 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Phase-Retrieval with Incomplete Autocorrelations Using Deep Convolutional Autoencoders
Apr 18, 2023


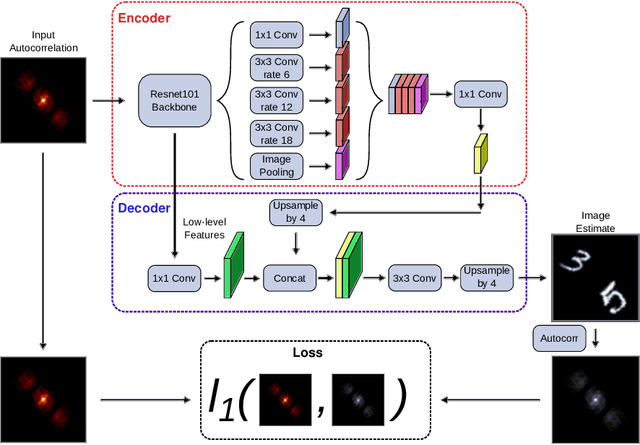
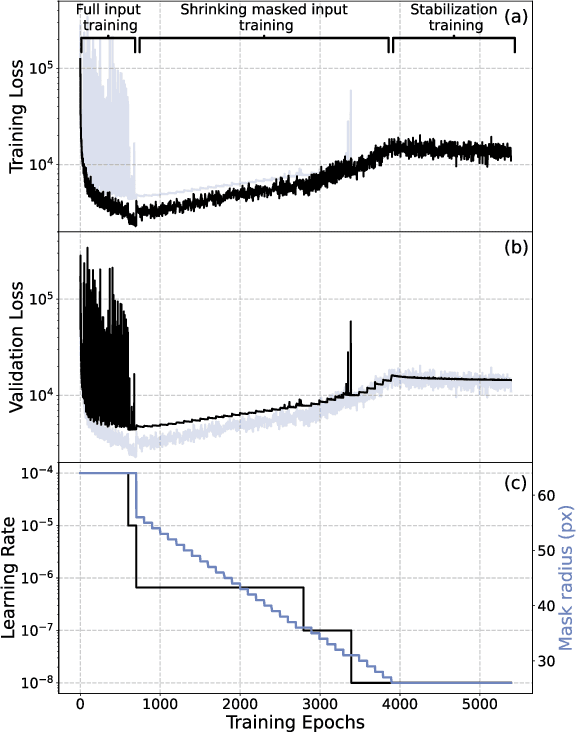
Phase-retrieval techniques aim to recover the original signal from just the modulus of its Fourier transform, which is usually much easier to measure than its phase, but the standard iterative techniques tend to fail if only part of the modulus information is available. We show that a neural network can be trained to perform phase retrieval using only incomplete information, and we discuss advantages and limitations of this approach.
XTab: Cross-table Pretraining for Tabular Transformers
May 10, 2023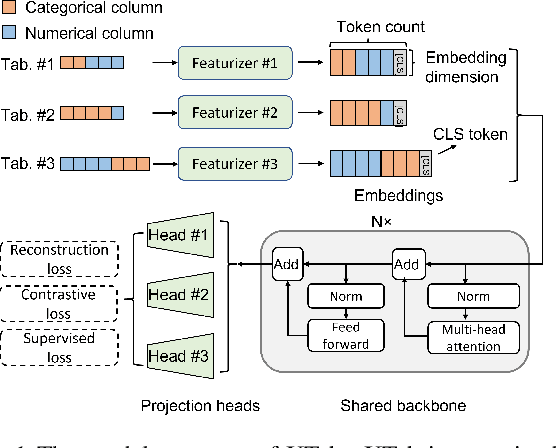
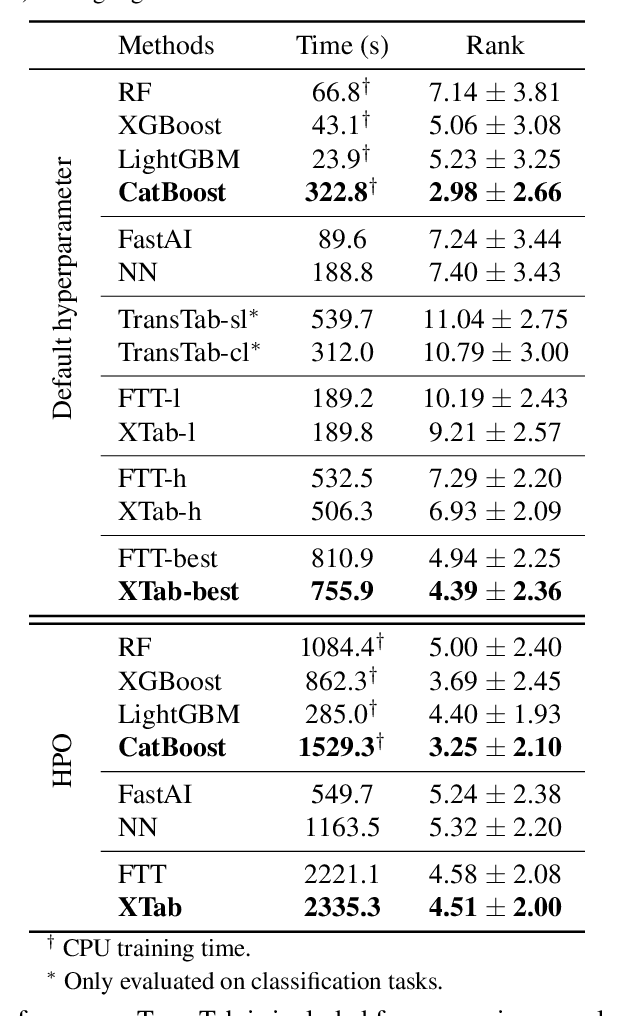
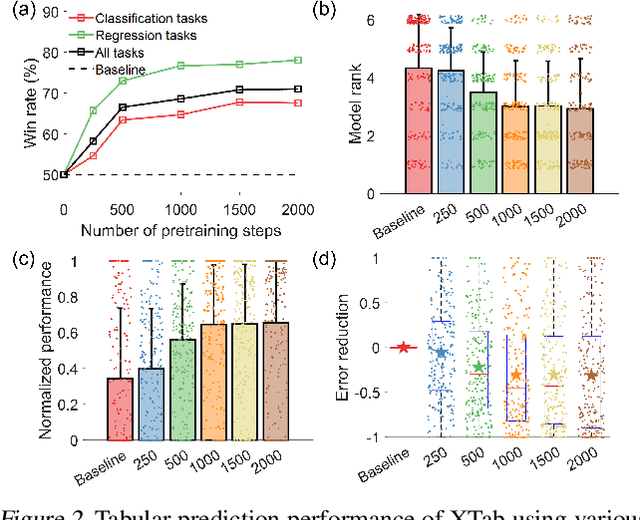

The success of self-supervised learning in computer vision and natural language processing has motivated pretraining methods on tabular data. However, most existing tabular self-supervised learning models fail to leverage information across multiple data tables and cannot generalize to new tables. In this work, we introduce XTab, a framework for cross-table pretraining of tabular transformers on datasets from various domains. We address the challenge of inconsistent column types and quantities among tables by utilizing independent featurizers and using federated learning to pretrain the shared component. Tested on 84 tabular prediction tasks from the OpenML-AutoML Benchmark (AMLB), we show that (1) XTab consistently boosts the generalizability, learning speed, and performance of multiple tabular transformers, (2) by pretraining FT-Transformer via XTab, we achieve superior performance than other state-of-the-art tabular deep learning models on various tasks such as regression, binary, and multiclass classification.
CLIP-S$^4$: Language-Guided Self-Supervised Semantic Segmentation
May 01, 2023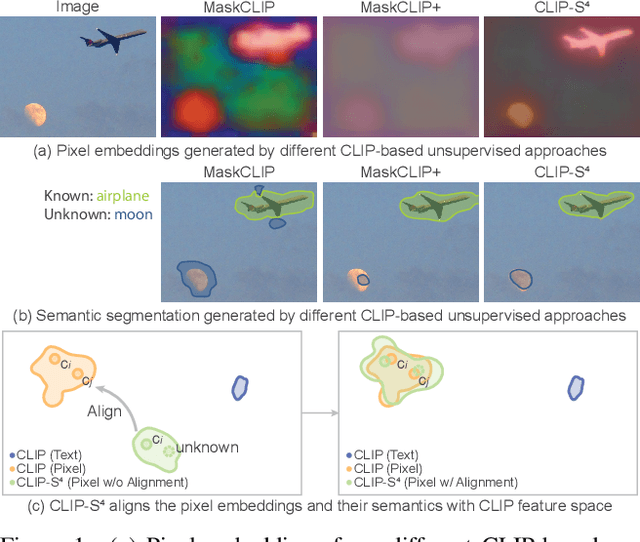

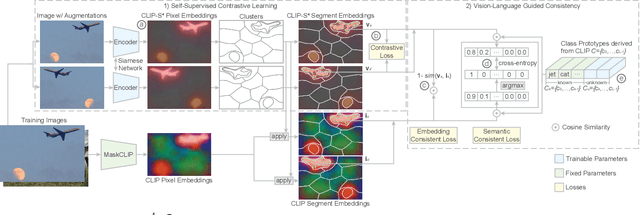
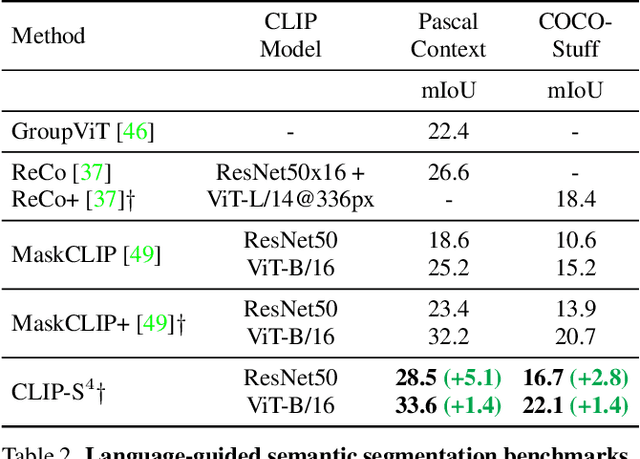
Existing semantic segmentation approaches are often limited by costly pixel-wise annotations and predefined classes. In this work, we present CLIP-S$^4$ that leverages self-supervised pixel representation learning and vision-language models to enable various semantic segmentation tasks (e.g., unsupervised, transfer learning, language-driven segmentation) without any human annotations and unknown class information. We first learn pixel embeddings with pixel-segment contrastive learning from different augmented views of images. To further improve the pixel embeddings and enable language-driven semantic segmentation, we design two types of consistency guided by vision-language models: 1) embedding consistency, aligning our pixel embeddings to the joint feature space of a pre-trained vision-language model, CLIP; and 2) semantic consistency, forcing our model to make the same predictions as CLIP over a set of carefully designed target classes with both known and unknown prototypes. Thus, CLIP-S$^4$ enables a new task of class-free semantic segmentation where no unknown class information is needed during training. As a result, our approach shows consistent and substantial performance improvement over four popular benchmarks compared with the state-of-the-art unsupervised and language-driven semantic segmentation methods. More importantly, our method outperforms these methods on unknown class recognition by a large margin.
Leveraging Language Representation for Material Recommendation, Ranking, and Exploration
May 01, 2023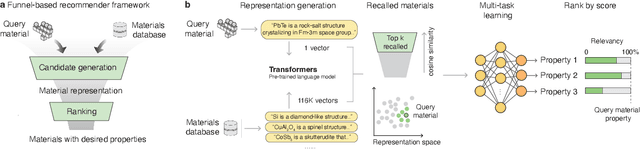
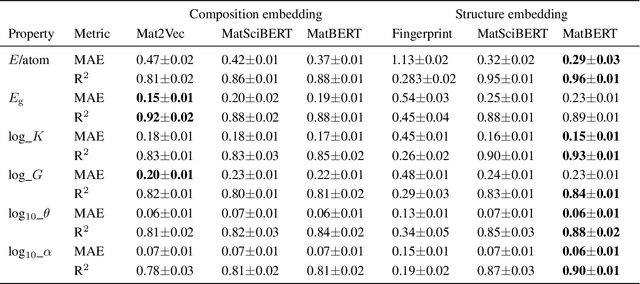
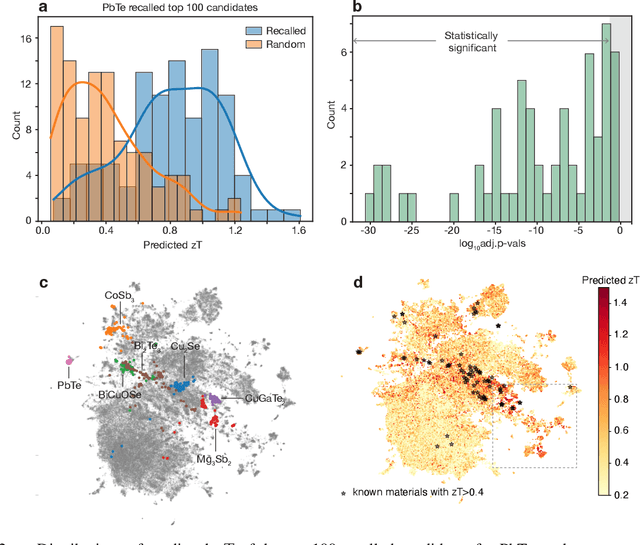
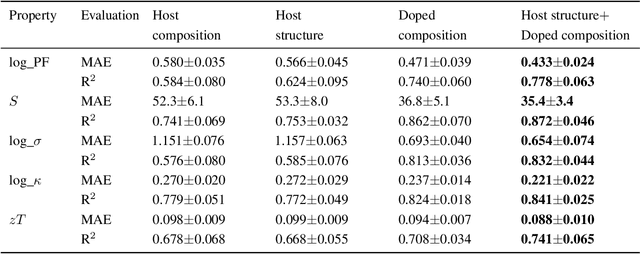
Data-driven approaches for material discovery and design have been accelerated by emerging efforts in machine learning. While there is enormous progress towards learning the structure to property relationship of materials, methods that allow for general representations of crystals to effectively explore the vast material search space and identify high-performance candidates remain limited. In this work, we introduce a material discovery framework that uses natural language embeddings derived from material science-specific language models as representations of compositional and structural features. The discovery framework consists of a joint scheme that, given a query material, first recalls candidates based on representational similarity, and ranks the candidates based on target properties through multi-task learning. The contextual knowledge encoded in language representations is found to convey information about material properties and structures, enabling both similarity analysis for recall, and multi-task learning to share information for related properties. By applying the discovery framework to thermoelectric materials, we demonstrate diversified recommendations of prototype structures and identify under-studied high-performance material spaces, including halide perovskite, delafossite-like, and spinel-like structures. By leveraging material language representations, our framework provides a generalized means for effective material recommendation, which is task-agnostic and can be applied to various material systems.
ChatGPT Perpetuates Gender Bias in Machine Translation and Ignores Non-Gendered Pronouns: Findings across Bengali and Five other Low-Resource Languages
May 17, 2023



In this multicultural age, language translation is one of the most performed tasks, and it is becoming increasingly AI-moderated and automated. As a novel AI system, ChatGPT claims to be proficient in such translation tasks and in this paper, we put that claim to the test. Specifically, we examine ChatGPT's accuracy in translating between English and languages that exclusively use gender-neutral pronouns. We center this study around Bengali, the 7$^{th}$ most spoken language globally, but also generalize our findings across five other languages: Farsi, Malay, Tagalog, Thai, and Turkish. We find that ChatGPT perpetuates gender defaults and stereotypes assigned to certain occupations (e.g. man = doctor, woman = nurse) or actions (e.g. woman = cook, man = go to work), as it converts gender-neutral pronouns in languages to `he' or `she'. We also observe ChatGPT completely failing to translate the English gender-neutral pronoun `they' into equivalent gender-neutral pronouns in other languages, as it produces translations that are incoherent and incorrect. While it does respect and provide appropriately gender-marked versions of Bengali words when prompted with gender information in English, ChatGPT appears to confer a higher respect to men than to women in the same occupation. We conclude that ChatGPT exhibits the same gender biases which have been demonstrated for tools like Google Translate or MS Translator, as we provide recommendations for a human centered approach for future designers of AIs that perform language translation to better accommodate such low-resource languages.
Multi-Level Global Context Cross Consistency Model for Semi-Supervised Ultrasound Image Segmentation with Diffusion Model
May 17, 2023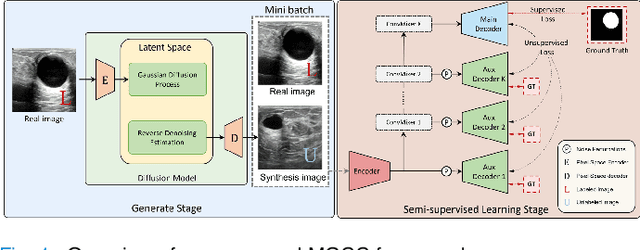
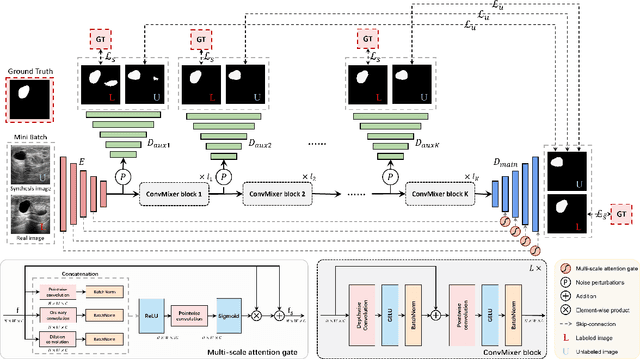
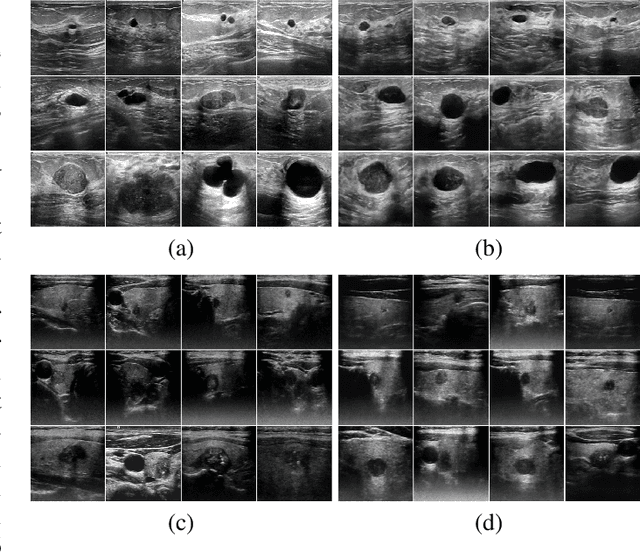
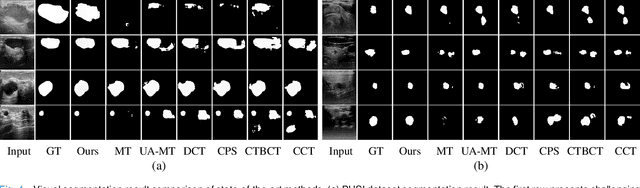
Medical image segmentation is a critical step in computer-aided diagnosis, and convolutional neural networks are popular segmentation networks nowadays. However, the inherent local operation characteristics make it difficult to focus on the global contextual information of lesions with different positions, shapes, and sizes. Semi-supervised learning can be used to learn from both labeled and unlabeled samples, alleviating the burden of manual labeling. However, obtaining a large number of unlabeled images in medical scenarios remains challenging. To address these issues, we propose a Multi-level Global Context Cross-consistency (MGCC) framework that uses images generated by a Latent Diffusion Model (LDM) as unlabeled images for semi-supervised learning. The framework involves of two stages. In the first stage, a LDM is used to generate synthetic medical images, which reduces the workload of data annotation and addresses privacy concerns associated with collecting medical data. In the second stage, varying levels of global context noise perturbation are added to the input of the auxiliary decoder, and output consistency is maintained between decoders to improve the representation ability. Experiments conducted on open-source breast ultrasound and private thyroid ultrasound datasets demonstrate the effectiveness of our framework in bridging the probability distribution and the semantic representation of the medical image. Our approach enables the effective transfer of probability distribution knowledge to the segmentation network, resulting in improved segmentation accuracy. The code is available at https://github.com/FengheTan9/Multi-Level-Global-Context-Cross-Consistency.
Improving Link Prediction in Social Networks Using Local and Global Features: A Clustering-based Approach
May 17, 2023Link prediction problem has increasingly become prominent in many domains such as social network analyses, bioinformatics experiments, transportation networks, criminal investigations and so forth. A variety of techniques has been developed for link prediction problem, categorized into 1) similarity based approaches which study a set of features to extract similar nodes; 2) learning based approaches which extract patterns from the input data; 3) probabilistic statistical approaches which optimize a set of parameters to establish a model which can best compute formation probability. However, existing literatures lack approaches which utilize strength of each approach by integrating them to achieve a much more productive one. To tackle the link prediction problem, we propose an approach based on the combination of first and second group methods; the existing studied works use just one of these categories. Our two-phase developed method firstly determines new features related to the position and dynamic behavior of nodes, which enforce the approach more efficiency compared to approaches using mere measures. Then, a subspace clustering algorithm is applied to group social objects based on the computed similarity measures which differentiate the strength of clusters; basically, the usage of local and global indices and the clustering information plays an imperative role in our link prediction process. Some extensive experiments held on real datasets including Facebook, Brightkite and HepTh indicate good performances of our proposal method. Besides, we have experimentally verified our approach with some previous techniques in the area to prove the supremacy of ours.
Iteratively Learning Representations for Unseen Entities with Inter-Rule Correlations
May 17, 2023
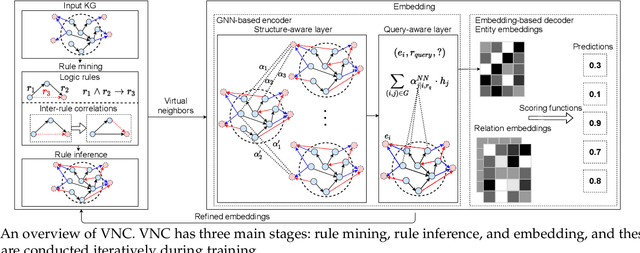
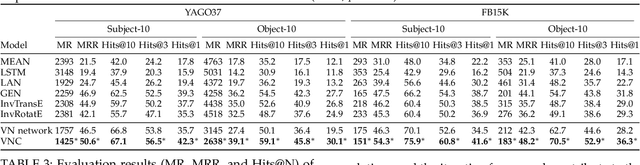
Recent work on knowledge graph completion (KGC) focused on learning embeddings of entities and relations in knowledge graphs. These embedding methods require that all test entities are observed at training time, resulting in a time-consuming retraining process for out-of-knowledge-graph (OOKG) entities. To address this issue, current inductive knowledge embedding methods employ graph neural networks (GNNs) to represent unseen entities by aggregating information of known neighbors. They face three important challenges: (i) data sparsity, (ii) the presence of complex patterns in knowledge graphs (e.g., inter-rule correlations), and (iii) the presence of interactions among rule mining, rule inference, and embedding. In this paper, we propose a virtual neighbor network with inter-rule correlations (VNC) that consists of three stages: (i) rule mining, (ii) rule inference, and (iii) embedding. In the rule mining process, to identify complex patterns in knowledge graphs, both logic rules and inter-rule correlations are extracted from knowledge graphs based on operations over relation embeddings. To reduce data sparsity, virtual neighbors for OOKG entities are predicted and assigned soft labels by optimizing a rule-constrained problem. We also devise an iterative framework to capture the underlying relations between rule learning and embedding learning. In our experiments, results on both link prediction and triple classification tasks show that the proposed VNC framework achieves state-of-the-art performance on four widely-used knowledge graphs. Further analysis reveals that VNC is robust to the proportion of unseen entities and effectively mitigates data sparsity.
Collective Large-scale Wind Farm Multivariate Power Output Control Based on Hierarchical Communication Multi-Agent Proximal Policy Optimization
May 17, 2023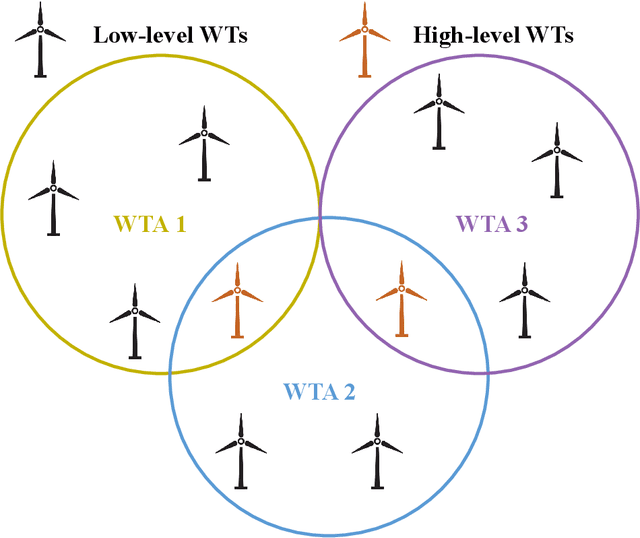

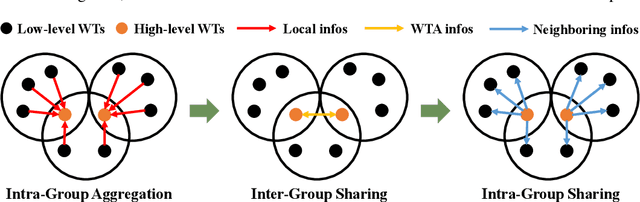
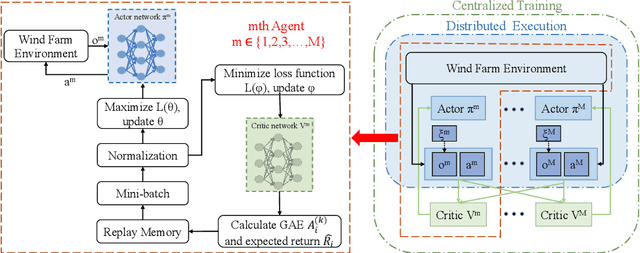
Wind power is becoming an increasingly important source of renewable energy worldwide. However, wind farm power control faces significant challenges due to the high system complexity inherent in these farms. A novel communication-based multi-agent deep reinforcement learning large-scale wind farm multivariate control is proposed to handle this challenge and maximize power output. A wind farm multivariate power model is proposed to study the influence of wind turbines (WTs) wake on power. The multivariate model includes axial induction factor, yaw angle, and tilt angle controllable variables. The hierarchical communication multi-agent proximal policy optimization (HCMAPPO) algorithm is proposed to coordinate the multivariate large-scale wind farm continuous controls. The large-scale wind farm is divided into multiple wind turbine aggregators (WTAs), and neighboring WTAs can exchange information through hierarchical communication to maximize the wind farm power output. Simulation results demonstrate that the proposed multivariate HCMAPPO can significantly increase wind farm power output compared to the traditional PID control, coordinated model-based predictive control, and multi-agent deep deterministic policy gradient algorithm. Particularly, the HCMAPPO algorithm can be trained with the environment based on the thirteen-turbine wind farm and effectively applied to larger wind farms. At the same time, there is no significant increase in the fatigue damage of the wind turbine blade from the wake control as the wind farm scale increases. The multivariate HCMAPPO control can realize the collective large-scale wind farm maximum power output.
Two Birds, One Stone: A Unified Framework for Joint Learning of Image and Video Style Transfers
Apr 22, 2023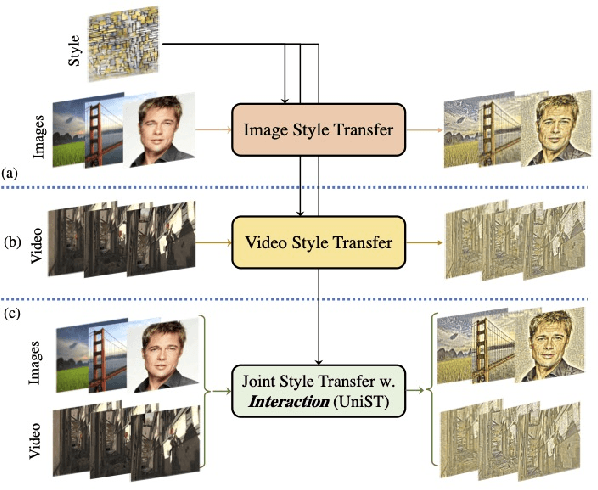

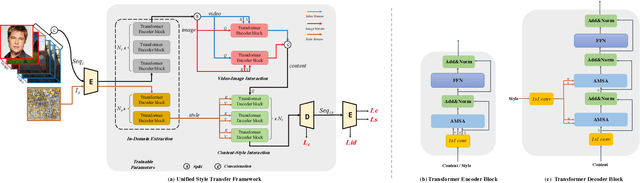
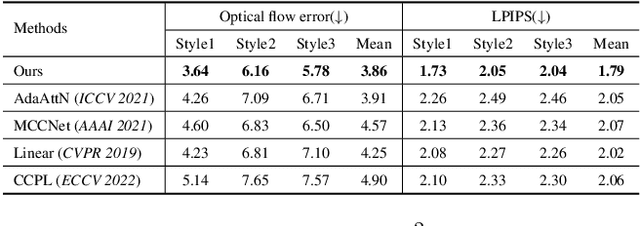
Current arbitrary style transfer models are limited to either image or video domains. In order to achieve satisfying image and video style transfers, two different models are inevitably required with separate training processes on image and video domains, respectively. In this paper, we show that this can be precluded by introducing UniST, a Unified Style Transfer framework for both images and videos. At the core of UniST is a domain interaction transformer (DIT), which first explores context information within the specific domain and then interacts contextualized domain information for joint learning. In particular, DIT enables exploration of temporal information from videos for the image style transfer task and meanwhile allows rich appearance texture from images for video style transfer, thus leading to mutual benefits. Considering heavy computation of traditional multi-head self-attention, we present a simple yet effective axial multi-head self-attention (AMSA) for DIT, which improves computational efficiency while maintains style transfer performance. To verify the effectiveness of UniST, we conduct extensive experiments on both image and video style transfer tasks and show that UniST performs favorably against state-of-the-art approaches on both tasks. Our code and results will be released.