 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sentiment Analysis in the Era of Large Language Models: A Reality Check
May 24, 2023
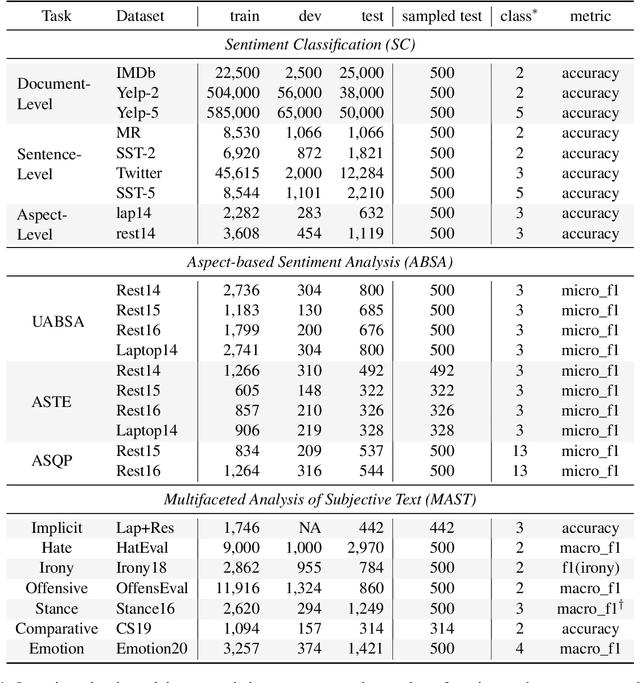
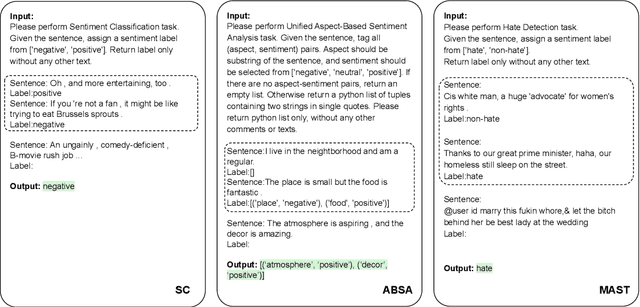
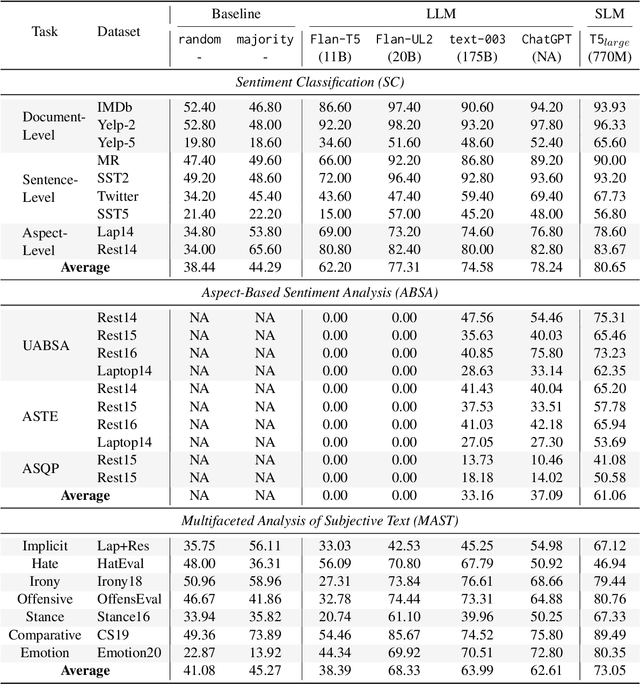
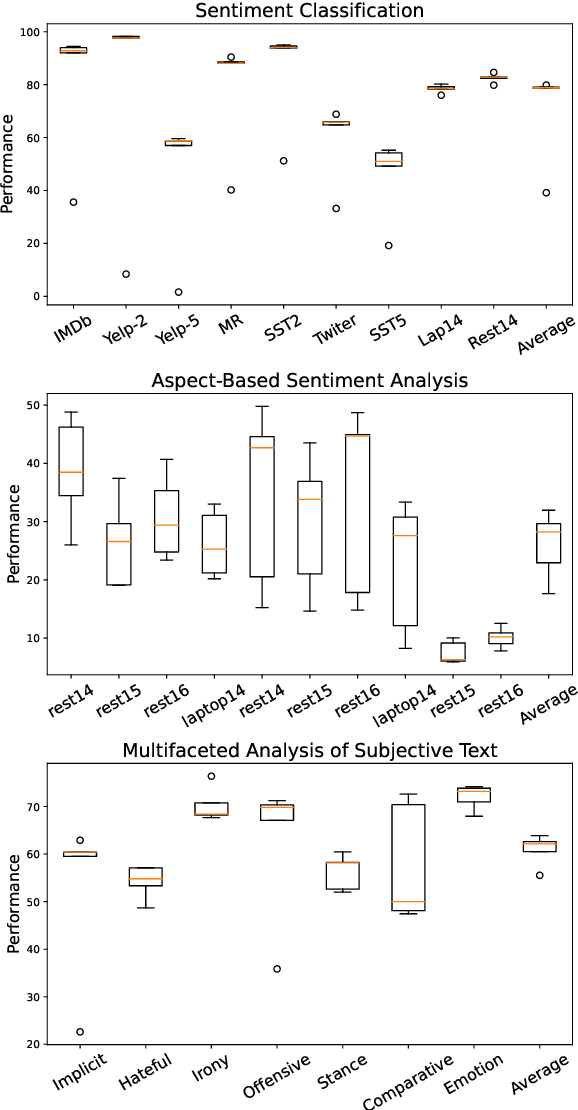
Sentiment analysis (SA) has been a long-standing research area in natural language processing. It can offer rich insights into human sentiments and opinions and has thus seen considerable interest from both academia and industry. With the advent of large language models (LLMs) such as ChatGPT, there is a great potential for their employment on SA problems. However, the extent to which existing LLMs can be leveraged for different sentiment analysis tasks remains unclear. This paper aims to provide a comprehensive investigation into the capabilities of LLMs in performing various sentiment analysis tasks, from conventional sentiment classification to aspect-based sentiment analysis and multifaceted analysis of subjective texts. We evaluate performance across 13 tasks on 26 datasets and compare the results against small language models (SLMs) trained on domain-specific datasets. Our study reveals that while LLMs demonstrate satisfactory performance in simpler tasks, they lag behind in more complex tasks requiring deeper understanding or structured sentiment information. However, LLMs significantly outperform SLMs in few-shot learning settings, suggesting their potential when annotation resources are limited. We also highlight the limitations of current evaluation practices in assessing LLMs' SA abilities and propose a novel benchmark, \textsc{SentiEval}, for a more comprehensive and realistic evaluation. Data and code during our investigations are available at \url{https://github.com/DAMO-NLP-SG/LLM-Sentiment}.
CSTS: Conditional Semantic Textual Similarity
May 24, 2023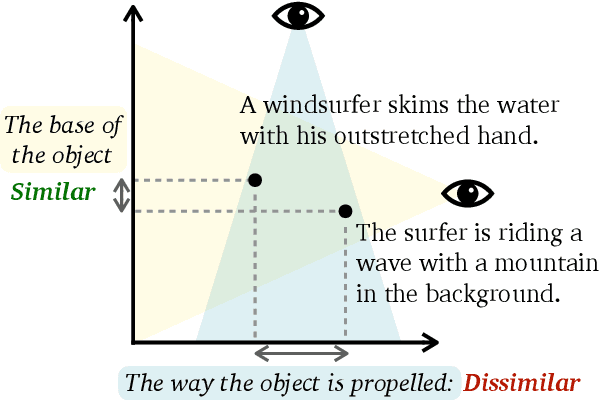
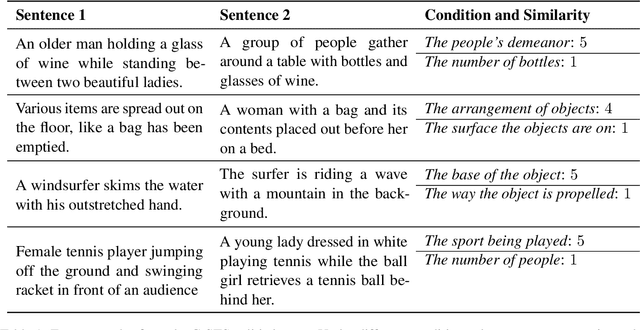
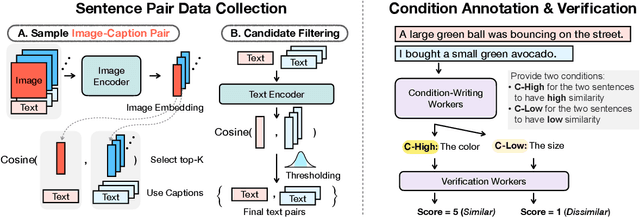
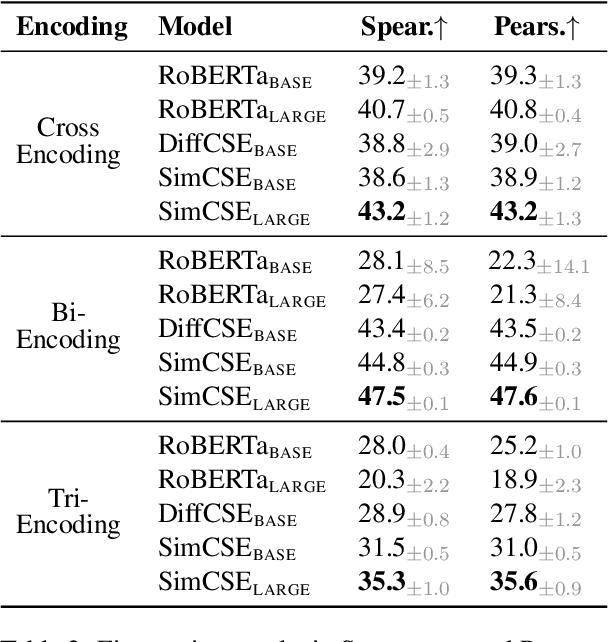
Semantic textual similarity (STS) has been a cornerstone task in NLP that measures the degree of similarity between a pair of sentences, with applications in information retrieval, question answering, and embedding methods. However, it is an inherently ambiguous task, with the sentence similarity depending on the specific aspect of interest. We resolve this ambiguity by proposing a novel task called conditional STS (C-STS) which measures similarity conditioned on an aspect elucidated in natural language (hereon, condition). As an example, the similarity between the sentences "The NBA player shoots a three-pointer." and "A man throws a tennis ball into the air to serve." is higher for the condition "The motion of the ball." (both upward) and lower for "The size of the ball." (one large and one small). C-STS's advantages are two-fold: (1) it reduces the subjectivity and ambiguity of STS, and (2) enables fine-grained similarity evaluation using diverse conditions. C-STS contains almost 20,000 instances from diverse domains and we evaluate several state-of-the-art models to demonstrate that even the most performant fine-tuning and in-context learning models (GPT-4, Flan, SimCSE) find it challenging, with Spearman correlation scores of <50. We encourage the community to evaluate their models on C-STS to provide a more holistic view of semantic similarity and natural language understanding.
Peek Across: Improving Multi-Document Modeling via Cross-Document Question-Answering
May 24, 2023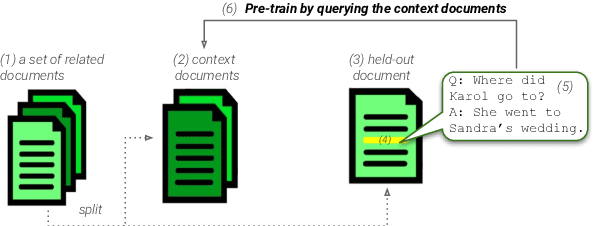
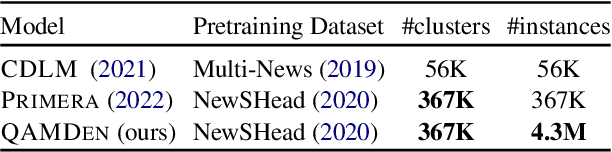
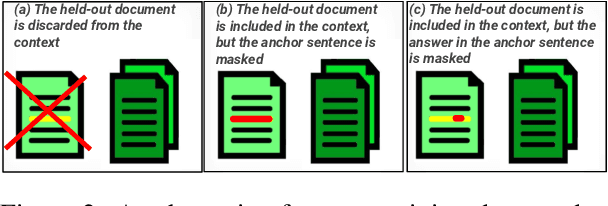
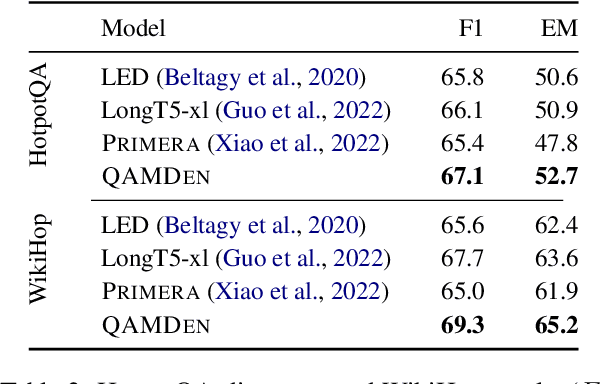
The integration of multi-document pre-training objectives into language models has resulted in remarkable improvements in multi-document downstream tasks. In this work, we propose extending this idea by pre-training a generic multi-document model from a novel cross-document question answering pre-training objective. To that end, given a set (or cluster) of topically-related documents, we systematically generate semantically-oriented questions from a salient sentence in one document and challenge the model, during pre-training, to answer these questions while "peeking" into other topically-related documents. In a similar manner, the model is also challenged to recover the sentence from which the question was generated, again while leveraging cross-document information. This novel multi-document QA formulation directs the model to better recover cross-text informational relations, and introduces a natural augmentation that artificially increases the pre-training data. Further, unlike prior multi-document models that focus on either classification or summarization tasks, our pre-training objective formulation enables the model to perform tasks that involve both short text generation (e.g., QA) and long text generation (e.g., summarization). Following this scheme, we pre-train our model -- termed QAmden -- and evaluate its performance across several multi-document tasks, including multi-document QA, summarization, and query-focused summarization, yielding improvements of up to 7%, and significantly outperforms zero-shot GPT-3.5 and GPT-4.
Robust Sparse Mean Estimation via Incremental Learning
May 24, 2023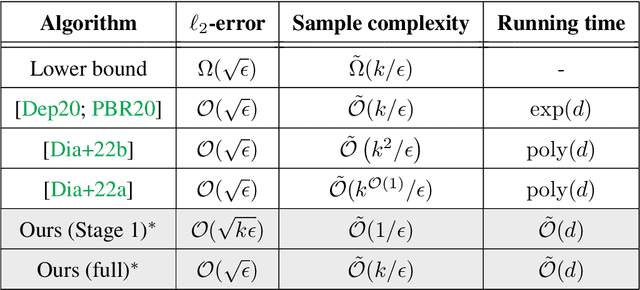
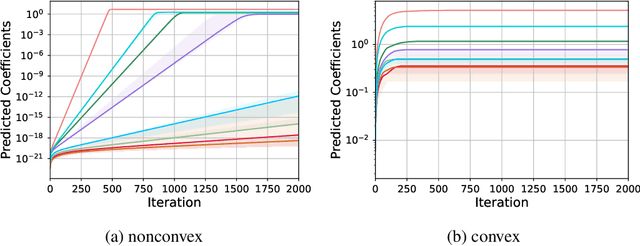
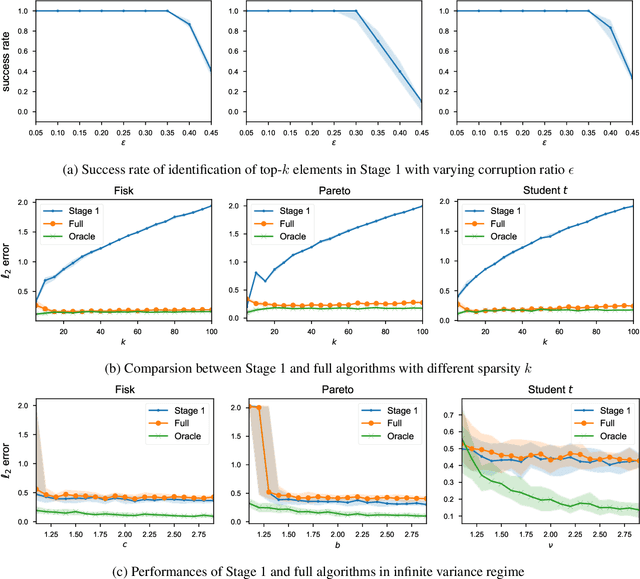
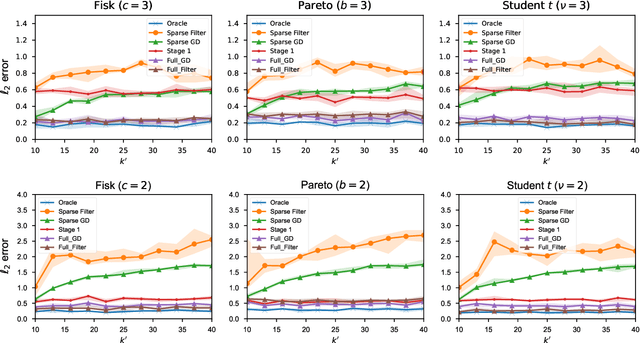
In this paper, we study the problem of robust sparse mean estimation, where the goal is to estimate a $k$-sparse mean from a collection of partially corrupted samples drawn from a heavy-tailed distribution. Existing estimators face two critical challenges in this setting. First, they are limited by a conjectured computational-statistical tradeoff, implying that any computationally efficient algorithm needs $\tilde\Omega(k^2)$ samples, while its statistically-optimal counterpart only requires $\tilde O(k)$ samples. Second, the existing estimators fall short of practical use as they scale poorly with the ambient dimension. This paper presents a simple mean estimator that overcomes both challenges under moderate conditions: it runs in near-linear time and memory (both with respect to the ambient dimension) while requiring only $\tilde O(k)$ samples to recover the true mean. At the core of our method lies an incremental learning phenomenon: we introduce a simple nonconvex framework that can incrementally learn the top-$k$ nonzero elements of the mean while keeping the zero elements arbitrarily small. Unlike existing estimators, our method does not need any prior knowledge of the sparsity level $k$. We prove the optimality of our estimator by providing a matching information-theoretic lower bound. Finally, we conduct a series of simulations to corroborate our theoretical findings. Our code is available at https://github.com/huihui0902/Robust_mean_estimation.
Deep Learning for Survival Analysis: A Review
May 24, 2023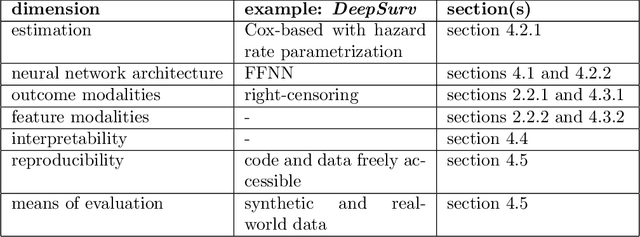

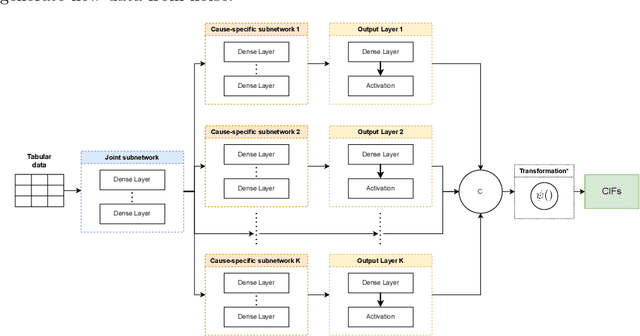
The influx of deep learning (DL) techniques into the field of survival analysis in recent years, coupled with the increasing availability of high-dimensional omics data and unstructured data like images or text, has led to substantial methodological progress; for instance, learning from such high-dimensional or unstructured data. Numerous modern DL-based survival methods have been developed since the mid-2010s; however, they often address only a small subset of scenarios in the time-to-event data setting - e.g., single-risk right-censored survival tasks - and neglect to incorporate more complex (and common) settings. Partially, this is due to a lack of exchange between experts in the respective fields. In this work, we provide a comprehensive systematic review of DL-based methods for time-to-event analysis, characterizing them according to both survival- and DL-related attributes. In doing so, we hope to provide a helpful overview to practitioners who are interested in DL techniques applicable to their specific use case as well as to enable researchers from both fields to identify directions for future investigation. We provide a detailed characterization of the methods included in this review as an open-source, interactive table: https://survival-org.github.io/DL4Survival. As this research area is advancing rapidly, we encourage the research community to contribute to keeping the information up to date.
Improving accuracy of GPT-3/4 results on biomedical data using a retrieval-augmented language model
May 26, 2023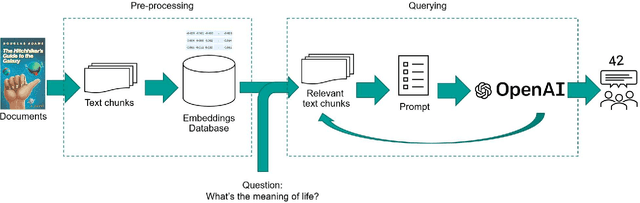
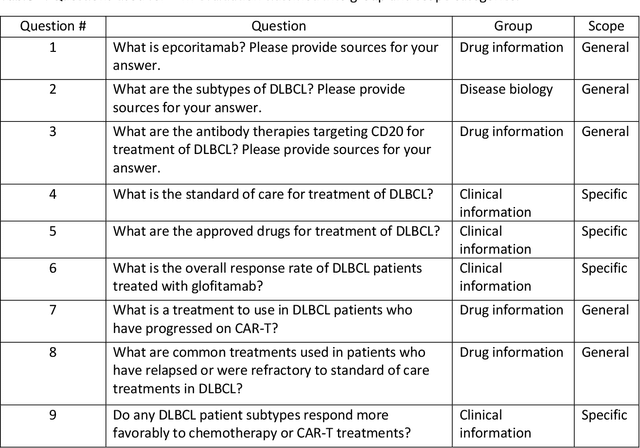

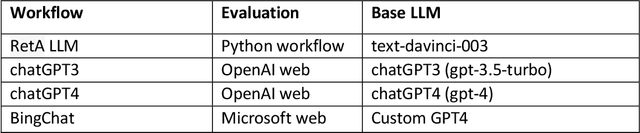
Large language models (LLMs) have made significant advancements in natural language processing (NLP). Broad corpora capture diverse patterns but can introduce irrelevance, while focused corpora enhance reliability by reducing misleading information. Training LLMs on focused corpora poses computational challenges. An alternative approach is to use a retrieval-augmentation (RetA) method tested in a specific domain. To evaluate LLM performance, OpenAI's GPT-3, GPT-4, Bing's Prometheus, and a custom RetA model were compared using 19 questions on diffuse large B-cell lymphoma (DLBCL) disease. Eight independent reviewers assessed responses based on accuracy, relevance, and readability (rated 1-3). The RetA model performed best in accuracy (12/19 3-point scores, total=47) and relevance (13/19, 50), followed by GPT-4 (8/19, 43; 11/19, 49). GPT-4 received the highest readability scores (17/19, 55), followed by GPT-3 (15/19, 53) and the RetA model (11/19, 47). Prometheus underperformed in accuracy (34), relevance (32), and readability (38). Both GPT-3.5 and GPT-4 had more hallucinations in all 19 responses compared to the RetA model and Prometheus. Hallucinations were mostly associated with non-existent references or fabricated efficacy data. These findings suggest that RetA models, supplemented with domain-specific corpora, may outperform general-purpose LLMs in accuracy and relevance within specific domains. However, this evaluation was limited to specific questions and metrics and may not capture challenges in semantic search and other NLP tasks. Further research will explore different LLM architectures, RetA methodologies, and evaluation methods to assess strengths and limitations more comprehensively.
FARA: Future-aware Ranking Algorithm for Fairness Optimization
May 26, 2023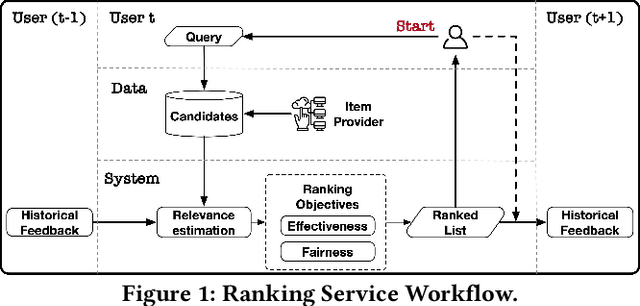
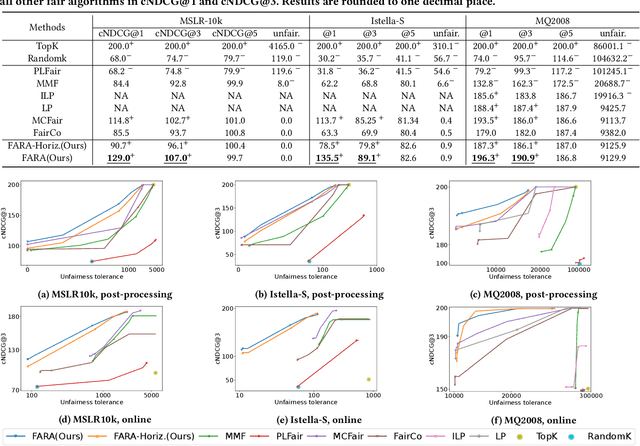
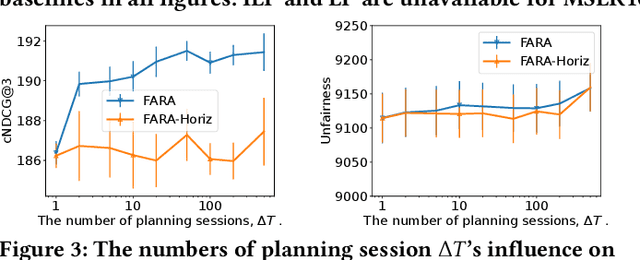
Ranking systems are the key components of modern Information Retrieval (IR) applications, such as search engines and recommender systems. Besides the ranking relevance to users, the exposure fairness to item providers has also been considered an important factor in ranking optimization. Many fair ranking algorithms have been proposed to jointly optimize both ranking relevance and fairness. However, we find that most existing fair ranking methods adopt greedy algorithms that only optimize rankings for the next immediate session or request. As shown in this paper, such a myopic paradigm could limit the upper bound of ranking optimization and lead to suboptimal performance in the long term. To this end, we propose FARA, a novel Future-Aware Ranking Algorithm for ranking relevance and fairness optimization. Instead of greedily optimizing rankings for the next immediate session, FARA plans ahead by jointly optimizing multiple ranklists together and saving them for future sessions. Particularly, FARA first uses the Taylor expansion to investigate how future ranklists will influence the overall fairness of the system. Then, based on the analysis of the Taylor expansion, FARA adopts a two-phase optimization algorithm where we first solve an optimal future exposure planning problem and then construct the optimal ranklists according to the optimal future exposure planning. Theoretically, we show that FARA is optimal for ranking relevance and fairness joint optimization. Empirically, our extensive experiments on three semi-synthesized datasets show that FARA is efficient, effective, and can deliver significantly better ranking performance compared to state-of-the-art fair ranking methods.
Robust Lane Detection through Self Pre-training with Masked Sequential Autoencoders and Fine-tuning with Customized PolyLoss
May 26, 2023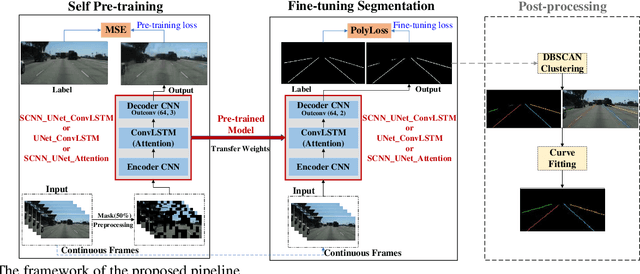
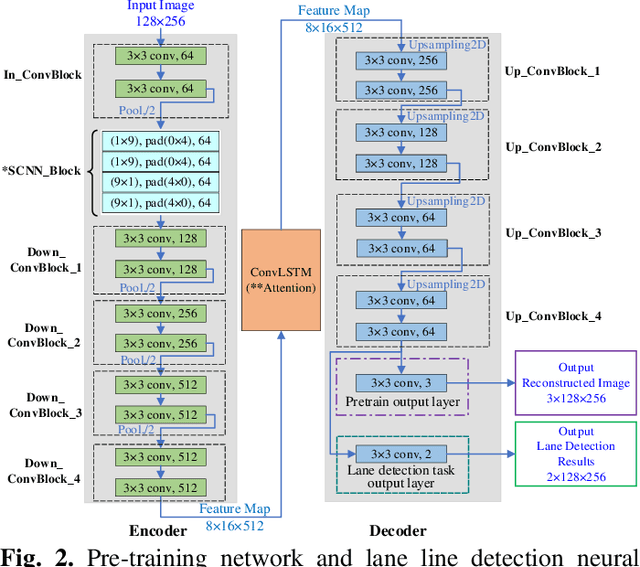
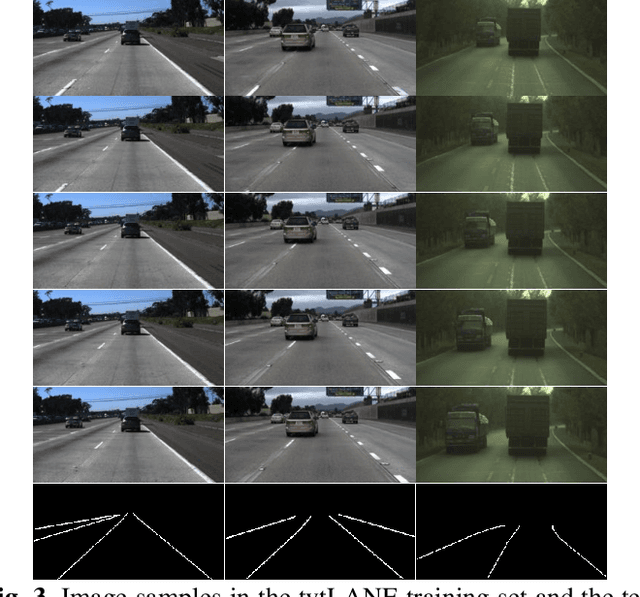

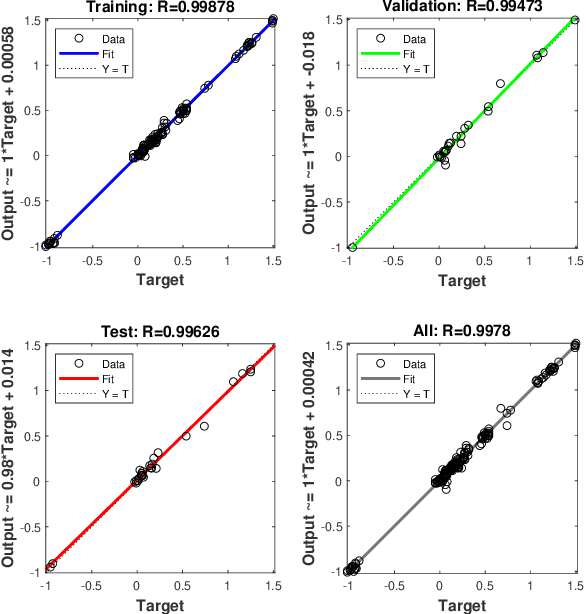
Lane detection is crucial for vehicle localization which makes it the foundation for automated driving and many intelligent and advanced driving assistant systems. Available vision-based lane detection methods do not make full use of the valuable features and aggregate contextual information, especially the interrelationships between lane lines and other regions of the images in continuous frames. To fill this research gap and upgrade lane detection performance, this paper proposes a pipeline consisting of self pre-training with masked sequential autoencoders and fine-tuning with customized PolyLoss for the end-to-end neural network models using multi-continuous image frames. The masked sequential autoencoders are adopted to pre-train the neural network models with reconstructing the missing pixels from a random masked image as the objective. Then, in the fine-tuning segmentation phase where lane detection segmentation is performed, the continuous image frames are served as the inputs, and the pre-trained model weights are transferred and further updated using the backpropagation mechanism with customized PolyLoss calculating the weighted errors between the output lane detection results and the labeled ground truth. Extensive experiment results demonstrate that, with the proposed pipeline, the lane detection model performance on both normal and challenging scenes can be advanced beyond the state-of-the-art, delivering the best testing accuracy (98.38%), precision (0.937), and F1-measure (0.924) on the normal scene testing set, together with the best overall accuracy (98.36%) and precision (0.844) in the challenging scene test set, while the training time can be substantially shortened.
To Collide or Not To Collide -- Exploiting Passive Deformable Quadrotors for Contact-Rich Tasks
May 26, 2023
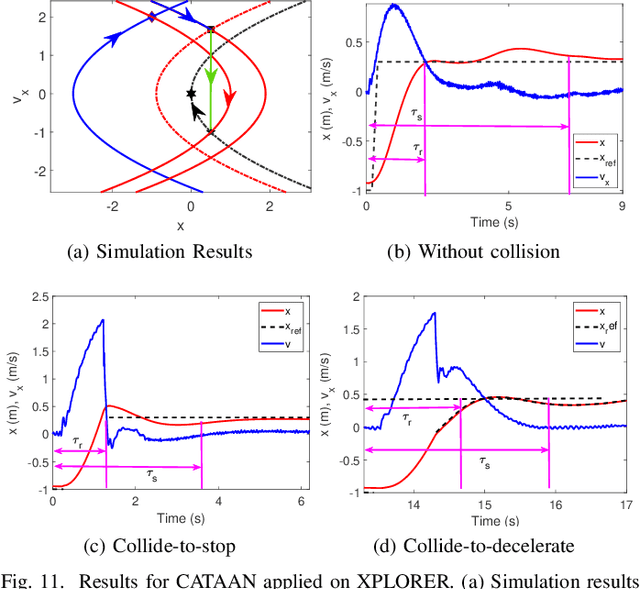
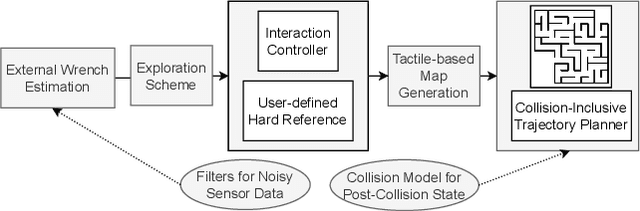
With an increase in aerial vehicle applications, passive deformable quadrotors are getting significant attention in the research community due to their potential to perform physical interaction tasks. Such quadrotors are capable of undergoing collisions, both planned and unplanned, which are harnessed to induce deformation and retain stability by dissipating collision energies. In this article, we utilize one such passive deforming quadrotor, XPLORER, to complete various contact-rich tasks by exploiting its compliant chassis via various impact-aware planning and control algorithms. At the core of these algorithms is a novel external wrench estimation technique developed specifically for the unique multi-linked structure of XPLORER's chassis. The external wrench information is then employed for designing interaction controllers to obtain three additional flight modes: static-wrench application, disturbance rejection and yielding to the disturbance. These modes are then incorporated into a novel online exploration scheme to enable navigation in unknown flight spaces with only tactile feedback and generate a map of the environment without requiring additional sensors. Experiments show the efficacy of this scheme to generate maps of the previously unexplored flight space with an accuracy of 96.72%. Finally, we develop a novel collision-aware trajectory planner (CATAAN) to generate minimum time maneuvers for waypoint tracking by integrating collision-induced state jumps for both elastic and inelastic cases. We experimentally validate that minimum time trajectories can be obtained with CATAAN leading to a 40.38% reduction of settling time accompanied by improved tracking performance of a root mean squared error in position within 0.5cm as compared to 3cm of conventional methods.
pFedSim: Similarity-Aware Model Aggregation Towards Personalized Federated Learning
May 25, 2023
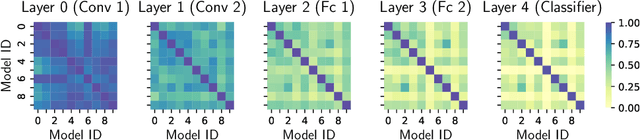
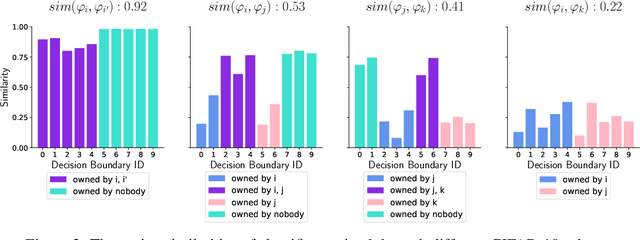
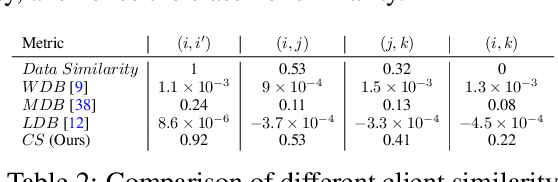
The federated learning (FL) paradigm emerges to preserve data privacy during model training by only exposing clients' model parameters rather than original data. One of the biggest challenges in FL lies in the non-IID (not identical and independently distributed) data (a.k.a., data heterogeneity) distributed on clients. To address this challenge, various personalized FL (pFL) methods are proposed such as similarity-based aggregation and model decoupling. The former one aggregates models from clients of a similar data distribution. The later one decouples a neural network (NN) model into a feature extractor and a classifier. Personalization is captured by classifiers which are obtained by local training. To advance pFL, we propose a novel pFedSim (pFL based on model similarity) algorithm in this work by combining these two kinds of methods. More specifically, we decouple a NN model into a personalized feature extractor, obtained by aggregating models from similar clients, and a classifier, which is obtained by local training and used to estimate client similarity. Compared with the state-of-the-art baselines, the advantages of pFedSim include: 1) significantly improved model accuracy; 2) low communication and computation overhead; 3) a low risk of privacy leakage; 4) no requirement for any external public information. To demonstrate the superiority of pFedSim, extensive experiments are conducted on real datasets. The results validate the superb performance of our algorithm which can significantly outperform baselines under various heterogeneous data settings.