 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Persistent Laplacian-enhanced Algorithm for Scarcely Labeled Data Classification
May 25, 2023
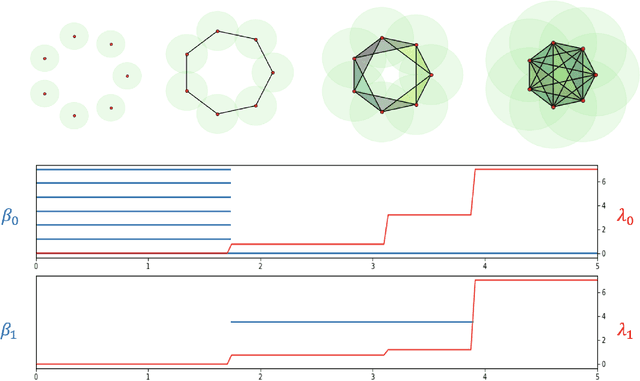
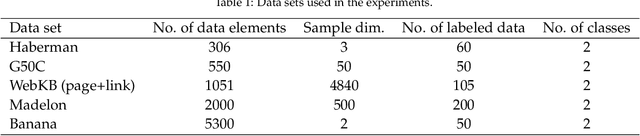
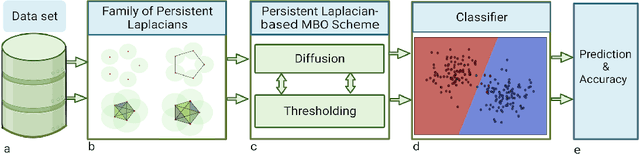
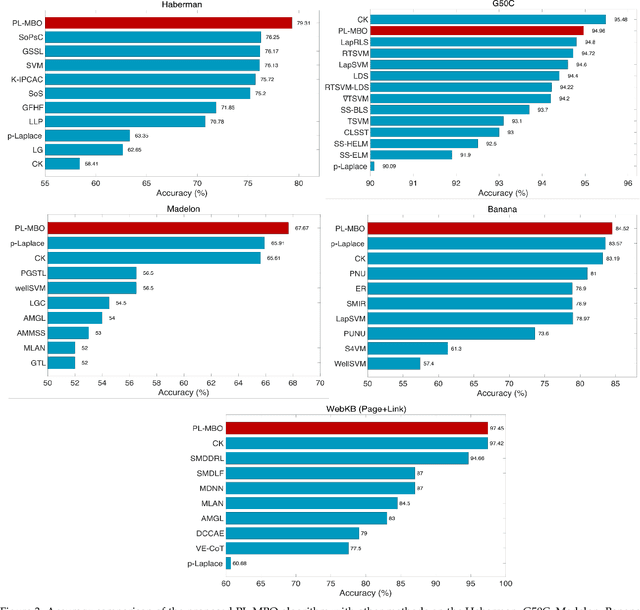
The success of many machine learning (ML) methods depends crucially on having large amounts of labeled data. However, obtaining enough labeled data can be expensive, time-consuming, and subject to ethical constraints for many applications. One approach that has shown tremendous value in addressing this challenge is semi-supervised learning (SSL); this technique utilizes both labeled and unlabeled data during training, often with much less labeled data than unlabeled data, which is often relatively easy and inexpensive to obtain. In fact, SSL methods are particularly useful in applications where the cost of labeling data is especially expensive, such as medical analysis, natural language processing (NLP), or speech recognition. A subset of SSL methods that have achieved great success in various domains involves algorithms that integrate graph-based techniques. These procedures are popular due to the vast amount of information provided by the graphical framework and the versatility of their applications. In this work, we propose an algebraic topology-based semi-supervised method called persistent Laplacian-enhanced graph MBO (PL-MBO) by integrating persistent spectral graph theory with the classical Merriman-Bence- Osher (MBO) scheme. Specifically, we use a filtration procedure to generate a sequence of chain complexes and associated families of simplicial complexes, from which we construct a family of persistent Laplacians. Overall, it is a very efficient procedure that requires much less labeled data to perform well compared to many ML techniques, and it can be adapted for both small and large datasets. We evaluate the performance of the proposed method on data classification, and the results indicate that the proposed technique outperforms other existing semi-supervised algorithms.
VLAB: Enhancing Video Language Pre-training by Feature Adapting and Blending
May 22, 2023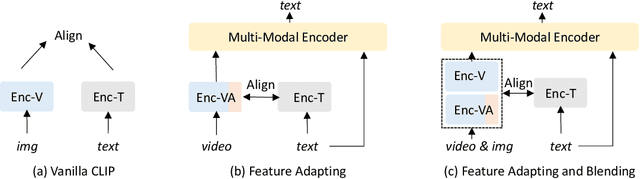
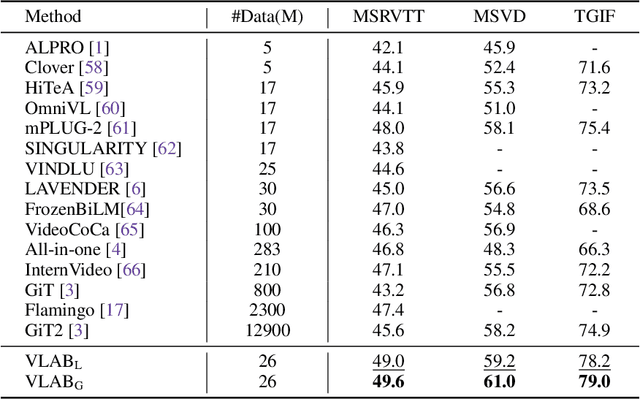
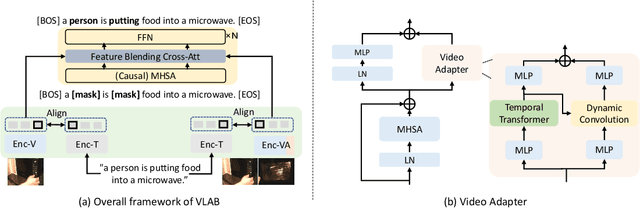
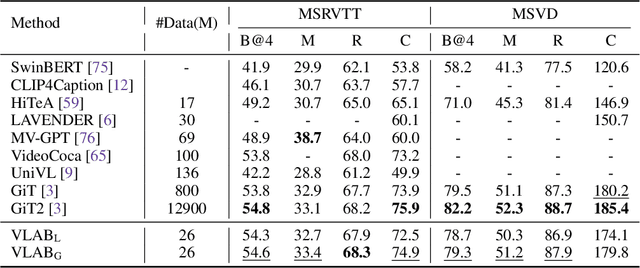
Large-scale image-text contrastive pre-training models, such as CLIP, have been demonstrated to effectively learn high-quality multimodal representations. However, there is limited research on learning video-text representations for general video multimodal tasks based on these powerful features. Towards this goal, we propose a novel video-text pre-training method dubbed VLAB: Video Language pre-training by feature Adapting and Blending, which transfers CLIP representations to video pre-training tasks and develops unified video multimodal models for a wide range of video-text tasks. Specifically, VLAB is founded on two key strategies: feature adapting and feature blending. In the former, we introduce a new video adapter module to address CLIP's deficiency in modeling temporal information and extend the model's capability to encompass both contrastive and generative tasks. In the latter, we propose an end-to-end training method that further enhances the model's performance by exploiting the complementarity of image and video features. We validate the effectiveness and versatility of VLAB through extensive experiments on highly competitive video multimodal tasks, including video text retrieval, video captioning, and video question answering. Remarkably, VLAB outperforms competing methods significantly and sets new records in video question answering on MSRVTT, MSVD, and TGIF datasets. It achieves an accuracy of 49.6, 61.0, and 79.0, respectively. Codes and models will be released.
Bandit Submodular Maximization for Multi-Robot Coordination in Unpredictable and Partially Observable Environments
May 22, 2023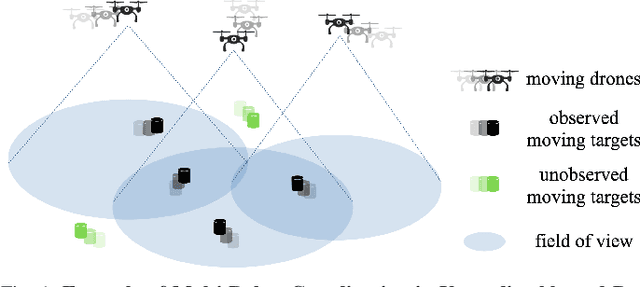
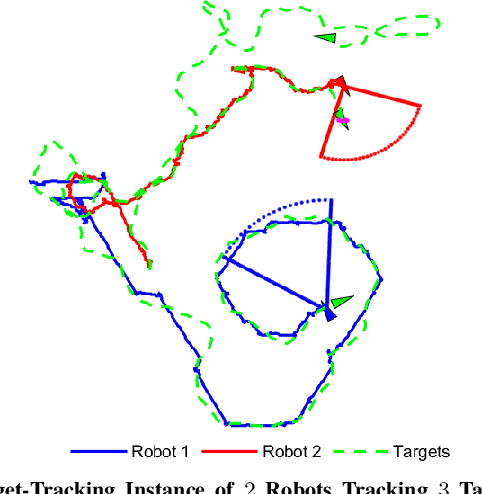
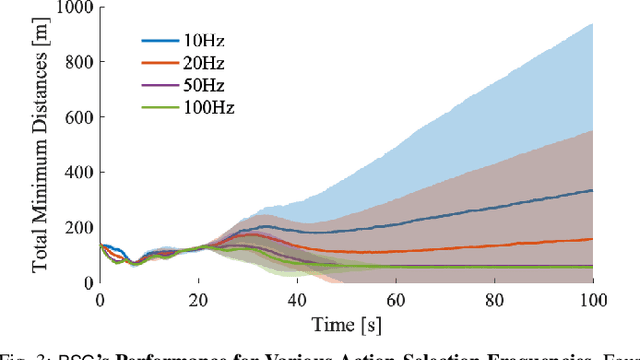
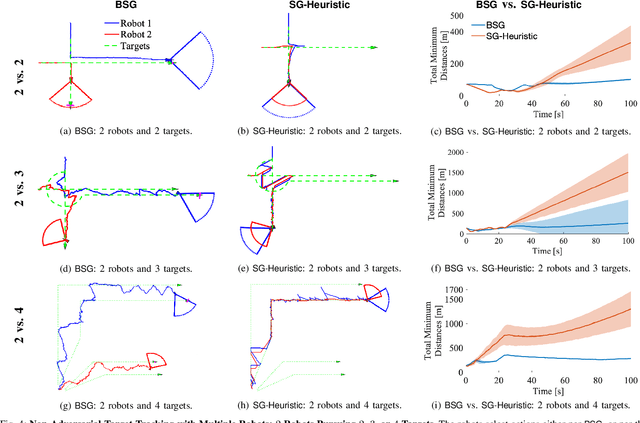
We study the problem of multi-agent coordination in unpredictable and partially observable environments, that is, environments whose future evolution is unknown a priori and that can only be partially observed. We are motivated by the future of autonomy that involves multiple robots coordinating actions in dynamic, unstructured, and partially observable environments to complete complex tasks such as target tracking, environmental mapping, and area monitoring. Such tasks are often modeled as submodular maximization coordination problems due to the information overlap among the robots. We introduce the first submodular coordination algorithm with bandit feedback and bounded tracking regret -- bandit feedback is the robots' ability to compute in hindsight only the effect of their chosen actions, instead of all the alternative actions that they could have chosen instead, due to the partial observability; and tracking regret is the algorithm's suboptimality with respect to the optimal time-varying actions that fully know the future a priori. The bound gracefully degrades with the environments' capacity to change adversarially, quantifying how often the robots should re-select actions to learn to coordinate as if they fully knew the future a priori. The algorithm generalizes the seminal Sequential Greedy algorithm by Fisher et al. to the bandit setting, by leveraging submodularity and algorithms for the problem of tracking the best action. We validate our algorithm in simulated scenarios of multi-target tracking.
D$^2$TV: Dual Knowledge Distillation and Target-oriented Vision Modeling for Many-to-Many Multimodal Summarization
May 22, 2023
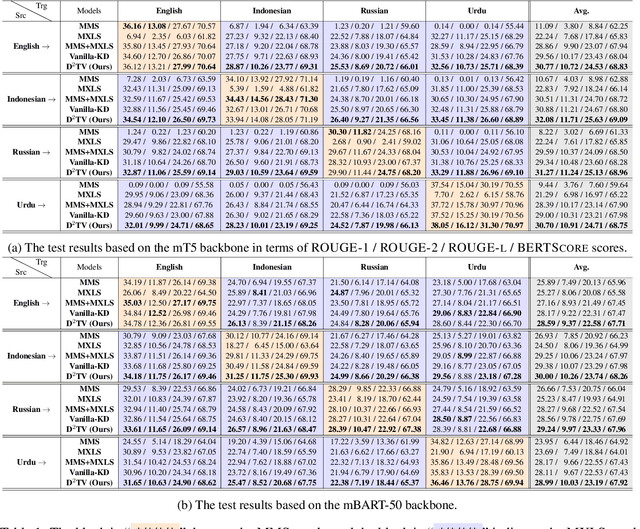

Many-to-many multimodal summarization (M$^3$S) task aims to generate summaries in any language with document inputs in any language and the corresponding image sequence, which essentially comprises multimodal monolingual summarization (MMS) and multimodal cross-lingual summarization (MXLS) tasks. Although much work has been devoted to either MMS or MXLS and has obtained increasing attention in recent years, little research pays attention to the M$^3$S task. Besides, existing studies mainly focus on 1) utilizing MMS to enhance MXLS via knowledge distillation without considering the performance of MMS or 2) improving MMS models by filtering summary-unrelated visual features with implicit learning or explicitly complex training objectives. In this paper, we first introduce a general and practical task, i.e., M$^3$S. Further, we propose a dual knowledge distillation and target-oriented vision modeling framework for the M$^3$S task. Specifically, the dual knowledge distillation method guarantees that the knowledge of MMS and MXLS can be transferred to each other and thus mutually prompt both of them. To offer target-oriented visual features, a simple yet effective target-oriented contrastive objective is designed and responsible for discarding needless visual information. Extensive experiments on the many-to-many setting show the effectiveness of the proposed approach. Additionally, we will contribute a many-to-many multimodal summarization (M$^3$Sum) dataset.
ForestTrav: Accurate, Efficient and Deployable Forest Traversability Estimation for Autonomous Ground Vehicles
May 22, 2023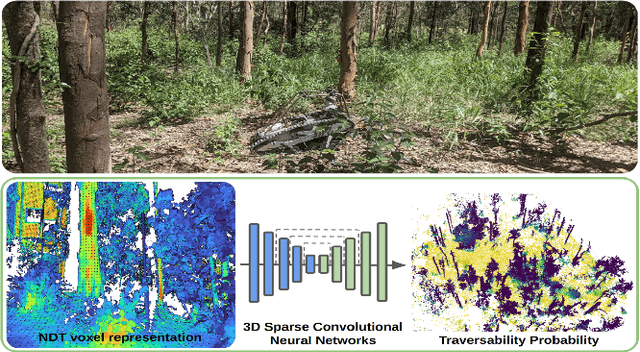
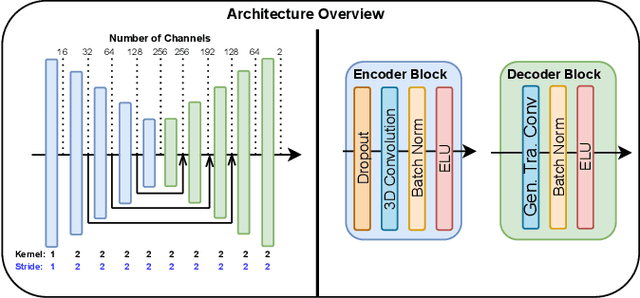
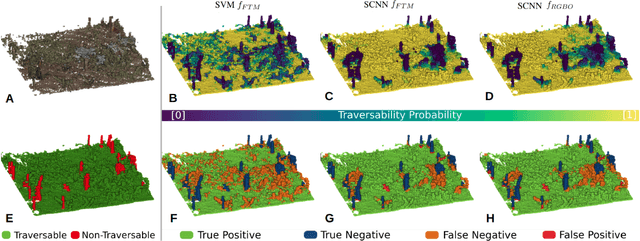
Autonomous navigation in unstructured vegetated environments remains an open challenge. To successfully operate in these settings, ground vehicles must assess the traversability of the environment and determine which vegetation is pliable enough to push through. In this work, we propose a novel method that combines a high-fidelity and feature-rich 3D voxel representation while leveraging the structural context and sparseness of \acfp{SCNN} to assess \ac{TE} in densely vegetated environments. The proposed method is thoroughly evaluated on an accurately-labeled real-world data set that we provide to the community. It is shown to outperform state-of-the-art methods by a significant margin (0.59 vs. 0.39 MCC score at 0.1m voxel resolution) in challenging scenes and to generalize to unseen environments. In addition, the method is economical in the amount of training data and training time required: a model is trained in minutes on a desktop computer. We show that by exploiting the context of the environment, our method can use different feature combinations with only limited performance variations. For example, our approach can be used with lidar-only features, whilst still assessing complex vegetated environments accurately, which was not demonstrated previously in the literature in such environments. In addition, we propose an approach to assess a traversability estimator's sensitivity to information quality and show our method's sensitivity is low.
DLUE: Benchmarking Document Language Understanding
May 16, 2023

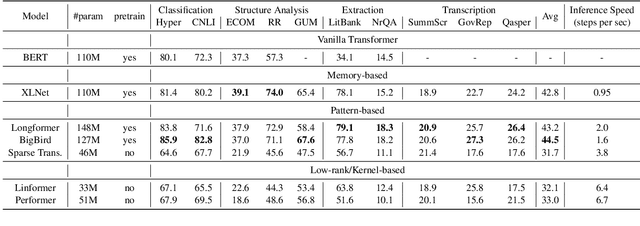
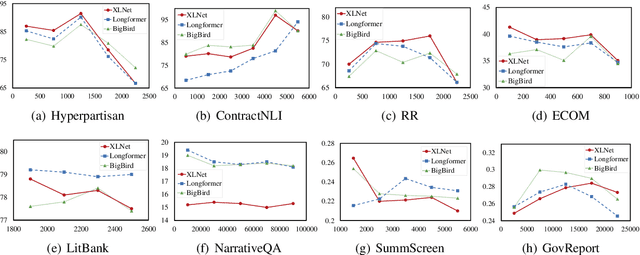
Understanding documents is central to many real-world tasks but remains a challenging topic. Unfortunately, there is no well-established consensus on how to comprehensively evaluate document understanding abilities, which significantly hinders the fair comparison and measuring the progress of the field. To benchmark document understanding researches, this paper summarizes four representative abilities, i.e., document classification, document structural analysis, document information extraction, and document transcription. Under the new evaluation framework, we propose \textbf{Document Language Understanding Evaluation} -- \textbf{DLUE}, a new task suite which covers a wide-range of tasks in various forms, domains and document genres. We also systematically evaluate six well-established transformer models on DLUE, and find that due to the lengthy content, complicated underlying structure and dispersed knowledge, document understanding is still far from being solved, and currently there is no neural architecture that dominates all tasks, raising requirements for a universal document understanding architecture.
Semi-supervised Road Updating Network (SRUNet): A Deep Learning Method for Road Updating from Remote Sensing Imagery and Historical Vector Maps
Apr 28, 2023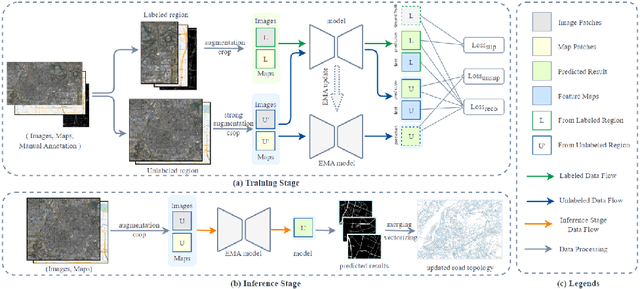
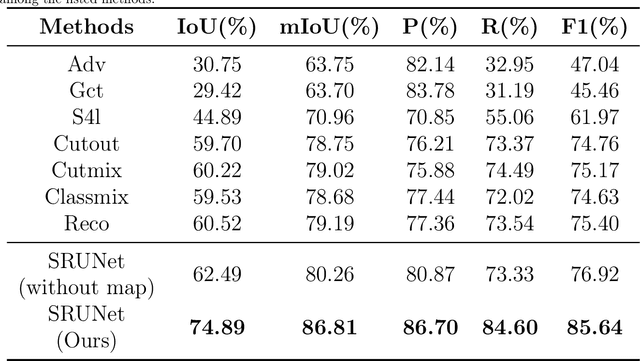
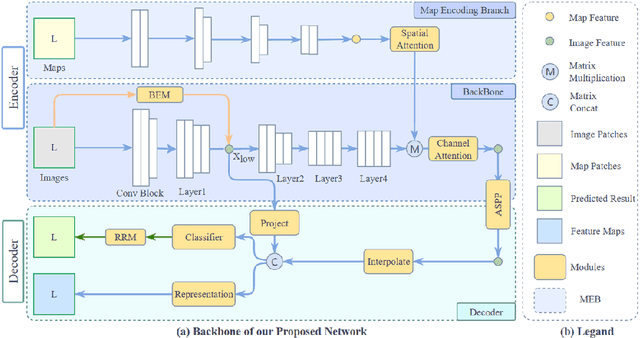
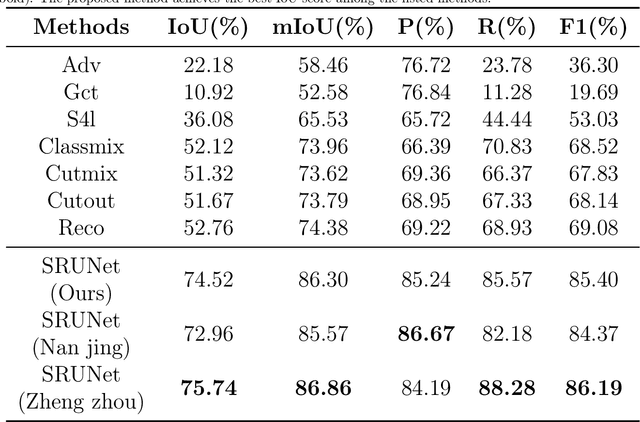
A road is the skeleton of a city and is a fundamental and important geographical component. Currently, many countries have built geo-information databases and gathered large amounts of geographic data. However, with the extensive construction of infrastructure and rapid expansion of cities, automatic updating of road data is imperative to maintain the high quality of current basic geographic information. However, obtaining bi-phase images for the same area is difficult, and complex post-processing methods are required to update the existing databases.To solve these problems, we proposed a road detection method based on semi-supervised learning (SRUNet) specifically for road-updating applications; in this approach, historical road information was fused with the latest images to directly obtain the latest state of the road.Considering that the texture of a road is complex, a multi-branch network, named the Map Encoding Branch (MEB) was proposed for representation learning, where the Boundary Enhancement Module (BEM) was used to improve the accuracy of boundary prediction, and the Residual Refinement Module (RRM) was used to optimize the prediction results. Further, to fully utilize the limited amount of label information and to enhance the prediction accuracy on unlabeled images, we utilized the mean teacher framework as the basic semi-supervised learning framework and introduced Regional Contrast (ReCo) in our work to improve the model capacity for distinguishing between the characteristics of roads and background elements.We applied our method to two datasets. Our model can effectively improve the performance of a model with fewer labels. Overall, the proposed SRUNet can provide stable, up-to-date, and reliable prediction results for a wide range of road renewal tasks.
Know Your Self-supervised Learning: A Survey on Image-based Generative and Discriminative Training
May 23, 2023

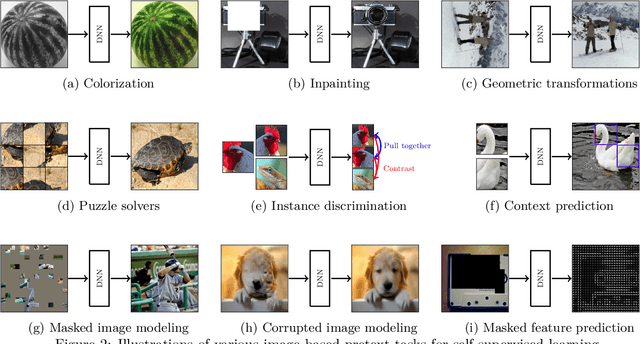
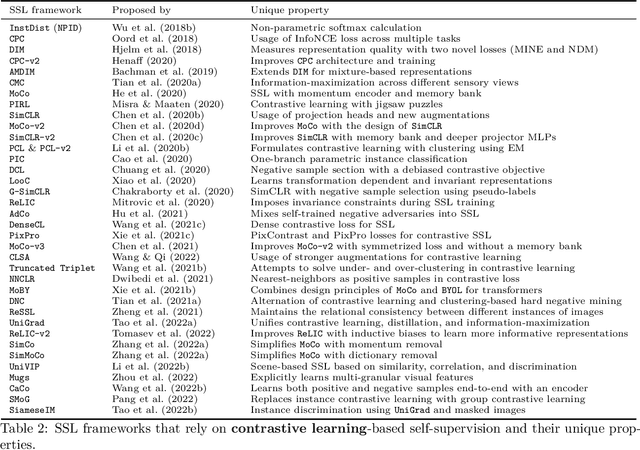
Although supervised learning has been highly successful in improving the state-of-the-art in the domain of image-based computer vision in the past, the margin of improvement has diminished significantly in recent years, indicating that a plateau is in sight. Meanwhile, the use of self-supervised learning (SSL) for the purpose of natural language processing (NLP) has seen tremendous successes during the past couple of years, with this new learning paradigm yielding powerful language models. Inspired by the excellent results obtained in the field of NLP, self-supervised methods that rely on clustering, contrastive learning, distillation, and information-maximization, which all fall under the banner of discriminative SSL, have experienced a swift uptake in the area of computer vision. Shortly afterwards, generative SSL frameworks that are mostly based on masked image modeling, complemented and surpassed the results obtained with discriminative SSL. Consequently, within a span of three years, over $100$ unique general-purpose frameworks for generative and discriminative SSL, with a focus on imaging, were proposed. In this survey, we review a plethora of research efforts conducted on image-oriented SSL, providing a historic view and paying attention to best practices as well as useful software packages. While doing so, we discuss pretext tasks for image-based SSL, as well as techniques that are commonly used in image-based SSL. Lastly, to aid researchers who aim at contributing to image-focused SSL, we outline a number of promising research directions.
* Published in Transactions on Machine Learning Research
Knowledge Graph Quality Evaluation under Incomplete Information
Dec 02, 2022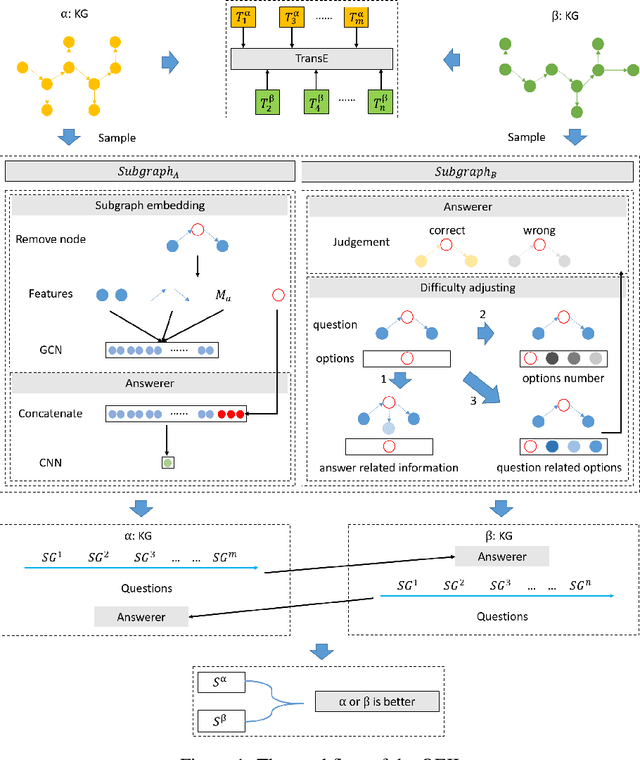

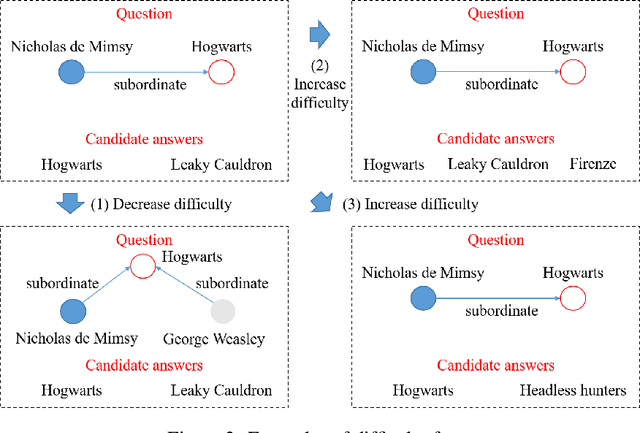
Utilities of knowledge graphs (KGs) depend on their qualities. A KG that is of poor quality not only has little applicability but also leads to some unexpected errors. Therefore, quality evaluation for KGs is crucial and indispensable. Existing methods design many quality dimensions and calculate metrics in the corresponding dimensions based on details (i.e., raw data and graph structures) of KGs for evaluation. However, there are two major issues. On one hand, they consider the details as public information, which exposes the raw data and graph structures. These details are strictly confidential because they involve commercial privacy or others in practice. On the other hand, the existing methods focus on how much knowledge KGs have rather than KGs' practicability. To address the above problems, we propose a knowledge graph quality evaluation framework under incomplete information (QEII). The quality evaluation problem is transformed into an adversarial game, and the relative quality is evaluated according to the winner and loser. Participants of the game are KGs, and the adversarial gameplay is to question and answer (Q&A). In the QEII, we generate and train a question model and an answer model for each KG. The question model of a KG first asks a certain number of questions to the other KG. Then it evaluates the answers returned by the answer model of the other KG and outputs a percentage score. The relative quality is evaluated by the scores, which measures the ability to apply knowledge. Q&A messages are the only information that KGs exchange, without exposing any raw data and graph structure. Experimental results on two pairs of KGs demonstrate that, comparing with baselines, the QEII realizes a reasonable quality evaluation from the perspective of third-party evaluators under incomplete information.
Toward Connecting Speech Acts and Search Actions in Conversational Search Tasks
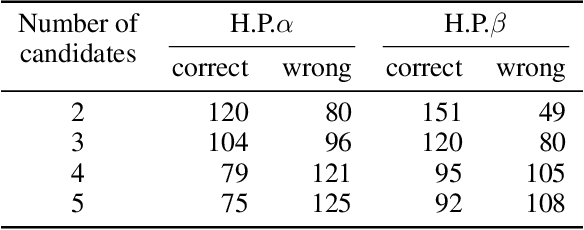
May 08, 2023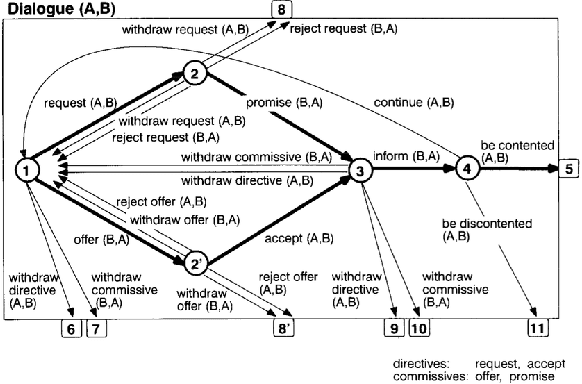
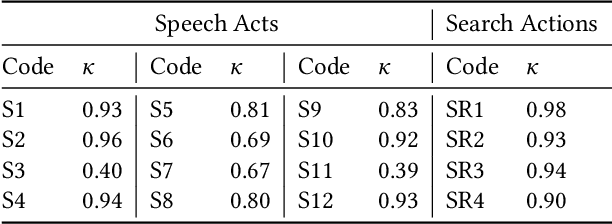
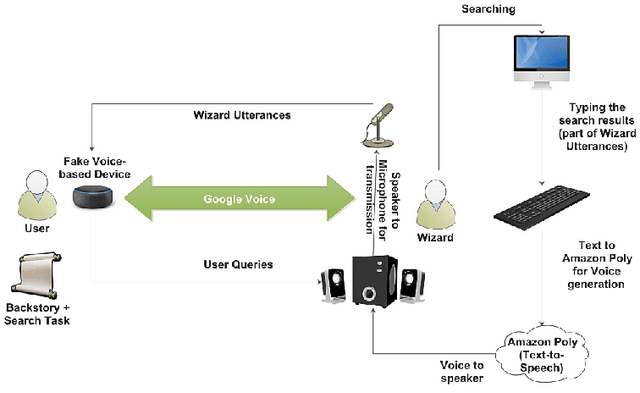
Conversational search systems can improve user experience in digital libraries by facilitating a natural and intuitive way to interact with library content. However, most conversational search systems are limited to performing simple tasks and controlling smart devices. Therefore, there is a need for systems that can accurately understand the user's information requirements and perform the appropriate search activity. Prior research on intelligent systems suggested that it is possible to comprehend the functional aspect of discourse (search intent) by identifying the speech acts in user dialogues. In this work, we automatically identify the speech acts associated with spoken utterances and use them to predict the system-level search actions. First, we conducted a Wizard-of-Oz study to collect data from 75 search sessions. We performed thematic analysis to curate a gold standard dataset -- containing 1,834 utterances and 509 system actions -- of human-system interactions in three information-seeking scenarios. Next, we developed attention-based deep neural networks to understand natural language and predict speech acts. Then, the speech acts were fed to the model to predict the corresponding system-level search actions. We also annotated a second dataset to validate our results. For the two datasets, the best-performing classification model achieved maximum accuracy of 90.2% and 72.7% for speech act classification and 58.8% and 61.1%, respectively, for search act classification.