 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HeR-DRL:Heterogeneous Relational Deep Reinforcement Learning for Decentralized Multi-Robot Crowd Navigation
Mar 15, 2024
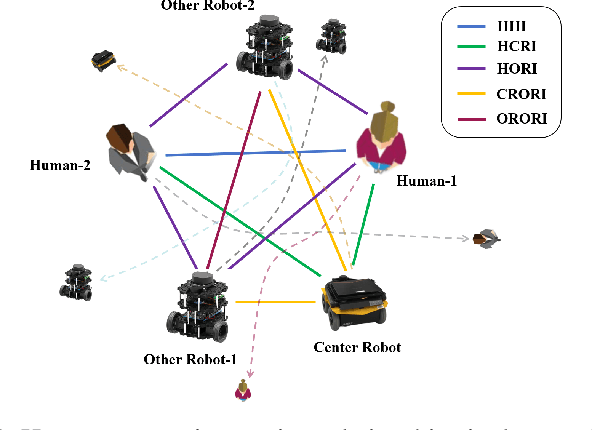
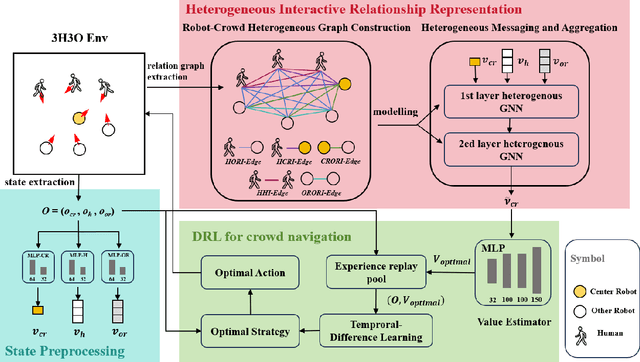
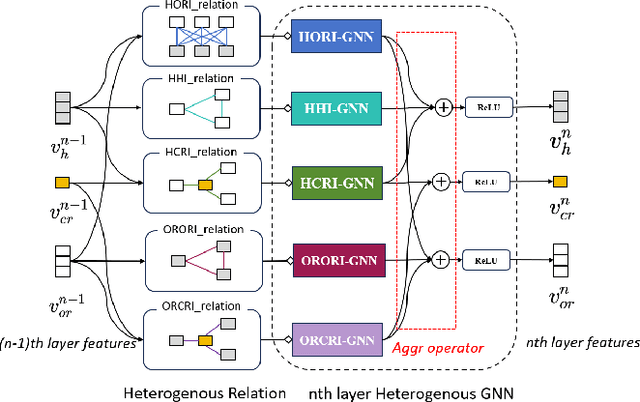
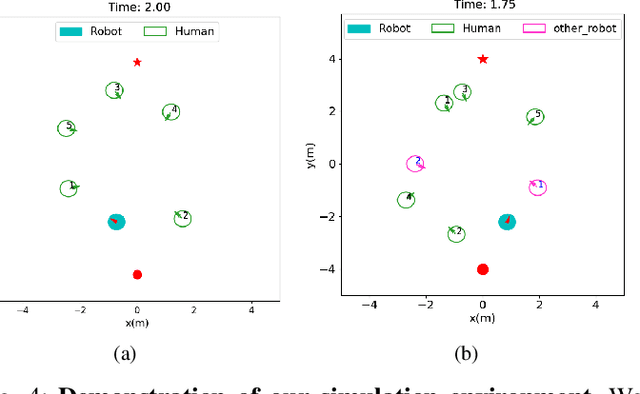
Crowd navigation has received significant research attention in recent years, especially DRL-based methods. While single-robot crowd scenarios have dominated research, they offer limited applicability to real-world complexities. The heterogeneity of interaction among multiple agent categories, like in decentralized multi-robot pedestrian scenarios, are frequently disregarded. This "interaction blind spot" hinders generalizability and restricts progress towards robust navigation algorithms. In this paper, we propose a heterogeneous relational deep reinforcement learning(HeR-DRL), based on customised heterogeneous GNN, in order to improve navigation strategies in decentralized multi-robot crowd navigation. Firstly, we devised a method for constructing robot-crowd heterogenous relation graph that effectively simulates the heterogeneous pair-wise interaction relationships. We proposed a new heterogeneous graph neural network for transferring and aggregating the heterogeneous state information. Finally, we incorporate the encoded information into deep reinforcement learning to explore the optimal policy. HeR-DRL are rigorously evaluated through comparing it to state-of-the-art algorithms in both single-robot and multi-robot circle crowssing scenario. The experimental results demonstrate that HeR-DRL surpasses the state-of-the-art approaches in overall performance, particularly excelling in safety and comfort metrics. This underscores the significance of interaction heterogeneity for crowd navigation. The source code will be publicly released in https://github.com/Zhouxy-Debugging-Den/HeR-DRL.
CrossGLG: LLM Guides One-shot Skeleton-based 3D Action Recognition in a Cross-level Manner
Mar 15, 2024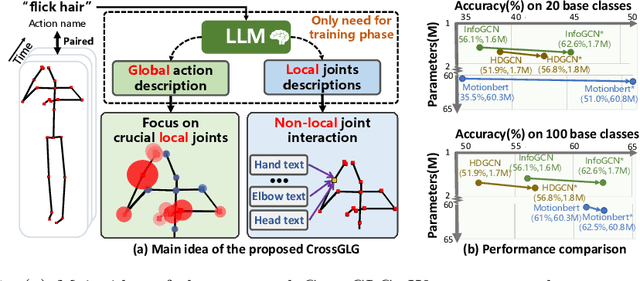
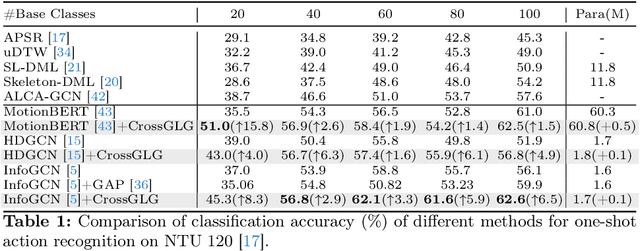
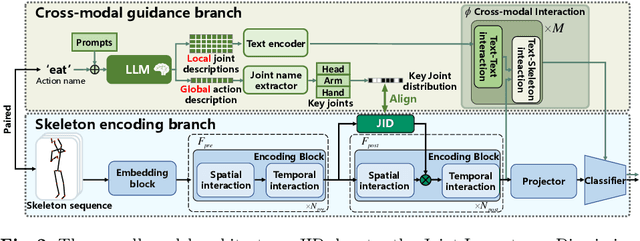
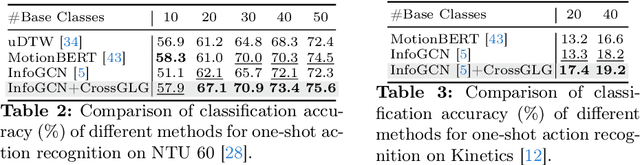
Most existing one-shot skeleton-based action recognition focuses on raw low-level information (e.g., joint location), and may suffer from local information loss and low generalization ability. To alleviate these, we propose to leverage text description generated from large language models (LLM) that contain high-level human knowledge, to guide feature learning, in a global-local-global way. Particularly, during training, we design $2$ prompts to gain global and local text descriptions of each action from an LLM. We first utilize the global text description to guide the skeleton encoder focus on informative joints (i.e.,global-to-local). Then we build non-local interaction between local text and joint features, to form the final global representation (i.e., local-to-global). To mitigate the asymmetry issue between the training and inference phases, we further design a dual-branch architecture that allows the model to perform novel class inference without any text input, also making the additional inference cost neglectable compared with the base skeleton encoder. Extensive experiments on three different benchmarks show that CrossGLG consistently outperforms the existing SOTA methods with large margins, and the inference cost (model size) is only $2.8$\% than the previous SOTA. CrossGLG can also serve as a plug-and-play module that can substantially enhance the performance of different SOTA skeleton encoders with a neglectable cost during inference. The source code will be released soon.
Efficient Combinatorial Optimization via Heat Diffusion
Mar 14, 2024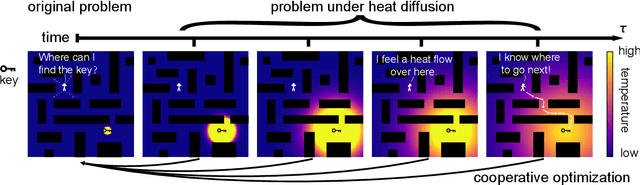
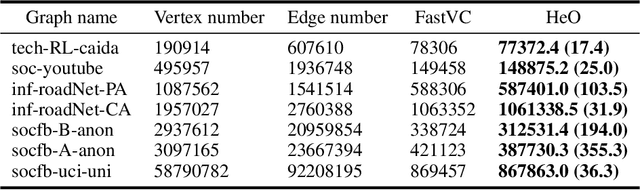
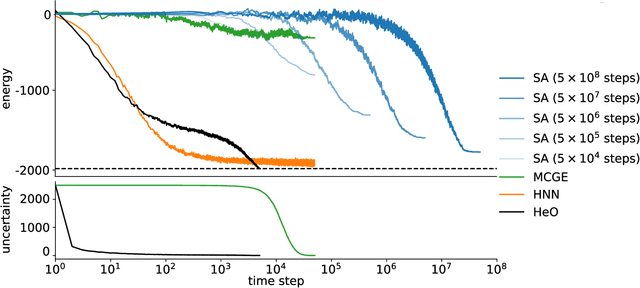
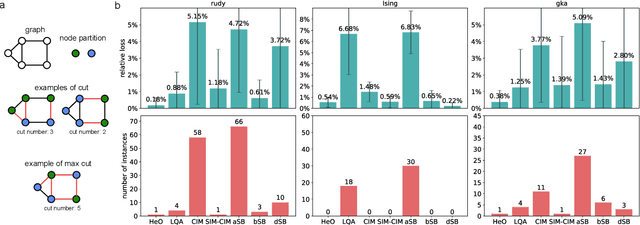
Combinatorial optimization problems are widespread but inherently challenging due to their discrete nature.The primary limitation of existing methods is that they can only access a small fraction of the solution space at each iteration, resulting in limited efficiency for searching the global optimal. To overcome this challenge, diverging from conventional efforts of expanding the solver's search scope, we focus on enabling information to actively propagate to the solver through heat diffusion. By transforming the target function while preserving its optima, heat diffusion facilitates information flow from distant regions to the solver, providing more efficient navigation. Utilizing heat diffusion, we propose a framework for solving general combinatorial optimization problems. The proposed methodology demonstrates superior performance across a range of the most challenging and widely encountered combinatorial optimizations. Echoing recent advancements in harnessing thermodynamics for generative artificial intelligence, our study further reveals its significant potential in advancing combinatorial optimization.
Federated Modality-specific Encoders and Multimodal Anchors for Personalized Brain Tumor Segmentation
Mar 18, 2024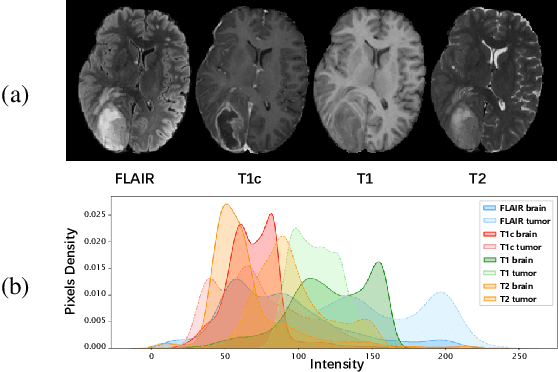
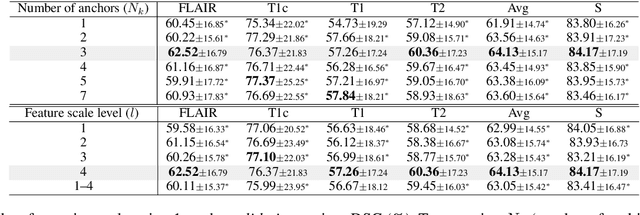
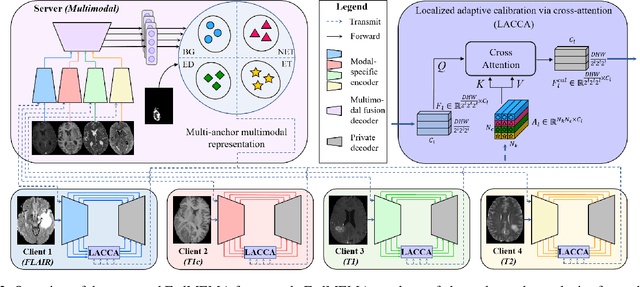
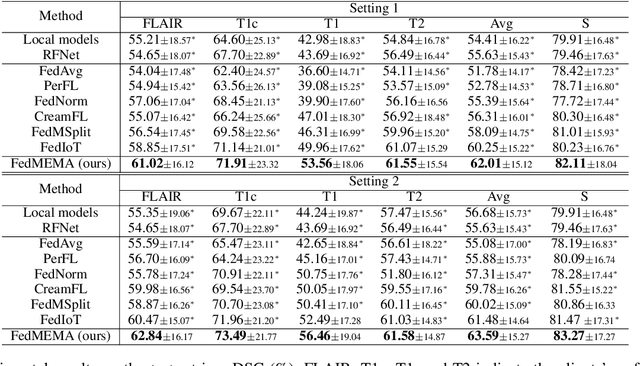
Most existing federated learning (FL) methods for medical image analysis only considered intramodal heterogeneity, limiting their applicability to multimodal imaging applications. In practice, it is not uncommon that some FL participants only possess a subset of the complete imaging modalities, posing inter-modal heterogeneity as a challenge to effectively training a global model on all participants' data. In addition, each participant would expect to obtain a personalized model tailored for its local data characteristics from the FL in such a scenario. In this work, we propose a new FL framework with federated modality-specific encoders and multimodal anchors (FedMEMA) to simultaneously address the two concurrent issues. Above all, FedMEMA employs an exclusive encoder for each modality to account for the inter-modal heterogeneity in the first place. In the meantime, while the encoders are shared by the participants, the decoders are personalized to meet individual needs. Specifically, a server with full-modal data employs a fusion decoder to aggregate and fuse representations from all modality-specific encoders, thus bridging the modalities to optimize the encoders via backpropagation reversely. Meanwhile, multiple anchors are extracted from the fused multimodal representations and distributed to the clients in addition to the encoder parameters. On the other end, the clients with incomplete modalities calibrate their missing-modal representations toward the global full-modal anchors via scaled dot-product cross-attention, making up the information loss due to absent modalities while adapting the representations of present ones. FedMEMA is validated on the BraTS 2020 benchmark for multimodal brain tumor segmentation. Results show that it outperforms various up-to-date methods for multimodal and personalized FL and that its novel designs are effective. Our code is available.
Adversarial Training with OCR Modality Perturbation for Scene-Text Visual Question Answering
Mar 14, 2024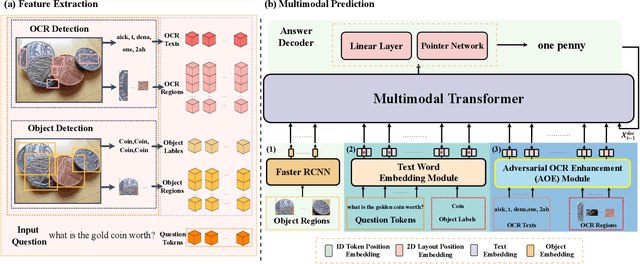
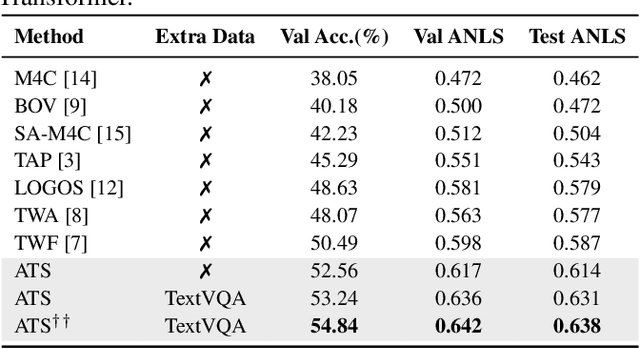
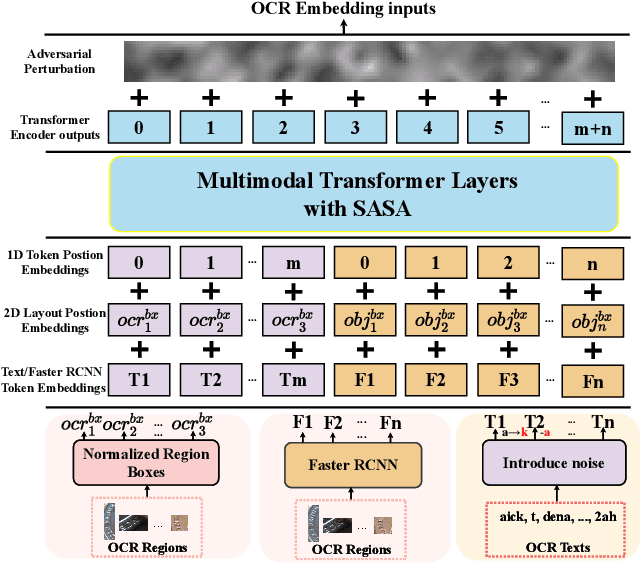
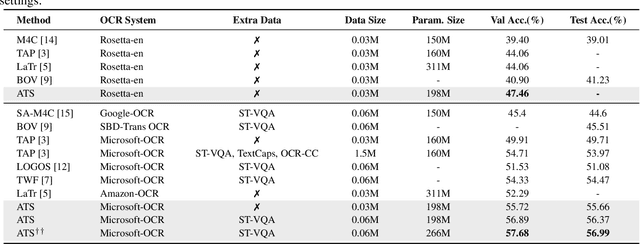
Scene-Text Visual Question Answering (ST-VQA) aims to understand scene text in images and answer questions related to the text content. Most existing methods heavily rely on the accuracy of Optical Character Recognition (OCR) systems, and aggressive fine-tuning based on limited spatial location information and erroneous OCR text information often leads to inevitable overfitting. In this paper, we propose a multimodal adversarial training architecture with spatial awareness capabilities. Specifically, we introduce an Adversarial OCR Enhancement (AOE) module, which leverages adversarial training in the embedding space of OCR modality to enhance fault-tolerant representation of OCR texts, thereby reducing noise caused by OCR errors. Simultaneously, We add a Spatial-Aware Self-Attention (SASA) mechanism to help the model better capture the spatial relationships among OCR tokens. Various experiments demonstrate that our method achieves significant performance improvements on both the ST-VQA and TextVQA datasets and provides a novel paradigm for multimodal adversarial training.
A Fourier Transform Framework for Domain Adaptation
Mar 12, 2024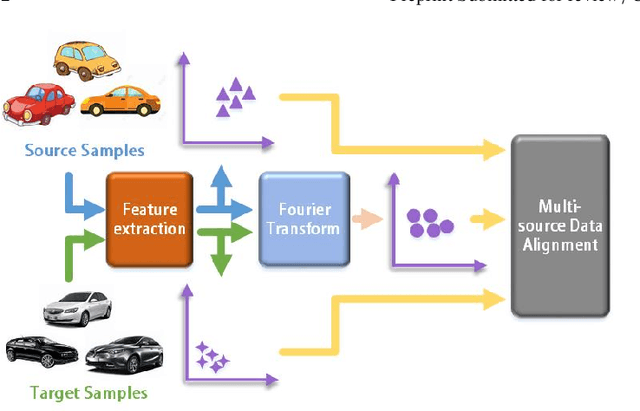
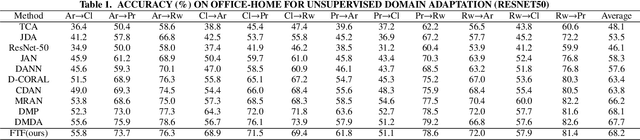
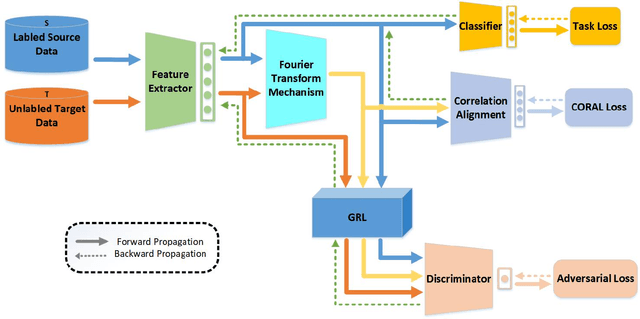

By using unsupervised domain adaptation (UDA), knowledge can be transferred from a label-rich source domain to a target domain that contains relevant information but lacks labels. Many existing UDA algorithms suffer from directly using raw images as input, resulting in models that overly focus on redundant information and exhibit poor generalization capability. To address this issue, we attempt to improve the performance of unsupervised domain adaptation by employing the Fourier method (FTF).Specifically, FTF is inspired by the amplitude of Fourier spectra, which primarily preserves low-level statistical information. In FTF, we effectively incorporate low-level information from the target domain into the source domain by fusing the amplitudes of both domains in the Fourier domain. Additionally, we observe that extracting features from batches of images can eliminate redundant information while retaining class-specific features relevant to the task. Building upon this observation, we apply the Fourier Transform at the data stream level for the first time. To further align multiple sources of data, we introduce the concept of correlation alignment. To evaluate the effectiveness of our FTF method, we conducted evaluations on four benchmark datasets for domain adaptation, including Office-31, Office-Home, ImageCLEF-DA, and Office-Caltech. Our results demonstrate superior performance.
Learning under Singularity: An Information Criterion improving WBIC and sBIC
Feb 22, 2024We introduce a novel Information Criterion (IC), termed Learning under Singularity (LS), designed to enhance the functionality of the Widely Applicable Bayes Information Criterion (WBIC) and the Singular Bayesian Information Criterion (sBIC). LS is effective without regularity constraints and demonstrates stability. Watanabe defined a statistical model or a learning machine as regular if the mapping from a parameter to a probability distribution is one-to-one and its Fisher information matrix is positive definite. In contrast, models not meeting these conditions are termed singular. Over the past decade, several information criteria for singular cases have been proposed, including WBIC and sBIC. WBIC is applicable in non-regular scenarios but faces challenges with large sample sizes and redundant estimation of known learning coefficients. Conversely, sBIC is limited in its broader application due to its dependence on maximum likelihood estimates. LS addresses these limitations by enhancing the utility of both WBIC and sBIC. It incorporates the empirical loss from the Widely Applicable Information Criterion (WAIC) to represent the goodness of fit to the statistical model, along with a penalty term similar to that of sBIC. This approach offers a flexible and robust method for model selection, free from regularity constraints.
Local-consistent Transformation Learning for Rotation-invariant Point Cloud Analysis
Mar 17, 2024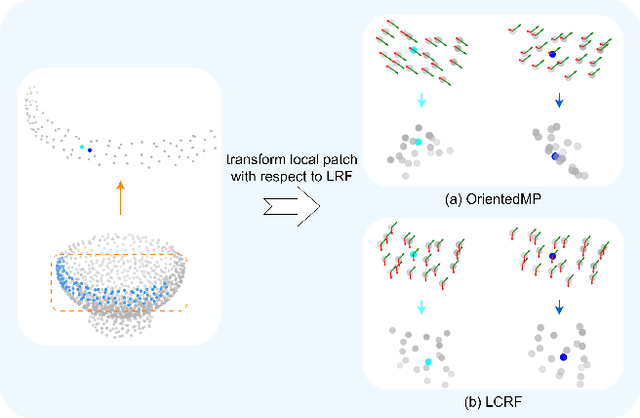
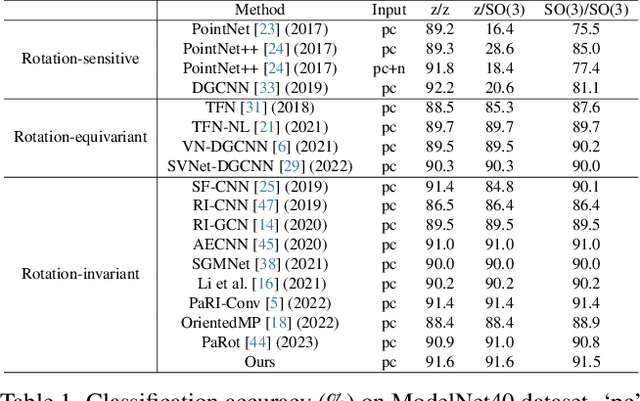
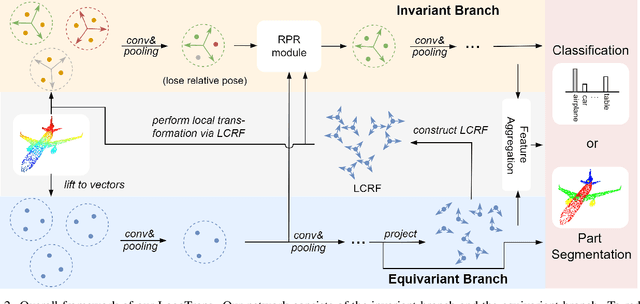
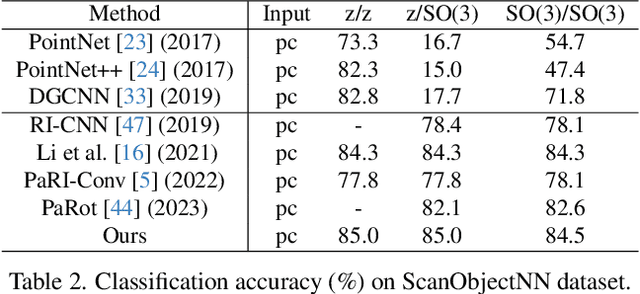
Rotation invariance is an important requirement for point shape analysis. To achieve this, current state-of-the-art methods attempt to construct the local rotation-invariant representation through learning or defining the local reference frame (LRF). Although efficient, these LRF-based methods suffer from perturbation of local geometric relations, resulting in suboptimal local rotation invariance. To alleviate this issue, we propose a Local-consistent Transformation (LocoTrans) learning strategy. Specifically, we first construct the local-consistent reference frame (LCRF) by considering the symmetry of the two axes in LRF. In comparison with previous LRFs, our LCRF is able to preserve local geometric relationships better through performing local-consistent transformation. However, as the consistency only exists in local regions, the relative pose information is still lost in the intermediate layers of the network. We mitigate such a relative pose issue by developing a relative pose recovery (RPR) module. RPR aims to restore the relative pose between adjacent transformed patches. Equipped with LCRF and RPR, our LocoTrans is capable of learning local-consistent transformation and preserving local geometry, which benefits rotation invariance learning. Competitive performance under arbitrary rotations on both shape classification and part segmentation tasks and ablations can demonstrate the effectiveness of our method. Code will be available publicly at https://github.com/wdttt/LocoTrans.
Self-Supervised Video Desmoking for Laparoscopic Surgery
Mar 17, 2024
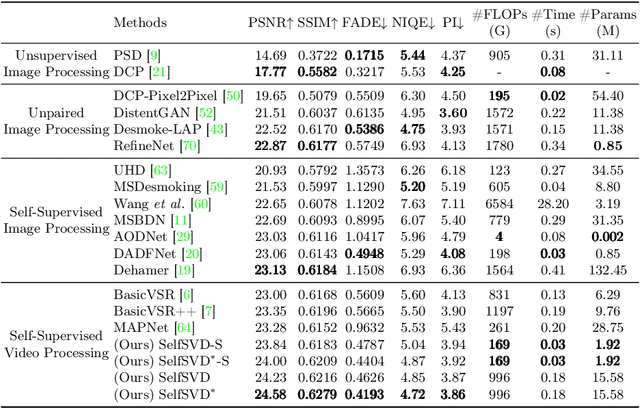
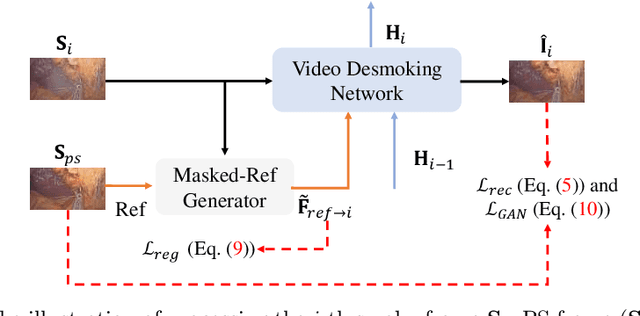
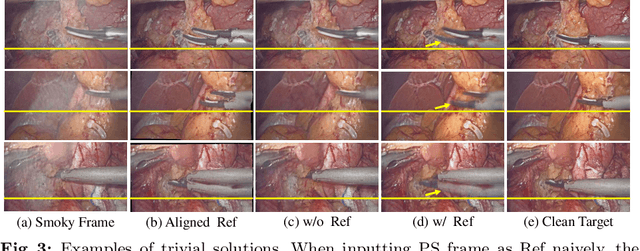
Due to the difficulty of collecting real paired data, most existing desmoking methods train the models by synthesizing smoke, generalizing poorly to real surgical scenarios. Although a few works have explored single-image real-world desmoking in unpaired learning manners, they still encounter challenges in handling dense smoke. In this work, we address these issues together by introducing the self-supervised surgery video desmoking (SelfSVD). On the one hand, we observe that the frame captured before the activation of high-energy devices is generally clear (named pre-smoke frame, PS frame), thus it can serve as supervision for other smoky frames, making real-world self-supervised video desmoking practically feasible. On the other hand, in order to enhance the desmoking performance, we further feed the valuable information from PS frame into models, where a masking strategy and a regularization term are presented to avoid trivial solutions. In addition, we construct a real surgery video dataset for desmoking, which covers a variety of smoky scenes. Extensive experiments on the dataset show that our SelfSVD can remove smoke more effectively and efficiently while recovering more photo-realistic details than the state-of-the-art methods. The dataset, codes, and pre-trained models are available at \url{https://github.com/ZcsrenlongZ/SelfSVD}.
IGANN Sparse: Bridging Sparsity and Interpretability with Non-linear Insight
Mar 17, 2024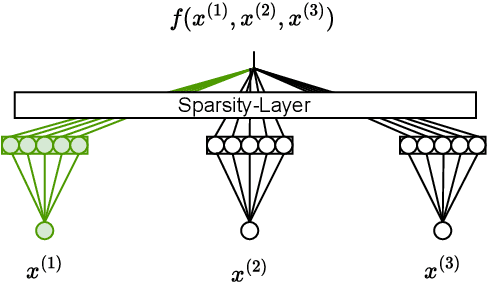
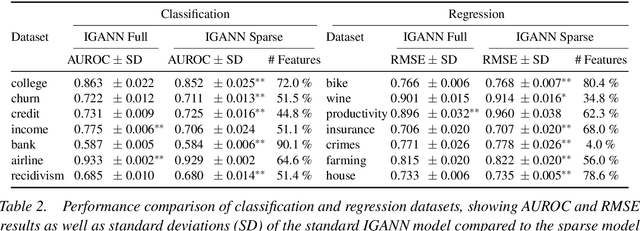
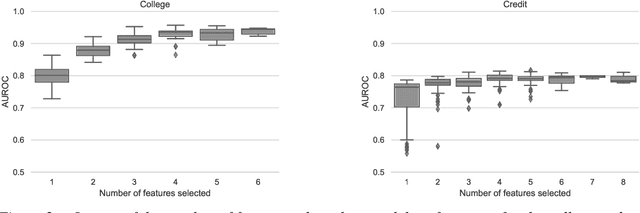
Feature selection is a critical component in predictive analytics that significantly affects the prediction accuracy and interpretability of models. Intrinsic methods for feature selection are built directly into model learning, providing a fast and attractive option for large amounts of data. Machine learning algorithms, such as penalized regression models (e.g., lasso) are the most common choice when it comes to in-built feature selection. However, they fail to capture non-linear relationships, which ultimately affects their ability to predict outcomes in intricate datasets. In this paper, we propose IGANN Sparse, a novel machine learning model from the family of generalized additive models, which promotes sparsity through a non-linear feature selection process during training. This ensures interpretability through improved model sparsity without sacrificing predictive performance. Moreover, IGANN Sparse serves as an exploratory tool for information systems researchers to unveil important non-linear relationships in domains that are characterized by complex patterns. Our ongoing research is directed at a thorough evaluation of the IGANN Sparse model, including user studies that allow to assess how well users of the model can benefit from the reduced number of features. This will allow for a deeper understanding of the interactions between linear vs. non-linear modeling, number of selected features, and predictive performance.