 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Contrastive Balancing Representation Learning for Heterogeneous Dose-Response Curves Estimation
Mar 21, 2024
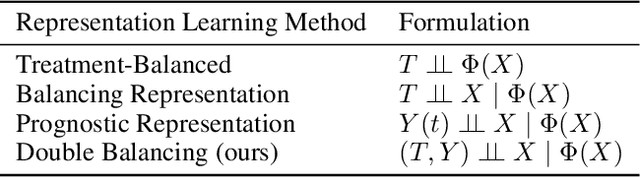
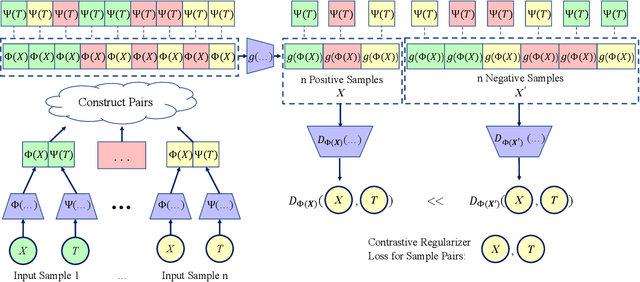
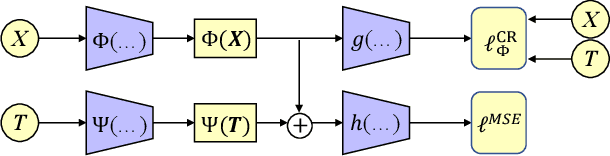
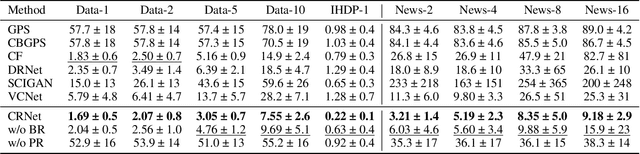
Estimating the individuals' potential response to varying treatment doses is crucial for decision-making in areas such as precision medicine and management science. Most recent studies predict counterfactual outcomes by learning a covariate representation that is independent of the treatment variable. However, such independence constraints neglect much of the covariate information that is useful for counterfactual prediction, especially when the treatment variables are continuous. To tackle the above issue, in this paper, we first theoretically demonstrate the importance of the balancing and prognostic representations for unbiased estimation of the heterogeneous dose-response curves, that is, the learned representations are constrained to satisfy the conditional independence between the covariates and both of the treatment variables and the potential responses. Based on this, we propose a novel Contrastive balancing Representation learning Network using a partial distance measure, called CRNet, for estimating the heterogeneous dose-response curves without losing the continuity of treatments. Extensive experiments are conducted on synthetic and real-world datasets demonstrating that our proposal significantly outperforms previous methods.
LeFusion: Synthesizing Myocardial Pathology on Cardiac MRI via Lesion-Focus Diffusion Models
Mar 21, 2024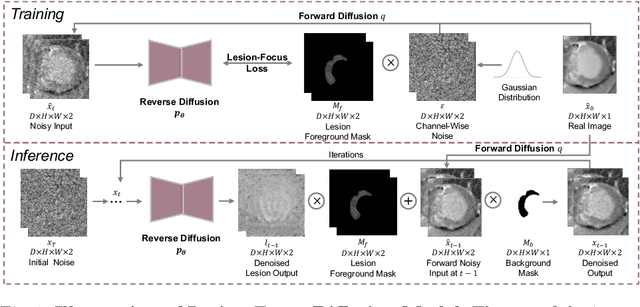
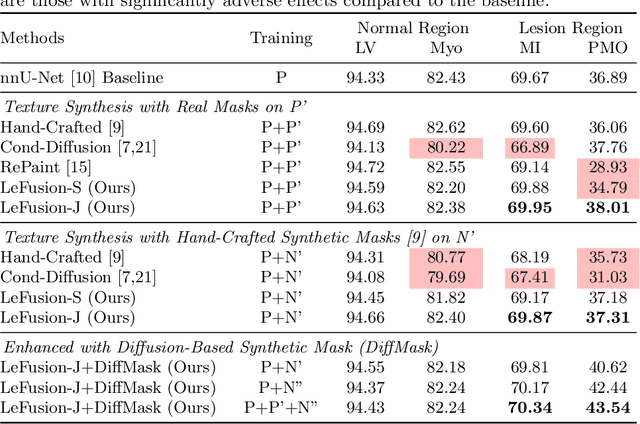
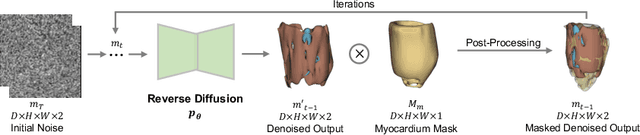
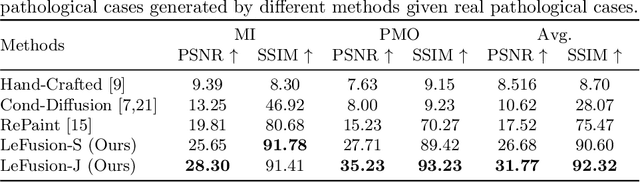
Data generated in clinical practice often exhibits biases, such as long-tail imbalance and algorithmic unfairness. This study aims to mitigate these challenges through data synthesis. Previous efforts in medical imaging synthesis have struggled with separating lesion information from background context, leading to difficulties in generating high-quality backgrounds and limited control over the synthetic output. Inspired by diffusion-based image inpainting, we propose LeFusion, lesion-focused diffusion models. By redesigning the diffusion learning objectives to concentrate on lesion areas, it simplifies the model learning process and enhance the controllability of the synthetic output, while preserving background by integrating forward-diffused background contexts into the reverse diffusion process. Furthermore, we generalize it to jointly handle multi-class lesions, and further introduce a generative model for lesion masks to increase synthesis diversity. Validated on the DE-MRI cardiac lesion segmentation dataset (Emidec), our methodology employs the popular nnUNet to demonstrate that the synthetic data make it possible to effectively enhance a state-of-the-art model. Code and model are available at https://github.com/M3DV/LeFusion.
An Active Contour Model Driven By the Hybrid Signed Pressure Function
Mar 21, 2024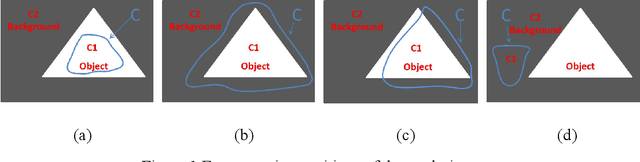
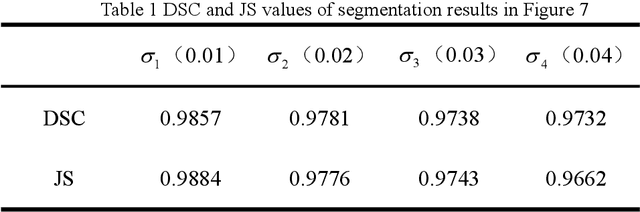
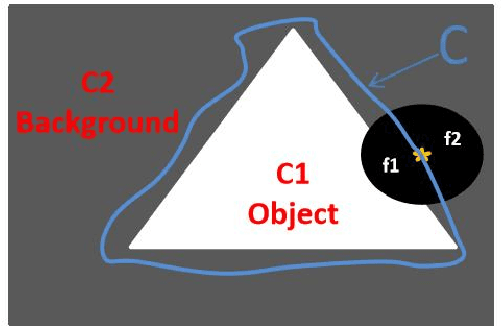
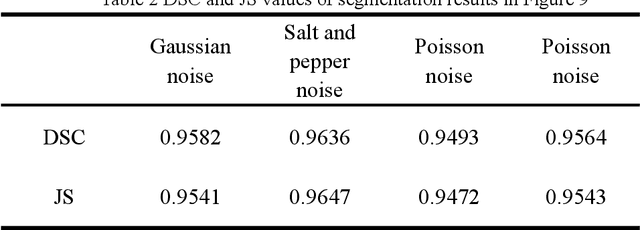
Due to the influence of imaging equipment and complex imaging environments, most images in daily life have features of intensity inhomogeneity and noise. Therefore, many scholars have designed many image segmentation algorithms to address these issues. Among them, the active contour model is one of the most effective image segmentation algorithms.This paper proposes an active contour model driven by the hybrid signed pressure function that combines global and local information construction. Firstly, a new global region-based signed pressure function is introduced by combining the average intensity of the inner and outer regions of the curve with the median intensity of the inner region of the evolution curve. Then, the paper uses the energy differences between the inner and outer regions of the curve in the local region to design the signed pressure function of the local term. Combine the two SPF function to obtain a new signed pressure function and get the evolution equation of the new model. Finally, experiments and numerical analysis show that the model has excellent segmentation performance for both intensity inhomogeneous images and noisy images.
Enhancing Medical Support in the Arabic Language Through Personalized ChatGPT Assistance
Mar 21, 2024This Paper discusses the growing popularity of online medical diagnosis as an alternative to traditional doctor visits. It highlights the limitations of existing tools and emphasizes the advantages of using ChatGPT, which provides real-time, personalized medical diagnosis at no cost. The paragraph summarizes a research study that evaluated the performance of ChatGPT in Arabic medical diagnosis. The study involved compiling a dataset of disease information and generating multiple messages for each disease using different prompting techniques. ChatGPT's performance was assessed by measuring the similarity between its responses and the actual diseases. The results showed promising performance, with average scores of around 76% for similarity measures. Various prompting techniques were used, and chain prompting demonstrated a relative advantage. The study also recorded an average response time of 6.12 seconds for the ChatGPT API, which is considered acceptable but has room for improvement. While ChatGPT cannot replace human doctors entirely, the findings suggest its potential in emergency cases and addressing general medical inquiries. Overall, the study highlights ChatGPT's viability as a valuable tool in the medical field.
FedMef: Towards Memory-efficient Federated Dynamic Pruning
Mar 21, 2024Federated learning (FL) promotes decentralized training while prioritizing data confidentiality. However, its application on resource-constrained devices is challenging due to the high demand for computation and memory resources to train deep learning models. Neural network pruning techniques, such as dynamic pruning, could enhance model efficiency, but directly adopting them in FL still poses substantial challenges, including post-pruning performance degradation, high activation memory usage, etc. To address these challenges, we propose FedMef, a novel and memory-efficient federated dynamic pruning framework. FedMef comprises two key components. First, we introduce the budget-aware extrusion that maintains pruning efficiency while preserving post-pruning performance by salvaging crucial information from parameters marked for pruning within a given budget. Second, we propose scaled activation pruning to effectively reduce activation memory footprints, which is particularly beneficial for deploying FL to memory-limited devices. Extensive experiments demonstrate the effectiveness of our proposed FedMef. In particular, it achieves a significant reduction of 28.5% in memory footprint compared to state-of-the-art methods while obtaining superior accuracy.
Open Knowledge Base Canonicalization with Multi-task Learning
Mar 21, 2024The construction of large open knowledge bases (OKBs) is integral to many knowledge-driven applications on the world wide web such as web search. However, noun phrases and relational phrases in OKBs often suffer from redundancy and ambiguity, which calls for the investigation on OKB canonicalization. Current solutions address OKB canonicalization by devising advanced clustering algorithms and using knowledge graph embedding (KGE) to further facilitate the canonicalization process. Nevertheless, these works fail to fully exploit the synergy between clustering and KGE learning, and the methods designed for these subtasks are sub-optimal. To this end, we put forward a multi-task learning framework, namely MulCanon, to tackle OKB canonicalization. In addition, diffusion model is used in the soft clustering process to improve the noun phrase representations with neighboring information, which can lead to more accurate representations. MulCanon unifies the learning objectives of these sub-tasks, and adopts a two-stage multi-task learning paradigm for training. A thorough experimental study on popular OKB canonicalization benchmarks validates that MulCanon can achieve competitive canonicalization results.
QUASAR: QUality and Aesthetics Scoring with Advanced Representations
Mar 20, 2024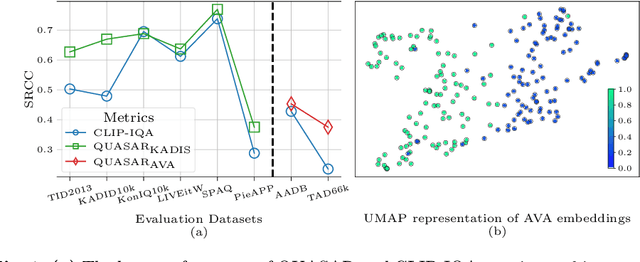
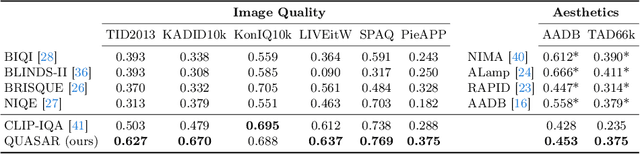
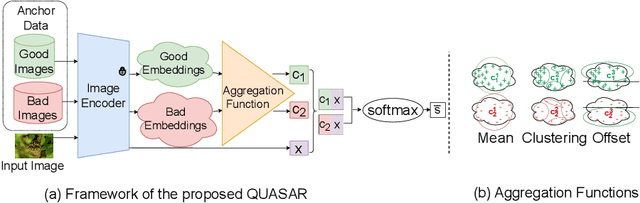

This paper introduces a new data-driven, non-parametric method for image quality and aesthetics assessment, surpassing existing approaches and requiring no prompt engineering or fine-tuning. We eliminate the need for expressive textual embeddings by proposing efficient image anchors in the data. Through extensive evaluations of 7 state-of-the-art self-supervised models, our method demonstrates superior performance and robustness across various datasets and benchmarks. Notably, it achieves high agreement with human assessments even with limited data and shows high robustness to the nature of data and their pre-processing pipeline. Our contributions offer a streamlined solution for assessment of images while providing insights into the perception of visual information.
Improved EATFormer: A Vision Transformer for Medical Image Classification
Mar 19, 2024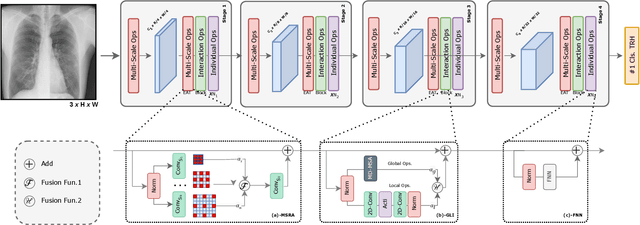
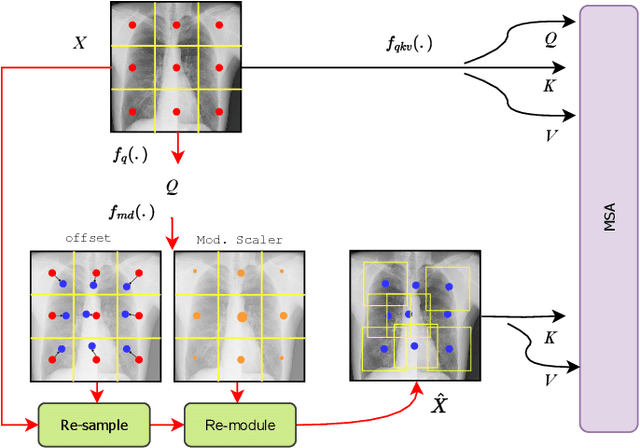
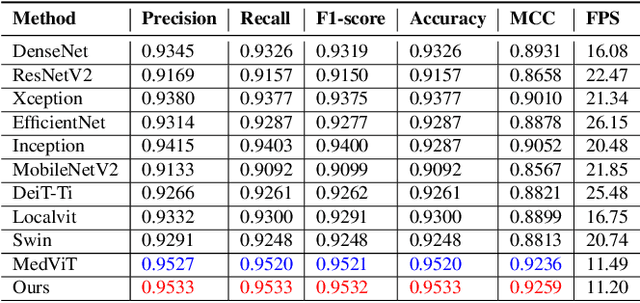
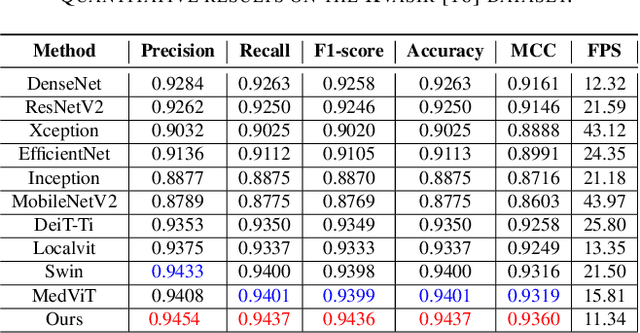
The accurate analysis of medical images is vital for diagnosing and predicting medical conditions. Traditional approaches relying on radiologists and clinicians suffer from inconsistencies and missed diagnoses. Computer-aided diagnosis systems can assist in achieving early, accurate, and efficient diagnoses. This paper presents an improved Evolutionary Algorithm-based Transformer architecture for medical image classification using Vision Transformers. The proposed EATFormer architecture combines the strengths of Convolutional Neural Networks and Vision Transformers, leveraging their ability to identify patterns in data and adapt to specific characteristics. The architecture incorporates novel components, including the Enhanced EA-based Transformer block with Feed-Forward Network, Global and Local Interaction , and Multi-Scale Region Aggregation modules. It also introduces the Modulated Deformable MSA module for dynamic modeling of irregular locations. The paper discusses the Vision Transformer (ViT) model's key features, such as patch-based processing, positional context incorporation, and Multi-Head Attention mechanism. It introduces the Multi-Scale Region Aggregation module, which aggregates information from different receptive fields to provide an inductive bias. The Global and Local Interaction module enhances the MSA-based global module by introducing a local path for extracting discriminative local information. Experimental results on the Chest X-ray and Kvasir datasets demonstrate that the proposed EATFormer significantly improves prediction speed and accuracy compared to baseline models.
VQ-NeRV: A Vector Quantized Neural Representation for Videos
Mar 19, 2024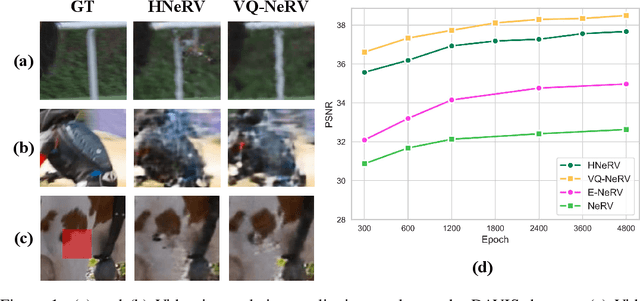
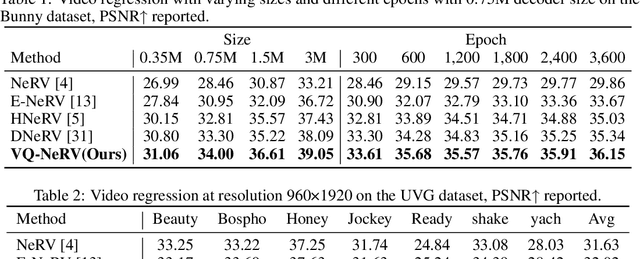
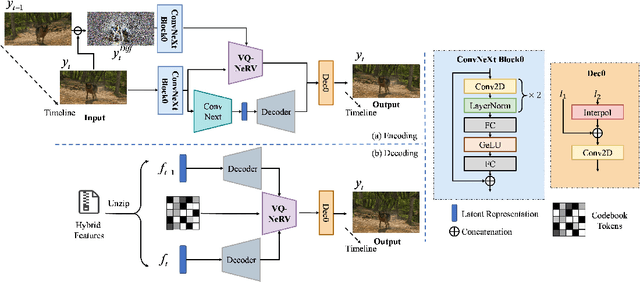
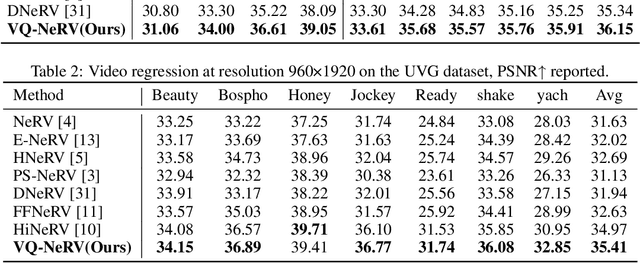
Implicit neural representations (INR) excel in encoding videos within neural networks, showcasing promise in computer vision tasks like video compression and denoising. INR-based approaches reconstruct video frames from content-agnostic embeddings, which hampers their efficacy in video frame regression and restricts their generalization ability for video interpolation. To address these deficiencies, Hybrid Neural Representation for Videos (HNeRV) was introduced with content-adaptive embeddings. Nevertheless, HNeRV's compression ratios remain relatively low, attributable to an oversight in leveraging the network's shallow features and inter-frame residual information. In this work, we introduce an advanced U-shaped architecture, Vector Quantized-NeRV (VQ-NeRV), which integrates a novel component--the VQ-NeRV Block. This block incorporates a codebook mechanism to discretize the network's shallow residual features and inter-frame residual information effectively. This approach proves particularly advantageous in video compression, as it results in smaller size compared to quantized features. Furthermore, we introduce an original codebook optimization technique, termed shallow codebook optimization, designed to refine the utility and efficiency of the codebook. The experimental evaluations indicate that VQ-NeRV outperforms HNeRV on video regression tasks, delivering superior reconstruction quality (with an increase of 1-2 dB in Peak Signal-to-Noise Ratio (PSNR)), better bit per pixel (bpp) efficiency, and improved video inpainting outcomes.
GRA: Detecting Oriented Objects through Group-wise Rotating and Attention
Mar 19, 2024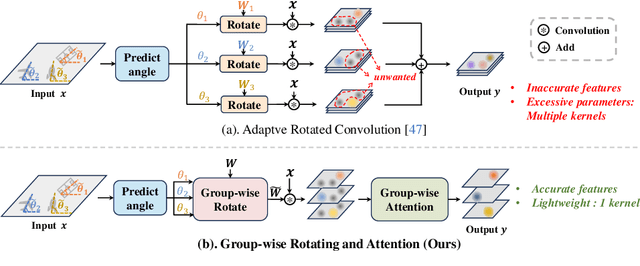
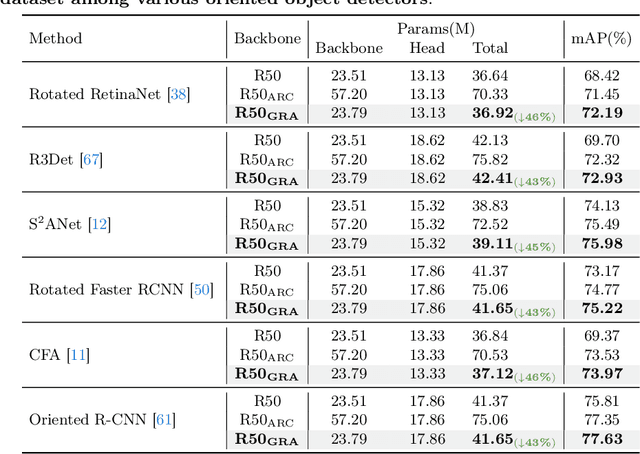
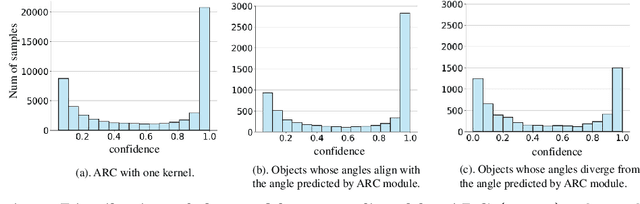
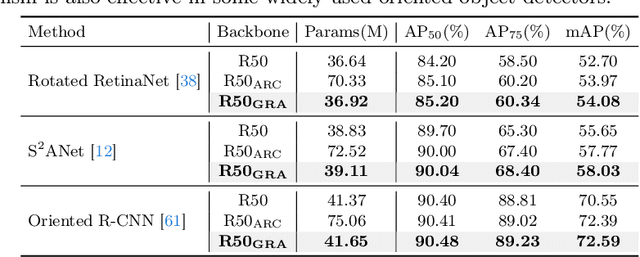
Oriented object detection, an emerging task in recent years, aims to identify and locate objects across varied orientations. This requires the detector to accurately capture the orientation information, which varies significantly within and across images. Despite the existing substantial efforts, simultaneously ensuring model effectiveness and parameter efficiency remains challenging in this scenario. In this paper, we propose a lightweight yet effective Group-wise Rotating and Attention (GRA) module to replace the convolution operations in backbone networks for oriented object detection. GRA can adaptively capture fine-grained features of objects with diverse orientations, comprising two key components: Group-wise Rotating and Group-wise Attention. Group-wise Rotating first divides the convolution kernel into groups, where each group extracts different object features by rotating at a specific angle according to the object orientation. Subsequently, Group-wise Attention is employed to adaptively enhance the object-related regions in the feature. The collaborative effort of these components enables GRA to effectively capture the various orientation information while maintaining parameter efficiency. Extensive experimental results demonstrate the superiority of our method. For example, GRA achieves a new state-of-the-art (SOTA) on the DOTA-v2.0 benchmark, while saving the parameters by nearly 50% compared to the previous SOTA method. Code will be released.