 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Subabdominal MRI Image Segmentation Algorithm Based on Multi-Scale Feature Pyramid Network and Dual Attention Mechanism
May 19, 2023
This study aimed to solve the semantic gap and misalignment issue between encoding and decoding because of multiple convolutional and pooling operations in U-Net when segmenting subabdominal MRI images during rectal cancer treatment. A MRI Image Segmentation is proposed based on a multi-scale feature pyramid network and dual attention mechanism. Our innovation is the design of two modules: 1) a dilated convolution and multi-scale feature pyramid network are used in the encoding to avoid the semantic gap. 2) a dual attention mechanism is designed to maintain spatial information of U-Net and reduce misalignment. Experiments on a subabdominal MRI image dataset show the proposed method achieves better performance than others methods. In conclusion, a multi-scale feature pyramid network can reduce the semantic gap, and the dual attention mechanism can make an alignment of features between encoding and decoding.
Scribble-Supervised Target Extraction Method Based on Inner Structure-Constraint for Remote Sensing Images
May 18, 2023
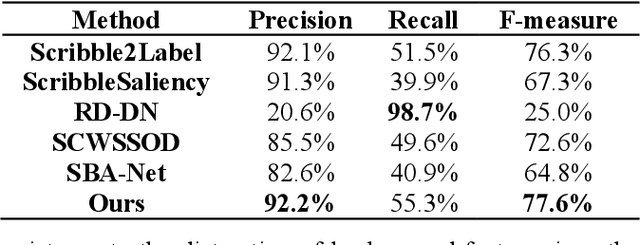
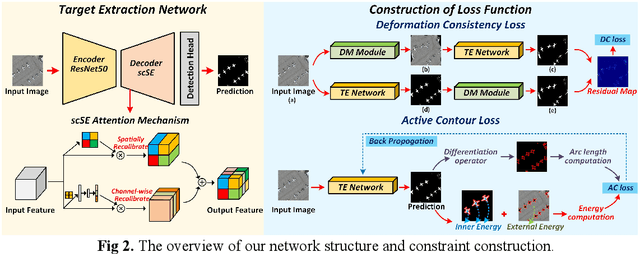
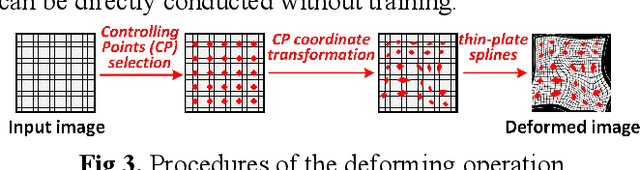
Weakly supervised learning based on scribble annotations in target extraction of remote sensing images has drawn much interest due to scribbles' flexibility in denoting winding objects and low cost of manually labeling. However, scribbles are too sparse to identify object structure and detailed information, bringing great challenges in target localization and boundary description. To alleviate these problems, in this paper, we construct two inner structure-constraints, a deformation consistency loss and a trainable active contour loss, together with a scribble-constraint to supervise the optimization of the encoder-decoder network without introducing any auxiliary module or extra operation based on prior cues. Comprehensive experiments demonstrate our method's superiority over five state-of-the-art algorithms in this field. Source code is available at https://github.com/yitongli123/ISC-TE.
Information Maximizing Curriculum: A Curriculum-Based Approach for Training Mixtures of Experts
Mar 27, 2023


Mixtures of Experts (MoE) are known for their ability to learn complex conditional distributions with multiple modes. However, despite their potential, these models are challenging to train and often tend to produce poor performance, explaining their limited popularity. Our hypothesis is that this under-performance is a result of the commonly utilized maximum likelihood (ML) optimization, which leads to mode averaging and a higher likelihood of getting stuck in local maxima. We propose a novel curriculum-based approach to learning mixture models in which each component of the MoE is able to select its own subset of the training data for learning. This approach allows for independent optimization of each component, resulting in a more modular architecture that enables the addition and deletion of components on the fly, leading to an optimization less susceptible to local optima. The curricula can ignore data-points from modes not represented by the MoE, reducing the mode-averaging problem. To achieve a good data coverage, we couple the optimization of the curricula with a joint entropy objective and optimize a lower bound of this objective. We evaluate our curriculum-based approach on a variety of multimodal behavior learning tasks and demonstrate its superiority over competing methods for learning MoE models and conditional generative models.
Assessing the Impact of Context Inference Error and Partial Observability on RL Methods for Just-In-Time Adaptive Interventions
May 17, 2023
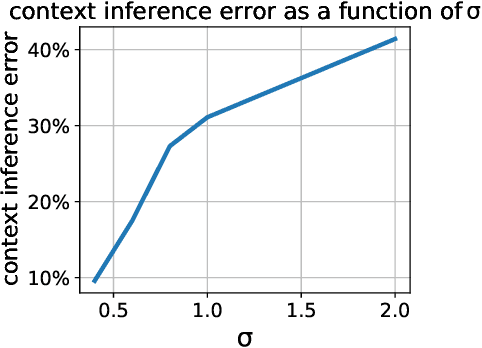

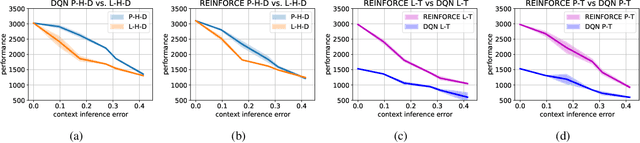
Just-in-Time Adaptive Interventions (JITAIs) are a class of personalized health interventions developed within the behavioral science community. JITAIs aim to provide the right type and amount of support by iteratively selecting a sequence of intervention options from a pre-defined set of components in response to each individual's time varying state. In this work, we explore the application of reinforcement learning methods to the problem of learning intervention option selection policies. We study the effect of context inference error and partial observability on the ability to learn effective policies. Our results show that the propagation of uncertainty from context inferences is critical to improving intervention efficacy as context uncertainty increases, while policy gradient algorithms can provide remarkable robustness to partially observed behavioral state information.
Link Prediction without Graph Neural Networks
May 23, 2023
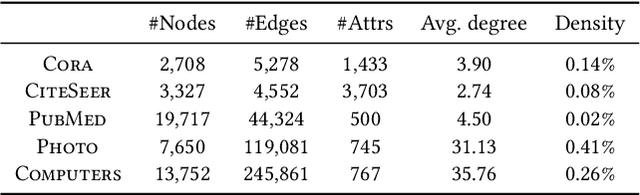
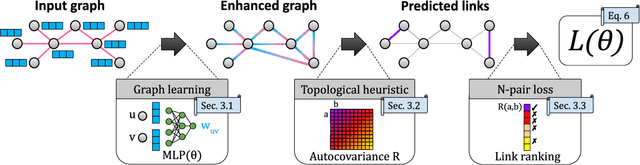
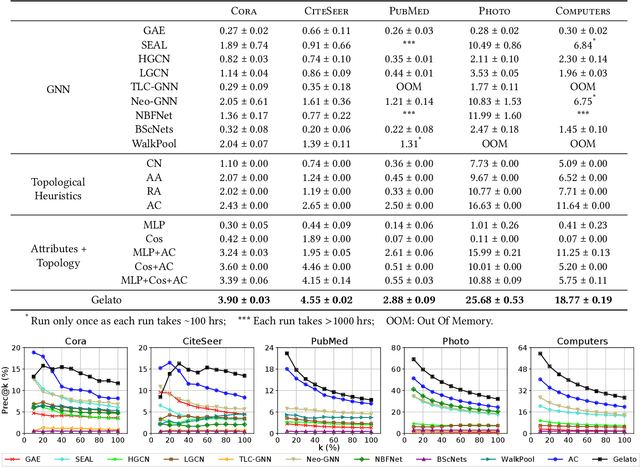
Link prediction, which consists of predicting edges based on graph features, is a fundamental task in many graph applications. As for several related problems, Graph Neural Networks (GNNs), which are based on an attribute-centric message-passing paradigm, have become the predominant framework for link prediction. GNNs have consistently outperformed traditional topology-based heuristics, but what contributes to their performance? Are there simpler approaches that achieve comparable or better results? To answer these questions, we first identify important limitations in how GNN-based link prediction methods handle the intrinsic class imbalance of the problem -- due to the graph sparsity -- in their training and evaluation. Moreover, we propose Gelato, a novel topology-centric framework that applies a topological heuristic to a graph enhanced by attribute information via graph learning. Our model is trained end-to-end with an N-pair loss on an unbiased training set to address class imbalance. Experiments show that Gelato is 145% more accurate, trains 11 times faster, infers 6,000 times faster, and has less than half of the trainable parameters compared to state-of-the-art GNNs for link prediction.
Not All Image Regions Matter: Masked Vector Quantization for Autoregressive Image Generation
May 23, 2023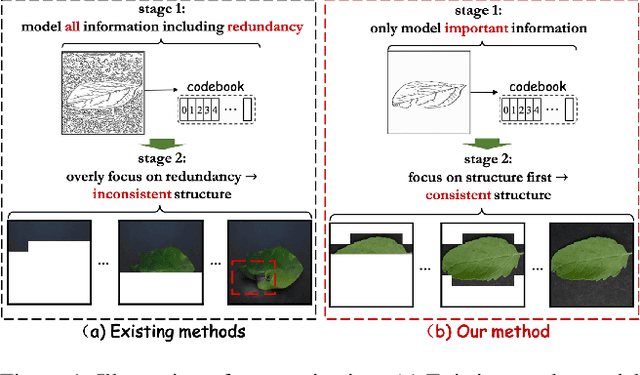
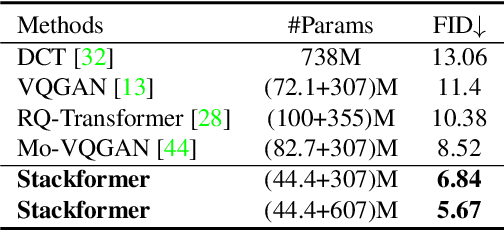
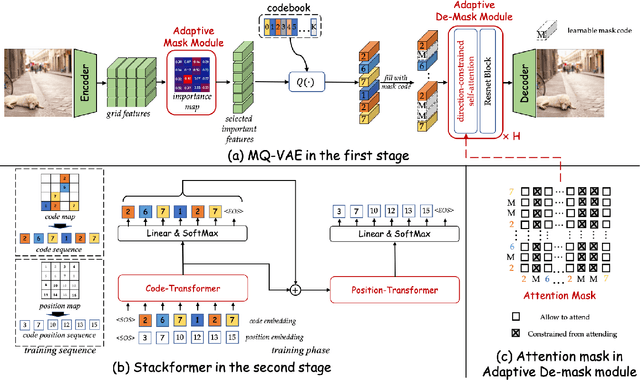
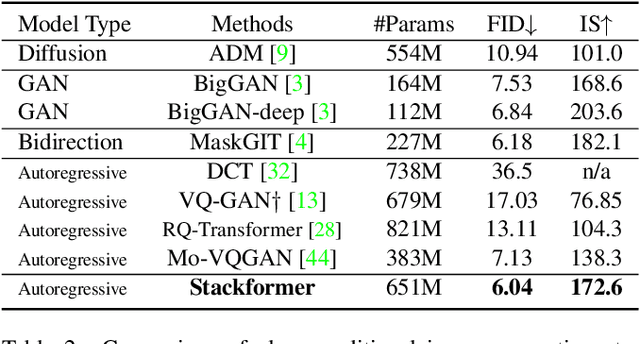
Existing autoregressive models follow the two-stage generation paradigm that first learns a codebook in the latent space for image reconstruction and then completes the image generation autoregressively based on the learned codebook. However, existing codebook learning simply models all local region information of images without distinguishing their different perceptual importance, which brings redundancy in the learned codebook that not only limits the next stage's autoregressive model's ability to model important structure but also results in high training cost and slow generation speed. In this study, we borrow the idea of importance perception from classical image coding theory and propose a novel two-stage framework, which consists of Masked Quantization VAE (MQ-VAE) and Stackformer, to relieve the model from modeling redundancy. Specifically, MQ-VAE incorporates an adaptive mask module for masking redundant region features before quantization and an adaptive de-mask module for recovering the original grid image feature map to faithfully reconstruct the original images after quantization. Then, Stackformer learns to predict the combination of the next code and its position in the feature map. Comprehensive experiments on various image generation validate our effectiveness and efficiency. Code will be released at https://github.com/CrossmodalGroup/MaskedVectorQuantization.
Self-Polish: Enhance Reasoning in Large Language Models via Problem Refinement
May 23, 2023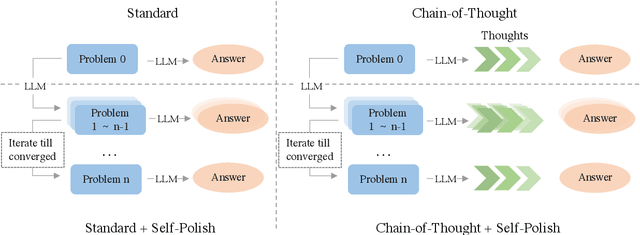
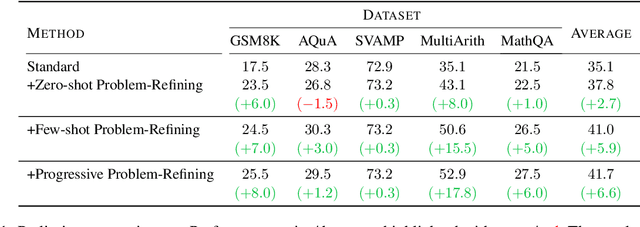

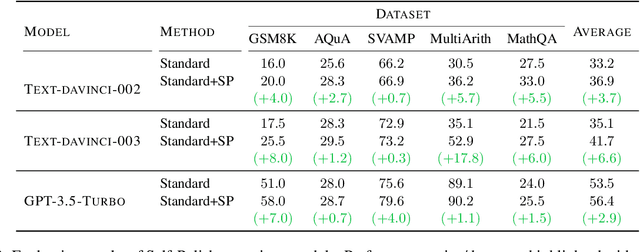
Prompting methods such as Chain-of-Thought (CoT) have shed new light on enhancing the reasoning capabilities of large language models, and researchers have extensively explored the generation process of rationales and answers. However, they have overlooked the potential challenges posed by the poor quality of reasoning problems, which may influence the reasoning performance significantly. In this work, we propose Self-Polish (SP), a novel method that facilitates the model's problem-solving process by prompting them to progressively refine the given problems to be more comprehensible and solvable. Specifically, the method teaches models to eliminate irrelevant information, rearrange the logic structure and organize local conditions into new ones parallelly. SP is orthogonal to all other prompting methods, making it convenient to integrate with state-of-the-art techniques for further improvement. We conduct thorough experiments on five benchmarks to illustrate the effectiveness of the proposed method. For example, with Text-davinci-003, our method boosts the performance of standard few-shot prompting by $8.0\%$ on GSM8K and $17.8\%$ on MultiArith; it also improves the performance of CoT by $6.0\%$ on GSM8K and $6.0\%$ on MathQA, respectively. Furthermore, our method also showcases impressive performance on robustness evaluation.
Layer-wise Adaptive Step-Sizes for Stochastic First-Order Methods for Deep Learning
May 23, 2023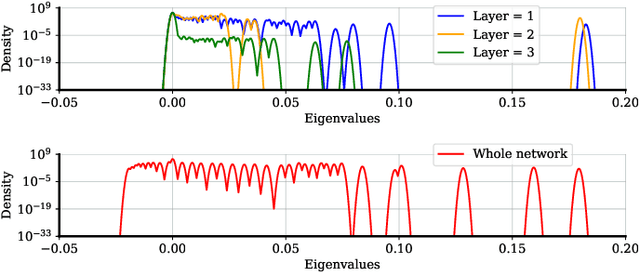

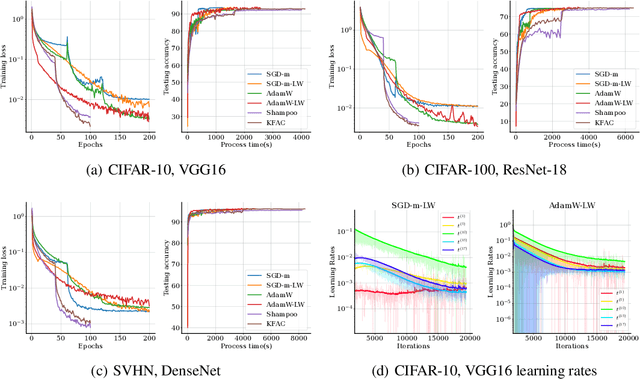

We propose a new per-layer adaptive step-size procedure for stochastic first-order optimization methods for minimizing empirical loss functions in deep learning, eliminating the need for the user to tune the learning rate (LR). The proposed approach exploits the layer-wise stochastic curvature information contained in the diagonal blocks of the Hessian in deep neural networks (DNNs) to compute adaptive step-sizes (i.e., LRs) for each layer. The method has memory requirements that are comparable to those of first-order methods, while its per-iteration time complexity is only increased by an amount that is roughly equivalent to an additional gradient computation. Numerical experiments show that SGD with momentum and AdamW combined with the proposed per-layer step-sizes are able to choose effective LR schedules and outperform fine-tuned LR versions of these methods as well as popular first-order and second-order algorithms for training DNNs on Autoencoder, Convolutional Neural Network (CNN) and Graph Convolutional Network (GCN) models. Finally, it is proved that an idealized version of SGD with the layer-wise step sizes converges linearly when using full-batch gradients.
VIP5: Towards Multimodal Foundation Models for Recommendation
May 23, 2023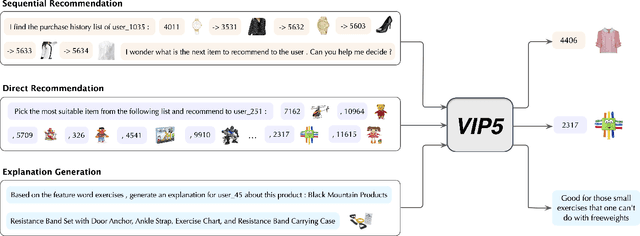
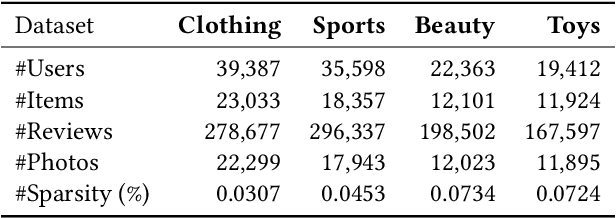
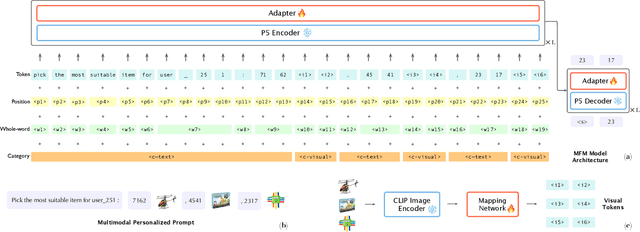
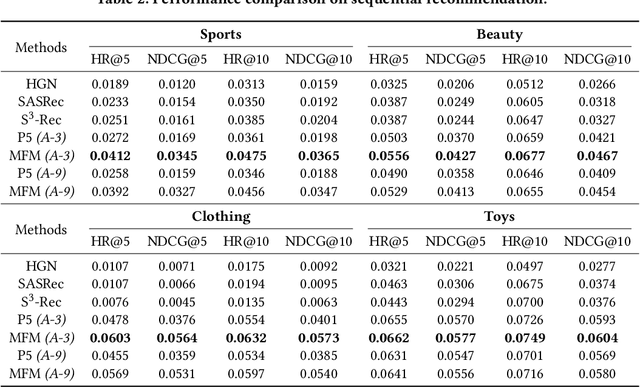
Computer Vision (CV), Natural Language Processing (NLP), and Recommender Systems (RecSys) are three prominent AI applications that have traditionally developed independently, resulting in disparate modeling and engineering methodologies. This has impeded the ability for these fields to directly benefit from each other's advancements. With the increasing availability of multimodal data on the web, there is a growing need to consider various modalities when making recommendations for users. With the recent emergence of foundation models, large language models have emerged as a potential general-purpose interface for unifying different modalities and problem formulations. In light of this, we propose the development of a multimodal foundation model by considering both visual and textual modalities under the P5 recommendation paradigm (VIP5) to unify various modalities and recommendation tasks. This will enable the processing of vision, language, and personalization information in a shared architecture for improved recommendations. To achieve this, we introduce multimodal personalized prompts to accommodate multiple modalities under a shared format. Additionally, we propose a parameter-efficient training method for foundation models, which involves freezing the backbone and fine-tuning lightweight adapters, resulting in improved recommendation performance and increased efficiency in terms of training time and memory usage.
ConGraT: Self-Supervised Contrastive Pretraining for Joint Graph and Text Embeddings
May 23, 2023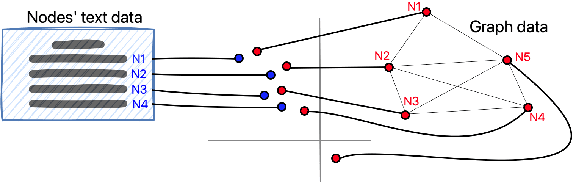
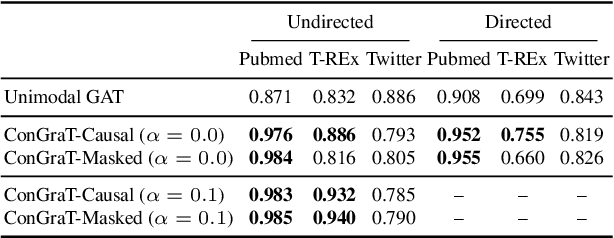
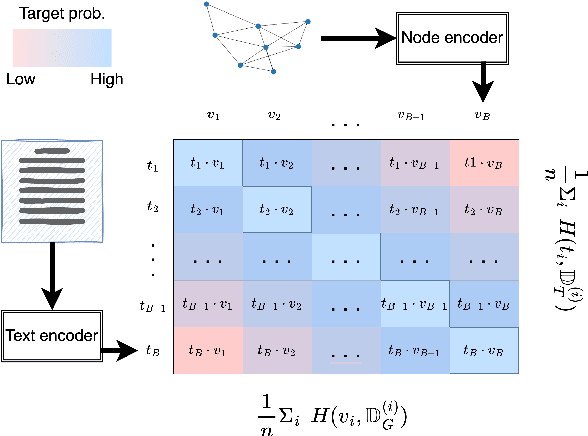
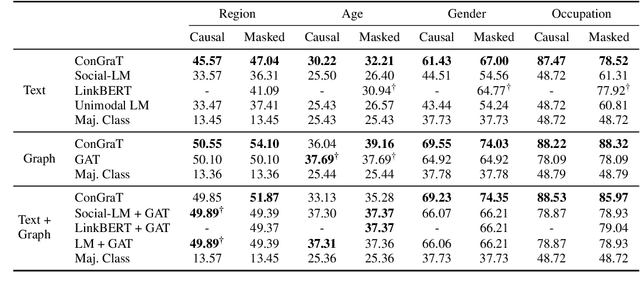
We propose ConGraT(Contrastive Graph-Text pretraining), a general, self-supervised method for jointly learning separate representations of texts and nodes in a parent (or ``supervening'') graph, where each text is associated with one of the nodes. Datasets fitting this paradigm are common, from social media (users and posts), to citation networks over articles, to link graphs over web pages. We expand on prior work by providing a general, self-supervised, joint pretraining method, one which does not depend on particular dataset structure or a specific task. Our method uses two separate encoders for graph nodes and texts, which are trained to align their representations within a common latent space. Training uses a batch-wise contrastive learning objective inspired by prior work on joint text and image encoding. As graphs are more structured objects than images, we also extend the training objective to incorporate information about node similarity and plausible next guesses in matching nodes and texts. Experiments on various datasets reveal that ConGraT outperforms strong baselines on various downstream tasks, including node and text category classification and link prediction. Code and certain datasets are available at https://github.com/wwbrannon/congrat.