 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Informative Data Selection with Uncertainty for Multi-modal Object Detection
Apr 23, 2023
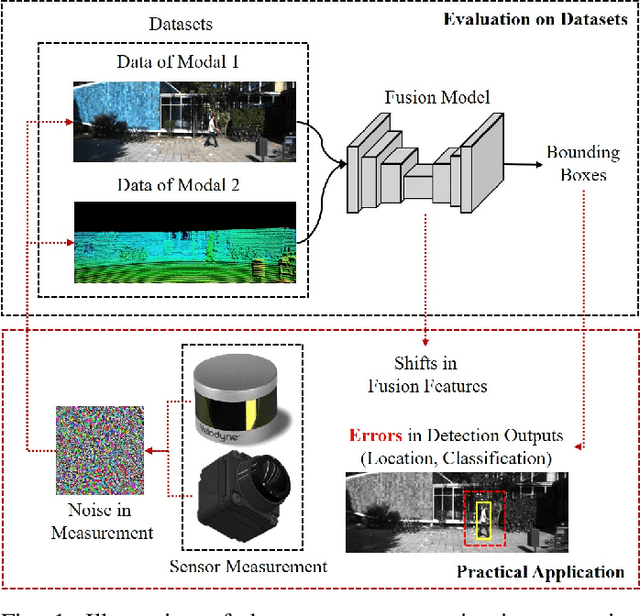

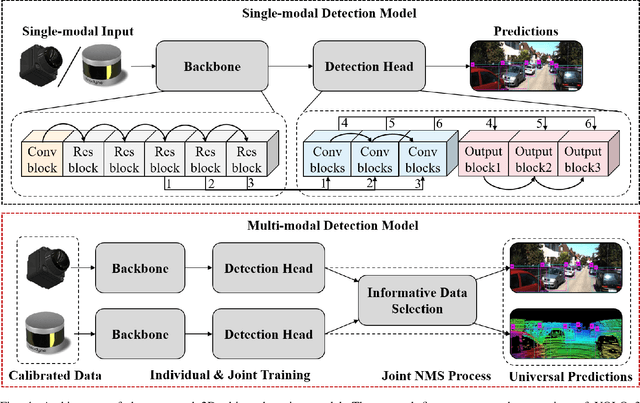
Noise has always been nonnegligible trouble in object detection by creating confusion in model reasoning, thereby reducing the informativeness of the data. It can lead to inaccurate recognition due to the shift in the observed pattern, that requires a robust generalization of the models. To implement a general vision model, we need to develop deep learning models that can adaptively select valid information from multi-modal data. This is mainly based on two reasons. Multi-modal learning can break through the inherent defects of single-modal data, and adaptive information selection can reduce chaos in multi-modal data. To tackle this problem, we propose a universal uncertainty-aware multi-modal fusion model. It adopts a multi-pipeline loosely coupled architecture to combine the features and results from point clouds and images. To quantify the correlation in multi-modal information, we model the uncertainty, as the inverse of data information, in different modalities and embed it in the bounding box generation. In this way, our model reduces the randomness in fusion and generates reliable output. Moreover, we conducted a completed investigation on the KITTI 2D object detection dataset and its derived dirty data. Our fusion model is proven to resist severe noise interference like Gaussian, motion blur, and frost, with only slight degradation. The experiment results demonstrate the benefits of our adaptive fusion. Our analysis on the robustness of multi-modal fusion will provide further insights for future research.
MSI: Maximize Support-Set Information for Few-Shot Segmentation
Dec 09, 2022
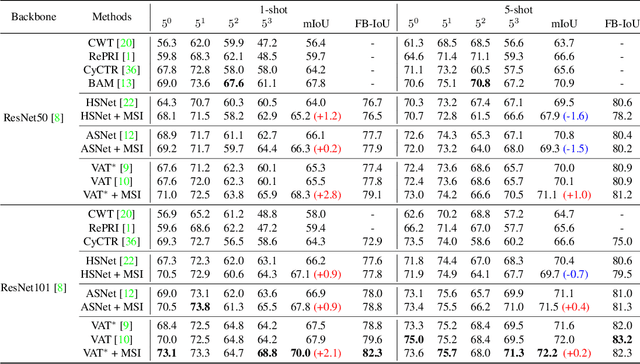
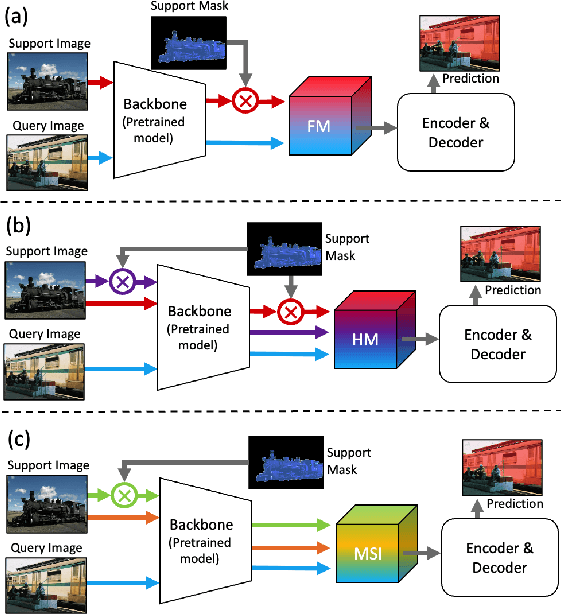
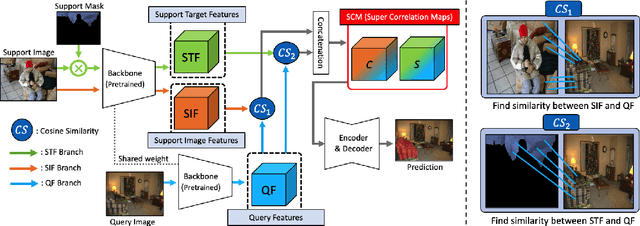
FSS(Few-shot segmentation)~aims to segment a target class with a small number of labeled images (support Set). To extract information relevant to target class, a dominant approach in best performing FSS baselines removes background features using support mask. We observe that this support mask presents an information bottleneck in several challenging FSS cases e.g., for small targets and/or inaccurate target boundaries. To this end, we present a novel method (MSI), which maximizes the support-set information by exploiting two complementary source of features in generating super correlation maps. We validate the effectiveness of our approach by instantiating it into three recent and strong FSS baselines. Experimental results on several publicly available FSS benchmarks show that our proposed method consistently improves the performance by visible margins and allows faster convergence. Our codes and models will be publicly released.
Decouple Graph Neural Networks: Train Multiple Simple GNNs Simultaneously Instead of One
Apr 20, 2023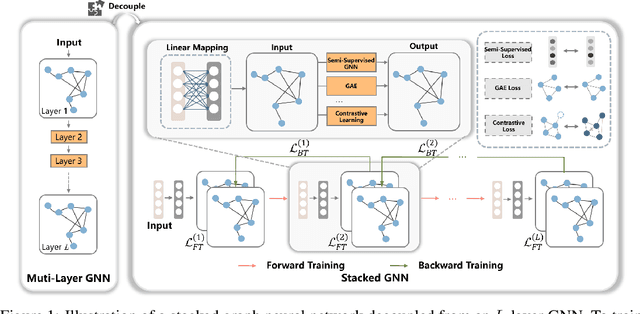
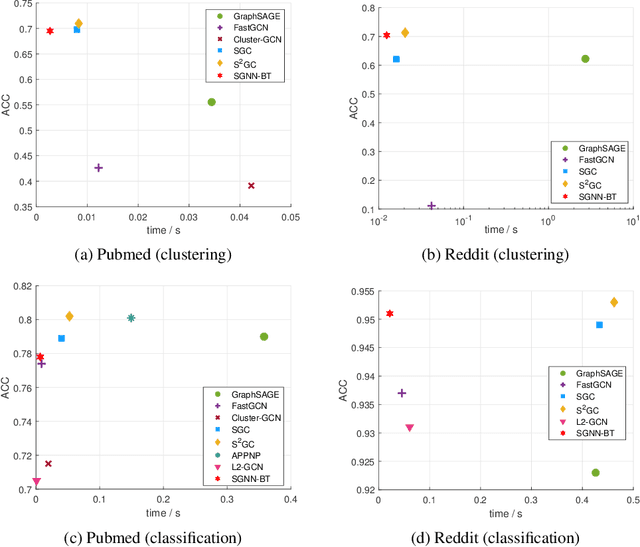
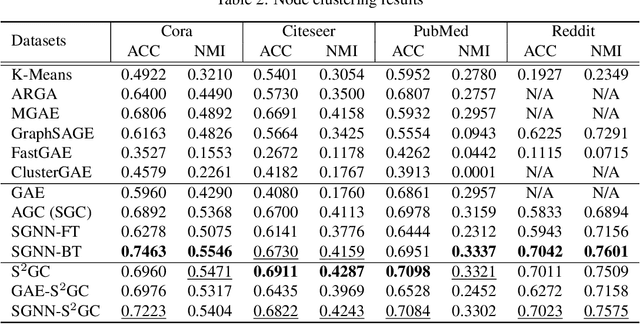
Graph neural networks (GNN) suffer from severe inefficiency. It is mainly caused by the exponential growth of node dependency with the increase of layers. It extremely limits the application of stochastic optimization algorithms so that the training of GNN is usually time-consuming. To address this problem, we propose to decouple a multi-layer GNN as multiple simple modules for more efficient training, which is comprised of classical forward training (FT)and designed backward training (BT). Under the proposed framework, each module can be trained efficiently in FT by stochastic algorithms without distortion of graph information owing to its simplicity. To avoid the only unidirectional information delivery of FT and sufficiently train shallow modules with the deeper ones, we develop a backward training mechanism that makes the former modules perceive the latter modules. The backward training introduces the reversed information delivery into the decoupled modules as well as the forward information delivery. To investigate how the decoupling and greedy training affect the representational capacity, we theoretically prove that the error produced by linear modules will not accumulate on unsupervised tasks in most cases. The theoretical and experimental results show that the proposed framework is highly efficient with reasonable performance.
Lightweight Convolution Transformer for Cross-patient Seizure Detection in Multi-channel EEG Signals
May 07, 2023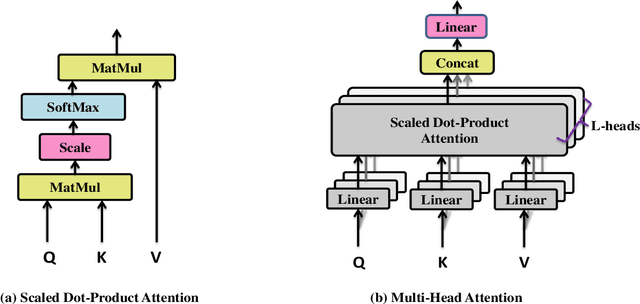

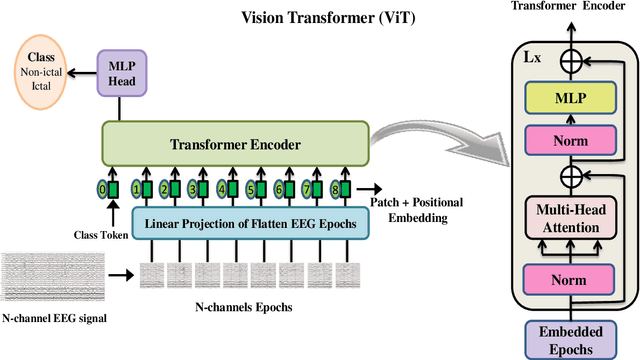
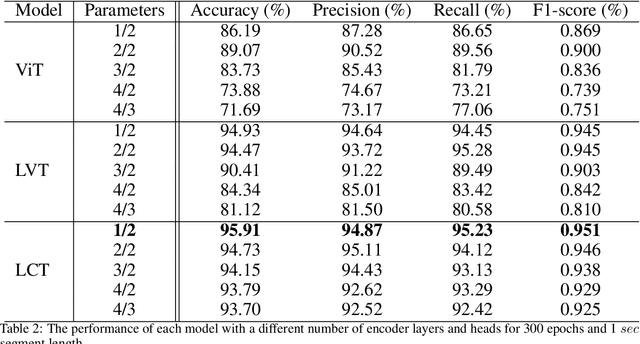
Background: Epilepsy is a neurological illness affecting the brain that makes people more likely to experience frequent, spontaneous seizures. There has to be an accurate automated method for measuring seizure frequency and severity in order to assess the efficacy of pharmacological therapy for epilepsy. The drug quantities are often derived from patient reports which may cause significant issues owing to inadequate or inaccurate descriptions of seizures and their frequencies. Methods and materials: This study proposes a novel deep learning architecture based lightweight convolution transformer (LCT). The transformer is able to learn spatial and temporal correlated information simultaneously from the multi-channel electroencephalogram (EEG) signal to detect seizures at smaller segment lengths. In the proposed model, the lack of translation equivariance and localization of ViT is reduced using convolution tokenization, and rich information from the transformer encoder is extracted by sequence pooling instead of the learnable class token. Results: Extensive experimental results demonstrate that the proposed model of cross-patient learning can effectively detect seizures from the raw EEG signals. The accuracy and F1-score of seizure detection in the cross-patient case on the CHB-MIT dataset are shown to be 96.31% and 96.32%, respectively, at 0.5 sec segment length. In addition, the performance metrics show that the inclusion of inductive biases and attention-based pooling in the model enhances the performance and reduces the number of transformer encoder layers, which significantly reduces the computational complexity. In this research work, we provided a novel approach to enhance efficiency and simplify the architecture for multi-channel automated seizure detection.
Cross-Modal Retrieval for Motion and Text via MildTriple Loss
May 07, 2023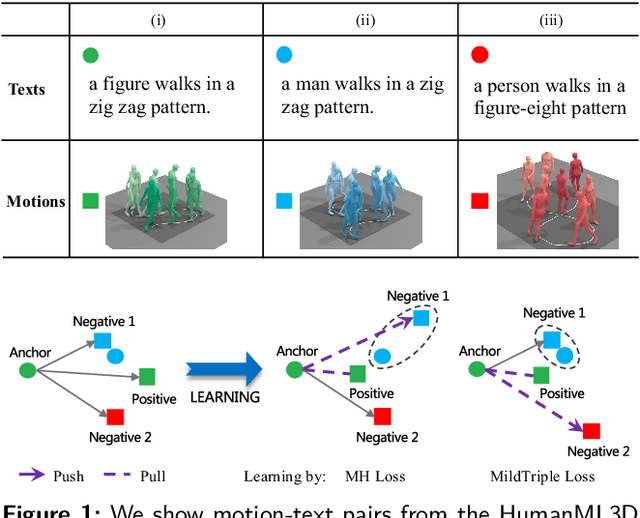
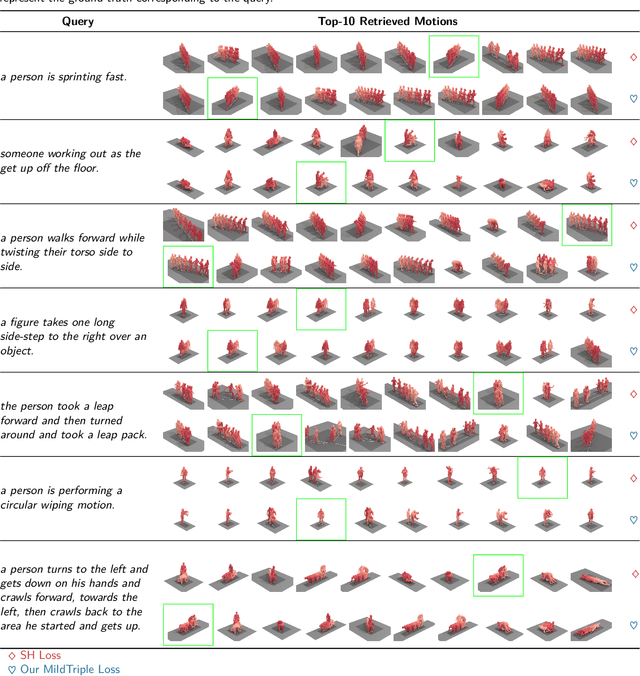
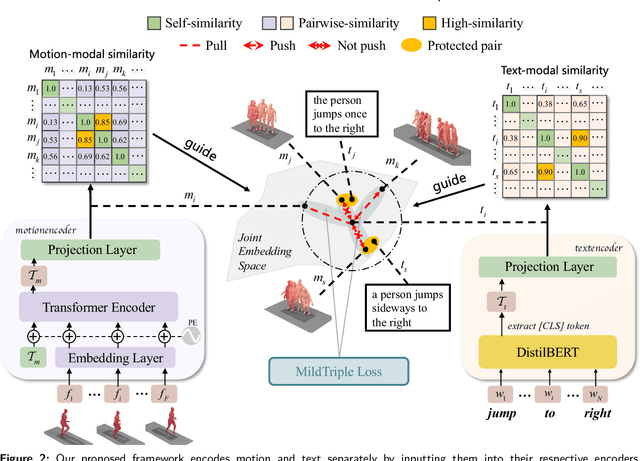

Cross-modal retrieval has become a prominent research topic in computer vision and natural language processing with advances made in image-text and video-text retrieval technologies. However, cross-modal retrieval between human motion sequences and text has not garnered sufficient attention despite the extensive application value it holds, such as aiding virtual reality applications in better understanding users' actions and language. This task presents several challenges, including joint modeling of the two modalities, demanding the understanding of person-centered information from text, and learning behavior features from 3D human motion sequences. Previous work on motion data modeling mainly relied on autoregressive feature extractors that may forget previous information, while we propose an innovative model that includes simple yet powerful transformer-based motion and text encoders, which can learn representations from the two different modalities and capture long-term dependencies. Furthermore, the overlap of the same atomic actions of different human motions can cause semantic conflicts, leading us to explore a new triplet loss function, MildTriple Loss. it leverages the similarity between samples in intra-modal space to guide soft-hard negative sample mining in the joint embedding space to train the triplet loss and reduce the violation caused by false negative samples. We evaluated our model and method on the latest HumanML3D and KIT Motion-Language datasets, achieving a 62.9\% recall for motion retrieval and a 71.5\% recall for text retrieval (based on R@10) on the HumanML3D dataset. Our code is available at https://github.com/eanson023/rehamot.
Emergent Cooperative Behavior in Distributed Target Tracking with Unknown Occlusions
Apr 21, 2023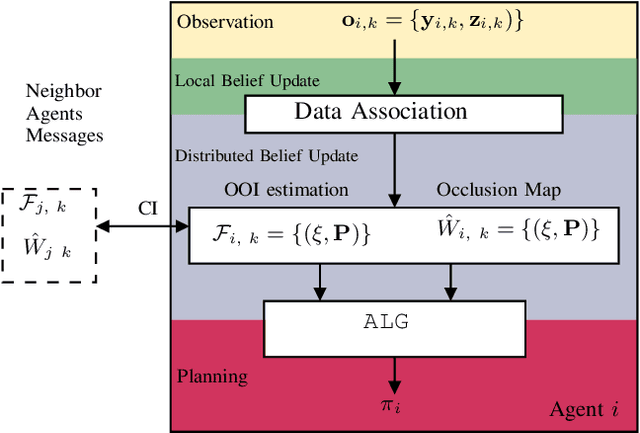
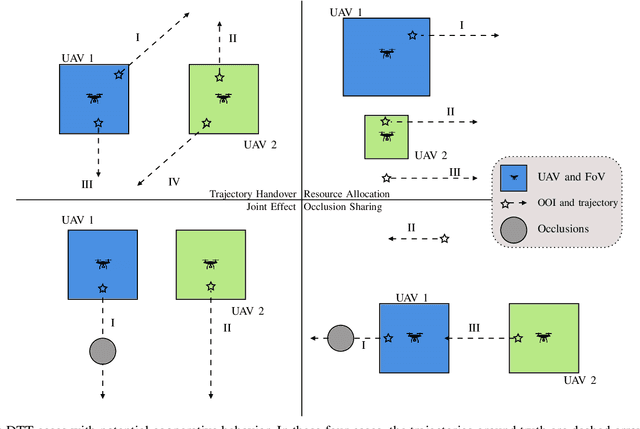
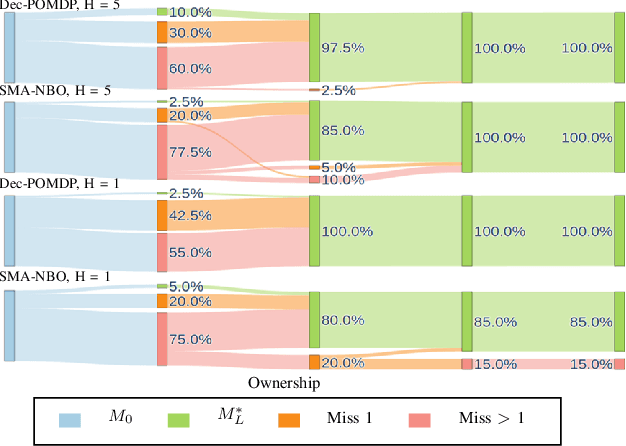
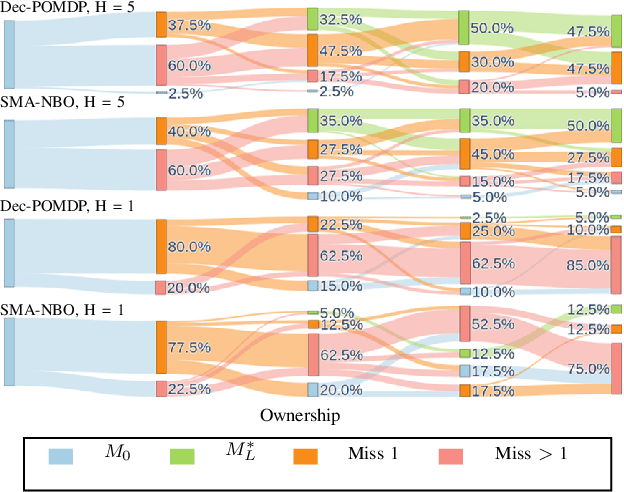
Tracking multiple moving objects of interest (OOI) with multiple robot systems (MRS) has been addressed by active sensing that maintains a shared belief of OOIs and plans the motion of robots to maximize the information quality. Mobility of robots enables the behavior of pursuing better visibility, which is constrained by sensor field of view (FoV) and occlusion objects. We first extend prior work to detect, maintain and share occlusion information explicitly, allowing us to generate occlusion-aware planning even if a priori semantic occlusion information is unavailable. The efficacy of active sensing approaches is often evaluated according to estimation error and information gain metrics. However, these metrics do not directly explain the level of cooperative behavior engendered by the active sensing algorithms. Next, we extract different emergent cooperative behaviors that stem from the same underlying algorithms but manifest differently under differing scenarios. In particular, we highlight and demonstrate three emergent behavior patterns in active sensing MRS: (i) Change of tracking responsibility between agents when tracking trajectories with divergent directions or due to a re-allocation of the resource among heterogeneous agents; (ii) Awareness of occlusions to a trajectory and temporal leave-and-return of the sensing agent; (iii) Sharing of local occlusion objects in MRS that subsequently improves the awareness of occlusion.
Analyzing Vietnamese Legal Questions Using Deep Neural Networks with Biaffine Classifiers
Apr 27, 2023In this paper, we propose using deep neural networks to extract important information from Vietnamese legal questions, a fundamental task towards building a question answering system in the legal domain. Given a legal question in natural language, the goal is to extract all the segments that contain the needed information to answer the question. We introduce a deep model that solves the task in three stages. First, our model leverages recent advanced autoencoding language models to produce contextual word embeddings, which are then combined with character-level and POS-tag information to form word representations. Next, bidirectional long short-term memory networks are employed to capture the relations among words and generate sentence-level representations. At the third stage, borrowing ideas from graph-based dependency parsing methods which provide a global view on the input sentence, we use biaffine classifiers to estimate the probability of each pair of start-end words to be an important segment. Experimental results on a public Vietnamese legal dataset show that our model outperforms the previous work by a large margin, achieving 94.79% in the F1 score. The results also prove the effectiveness of using contextual features extracted from pre-trained language models combined with other types of features such as character-level and POS-tag features when training on a limited dataset.
ST-GIN: An Uncertainty Quantification Approach in Traffic Data Imputation with Spatio-temporal Graph Attention and Bidirectional Recurrent United Neural Networks
May 10, 2023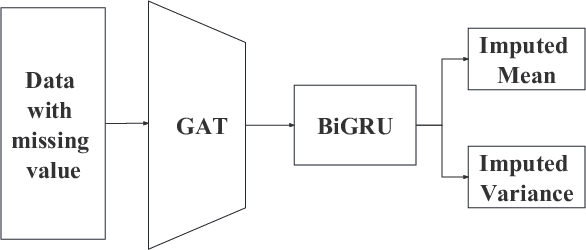
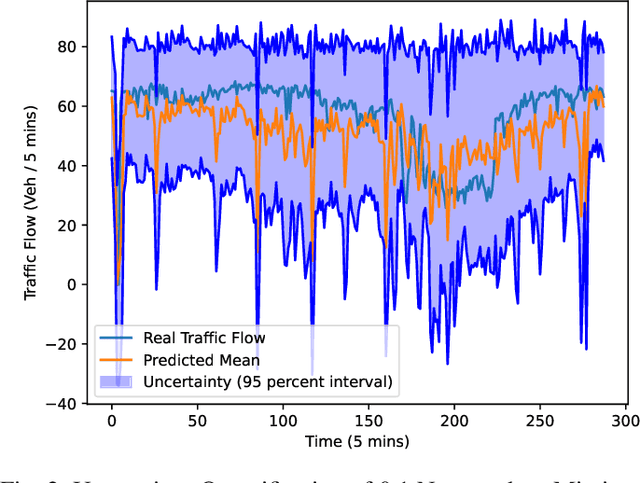
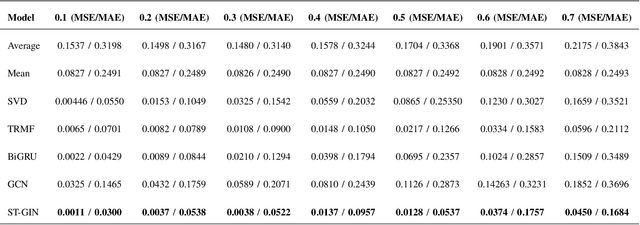
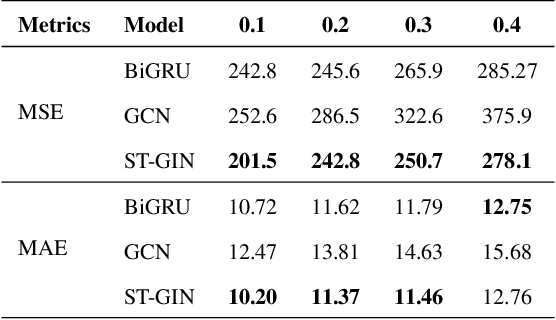
Traffic data serves as a fundamental component in both research and applications within intelligent transportation systems. However, real-world transportation data, collected from loop detectors or similar sources, often contain missing values (MVs), which can adversely impact associated applications and research. Instead of discarding this incomplete data, researchers have sought to recover these missing values through numerical statistics, tensor decomposition, and deep learning techniques. In this paper, we propose an innovative deep-learning approach for imputing missing data. A graph attention architecture is employed to capture the spatial correlations present in traffic data, while a bidirectional neural network is utilized to learn temporal information. Experimental results indicate that our proposed method outperforms all other benchmark techniques, thus demonstrating its effectiveness.
HyperE2VID: Improving Event-Based Video Reconstruction via Hypernetworks
May 10, 2023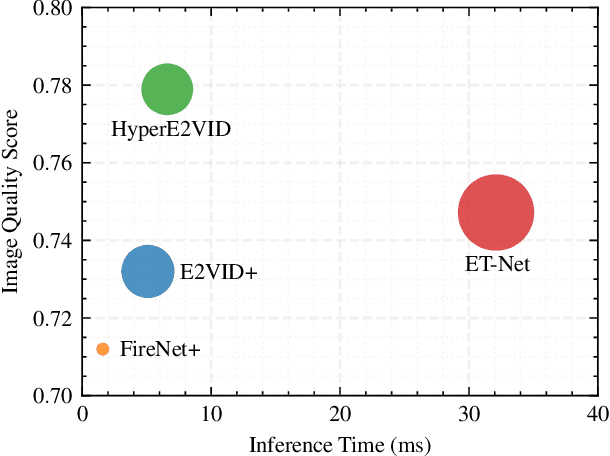
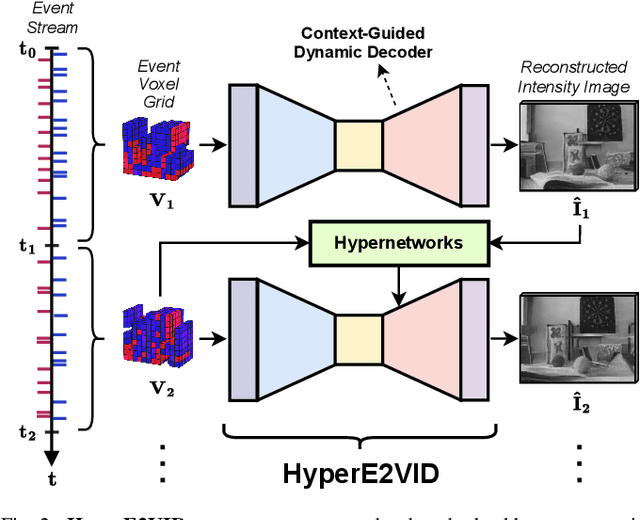
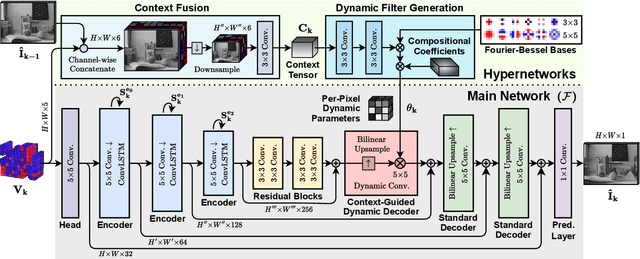
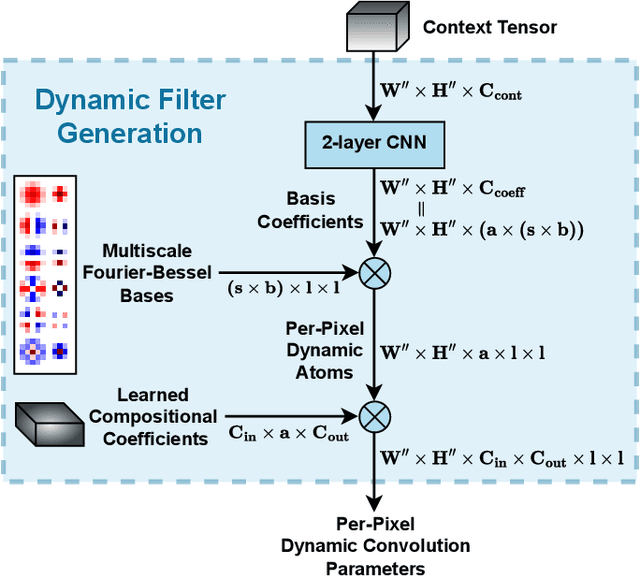
Event-based cameras are becoming increasingly popular for their ability to capture high-speed motion with low latency and high dynamic range. However, generating videos from events remains challenging due to the highly sparse and varying nature of event data. To address this, in this study, we propose HyperE2VID, a dynamic neural network architecture for event-based video reconstruction. Our approach uses hypernetworks and dynamic convolutions to generate per-pixel adaptive filters guided by a context fusion module that combines information from event voxel grids and previously reconstructed intensity images. We also employ a curriculum learning strategy to train the network more robustly. Experimental results demonstrate that HyperE2VID achieves better reconstruction quality with fewer parameters and faster inference time than the state-of-the-art methods.
Decker: Double Check with Heterogeneous Knowledge for Commonsense Fact Verification
May 10, 2023

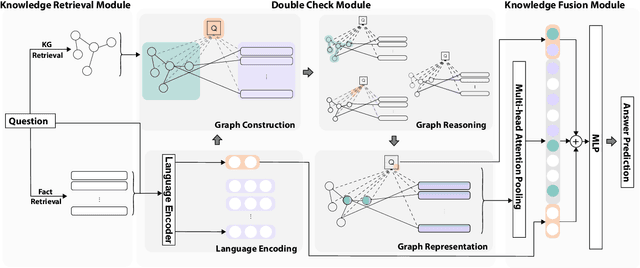
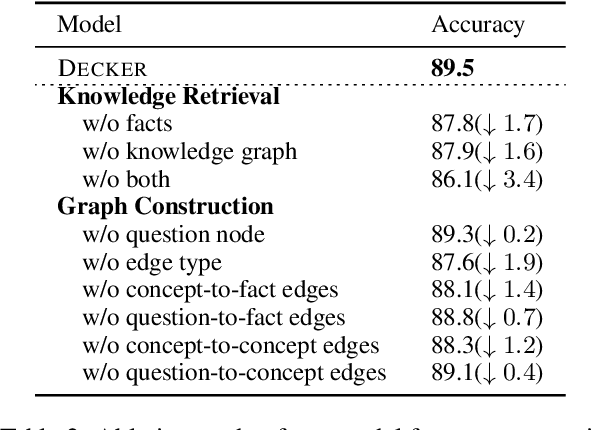
Commonsense fact verification, as a challenging branch of commonsense question-answering (QA), aims to verify through facts whether a given commonsense claim is correct or not. Answering commonsense questions necessitates a combination of knowledge from various levels. However, existing studies primarily rest on grasping either unstructured evidence or potential reasoning paths from structured knowledge bases, yet failing to exploit the benefits of heterogeneous knowledge simultaneously. In light of this, we propose Decker, a commonsense fact verification model that is capable of bridging heterogeneous knowledge by uncovering latent relationships between structured and unstructured knowledge. Experimental results on two commonsense fact verification benchmark datasets, CSQA2.0 and CREAK demonstrate the effectiveness of our Decker and further analysis verifies its capability to seize more precious information through reasoning.