 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
In the Name of Fairness: Assessing the Bias in Clinical Record De-identification
May 18, 2023
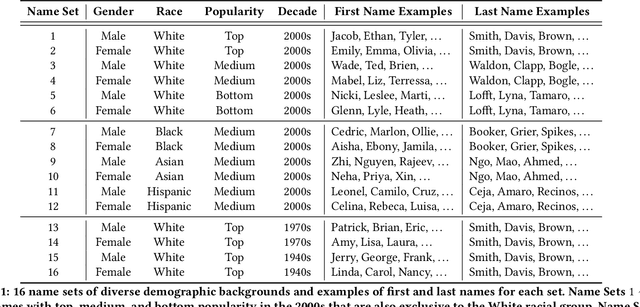
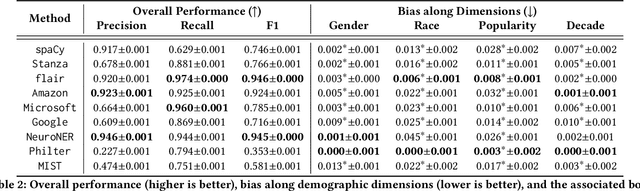
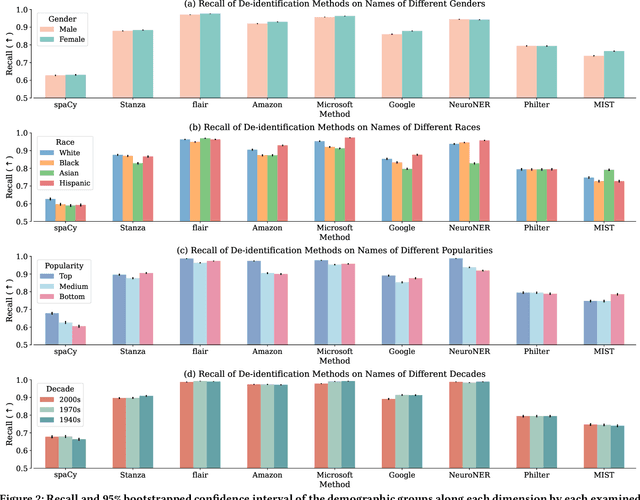
Data sharing is crucial for open science and reproducible research, but the legal sharing of clinical data requires the removal of protected health information from electronic health records. This process, known as de-identification, is often achieved through the use of machine learning algorithms by many commercial and open-source systems. While these systems have shown compelling results on average, the variation in their performance across different demographic groups has not been thoroughly examined. In this work, we investigate the bias of de-identification systems on names in clinical notes via a large-scale empirical analysis. To achieve this, we create 16 name sets that vary along four demographic dimensions: gender, race, name popularity, and the decade of popularity. We insert these names into 100 manually curated clinical templates and evaluate the performance of nine public and private de-identification methods. Our findings reveal that there are statistically significant performance gaps along a majority of the demographic dimensions in most methods. We further illustrate that de-identification quality is affected by polysemy in names, gender context, and clinical note characteristics. To mitigate the identified gaps, we propose a simple and method-agnostic solution by fine-tuning de-identification methods with clinical context and diverse names. Overall, it is imperative to address the bias in existing methods immediately so that downstream stakeholders can build high-quality systems to serve all demographic parties fairly.
SmartPhone: Exploring Keyword Mnemonic with Auto-generated Verbal and Visual Cues
May 11, 2023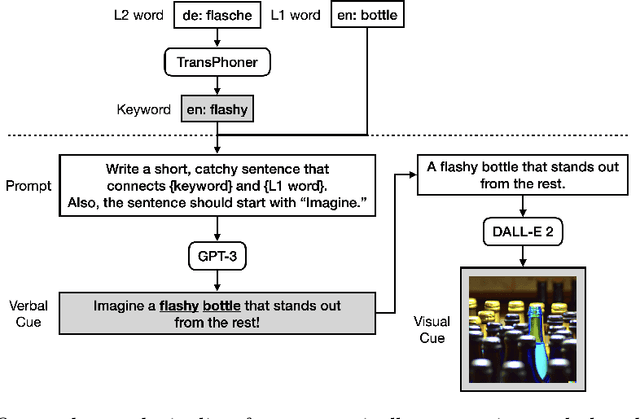

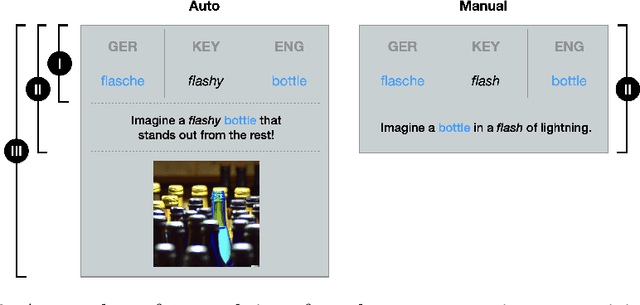
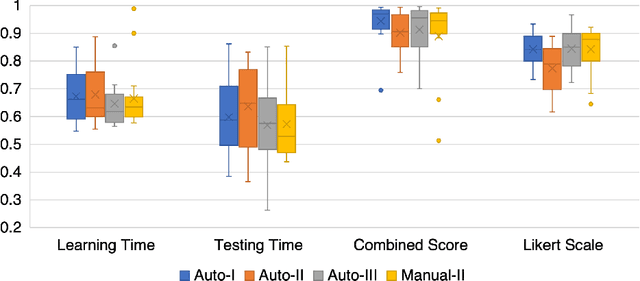
In second language vocabulary learning, existing works have primarily focused on either the learning interface or scheduling personalized retrieval practices to maximize memory retention. However, the learning content, i.e., the information presented on flashcards, has mostly remained constant. Keyword mnemonic is a notable learning strategy that relates new vocabulary to existing knowledge by building an acoustic and imagery link using a keyword that sounds alike. Beyond that, producing verbal and visual cues associated with the keyword to facilitate building these links requires a manual process and is not scalable. In this paper, we explore an opportunity to use large language models to automatically generate verbal and visual cues for keyword mnemonics. Our approach, an end-to-end pipeline for auto-generating verbal and visual cues, can automatically generate highly memorable cues. We investigate the effectiveness of our approach via a human participant experiment by comparing it with manually generated cues.
KEPLET: Knowledge-Enhanced Pretrained Language Model with Topic Entity Awareness
May 02, 2023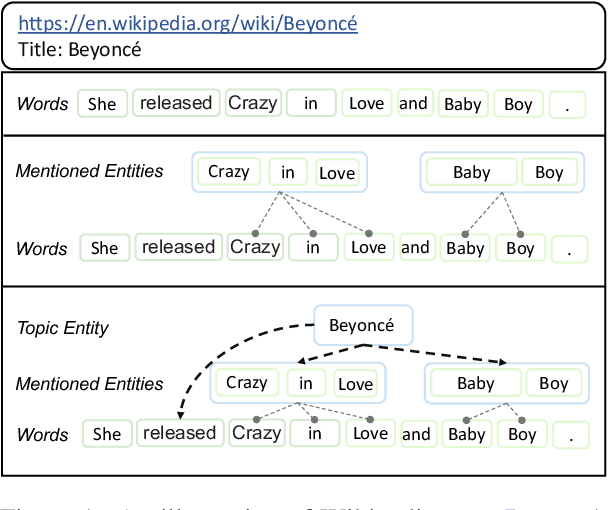
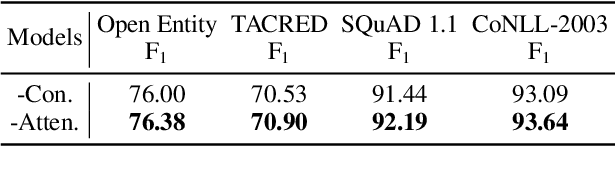
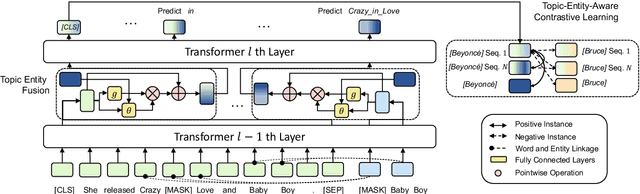
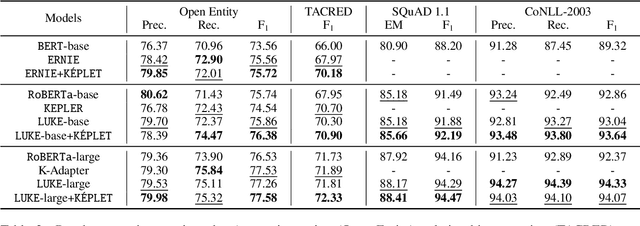
In recent years, Pre-trained Language Models (PLMs) have shown their superiority by pre-training on unstructured text corpus and then fine-tuning on downstream tasks. On entity-rich textual resources like Wikipedia, Knowledge-Enhanced PLMs (KEPLMs) incorporate the interactions between tokens and mentioned entities in pre-training, and are thus more effective on entity-centric tasks such as entity linking and relation classification. Although exploiting Wikipedia's rich structures to some extent, conventional KEPLMs still neglect a unique layout of the corpus where each Wikipedia page is around a topic entity (identified by the page URL and shown in the page title). In this paper, we demonstrate that KEPLMs without incorporating the topic entities will lead to insufficient entity interaction and biased (relation) word semantics. We thus propose KEPLET, a novel Knowledge-Enhanced Pre-trained LanguagE model with Topic entity awareness. In an end-to-end manner, KEPLET identifies where to add the topic entity's information in a Wikipedia sentence, fuses such information into token and mentioned entities representations, and supervises the network learning, through which it takes topic entities back into consideration. Experiments demonstrated the generality and superiority of KEPLET which was applied to two representative KEPLMs, achieving significant improvements on four entity-centric tasks.
CVRecon: Rethinking 3D Geometric Feature Learning For Neural Reconstruction
Apr 28, 2023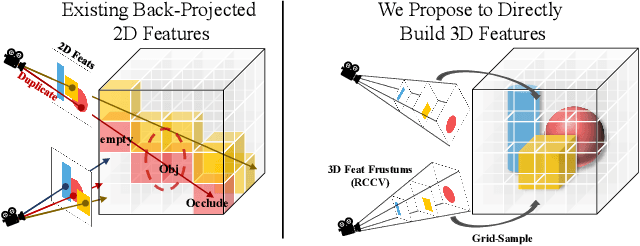
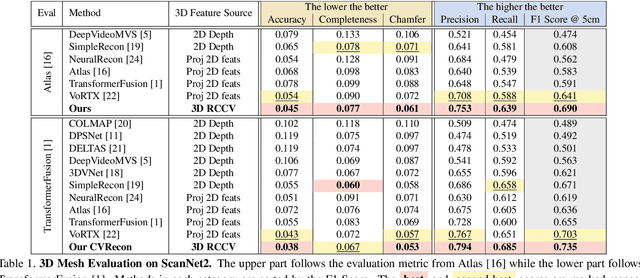
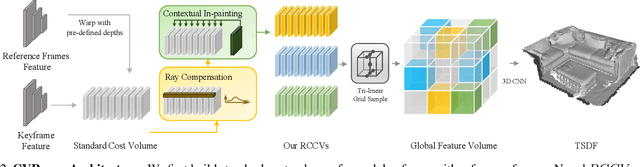
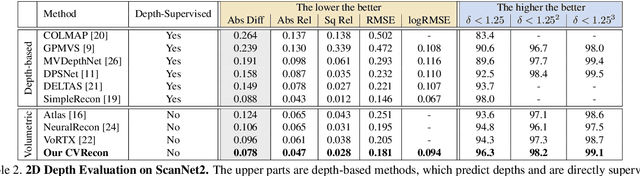
Recent advances in neural reconstruction using posed image sequences have made remarkable progress. However, due to the lack of depth information, existing volumetric-based techniques simply duplicate 2D image features of the object surface along the entire camera ray. We contend this duplication introduces noise in empty and occluded spaces, posing challenges for producing high-quality 3D geometry. Drawing inspiration from traditional multi-view stereo methods, we propose an end-to-end 3D neural reconstruction framework CVRecon, designed to exploit the rich geometric embedding in the cost volumes to facilitate 3D geometric feature learning. Furthermore, we present Ray-contextual Compensated Cost Volume (RCCV), a novel 3D geometric feature representation that encodes view-dependent information with improved integrity and robustness. Through comprehensive experiments, we demonstrate that our approach significantly improves the reconstruction quality in various metrics and recovers clear fine details of the 3D geometries. Our extensive ablation studies provide insights into the development of effective 3D geometric feature learning schemes. Project page: https://cvrecon.ziyue.cool/
Click-Feedback Retrieval
Apr 28, 2023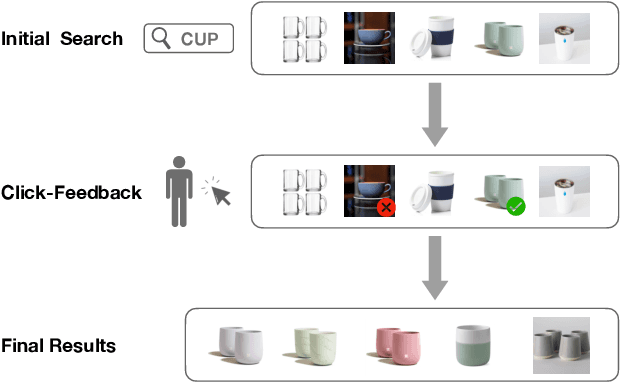
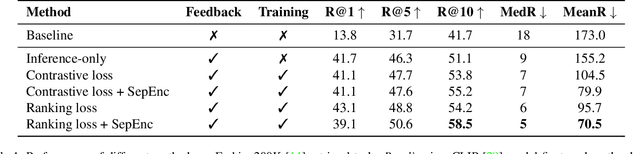
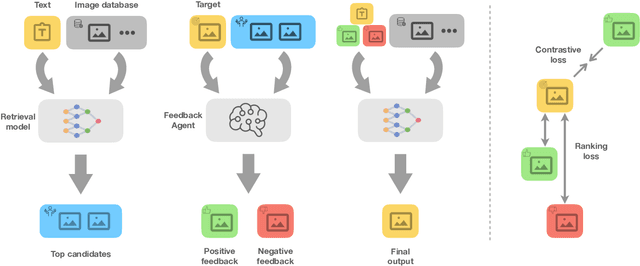
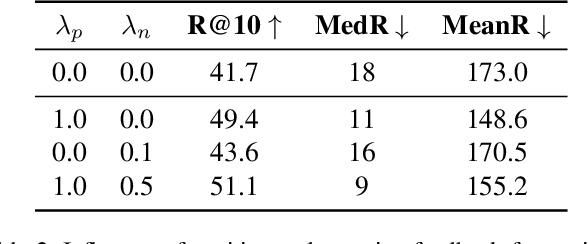
Retrieving target information based on input query is of fundamental importance in many real-world applications. In practice, it is not uncommon for the initial search to fail, where additional feedback information is needed to guide the searching process. In this work, we study a setting where the feedback is provided through users clicking liked and disliked searching results. We believe this form of feedback is of great practical interests for its convenience and efficiency. To facilitate future work in this direction, we construct a new benchmark termed click-feedback retrieval based on a large-scale dataset in fashion domain. We demonstrate that incorporating click-feedback can drastically improve the retrieval performance, which validates the value of the proposed setting. We also introduce several methods to utilize click-feedback during training, and show that click-feedback-guided training can significantly enhance the retrieval quality. We hope further exploration in this direction can bring new insights on building more efficient and user-friendly search engines.
Geometric Relational Embeddings: A Survey
Apr 24, 2023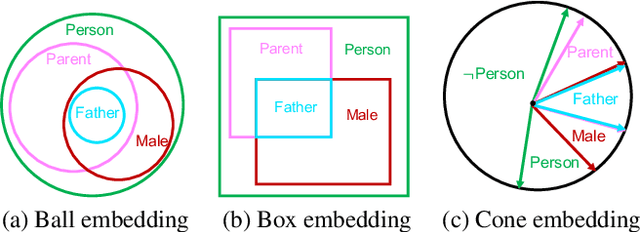
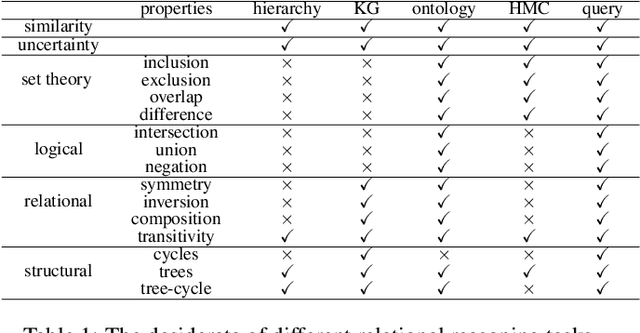
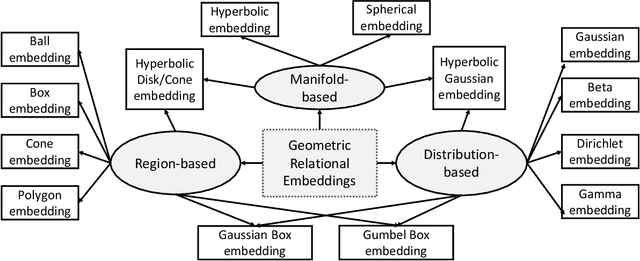
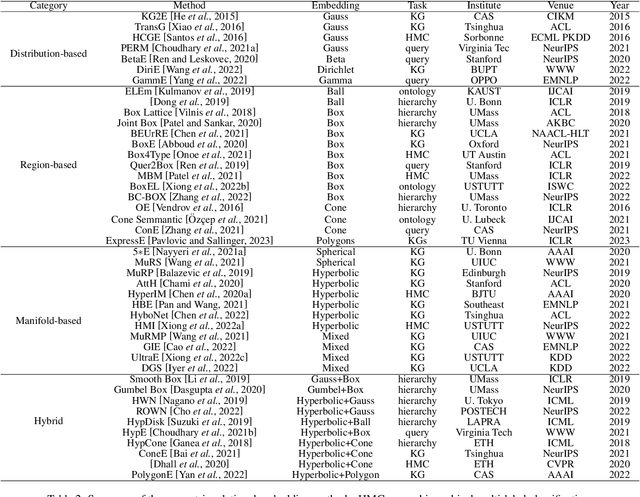
Geometric relational embeddings map relational data as geometric objects that combine vector information suitable for machine learning and structured/relational information for structured/relational reasoning, typically in low dimensions. Their preservation of relational structures and their appealing properties and interpretability have led to their uptake for tasks such as knowledge graph completion, ontology and hierarchy reasoning, logical query answering, and hierarchical multi-label classification. We survey methods that underly geometric relational embeddings and categorize them based on (i) the embedding geometries that are used to represent the data; and (ii) the relational reasoning tasks that they aim to improve. We identify the desired properties (i.e., inductive biases) of each kind of embedding and discuss some potential future work.
NervePool: A Simplicial Pooling Layer
May 10, 2023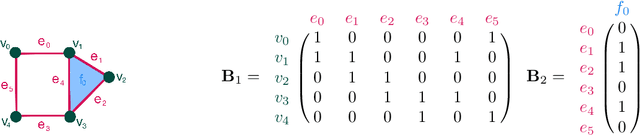


For deep learning problems on graph-structured data, pooling layers are important for down sampling, reducing computational cost, and to minimize overfitting. We define a pooling layer, NervePool, for data structured as simplicial complexes, which are generalizations of graphs that include higher-dimensional simplices beyond vertices and edges; this structure allows for greater flexibility in modeling higher-order relationships. The proposed simplicial coarsening scheme is built upon partitions of vertices, which allow us to generate hierarchical representations of simplicial complexes, collapsing information in a learned fashion. NervePool builds on the learned vertex cluster assignments and extends to coarsening of higher dimensional simplices in a deterministic fashion. While in practice, the pooling operations are computed via a series of matrix operations, the topological motivation is a set-theoretic construction based on unions of stars of simplices and the nerve complex
On the Hidden Mystery of OCR in Large Multimodal Models
May 13, 2023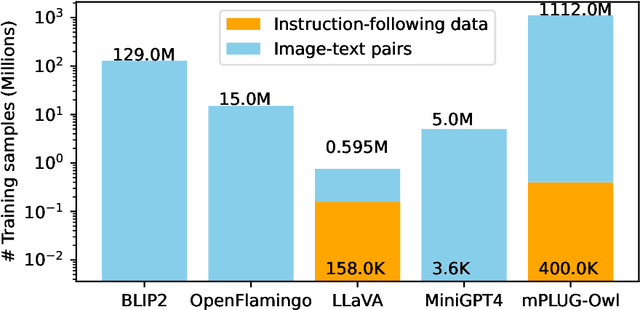
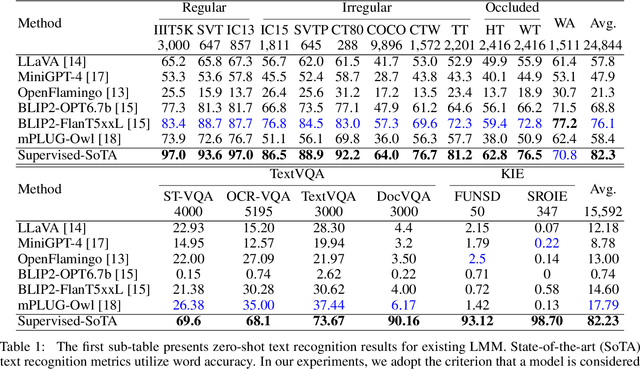
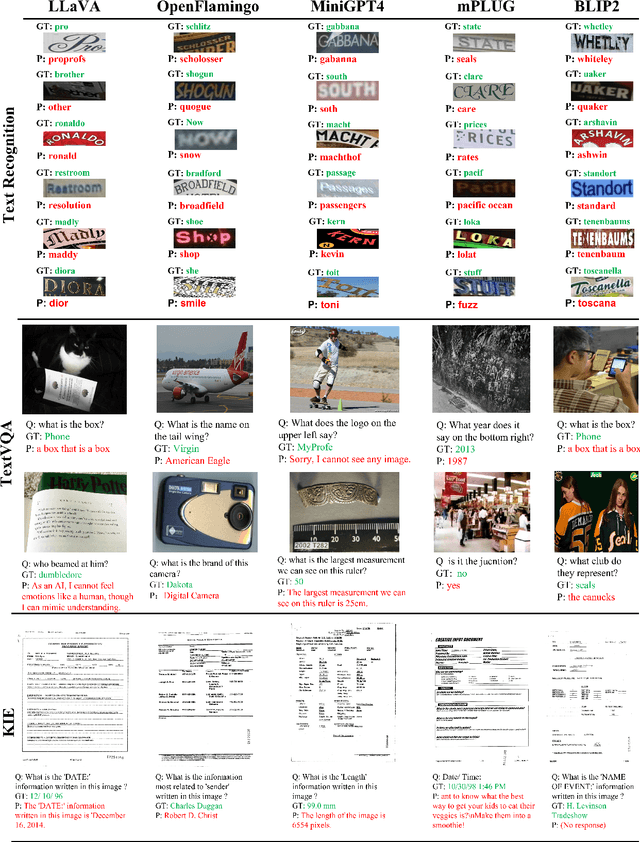
Large models have recently played a dominant role in natural language processing and multimodal vision-language learning. It remains less explored about their efficacy in text-related visual tasks. We conducted a comprehensive study of existing publicly available multimodal models, evaluating their performance in text recognition, text-based visual question answering, and key information extraction. Our findings reveal strengths and weaknesses in these models, which primarily rely on semantic understanding for word recognition and exhibit inferior perception of individual character shapes. They also display indifference towards text length and have limited capabilities in detecting fine-grained features in images. Consequently, these results demonstrate that even the current most powerful large multimodal models cannot match domain-specific methods in traditional text tasks and face greater challenges in more complex tasks. Most importantly, the baseline results showcased in this study could provide a foundational framework for the conception and assessment of innovative strategies targeted at enhancing zero-shot multimodal techniques. Evaluation pipeline will be available at https://github.com/Yuliang-Liu/MultimodalOCR.
Urban GeoBIM construction by integrating semantic LiDAR point clouds with as-designed BIM models
Apr 23, 2023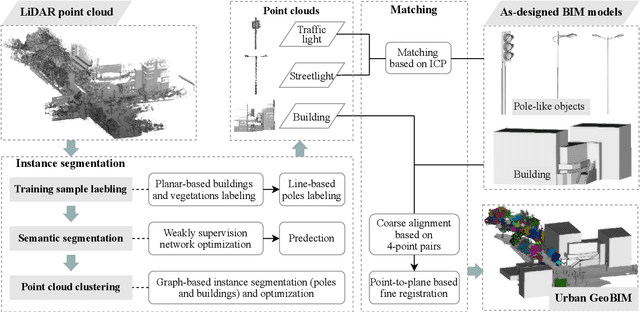



Developments in three-dimensional real worlds promote the integration of geoinformation and building information models (BIM) known as GeoBIM in urban construction. Light detection and ranging (LiDAR) integrated with global navigation satellite systems can provide geo-referenced spatial information. However, constructing detailed urban GeoBIM poses challenges in terms of LiDAR data quality. BIM models designed from software are rich in geometrical information but often lack accurate geo-referenced locations. In this paper, we propose a complementary strategy that integrates LiDAR point clouds with as-designed BIM models for reconstructing urban scenes. A state-of-the-art deep learning framework and graph theory are first combined for LiDAR point cloud segmentation. A coarse-to-fine matching program is then developed to integrate object point clouds with corresponding BIM models. Results show the overall segmentation accuracy of LiDAR datasets reaches up to 90%, and average positioning accuracies of BIM models are 0.023 m for pole-like objects and 0.156 m for buildings, demonstrating the effectiveness of the method in segmentation and matching processes. This work offers a practical solution for rapid and accurate urban GeoBIM construction.
On Narrative Information and the Distillation of Stories
Nov 22, 2022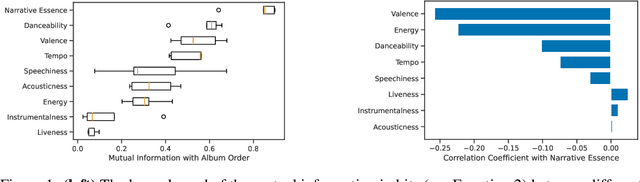
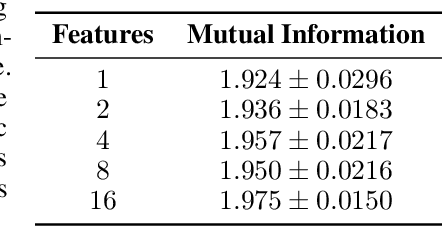
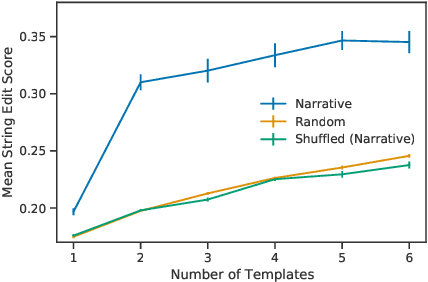
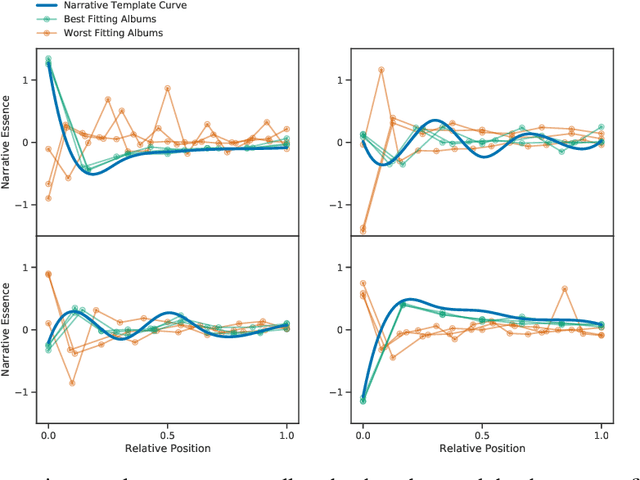
The act of telling stories is a fundamental part of what it means to be human. This work introduces the concept of narrative information, which we define to be the overlap in information space between a story and the items that compose the story. Using contrastive learning methods, we show how modern artificial neural networks can be leveraged to distill stories and extract a representation of the narrative information. We then demonstrate how evolutionary algorithms can leverage this to extract a set of narrative templates and how these templates -- in tandem with a novel curve-fitting algorithm we introduce -- can reorder music albums to automatically induce stories in them. In the process of doing so, we give strong statistical evidence that these narrative information templates are present in existing albums. While we experiment only with music albums here, the premises of our work extend to any form of (largely) independent media.