 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-duplicated Characterization of Graph Structures using Information Gain Ratio for Graph Neural Networks
Dec 27, 2022
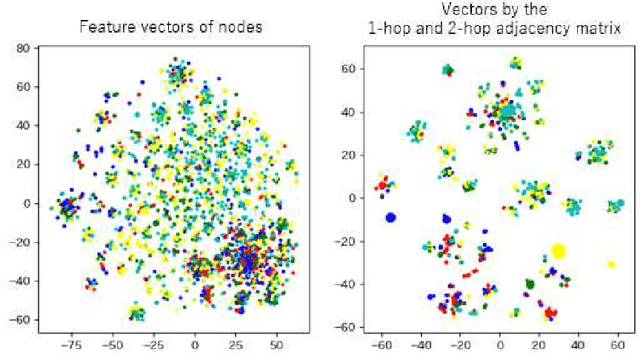
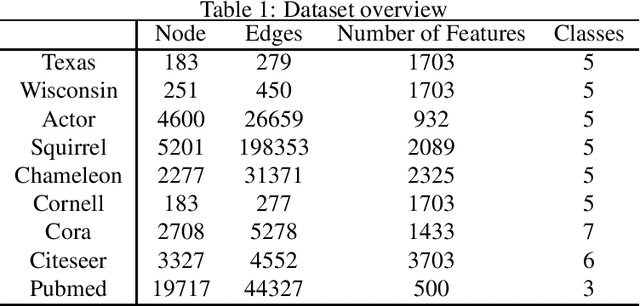
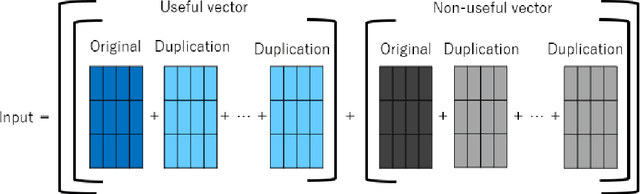
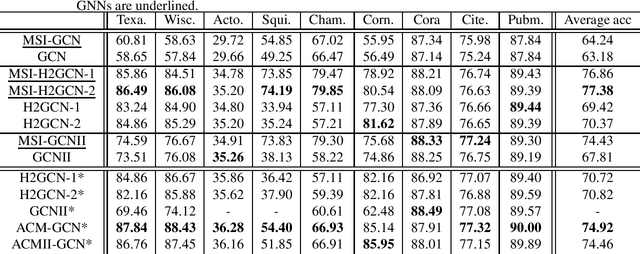
Various graph neural networks (GNNs) have been proposed to solve node classification tasks in machine learning for graph data. GNNs use the structural information of graph data by aggregating the features of neighboring nodes. However, they fail to directly characterize and leverage the structural information. In this paper, we propose multi-duplicated characterization of graph structures using information gain ratio (IGR) for GNNs (MSI-GNN), which enhances the performance of node classification by using an i-hop adjacency matrix as the structural information of the graph data. In MSI-GNN, the i-hop adjacency matrix is adaptively adjusted by two methods: (i) structural features in the matrix are selected based on the IGR, and (ii) the selected features in (i) for each node are duplicated and combined flexibly. In an experiment, we show that our MSI-GNN outperforms GCN, H2GCN, and GCNII in terms of average accuracies in benchmark graph datasets.
CVRecon: Rethinking 3D Geometric Feature Learning For Neural Reconstruction
Apr 28, 2023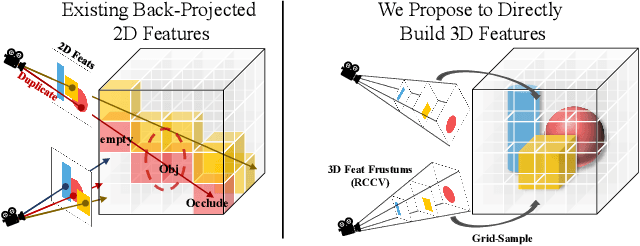
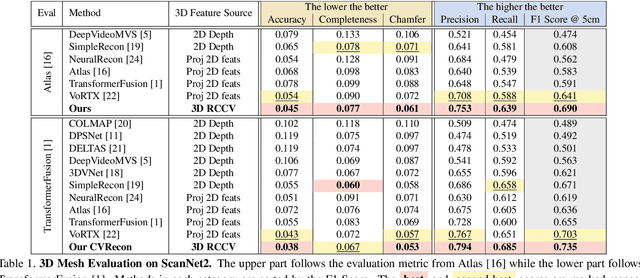
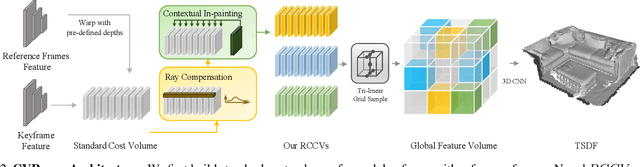
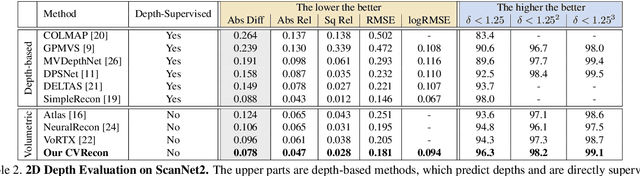
Recent advances in neural reconstruction using posed image sequences have made remarkable progress. However, due to the lack of depth information, existing volumetric-based techniques simply duplicate 2D image features of the object surface along the entire camera ray. We contend this duplication introduces noise in empty and occluded spaces, posing challenges for producing high-quality 3D geometry. Drawing inspiration from traditional multi-view stereo methods, we propose an end-to-end 3D neural reconstruction framework CVRecon, designed to exploit the rich geometric embedding in the cost volumes to facilitate 3D geometric feature learning. Furthermore, we present Ray-contextual Compensated Cost Volume (RCCV), a novel 3D geometric feature representation that encodes view-dependent information with improved integrity and robustness. Through comprehensive experiments, we demonstrate that our approach significantly improves the reconstruction quality in various metrics and recovers clear fine details of the 3D geometries. Our extensive ablation studies provide insights into the development of effective 3D geometric feature learning schemes. Project page: https://cvrecon.ziyue.cool/
Click-Feedback Retrieval
Apr 28, 2023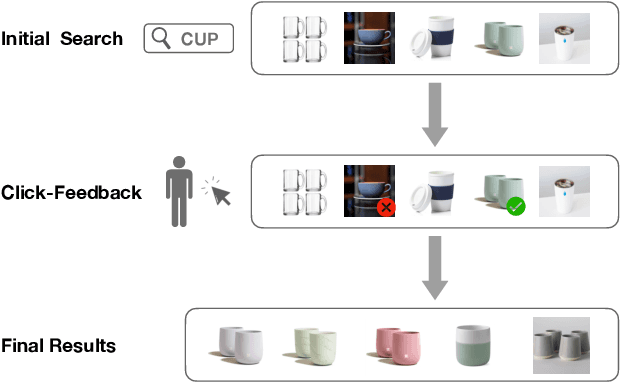
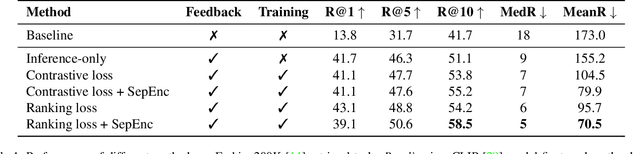
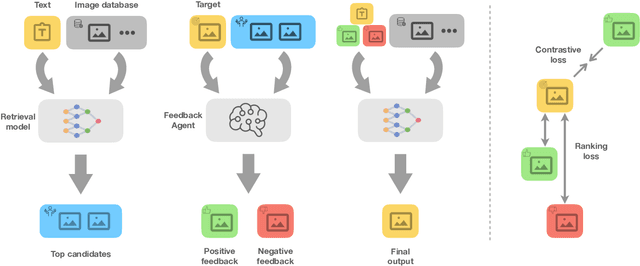
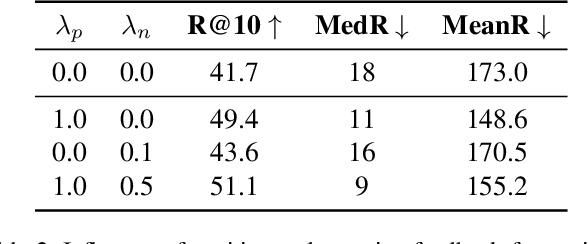
Retrieving target information based on input query is of fundamental importance in many real-world applications. In practice, it is not uncommon for the initial search to fail, where additional feedback information is needed to guide the searching process. In this work, we study a setting where the feedback is provided through users clicking liked and disliked searching results. We believe this form of feedback is of great practical interests for its convenience and efficiency. To facilitate future work in this direction, we construct a new benchmark termed click-feedback retrieval based on a large-scale dataset in fashion domain. We demonstrate that incorporating click-feedback can drastically improve the retrieval performance, which validates the value of the proposed setting. We also introduce several methods to utilize click-feedback during training, and show that click-feedback-guided training can significantly enhance the retrieval quality. We hope further exploration in this direction can bring new insights on building more efficient and user-friendly search engines.
Geometric Relational Embeddings: A Survey
Apr 24, 2023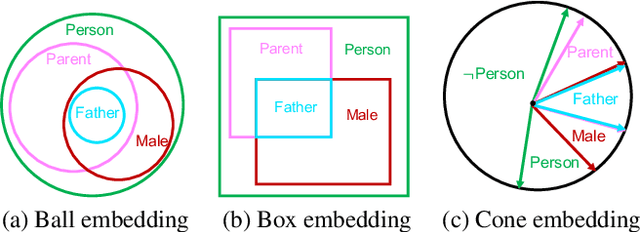
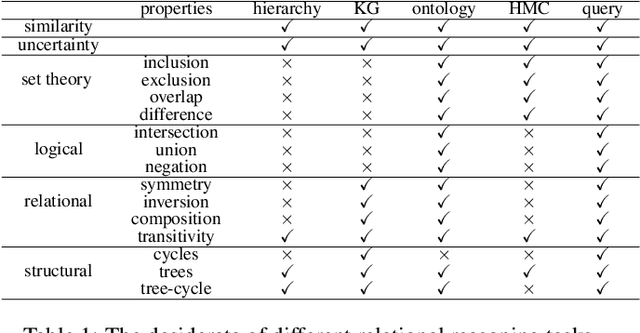
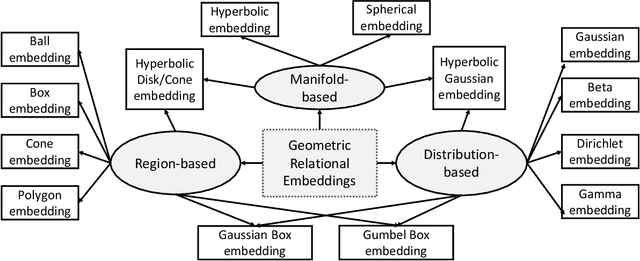
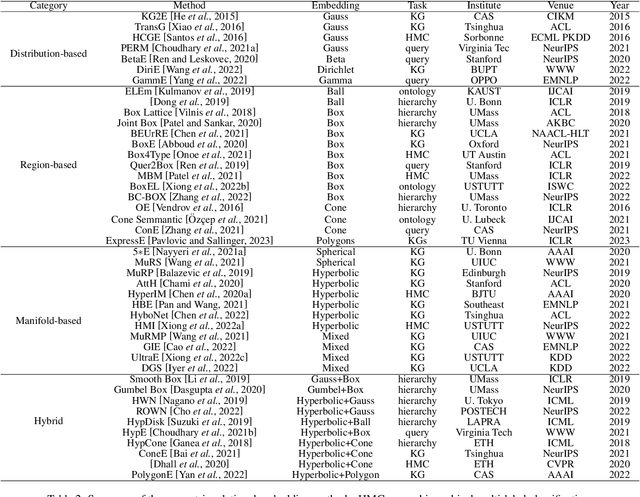
Geometric relational embeddings map relational data as geometric objects that combine vector information suitable for machine learning and structured/relational information for structured/relational reasoning, typically in low dimensions. Their preservation of relational structures and their appealing properties and interpretability have led to their uptake for tasks such as knowledge graph completion, ontology and hierarchy reasoning, logical query answering, and hierarchical multi-label classification. We survey methods that underly geometric relational embeddings and categorize them based on (i) the embedding geometries that are used to represent the data; and (ii) the relational reasoning tasks that they aim to improve. We identify the desired properties (i.e., inductive biases) of each kind of embedding and discuss some potential future work.
Urban GeoBIM construction by integrating semantic LiDAR point clouds with as-designed BIM models
Apr 23, 2023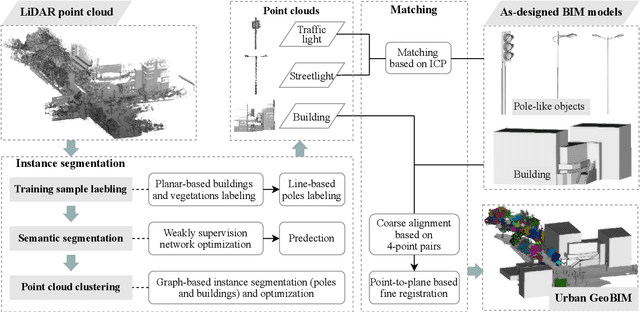



Developments in three-dimensional real worlds promote the integration of geoinformation and building information models (BIM) known as GeoBIM in urban construction. Light detection and ranging (LiDAR) integrated with global navigation satellite systems can provide geo-referenced spatial information. However, constructing detailed urban GeoBIM poses challenges in terms of LiDAR data quality. BIM models designed from software are rich in geometrical information but often lack accurate geo-referenced locations. In this paper, we propose a complementary strategy that integrates LiDAR point clouds with as-designed BIM models for reconstructing urban scenes. A state-of-the-art deep learning framework and graph theory are first combined for LiDAR point cloud segmentation. A coarse-to-fine matching program is then developed to integrate object point clouds with corresponding BIM models. Results show the overall segmentation accuracy of LiDAR datasets reaches up to 90%, and average positioning accuracies of BIM models are 0.023 m for pole-like objects and 0.156 m for buildings, demonstrating the effectiveness of the method in segmentation and matching processes. This work offers a practical solution for rapid and accurate urban GeoBIM construction.
A Conditional Denoising Diffusion Probabilistic Model for Radio Interferometric Image Reconstruction
May 16, 2023
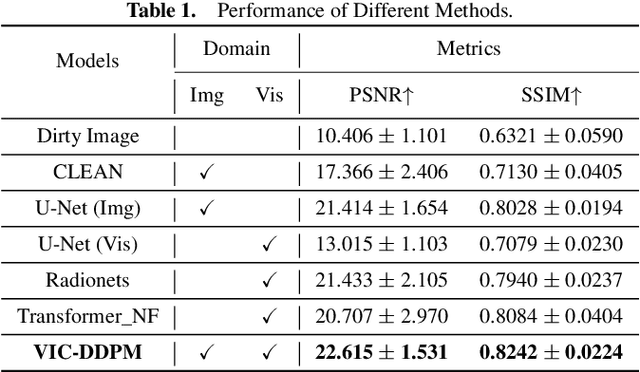
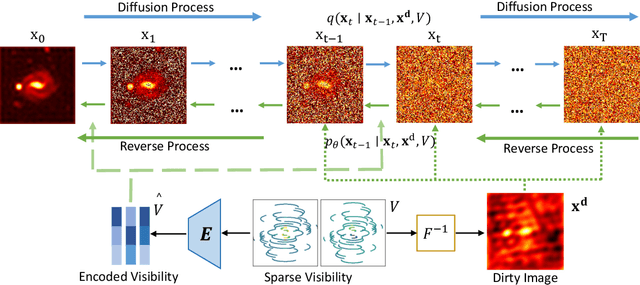
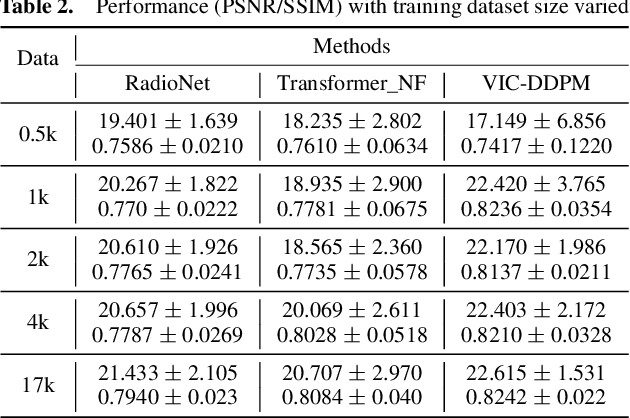
In radio astronomy, signals from radio telescopes are transformed into images of observed celestial objects, or sources. However, these images, called dirty images, contain real sources as well as artifacts due to signal sparsity and other factors. Therefore, radio interferometric image reconstruction is performed on dirty images, aiming to produce clean images in which artifacts are reduced and real sources are recovered. So far, existing methods have limited success on recovering faint sources, preserving detailed structures, and eliminating artifacts. In this paper, we present VIC-DDPM, a Visibility and Image Conditioned Denoising Diffusion Probabilistic Model. Our main idea is to use both the original visibility data in the spectral domain and dirty images in the spatial domain to guide the image generation process with DDPM. This way, we can leverage DDPM to generate fine details and eliminate noise, while utilizing visibility data to separate signals from noise and retaining spatial information in dirty images. We have conducted experiments in comparison with both traditional methods and recent deep learning based approaches. Our results show that our method significantly improves the resulting images by reducing artifacts, preserving fine details, and recovering dim sources. This advancement further facilitates radio astronomical data analysis tasks on celestial phenomena.
Outage Performance and Novel Loss Function for an ML-Assisted Resource Allocation: An Exact Analytical Framework
May 16, 2023
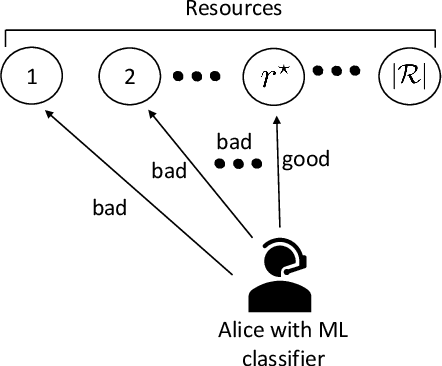
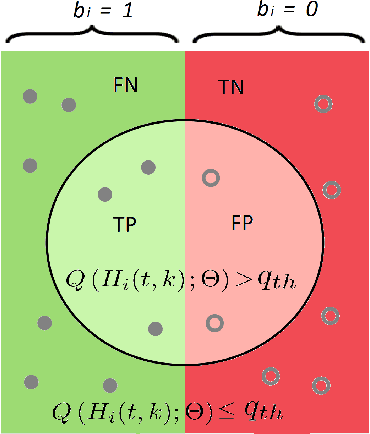
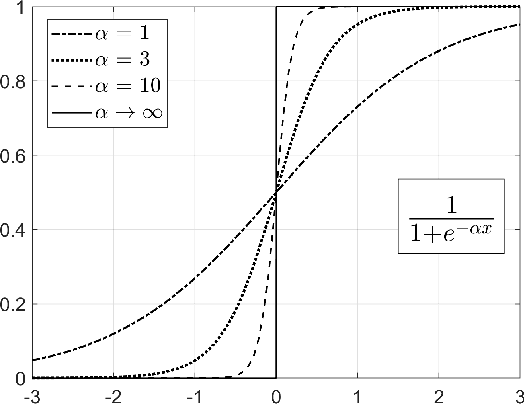
Machine Learning (ML) is a popular tool that will be pivotal in enabling 6G and beyond communications. This paper focuses on applying ML solutions to address outage probability issues commonly encountered in these systems. In particular, we consider a single-user multi-resource greedy allocation strategy, where an ML binary classification predictor assists in seizing an adequate resource. With no access to future channel state information, this predictor foresees each resource's likely future outage status. When the predictor encounters a resource it believes will be satisfactory, it allocates it to the user. Critically, the goal of the predictor is to ensure that a user avoids an unsatisfactory resource since this is likely to cause an outage. Our main result establishes exact and asymptotic expressions for this system's outage probability. With this, we formulate a theoretically optimal, differentiable loss function to train our predictor. We then compare predictors trained using this and traditional loss functions; namely, binary cross-entropy (BCE), mean squared error (MSE), and mean absolute error (MAE). Predictors trained using our novel loss function provide superior outage probability in all scenarios. Our loss function sometimes outperforms predictors trained with the BCE, MAE, and MSE loss functions by multiple orders of magnitude.
Component Training of Turbo Autoencoders
May 16, 2023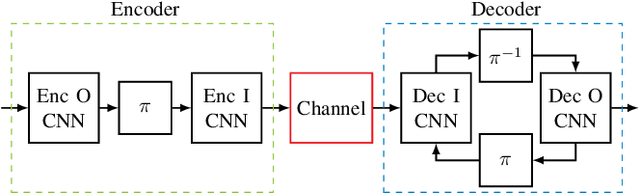
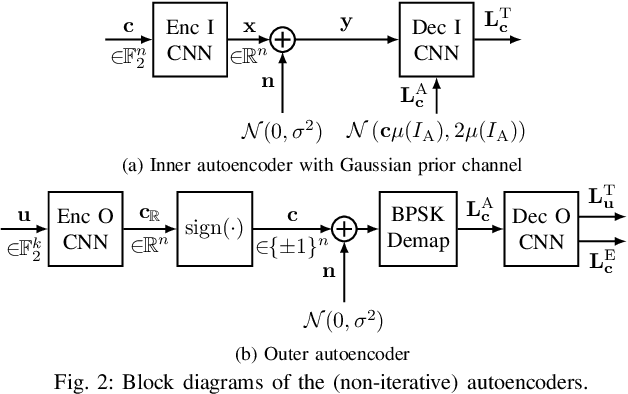
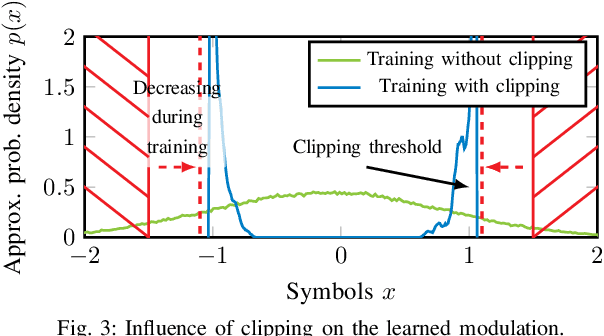
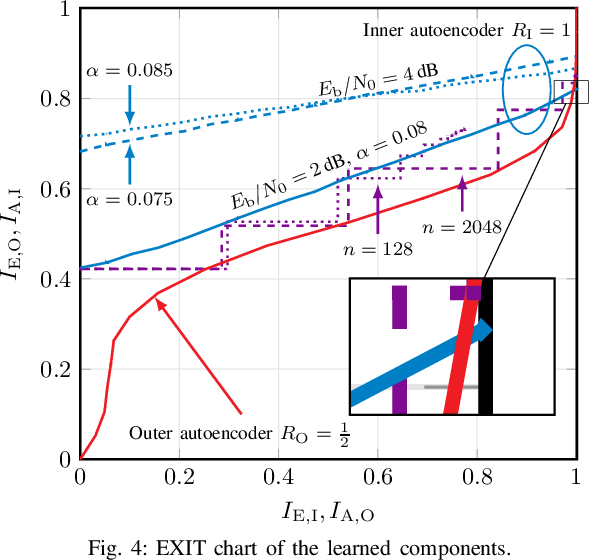
Isolated training with Gaussian priors (TGP) of the component autoencoders of turbo-autoencoder architectures enables faster, more consistent training and better generalization to arbitrary decoding iterations than training based on deep unfolding. We propose fitting the components via extrinsic information transfer (EXIT) charts to a desired behavior which enables scaling to larger message lengths ($k \approx 1000$) while retaining competitive performance. To the best of our knowledge, this is the first autoencoder that performs close to classical codes in this regime. Although the binary cross-entropy (BCE) loss function optimizes the bit error rate (BER) of the components, the design via EXIT charts enables to focus on the block error rate (BLER). In serially concatenated systems the component-wise TGP approach is well known for inner components with a fixed outer binary interface, e.g., a learned inner code or equalizer, with an outer binary error correcting code. In this paper we extend the component training to structures with an inner and outer autoencoder, where we propose a new 1-bit quantization strategy for the encoder outputs based on the underlying communication problem. Finally, we discuss the model complexity of the learned components during design time (training) and inference and show that the number of weights in the encoder can be reduced by 99.96 %.
KEPLET: Knowledge-Enhanced Pretrained Language Model with Topic Entity Awareness
May 02, 2023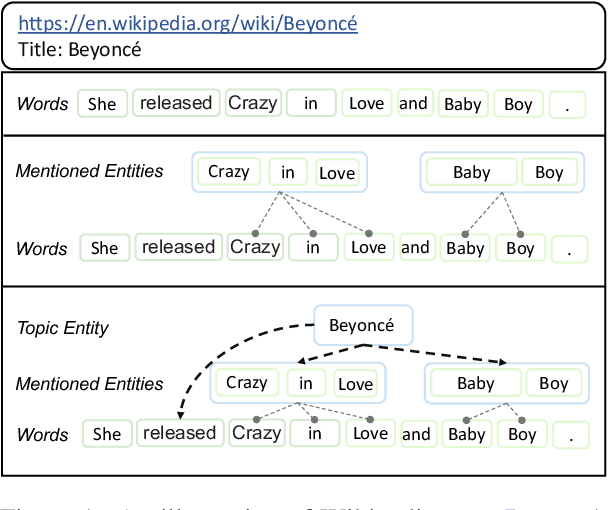
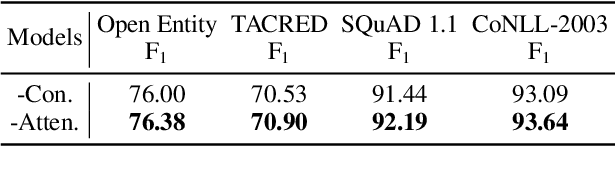
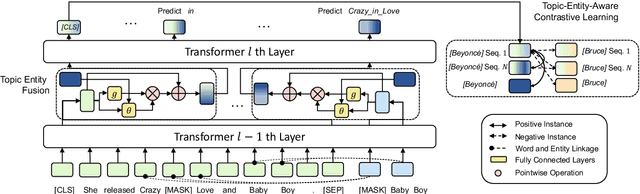
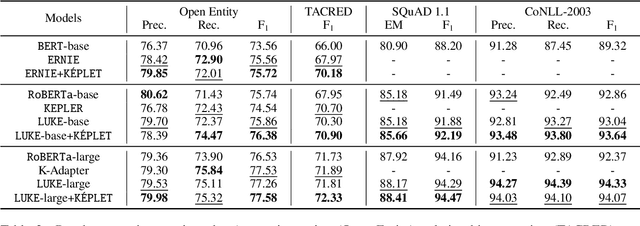
In recent years, Pre-trained Language Models (PLMs) have shown their superiority by pre-training on unstructured text corpus and then fine-tuning on downstream tasks. On entity-rich textual resources like Wikipedia, Knowledge-Enhanced PLMs (KEPLMs) incorporate the interactions between tokens and mentioned entities in pre-training, and are thus more effective on entity-centric tasks such as entity linking and relation classification. Although exploiting Wikipedia's rich structures to some extent, conventional KEPLMs still neglect a unique layout of the corpus where each Wikipedia page is around a topic entity (identified by the page URL and shown in the page title). In this paper, we demonstrate that KEPLMs without incorporating the topic entities will lead to insufficient entity interaction and biased (relation) word semantics. We thus propose KEPLET, a novel Knowledge-Enhanced Pre-trained LanguagE model with Topic entity awareness. In an end-to-end manner, KEPLET identifies where to add the topic entity's information in a Wikipedia sentence, fuses such information into token and mentioned entities representations, and supervises the network learning, through which it takes topic entities back into consideration. Experiments demonstrated the generality and superiority of KEPLET which was applied to two representative KEPLMs, achieving significant improvements on four entity-centric tasks.
CNN-based Dendrite Core Detection from Microscopic Images of Directionally Solidified Ni-base Alloys
May 21, 2023

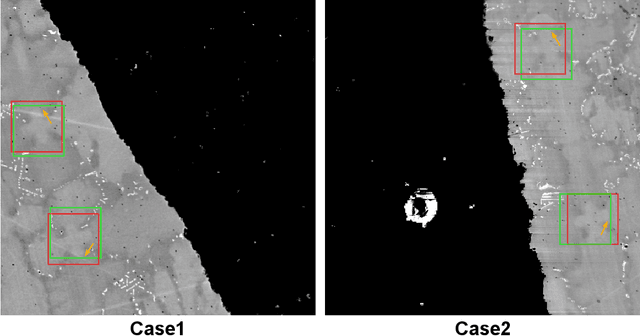
Dendrite core is the center point of the dendrite. The information of dendrite core is very helpful for material scientists to analyze the properties of materials. Therefore, detecting the dendrite core is a very important task in the material science field. Meanwhile, because of some special properties of the dendrites, this task is also very challenging. Different from the typical detection problems in the computer vision field, detecting the dendrite core aims to detect a single point location instead of the bounding-box. As a result, the existing regressing bounding-box based detection methods can not work well on this task because the calculated center point location based on the upper-left and lower-right corners of the bounding-box is usually not precise. In this work, we formulate the dendrite core detection problem as a segmentation task and proposed a novel detection method to detect the dendrite core directly. Our whole pipeline contains three steps: Easy Sample Detection (ESD), Hard Sample Detection(HSD), and Hard Sample Refinement (HSR). Specifically, ESD and HSD focus on the easy samples and hard samples of dendrite cores respectively. Both of them employ the same Central Point Detection Network (CPDN) but do not share parameters. To make HSD only focus on the feature of hard samples of dendrite cores, we destroy the structure of the easy samples of dendrites which are detected by ESD and force HSD to learn the feature of hard samples. HSR is a binary classifier which is used to filter out the false positive prediction of HSD. We evaluate our method on the dendrite dataset. Our method outperforms the state-of-the-art baselines on three metrics, i.e., Recall, Precision, and F-score.