 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-source Education Knowledge Graph Construction and Fusion for College Curricula
May 08, 2023
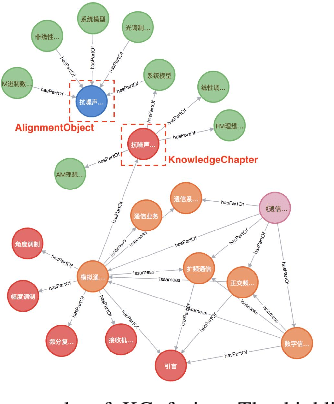
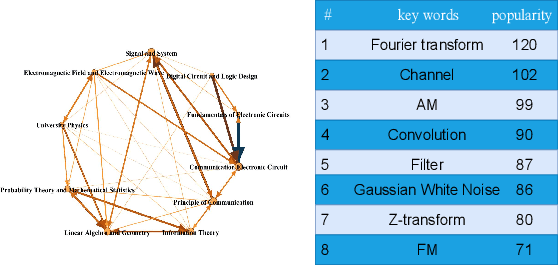
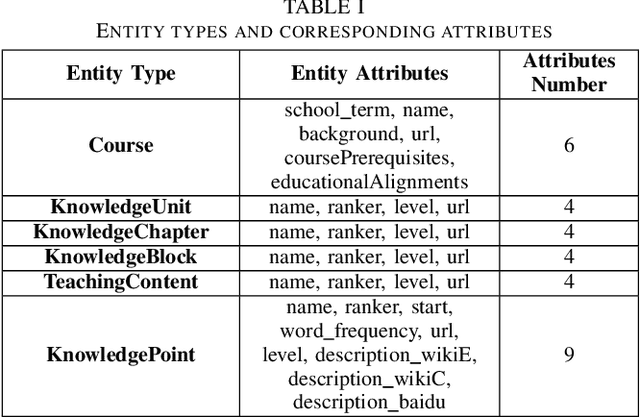

The field of education has undergone a significant transformation due to the rapid advancements in Artificial Intelligence (AI). Among the various AI technologies, Knowledge Graphs (KGs) using Natural Language Processing (NLP) have emerged as powerful visualization tools for integrating multifaceted information. In the context of university education, the availability of numerous specialized courses and complicated learning resources often leads to inferior learning outcomes for students. In this paper, we propose an automated framework for knowledge extraction, visual KG construction, and graph fusion, tailored for the major of Electronic Information. Furthermore, we perform data analysis to investigate the correlation degree and relationship between courses, rank hot knowledge concepts, and explore the intersection of courses. Our objective is to enhance the learning efficiency of students and to explore new educational paradigms enabled by AI. The proposed framework is expected to enable students to better understand and appreciate the intricacies of their field of study by providing them with a comprehensive understanding of the relationships between the various concepts and courses.
Language Independent Neuro-Symbolic Semantic Parsing for Form Understanding
May 08, 2023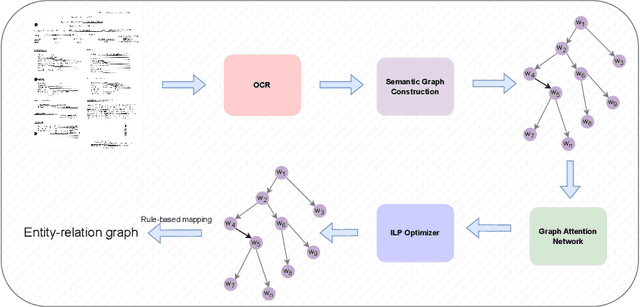
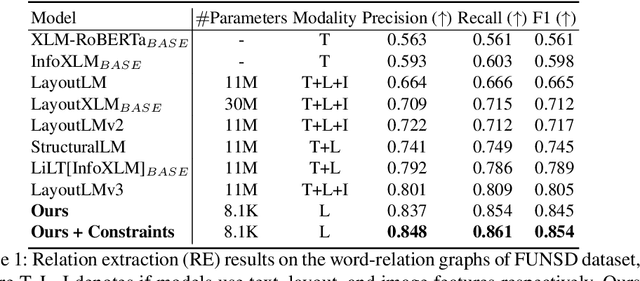
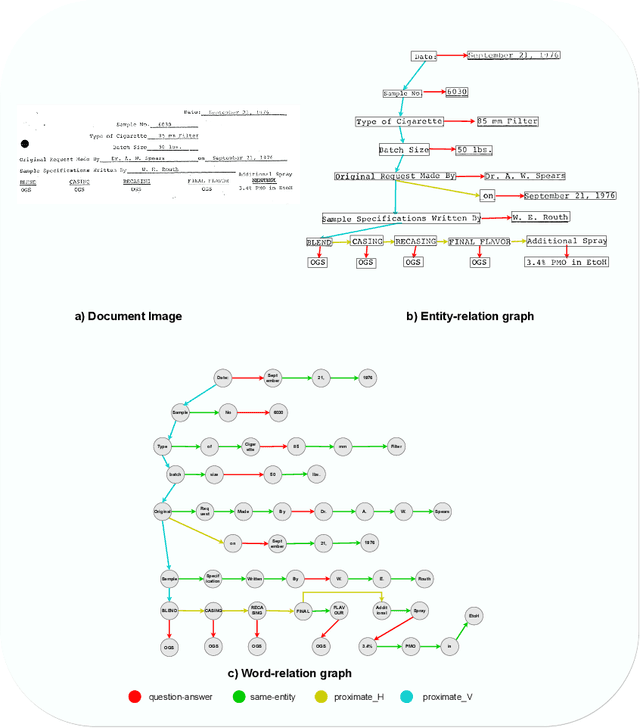
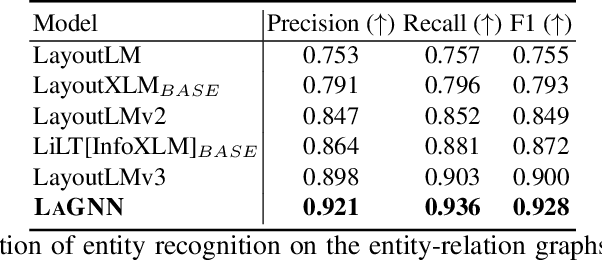
Recent works on form understanding mostly employ multimodal transformers or large-scale pre-trained language models. These models need ample data for pre-training. In contrast, humans can usually identify key-value pairings from a form only by looking at layouts, even if they don't comprehend the language used. No prior research has been conducted to investigate how helpful layout information alone is for form understanding. Hence, we propose a unique entity-relation graph parsing method for scanned forms called LAGNN, a language-independent Graph Neural Network model. Our model parses a form into a word-relation graph in order to identify entities and relations jointly and reduce the time complexity of inference. This graph is then transformed by deterministic rules into a fully connected entity-relation graph. Our model simply takes into account relative spacing between bounding boxes from layout information to facilitate easy transfer across languages. To further improve the performance of LAGNN, and achieve isomorphism between entity-relation graphs and word-relation graphs, we use integer linear programming (ILP) based inference. Code is publicly available at https://github.com/Bhanu068/LAGNN
Link Prediction without Graph Neural Networks
May 23, 2023
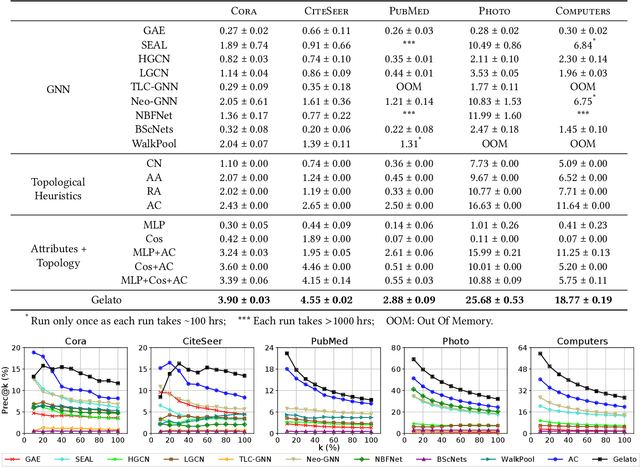
Link prediction, which consists of predicting edges based on graph features, is a fundamental task in many graph applications. As for several related problems, Graph Neural Networks (GNNs), which are based on an attribute-centric message-passing paradigm, have become the predominant framework for link prediction. GNNs have consistently outperformed traditional topology-based heuristics, but what contributes to their performance? Are there simpler approaches that achieve comparable or better results? To answer these questions, we first identify important limitations in how GNN-based link prediction methods handle the intrinsic class imbalance of the problem -- due to the graph sparsity -- in their training and evaluation. Moreover, we propose Gelato, a novel topology-centric framework that applies a topological heuristic to a graph enhanced by attribute information via graph learning. Our model is trained end-to-end with an N-pair loss on an unbiased training set to address class imbalance. Experiments show that Gelato is 145% more accurate, trains 11 times faster, infers 6,000 times faster, and has less than half of the trainable parameters compared to state-of-the-art GNNs for link prediction.
Not All Image Regions Matter: Masked Vector Quantization for Autoregressive Image Generation
May 23, 2023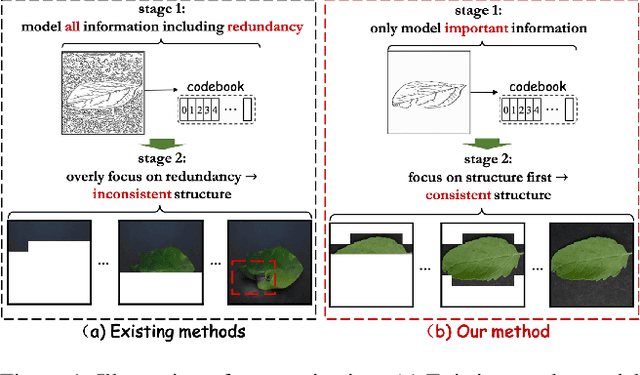
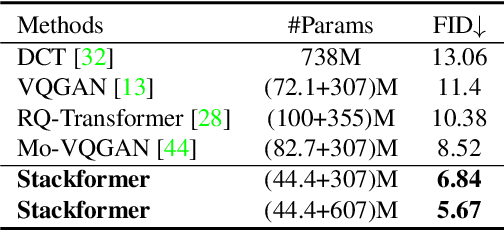
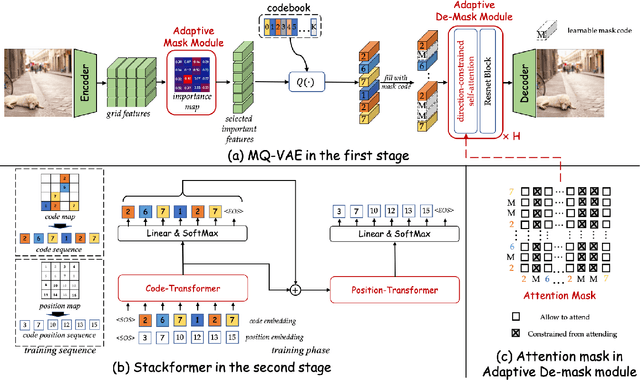
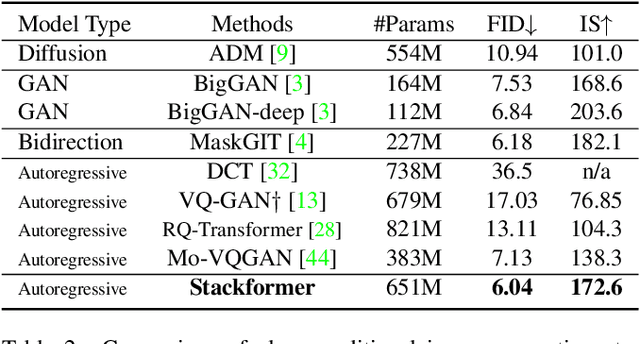
Existing autoregressive models follow the two-stage generation paradigm that first learns a codebook in the latent space for image reconstruction and then completes the image generation autoregressively based on the learned codebook. However, existing codebook learning simply models all local region information of images without distinguishing their different perceptual importance, which brings redundancy in the learned codebook that not only limits the next stage's autoregressive model's ability to model important structure but also results in high training cost and slow generation speed. In this study, we borrow the idea of importance perception from classical image coding theory and propose a novel two-stage framework, which consists of Masked Quantization VAE (MQ-VAE) and Stackformer, to relieve the model from modeling redundancy. Specifically, MQ-VAE incorporates an adaptive mask module for masking redundant region features before quantization and an adaptive de-mask module for recovering the original grid image feature map to faithfully reconstruct the original images after quantization. Then, Stackformer learns to predict the combination of the next code and its position in the feature map. Comprehensive experiments on various image generation validate our effectiveness and efficiency. Code will be released at https://github.com/CrossmodalGroup/MaskedVectorQuantization.
Self-Polish: Enhance Reasoning in Large Language Models via Problem Refinement
May 23, 2023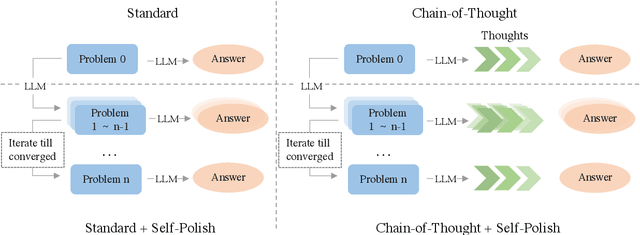
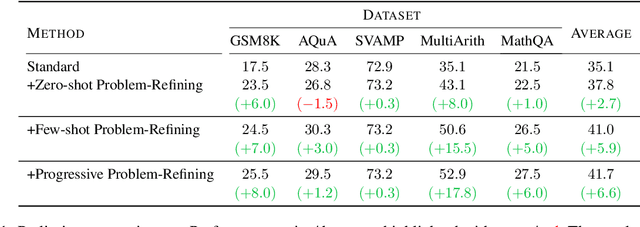

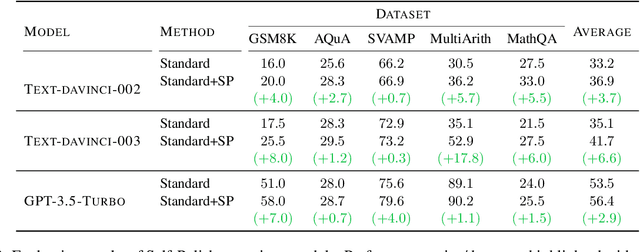
Prompting methods such as Chain-of-Thought (CoT) have shed new light on enhancing the reasoning capabilities of large language models, and researchers have extensively explored the generation process of rationales and answers. However, they have overlooked the potential challenges posed by the poor quality of reasoning problems, which may influence the reasoning performance significantly. In this work, we propose Self-Polish (SP), a novel method that facilitates the model's problem-solving process by prompting them to progressively refine the given problems to be more comprehensible and solvable. Specifically, the method teaches models to eliminate irrelevant information, rearrange the logic structure and organize local conditions into new ones parallelly. SP is orthogonal to all other prompting methods, making it convenient to integrate with state-of-the-art techniques for further improvement. We conduct thorough experiments on five benchmarks to illustrate the effectiveness of the proposed method. For example, with Text-davinci-003, our method boosts the performance of standard few-shot prompting by $8.0\%$ on GSM8K and $17.8\%$ on MultiArith; it also improves the performance of CoT by $6.0\%$ on GSM8K and $6.0\%$ on MathQA, respectively. Furthermore, our method also showcases impressive performance on robustness evaluation.
Layer-wise Adaptive Step-Sizes for Stochastic First-Order Methods for Deep Learning
May 23, 2023

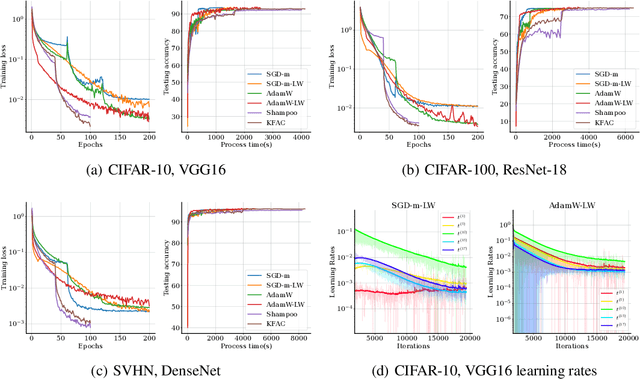

We propose a new per-layer adaptive step-size procedure for stochastic first-order optimization methods for minimizing empirical loss functions in deep learning, eliminating the need for the user to tune the learning rate (LR). The proposed approach exploits the layer-wise stochastic curvature information contained in the diagonal blocks of the Hessian in deep neural networks (DNNs) to compute adaptive step-sizes (i.e., LRs) for each layer. The method has memory requirements that are comparable to those of first-order methods, while its per-iteration time complexity is only increased by an amount that is roughly equivalent to an additional gradient computation. Numerical experiments show that SGD with momentum and AdamW combined with the proposed per-layer step-sizes are able to choose effective LR schedules and outperform fine-tuned LR versions of these methods as well as popular first-order and second-order algorithms for training DNNs on Autoencoder, Convolutional Neural Network (CNN) and Graph Convolutional Network (GCN) models. Finally, it is proved that an idealized version of SGD with the layer-wise step sizes converges linearly when using full-batch gradients.
VIP5: Towards Multimodal Foundation Models for Recommendation
May 23, 2023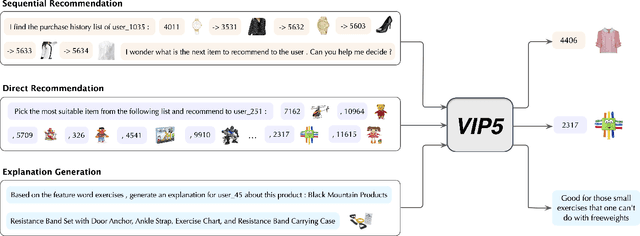
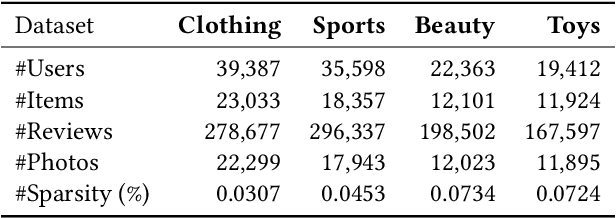
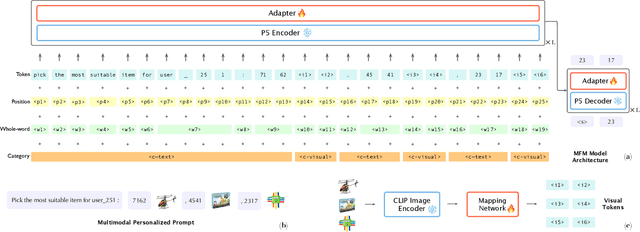
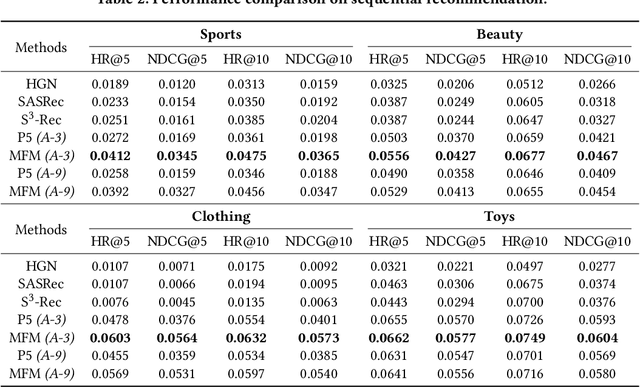
Computer Vision (CV), Natural Language Processing (NLP), and Recommender Systems (RecSys) are three prominent AI applications that have traditionally developed independently, resulting in disparate modeling and engineering methodologies. This has impeded the ability for these fields to directly benefit from each other's advancements. With the increasing availability of multimodal data on the web, there is a growing need to consider various modalities when making recommendations for users. With the recent emergence of foundation models, large language models have emerged as a potential general-purpose interface for unifying different modalities and problem formulations. In light of this, we propose the development of a multimodal foundation model by considering both visual and textual modalities under the P5 recommendation paradigm (VIP5) to unify various modalities and recommendation tasks. This will enable the processing of vision, language, and personalization information in a shared architecture for improved recommendations. To achieve this, we introduce multimodal personalized prompts to accommodate multiple modalities under a shared format. Additionally, we propose a parameter-efficient training method for foundation models, which involves freezing the backbone and fine-tuning lightweight adapters, resulting in improved recommendation performance and increased efficiency in terms of training time and memory usage.
ConGraT: Self-Supervised Contrastive Pretraining for Joint Graph and Text Embeddings
May 23, 2023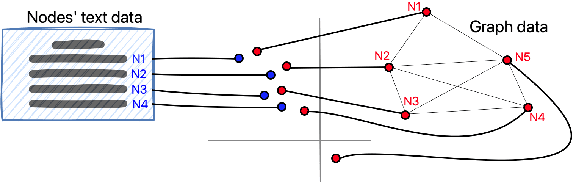
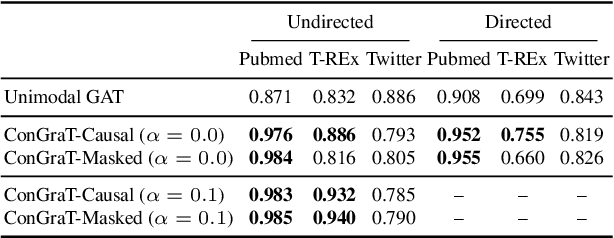
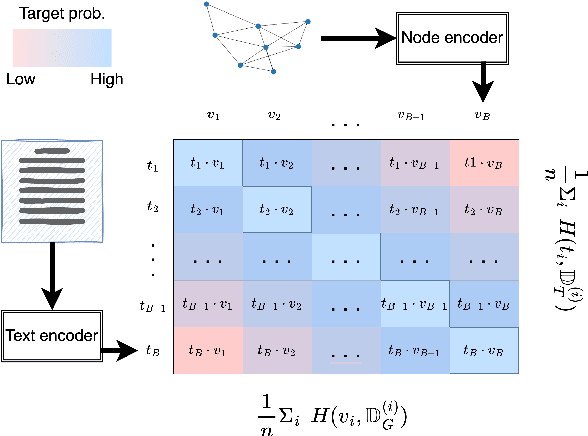
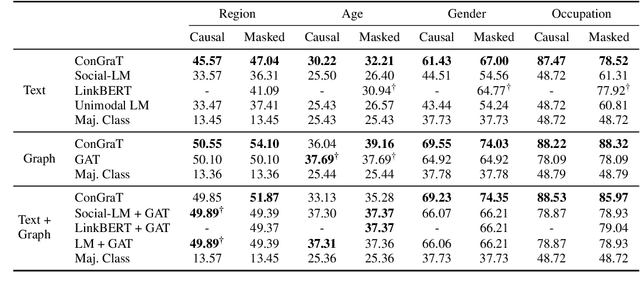
We propose ConGraT(Contrastive Graph-Text pretraining), a general, self-supervised method for jointly learning separate representations of texts and nodes in a parent (or ``supervening'') graph, where each text is associated with one of the nodes. Datasets fitting this paradigm are common, from social media (users and posts), to citation networks over articles, to link graphs over web pages. We expand on prior work by providing a general, self-supervised, joint pretraining method, one which does not depend on particular dataset structure or a specific task. Our method uses two separate encoders for graph nodes and texts, which are trained to align their representations within a common latent space. Training uses a batch-wise contrastive learning objective inspired by prior work on joint text and image encoding. As graphs are more structured objects than images, we also extend the training objective to incorporate information about node similarity and plausible next guesses in matching nodes and texts. Experiments on various datasets reveal that ConGraT outperforms strong baselines on various downstream tasks, including node and text category classification and link prediction. Code and certain datasets are available at https://github.com/wwbrannon/congrat.
Physics of Language Models: Part 1, Context-Free Grammar
May 23, 2023
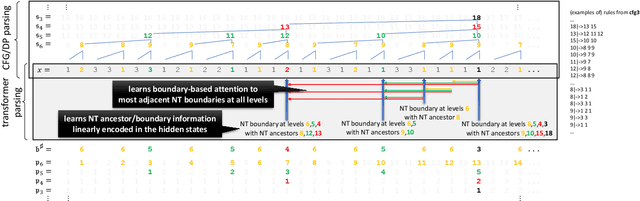
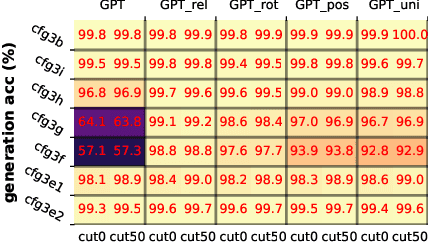
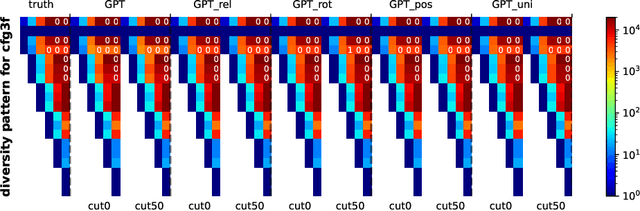
We design experiments to study $\textit{how}$ generative language models, like GPT, learn context-free grammars (CFGs) -- diverse language systems with a tree-like structure capturing many aspects of natural languages, programs, and human logics. CFGs are as hard as pushdown automata, and can be ambiguous so that verifying if a string satisfies the rules requires dynamic programming. We construct synthetic data and demonstrate that even for very challenging CFGs, pre-trained transformers can learn to generate sentences with near-perfect accuracy and remarkable $\textit{diversity}$. More importantly, we delve into the $\textit{physical principles}$ behind how transformers learns CFGs. We discover that the hidden states within the transformer implicitly and $\textit{precisely}$ encode the CFG structure (such as putting tree node information exactly on the subtree boundary), and learn to form "boundary to boundary" attentions that resemble dynamic programming. We also cover some extension of CFGs as well as the robustness aspect of transformers against grammar mistakes. Overall, our research provides a comprehensive and empirical understanding of how transformers learn CFGs, and reveals the physical mechanisms utilized by transformers to capture the structure and rules of languages.
Improving Stability and Performance of Spiking Neural Networks through Enhancing Temporal Consistency
May 23, 2023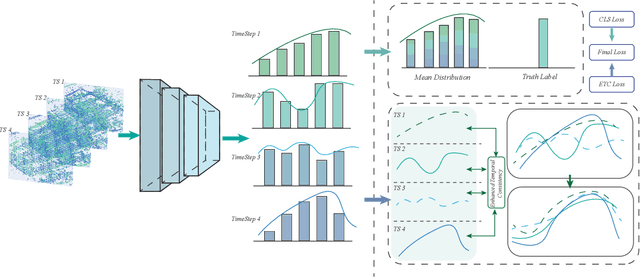
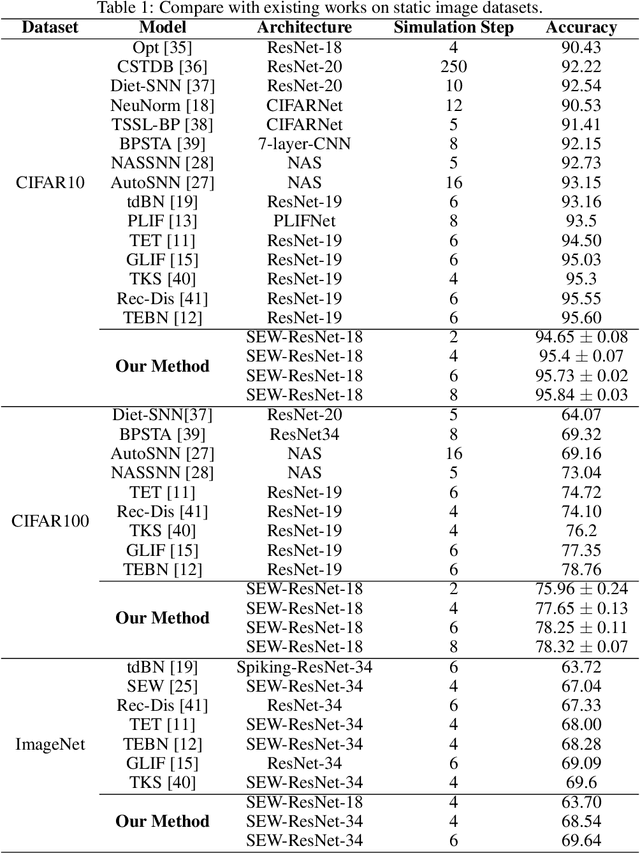
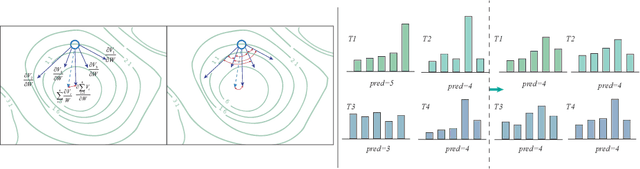
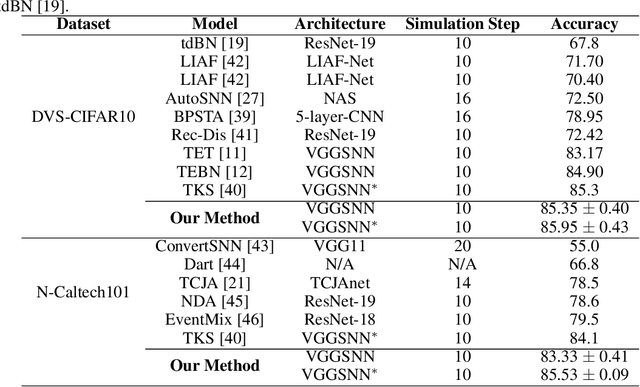
Spiking neural networks have gained significant attention due to their brain-like information processing capabilities. The use of surrogate gradients has made it possible to train spiking neural networks with backpropagation, leading to impressive performance in various tasks. However, spiking neural networks trained with backpropagation typically approximate actual labels using the average output, often necessitating a larger simulation timestep to enhance the network's performance. This delay constraint poses a challenge to the further advancement of SNNs. Current training algorithms tend to overlook the differences in output distribution at various timesteps. Particularly for neuromorphic datasets, inputs at different timesteps can cause inconsistencies in output distribution, leading to a significant deviation from the optimal direction when combining optimization directions from different moments. To tackle this issue, we have designed a method to enhance the temporal consistency of outputs at different timesteps. We have conducted experiments on static datasets such as CIFAR10, CIFAR100, and ImageNet. The results demonstrate that our algorithm can achieve comparable performance to other optimal SNN algorithms. Notably, our algorithm has achieved state-of-the-art performance on neuromorphic datasets DVS-CIFAR10 and N-Caltech101, and can achieve superior performance in the test phase with timestep T=1.