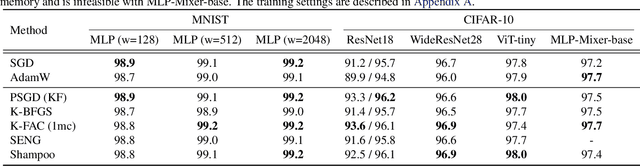
Gradient preconditioning is a key technique to integrate the second-order information into gradients for improving and extending gradient-based learning algorithms. In deep learning, stochasticity, nonconvexity, and high dimensionality lead to a wide variety of gradient preconditioning methods, with implementation complexity and inconsistent performance and feasibility. We propose the Automatic Second-order Differentiation Library (ASDL), an extension library for PyTorch, which offers various implementations and a plug-and-play unified interface for gradient preconditioning. ASDL enables the study and structured comparison of a range of gradient preconditioning methods.
The Current State of Summarization
May 08, 2023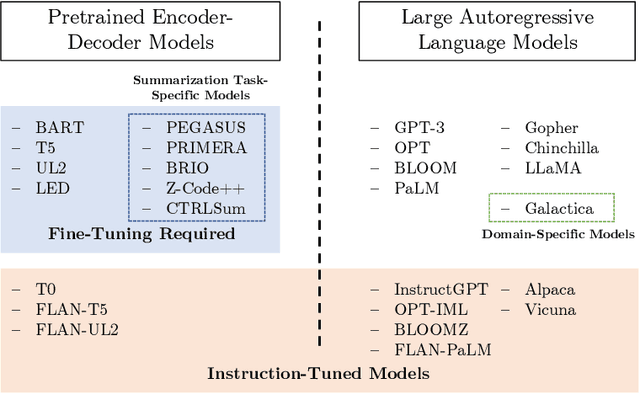
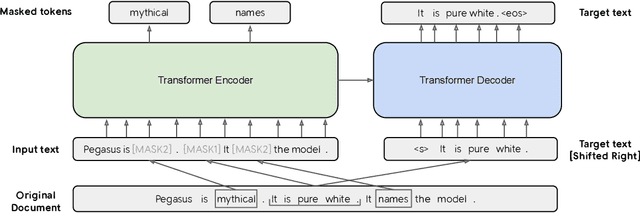
With the explosive growth of textual information, summarization systems have become increasingly important. This work aims at indicating the current state of the art in abstractive text summarization concisely. As part of this, we outline the current paradigm shifts towards pre-trained encoder-decoder models and large autoregressive language models. Additionally, we delve further into the challenges of evaluating summarization systems and the potential of instruction-tuned models for zero-shot summarization. Finally, we provide a brief overview of how summarization systems are currently being integrated into commercial applications.
GeoGLUE: A GeoGraphic Language Understanding Evaluation Benchmark
May 11, 2023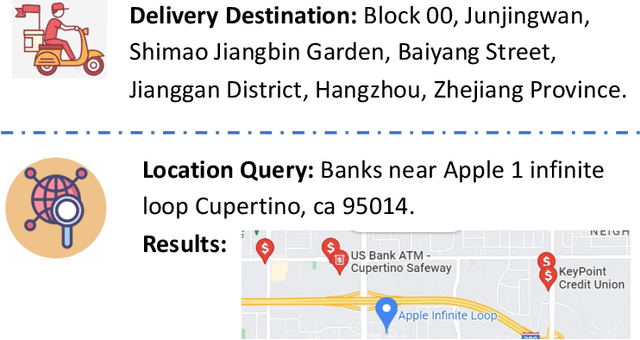
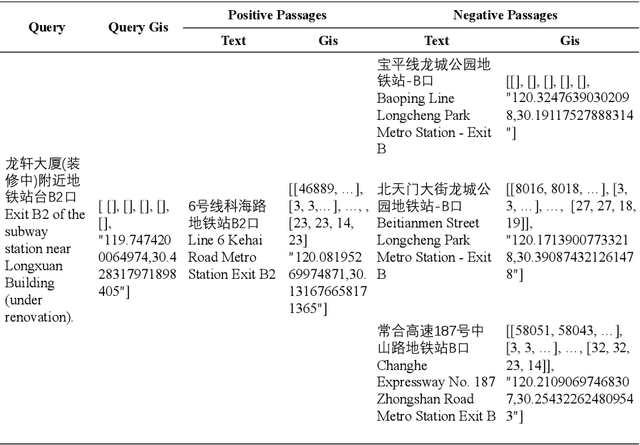
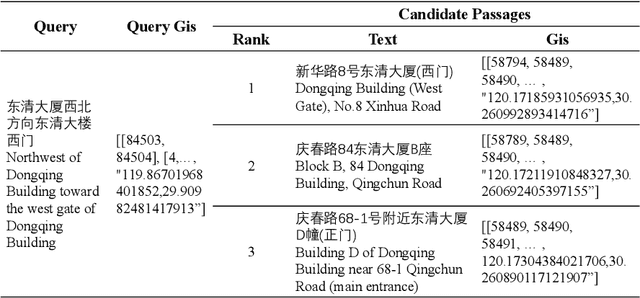
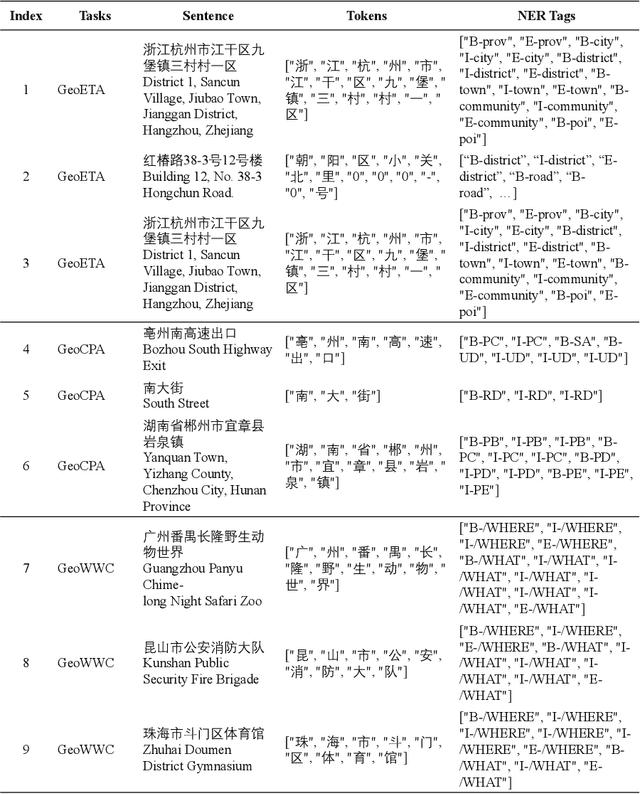
With a fast developing pace of geographic applications, automatable and intelligent models are essential to be designed to handle the large volume of information. However, few researchers focus on geographic natural language processing, and there has never been a benchmark to build a unified standard. In this work, we propose a GeoGraphic Language Understanding Evaluation benchmark, named GeoGLUE. We collect data from open-released geographic resources and introduce six natural language understanding tasks, including geographic textual similarity on recall, geographic textual similarity on rerank, geographic elements tagging, geographic composition analysis, geographic where what cut, and geographic entity alignment. We also pro vide evaluation experiments and analysis of general baselines, indicating the effectiveness and significance of the GeoGLUE benchmark.
Realization RGBD Image Stylization
May 11, 2023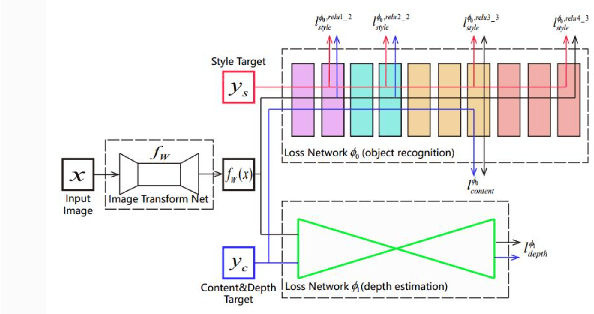



This research paper explores the application of style transfer in computer vision using RGB images and their corresponding depth maps. We propose a novel method that incorporates the depth map and a heatmap of the RGB image to generate more realistic style transfer results. We compare our method to the traditional neural style transfer approach and find that our method outperforms it in terms of producing more realistic color and style. The proposed method can be applied to various computer vision applications, such as image editing and virtual reality, to improve the realism of generated images. Overall, our findings demonstrate the potential of incorporating depth information and heatmap of RGB images in style transfer for more realistic results.
Transfer Entropy Bottleneck: Learning Sequence to Sequence Information Transfer
Nov 29, 2022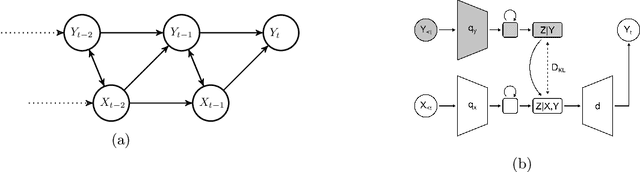



When presented with a data stream of two statistically dependent variables, predicting the future of one of the variables (the target stream) can benefit from information about both its history and the history of the other variable (the source stream). For example, fluctuations in temperature at a weather station can be predicted using both temperatures and barometric readings. However, a challenge when modelling such data is that it is easy for a neural network to rely on the greatest joint correlations within the target stream, which may ignore a crucial but small information transfer from the source to the target stream. As well, there are often situations where the target stream may have previously been modelled independently and it would be useful to use that model to inform a new joint model. Here, we develop an information bottleneck approach for conditional learning on two dependent streams of data. Our method, which we call Transfer Entropy Bottleneck (TEB), allows one to learn a model that bottlenecks the directed information transferred from the source variable to the target variable, while quantifying this information transfer within the model. As such, TEB provides a useful new information bottleneck approach for modelling two statistically dependent streams of data in order to make predictions about one of them.
MetaGAD: Learning to Meta Transfer for Few-shot Graph Anomaly Detection
May 18, 2023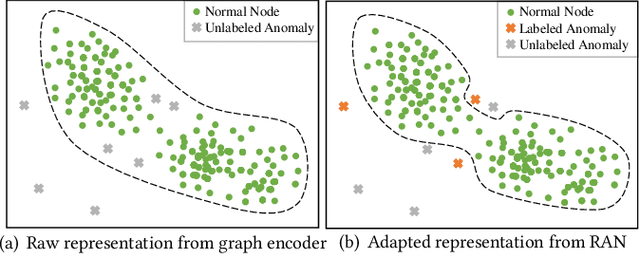
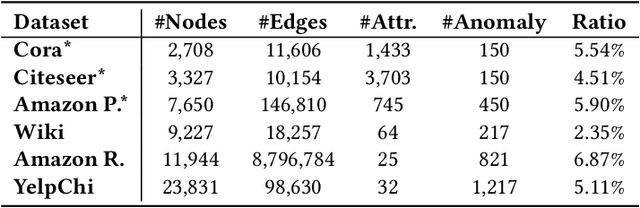
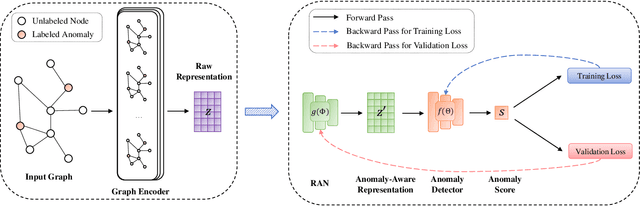
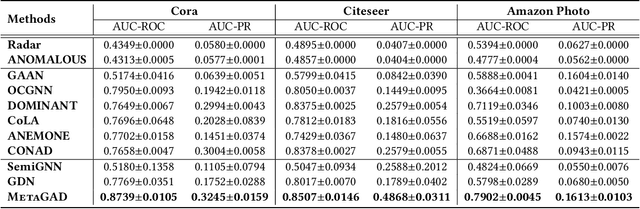
Graph anomaly detection has long been an important problem in various domains pertaining to information security such as financial fraud, social spam, network intrusion, etc. The majority of existing methods are performed in an unsupervised manner, as labeled anomalies in a large scale are often too expensive to acquire. However, the identified anomalies may turn out to be data noises or uninteresting data instances due to the lack of prior knowledge on the anomalies. In realistic scenarios, it is often feasible to obtain limited labeled anomalies, which have great potential to advance graph anomaly detection. However, the work exploring limited labeled anomalies and a large amount of unlabeled nodes in graphs to detect anomalies is rather limited. Therefore, in this paper, we study a novel problem of few-shot graph anomaly detection. We propose a new framework MetaGAD to learn to meta-transfer the knowledge between unlabeled and labeled nodes for graph anomaly detection. Experimental results on six real-world datasets with synthetic anomalies and "organic" anomalies (available in the dataset) demonstrate the effectiveness of the proposed approach in detecting anomalies with limited labeled anomalies.
Adapt and Align to Improve Zero-Shot Sketch-Based Image Retrieval
May 18, 2023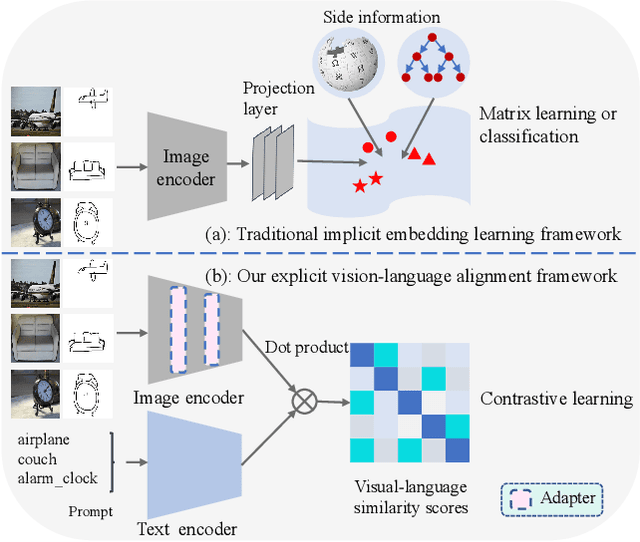
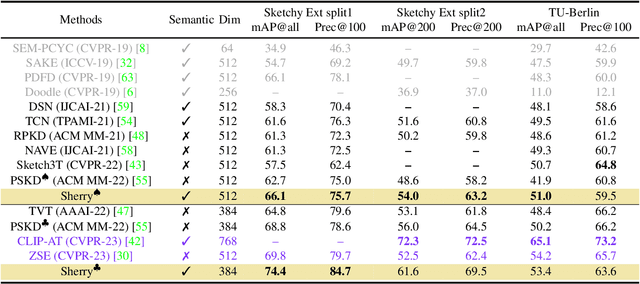
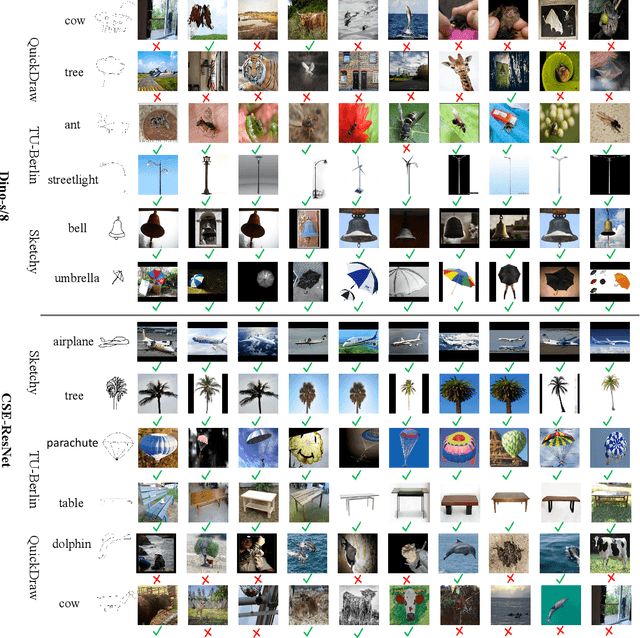
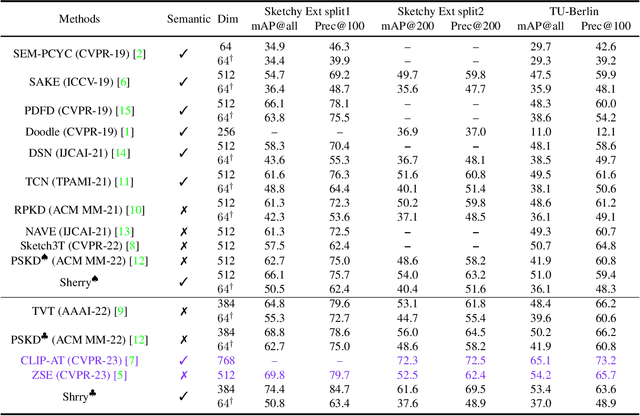
Zero-shot sketch-based image retrieval (ZS-SBIR) is challenging due to the cross-domain nature of sketches and photos, as well as the semantic gap between seen and unseen image distributions. Previous methods fine-tune pre-trained models with various side information and learning strategies to learn a compact feature space that is shared between the sketch and photo domains and bridges seen and unseen classes. However, these efforts are inadequate in adapting domains and transferring knowledge from seen to unseen classes. In this paper, we present an effective ``Adapt and Align'' approach to address the key challenges. Specifically, we insert simple and lightweight domain adapters to learn new abstract concepts of the sketch domain and improve cross-domain representation capabilities. Inspired by recent advances in image-text foundation models (e.g., CLIP) on zero-shot scenarios, we explicitly align the learned image embedding with a more semantic text embedding to achieve the desired knowledge transfer from seen to unseen classes. Extensive experiments on three benchmark datasets and two popular backbones demonstrate the superiority of our method in terms of retrieval accuracy and flexibility.
Unsupervised Pansharpening via Low-rank Diffusion Model
May 18, 2023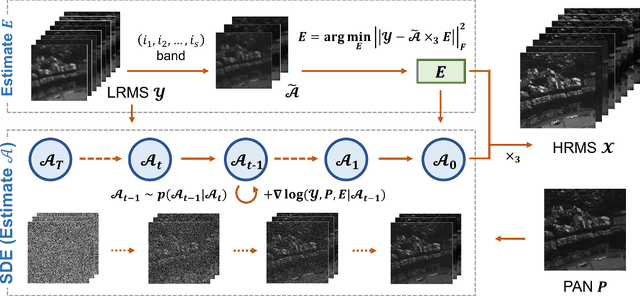


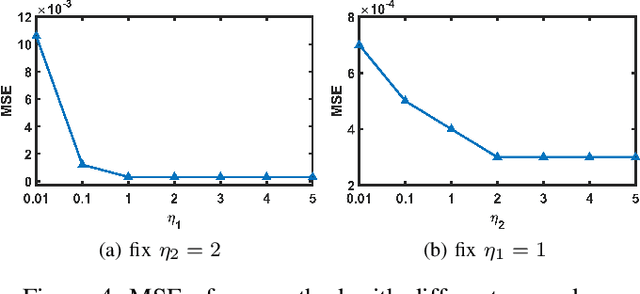
Pansharpening is a process of merging a highresolution panchromatic (PAN) image and a low-resolution multispectral (LRMS) image to create a single high-resolution multispectral (HRMS) image. Most of the existing deep learningbased pansharpening methods have poor generalization ability and the traditional model-based pansharpening methods need careful manual exploration for the image structure prior. To alleviate these issues, this paper proposes an unsupervised pansharpening method by combining the diffusion model with the low-rank matrix factorization technique. Specifically, we assume that the HRMS image is decomposed into the product of two low-rank tensors, i.e., the base tensor and the coefficient matrix. The base tensor lies on the image field and has low spectral dimension, we can thus conveniently utilize a pre-trained remote sensing diffusion model to capture its image structures. Additionally, we derive a simple yet quite effective way to preestimate the coefficient matrix from the observed LRMS image, which preserves the spectral information of the HRMS. Extensive experimental results on some benchmark datasets demonstrate that our proposed method performs better than traditional model-based approaches and has better generalization ability than deep learning-based techniques. The code is released in https://github.com/xyrui/PLRDiff.