 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploiting Pseudo Image Captions for Multimodal Summarization
May 09, 2023

Cross-modal contrastive learning in vision language pretraining (VLP) faces the challenge of (partial) false negatives. In this paper, we study this problem from the perspective of Mutual Information (MI) optimization. It is common sense that InfoNCE loss used in contrastive learning will maximize the lower bound of MI between anchors and their positives, while we theoretically prove that MI involving negatives also matters when noises commonly exist. Guided by a more general lower bound form for optimization, we propose a contrastive learning strategy regulated by progressively refined cross-modal similarity, to more accurately optimize MI between an image/text anchor and its negative texts/images instead of improperly minimizing it. Our method performs competitively on four downstream cross-modal tasks and systematically balances the beneficial and harmful effects of (partial) false negative samples under theoretical guidance.
EdgeNet : Encoder-decoder generative Network for Auction Design in E-commerce Online Advertising
May 09, 2023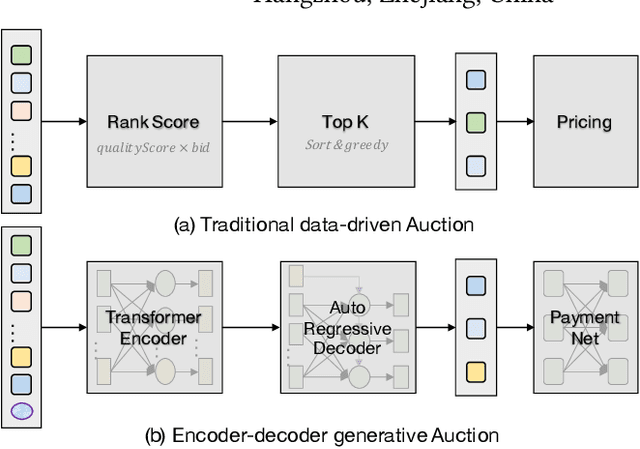

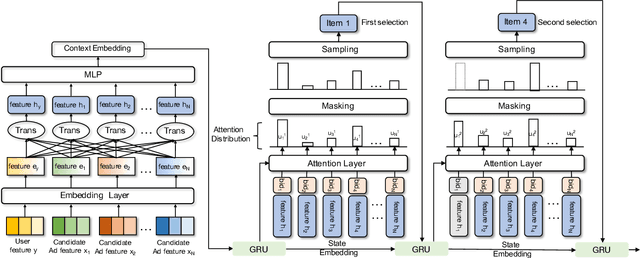
We present a new encoder-decoder generative network dubbed EdgeNet, which introduces a novel encoder-decoder framework for data-driven auction design in online e-commerce advertising. We break the neural auction paradigm of Generalized-Second-Price(GSP), and improve the utilization efficiency of data while ensuring the economic characteristics of the auction mechanism. Specifically, EdgeNet introduces a transformer-based encoder to better capture the mutual influence among different candidate advertisements. In contrast to GSP based neural auction model, we design an autoregressive decoder to better utilize the rich context information in online advertising auctions. EdgeNet is conceptually simple and easy to extend to the existing end-to-end neural auction framework. We validate the efficiency of EdgeNet on a wide range of e-commercial advertising auction, demonstrating its potential in improving user experience and platform revenue.
Vision Langauge Pre-training by Contrastive Learning with Cross-Modal Similarity Regulation
May 09, 2023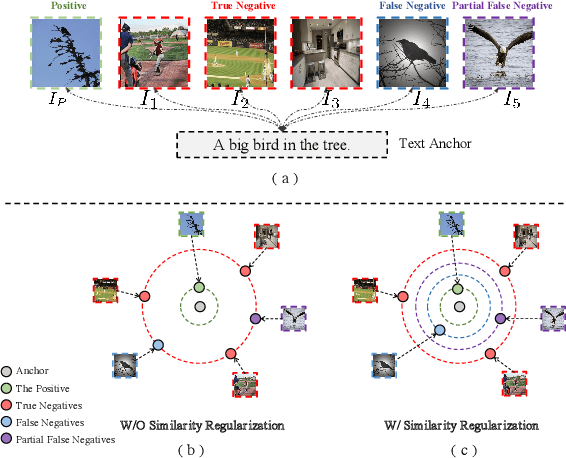
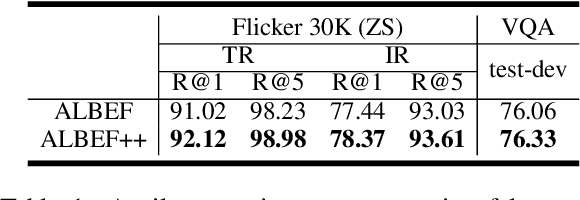
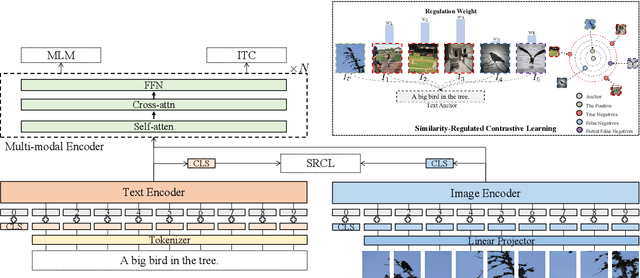
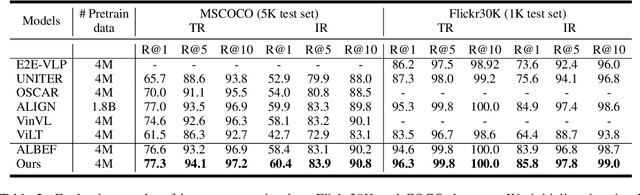
Cross-modal contrastive learning in vision language pretraining (VLP) faces the challenge of (partial) false negatives. In this paper, we study this problem from the perspective of Mutual Information (MI) optimization. It is common sense that InfoNCE loss used in contrastive learning will maximize the lower bound of MI between anchors and their positives, while we theoretically prove that MI involving negatives also matters when noises commonly exist. Guided by a more general lower bound form for optimization, we propose a contrastive learning strategy regulated by progressively refined cross-modal similarity, to more accurately optimize MI between an image/text anchor and its negative texts/images instead of improperly minimizing it. Our method performs competitively on four downstream cross-modal tasks and systematically balances the beneficial and harmful effects of (partial) false negative samples under theoretical guidance.
Towards autonomous system: flexible modular production system enhanced with large language model agents
May 02, 2023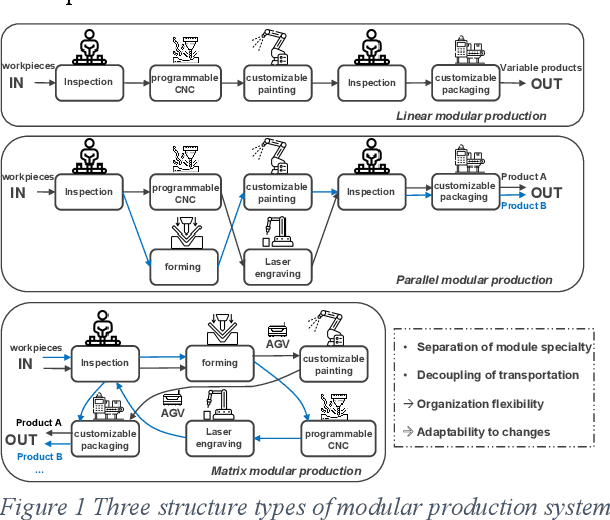
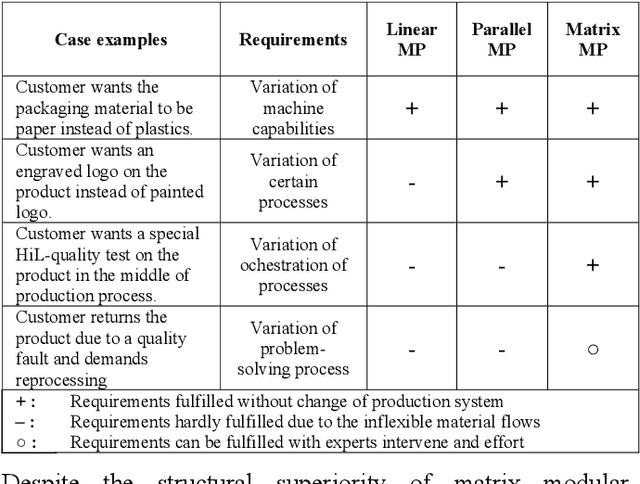
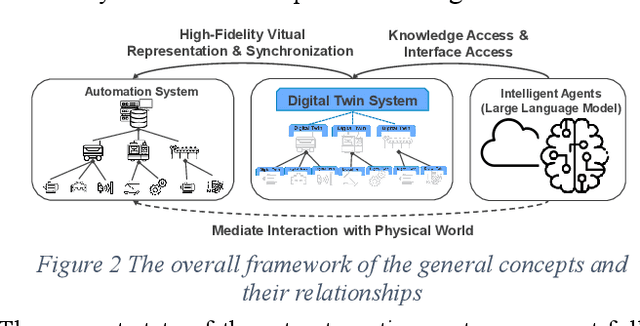

In this paper, we present a novel framework that combines large language models (LLMs), digital twins and industrial automation system to enable intelligent planning and control of production processes. We retrofit the automation system for a modular production facility and create executable control interfaces of fine-granular functionalities and coarse-granular skills. Low-level functionalities are executed by automation components, and high-level skills are performed by automation modules. Subsequently, a digital twin system is developed, registering these interfaces and containing additional descriptive information about the production system. Based on the retrofitted automation system and the created digital twins, LLM-agents are designed to interpret descriptive information in the digital twins and control the physical system through service interfaces. These LLM-agents serve as intelligent agents on different levels within an automation system, enabling autonomous planning and control of flexible production. Given a task instruction as input, the LLM-agents orchestrate a sequence of atomic functionalities and skills to accomplish the task. We demonstrate how our implemented prototype can handle un-predefined tasks, plan a production process, and execute the operations. This research highlights the potential of integrating LLMs into industrial automation systems in the context of smart factory for more agile, flexible, and adaptive production processes, while it also underscores the critical insights and limitations for future work.
Lower Bounds and Accelerated Algorithms in Distributed Stochastic Optimization with Communication Compression
May 12, 2023
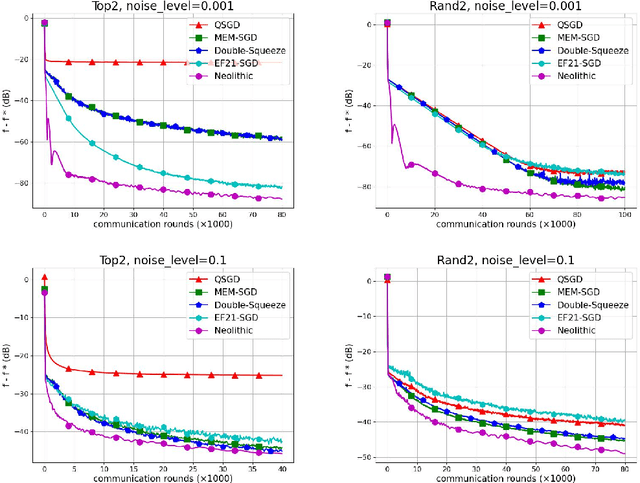

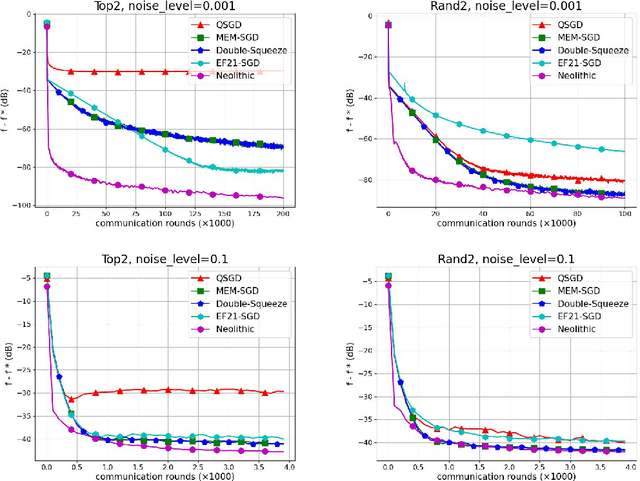
Communication compression is an essential strategy for alleviating communication overhead by reducing the volume of information exchanged between computing nodes in large-scale distributed stochastic optimization. Although numerous algorithms with convergence guarantees have been obtained, the optimal performance limit under communication compression remains unclear. In this paper, we investigate the performance limit of distributed stochastic optimization algorithms employing communication compression. We focus on two main types of compressors, unbiased and contractive, and address the best-possible convergence rates one can obtain with these compressors. We establish the lower bounds for the convergence rates of distributed stochastic optimization in six different settings, combining strongly-convex, generally-convex, or non-convex functions with unbiased or contractive compressor types. To bridge the gap between lower bounds and existing algorithms' rates, we propose NEOLITHIC, a nearly optimal algorithm with compression that achieves the established lower bounds up to logarithmic factors under mild conditions. Extensive experimental results support our theoretical findings. This work provides insights into the theoretical limitations of existing compressors and motivates further research into fundamentally new compressor properties.
Zero-shot Item-based Recommendation via Multi-task Product Knowledge Graph Pre-Training
May 12, 2023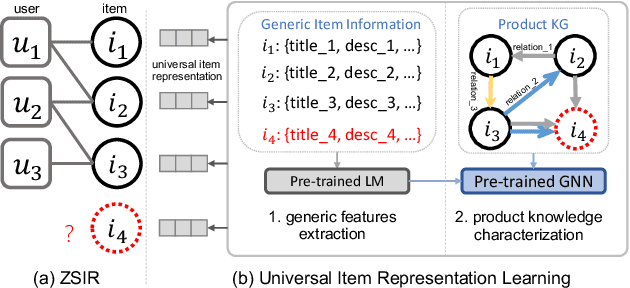
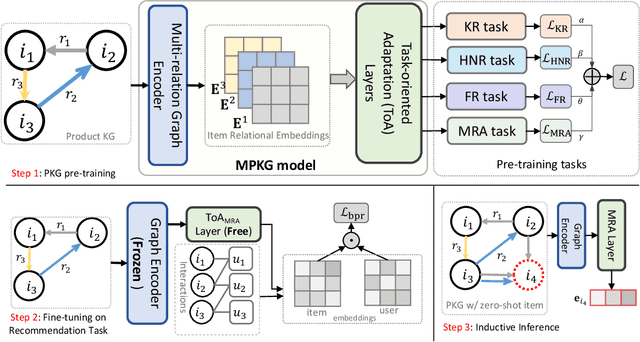

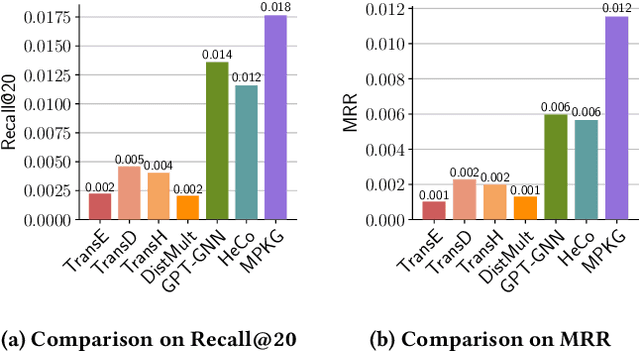
Existing recommender systems face difficulties with zero-shot items, i.e. items that have no historical interactions with users during the training stage. Though recent works extract universal item representation via pre-trained language models (PLMs), they ignore the crucial item relationships. This paper presents a novel paradigm for the Zero-Shot Item-based Recommendation (ZSIR) task, which pre-trains a model on product knowledge graph (PKG) to refine the item features from PLMs. We identify three challenges for pre-training PKG, which are multi-type relations in PKG, semantic divergence between item generic information and relations and domain discrepancy from PKG to downstream ZSIR task. We address the challenges by proposing four pre-training tasks and novel task-oriented adaptation (ToA) layers. Moreover, this paper discusses how to fine-tune the model on new recommendation task such that the ToA layers are adapted to ZSIR task. Comprehensive experiments on 18 markets dataset are conducted to verify the effectiveness of the proposed model in both knowledge prediction and ZSIR task.
Diffusion-based Signal Refiner for Speech Separation
May 12, 2023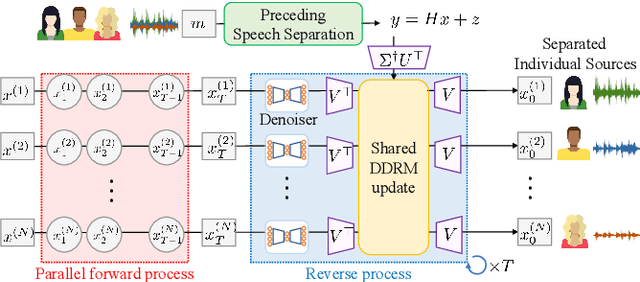
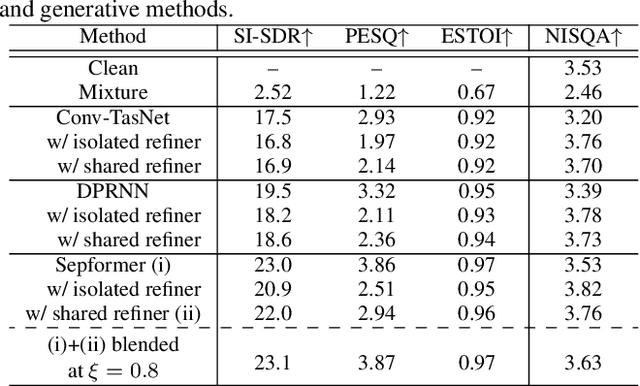
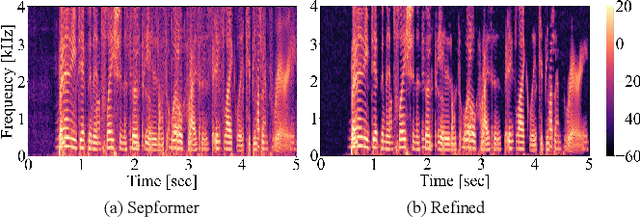
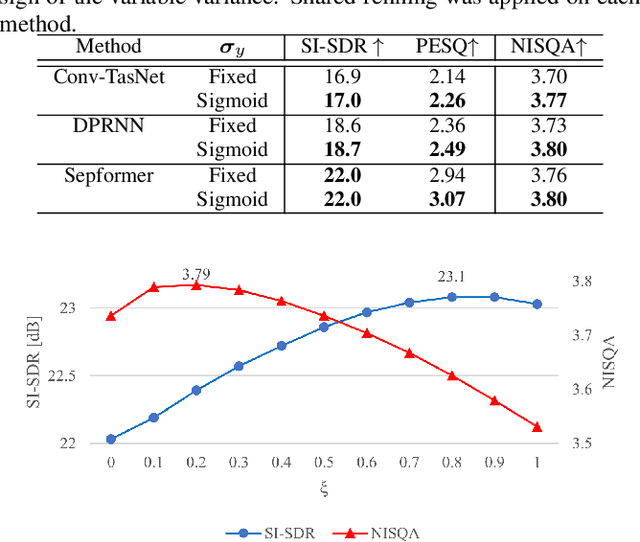
We have developed a diffusion-based speech refiner that improves the reference-free perceptual quality of the audio predicted by preceding single-channel speech separation models. Although modern deep neural network-based speech separation models have show high performance in reference-based metrics, they often produce perceptually unnatural artifacts. The recent advancements made to diffusion models motivated us to tackle this problem by restoring the degraded parts of initial separations with a generative approach. Utilizing the denoising diffusion restoration model (DDRM) as a basis, we propose a shared DDRM-based refiner that generates samples conditioned on the global information of preceding outputs from arbitrary speech separation models. We experimentally show that our refiner can provide a clearer harmonic structure of speech and improves the reference-free metric of perceptual quality for arbitrary preceding model architectures. Furthermore, we tune the variance of the measurement noise based on preceding outputs, which results in higher scores in both reference-free and reference-based metrics. The separation quality can also be further improved by blending the discriminative and generative outputs.
Meta-Optimization for Higher Model Generalizability in Single-Image Depth Prediction
May 12, 2023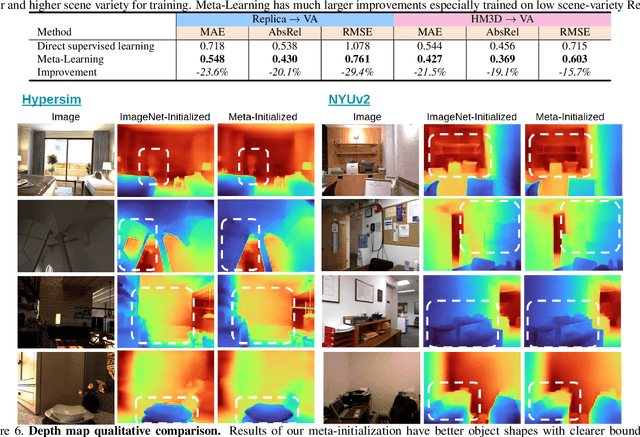
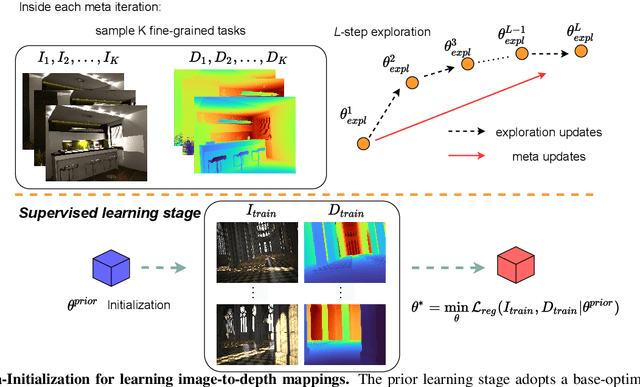
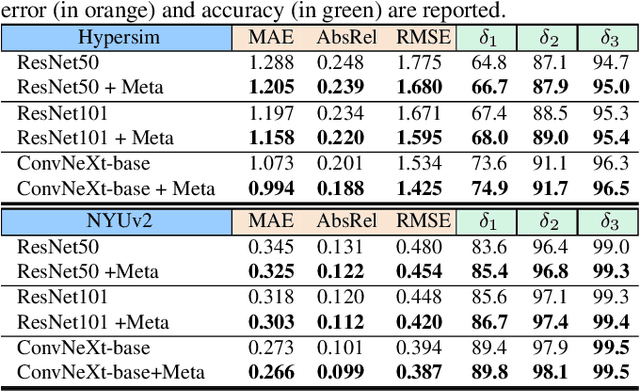
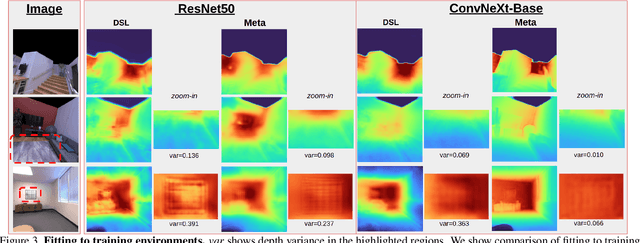
Model generalizability to unseen datasets, concerned with in-the-wild robustness, is less studied for indoor single-image depth prediction. We leverage gradient-based meta-learning for higher generalizability on zero-shot cross-dataset inference. Unlike the most-studied image classification in meta-learning, depth is pixel-level continuous range values, and mappings from each image to depth vary widely across environments. Thus no explicit task boundaries exist. We instead propose fine-grained task that treats each RGB-D pair as a task in our meta-optimization. We first show meta-learning on limited data induces much better prior (max +29.4\%). Using meta-learned weights as initialization for following supervised learning, without involving extra data or information, it consistently outperforms baselines without the method. Compared to most indoor-depth methods that only train/ test on a single dataset, we propose zero-shot cross-dataset protocols, closely evaluate robustness, and show consistently higher generalizability and accuracy by our meta-initialization. The work at the intersection of depth and meta-learning potentially drives both research streams to step closer to practical use.
Multi-Agent Reinforcement Learning for Network Routing in Integrated Access Backhaul Networks
May 12, 2023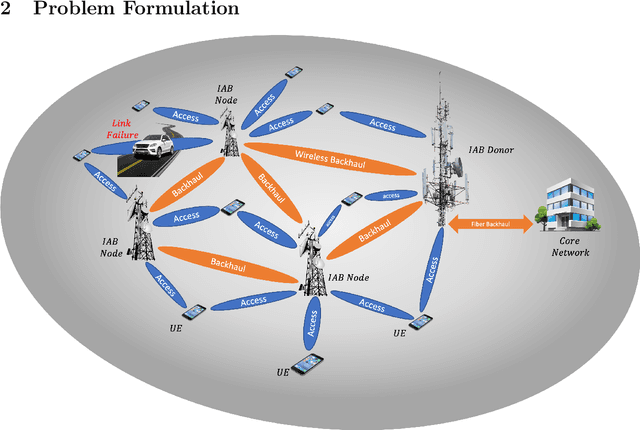
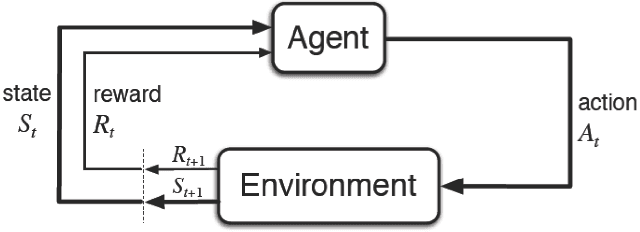
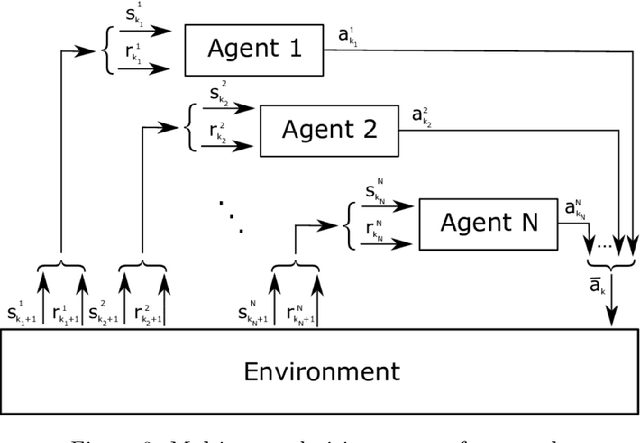

We investigate the problem of wireless routing in integrated access backhaul (IAB) networks consisting of fiber-connected and wireless base stations and multiple users. The physical constraints of these networks prevent the use of a central controller, and base stations have limited access to real-time network conditions. We aim to maximize packet arrival ratio while minimizing their latency, for this purpose, we formulate the problem as a multi-agent partially observed Markov decision process (POMDP). To solve this problem, we develop a Relational Advantage Actor Critic (Relational A2C) algorithm that uses Multi-Agent Reinforcement Learning (MARL) and information about similar destinations to derive a joint routing policy on a distributed basis. We present three training paradigms for this algorithm and demonstrate its ability to achieve near-centralized performance. Our results show that Relational A2C outperforms other reinforcement learning algorithms, leading to increased network efficiency and reduced selfish agent behavior. To the best of our knowledge, this work is the first to optimize routing strategy for IAB networks.
Masked Reconstruction Contrastive Learning with Information Bottleneck Principle
Nov 15, 2022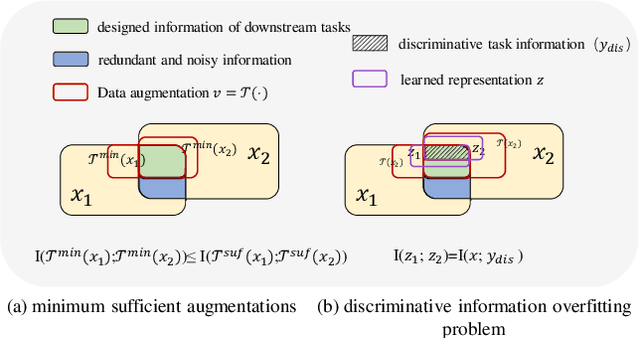
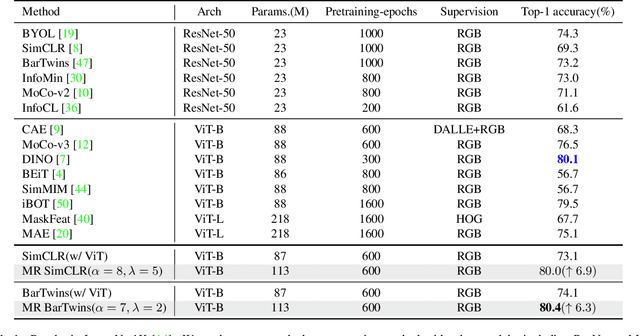
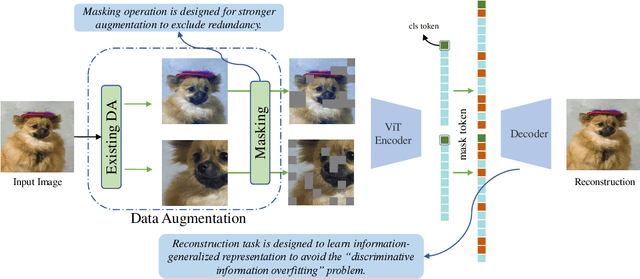
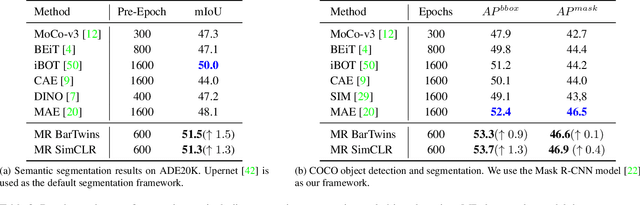
Contrastive learning (CL) has shown great power in self-supervised learning due to its ability to capture insight correlations among large-scale data. Current CL models are biased to learn only the ability to discriminate positive and negative pairs due to the discriminative task setting. However, this bias would lead to ignoring its sufficiency for other downstream tasks, which we call the discriminative information overfitting problem. In this paper, we propose to tackle the above problems from the aspect of the Information Bottleneck (IB) principle, further pushing forward the frontier of CL. Specifically, we present a new perspective that CL is an instantiation of the IB principle, including information compression and expression. We theoretically analyze the optimal information situation and demonstrate that minimum sufficient augmentation and information-generalized representation are the optimal requirements for achieving maximum compression and generalizability to downstream tasks. Therefore, we propose the Masked Reconstruction Contrastive Learning~(MRCL) model to improve CL models. For implementation in practice, MRCL utilizes the masking operation for stronger augmentation, further eliminating redundant and noisy information. In order to alleviate the discriminative information overfitting problem effectively, we employ the reconstruction task to regularize the discriminative task. We conduct comprehensive experiments and show the superiority of the proposed model on multiple tasks, including image classification, semantic segmentation and objective detection.