 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Task Learning Regression via Convex Clustering
Apr 26, 2023
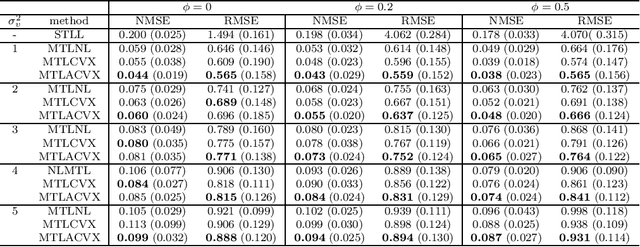
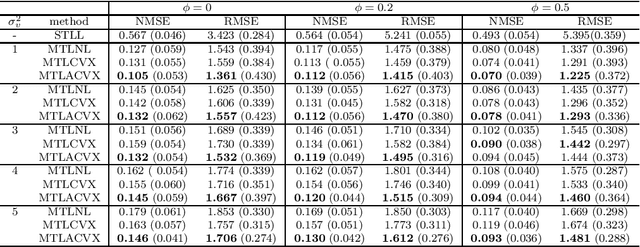
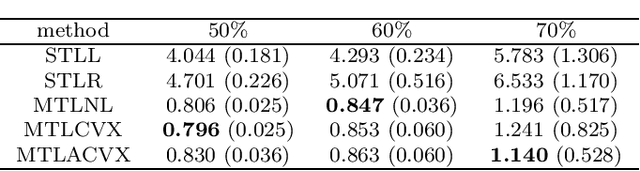
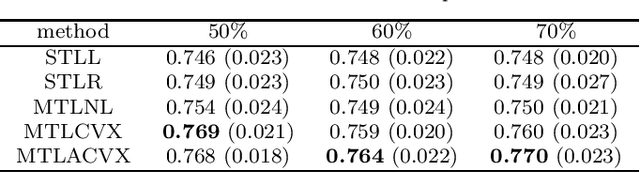
Multi-task learning (MTL) is a methodology that aims to improve the general performance of estimation and prediction by sharing common information among related tasks. In the MTL, there are several assumptions for the relationships and methods to incorporate them. One of the natural assumptions in the practical situation is that tasks are classified into some clusters with their characteristics. For this assumption, the group fused regularization approach performs clustering of the tasks by shrinking the difference among tasks. This enables us to transfer common information within the same cluster. However, this approach also transfers the information between different clusters, which worsens the estimation and prediction. To overcome this problem, we propose an MTL method with a centroid parameter representing a cluster center of the task. Because this model separates parameters into the parameters for regression and the parameters for clustering, we can improve estimation and prediction accuracy for regression coefficient vectors. We show the effectiveness of the proposed method through Monte Carlo simulations and applications to real data.
MasonNLP+ at SemEval-2023 Task 8: Extracting Medical Questions, Experiences and Claims from Social Media using Knowledge-Augmented Pre-trained Language Models
Apr 26, 2023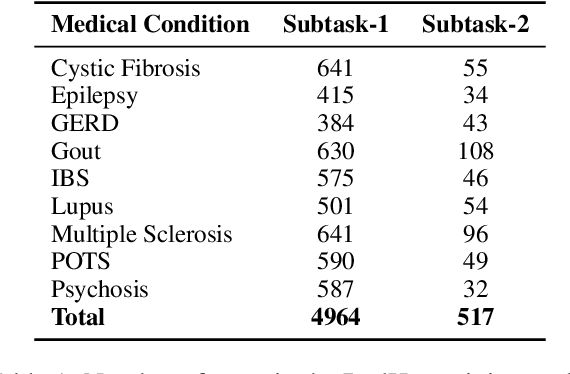



In online forums like Reddit, users share their experiences with medical conditions and treatments, including making claims, asking questions, and discussing the effects of treatments on their health. Building systems to understand this information can effectively monitor the spread of misinformation and verify user claims. The Task-8 of the 2023 International Workshop on Semantic Evaluation focused on medical applications, specifically extracting patient experience- and medical condition-related entities from user posts on social media. The Reddit Health Online Talk (RedHot) corpus contains posts from medical condition-related subreddits with annotations characterizing the patient experience and medical conditions. In Subtask-1, patient experience is characterized by personal experience, questions, and claims. In Subtask-2, medical conditions are characterized by population, intervention, and outcome. For the automatic extraction of patient experiences and medical condition information, as a part of the challenge, we proposed language-model-based extraction systems that ranked $3^{rd}$ on both subtasks' leaderboards. In this work, we describe our approach and, in addition, explore the automatic extraction of this information using domain-specific language models and the inclusion of external knowledge.
Iterative fluctuation ghost imaging
Apr 22, 2023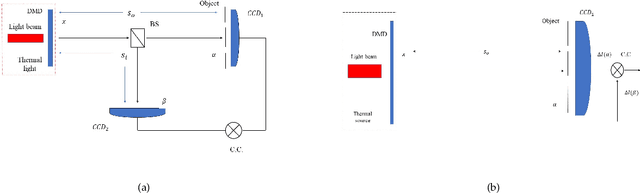
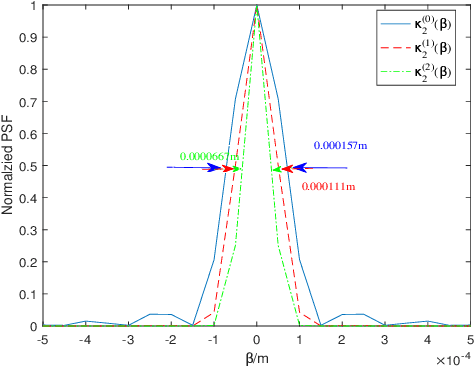

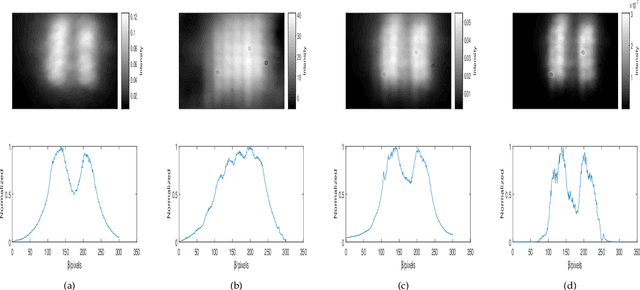
We present a new technique, iterative fluctuation ghost imaging (IFGI) which dramatically enhances the resolution of ghost imaging (GI). It is shown that, by the fluctuation characteristics of the second-order correlation function, the imaging information with the narrower point spread function (PSF) than the original information can be got. The effects arising from the PSF and the iteration times also be discussed.
Vision Transformer Off-the-Shelf: A Surprising Baseline for Few-Shot Class-Agnostic Counting
May 08, 2023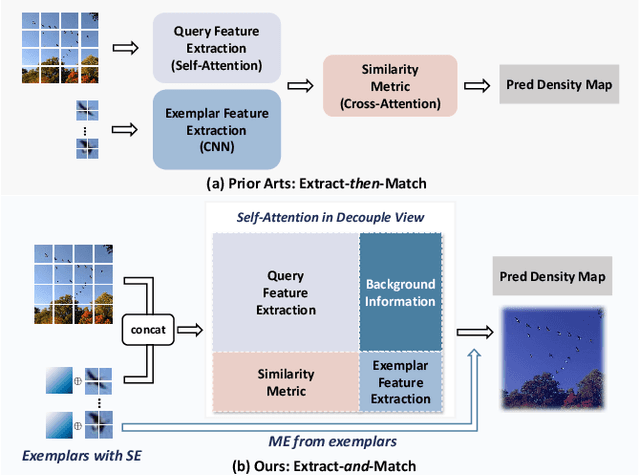
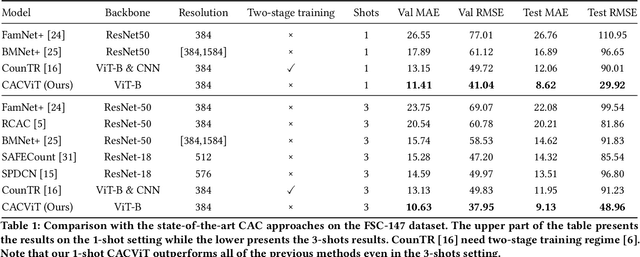
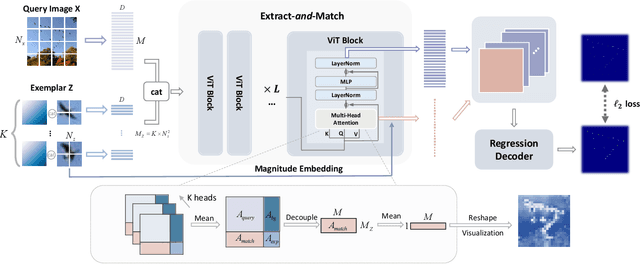
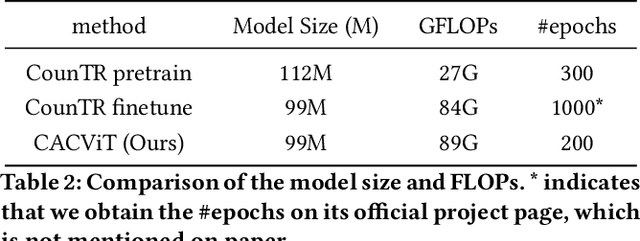
Class-agnostic counting (CAC) aims to count objects of interest from a query image given few exemplars. This task is typically addressed by extracting the features of query image and exemplars respectively with (un)shared feature extractors and by matching their feature similarity, leading to an extract-\textit{then}-match paradigm. In this work, we show that CAC can be simplified in an extract-\textit{and}-match manner, particularly using a pretrained and plain vision transformer (ViT) where feature extraction and similarity matching are executed simultaneously within the self-attention. We reveal the rationale of such simplification from a decoupled view of the self-attention and point out that the simplification is only made possible if the query and exemplar tokens are concatenated as input. The resulting model, termed CACViT, simplifies the CAC pipeline and unifies the feature spaces between the query image and exemplars. In addition, we find CACViT naturally encodes background information within self-attention, which helps reduce background disturbance. Further, to compensate the loss of the scale and the order-of-magnitude information due to resizing and normalization in ViT, we present two effective strategies for scale and magnitude embedding. Extensive experiments on the FSC147 and the CARPK datasets show that CACViT significantly outperforms state-of-the-art CAC approaches in both effectiveness (23.60% error reduction) and generalization, which suggests CACViT provides a concise and strong baseline for CAC. Code will be available.
Do Large Language Models Show Decision Heuristics Similar to Humans? A Case Study Using GPT-3.5
May 08, 2023


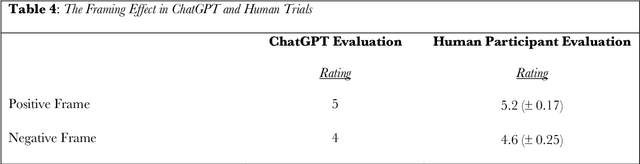
A Large Language Model (LLM) is an artificial intelligence system that has been trained on vast amounts of natural language data, enabling it to generate human-like responses to written or spoken language input. GPT-3.5 is an example of an LLM that supports a conversational agent called ChatGPT. In this work, we used a series of novel prompts to determine whether ChatGPT shows heuristics, biases, and other decision effects. We also tested the same prompts on human participants. Across four studies, we found that ChatGPT was influenced by random anchors in making estimates (Anchoring Heuristic, Study 1); it judged the likelihood of two events occurring together to be higher than the likelihood of either event occurring alone, and it was erroneously influenced by salient anecdotal information (Representativeness and Availability Heuristic, Study 2); it found an item to be more efficacious when its features were presented positively rather than negatively - even though both presentations contained identical information (Framing Effect, Study 3); and it valued an owned item more than a newly found item even though the two items were identical (Endowment Effect, Study 4). In each study, human participants showed similar effects. Heuristics and related decision effects in humans are thought to be driven by cognitive and affective processes such as loss aversion and effort reduction. The fact that an LLM - which lacks these processes - also shows such effects invites consideration of the possibility that language may play a role in generating these effects in humans.
Breaking Through the Haze: An Advanced Non-Homogeneous Dehazing Method based on Fast Fourier Convolution and ConvNeXt
May 08, 2023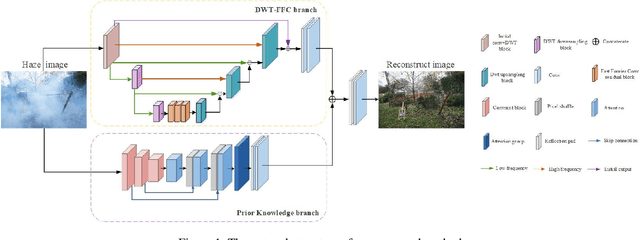

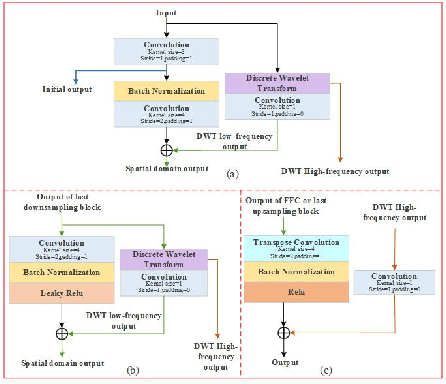
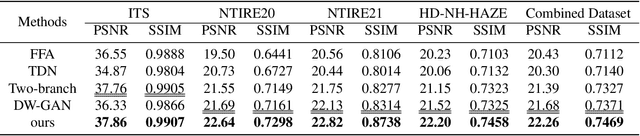
Haze usually leads to deteriorated images with low contrast, color shift and structural distortion. We observe that many deep learning based models exhibit exceptional performance on removing homogeneous haze, but they usually fail to address the challenge of non-homogeneous dehazing. Two main factors account for this situation. Firstly, due to the intricate and non uniform distribution of dense haze, the recovery of structural and chromatic features with high fidelity is challenging, particularly in regions with heavy haze. Secondly, the existing small scale datasets for non-homogeneous dehazing are inadequate to support reliable learning of feature mappings between hazy images and their corresponding haze-free counterparts by convolutional neural network (CNN)-based models. To tackle these two challenges, we propose a novel two branch network that leverages 2D discrete wavelete transform (DWT), fast Fourier convolution (FFC) residual block and a pretrained ConvNeXt model. Specifically, in the DWT-FFC frequency branch, our model exploits DWT to capture more high-frequency features. Moreover, by taking advantage of the large receptive field provided by FFC residual blocks, our model is able to effectively explore global contextual information and produce images with better perceptual quality. In the prior knowledge branch, an ImageNet pretrained ConvNeXt as opposed to Res2Net is adopted. This enables our model to learn more supplementary information and acquire a stronger generalization ability. The feasibility and effectiveness of the proposed method is demonstrated via extensive experiments and ablation studies. The code is available at https://github.com/zhouh115/DWT-FFC.
Adapt and Align to Improve Zero-Shot Sketch-Based Image Retrieval
May 18, 2023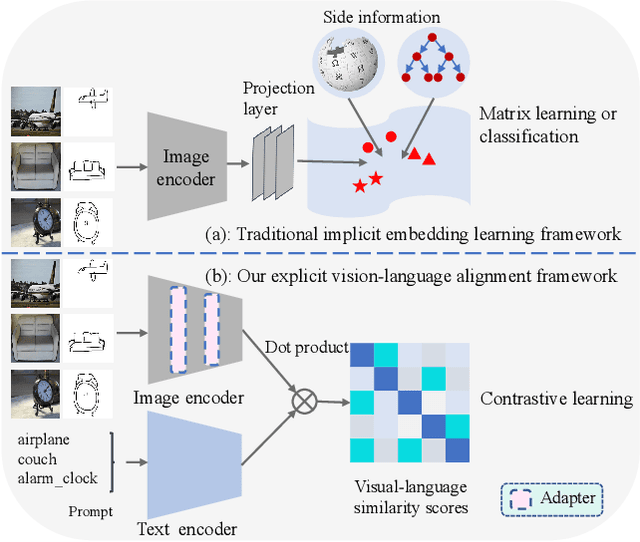
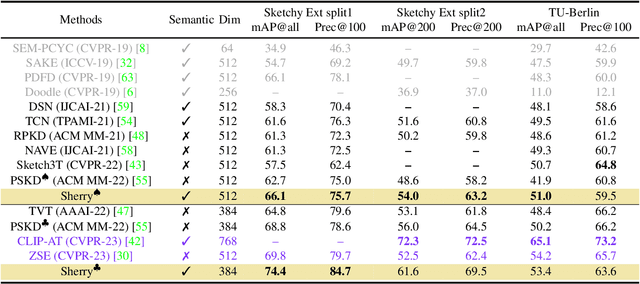
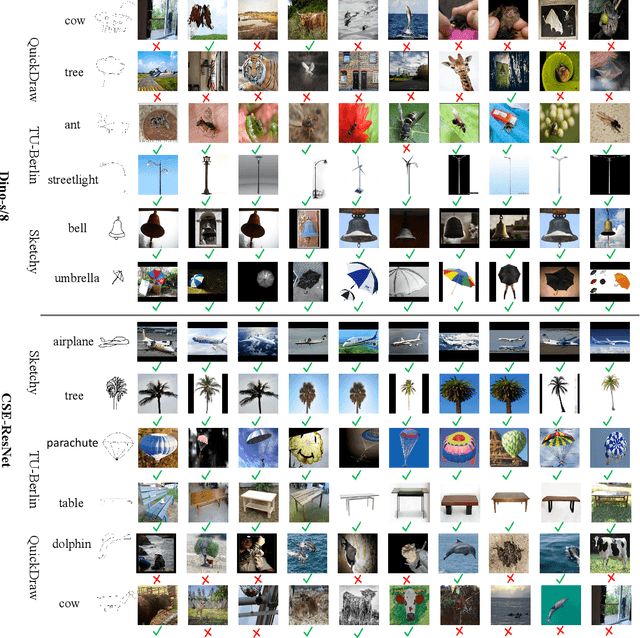
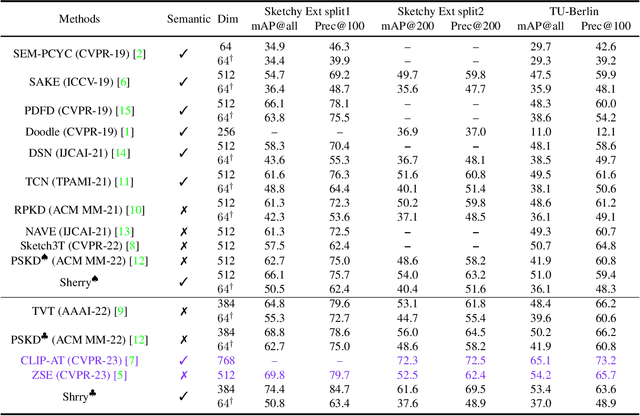
Zero-shot sketch-based image retrieval (ZS-SBIR) is challenging due to the cross-domain nature of sketches and photos, as well as the semantic gap between seen and unseen image distributions. Previous methods fine-tune pre-trained models with various side information and learning strategies to learn a compact feature space that is shared between the sketch and photo domains and bridges seen and unseen classes. However, these efforts are inadequate in adapting domains and transferring knowledge from seen to unseen classes. In this paper, we present an effective ``Adapt and Align'' approach to address the key challenges. Specifically, we insert simple and lightweight domain adapters to learn new abstract concepts of the sketch domain and improve cross-domain representation capabilities. Inspired by recent advances in image-text foundation models (e.g., CLIP) on zero-shot scenarios, we explicitly align the learned image embedding with a more semantic text embedding to achieve the desired knowledge transfer from seen to unseen classes. Extensive experiments on three benchmark datasets and two popular backbones demonstrate the superiority of our method in terms of retrieval accuracy and flexibility.
MetaGAD: Learning to Meta Transfer for Few-shot Graph Anomaly Detection
May 18, 2023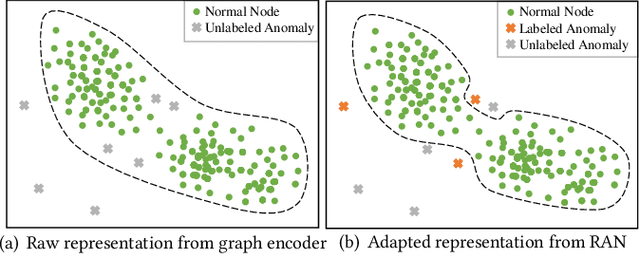
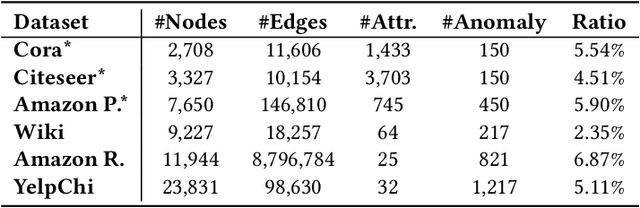
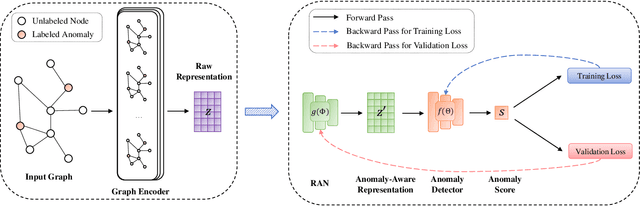
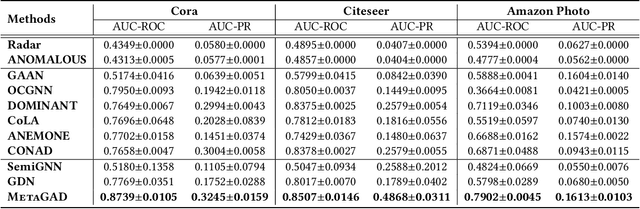
Graph anomaly detection has long been an important problem in various domains pertaining to information security such as financial fraud, social spam, network intrusion, etc. The majority of existing methods are performed in an unsupervised manner, as labeled anomalies in a large scale are often too expensive to acquire. However, the identified anomalies may turn out to be data noises or uninteresting data instances due to the lack of prior knowledge on the anomalies. In realistic scenarios, it is often feasible to obtain limited labeled anomalies, which have great potential to advance graph anomaly detection. However, the work exploring limited labeled anomalies and a large amount of unlabeled nodes in graphs to detect anomalies is rather limited. Therefore, in this paper, we study a novel problem of few-shot graph anomaly detection. We propose a new framework MetaGAD to learn to meta-transfer the knowledge between unlabeled and labeled nodes for graph anomaly detection. Experimental results on six real-world datasets with synthetic anomalies and "organic" anomalies (available in the dataset) demonstrate the effectiveness of the proposed approach in detecting anomalies with limited labeled anomalies.
Unsupervised Pansharpening via Low-rank Diffusion Model
May 18, 2023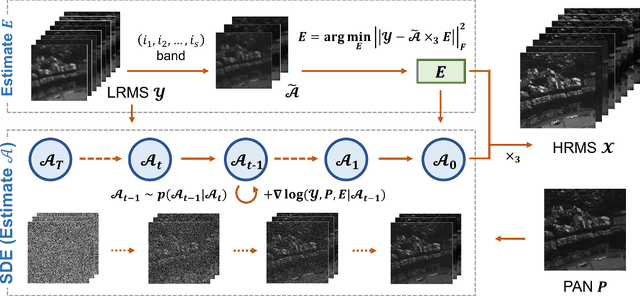


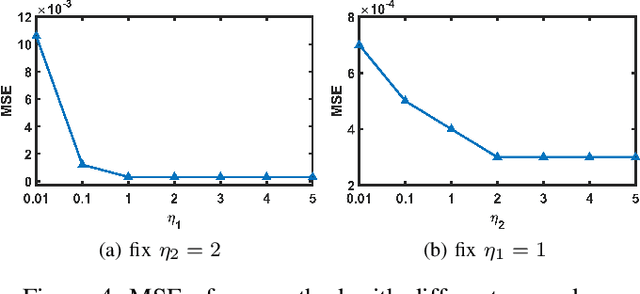
Pansharpening is a process of merging a highresolution panchromatic (PAN) image and a low-resolution multispectral (LRMS) image to create a single high-resolution multispectral (HRMS) image. Most of the existing deep learningbased pansharpening methods have poor generalization ability and the traditional model-based pansharpening methods need careful manual exploration for the image structure prior. To alleviate these issues, this paper proposes an unsupervised pansharpening method by combining the diffusion model with the low-rank matrix factorization technique. Specifically, we assume that the HRMS image is decomposed into the product of two low-rank tensors, i.e., the base tensor and the coefficient matrix. The base tensor lies on the image field and has low spectral dimension, we can thus conveniently utilize a pre-trained remote sensing diffusion model to capture its image structures. Additionally, we derive a simple yet quite effective way to preestimate the coefficient matrix from the observed LRMS image, which preserves the spectral information of the HRMS. Extensive experimental results on some benchmark datasets demonstrate that our proposed method performs better than traditional model-based approaches and has better generalization ability than deep learning-based techniques. The code is released in https://github.com/xyrui/PLRDiff.
Preference or Intent? Double Disentangled Collaborative Filtering
May 18, 2023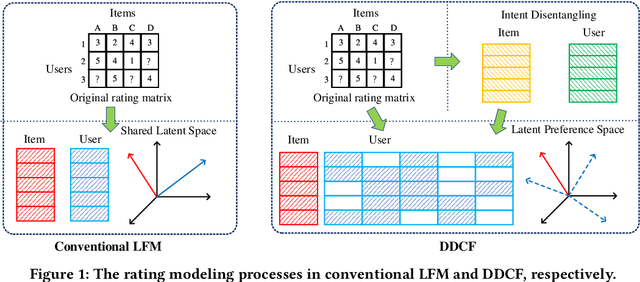
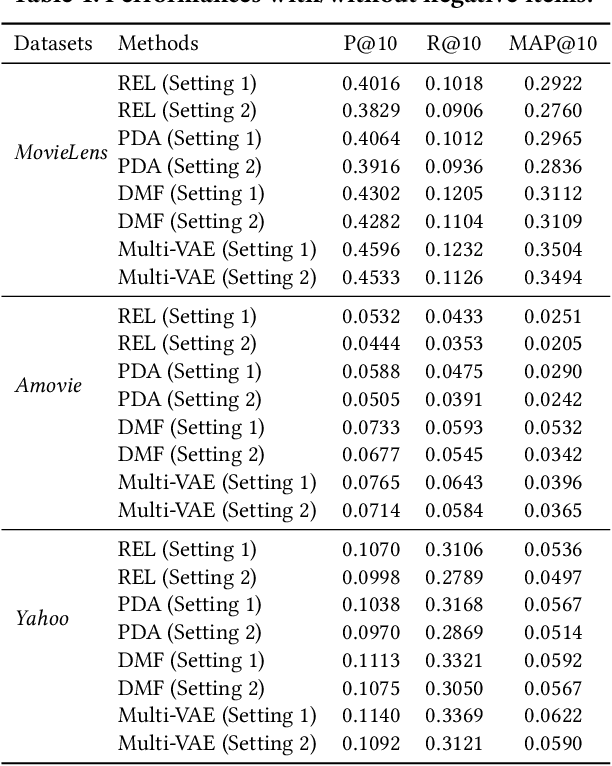
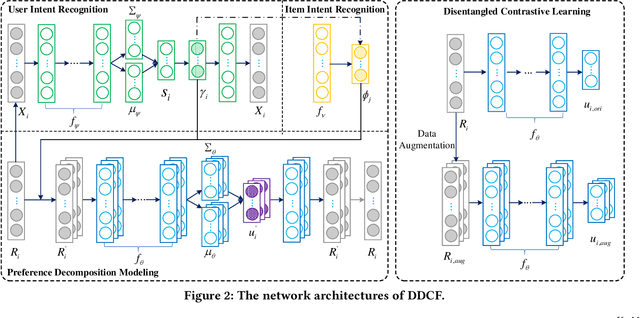
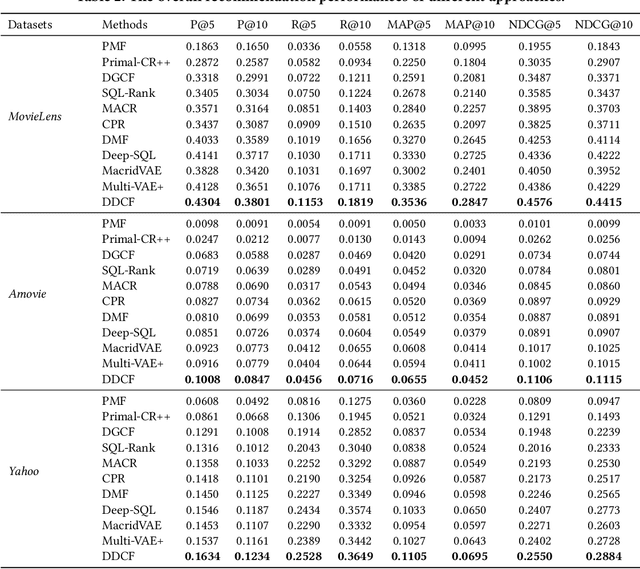
People usually have different intents for choosing items, while their preferences under the same intent may also different. In traditional collaborative filtering approaches, both intent and preference factors are usually entangled in the modeling process, which significantly limits the robustness and interpretability of recommendation performances. For example, the low-rating items are always treated as negative feedback while they actually could provide positive information about user intent. To this end, in this paper, we propose a two-fold representation learning approach, namely Double Disentangled Collaborative Filtering (DDCF), for personalized recommendations. The first-level disentanglement is for separating the influence factors of intent and preference, while the second-level disentanglement is performed to build independent sparse preference representations under individual intent with limited computational complexity. Specifically, we employ two variational autoencoder networks, intent recognition network and preference decomposition network, to learn the intent and preference factors, respectively. In this way, the low-rating items will be treated as positive samples for modeling intents while the negative samples for modeling preferences. Finally, extensive experiments on three real-world datasets and four evaluation metrics clearly validate the effectiveness and the interpretability of DDCF.