 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring the Viability of Synthetic Query Generation for Relevance Prediction
May 19, 2023
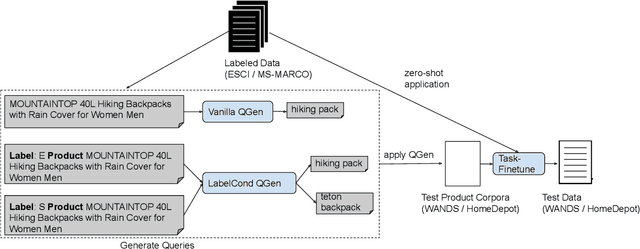
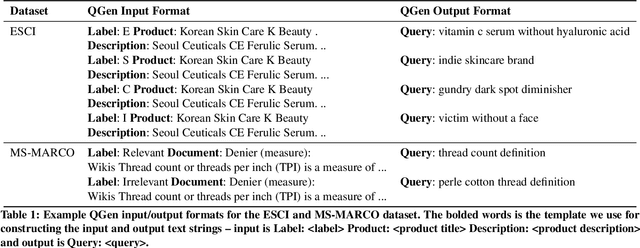

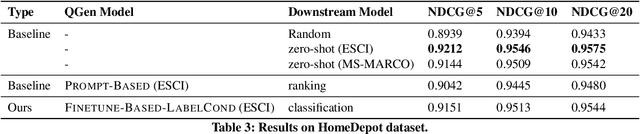
Query-document relevance prediction is a critical problem in Information Retrieval systems. This problem has increasingly been tackled using (pretrained) transformer-based models which are finetuned using large collections of labeled data. However, in specialized domains such as e-commerce and healthcare, the viability of this approach is limited by the dearth of large in-domain data. To address this paucity, recent methods leverage these powerful models to generate high-quality task and domain-specific synthetic data. Prior work has largely explored synthetic data generation or query generation (QGen) for Question-Answering (QA) and binary (yes/no) relevance prediction, where for instance, the QGen models are given a document, and trained to generate a query relevant to that document. However in many problems, we have a more fine-grained notion of relevance than a simple yes/no label. Thus, in this work, we conduct a detailed study into how QGen approaches can be leveraged for nuanced relevance prediction. We demonstrate that -- contrary to claims from prior works -- current QGen approaches fall short of the more conventional cross-domain transfer-learning approaches. Via empirical studies spanning 3 public e-commerce benchmarks, we identify new shortcomings of existing QGen approaches -- including their inability to distinguish between different grades of relevance. To address this, we introduce label-conditioned QGen models which incorporates knowledge about the different relevance. While our experiments demonstrate that these modifications help improve performance of QGen techniques, we also find that QGen approaches struggle to capture the full nuance of the relevance label space and as a result the generated queries are not faithful to the desired relevance label.
Two-Bit RIS-Aided Communications at 3.5GHz: Some Insights from the Measurement Results Under Multiple Practical Scenes
May 19, 2023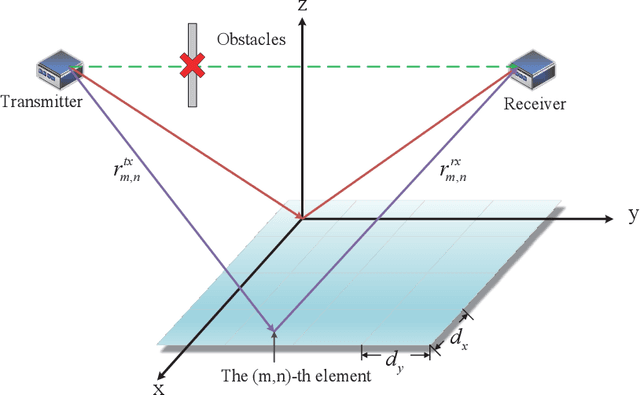
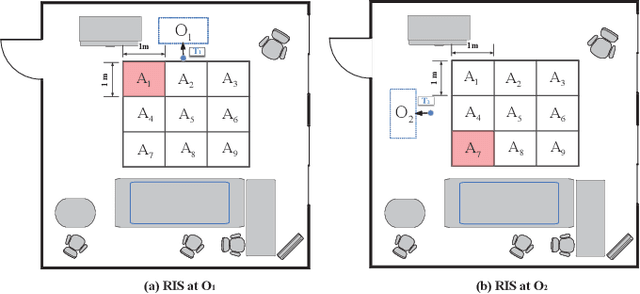
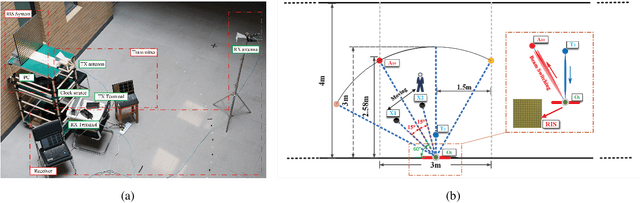
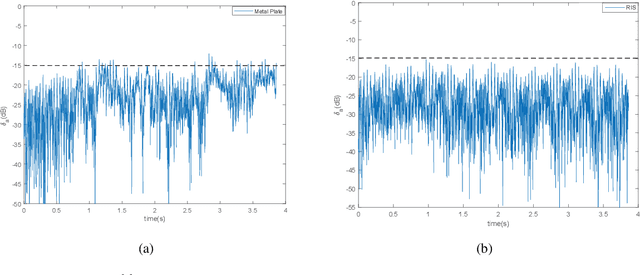
In this paper, we propose a two-bit reconfigurable intelligent surface (RIS)-aided communication system, which mainly consists of a two-bit RIS, a transmitter and a receiver. A corresponding prototype verification system is designed to perform experimental tests in practical environments. The carrier frequency is set as 3.5GHz, and the RIS array possesses 256 units, each of which adopts two-bit phase quantization. In particular, we adopt a self-developed broadband intelligent communication system 40MHz-Net (BICT-40N) terminal in order to fully acquire the channel information. The terminal mainly includes a baseband board and a radio frequency (RF) front-end board, where the latter can achieve 26 dB transmitting link gain and 33 dB receiving link gain. The orthogonal frequency division multiplexing (OFDM) signal is used for the terminal, where the bandwidth is 40MHz and the subcarrier spacing is 625KHz. Also, the terminal supports a series of modulation modes, including QPSK, QAM, etc.Through experimental tests, we validate a few functions and properties of the RIS as follows. First, we validate a novel RIS power consumption model, which considers both the static and the dynamic power consumption. Besides, we demonstrate the existence of the imaging interference and find that two-bit RIS can lower the imaging interference about 10 dBm. Moreover, we verify that the RIS can outperform the metal plate in terms of the beam focusing performance. In addition, we find that the RIS has the ability to improve the channel stationarity. Then, we realize the multi-beam reflection of the RIS utilizing the pattern addition (PA) algorithm. Lastly, we validate the existence of the mutual coupling between different RIS units.
Leveraging Large Language Models in Conversational Recommender Systems
May 16, 2023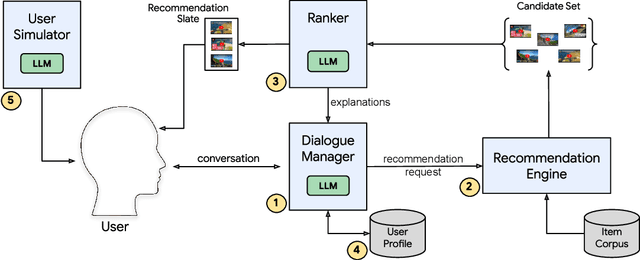



A Conversational Recommender System (CRS) offers increased transparency and control to users by enabling them to engage with the system through a real-time multi-turn dialogue. Recently, Large Language Models (LLMs) have exhibited an unprecedented ability to converse naturally and incorporate world knowledge and common-sense reasoning into language understanding, unlocking the potential of this paradigm. However, effectively leveraging LLMs within a CRS introduces new technical challenges, including properly understanding and controlling a complex conversation and retrieving from external sources of information. These issues are exacerbated by a large, evolving item corpus and a lack of conversational data for training. In this paper, we provide a roadmap for building an end-to-end large-scale CRS using LLMs. In particular, we propose new implementations for user preference understanding, flexible dialogue management and explainable recommendations as part of an integrated architecture powered by LLMs. For improved personalization, we describe how an LLM can consume interpretable natural language user profiles and use them to modulate session-level context. To overcome conversational data limitations in the absence of an existing production CRS, we propose techniques for building a controllable LLM-based user simulator to generate synthetic conversations. As a proof of concept we introduce RecLLM, a large-scale CRS for YouTube videos built on LaMDA, and demonstrate its fluency and diverse functionality through some illustrative example conversations.
Increasing Melanoma Diagnostic Confidence: Forcing the Convolutional Network to Learn from the Lesion
May 16, 2023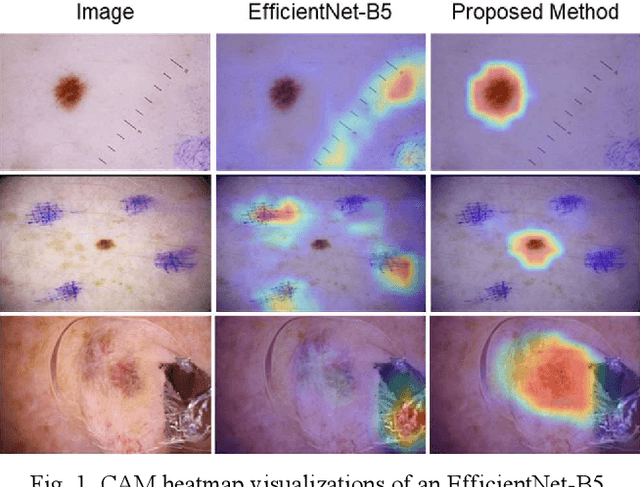
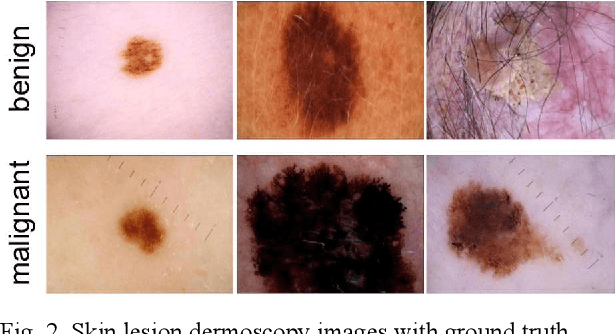
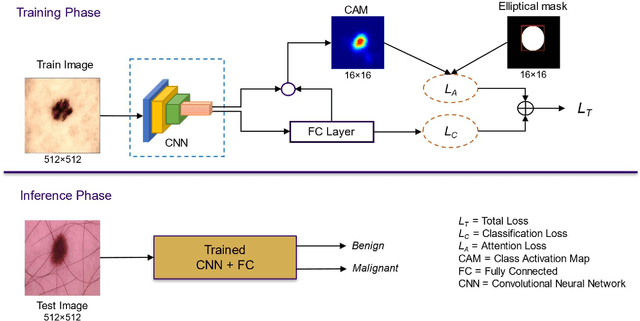

Deep learning implemented with convolutional network architectures can exceed specialists' diagnostic accuracy. However, whole-image deep learning trained on a given dataset may not generalize to other datasets. The problem arises because extra-lesional features - ruler marks, ink marks, and other melanoma correlates - may serve as information leaks. These extra-lesional features, discoverable by heat maps, degrade melanoma diagnostic performance and cause techniques learned on one data set to fail to generalize. We propose a novel technique to improve melanoma recognition by an EfficientNet model. The model trains the network to detect the lesion and learn features from the detected lesion. A generalizable elliptical segmentation model for lesions was developed, with an ellipse enclosing a lesion and the ellipse enclosed by an extended rectangle (bounding box). The minimal bounding box was extended by 20% to allow some background around the lesion. The publicly available International Skin Imaging Collaboration (ISIC) 2020 skin lesion image dataset was used to evaluate the effectiveness of the proposed method. Our test results show that the proposed method improved diagnostic accuracy by increasing the mean area under receiver operating characteristic curve (mean AUC) score from 0.9 to 0.922. Additionally, correctly diagnosed scores are also improved, providing better separation of scores, thereby increasing melanoma diagnostic confidence. The proposed lesion-focused convolutional technique warrants further study.
A Method for Training-free Person Image Picture Generation
May 16, 2023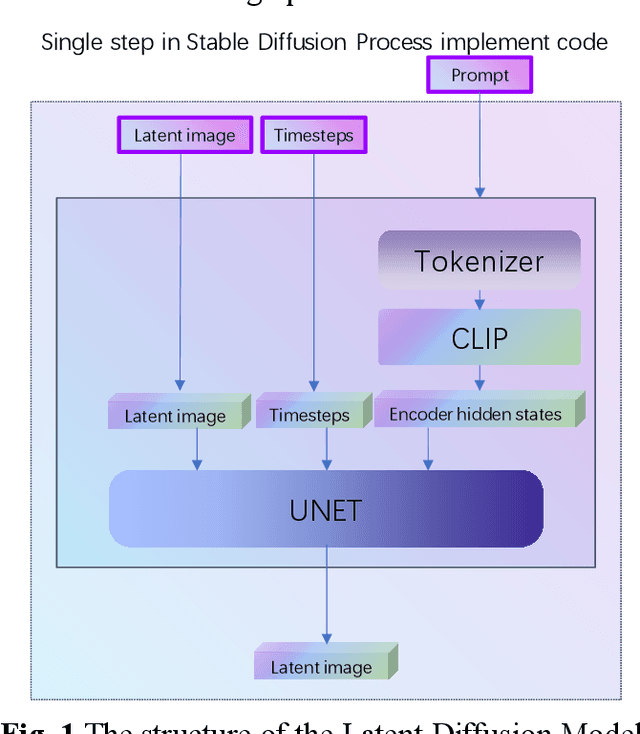
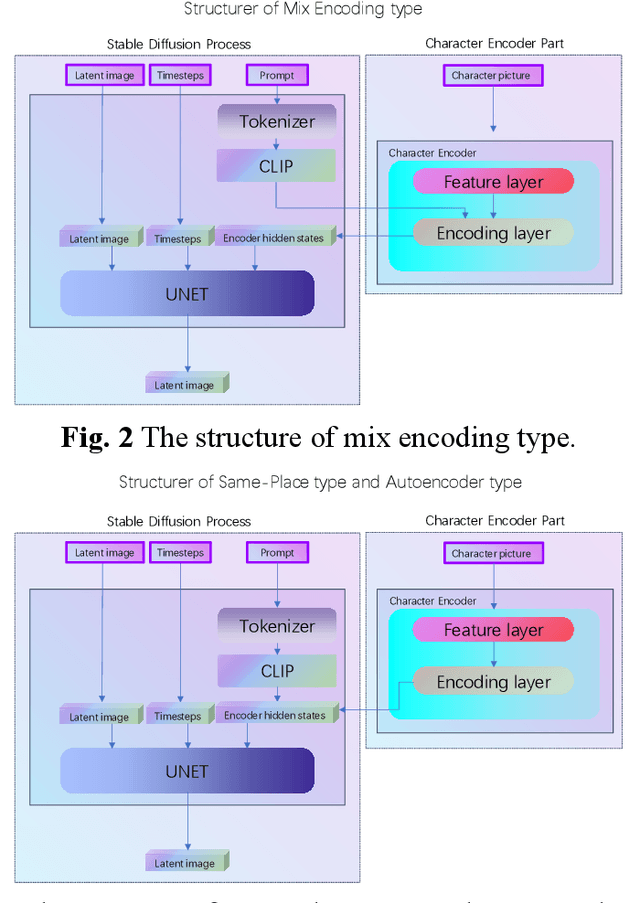

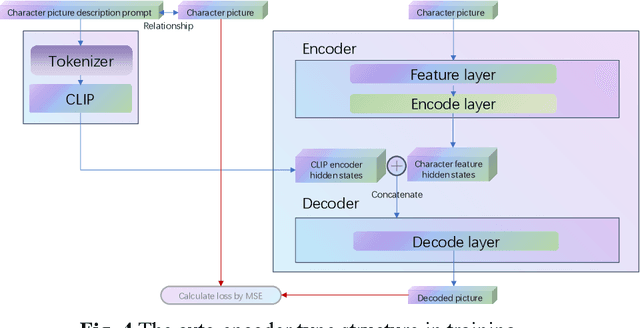
The current state-of-the-art Diffusion model has demonstrated excellent results in generating images. However, the images are monotonous and are mostly the result of the distribution of images of people in the training set, making it challenging to generate multiple images for a fixed number of individuals. This problem can often only be solved by fine-tuning the training of the model. This means that each individual/animated character image must be trained if it is to be drawn, and the hardware and cost of this training is often beyond the reach of the average user, who accounts for the largest number of people. To solve this problem, the Character Image Feature Encoder model proposed in this paper enables the user to use the process by simply providing a picture of the character to make the image of the character in the generated image match the expectation. In addition, various details can be adjusted during the process using prompts. Unlike traditional Image-to-Image models, the Character Image Feature Encoder extracts only the relevant image features, rather than information about the model's composition or movements. In addition, the Character Image Feature Encoder can be adapted to different models after training. The proposed model can be conveniently incorporated into the Stable Diffusion generation process without modifying the model's ontology or used in combination with Stable Diffusion as a joint model.
FreConv: Frequency Branch-and-Integration Convolutional Networks
Apr 10, 2023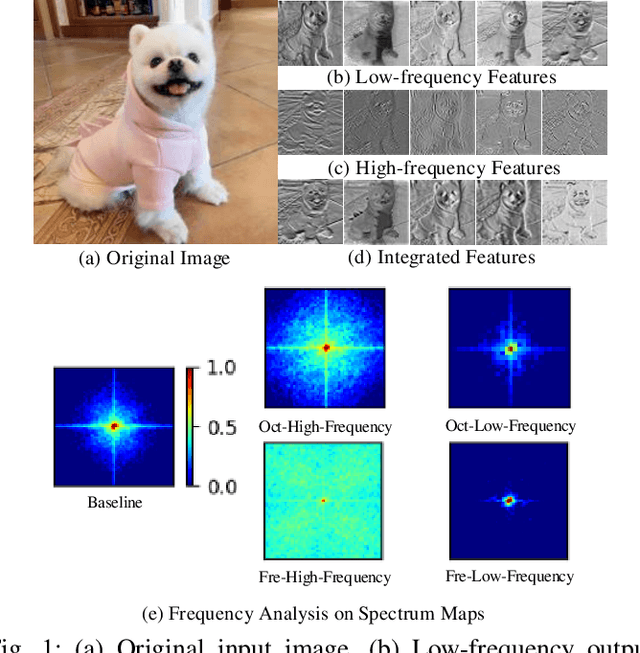
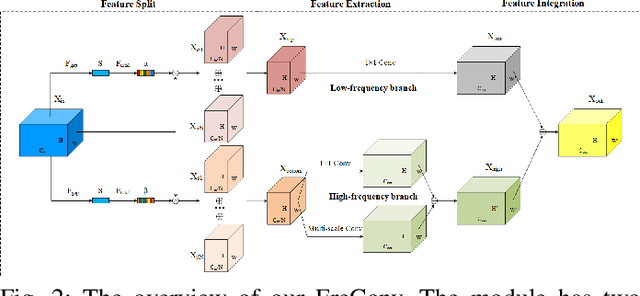
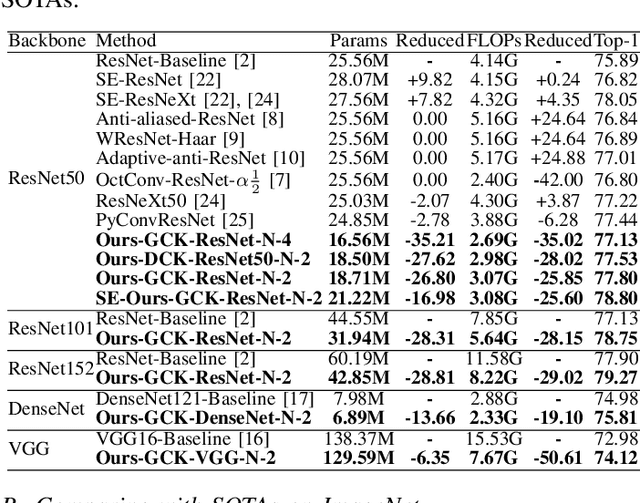
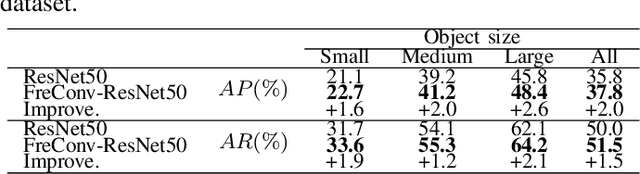
Recent researches indicate that utilizing the frequency information of input data can enhance the performance of networks. However, the existing popular convolutional structure is not designed specifically for utilizing the frequency information contained in datasets. In this paper, we propose a novel and effective module, named FreConv (frequency branch-and-integration convolution), to replace the vanilla convolution. FreConv adopts a dual-branch architecture to extract and integrate high- and low-frequency information. In the high-frequency branch, a derivative-filter-like architecture is designed to extract the high-frequency information while a light extractor is employed in the low-frequency branch because the low-frequency information is usually redundant. FreConv is able to exploit the frequency information of input data in a more reasonable way to enhance feature representation ability and reduce the memory and computational cost significantly. Without any bells and whistles, experimental results on various tasks demonstrate that FreConv-equipped networks consistently outperform state-of-the-art baselines.
ChatGPT Perpetuates Gender Bias in Machine Translation and Ignores Non-Gendered Pronouns: Findings across Bengali and Five other Low-Resource Languages
May 17, 2023



In this multicultural age, language translation is one of the most performed tasks, and it is becoming increasingly AI-moderated and automated. As a novel AI system, ChatGPT claims to be proficient in such translation tasks and in this paper, we put that claim to the test. Specifically, we examine ChatGPT's accuracy in translating between English and languages that exclusively use gender-neutral pronouns. We center this study around Bengali, the 7$^{th}$ most spoken language globally, but also generalize our findings across five other languages: Farsi, Malay, Tagalog, Thai, and Turkish. We find that ChatGPT perpetuates gender defaults and stereotypes assigned to certain occupations (e.g. man = doctor, woman = nurse) or actions (e.g. woman = cook, man = go to work), as it converts gender-neutral pronouns in languages to `he' or `she'. We also observe ChatGPT completely failing to translate the English gender-neutral pronoun `they' into equivalent gender-neutral pronouns in other languages, as it produces translations that are incoherent and incorrect. While it does respect and provide appropriately gender-marked versions of Bengali words when prompted with gender information in English, ChatGPT appears to confer a higher respect to men than to women in the same occupation. We conclude that ChatGPT exhibits the same gender biases which have been demonstrated for tools like Google Translate or MS Translator, as we provide recommendations for a human centered approach for future designers of AIs that perform language translation to better accommodate such low-resource languages.
Multi-Level Global Context Cross Consistency Model for Semi-Supervised Ultrasound Image Segmentation with Diffusion Model
May 17, 2023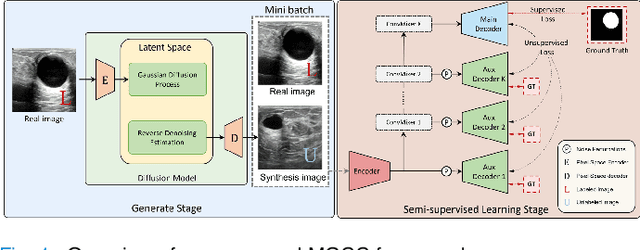
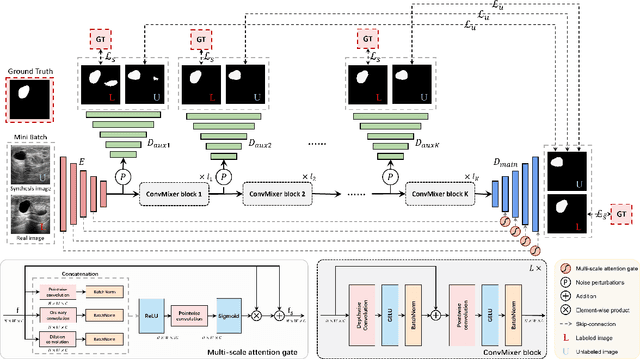
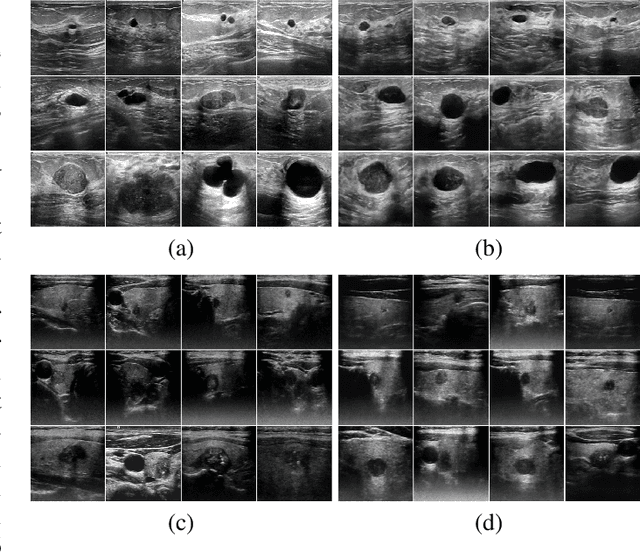
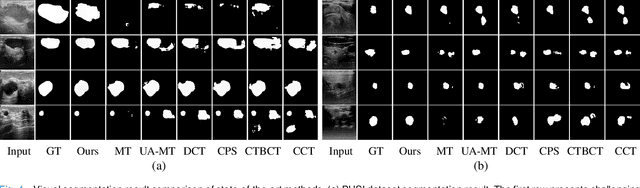
Medical image segmentation is a critical step in computer-aided diagnosis, and convolutional neural networks are popular segmentation networks nowadays. However, the inherent local operation characteristics make it difficult to focus on the global contextual information of lesions with different positions, shapes, and sizes. Semi-supervised learning can be used to learn from both labeled and unlabeled samples, alleviating the burden of manual labeling. However, obtaining a large number of unlabeled images in medical scenarios remains challenging. To address these issues, we propose a Multi-level Global Context Cross-consistency (MGCC) framework that uses images generated by a Latent Diffusion Model (LDM) as unlabeled images for semi-supervised learning. The framework involves of two stages. In the first stage, a LDM is used to generate synthetic medical images, which reduces the workload of data annotation and addresses privacy concerns associated with collecting medical data. In the second stage, varying levels of global context noise perturbation are added to the input of the auxiliary decoder, and output consistency is maintained between decoders to improve the representation ability. Experiments conducted on open-source breast ultrasound and private thyroid ultrasound datasets demonstrate the effectiveness of our framework in bridging the probability distribution and the semantic representation of the medical image. Our approach enables the effective transfer of probability distribution knowledge to the segmentation network, resulting in improved segmentation accuracy. The code is available at https://github.com/FengheTan9/Multi-Level-Global-Context-Cross-Consistency.
Improving Link Prediction in Social Networks Using Local and Global Features: A Clustering-based Approach
May 17, 2023Link prediction problem has increasingly become prominent in many domains such as social network analyses, bioinformatics experiments, transportation networks, criminal investigations and so forth. A variety of techniques has been developed for link prediction problem, categorized into 1) similarity based approaches which study a set of features to extract similar nodes; 2) learning based approaches which extract patterns from the input data; 3) probabilistic statistical approaches which optimize a set of parameters to establish a model which can best compute formation probability. However, existing literatures lack approaches which utilize strength of each approach by integrating them to achieve a much more productive one. To tackle the link prediction problem, we propose an approach based on the combination of first and second group methods; the existing studied works use just one of these categories. Our two-phase developed method firstly determines new features related to the position and dynamic behavior of nodes, which enforce the approach more efficiency compared to approaches using mere measures. Then, a subspace clustering algorithm is applied to group social objects based on the computed similarity measures which differentiate the strength of clusters; basically, the usage of local and global indices and the clustering information plays an imperative role in our link prediction process. Some extensive experiments held on real datasets including Facebook, Brightkite and HepTh indicate good performances of our proposal method. Besides, we have experimentally verified our approach with some previous techniques in the area to prove the supremacy of ours.
Iteratively Learning Representations for Unseen Entities with Inter-Rule Correlations
May 17, 2023
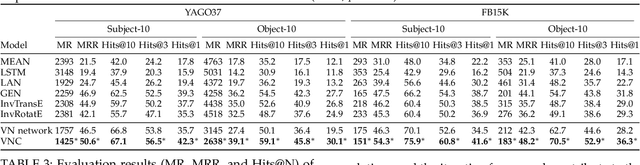
Recent work on knowledge graph completion (KGC) focused on learning embeddings of entities and relations in knowledge graphs. These embedding methods require that all test entities are observed at training time, resulting in a time-consuming retraining process for out-of-knowledge-graph (OOKG) entities. To address this issue, current inductive knowledge embedding methods employ graph neural networks (GNNs) to represent unseen entities by aggregating information of known neighbors. They face three important challenges: (i) data sparsity, (ii) the presence of complex patterns in knowledge graphs (e.g., inter-rule correlations), and (iii) the presence of interactions among rule mining, rule inference, and embedding. In this paper, we propose a virtual neighbor network with inter-rule correlations (VNC) that consists of three stages: (i) rule mining, (ii) rule inference, and (iii) embedding. In the rule mining process, to identify complex patterns in knowledge graphs, both logic rules and inter-rule correlations are extracted from knowledge graphs based on operations over relation embeddings. To reduce data sparsity, virtual neighbors for OOKG entities are predicted and assigned soft labels by optimizing a rule-constrained problem. We also devise an iterative framework to capture the underlying relations between rule learning and embedding learning. In our experiments, results on both link prediction and triple classification tasks show that the proposed VNC framework achieves state-of-the-art performance on four widely-used knowledge graphs. Further analysis reveals that VNC is robust to the proportion of unseen entities and effectively mitigates data sparsity.