 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Altered Topological Properties of Functional Brain Network Associated with Alzheimer's Disease
May 14, 2023
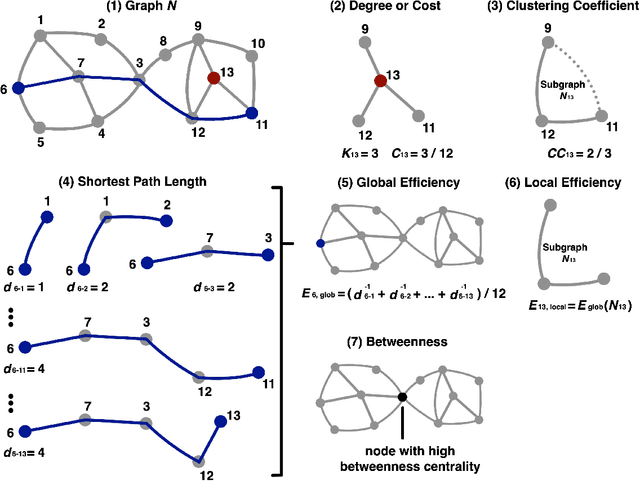
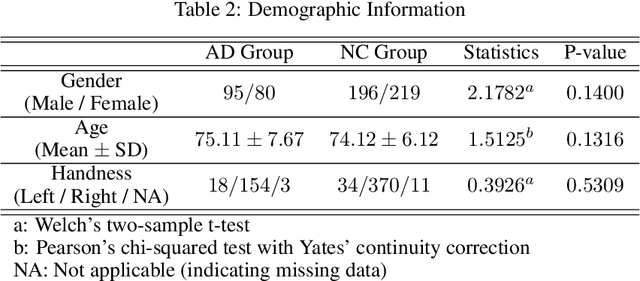
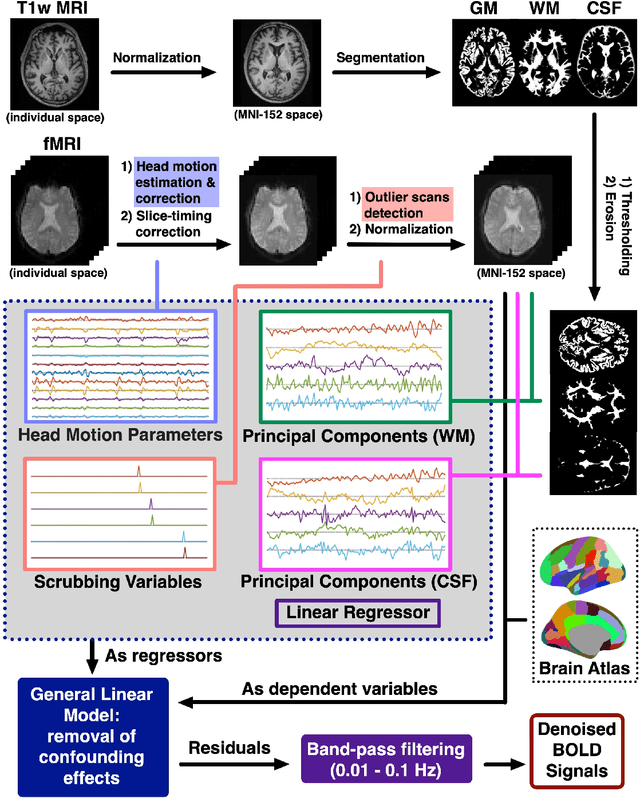
Functional Magnetic Resonance Imaging (fMRI) is commonly utilized to study human brain activity, including abnormal functional properties related to neurodegenerative diseases. This study aims to investigate the differences in the topological properties of functional brain networks between individuals with Alzheimer's Disease (AD) and normal controls. A total of 590 subjects, consisting of 175 with AD dementia and 415 age-, gender-, and handedness-matched controls, were included. The topological properties of the brain network were quantified using graph-theory-based analyses. The results indicate abnormal network integration and segregation in the AD group. These findings enhance our understanding of AD pathophysiology from a functional brain network structure perspective and may aid in identifying AD biomarkers. We provided more information to asist the validation of this study at https://github.com/YongchengYAO/AD-FunctionalBrainNetwork.
Analyzing Hong Kong's Legal Judgments from a Computational Linguistics point-of-view
May 04, 2023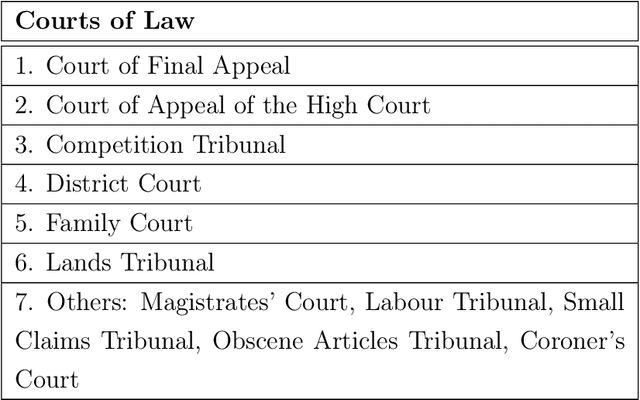
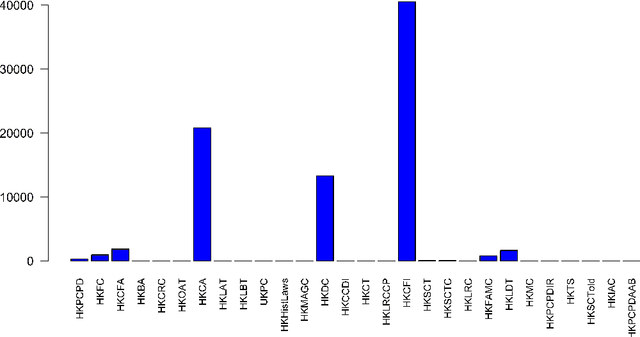
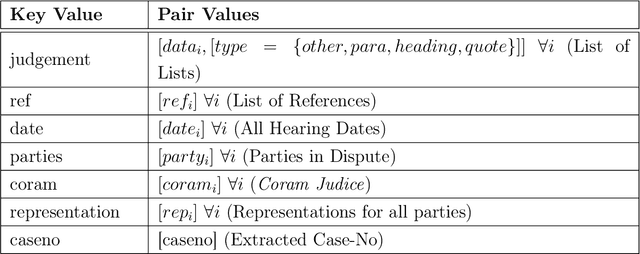
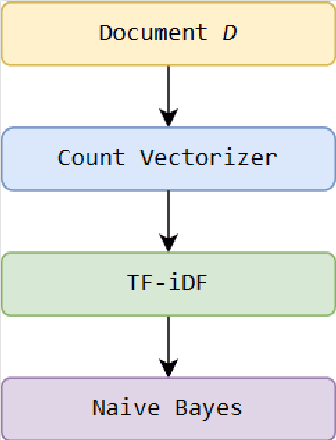
Analysis and extraction of useful information from legal judgments using computational linguistics was one of the earliest problems posed in the domain of information retrieval. Presently, several commercial vendors exist who automate such tasks. However, a crucial bottleneck arises in the form of exorbitant pricing and lack of resources available in analysis of judgements mete out by Hong Kong's Legal System. This paper attempts to bridge this gap by providing several statistical, machine learning, deep learning and zero-shot learning based methods to effectively analyze legal judgments from Hong Kong's Court System. The methods proposed consists of: (1) Citation Network Graph Generation, (2) PageRank Algorithm, (3) Keyword Analysis and Summarization, (4) Sentiment Polarity, and (5) Paragrah Classification, in order to be able to extract key insights from individual as well a group of judgments together. This would make the overall analysis of judgments in Hong Kong less tedious and more automated in order to extract insights quickly using fast inferencing. We also provide an analysis of our results by benchmarking our results using Large Language Models making robust use of the HuggingFace ecosystem.
X-LLM: Bootstrapping Advanced Large Language Models by Treating Multi-Modalities as Foreign Languages
May 10, 2023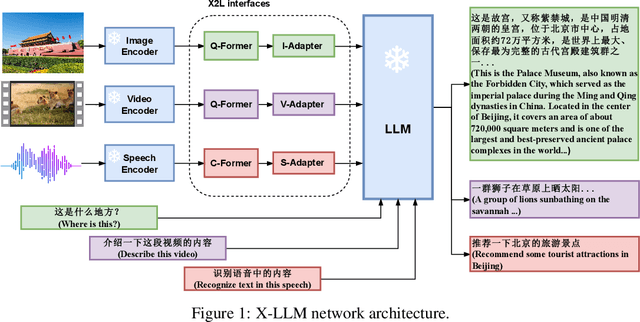
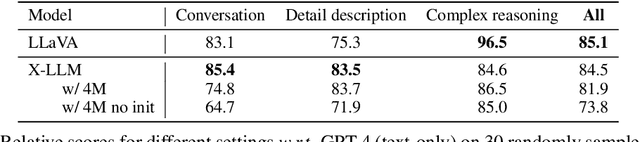


Large language models (LLMs) have demonstrated remarkable language abilities. GPT-4, based on advanced LLMs, exhibits extraordinary multimodal capabilities beyond previous visual language models. We attribute this to the use of more advanced LLMs compared with previous multimodal models. Unfortunately, the model architecture and training strategies of GPT-4 are unknown. To endow LLMs with multimodal capabilities, we propose X-LLM, which converts Multi-modalities (images, speech, videos) into foreign languages using X2L interfaces and inputs them into a large Language model (ChatGLM). Specifically, X-LLM aligns multiple frozen single-modal encoders and a frozen LLM using X2L interfaces, where ``X'' denotes multi-modalities such as image, speech, and videos, and ``L'' denotes languages. X-LLM's training consists of three stages: (1) Converting Multimodal Information: The first stage trains each X2L interface to align with its respective single-modal encoder separately to convert multimodal information into languages. (2) Aligning X2L representations with the LLM: single-modal encoders are aligned with the LLM through X2L interfaces independently. (3) Integrating multiple modalities: all single-modal encoders are aligned with the LLM through X2L interfaces to integrate multimodal capabilities into the LLM. Our experiments show that X-LLM demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 84.5\% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. And we also conduct quantitative tests on using LLM for ASR and multimodal ASR, hoping to promote the era of LLM-based speech recognition.
Subject-based Non-contrastive Self-Supervised Learning for ECG Signal Processing
May 12, 2023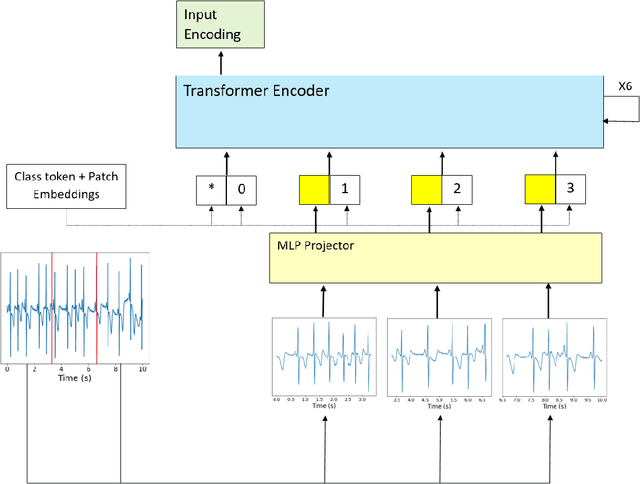

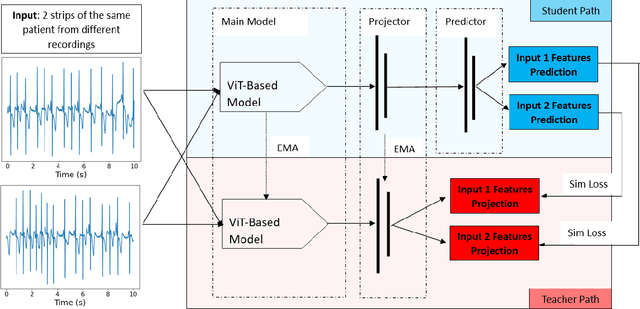
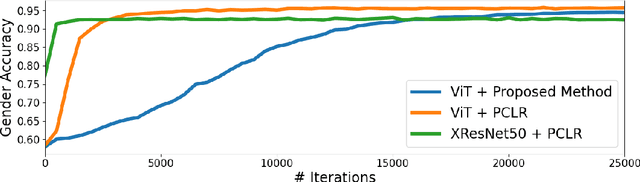
Extracting information from the electrocardiography (ECG) signal is an essential step in the design of digital health technologies in cardiology. In recent years, several machine learning (ML) algorithms for automatic extraction of information in ECG have been proposed. Supervised learning methods have successfully been used to identify specific aspects in the signal, like detection of rhythm disorders (arrhythmias). Self-supervised learning (SSL) methods, on the other hand, can be used to extract all the features contained in the data. The model is optimized without any specific goal and learns from the data itself. By adapting state-of-the-art computer vision methodologies to the signal processing domain, a few SSL approaches have been reported recently for ECG processing. However, such SSL methods require either data augmentation or negative pairs, which limits the method to only look for similarities between two ECG inputs, either two versions of the same signal or two signals from the same subject. This leads to models that are very effective at extracting characteristics that are stable in a subject, such as gender or age. But they are not successful at capturing changes within the ECG recording that can explain dynamic aspects, like different arrhythmias or different sleep stages. In this work, we introduce the first SSL method that uses neither data augmentation nor negative pairs for understanding ECG signals, and still, achieves comparable quality representations. As a result, it is possible to design a SSL method that not only captures similarities between two inputs, but also captures dissimilarities for a complete understanding of the data. In addition, a model based on transformer blocks is presented, which produces better results than a model based on convolutional layers (XResNet50) with almost the same number of parameters.
Bridging History with AI A Comparative Evaluation of GPT 3.5, GPT4, and GoogleBARD in Predictive Accuracy and Fact Checking
May 13, 2023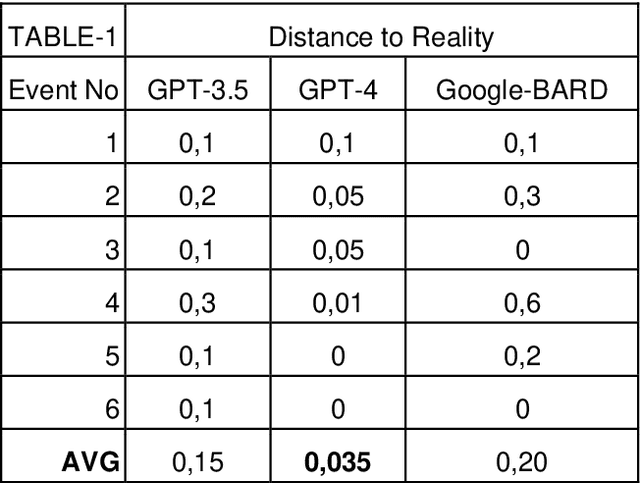
The rapid proliferation of information in the digital era underscores the importance of accurate historical representation and interpretation. While artificial intelligence has shown promise in various fields, its potential for historical fact-checking and gap-filling remains largely untapped. This study evaluates the performance of three large language models LLMs GPT 3.5, GPT 4, and GoogleBARD in the context of predicting and verifying historical events based on given data. A novel metric, Distance to Reality (DTR), is introduced to assess the models' outputs against established historical facts. The results reveal a substantial potential for AI in historical studies, with GPT 4 demonstrating superior performance. This paper underscores the need for further research into AI's role in enriching our understanding of the past and bridging historical knowledge gaps.
Do Models Really Learn to Follow Instructions? An Empirical Study of Instruction Tuning
May 19, 2023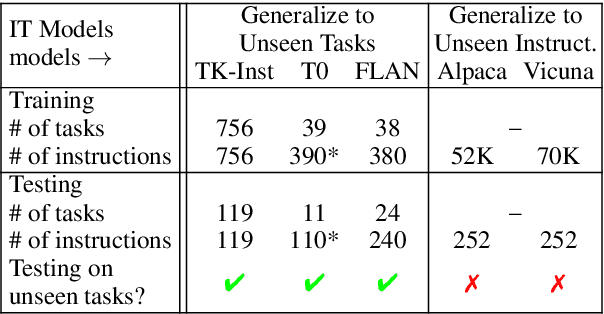
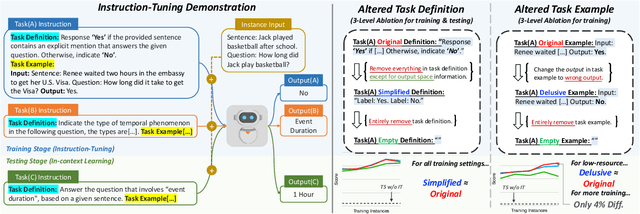
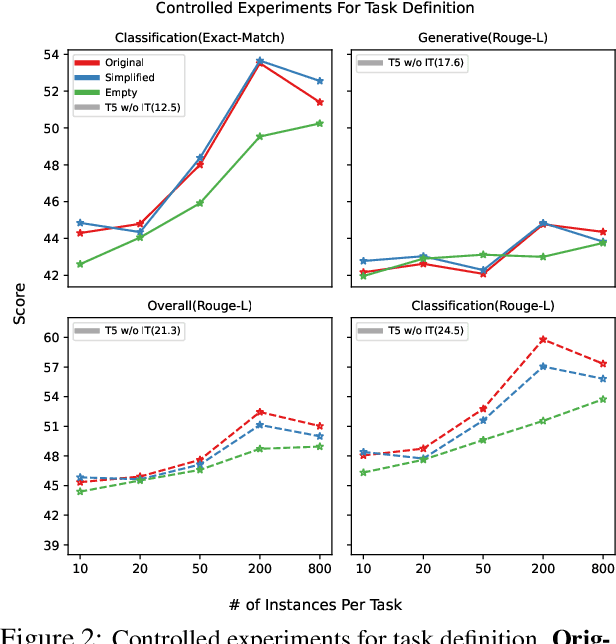
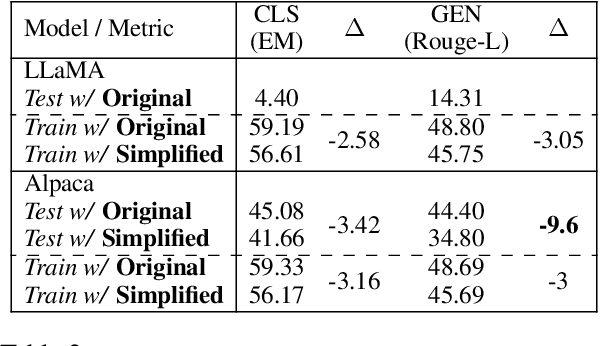
Recent works on instruction tuning (IT) have achieved great performance with zero-shot generalizability to unseen tasks. With additional context (e.g., task definition, examples) provided to models for fine-tuning, they achieved much higher performance than untuned models. However, despite impressive performance gains, the underlying mechanism for IT to work remains understudied. In this work, we analyze how models utilize instructions during IT by comparing model training with altered vs. original instructions. Specifically, we create simplified task definitions by removing all semantic components and only leaving the output space information, and delusive examples that contain incorrect input-output mapping. Our experiments show that models trained on simplified task definition or delusive examples can achieve comparable performance to the ones trained on the original instructions and examples. Furthermore, we introduce a random baseline to perform zero-shot classification tasks, and find it achieves similar performance (40% accuracy) as IT does (48% accuracy). In summary, our analysis provides evidence that the impressive performance gain of current IT models can come from picking up superficial patterns, such as learning the output format and guessing. Our study highlights the urgent need for more reliable IT methods and evaluation.
Speech-Text Dialog Pre-training for Spoken Dialog Understanding with Explicit Cross-Modal Alignment
May 19, 2023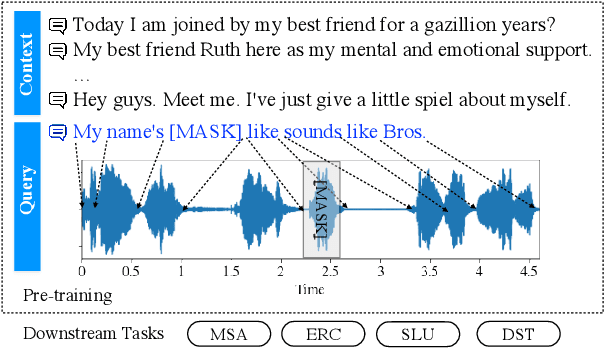

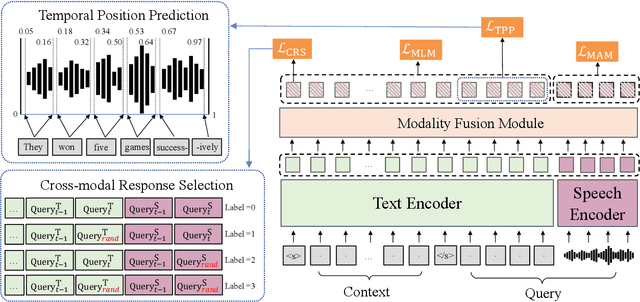
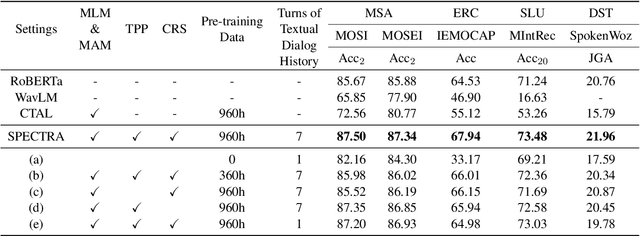
Recently, speech-text pre-training methods have shown remarkable success in many speech and natural language processing tasks. However, most previous pre-trained models are usually tailored for one or two specific tasks, but fail to conquer a wide range of speech-text tasks. In addition, existing speech-text pre-training methods fail to explore the contextual information within a dialogue to enrich utterance representations. In this paper, we propose Speech-text dialog Pre-training for spoken dialog understanding with ExpliCiT cRoss-Modal Alignment (SPECTRA), which is the first-ever speech-text dialog pre-training model. Concretely, to consider the temporality of speech modality, we design a novel temporal position prediction task to capture the speech-text alignment. This pre-training task aims to predict the start and end time of each textual word in the corresponding speech waveform. In addition, to learn the characteristics of spoken dialogs, we generalize a response selection task from textual dialog pre-training to speech-text dialog pre-training scenarios. Experimental results on four different downstream speech-text tasks demonstrate the superiority of SPECTRA in learning speech-text alignment and multi-turn dialog context.
Complex Claim Verification with Evidence Retrieved in the Wild
May 19, 2023
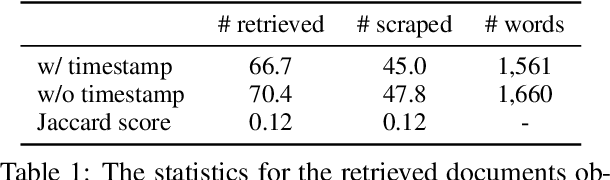
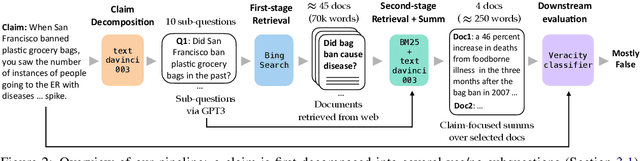
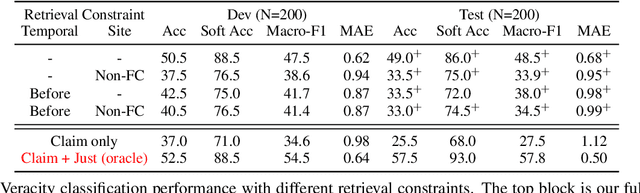
Evidence retrieval is a core part of automatic fact-checking. Prior work makes simplifying assumptions in retrieval that depart from real-world use cases: either no access to evidence, access to evidence curated by a human fact-checker, or access to evidence available long after the claim has been made. In this work, we present the first fully automated pipeline to check real-world claims by retrieving raw evidence from the web. We restrict our retriever to only search documents available prior to the claim's making, modeling the realistic scenario where an emerging claim needs to be checked. Our pipeline includes five components: claim decomposition, raw document retrieval, fine-grained evidence retrieval, claim-focused summarization, and veracity judgment. We conduct experiments on complex political claims in the ClaimDecomp dataset and show that the aggregated evidence produced by our pipeline improves veracity judgments. Human evaluation finds the evidence summary produced by our system is reliable (it does not hallucinate information) and relevant to answering key questions about a claim, suggesting that it can assist fact-checkers even when it cannot surface a complete evidence set.
Polar Ducks and Where to Find Them: Enhancing Entity Linking with Duck Typing and Polar Box Embeddings
May 19, 2023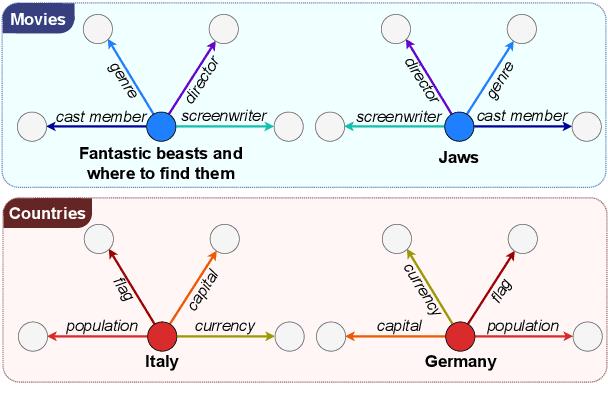
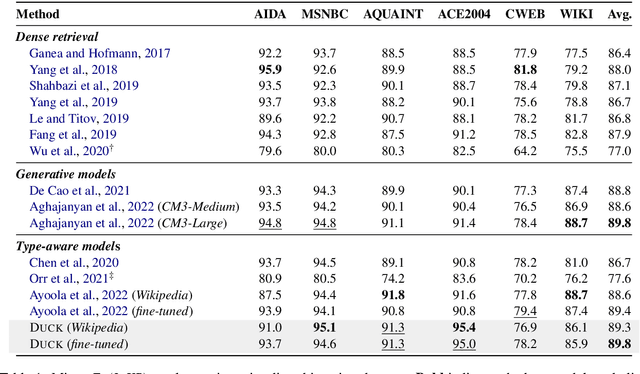
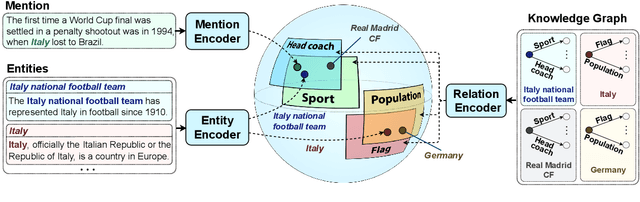
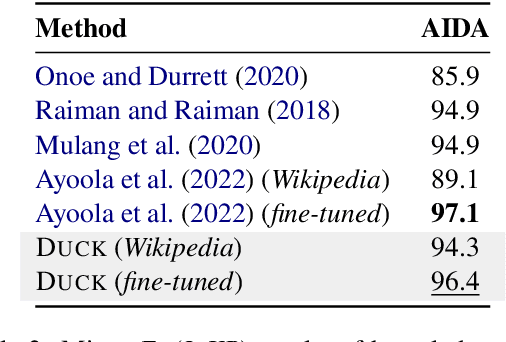
Entity linking methods based on dense retrieval are an efficient and widely used solution in large-scale applications, but they fall short of the performance of generative models, as they are sensitive to the structure of the embedding space. In order to address this issue, this paper introduces DUCK, an approach to infusing structural information in the space of entity representations, using prior knowledge of entity types. Inspired by duck typing in programming languages, we propose to define the type of an entity based on the relations that it has with other entities in a knowledge graph. Then, porting the concept of box embeddings to spherical polar coordinates, we propose to represent relations as boxes on the hypersphere. We optimize the model to cluster entities of similar type by placing them inside the boxes corresponding to their relations. Our experiments show that our method sets new state-of-the-art results on standard entity-disambiguation benchmarks, it improves the performance of the model by up to 7.9 F1 points, outperforms other type-aware approaches, and matches the results of generative models with 18 times more parameters.
Evolutionary Diversity Optimisation in Constructing Satisfying Assignments
May 19, 2023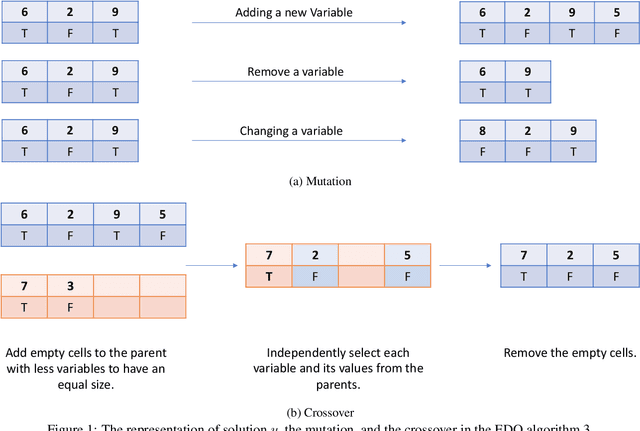
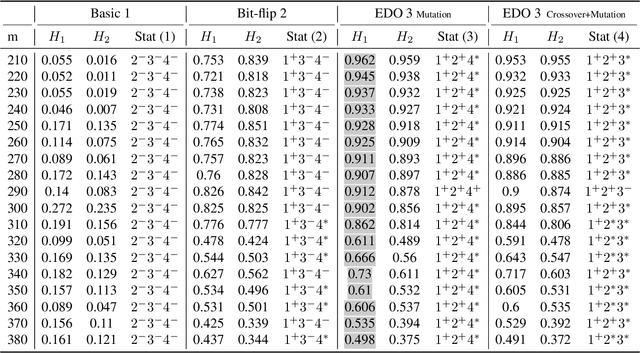
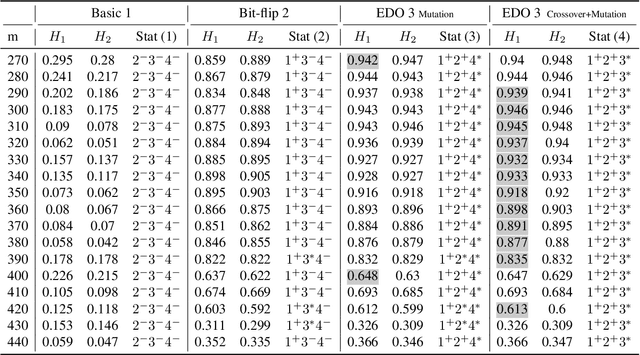
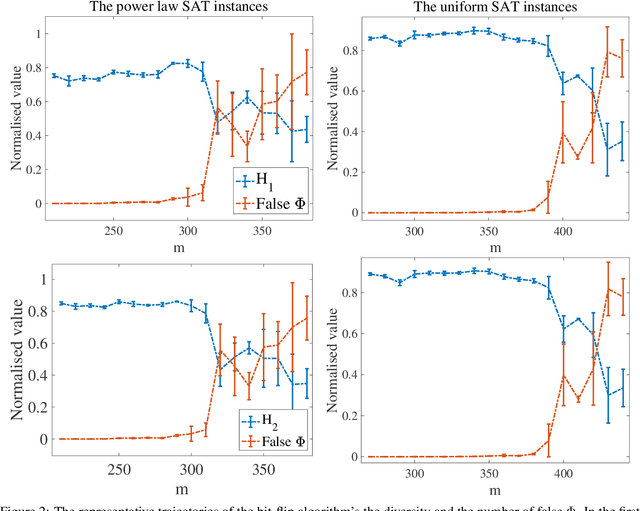
Computing diverse solutions for a given problem, in particular evolutionary diversity optimisation (EDO), is a hot research topic in the evolutionary computation community. This paper studies the Boolean satisfiability problem (SAT) in the context of EDO. SAT is of great importance in computer science and differs from the other problems studied in EDO literature, such as KP and TSP. SAT is heavily constrained, and the conventional evolutionary operators are inefficient in generating SAT solutions. Our approach avails of the following characteristics of SAT: 1) the possibility of adding more constraints (clauses) to the problem to forbid solutions or to fix variables, and 2) powerful solvers in the literature, such as minisat. We utilise such a solver to construct a diverse set of solutions. Moreover, maximising diversity provides us with invaluable information about the solution space of a given SAT problem, such as how large the feasible region is. In this study, we introduce evolutionary algorithms (EAs) employing a well-known SAT solver to maximise diversity among a set of SAT solutions explicitly. The experimental investigations indicate the introduced algorithms' capability to maximise diversity among the SAT solutions.