 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Blueprint of IR Evaluation Integrating Task and User Characteristics: Test Collection and Evaluation Metrics
May 01, 2023
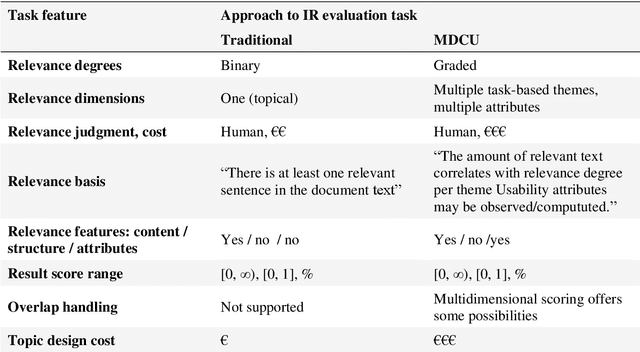
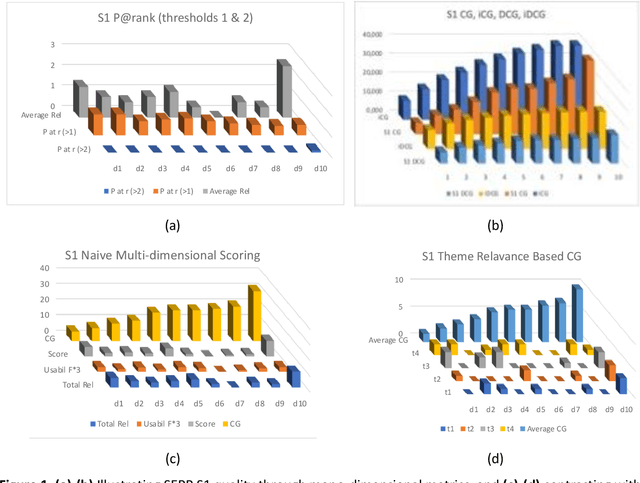
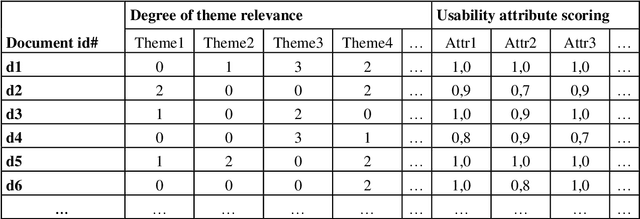
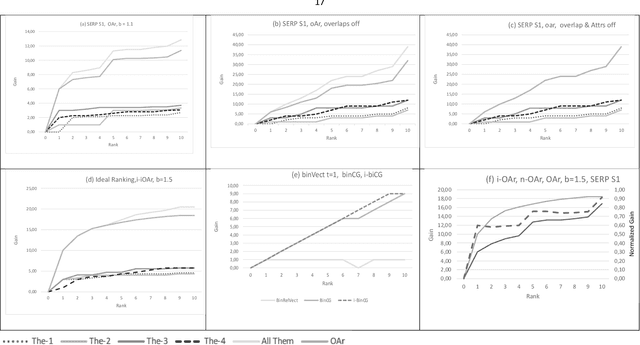
Relevance is generally understood as a multi-level and multi-dimensional relationship between an information need and an information object. However, traditional IR evaluation metrics naively assume mono-dimensionality. We ask: How to deal with multidimensional and graded relevance assessments in IR evaluation? Moreover, search result evaluation metrics neglect document overlaps and naively assume gains piling up as the searcher examines the ranked list into greater length. Consequently, we examine: How to deal with document overlap in IR evaluation? The usability of a document for a person-in-need also depends on document usability attributes beyond relevance. Therefore, we ask: How to deal with usability attributes, and how to combine this with multidimensional relevance assessments in IR evaluation? Finally, we ask how to define a formal model, which deals with multidimensional graded relevance assessments, document overlaps, and document usability attributes in a coherent framework serving IR evaluation?
Introducing Tales of Tribute AI Competition
May 14, 2023
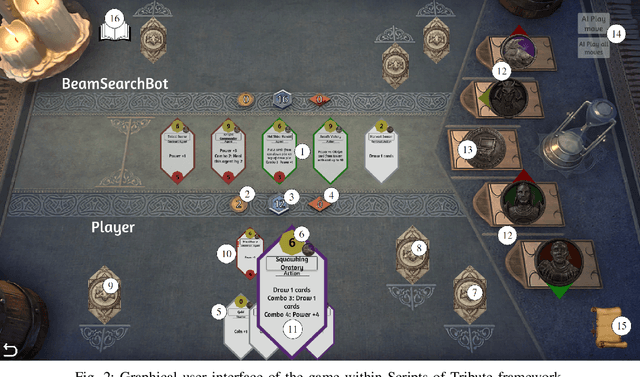
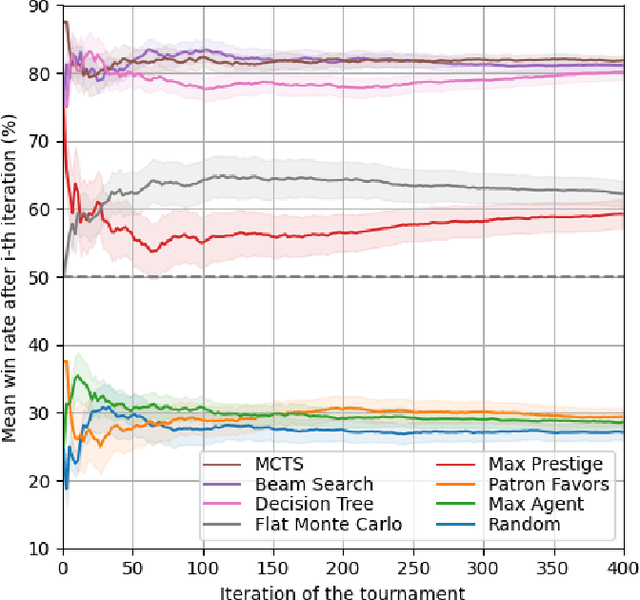
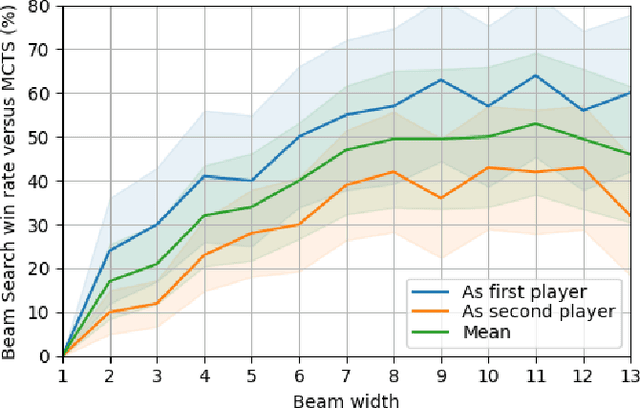
This paper presents a new AI challenge, the Tales of Tribute AI Competition (TOTAIC), based on a two-player deck-building card game released with the High Isle chapter of The Elder Scrolls Online. Currently, there is no other AI competition covering Collectible Card Games (CCG) genre, and there has never been one that targets a deck-building game. Thus, apart from usual CCG-related obstacles to overcome, like randomness, hidden information, and large branching factor, the successful approach additionally requires long-term planning and versatility. The game can be tackled with multiple approaches, including classic adversarial search, single-player planning, and Neural Networks-based algorithms. This paper introduces the competition framework, describes the rules of the game, and presents the results of a tournament between sample AI agents. The first edition of TOTAIC is hosted at the IEEE Conference on Games 2023.
$SmartProbe$: A Virtual Moderator for Market Research Surveys
May 14, 2023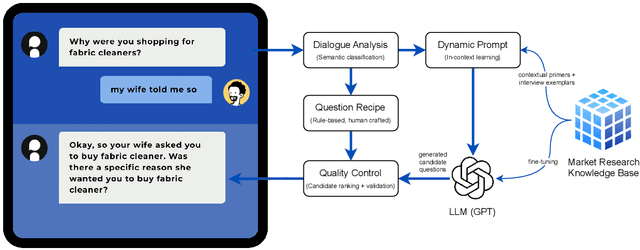



Market research surveys are a powerful methodology for understanding consumer perspectives at scale, but are limited by depth of understanding and insights. A virtual moderator can introduce elements of qualitative research into surveys, developing a rapport with survey participants and dynamically asking probing questions, ultimately to elicit more useful information for market researchers. In this work, we introduce ${\tt SmartProbe}$, an API which leverages the adaptive capabilities of large language models (LLMs), and incorporates domain knowledge from market research, in order to generate effective probing questions in any market research survey. We outline the modular processing flow of $\tt SmartProbe$, and evaluate the quality and effectiveness of its generated probing questions. We believe our efforts will inspire industry practitioners to build real-world applications based on the latest advances in LLMs. Our demo is publicly available at https://nexxt.in/smartprobe-demo
MSI: Maximize Support-Set Information for Few-Shot Segmentation
Dec 09, 2022
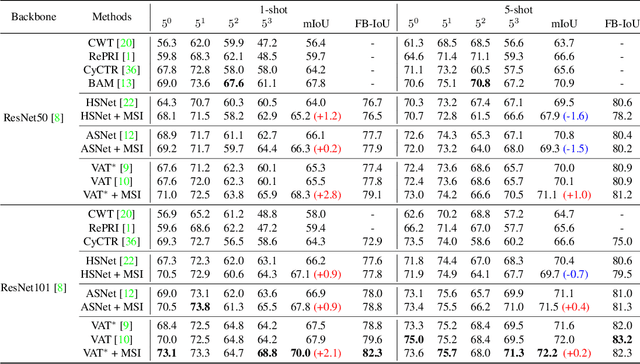
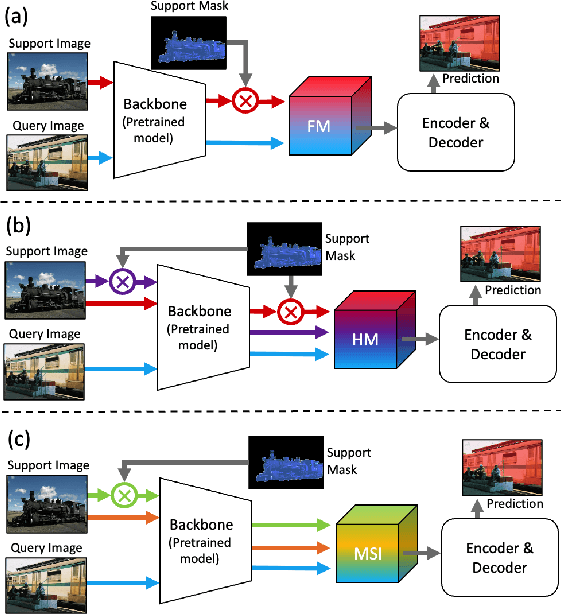
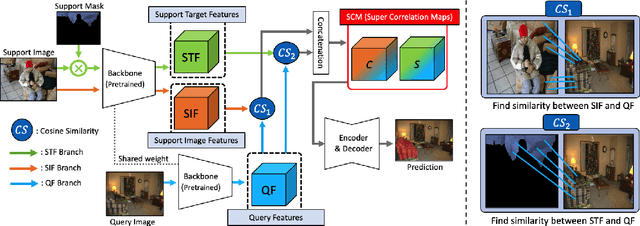
FSS(Few-shot segmentation)~aims to segment a target class with a small number of labeled images (support Set). To extract information relevant to target class, a dominant approach in best performing FSS baselines removes background features using support mask. We observe that this support mask presents an information bottleneck in several challenging FSS cases e.g., for small targets and/or inaccurate target boundaries. To this end, we present a novel method (MSI), which maximizes the support-set information by exploiting two complementary source of features in generating super correlation maps. We validate the effectiveness of our approach by instantiating it into three recent and strong FSS baselines. Experimental results on several publicly available FSS benchmarks show that our proposed method consistently improves the performance by visible margins and allows faster convergence. Our codes and models will be publicly released.
ThreatCrawl: A BERT-based Focused Crawler for the Cybersecurity Domain
Apr 24, 2023
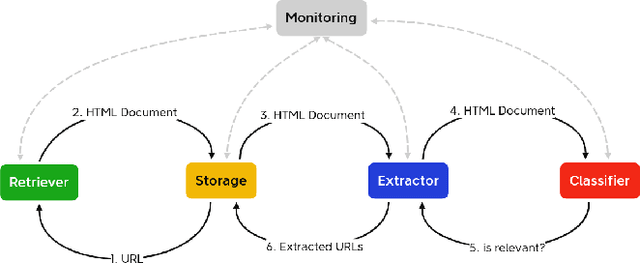

Publicly available information contains valuable information for Cyber Threat Intelligence (CTI). This can be used to prevent attacks that have already taken place on other systems. Ideally, only the initial attack succeeds and all subsequent ones are detected and stopped. But while there are different standards to exchange this information, a lot of it is shared in articles or blog posts in non-standardized ways. Manually scanning through multiple online portals and news pages to discover new threats and extracting them is a time-consuming task. To automize parts of this scanning process, multiple papers propose extractors that use Natural Language Processing (NLP) to extract Indicators of Compromise (IOCs) from documents. However, while this already solves the problem of extracting the information out of documents, the search for these documents is rarely considered. In this paper, a new focused crawler is proposed called ThreatCrawl, which uses Bidirectional Encoder Representations from Transformers (BERT)-based models to classify documents and adapt its crawling path dynamically. While ThreatCrawl has difficulties to classify the specific type of Open Source Intelligence (OSINT) named in texts, e.g., IOC content, it can successfully find relevant documents and modify its path accordingly. It yields harvest rates of up to 52%, which are, to the best of our knowledge, better than the current state of the art.
Unsourced Massive Access-Based Digital Over-the-Air Computation for Efficient Federated Edge Learning
May 17, 2023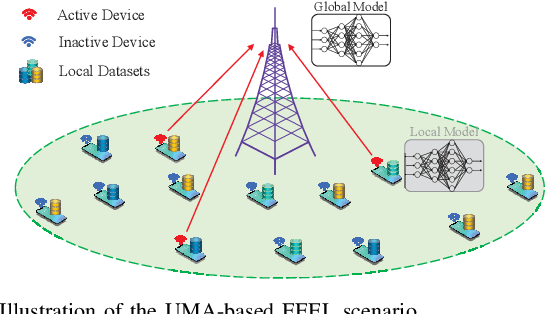
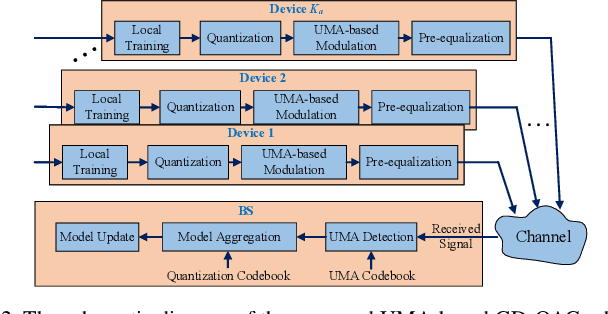
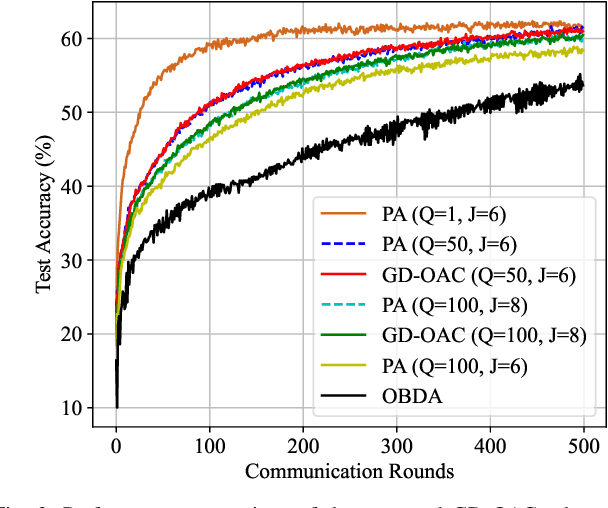
Over-the-air computation (OAC) is a promising technique to achieve fast model aggregation across multiple devices in federated edge learning (FEEL). In addition to the analog schemes, one-bit digital aggregation (OBDA) scheme was proposed to adapt OAC to modern digital wireless systems. However, one-bit quantization in OBDA can result in a serious information loss and slower convergence of FEEL. To overcome this limitation, this paper proposes an unsourced massive access (UMA)-based generalized digital OAC (GD-OAC) scheme. Specifically, at the transmitter, all the devices share the same non-orthogonal UMA codebook for uplink transmission. The local model update of each device is quantized based on the same quantization codebook. Then, each device transmits a sequence selected from the UMA codebook based on the quantized elements of its model update. At the receiver, we propose an approximate message passing-based algorithm for efficient UMA detection and model aggregation. Simulation results show that the proposed GD-OAC scheme significantly accelerates the FEEL convergences compared with the state-of-the-art OBDA scheme while using the same uplink communication resources.
Lingo3DMol: Generation of a Pocket-based 3D Molecule using a Language Model
May 17, 2023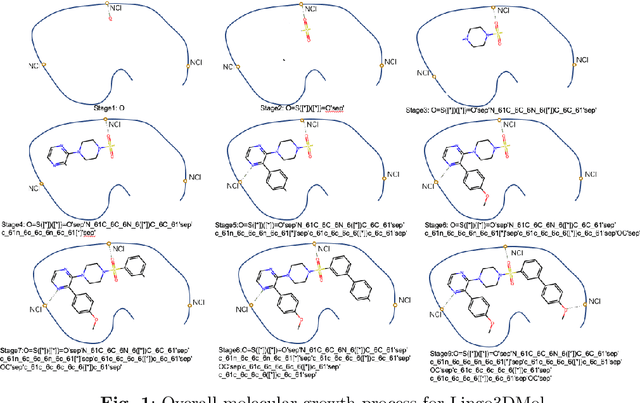
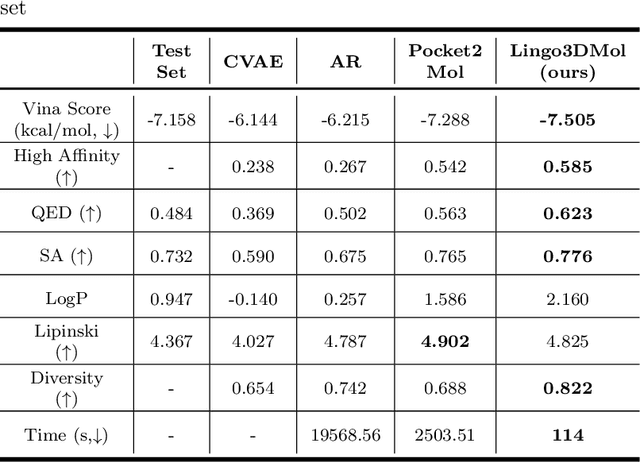
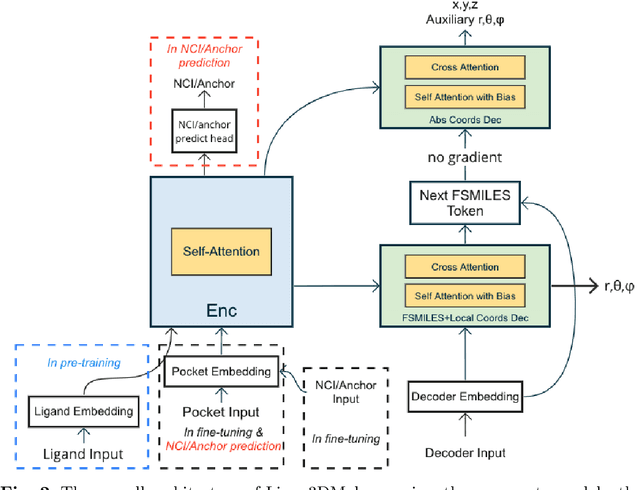
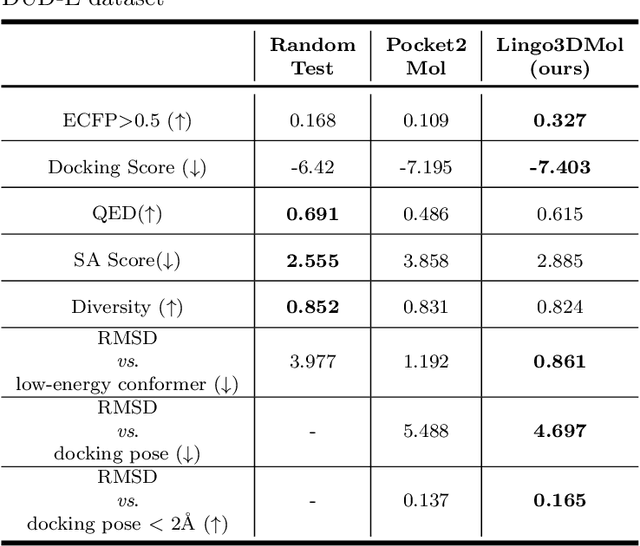
Structure-based drug design powered by deep generative models have attracted increasing research interest in recent years. Language models have demonstrated a robust capacity for generating valid molecules in 2D structures, while methods based on geometric deep learning can directly produce molecules with accurate 3D coordinates. Inspired by both methods, this article proposes a pocket-based 3D molecule generation method that leverages the language model with the ability to generate 3D coordinates. High quality protein-ligand complex data are insufficient; hence, a perturbation and restoration pre-training task is designed that can utilize vast amounts of small-molecule data. A new molecular representation, a fragment-based SMILES with local and global coordinates, is also presented, enabling the language model to learn molecular topological structures and spatial position information effectively. Ultimately, CrossDocked and DUD-E dataset is employed for evaluation and additional metrics are introduced. This method achieves state-of-the-art performance in nearly all metrics, notably in terms of binding patterns, drug-like properties, rational conformations, and inference speed. Our model is available as an online service to academic users via sw3dmg.stonewise.cn
Vision Transformer Off-the-Shelf: A Surprising Baseline for Few-Shot Class-Agnostic Counting
May 08, 2023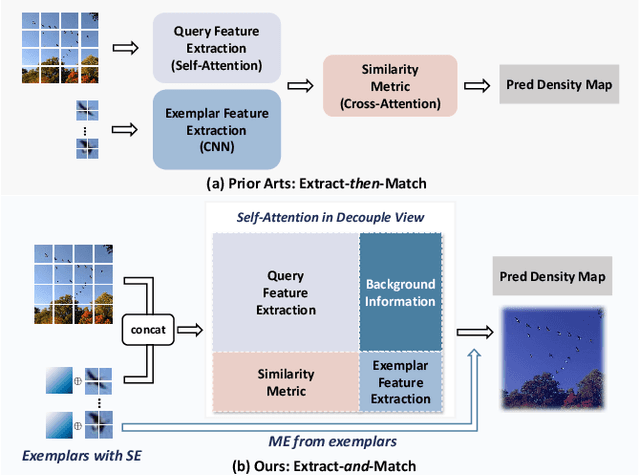
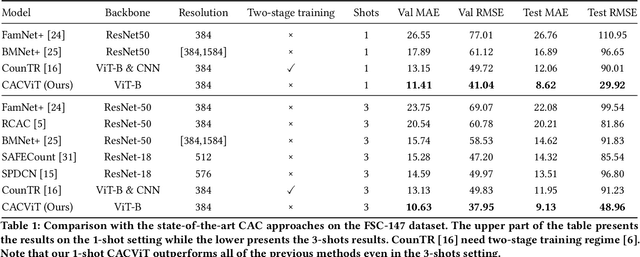
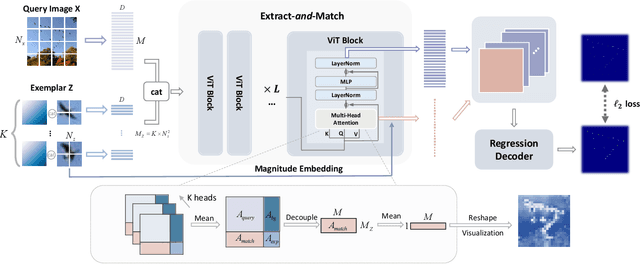
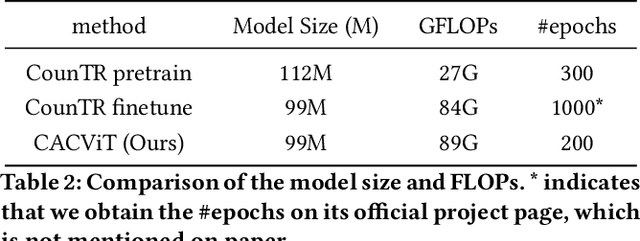
Class-agnostic counting (CAC) aims to count objects of interest from a query image given few exemplars. This task is typically addressed by extracting the features of query image and exemplars respectively with (un)shared feature extractors and by matching their feature similarity, leading to an extract-\textit{then}-match paradigm. In this work, we show that CAC can be simplified in an extract-\textit{and}-match manner, particularly using a pretrained and plain vision transformer (ViT) where feature extraction and similarity matching are executed simultaneously within the self-attention. We reveal the rationale of such simplification from a decoupled view of the self-attention and point out that the simplification is only made possible if the query and exemplar tokens are concatenated as input. The resulting model, termed CACViT, simplifies the CAC pipeline and unifies the feature spaces between the query image and exemplars. In addition, we find CACViT naturally encodes background information within self-attention, which helps reduce background disturbance. Further, to compensate the loss of the scale and the order-of-magnitude information due to resizing and normalization in ViT, we present two effective strategies for scale and magnitude embedding. Extensive experiments on the FSC147 and the CARPK datasets show that CACViT significantly outperforms state-of-the-art CAC approaches in both effectiveness (23.60% error reduction) and generalization, which suggests CACViT provides a concise and strong baseline for CAC. Code will be available.
Breaking Through the Haze: An Advanced Non-Homogeneous Dehazing Method based on Fast Fourier Convolution and ConvNeXt
May 08, 2023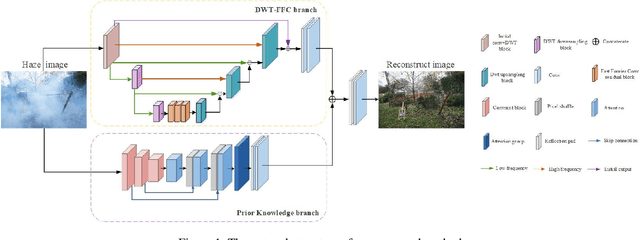

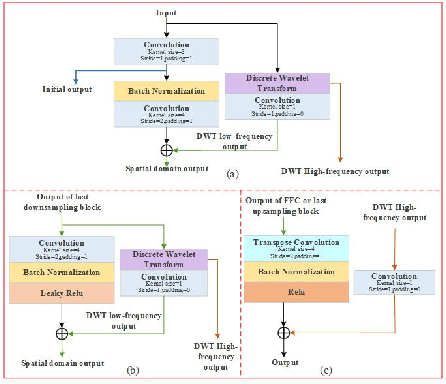
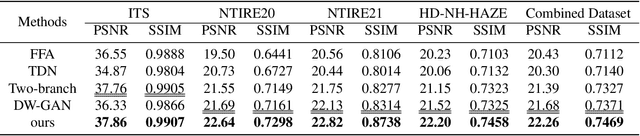
Haze usually leads to deteriorated images with low contrast, color shift and structural distortion. We observe that many deep learning based models exhibit exceptional performance on removing homogeneous haze, but they usually fail to address the challenge of non-homogeneous dehazing. Two main factors account for this situation. Firstly, due to the intricate and non uniform distribution of dense haze, the recovery of structural and chromatic features with high fidelity is challenging, particularly in regions with heavy haze. Secondly, the existing small scale datasets for non-homogeneous dehazing are inadequate to support reliable learning of feature mappings between hazy images and their corresponding haze-free counterparts by convolutional neural network (CNN)-based models. To tackle these two challenges, we propose a novel two branch network that leverages 2D discrete wavelete transform (DWT), fast Fourier convolution (FFC) residual block and a pretrained ConvNeXt model. Specifically, in the DWT-FFC frequency branch, our model exploits DWT to capture more high-frequency features. Moreover, by taking advantage of the large receptive field provided by FFC residual blocks, our model is able to effectively explore global contextual information and produce images with better perceptual quality. In the prior knowledge branch, an ImageNet pretrained ConvNeXt as opposed to Res2Net is adopted. This enables our model to learn more supplementary information and acquire a stronger generalization ability. The feasibility and effectiveness of the proposed method is demonstrated via extensive experiments and ablation studies. The code is available at https://github.com/zhouh115/DWT-FFC.
Do Large Language Models Show Decision Heuristics Similar to Humans? A Case Study Using GPT-3.5
May 08, 2023


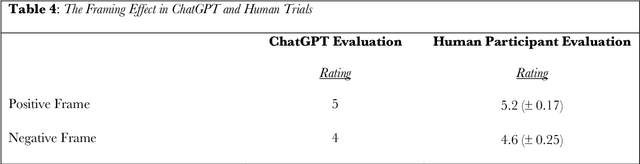
A Large Language Model (LLM) is an artificial intelligence system that has been trained on vast amounts of natural language data, enabling it to generate human-like responses to written or spoken language input. GPT-3.5 is an example of an LLM that supports a conversational agent called ChatGPT. In this work, we used a series of novel prompts to determine whether ChatGPT shows heuristics, biases, and other decision effects. We also tested the same prompts on human participants. Across four studies, we found that ChatGPT was influenced by random anchors in making estimates (Anchoring Heuristic, Study 1); it judged the likelihood of two events occurring together to be higher than the likelihood of either event occurring alone, and it was erroneously influenced by salient anecdotal information (Representativeness and Availability Heuristic, Study 2); it found an item to be more efficacious when its features were presented positively rather than negatively - even though both presentations contained identical information (Framing Effect, Study 3); and it valued an owned item more than a newly found item even though the two items were identical (Endowment Effect, Study 4). In each study, human participants showed similar effects. Heuristics and related decision effects in humans are thought to be driven by cognitive and affective processes such as loss aversion and effort reduction. The fact that an LLM - which lacks these processes - also shows such effects invites consideration of the possibility that language may play a role in generating these effects in humans.