 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GTNet: Graph Transformer Network for 3D Point Cloud Classification and Semantic Segmentation
May 24, 2023
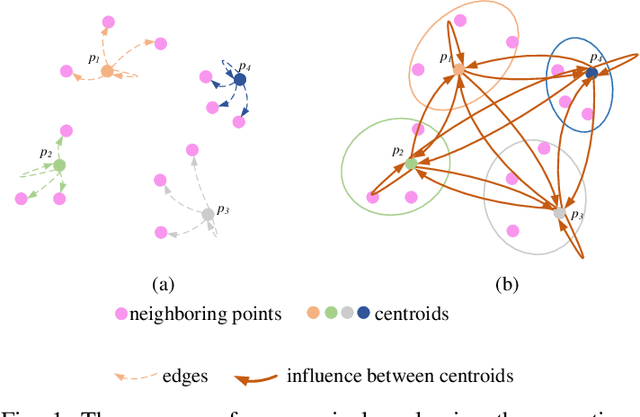
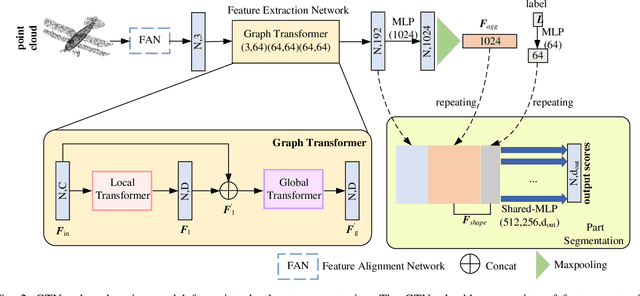
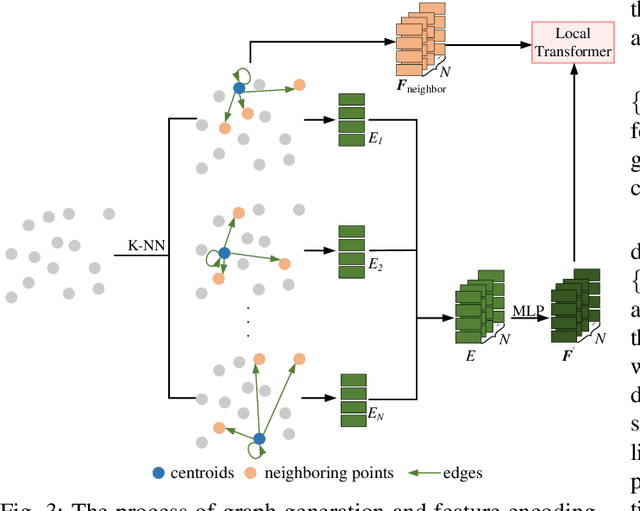
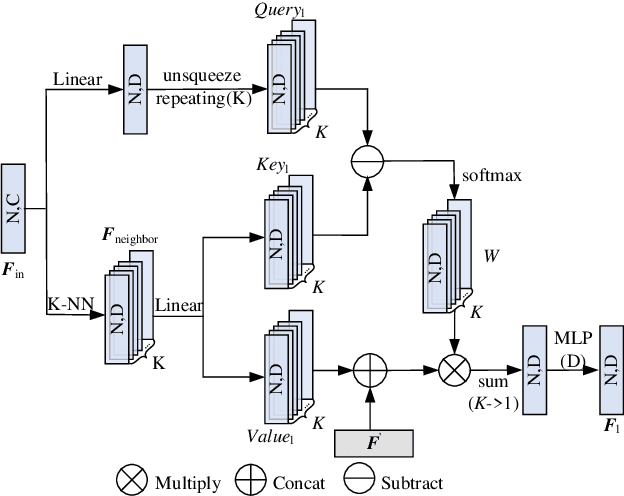
Recently, graph-based and Transformer-based deep learning networks have demonstrated excellent performances on various point cloud tasks. Most of the existing graph methods are based on static graph, which take a fixed input to establish graph relations. Moreover, many graph methods apply maximization and averaging to aggregate neighboring features, so that only a single neighboring point affects the feature of centroid or different neighboring points have the same influence on the centroid's feature, which ignoring the correlation and difference between points. Most Transformer-based methods extract point cloud features based on global attention and lack the feature learning on local neighbors. To solve the problems of these two types of models, we propose a new feature extraction block named Graph Transformer and construct a 3D point point cloud learning network called GTNet to learn features of point clouds on local and global patterns. Graph Transformer integrates the advantages of graph-based and Transformer-based methods, and consists of Local Transformer and Global Transformer modules. Local Transformer uses a dynamic graph to calculate all neighboring point weights by intra-domain cross-attention with dynamically updated graph relations, so that every neighboring point could affect the features of centroid with different weights; Global Transformer enlarges the receptive field of Local Transformer by a global self-attention. In addition, to avoid the disappearance of the gradient caused by the increasing depth of network, we conduct residual connection for centroid features in GTNet; we also adopt the features of centroid and neighbors to generate the local geometric descriptors in Local Transformer to strengthen the local information learning capability of the model. Finally, we use GTNet for shape classification, part segmentation and semantic segmentation tasks in this paper.
Distributed Online Rollout for Multivehicle Routing in Unmapped Environments
May 24, 2023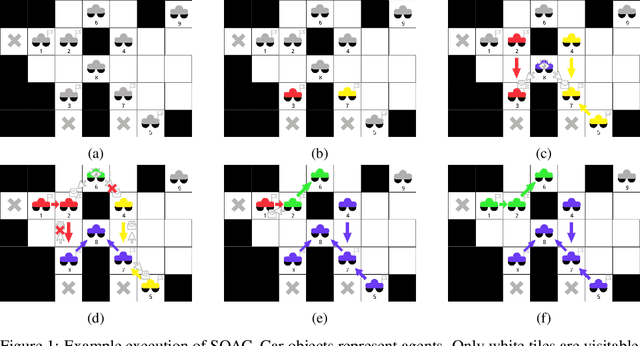
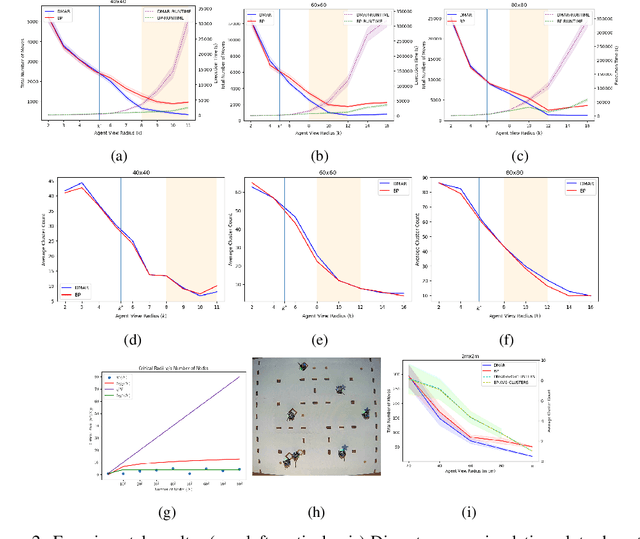
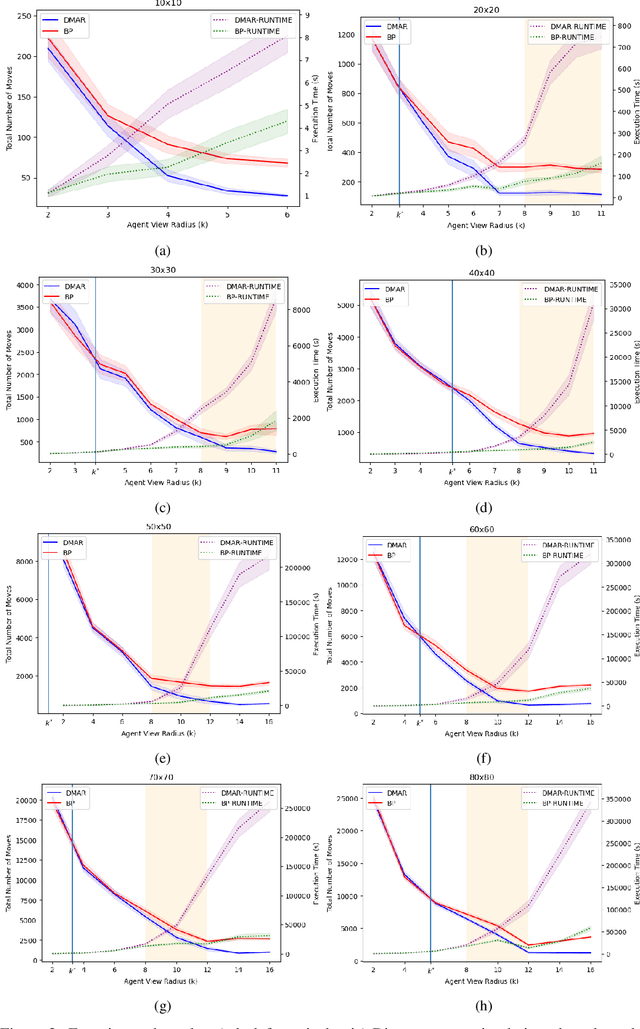
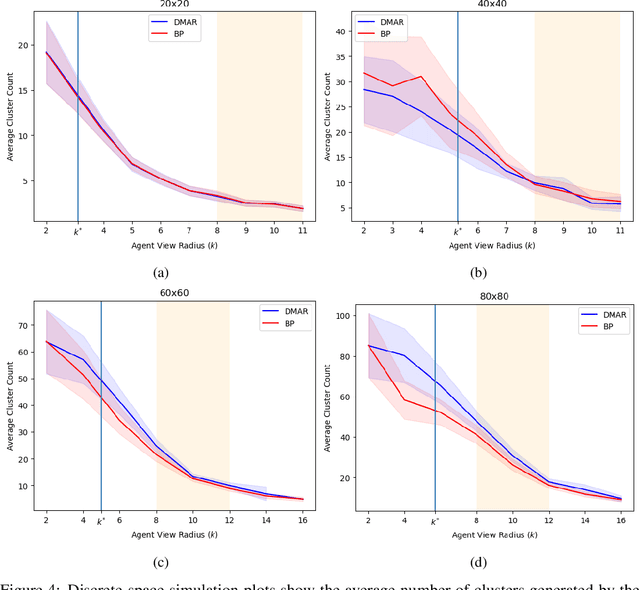
In this work we consider a generalization of the well-known multivehicle routing problem: given a network, a set of agents occupying a subset of its nodes, and a set of tasks, we seek a minimum cost sequence of movements subject to the constraint that each task is visited by some agent at least once. The classical version of this problem assumes a central computational server that observes the entire state of the system perfectly and directs individual agents according to a centralized control scheme. In contrast, we assume that there is no centralized server and that each agent is an individual processor with no a priori knowledge of the underlying network (including task and agent locations). Moreover, our agents possess strictly local communication and sensing capabilities (restricted to a fixed radius around their respective locations), aligning more closely with several real-world multiagent applications. These restrictions introduce many challenges that are overcome through local information sharing and direct coordination between agents. We present a fully distributed, online, and scalable reinforcement learning algorithm for this problem whereby agents self-organize into local clusters and independently apply a multiagent rollout scheme locally to each cluster. We demonstrate empirically via extensive simulations that there exists a critical sensing radius beyond which the distributed rollout algorithm begins to improve over a greedy base policy. This critical sensing radius grows proportionally to the $\log^*$ function of the size of the network, and is, therefore, a small constant for any relevant network. Our decentralized reinforcement learning algorithm achieves approximately a factor of two cost improvement over the base policy for a range of radii bounded from below and above by two and three times the critical sensing radius, respectively.
Lightweight Learner for Shared Knowledge Lifelong Learning
May 24, 2023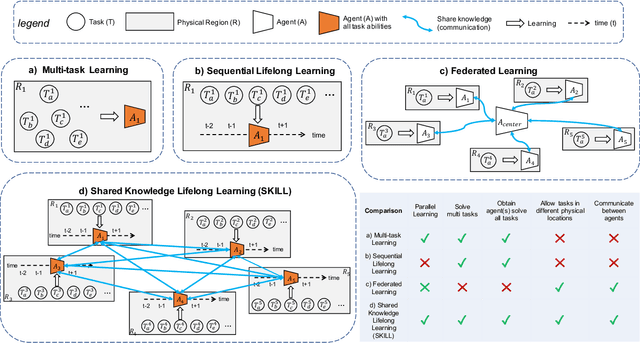
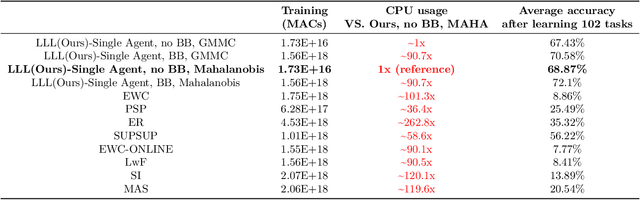
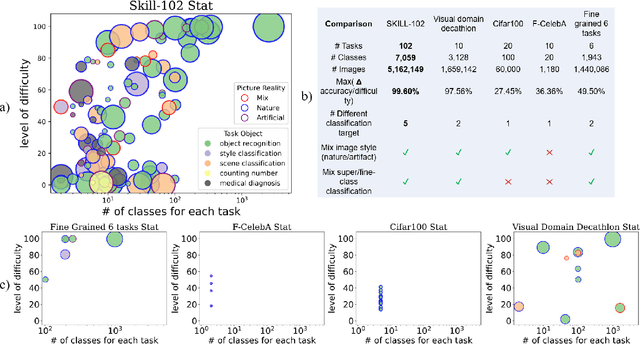
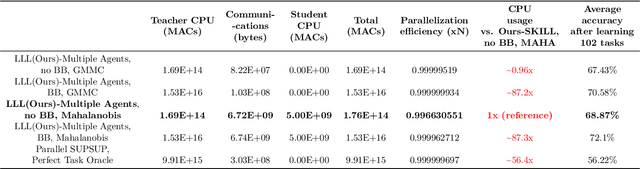
In Lifelong Learning (LL), agents continually learn as they encounter new conditions and tasks. Most current LL is limited to a single agent that learns tasks sequentially. Dedicated LL machinery is then deployed to mitigate the forgetting of old tasks as new tasks are learned. This is inherently slow. We propose a new Shared Knowledge Lifelong Learning (SKILL) challenge, which deploys a decentralized population of LL agents that each sequentially learn different tasks, with all agents operating independently and in parallel. After learning their respective tasks, agents share and consolidate their knowledge over a decentralized communication network, so that, in the end, all agents can master all tasks. We present one solution to SKILL which uses Lightweight Lifelong Learning (LLL) agents, where the goal is to facilitate efficient sharing by minimizing the fraction of the agent that is specialized for any given task. Each LLL agent thus consists of a common task-agnostic immutable part, where most parameters are, and individual task-specific modules that contain fewer parameters but are adapted to each task. Agents share their task-specific modules, plus summary information ("task anchors") representing their tasks in the common task-agnostic latent space of all agents. Receiving agents register each received task-specific module using the corresponding anchor. Thus, every agent improves its ability to solve new tasks each time new task-specific modules and anchors are received. On a new, very challenging SKILL-102 dataset with 102 image classification tasks (5,033 classes in total, 2,041,225 training, 243,464 validation, and 243,464 test images), we achieve much higher (and SOTA) accuracy over 8 LL baselines, while also achieving near perfect parallelization. Code and data can be found at https://github.com/gyhandy/Shared-Knowledge-Lifelong-Learning
Towards Achieving Near-optimal Utility for Privacy-Preserving Federated Learning via Data Generation and Parameter Distortion
May 19, 2023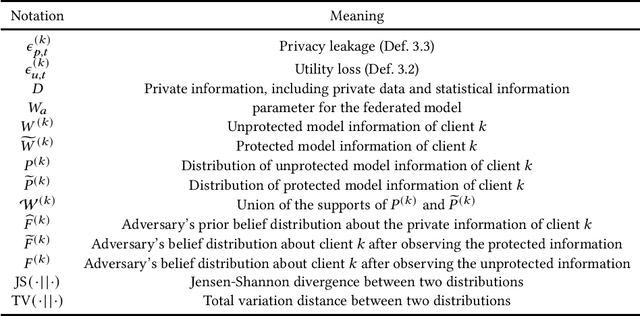
Federated learning (FL) enables participating parties to collaboratively build a global model with boosted utility without disclosing private data information. Appropriate protection mechanisms have to be adopted to fulfill the requirements in preserving \textit{privacy} and maintaining high model \textit{utility}. The nature of the widely-adopted protection mechanisms including \textit{Randomization Mechanism} and \textit{Compression Mechanism} is to protect privacy via distorting model parameter. We measure the utility via the gap between the original model parameter and the distorted model parameter. We want to identify under what general conditions privacy-preserving federated learning can achieve near-optimal utility via data generation and parameter distortion. To provide an avenue for achieving near-optimal utility, we present an upper bound for utility loss, which is measured using two main terms called variance-reduction and model parameter discrepancy separately. Our analysis inspires the design of appropriate protection parameters for the protection mechanisms to achieve near-optimal utility and meet the privacy requirements simultaneously. The main techniques for the protection mechanism include parameter distortion and data generation, which are generic and can be applied extensively. Furthermore, we provide an upper bound for the trade-off between privacy and utility, which together with the lower bound illustrated in NFL form the conditions for achieving optimal trade-off.
LLM-Pruner: On the Structural Pruning of Large Language Models
May 19, 2023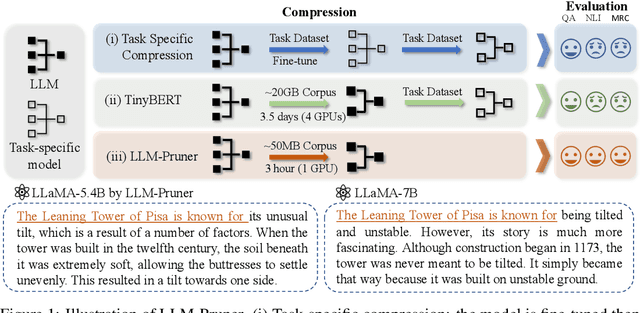
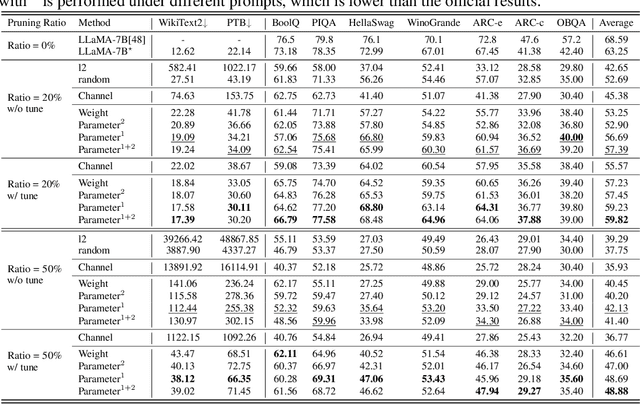
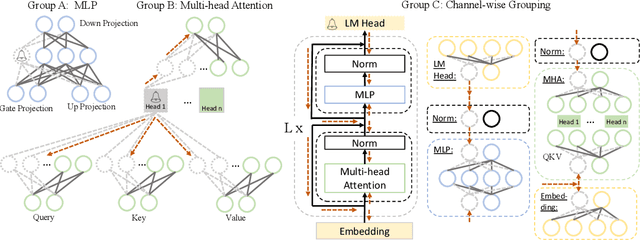
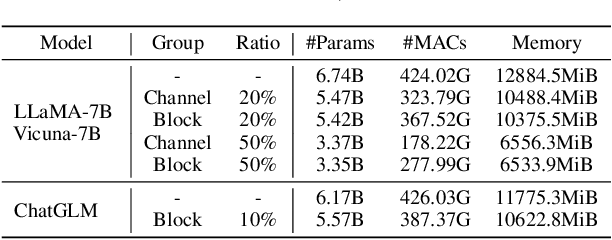
Large language models (LLMs) have shown remarkable capabilities in language understanding and generation. However, such impressive capability typically comes with a substantial model size, which presents significant challenges in both the deployment, inference, and training stages. With LLM being a general-purpose task solver, we explore its compression in a task-agnostic manner, which aims to preserve the multi-task solving and language generation ability of the original LLM. One challenge to achieving this is the enormous size of the training corpus of LLM, which makes both data transfer and model post-training over-burdensome. Thus, we tackle the compression of LLMs within the bound of two constraints: being task-agnostic and minimizing the reliance on the original training dataset. Our method, named LLM-Pruner, adopts structural pruning that selectively removes non-critical coupled structures based on gradient information, maximally preserving the majority of the LLM's functionality. To this end, the performance of pruned models can be efficiently recovered through tuning techniques, LoRA, in merely 3 hours, requiring only 50K data. We validate the LLM-Pruner on three LLMs, including LLaMA, Vicuna, and ChatGLM, and demonstrate that the compressed models still exhibit satisfactory capabilities in zero-shot classification and generation. The code is available at: https://github.com/horseee/LLM-Pruner
How Does Generative Retrieval Scale to Millions of Passages?
May 19, 2023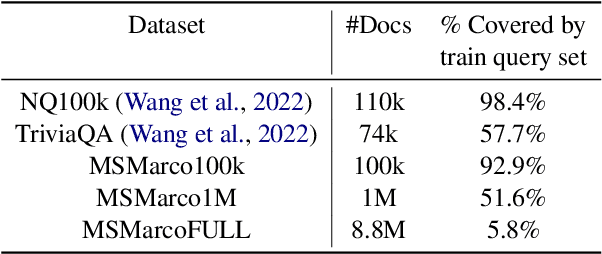
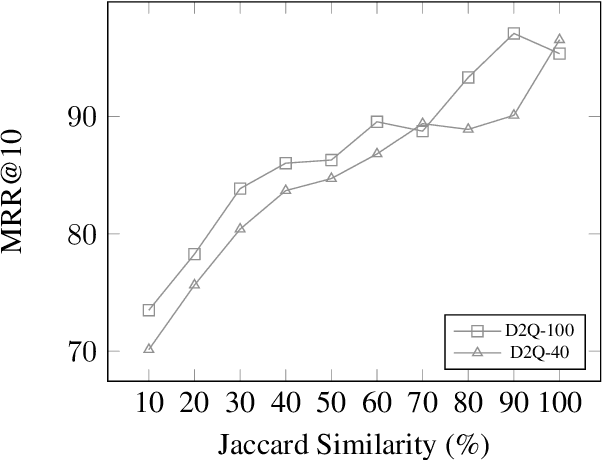
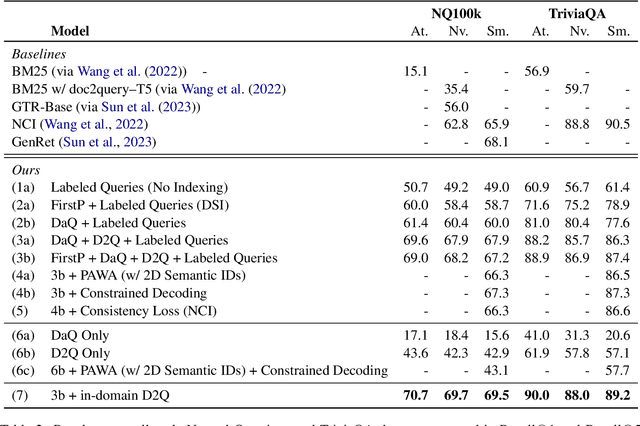
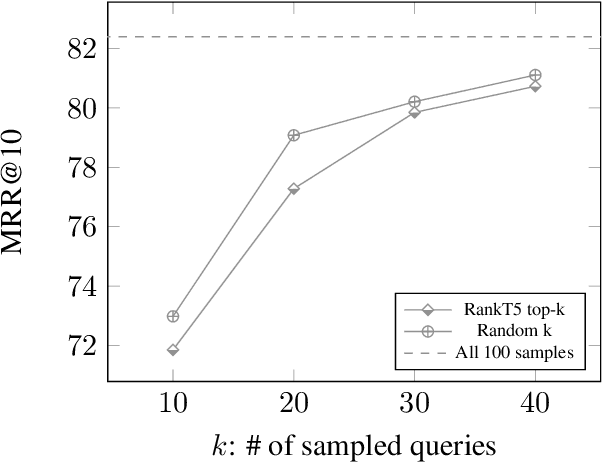
Popularized by the Differentiable Search Index, the emerging paradigm of generative retrieval re-frames the classic information retrieval problem into a sequence-to-sequence modeling task, forgoing external indices and encoding an entire document corpus within a single Transformer. Although many different approaches have been proposed to improve the effectiveness of generative retrieval, they have only been evaluated on document corpora on the order of 100k in size. We conduct the first empirical study of generative retrieval techniques across various corpus scales, ultimately scaling up to the entire MS MARCO passage ranking task with a corpus of 8.8M passages and evaluating model sizes up to 11B parameters. We uncover several findings about scaling generative retrieval to millions of passages; notably, the central importance of using synthetic queries as document representations during indexing, the ineffectiveness of existing proposed architecture modifications when accounting for compute cost, and the limits of naively scaling model parameters with respect to retrieval performance. While we find that generative retrieval is competitive with state-of-the-art dual encoders on small corpora, scaling to millions of passages remains an important and unsolved challenge. We believe these findings will be valuable for the community to clarify the current state of generative retrieval, highlight the unique challenges, and inspire new research directions.
Q-malizing flow and infinitesimal density ratio estimation
May 19, 2023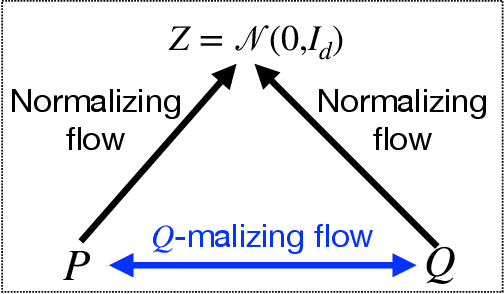

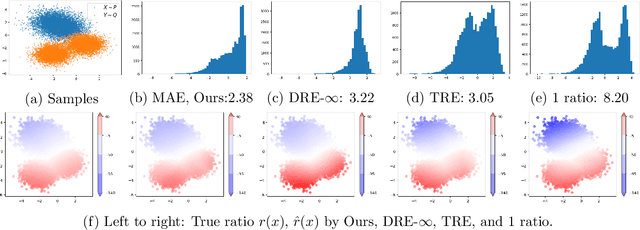
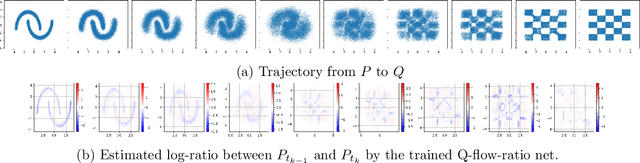
Continuous normalizing flows are widely used in generative tasks, where a flow network transports from a data distribution $P$ to a normal distribution. A flow model that can transport from $P$ to an arbitrary $Q$, where both $P$ and $Q$ are accessible via finite samples, would be of various application interests, particularly in the recently developed telescoping density ratio estimation (DRE) which calls for the construction of intermediate densities to bridge between $P$ and $Q$. In this work, we propose such a ``Q-malizing flow'' by a neural-ODE model which is trained to transport invertibly from $P$ to $Q$ (and vice versa) from empirical samples and is regularized by minimizing the transport cost. The trained flow model allows us to perform infinitesimal DRE along the time-parametrized $\log$-density by training an additional continuous-time flow network using classification loss, which estimates the time-partial derivative of the $\log$-density. Integrating the time-score network along time provides a telescopic DRE between $P$ and $Q$ that is more stable than a one-step DRE. The effectiveness of the proposed model is empirically demonstrated on mutual information estimation from high-dimensional data and energy-based generative models of image data.
Direction Specific Ambisonics Source Separation with End-To-End Deep Learning
May 19, 2023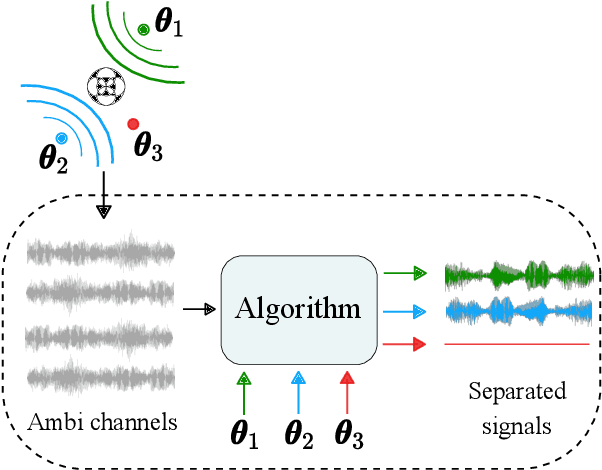
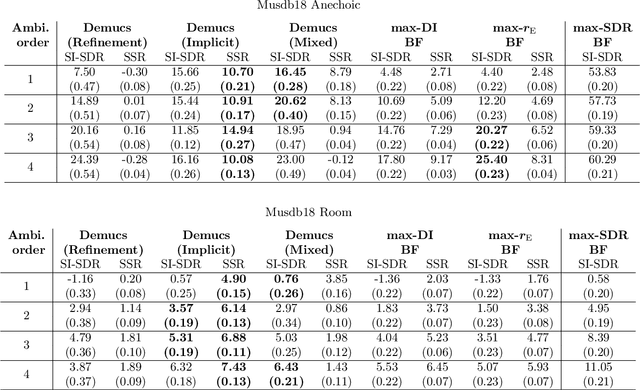
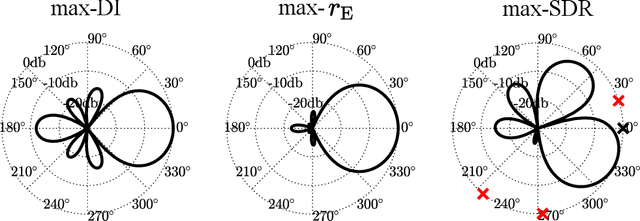
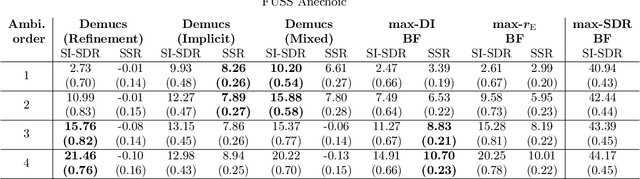
Ambisonics is a scene-based spatial audio format that has several useful features compared to object-based formats, such as efficient whole scene rotation and versatility. However, it does not provide direct access to the individual source signals, so that these have to be separated from the mixture when required. Typically, this is done with linear spherical harmonics (SH) beamforming. In this paper, we explore deep-learning-based source separation on static Ambisonics mixtures. In contrast to most source separation approaches, which separate a fixed number of sources of specific sound types, we focus on separating arbitrary sound from specific directions. Specifically, we propose three operating modes that combine a source separation neural network with SH beamforming: refinement, implicit, and mixed mode. We show that a neural network can implicitly associate conditioning directions with the spatial information contained in the Ambisonics scene to extract specific sources. We evaluate the performance of the three proposed approaches and compare them to SH beamforming on musical mixtures generated with the musdb18 dataset, as well as with mixtures generated with the FUSS dataset for universal source separation, under both anechoic and room conditions. Results show that the proposed approaches offer improved separation performance and spatial selectivity compared to conventional SH beamforming.
Goal-Oriented Communications in Federated Learning via Feedback on Risk-Averse Participation
May 19, 2023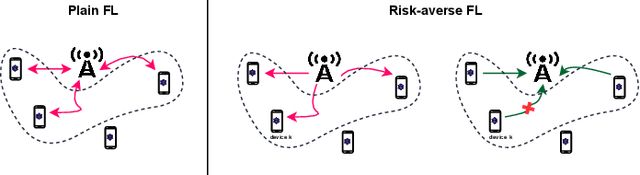
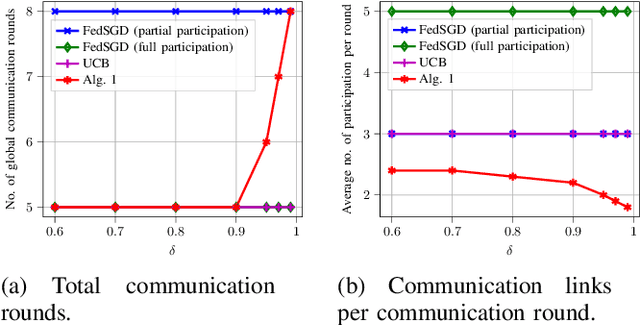
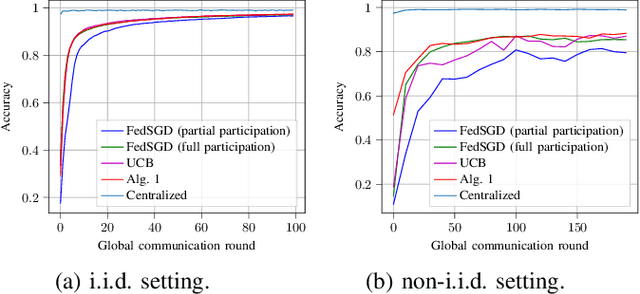
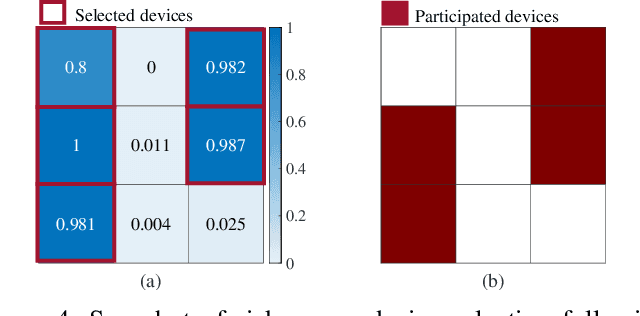
We treat the problem of client selection in a Federated Learning (FL) setup, where the learning objective and the local incentives of the participants are used to formulate a goal-oriented communication problem. Specifically, we incorporate the risk-averse nature of participants and obtain a communication-efficient on-device performance, while relying on feedback from the Parameter Server (\texttt{PS}). A client has to decide its transmission plan on when not to participate in FL. This is based on its intrinsic incentive, which is the value of the trained global model upon participation by this client. Poor updates not only plunge the performance of the global model with added communication cost but also propagate the loss in performance on other participating devices. We cast the relevance of local updates as \emph{semantic information} for developing local transmission strategies, i.e., making a decision on when to ``not transmit". The devices use feedback about the state of the PS and evaluate their contributions in training the learning model in each aggregation period, which eventually lowers the number of occupied connections. Simulation results validate the efficacy of our proposed approach, with up to $1.4\times$ gain in communication links utilization as compared with the baselines.
ThreatCrawl: A BERT-based Focused Crawler for the Cybersecurity Domain
Apr 24, 2023
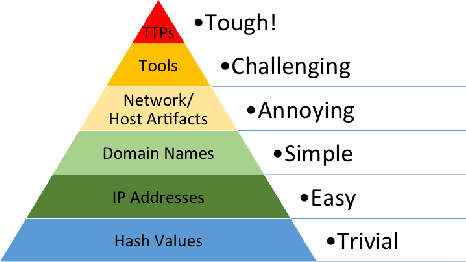
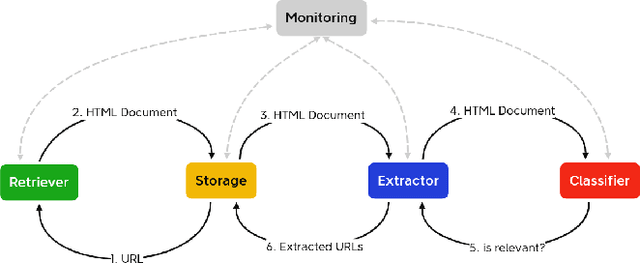

Publicly available information contains valuable information for Cyber Threat Intelligence (CTI). This can be used to prevent attacks that have already taken place on other systems. Ideally, only the initial attack succeeds and all subsequent ones are detected and stopped. But while there are different standards to exchange this information, a lot of it is shared in articles or blog posts in non-standardized ways. Manually scanning through multiple online portals and news pages to discover new threats and extracting them is a time-consuming task. To automize parts of this scanning process, multiple papers propose extractors that use Natural Language Processing (NLP) to extract Indicators of Compromise (IOCs) from documents. However, while this already solves the problem of extracting the information out of documents, the search for these documents is rarely considered. In this paper, a new focused crawler is proposed called ThreatCrawl, which uses Bidirectional Encoder Representations from Transformers (BERT)-based models to classify documents and adapt its crawling path dynamically. While ThreatCrawl has difficulties to classify the specific type of Open Source Intelligence (OSINT) named in texts, e.g., IOC content, it can successfully find relevant documents and modify its path accordingly. It yields harvest rates of up to 52%, which are, to the best of our knowledge, better than the current state of the art.