 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the Generalization Error of Meta Learning for the Gibbs Algorithm
Apr 27, 2023
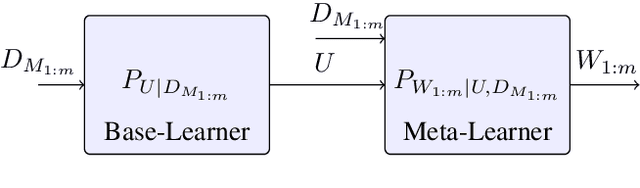
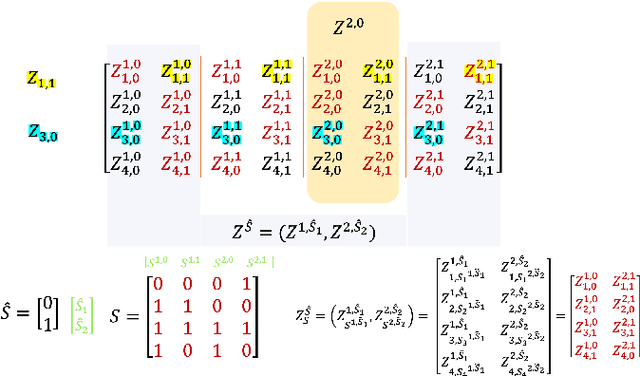
We analyze the generalization ability of joint-training meta learning algorithms via the Gibbs algorithm. Our exact characterization of the expected meta generalization error for the meta Gibbs algorithm is based on symmetrized KL information, which measures the dependence between all meta-training datasets and the output parameters, including task-specific and meta parameters. Additionally, we derive an exact characterization of the meta generalization error for the super-task Gibbs algorithm, in terms of conditional symmetrized KL information within the super-sample and super-task framework introduced in Steinke and Zakynthinou (2020) and Hellstrom and Durisi (2022) respectively. Our results also enable us to provide novel distribution-free generalization error upper bounds for these Gibbs algorithms applicable to meta learning.
Universal Domain Adaptation via Compressive Attention Matching
Apr 24, 2023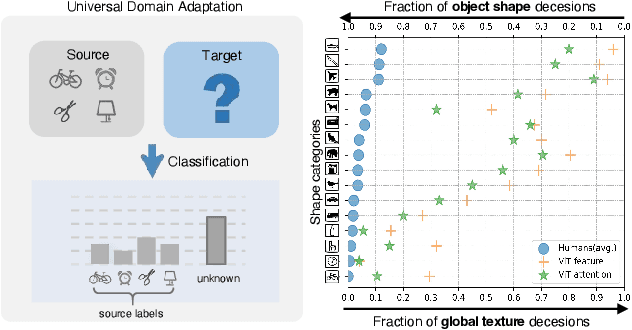
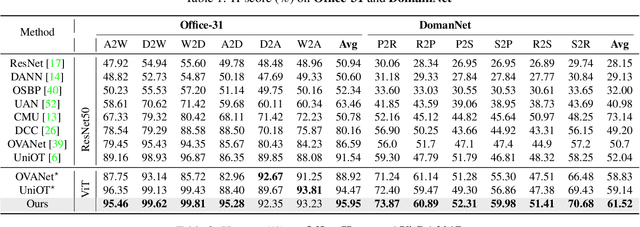

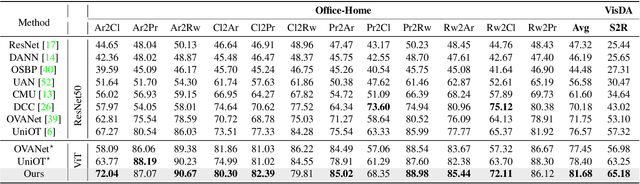
Universal domain adaptation (UniDA) aims to transfer knowledge from the source domain to the target domain without any prior knowledge about the label set. The challenge lies in how to determine whether the target samples belong to common categories. The mainstream methods make judgments based on the sample features, which overemphasizes global information while ignoring the most crucial local objects in the image, resulting in limited accuracy. To address this issue, we propose a Universal Attention Matching (UniAM) framework by exploiting the self-attention mechanism in vision transformer to capture the crucial object information. The proposed framework introduces a novel Compressive Attention Matching (CAM) approach to explore the core information by compressively representing attentions. Furthermore, CAM incorporates a residual-based measurement to determine the sample commonness. By utilizing the measurement, UniAM achieves domain-wise and category-wise Common Feature Alignment (CFA) and Target Class Separation (TCS). Notably, UniAM is the first method utilizing the attention in vision transformer directly to perform classification tasks. Extensive experiments show that UniAM outperforms the current state-of-the-art methods on various benchmark datasets.
Secret-Key-Agreement Advantage Distillation With Quantization Correction
Apr 20, 2023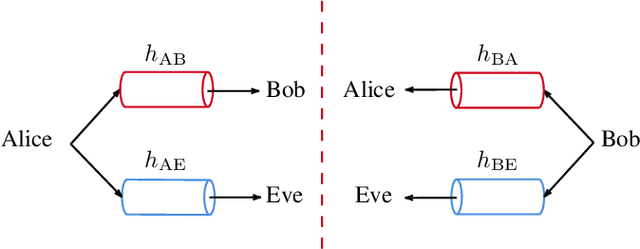
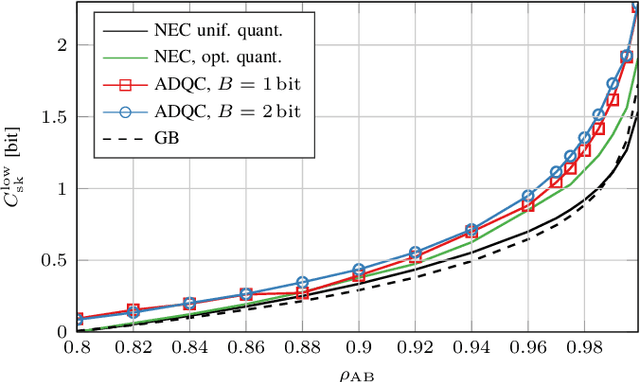
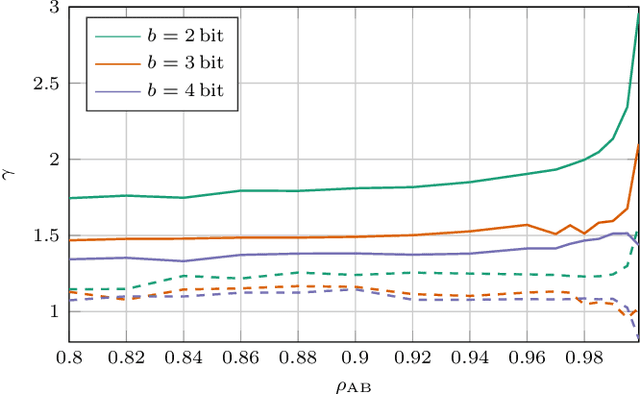

We propose a novel advantage distillation strategy for physical layer-based secret-key-agreement (SKA). We consider a scenario where Alice and Bob aim at extracting a common bit sequence, which should remain secret to Eve, by quantizing a random number obtained from measurements at their communication channel. We propose an asymmetric advantage distillation protocol with two novel features: i) Alice quantizes her measurement and sends partial information on it over an authenticated public side channel, and ii) Bob quantizes his measurement by exploiting the partial information. The partial information on the position of the measurement in the quantization interval and its sharing allows Bob to obtain a quantized value closer to that of Alice. Both strategies increase the lower bound of the secret key rate.
Aligning Instruction Tasks Unlocks Large Language Models as Zero-Shot Relation Extractors
May 18, 2023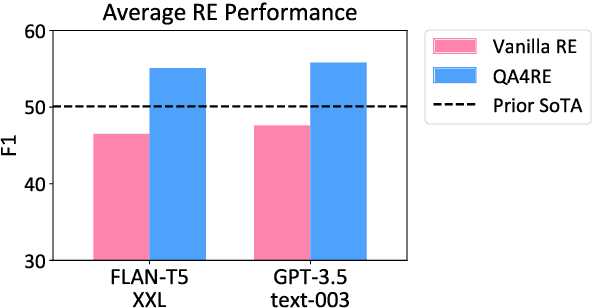
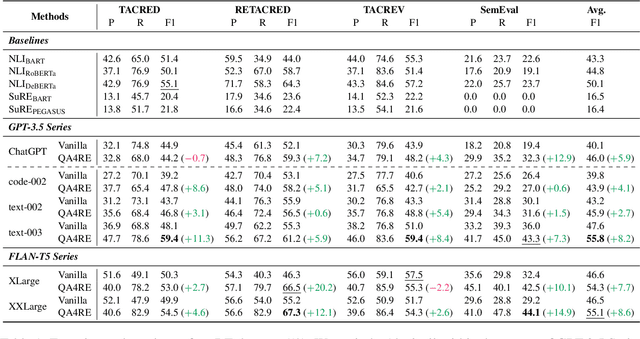

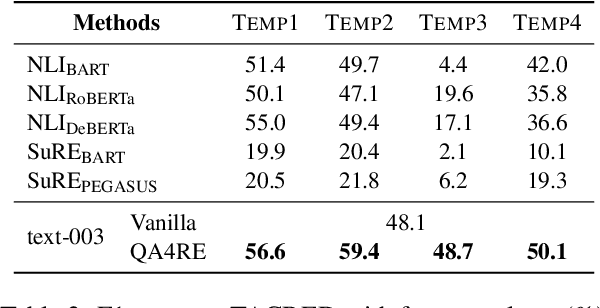
Recent work has shown that fine-tuning large language models (LLMs) on large-scale instruction-following datasets substantially improves their performance on a wide range of NLP tasks, especially in the zero-shot setting. However, even advanced instruction-tuned LLMs still fail to outperform small LMs on relation extraction (RE), a fundamental information extraction task. We hypothesize that instruction-tuning has been unable to elicit strong RE capabilities in LLMs due to RE's low incidence in instruction-tuning datasets, making up less than 1% of all tasks (Wang et al., 2022). To address this limitation, we propose QA4RE, a framework that aligns RE with question answering (QA), a predominant task in instruction-tuning datasets. Comprehensive zero-shot RE experiments over four datasets with two series of instruction-tuned LLMs (six LLMs in total) demonstrate that our QA4RE framework consistently improves LLM performance, strongly verifying our hypothesis and enabling LLMs to outperform strong zero-shot baselines by a large margin. Additionally, we provide thorough experiments and discussions to show the robustness, few-shot effectiveness, and strong transferability of our QA4RE framework. This work illustrates a promising way of adapting LLMs to challenging and underrepresented tasks by aligning these tasks with more common instruction-tuning tasks like QA.
Constrained Environment Optimization for Prioritized Multi-Agent Navigation
May 18, 2023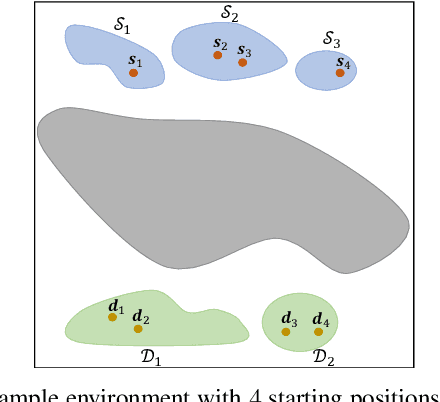
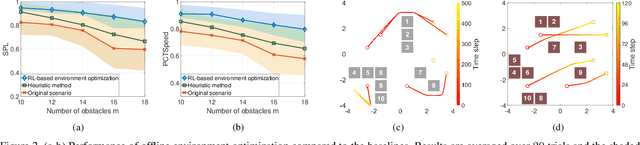
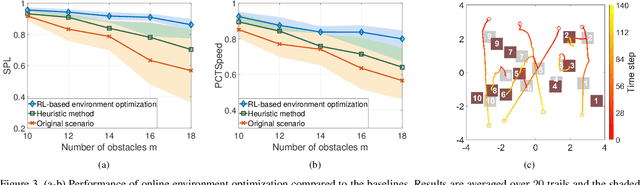
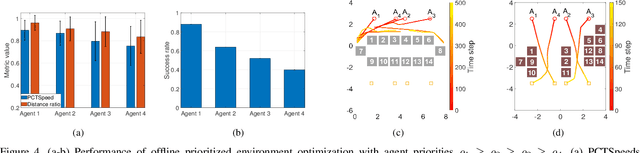
Traditional approaches to the design of multi-agent navigation algorithms consider the environment as a fixed constraint, despite the influence of spatial constraints on agents' performance. Yet hand-designing conducive environment layouts is inefficient and potentially expensive. The goal of this paper is to consider the environment as a decision variable in a system-level optimization problem, where both agent performance and environment cost are incorporated. Towards this end, we propose novel problems of unprioritized and prioritized environment optimization, where the former considers agents unbiasedly and the latter accounts for agent priorities. We show, through formal proofs, under which conditions the environment can change while guaranteeing completeness (i.e., all agents reach goals), and analyze the role of agent priorities in the environment optimization. We proceed to impose real-world constraints on the environment optimization and formulate it mathematically as a constrained stochastic optimization problem. Since the relation between agents, environment and performance is challenging to model, we leverage reinforcement learning to develop a model-free solution and a primal-dual mechanism to handle constraints. Distinct information processing architectures are integrated for various implementation scenarios, including online/offline optimization and discrete/continuous environment. Numerical results corroborate the theory and demonstrate the validity and adaptability of our approach.
PETAL: Physics Emulation Through Averaged Linearizations for Solving Inverse Problems
May 18, 2023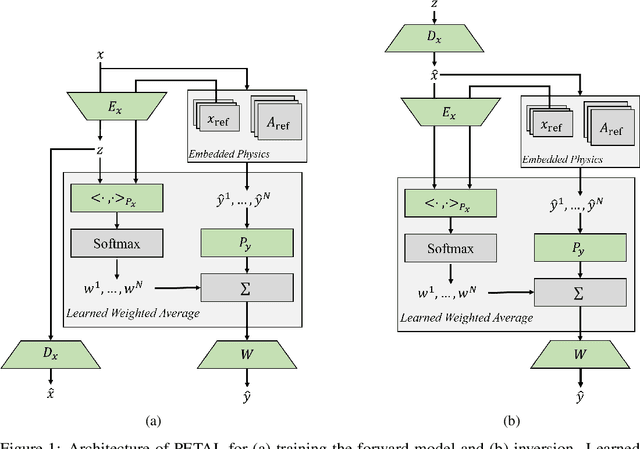
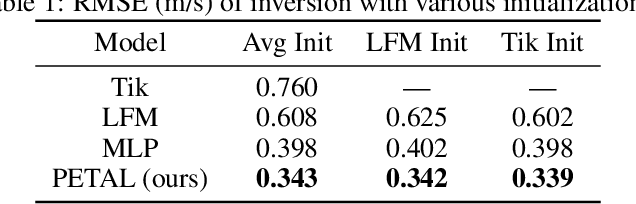
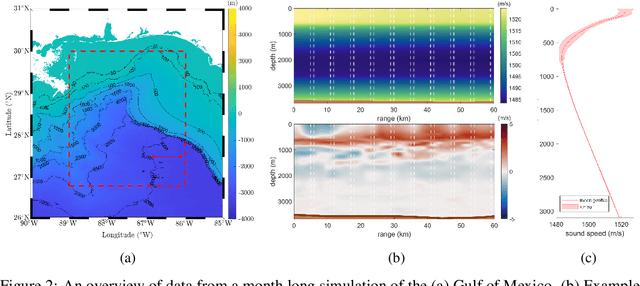

Inverse problems describe the task of recovering an underlying signal of interest given observables. Typically, the observables are related via some non-linear forward model applied to the underlying unknown signal. Inverting the non-linear forward model can be computationally expensive, as it often involves computing and inverting a linearization at a series of estimates. Rather than inverting the physics-based model, we instead train a surrogate forward model (emulator) and leverage modern auto-grad libraries to solve for the input within a classical optimization framework. Current methods to train emulators are done in a black box supervised machine learning fashion and fail to take advantage of any existing knowledge of the forward model. In this article, we propose a simple learned weighted average model that embeds linearizations of the forward model around various reference points into the model itself, explicitly incorporating known physics. Grounding the learned model with physics based linearizations improves the forward modeling accuracy and provides richer physics based gradient information during the inversion process leading to more accurate signal recovery. We demonstrate the efficacy on an ocean acoustic tomography (OAT) example that aims to recover ocean sound speed profile (SSP) variations from acoustic observations (e.g. eigenray arrival times) within simulation of ocean dynamics in the Gulf of Mexico.
A Lexical-aware Non-autoregressive Transformer-based ASR Model
May 18, 2023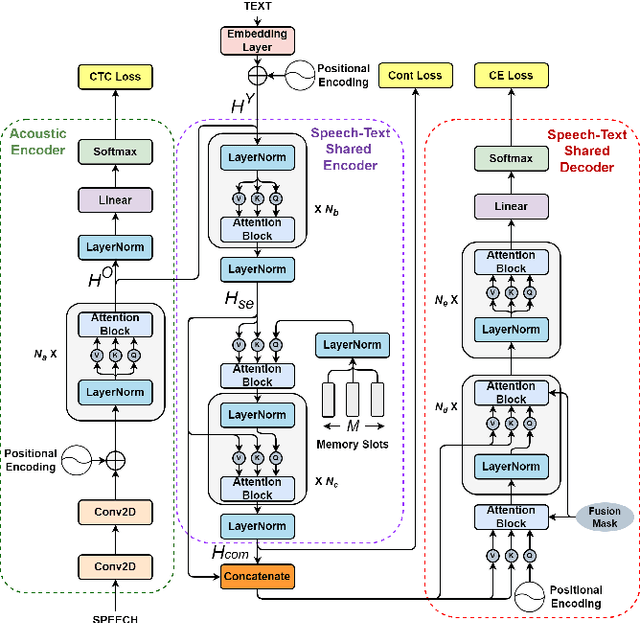
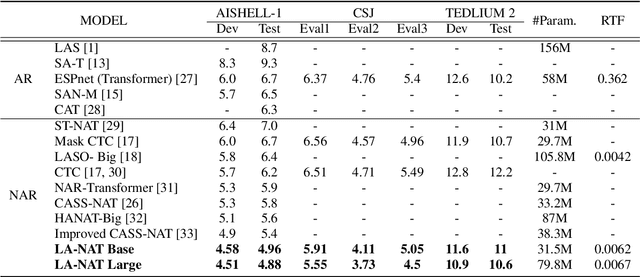
Non-autoregressive automatic speech recognition (ASR) has become a mainstream of ASR modeling because of its fast decoding speed and satisfactory result. To further boost the performance, relaxing the conditional independence assumption and cascading large-scaled pre-trained models are two active research directions. In addition to these strategies, we propose a lexical-aware non-autoregressive Transformer-based (LA-NAT) ASR framework, which consists of an acoustic encoder, a speech-text shared encoder, and a speech-text shared decoder. The acoustic encoder is used to process the input speech features as usual, and the speech-text shared encoder and decoder are designed to train speech and text data simultaneously. By doing so, LA-NAT aims to make the ASR model aware of lexical information, so the resulting model is expected to achieve better results by leveraging the learned linguistic knowledge. A series of experiments are conducted on the AISHELL-1, CSJ, and TEDLIUM 2 datasets. According to the experiments, the proposed LA-NAT can provide superior results than other recently proposed non-autoregressive ASR models. In addition, LA-NAT is a relatively compact model than most non-autoregressive ASR models, and it is about 58 times faster than the classic autoregressive model.
Rate-Adaptive Coding Mechanism for Semantic Communications With Multi-Modal Data
May 18, 2023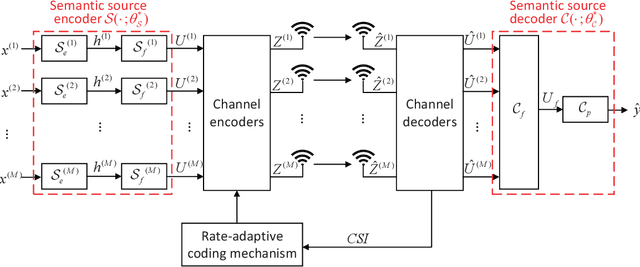
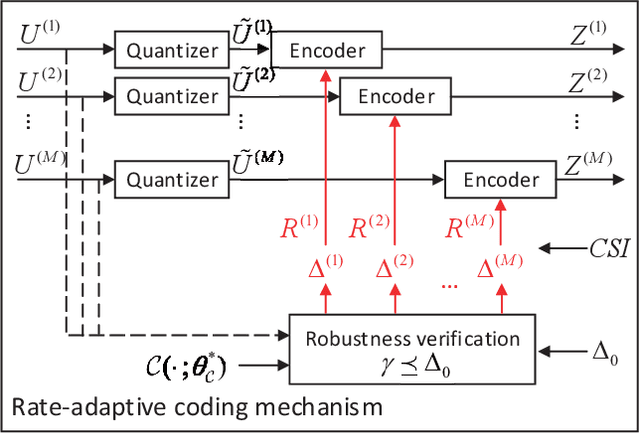
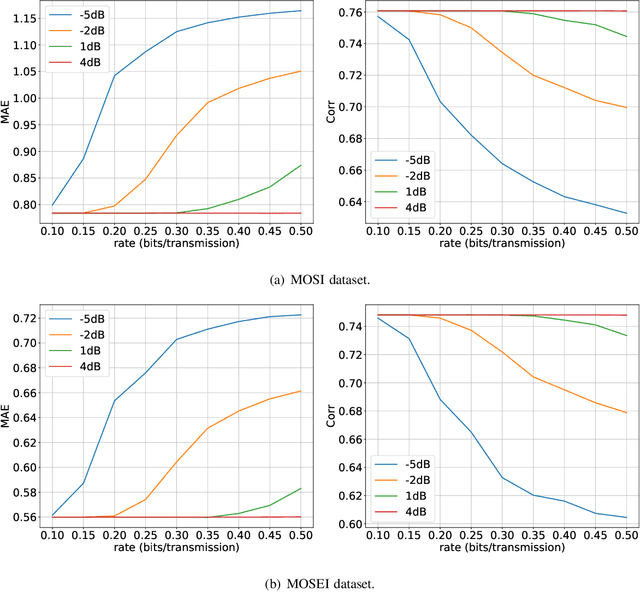
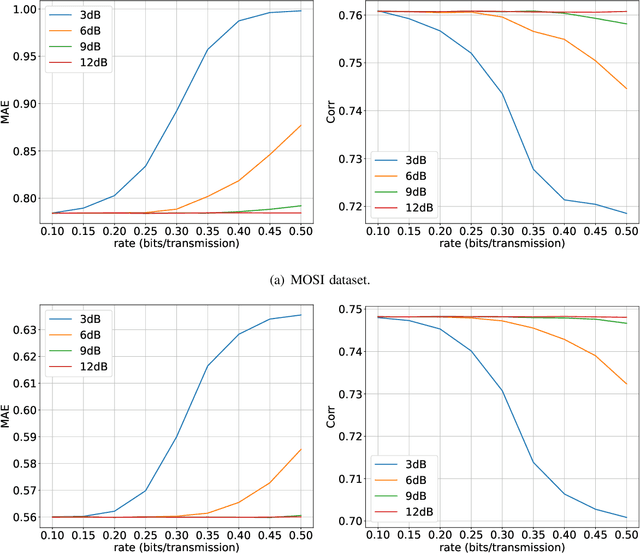
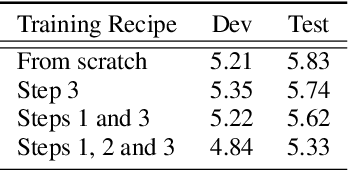
Recently, the ever-increasing demand for bandwidth in multi-modal communication systems requires a paradigm shift. Powered by deep learning, semantic communications are applied to multi-modal scenarios to boost communication efficiency and save communication resources. However, the existing end-to-end neural network (NN) based framework without the channel encoder/decoder is incompatible with modern digital communication systems. Moreover, most end-to-end designs are task-specific and require re-design and re-training for new tasks, which limits their applications. In this paper, we propose a distributed multi-modal semantic communication framework incorporating the conventional channel encoder/decoder. We adopt NN-based semantic encoder and decoder to extract correlated semantic information contained in different modalities, including speech, text, and image. Based on the proposed framework, we further establish a general rate-adaptive coding mechanism for various types of multi-modal semantic tasks. In particular, we utilize unequal error protection based on semantic importance, which is derived by evaluating the distortion bound of each modality. We further formulate and solve an optimization problem that aims at minimizing inference delay while maintaining inference accuracy for semantic tasks. Numerical results show that the proposed mechanism fares better than both conventional communication and existing semantic communication systems in terms of task performance, inference delay, and deployment complexity.
Learning Differentially Private Probabilistic Models for Privacy-Preserving Image Generation
May 18, 2023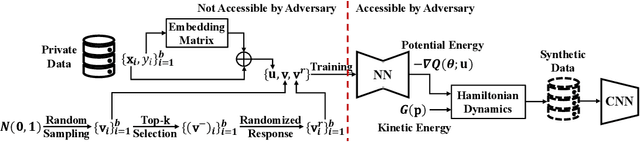
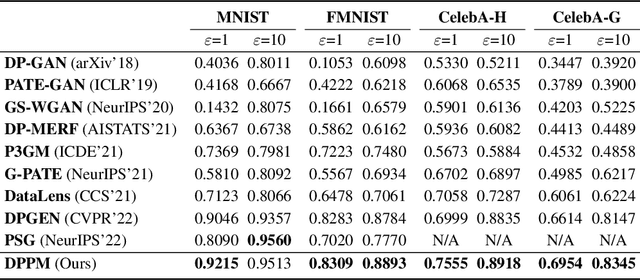
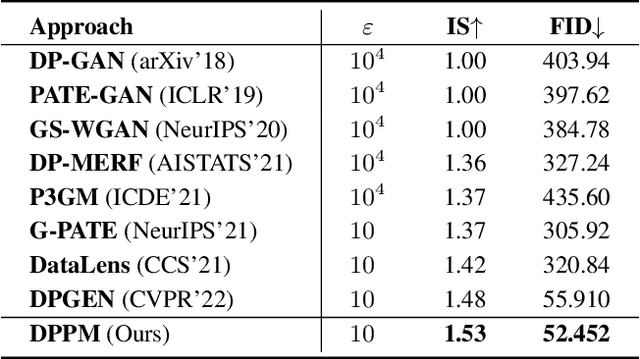

A number of deep models trained on high-quality and valuable images have been deployed in practical applications, which may pose a leakage risk of data privacy. Learning differentially private generative models can sidestep this challenge through indirect data access. However, such differentially private generative models learned by existing approaches can only generate images with a low-resolution of less than 128x128, hindering the widespread usage of generated images in downstream training. In this work, we propose learning differentially private probabilistic models (DPPM) to generate high-resolution images with differential privacy guarantee. In particular, we first train a model to fit the distribution of the training data and make it satisfy differential privacy by performing a randomized response mechanism during training process. Then we perform Hamiltonian dynamics sampling along with the differentially private movement direction predicted by the trained probabilistic model to obtain the privacy-preserving images. In this way, it is possible to apply these images to different downstream tasks while protecting private information. Notably, compared to other state-of-the-art differentially private generative approaches, our approach can generate images up to 256x256 with remarkable visual quality and data utility. Extensive experiments show the effectiveness of our approach.
QLoRA: Efficient Finetuning of Quantized LLMs
May 23, 2023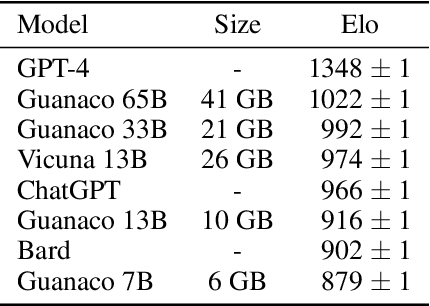
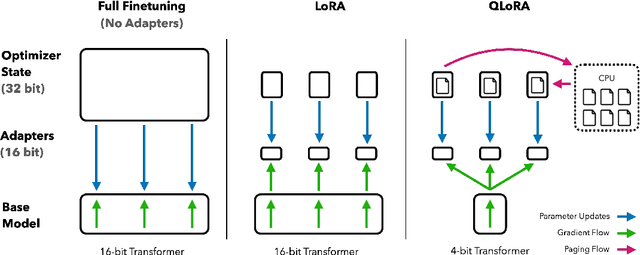
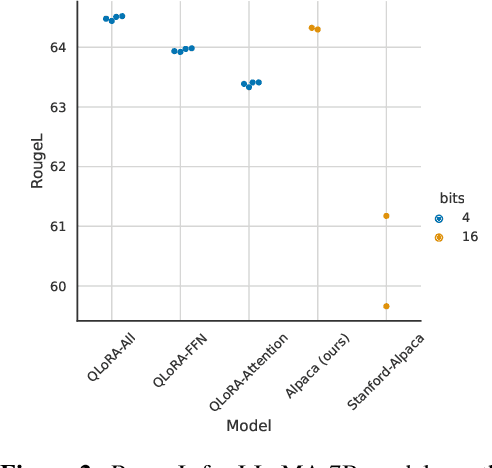
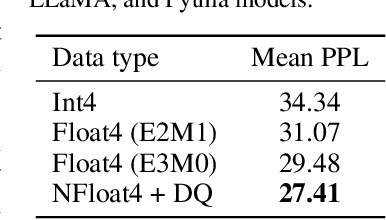
We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters~(LoRA). Our best model family, which we name Guanaco, outperforms all previous openly released models on the Vicuna benchmark, reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of finetuning on a single GPU. QLoRA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights (b) double quantization to reduce the average memory footprint by quantizing the quantization constants, and (c) paged optimziers to manage memory spikes. We use QLoRA to finetune more than 1,000 models, providing a detailed analysis of instruction following and chatbot performance across 8 instruction datasets, multiple model types (LLaMA, T5), and model scales that would be infeasible to run with regular finetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA finetuning on a small high-quality dataset leads to state-of-the-art results, even when using smaller models than the previous SoTA. We provide a detailed analysis of chatbot performance based on both human and GPT-4 evaluations showing that GPT-4 evaluations are a cheap and reasonable alternative to human evaluation. Furthermore, we find that current chatbot benchmarks are not trustworthy to accurately evaluate the performance levels of chatbots. A lemon-picked analysis demonstrates where Guanaco fails compared to ChatGPT. We release all of our models and code, including CUDA kernels for 4-bit training.