 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multimodal Graph Transformer for Multimodal Question Answering
Apr 30, 2023
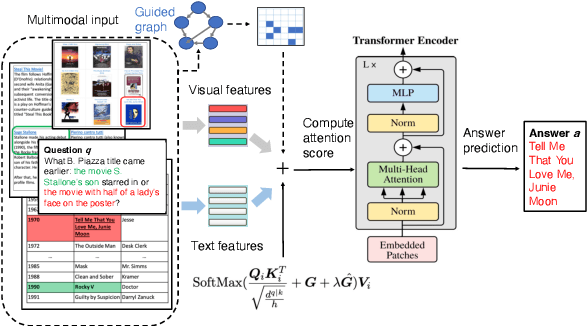
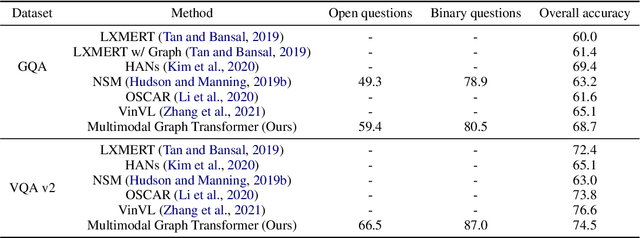
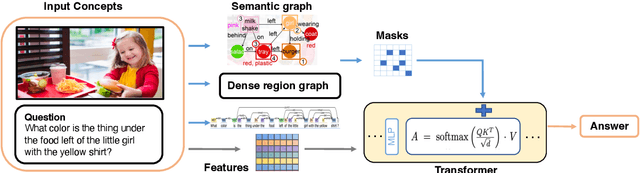
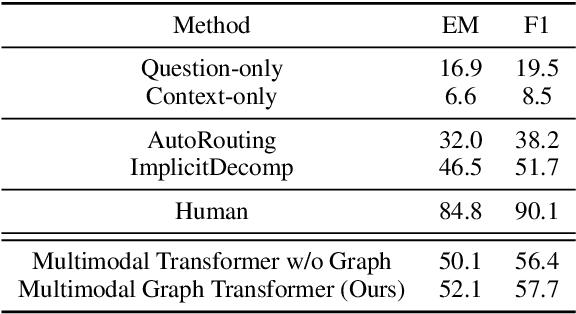
Despite the success of Transformer models in vision and language tasks, they often learn knowledge from enormous data implicitly and cannot utilize structured input data directly. On the other hand, structured learning approaches such as graph neural networks (GNNs) that integrate prior information can barely compete with Transformer models. In this work, we aim to benefit from both worlds and propose a novel Multimodal Graph Transformer for question answering tasks that requires performing reasoning across multiple modalities. We introduce a graph-involved plug-and-play quasi-attention mechanism to incorporate multimodal graph information, acquired from text and visual data, to the vanilla self-attention as effective prior. In particular, we construct the text graph, dense region graph, and semantic graph to generate adjacency matrices, and then compose them with input vision and language features to perform downstream reasoning. Such a way of regularizing self-attention with graph information significantly improves the inferring ability and helps align features from different modalities. We validate the effectiveness of Multimodal Graph Transformer over its Transformer baselines on GQA, VQAv2, and MultiModalQA datasets.
Fast Distributed Inference Serving for Large Language Models
May 10, 2023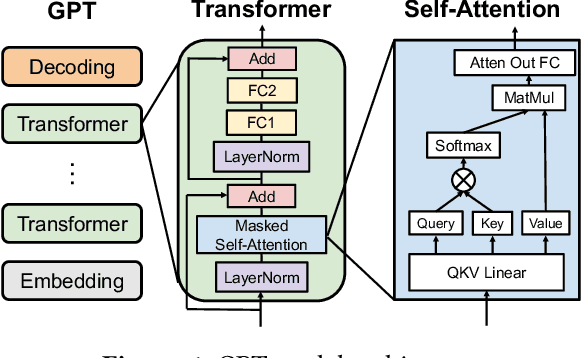
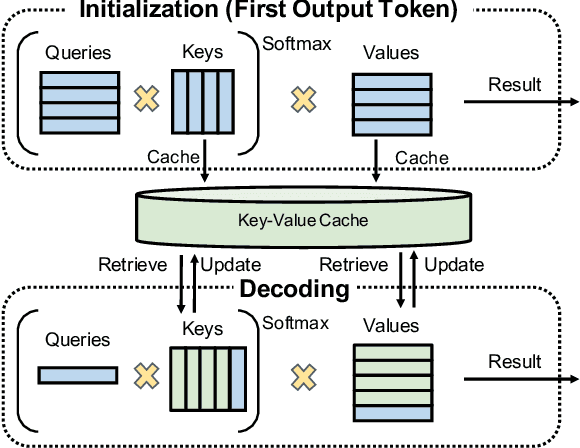
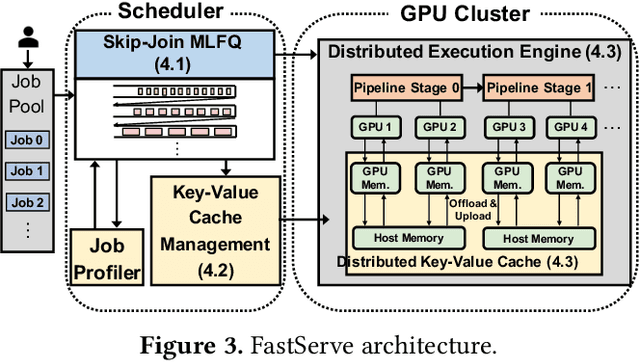
Large language models (LLMs) power a new generation of interactive AI applications exemplified by ChatGPT. The interactive nature of these applications demand low job completion time (JCT) for model inference. Existing LLM serving systems use run-to-completion processing for inference jobs, which suffers from head-of-line blocking and long JCT. We present FastServe, a distributed inference serving system for LLMs. FastServe exploits the autoregressive pattern of LLM inference to enable preemption at the granularity of each output token. FastServe uses preemptive scheduling to minimize JCT with a novel skip-join Multi-Level Feedback Queue scheduler. Based on the new semi information-agnostic setting of LLM inference, the scheduler leverages the input length information to assign an appropriate initial queue for each arrival job to join. The higher priority queues than the joined queue are skipped to reduce demotions. We design an efficient GPU memory management mechanism that proactively offloads and uploads intermediate states between GPU memory and host memory for LLM inference. We build a system prototype of FastServe based on NVIDIA FasterTransformer. Experimental results show that compared to the state-of-the-art solution Orca, FastServe improves the average and tail JCT by up to 5.1$\times$ and 6.4$\times$, respectively.
Generating medically-accurate summaries of patient-provider dialogue: A multi-stage approach using large language models
May 10, 2023
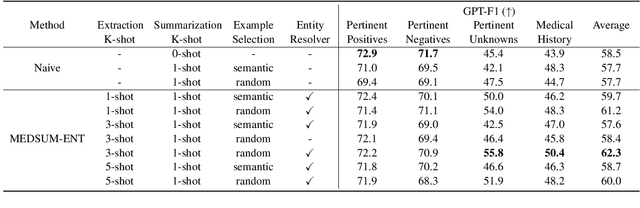
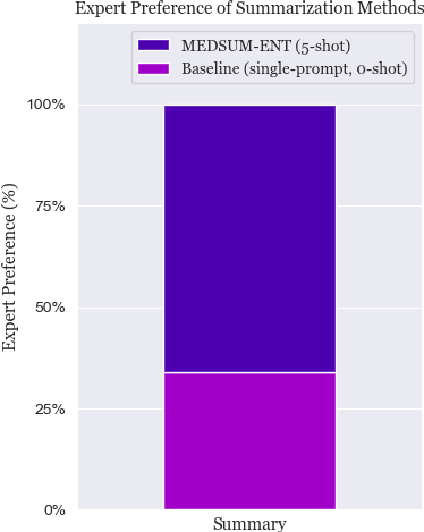
A medical provider's summary of a patient visit serves several critical purposes, including clinical decision-making, facilitating hand-offs between providers, and as a reference for the patient. An effective summary is required to be coherent and accurately capture all the medically relevant information in the dialogue, despite the complexity of patient-generated language. Even minor inaccuracies in visit summaries (for example, summarizing "patient does not have a fever" when a fever is present) can be detrimental to the outcome of care for the patient. This paper tackles the problem of medical conversation summarization by discretizing the task into several smaller dialogue-understanding tasks that are sequentially built upon. First, we identify medical entities and their affirmations within the conversation to serve as building blocks. We study dynamically constructing few-shot prompts for tasks by conditioning on relevant patient information and use GPT-3 as the backbone for our experiments. We also develop GPT-derived summarization metrics to measure performance against reference summaries quantitatively. Both our human evaluation study and metrics for medical correctness show that summaries generated using this approach are clinically accurate and outperform the baseline approach of summarizing the dialog in a zero-shot, single-prompt setting.
DiscoPrompt: Path Prediction Prompt Tuning for Implicit Discourse Relation Recognition
May 06, 2023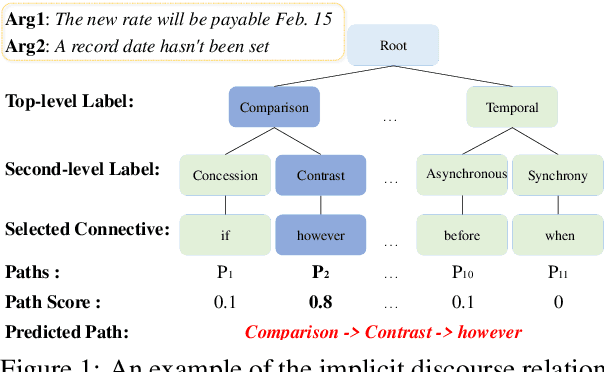
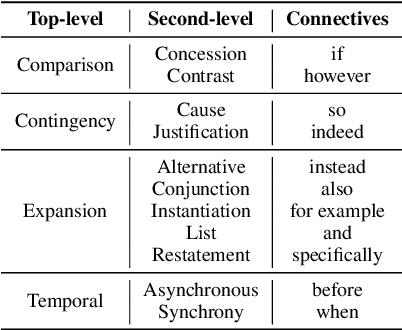
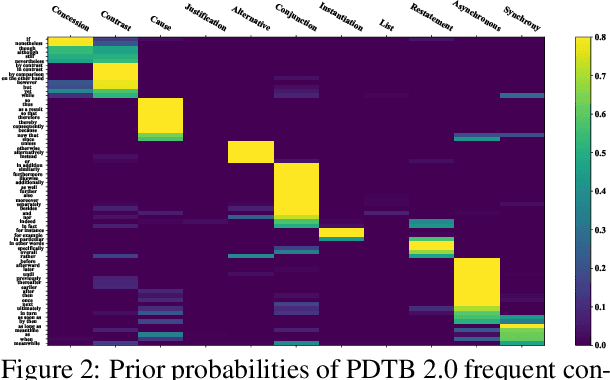
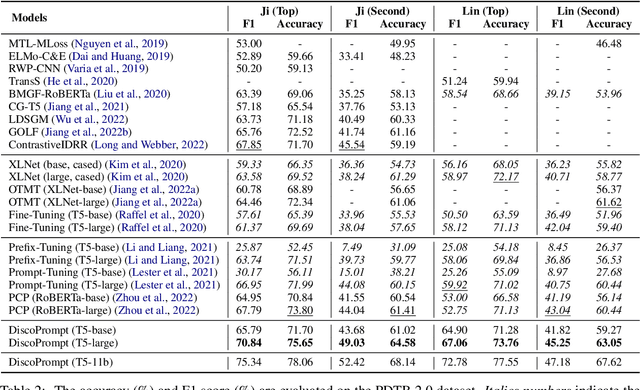
Implicit Discourse Relation Recognition (IDRR) is a sophisticated and challenging task to recognize the discourse relations between the arguments with the absence of discourse connectives. The sense labels for each discourse relation follow a hierarchical classification scheme in the annotation process (Prasad et al., 2008), forming a hierarchy structure. Most existing works do not well incorporate the hierarchy structure but focus on the syntax features and the prior knowledge of connectives in the manner of pure text classification. We argue that it is more effective to predict the paths inside the hierarchical tree (e.g., "Comparison -> Contrast -> however") rather than flat labels (e.g., Contrast) or connectives (e.g., however). We propose a prompt-based path prediction method to utilize the interactive information and intrinsic senses among the hierarchy in IDRR. This is the first work that injects such structure information into pre-trained language models via prompt tuning, and the performance of our solution shows significant and consistent improvement against competitive baselines.
Locate and Beamform: Two-dimensional Locating All-neural Beamformer for Multi-channel Speech Separation
May 18, 2023
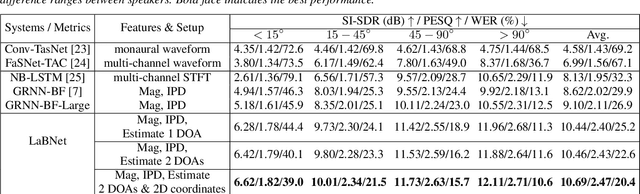
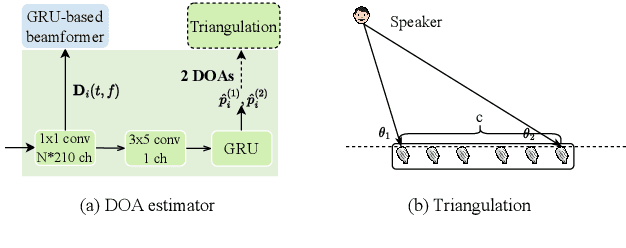
Recently, stunning improvements on multi-channel speech separation have been achieved by neural beamformers when direction information is available. However, most of them neglect to utilize speaker's 2-dimensional (2D) location cues contained in mixture signal, which limits the performance when two sources come from close directions. In this paper, we propose an end-to-end beamforming network for 2D location guided speech separation merely given mixture signal. It first estimates discriminable direction and 2D location cues, which imply directions the sources come from in multi views of microphones and their 2D coordinates. These cues are then integrated into location-aware neural beamformer, thus allowing accurate reconstruction of two sources' speech signals. Experiments show that our proposed model not only achieves a comprehensive decent improvement compared to baseline systems, but avoids inferior performance on spatial overlapping cases.
Retrieving Texts based on Abstract Descriptions
May 21, 2023


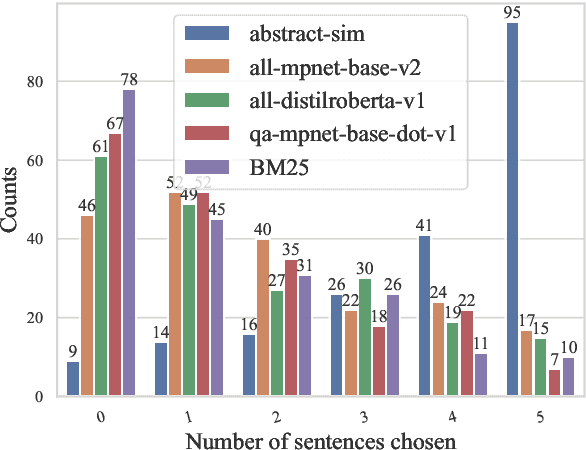
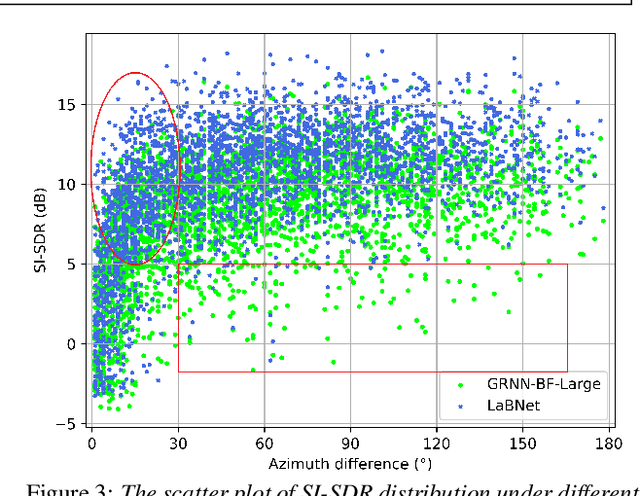
In this work, we aim to connect two research areas: instruction models and retrieval-based models. While instruction-tuned Large Language Models (LLMs) excel at extracting information from text, they are not suitable for semantic retrieval. Similarity search over embedding vectors allows to index and query vectors, but the similarity reflected in the embedding is sub-optimal for many use cases. We identify the task of retrieving sentences based on abstract descriptions of their content. We demonstrate the inadequacy of current text embeddings and propose an alternative model that significantly improves when used in standard nearest neighbor search. The model is trained using positive and negative pairs sourced through prompting an a large language model (LLM). While it is easy to source the training material from an LLM, the retrieval task cannot be performed by the LLM directly. This demonstrates that data from LLMs can be used not only for distilling more efficient specialized models than the original LLM, but also for creating new capabilities not immediately possible using the original model.
Target-Aware Spatio-Temporal Reasoning via Answering Questions in Dynamics Audio-Visual Scenarios
May 21, 2023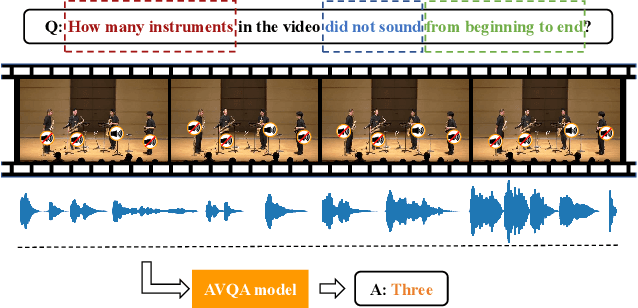

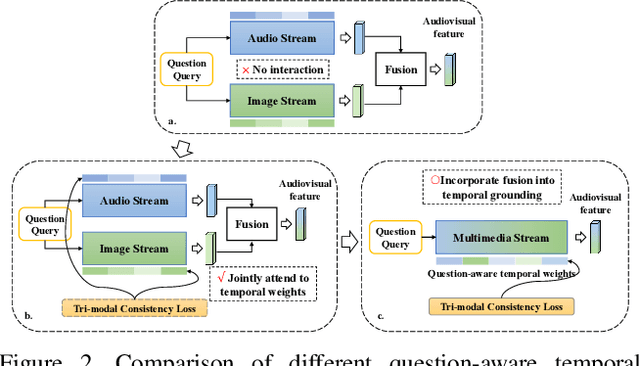

Audio-visual question answering (AVQA) is a challenging task that requires multistep spatio-temporal reasoning over multimodal contexts. To achieve scene understanding ability similar to humans, the AVQA task presents specific challenges, including effectively fusing audio and visual information and capturing question-relevant audio-visual features while maintaining temporal synchronization. This paper proposes a Target-aware Joint Spatio-Temporal Grounding Network for AVQA to address these challenges. The proposed approach has two main components: the Target-aware Spatial Grounding module, the Tri-modal consistency loss and corresponding Joint audio-visual temporal grounding module. The Target-aware module enables the model to focus on audio-visual cues relevant to the inquiry subject by exploiting the explicit semantics of text modality. The Tri-modal consistency loss facilitates the interaction between audio and video during question-aware temporal grounding and incorporates fusion within a simpler single-stream architecture. Experimental results on the MUSIC-AVQA dataset demonstrate the effectiveness and superiority of the proposed method over existing state-of-the-art methods. Our code will be availiable soon.
Conditional Generative Modeling is All You Need for Marked Temporal Point Processes
May 21, 2023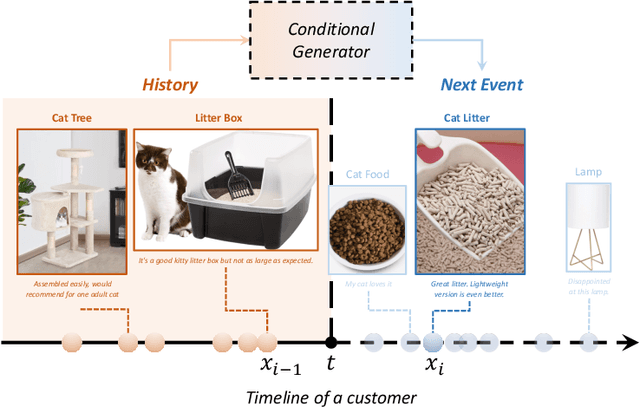

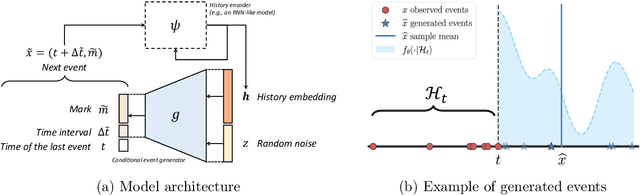
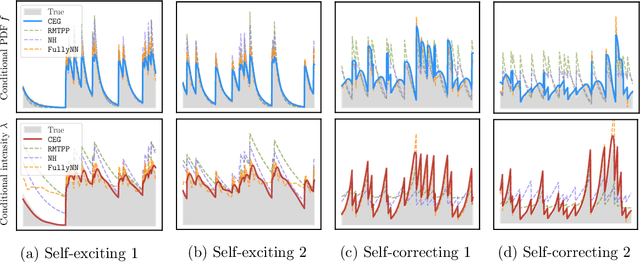
Recent advancements in generative modeling have made it possible to generate high-quality content from context information, but a key question remains: how to teach models to know when to generate content? To answer this question, this study proposes a novel event generative model that draws its statistical intuition from marked temporal point processes, and offers a clean, flexible, and computationally efficient solution for a wide range of applications involving multi-dimensional marks. We aim to capture the distribution of the point process without explicitly specifying the conditional intensity or probability density. Instead, we use a conditional generator that takes the history of events as input and generates the high-quality subsequent event that is likely to occur given the prior observations. The proposed framework offers a host of benefits, including exceptional efficiency in learning the model and generating samples, as well as considerable representational power to capture intricate dynamics in multi- or even high-dimensional event space. Our numerical results demonstrate superior performance compared to other state-of-the-art baselines.
GMD: Controllable Human Motion Synthesis via Guided Diffusion Models
May 21, 2023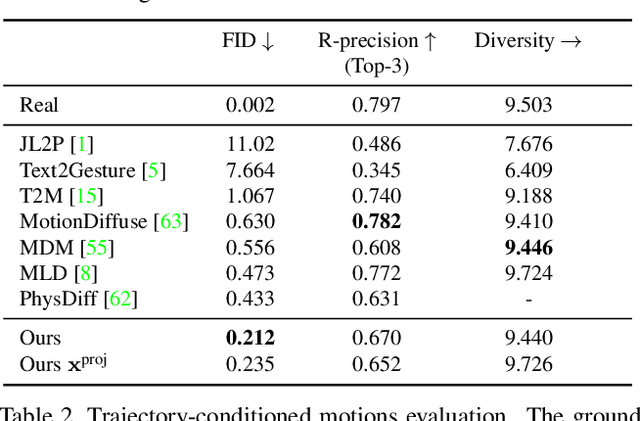
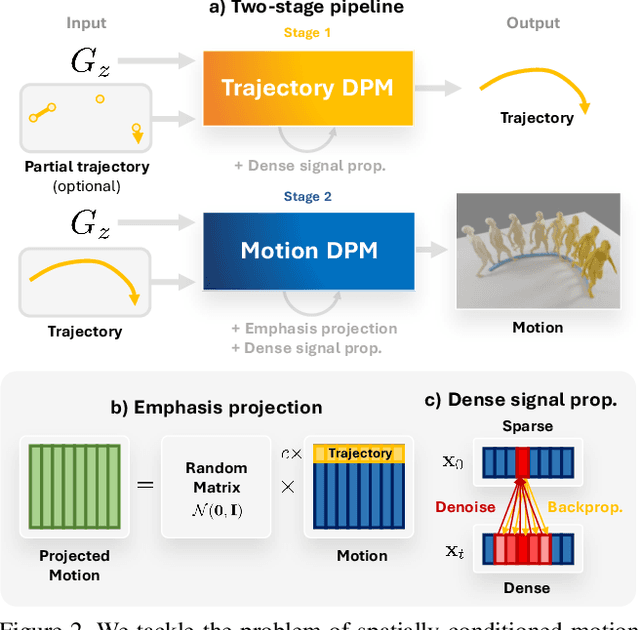
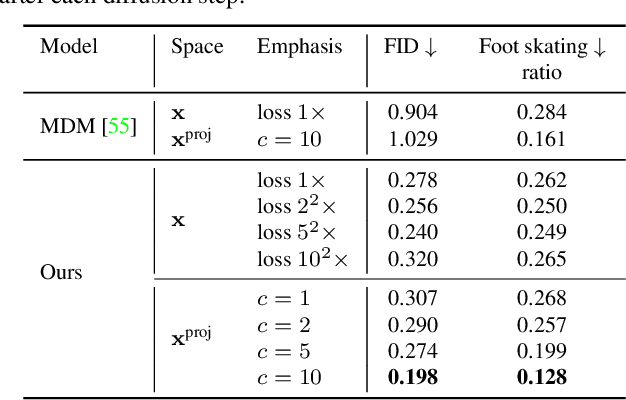
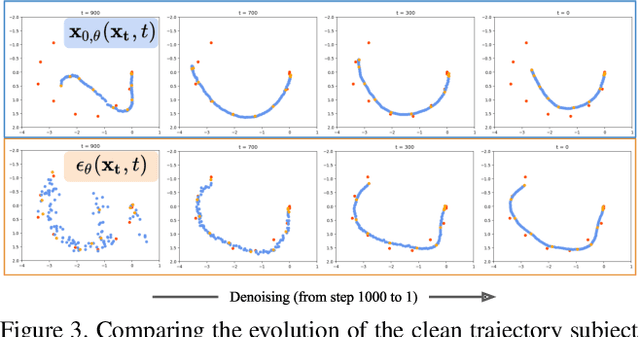
Denoising diffusion models have shown great promise in human motion synthesis conditioned on natural language descriptions. However, it remains a challenge to integrate spatial constraints, such as pre-defined motion trajectories and obstacles, which is essential for bridging the gap between isolated human motion and its surrounding environment. To address this issue, we propose Guided Motion Diffusion (GMD), a method that incorporates spatial constraints into the motion generation process. Specifically, we propose an effective feature projection scheme that largely enhances the coherency between spatial information and local poses. Together with a new imputation formulation, the generated motion can reliably conform to spatial constraints such as global motion trajectories. Furthermore, given sparse spatial constraints (e.g. sparse keyframes), we introduce a new dense guidance approach that utilizes the denoiser of diffusion models to turn a sparse signal into denser signals, effectively guiding the generation motion to the given constraints. The extensive experiments justify the development of GMD, which achieves a significant improvement over state-of-the-art methods in text-based motion generation while being able to control the synthesized motions with spatial constraints.
FlowText: Synthesizing Realistic Scene Text Video with Optical Flow Estimation
May 05, 2023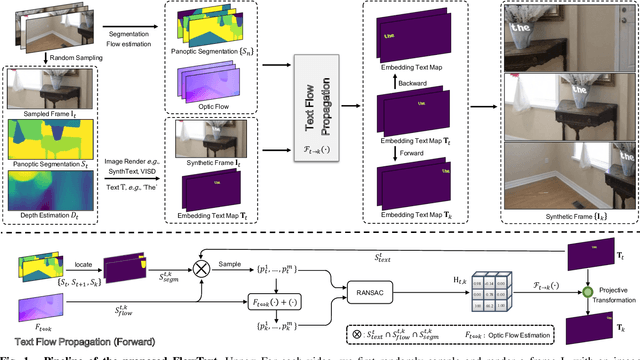
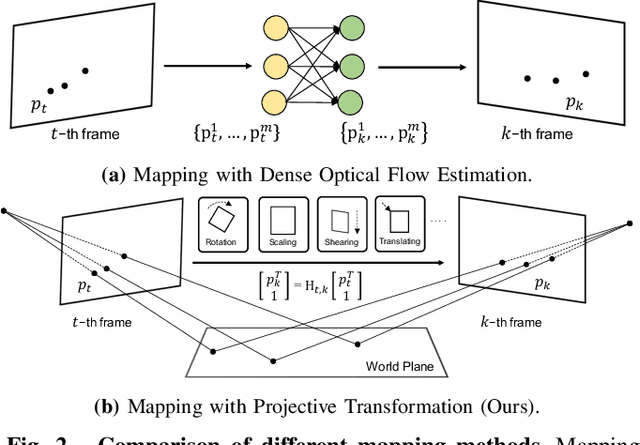

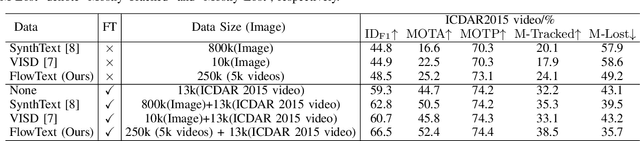
Current video text spotting methods can achieve preferable performance, powered with sufficient labeled training data. However, labeling data manually is time-consuming and labor-intensive. To overcome this, using low-cost synthetic data is a promising alternative. This paper introduces a novel video text synthesis technique called FlowText, which utilizes optical flow estimation to synthesize a large amount of text video data at a low cost for training robust video text spotters. Unlike existing methods that focus on image-level synthesis, FlowText concentrates on synthesizing temporal information of text instances across consecutive frames using optical flow. This temporal information is crucial for accurately tracking and spotting text in video sequences, including text movement, distortion, appearance, disappearance, shelter, and blur. Experiments show that combining general detectors like TransDETR with the proposed FlowText produces remarkable results on various datasets, such as ICDAR2015video and ICDAR2013video. Code is available at https://github.com/callsys/FlowText.