 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Absorption Rates in Glucose-Insulin Dynamics from Meal Covariates
Apr 27, 2023
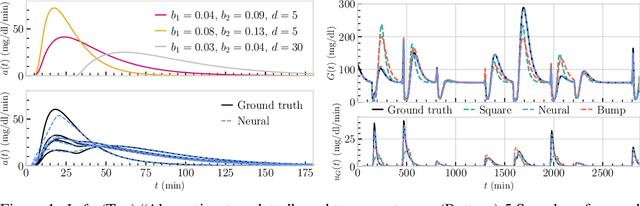

Traditional models of glucose-insulin dynamics rely on heuristic parameterizations chosen to fit observations within a laboratory setting. However, these models cannot describe glucose dynamics in daily life. One source of failure is in their descriptions of glucose absorption rates after meal events. A meal's macronutritional content has nuanced effects on the absorption profile, which is difficult to model mechanistically. In this paper, we propose to learn the effects of macronutrition content from glucose-insulin data and meal covariates. Given macronutrition information and meal times, we use a neural network to predict an individual's glucose absorption rate. We use this neural rate function as the control function in a differential equation of glucose dynamics, enabling end-to-end training. On simulated data, our approach is able to closely approximate true absorption rates, resulting in better forecast than heuristic parameterizations, despite only observing glucose, insulin, and macronutritional information. Our work readily generalizes to meal events with higher-dimensional covariates, such as images, setting the stage for glucose dynamics models that are personalized to each individual's daily life.
Learning from Aggregated Data: Curated Bags versus Random Bags
May 18, 2023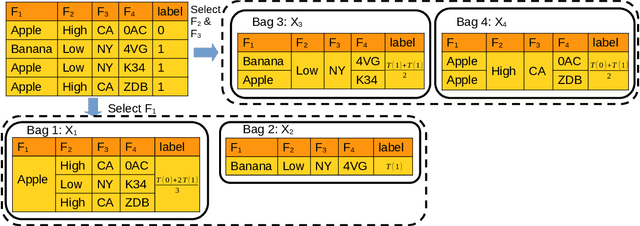
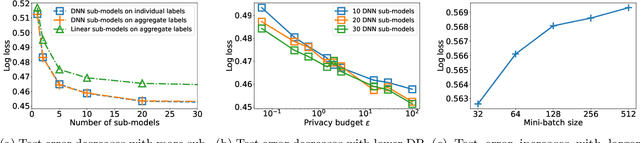
Protecting user privacy is a major concern for many machine learning systems that are deployed at scale and collect from a diverse set of population. One way to address this concern is by collecting and releasing data labels in an aggregated manner so that the information about a single user is potentially combined with others. In this paper, we explore the possibility of training machine learning models with aggregated data labels, rather than individual labels. Specifically, we consider two natural aggregation procedures suggested by practitioners: curated bags where the data points are grouped based on common features and random bags where the data points are grouped randomly in bag of similar sizes. For the curated bag setting and for a broad range of loss functions, we show that we can perform gradient-based learning without any degradation in performance that may result from aggregating data. Our method is based on the observation that the sum of the gradients of the loss function on individual data examples in a curated bag can be computed from the aggregate label without the need for individual labels. For the random bag setting, we provide a generalization risk bound based on the Rademacher complexity of the hypothesis class and show how empirical risk minimization can be regularized to achieve the smallest risk bound. In fact, in the random bag setting, there is a trade-off between size of the bag and the achievable error rate as our bound indicates. Finally, we conduct a careful empirical study to confirm our theoretical findings. In particular, our results suggest that aggregate learning can be an effective method for preserving user privacy while maintaining model accuracy.
Ship-D: Ship Hull Dataset for Design Optimization using Machine Learning
May 16, 2023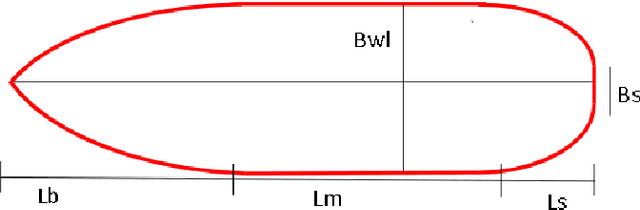


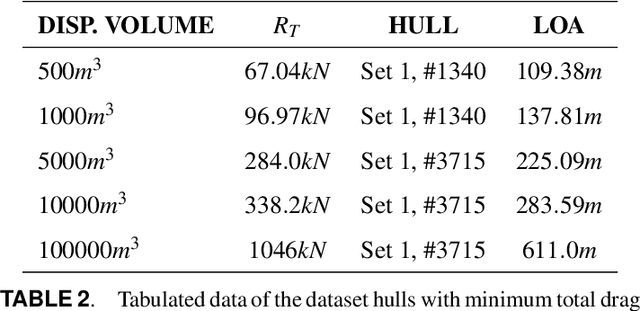
Machine learning has recently made significant strides in reducing design cycle time for complex products. Ship design, which currently involves years long cycles and small batch production, could greatly benefit from these advancements. By developing a machine learning tool for ship design that learns from the design of many different types of ships, tradeoffs in ship design could be identified and optimized. However, the lack of publicly available ship design datasets currently limits the potential for leveraging machine learning in generalized ship design. To address this gap, this paper presents a large dataset of thirty thousand ship hulls, each with design and functional performance information, including parameterization, mesh, point cloud, and image representations, as well as thirty two hydrodynamic drag measures under different operating conditions. The dataset is structured to allow human input and is also designed for computational methods. Additionally, the paper introduces a set of twelve ship hulls from publicly available CAD repositories to showcase the proposed parameterizations ability to accurately reconstruct existing hulls. A surrogate model was developed to predict the thirty two wave drag coefficients, which was then implemented in a genetic algorithm case study to reduce the total drag of a hull by sixty percent while maintaining the shape of the hulls cross section and the length of the parallel midbody. Our work provides a comprehensive dataset and application examples for other researchers to use in advancing data driven ship design.
Text2Cohort: Democratizing the NCI Imaging Data Commons with Natural Language Cohort Discovery
May 16, 2023
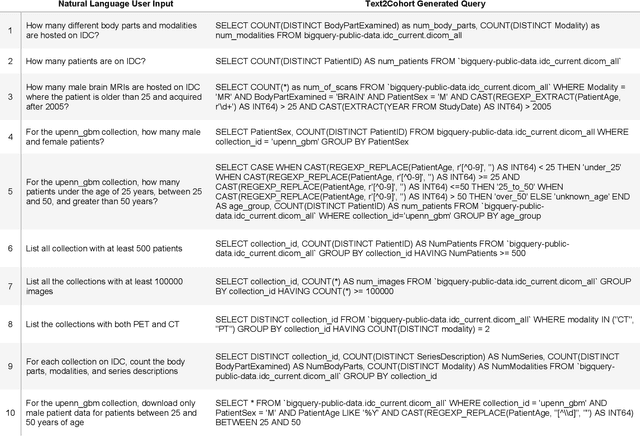

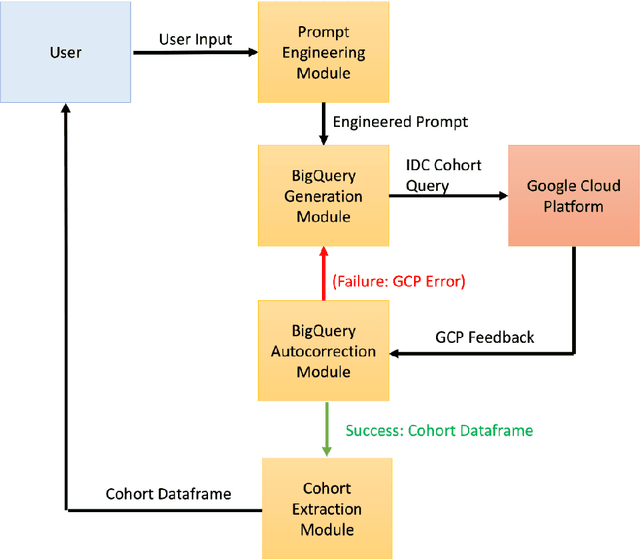
The Imaging Data Commons (IDC) is a cloud-based database that provides researchers with open access to cancer imaging data, with the goal of facilitating collaboration in medical imaging research. However, querying the IDC database for cohort discovery and access to imaging data has a significant learning curve for researchers due to its complex nature. We developed Text2Cohort, a large language model (LLM) based toolkit to facilitate user-friendly and intuitive natural language cohort discovery in the IDC. Text2Cohorts translates user input into IDC database queries using prompt engineering and autocorrection and returns the query's response to the user. Autocorrection resolves errors in queries by passing the errors back to the model for interpretation and correction. We evaluate Text2Cohort on 50 natural language user inputs ranging from information extraction to cohort discovery. The resulting queries and outputs were verified by two computer scientists to measure Text2Cohort's accuracy and F1 score. Text2Cohort successfully generated queries and their responses with an 88% accuracy and F1 score of 0.94. However, it failed to generate queries for 6/50 (12%) user inputs due to syntax and semantic errors. Our results indicate that Text2Cohort succeeded at generating queries with correct responses, but occasionally failed due to a lack of understanding of the data schema. Despite these shortcomings, Text2Cohort demonstrates the utility of LLMs to enable researchers to discover and curate cohorts using data hosted on IDC with high levels of accuracy using natural language in a more intuitive and user-friendly way.
Conditional variational autoencoder with Gaussian process regression recognition for parametric models
May 16, 2023
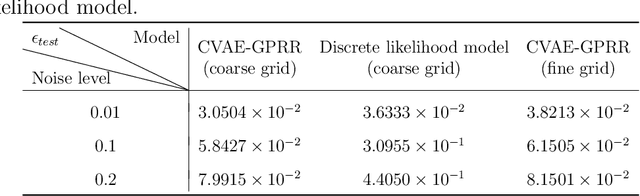

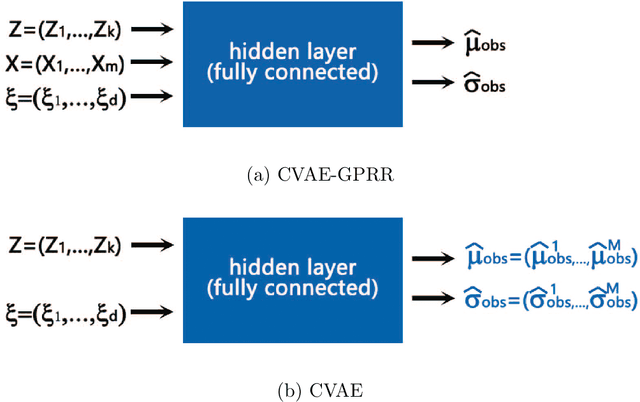
In this article, we present a data-driven method for parametric models with noisy observation data. Gaussian process regression based reduced order modeling (GPR-based ROM) can realize fast online predictions without using equations in the offline stage. However, GPR-based ROM does not perform well for complex systems since POD projection are naturally linear. Conditional variational autoencoder (CVAE) can address this issue via nonlinear neural networks but it has more model complexity, which poses challenges for training and tuning hyperparameters. To this end, we propose a framework of CVAE with Gaussian process regression recognition (CVAE-GPRR). The proposed method consists of a recognition model and a likelihood model. In the recognition model, we first extract low-dimensional features from data by POD to filter the redundant information with high frequency. And then a non-parametric model GPR is used to learn the map from parameters to POD latent variables, which can also alleviate the impact of noise. CVAE-GPRR can achieve the similar accuracy to CVAE but with fewer parameters. In the likelihood model, neural networks are used to reconstruct data. Besides the samples of POD latent variables and input parameters, physical variables are also added as the inputs to make predictions in the whole physical space. This can not be achieved by either GPR-based ROM or CVAE. Moreover, the numerical results show that CVAE-GPRR may alleviate the overfitting issue in CVAE.
Fusion-S2iGan: An Efficient and Effective Single-Stage Framework for Speech-to-Image Generation
May 17, 2023
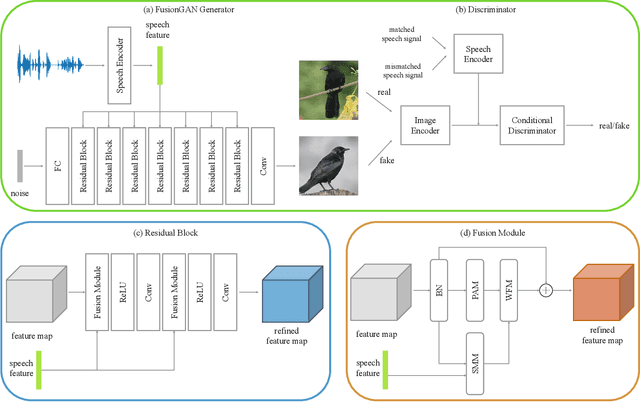
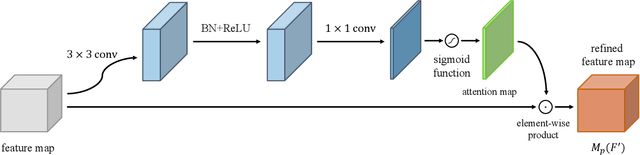
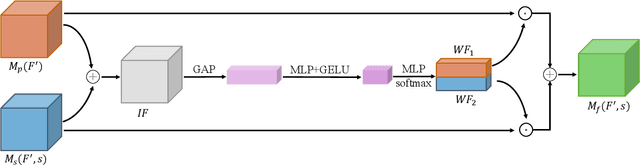
The goal of a speech-to-image transform is to produce a photo-realistic picture directly from a speech signal. Recently, various studies have focused on this task and have achieved promising performance. However, current speech-to-image approaches are based on a stacked modular framework that suffers from three vital issues: 1) Training separate networks is time-consuming as well as inefficient and the convergence of the final generative model strongly depends on the previous generators; 2) The quality of precursor images is ignored by this architecture; 3) Multiple discriminator networks are required to be trained. To this end, we propose an efficient and effective single-stage framework called Fusion-S2iGan to yield perceptually plausible and semantically consistent image samples on the basis of given spoken descriptions. Fusion-S2iGan introduces a visual+speech fusion module (VSFM), constructed with a pixel-attention module (PAM), a speech-modulation module (SMM) and a weighted-fusion module (WFM), to inject the speech embedding from a speech encoder into the generator while improving the quality of synthesized pictures. Fusion-S2iGan spreads the bimodal information over all layers of the generator network to reinforce the visual feature maps at various hierarchical levels in the architecture. We conduct a series of experiments on four benchmark data sets, i.e., CUB birds, Oxford-102, Flickr8k and Places-subset. The experimental results demonstrate the superiority of the presented Fusion-S2iGan compared to the state-of-the-art models with a multi-stage architecture and a performance level that is close to traditional text-to-image approaches.
FactKG: Fact Verification via Reasoning on Knowledge Graphs
May 11, 2023

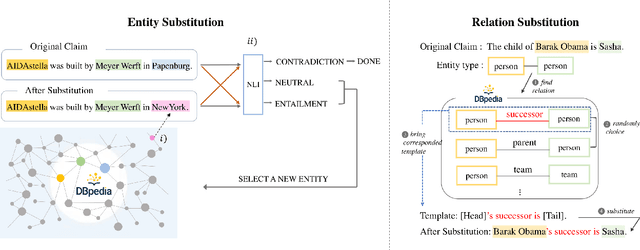
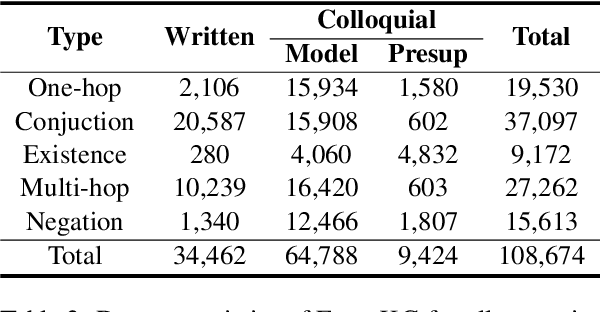
In real world applications, knowledge graphs (KG) are widely used in various domains (e.g. medical applications and dialogue agents). However, for fact verification, KGs have not been adequately utilized as a knowledge source. KGs can be a valuable knowledge source in fact verification due to their reliability and broad applicability. A KG consists of nodes and edges which makes it clear how concepts are linked together, allowing machines to reason over chains of topics. However, there are many challenges in understanding how these machine-readable concepts map to information in text. To enable the community to better use KGs, we introduce a new dataset, FactKG: Fact Verification via Reasoning on Knowledge Graphs. It consists of 108k natural language claims with five types of reasoning: One-hop, Conjunction, Existence, Multi-hop, and Negation. Furthermore, FactKG contains various linguistic patterns, including colloquial style claims as well as written style claims to increase practicality. Lastly, we develop a baseline approach and analyze FactKG over these reasoning types. We believe FactKG can advance both reliability and practicality in KG-based fact verification.
SparseGNV: Generating Novel Views of Indoor Scenes with Sparse Input Views
May 11, 2023
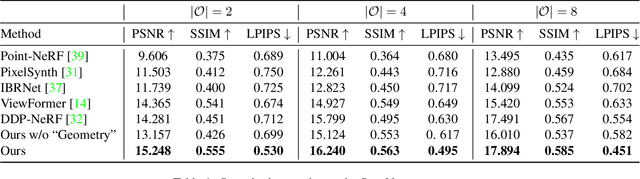
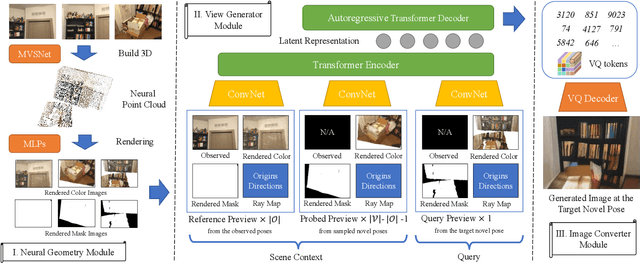

We study to generate novel views of indoor scenes given sparse input views. The challenge is to achieve both photorealism and view consistency. We present SparseGNV: a learning framework that incorporates 3D structures and image generative models to generate novel views with three modules. The first module builds a neural point cloud as underlying geometry, providing contextual information and guidance for the target novel view. The second module utilizes a transformer-based network to map the scene context and the guidance into a shared latent space and autoregressively decodes the target view in the form of discrete image tokens. The third module reconstructs the tokens into the image of the target view. SparseGNV is trained across a large indoor scene dataset to learn generalizable priors. Once trained, it can efficiently generate novel views of an unseen indoor scene in a feed-forward manner. We evaluate SparseGNV on both real-world and synthetic indoor scenes and demonstrate that it outperforms state-of-the-art methods based on either neural radiance fields or conditional image generation.
Local Life: Stay Informed Around You, A Scalable Geoparsing and Geotagging Approach to Serve Local News Worldwide
May 11, 2023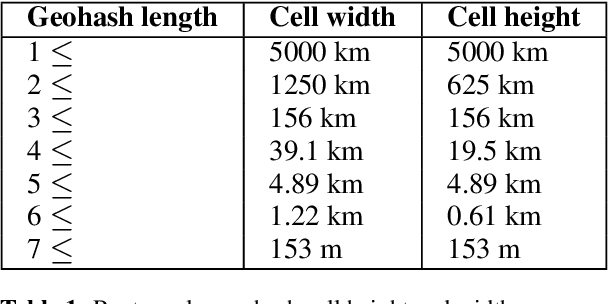
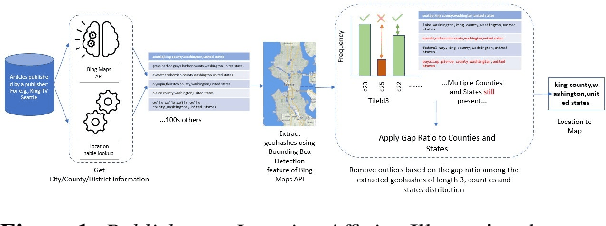
Local news has become increasingly important in the news industry due to its various benefits. It offers local audiences information that helps them participate in their communities and interests. It also serves as a reliable source of factual reporting that can prevent misinformation. Moreover, it can influence national audiences as some local stories may have wider implications for politics, environment or crime. Hence, detecting the exact geolocation and impact scope of local news is crucial for news recommendation systems. There are two fundamental things required in this process, (1) classify whether an article belongs to local news, and (2) identify the geolocation of the article and its scope of influence to recommend it to appropriate users. In this paper, we focus on the second step and propose (1) an efficient approach to determine the location and radius of local news articles, (2) a method to reconcile the user's location with the article's location, and (3) a metric to evaluate the quality of the local news feed. We demonstrate that our technique is scalable and effective in serving hyperlocal news to users worldwide.
A statistical approach to detect sensitive features in a group fairness setting
May 11, 2023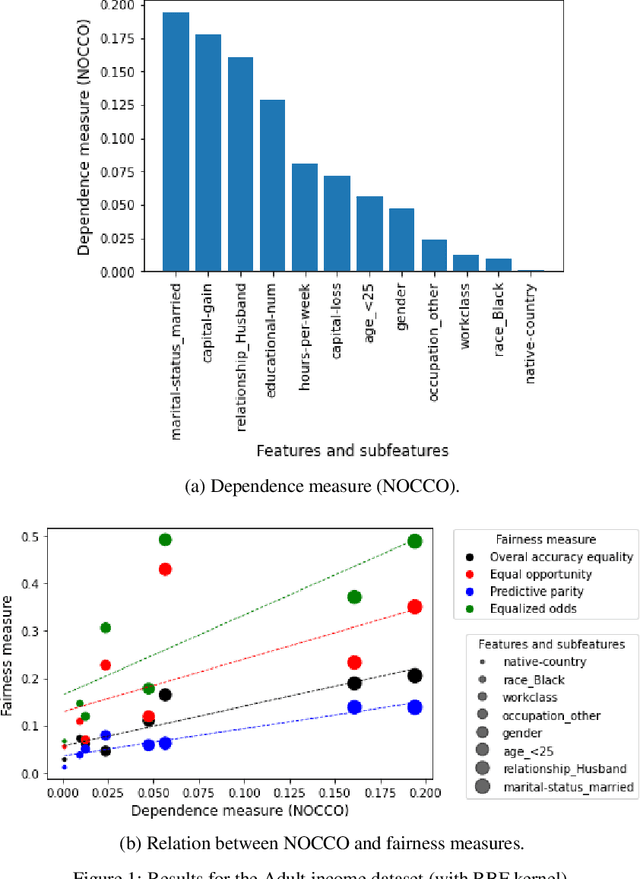
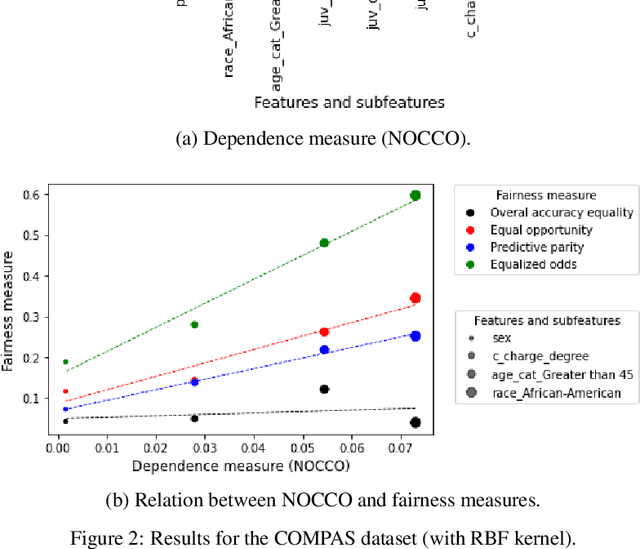
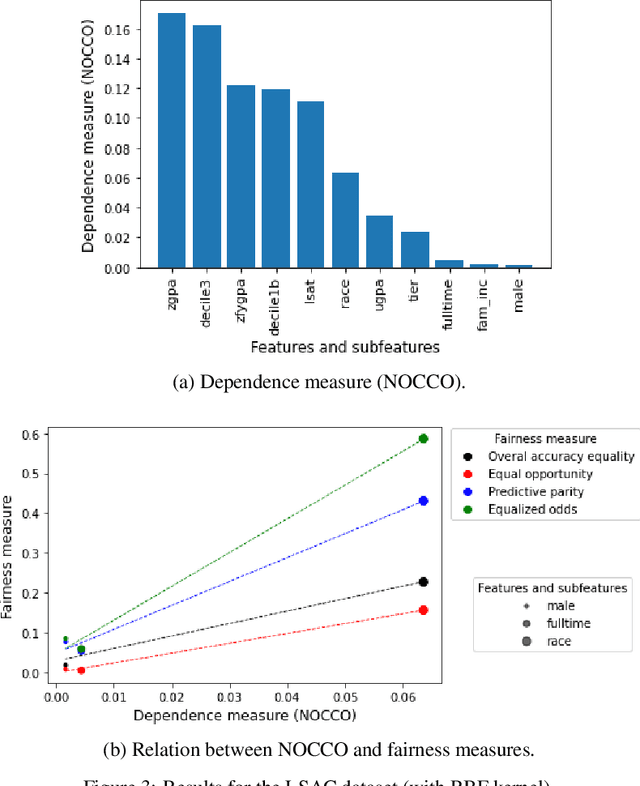
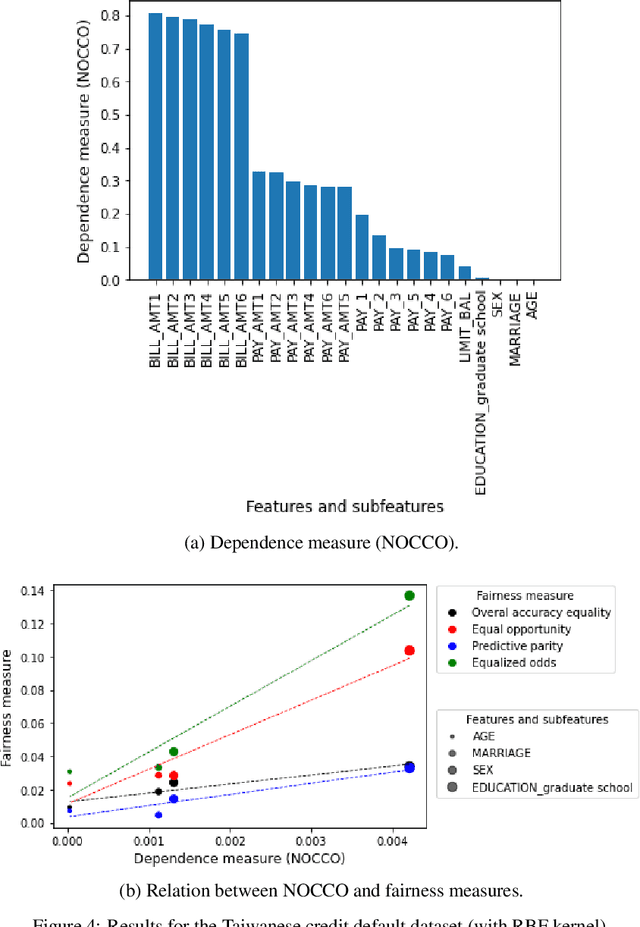
The use of machine learning models in decision support systems with high societal impact raised concerns about unfair (disparate) results for different groups of people. When evaluating such unfair decisions, one generally relies on predefined groups that are determined by a set of features that are considered sensitive. However, such an approach is subjective and does not guarantee that these features are the only ones to be considered as sensitive nor that they entail unfair (disparate) outcomes. In this paper, we propose a preprocessing step to address the task of automatically recognizing sensitive features that does not require a trained model to verify unfair results. Our proposal is based on the Hilber-Schmidt independence criterion, which measures the statistical dependence of variable distributions. We hypothesize that if the dependence between the label vector and a candidate is high for a sensitive feature, then the information provided by this feature will entail disparate performance measures between groups. Our empirical results attest our hypothesis and show that several features considered as sensitive in the literature do not necessarily entail disparate (unfair) results.