 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Differential Convolutional Fuzzy Time Series Forecasting
May 15, 2023
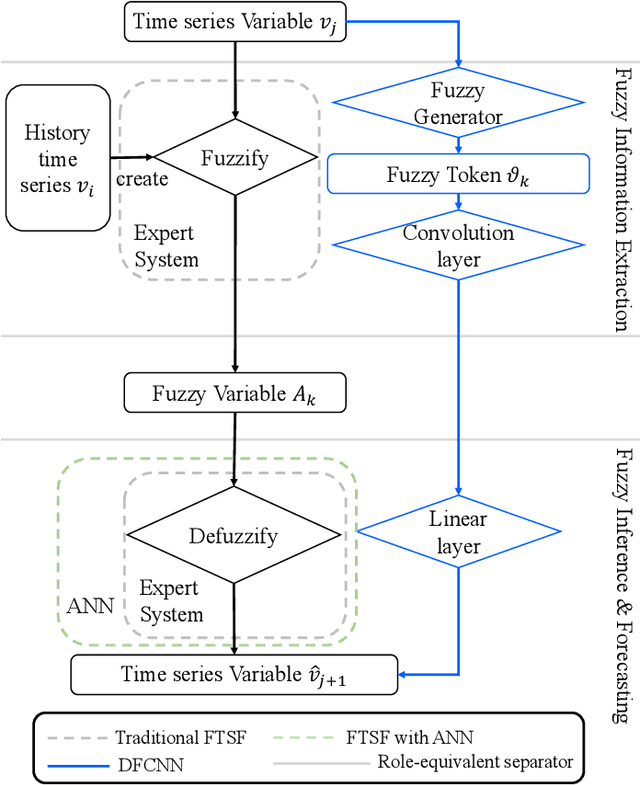
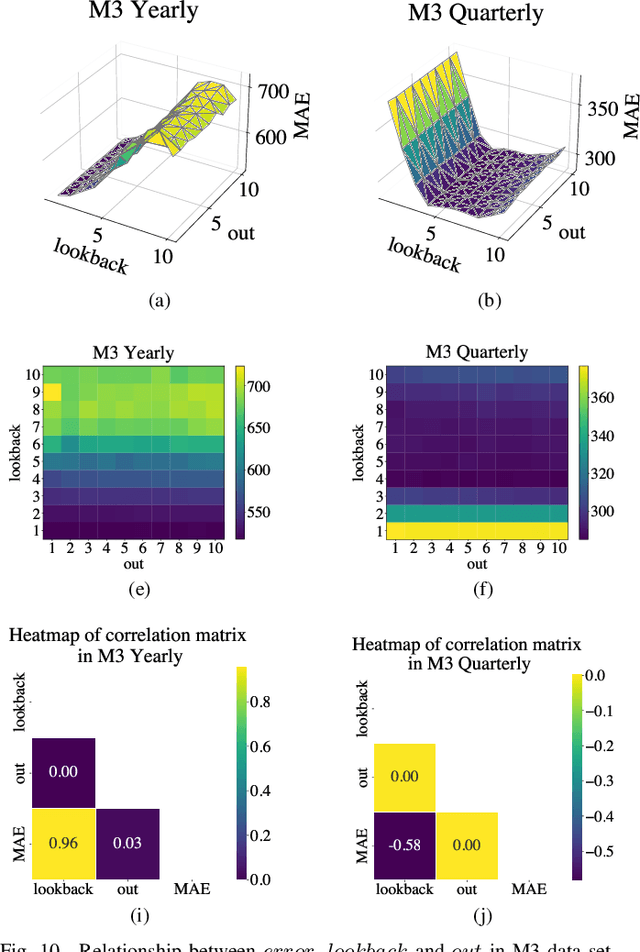
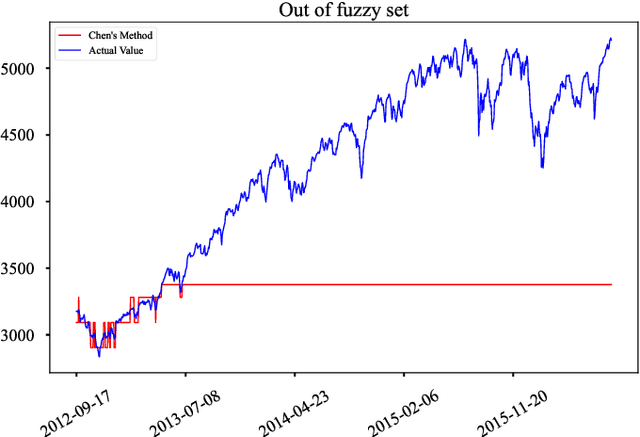
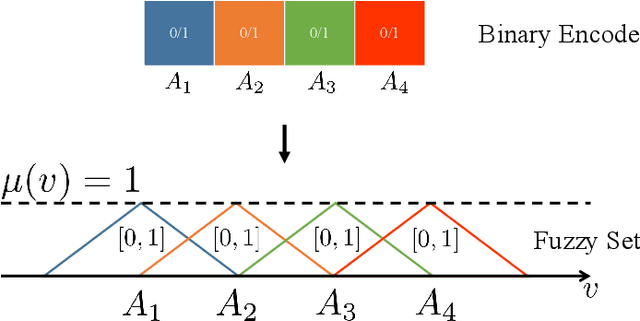
Fuzzy time series forecasting (FTSF) is a typical forecasting method with wide application. Traditional FTSF is regarded as an expert system which leads to lose the ability to recognize undefined feature. The mentioned is main reason of poor forecasting with FTSF. To solve the problem, the proposed model Differential Fuzzy Convolutional Neural Network (DFCNN) utilizes convolution neural network to re-implement FTSF with learnable ability. DFCNN is capable of recognizing the potential information and improve the forecasting accuracy. Thanks to learnable ability of neural network, length of fuzzy rules established in FTSF is expended to arbitrary length which expert is not able to be handle by expert system. At the same time, FTSF usually cannot achieve satisfactory performance of non-stationary time series due to trend of non-stationary time series. The trend of non-stationary time series causes the fuzzy set established by FTSF to invalid and cause the forecasting to fail. DFCNN utilizes the Difference algorithm to weaken the non-stationarity of time series, so that DFCNN can forecast the non-stationary time series with low error that FTSF cannot forecast in satisfactory performance. After mass of experiments, DFCNN has excellent prediction effect, which is ahead of the existing FTSF and common time series forecasting algorithms. Finally, DFCNN provides further ideas for improving FTSF and holds continued research value.
PLM-GNN: A Webpage Classification Method based on Joint Pre-trained Language Model and Graph Neural Network
May 09, 2023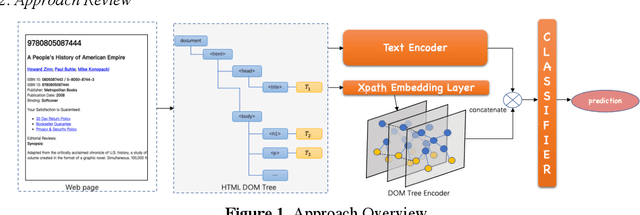

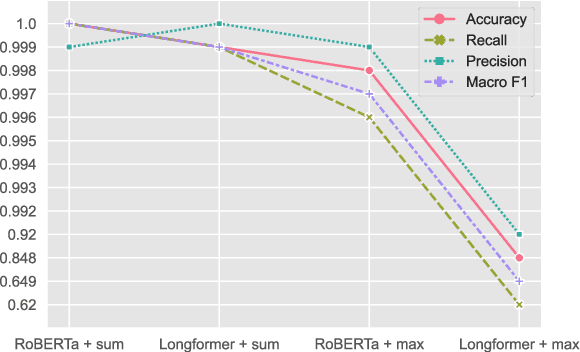
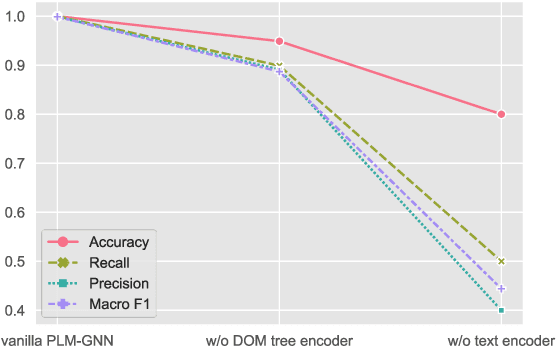
The number of web pages is growing at an exponential rate, accumulating massive amounts of data on the web. It is one of the key processes to classify webpages in web information mining. Some classical methods are based on manually building features of web pages and training classifiers based on machine learning or deep learning. However, building features manually requires specific domain knowledge and usually takes a long time to validate the validity of features. Considering webpages generated by the combination of text and HTML Document Object Model(DOM) trees, we propose a representation and classification method based on a pre-trained language model and graph neural network, named PLM-GNN. It is based on the joint encoding of text and HTML DOM trees in the web pages. It performs well on the KI-04 and SWDE datasets and on practical dataset AHS for the project of scholar's homepage crawling.
Fully Bayesian VIB-DeepSSM
May 09, 2023
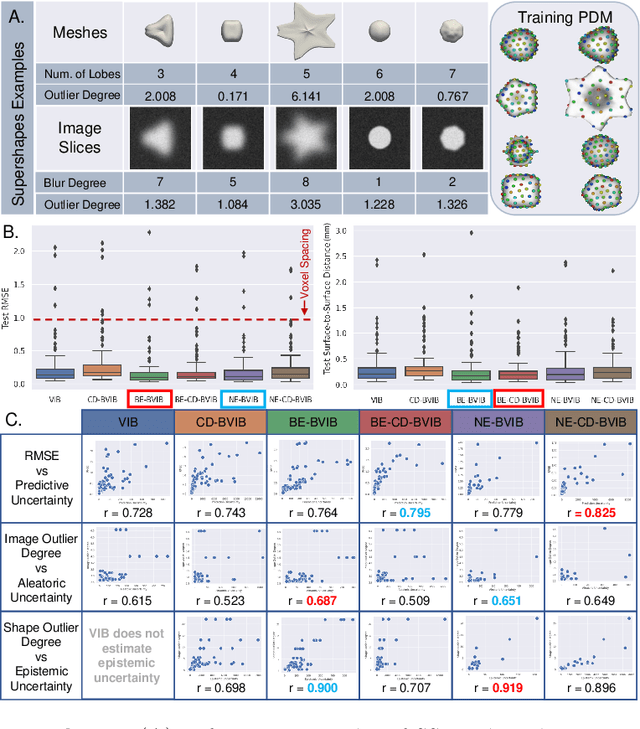
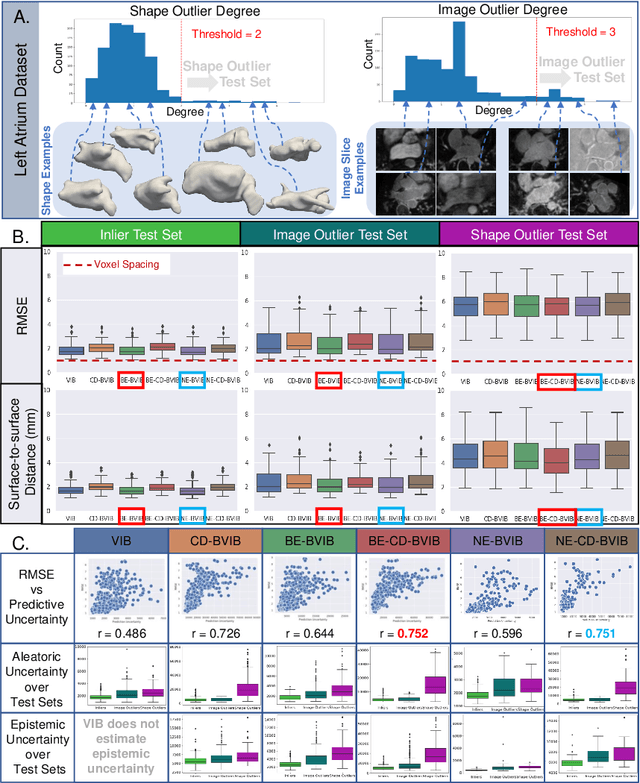
Statistical shape modeling (SSM) enables population-based quantitative analysis of anatomical shapes, informing clinical diagnosis. Deep learning approaches predict correspondence-based SSM directly from unsegmented 3D images but require calibrated uncertainty quantification, motivating Bayesian formulations. Variational information bottleneck DeepSSM (VIB-DeepSSM) is an effective, principled framework for predicting probabilistic shapes of anatomy from images with aleatoric uncertainty quantification. However, VIB is only half-Bayesian and lacks epistemic uncertainty inference. We derive a fully Bayesian VIB formulation from both the probably approximately correct (PAC)-Bayes and variational inference perspectives. We demonstrate the efficacy of two scalable approaches for Bayesian VIB with epistemic uncertainty: concrete dropout and batch ensemble. Additionally, we introduce a novel combination of the two that further enhances uncertainty calibration via multimodal marginalization. Experiments on synthetic shapes and left atrium data demonstrate that the fully Bayesian VIB network predicts SSM from images with improved uncertainty reasoning without sacrificing accuracy.
Learning Personalized Page Content Ranking Using Customer Representation
May 09, 2023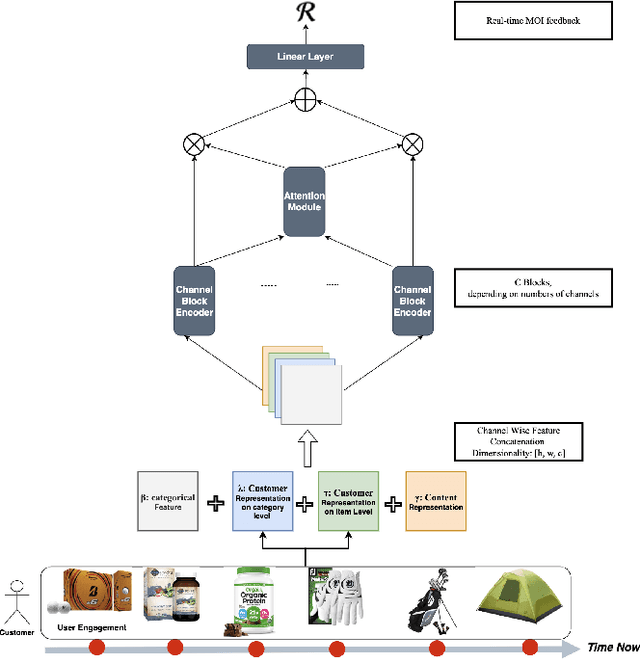
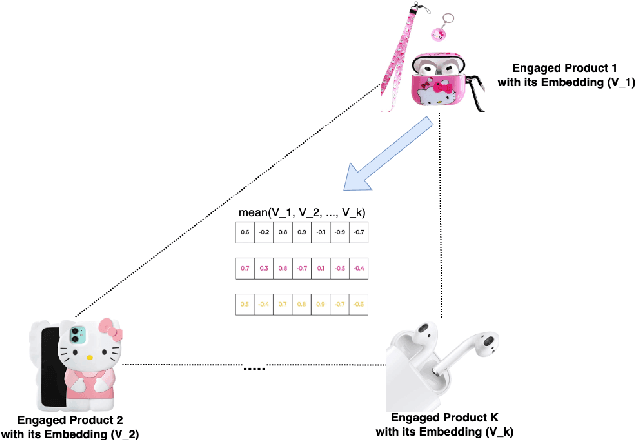
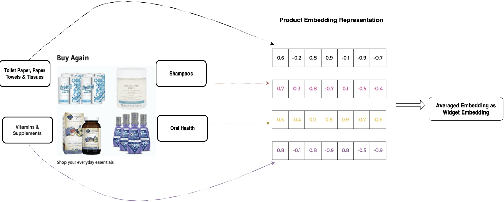

On E-commerce stores (Amazon, eBay etc.) there are rich recommendation content to help shoppers shopping more efficiently. However given numerous products, it's crucial to select most relevant content to reduce the burden of information overload. We introduced a content ranking service powered by a linear causal bandit algorithm to rank and select content for each shopper under each context. The algorithm mainly leverages aggregated customer behavior features, and ignores single shopper level past activities. We study the problem of inferring shoppers interest from historical activities. We propose a deep learning based bandit algorithm that incorporates historical shopping behavior, customer latent shopping goals, and the correlation between customers and content categories. This model produces more personalized content ranking measured by 12.08% nDCG lift. In the online A/B test setting, the model improved 0.02% annualized commercial impact measured by our business metric, validating its effectiveness.
Learning from Aggregated Data: Curated Bags versus Random Bags
May 18, 2023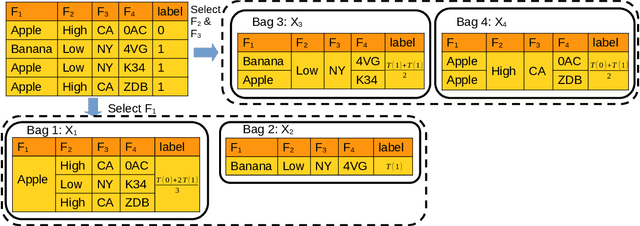
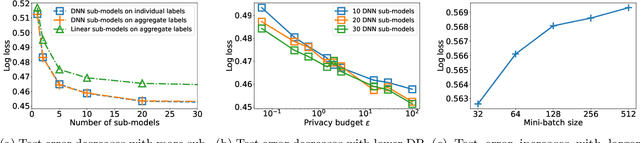
Protecting user privacy is a major concern for many machine learning systems that are deployed at scale and collect from a diverse set of population. One way to address this concern is by collecting and releasing data labels in an aggregated manner so that the information about a single user is potentially combined with others. In this paper, we explore the possibility of training machine learning models with aggregated data labels, rather than individual labels. Specifically, we consider two natural aggregation procedures suggested by practitioners: curated bags where the data points are grouped based on common features and random bags where the data points are grouped randomly in bag of similar sizes. For the curated bag setting and for a broad range of loss functions, we show that we can perform gradient-based learning without any degradation in performance that may result from aggregating data. Our method is based on the observation that the sum of the gradients of the loss function on individual data examples in a curated bag can be computed from the aggregate label without the need for individual labels. For the random bag setting, we provide a generalization risk bound based on the Rademacher complexity of the hypothesis class and show how empirical risk minimization can be regularized to achieve the smallest risk bound. In fact, in the random bag setting, there is a trade-off between size of the bag and the achievable error rate as our bound indicates. Finally, we conduct a careful empirical study to confirm our theoretical findings. In particular, our results suggest that aggregate learning can be an effective method for preserving user privacy while maintaining model accuracy.
Much Ado About Gender: Current Practices and Future Recommendations for Appropriate Gender-Aware Information Access
Jan 13, 2023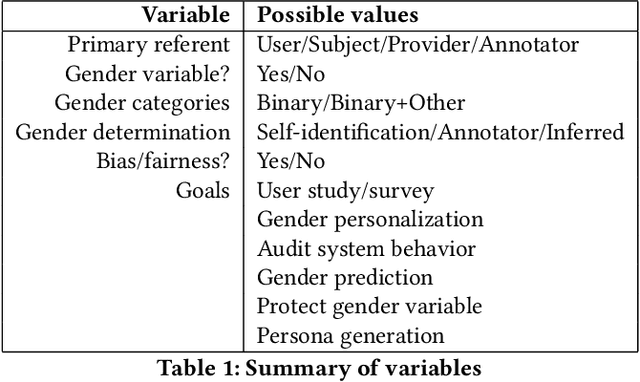
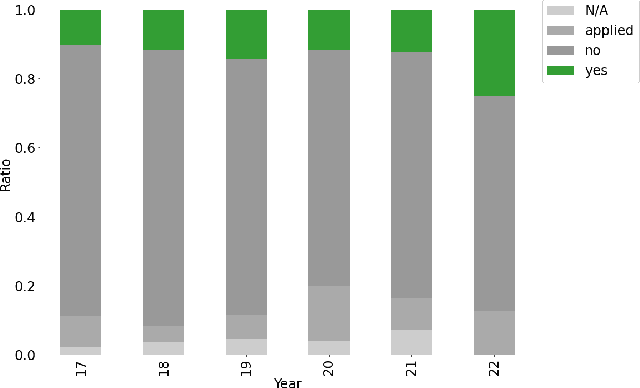
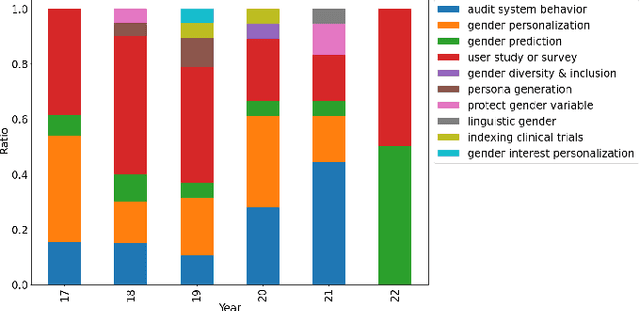
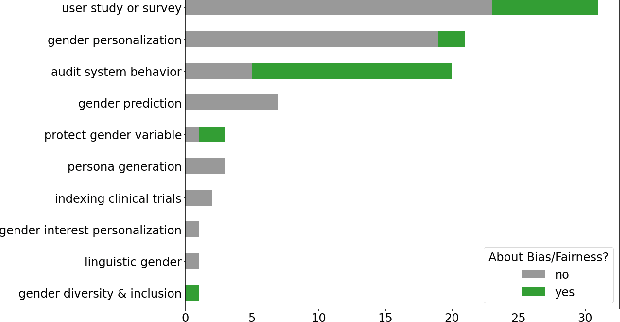
Information access research (and development) sometimes makes use of gender, whether to report on the demographics of participants in a user study, as inputs to personalized results or recommendations, or to make systems gender-fair, amongst other purposes. This work makes a variety of assumptions about gender, however, that are not necessarily aligned with current understandings of what gender is, how it should be encoded, and how a gender variable should be ethically used. In this work, we present a systematic review of papers on information retrieval and recommender systems that mention gender in order to document how gender is currently being used in this field. We find that most papers mentioning gender do not use an explicit gender variable, but most of those that do either focus on contextualizing results of model performance, personalizing a system based on assumptions of user gender, or auditing a model's behavior for fairness or other privacy-related issues. Moreover, most of the papers we review rely on a binary notion of gender, even if they acknowledge that gender cannot be split into two categories. We connect these findings with scholarship on gender theory and recent work on gender in human-computer interaction and natural language processing. We conclude by making recommendations for ethical and well-grounded use of gender in building and researching information access systems.
Ship-D: Ship Hull Dataset for Design Optimization using Machine Learning
May 16, 2023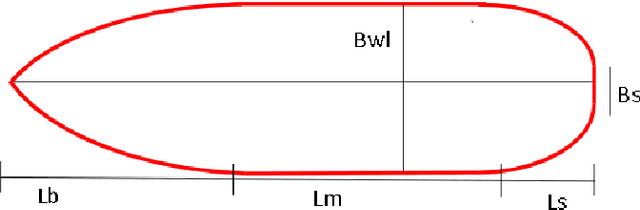


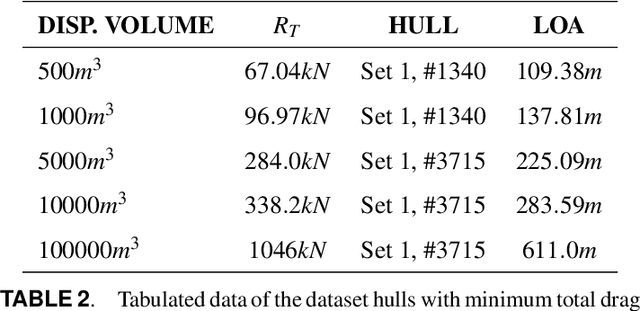
Machine learning has recently made significant strides in reducing design cycle time for complex products. Ship design, which currently involves years long cycles and small batch production, could greatly benefit from these advancements. By developing a machine learning tool for ship design that learns from the design of many different types of ships, tradeoffs in ship design could be identified and optimized. However, the lack of publicly available ship design datasets currently limits the potential for leveraging machine learning in generalized ship design. To address this gap, this paper presents a large dataset of thirty thousand ship hulls, each with design and functional performance information, including parameterization, mesh, point cloud, and image representations, as well as thirty two hydrodynamic drag measures under different operating conditions. The dataset is structured to allow human input and is also designed for computational methods. Additionally, the paper introduces a set of twelve ship hulls from publicly available CAD repositories to showcase the proposed parameterizations ability to accurately reconstruct existing hulls. A surrogate model was developed to predict the thirty two wave drag coefficients, which was then implemented in a genetic algorithm case study to reduce the total drag of a hull by sixty percent while maintaining the shape of the hulls cross section and the length of the parallel midbody. Our work provides a comprehensive dataset and application examples for other researchers to use in advancing data driven ship design.
Text2Cohort: Democratizing the NCI Imaging Data Commons with Natural Language Cohort Discovery
May 16, 2023
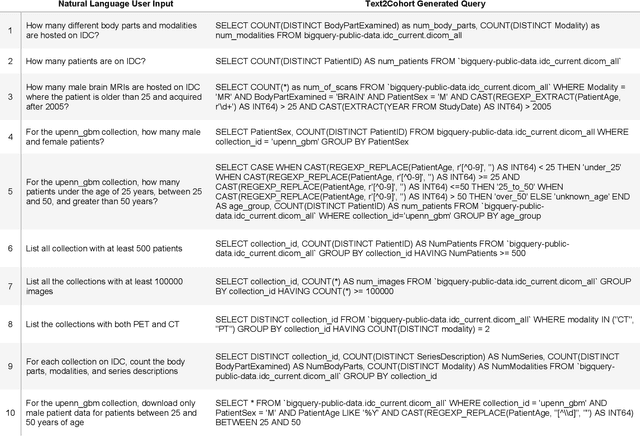

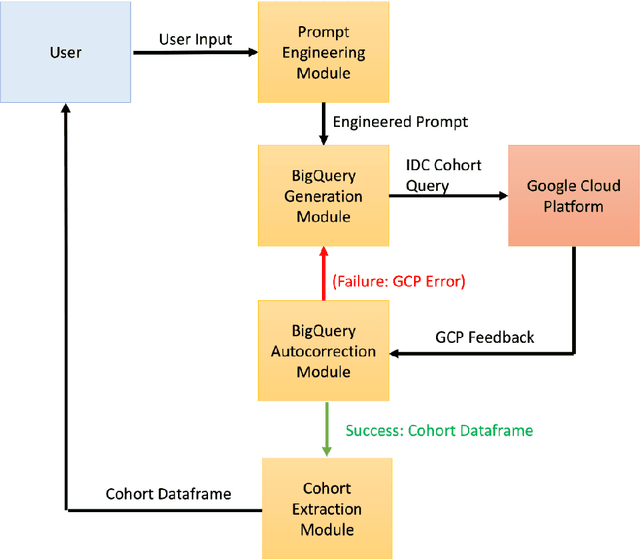
The Imaging Data Commons (IDC) is a cloud-based database that provides researchers with open access to cancer imaging data, with the goal of facilitating collaboration in medical imaging research. However, querying the IDC database for cohort discovery and access to imaging data has a significant learning curve for researchers due to its complex nature. We developed Text2Cohort, a large language model (LLM) based toolkit to facilitate user-friendly and intuitive natural language cohort discovery in the IDC. Text2Cohorts translates user input into IDC database queries using prompt engineering and autocorrection and returns the query's response to the user. Autocorrection resolves errors in queries by passing the errors back to the model for interpretation and correction. We evaluate Text2Cohort on 50 natural language user inputs ranging from information extraction to cohort discovery. The resulting queries and outputs were verified by two computer scientists to measure Text2Cohort's accuracy and F1 score. Text2Cohort successfully generated queries and their responses with an 88% accuracy and F1 score of 0.94. However, it failed to generate queries for 6/50 (12%) user inputs due to syntax and semantic errors. Our results indicate that Text2Cohort succeeded at generating queries with correct responses, but occasionally failed due to a lack of understanding of the data schema. Despite these shortcomings, Text2Cohort demonstrates the utility of LLMs to enable researchers to discover and curate cohorts using data hosted on IDC with high levels of accuracy using natural language in a more intuitive and user-friendly way.
Conditional variational autoencoder with Gaussian process regression recognition for parametric models
May 16, 2023
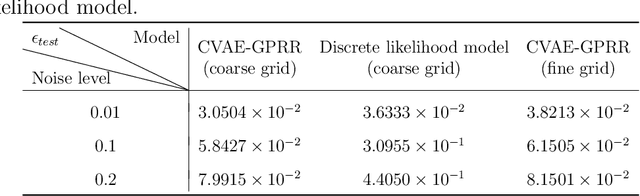

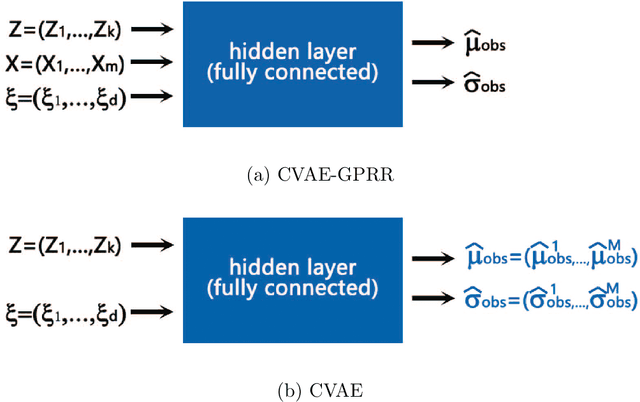
In this article, we present a data-driven method for parametric models with noisy observation data. Gaussian process regression based reduced order modeling (GPR-based ROM) can realize fast online predictions without using equations in the offline stage. However, GPR-based ROM does not perform well for complex systems since POD projection are naturally linear. Conditional variational autoencoder (CVAE) can address this issue via nonlinear neural networks but it has more model complexity, which poses challenges for training and tuning hyperparameters. To this end, we propose a framework of CVAE with Gaussian process regression recognition (CVAE-GPRR). The proposed method consists of a recognition model and a likelihood model. In the recognition model, we first extract low-dimensional features from data by POD to filter the redundant information with high frequency. And then a non-parametric model GPR is used to learn the map from parameters to POD latent variables, which can also alleviate the impact of noise. CVAE-GPRR can achieve the similar accuracy to CVAE but with fewer parameters. In the likelihood model, neural networks are used to reconstruct data. Besides the samples of POD latent variables and input parameters, physical variables are also added as the inputs to make predictions in the whole physical space. This can not be achieved by either GPR-based ROM or CVAE. Moreover, the numerical results show that CVAE-GPRR may alleviate the overfitting issue in CVAE.
Fusion-S2iGan: An Efficient and Effective Single-Stage Framework for Speech-to-Image Generation
May 17, 2023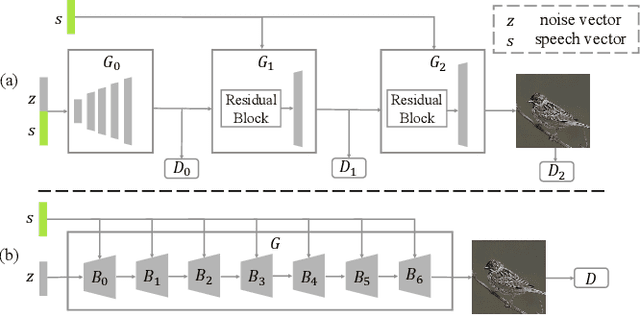
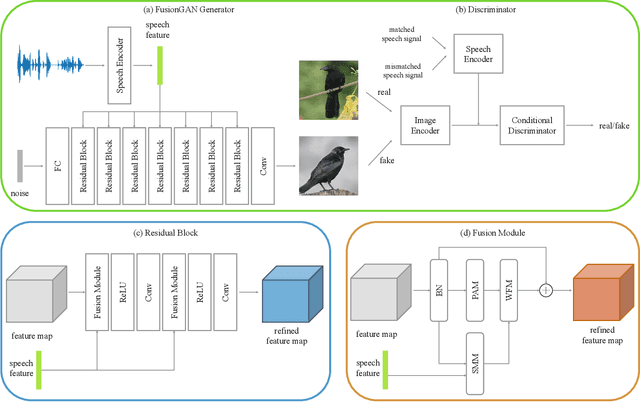
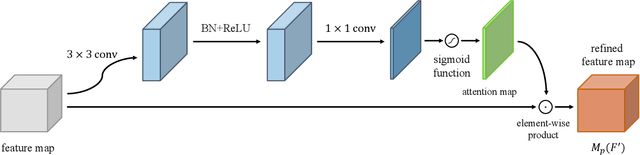
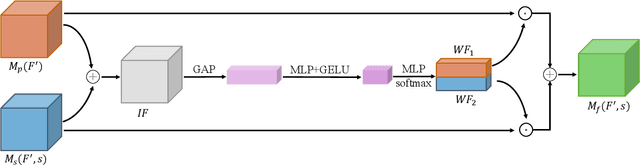
The goal of a speech-to-image transform is to produce a photo-realistic picture directly from a speech signal. Recently, various studies have focused on this task and have achieved promising performance. However, current speech-to-image approaches are based on a stacked modular framework that suffers from three vital issues: 1) Training separate networks is time-consuming as well as inefficient and the convergence of the final generative model strongly depends on the previous generators; 2) The quality of precursor images is ignored by this architecture; 3) Multiple discriminator networks are required to be trained. To this end, we propose an efficient and effective single-stage framework called Fusion-S2iGan to yield perceptually plausible and semantically consistent image samples on the basis of given spoken descriptions. Fusion-S2iGan introduces a visual+speech fusion module (VSFM), constructed with a pixel-attention module (PAM), a speech-modulation module (SMM) and a weighted-fusion module (WFM), to inject the speech embedding from a speech encoder into the generator while improving the quality of synthesized pictures. Fusion-S2iGan spreads the bimodal information over all layers of the generator network to reinforce the visual feature maps at various hierarchical levels in the architecture. We conduct a series of experiments on four benchmark data sets, i.e., CUB birds, Oxford-102, Flickr8k and Places-subset. The experimental results demonstrate the superiority of the presented Fusion-S2iGan compared to the state-of-the-art models with a multi-stage architecture and a performance level that is close to traditional text-to-image approaches.