 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Transferring Visual Attributes from Natural Language to Verified Image Generation
May 24, 2023
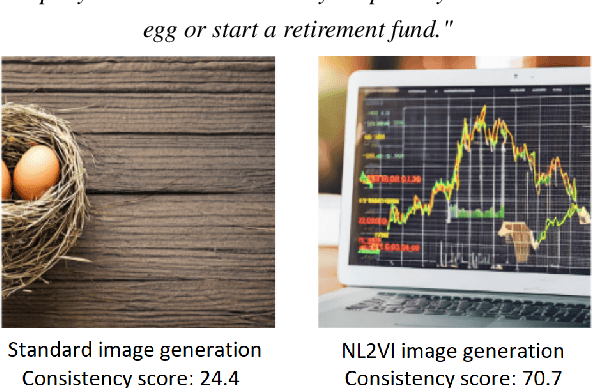

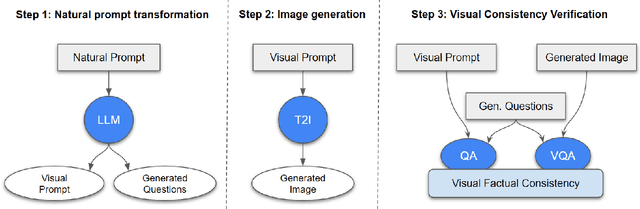
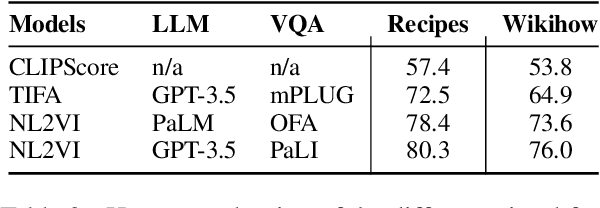
Text to image generation methods (T2I) are widely popular in generating art and other creative artifacts. While visual hallucinations can be a positive factor in scenarios where creativity is appreciated, such artifacts are poorly suited for cases where the generated image needs to be grounded in complex natural language without explicit visual elements. In this paper, we propose to strengthen the consistency property of T2I methods in the presence of natural complex language, which often breaks the limits of T2I methods by including non-visual information, and textual elements that require knowledge for accurate generation. To address these phenomena, we propose a Natural Language to Verified Image generation approach (NL2VI) that converts a natural prompt into a visual prompt, which is more suitable for image generation. A T2I model then generates an image for the visual prompt, which is then verified with VQA algorithms. Experimentally, aligning natural prompts with image generation can improve the consistency of the generated images by up to 11% over the state of the art. Moreover, improvements can generalize to challenging domains like cooking and DIY tasks, where the correctness of the generated image is crucial to illustrate actions.
Learning Semantic Role Labeling from Compatible Label Sequences
May 24, 2023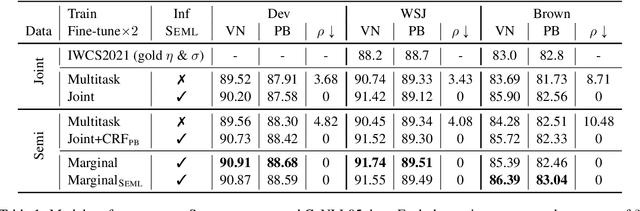
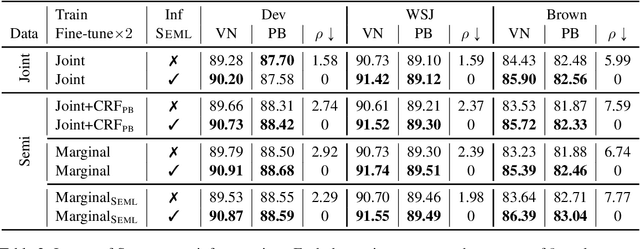
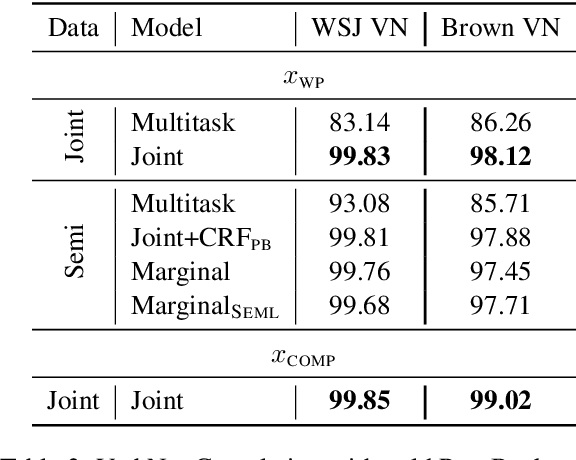
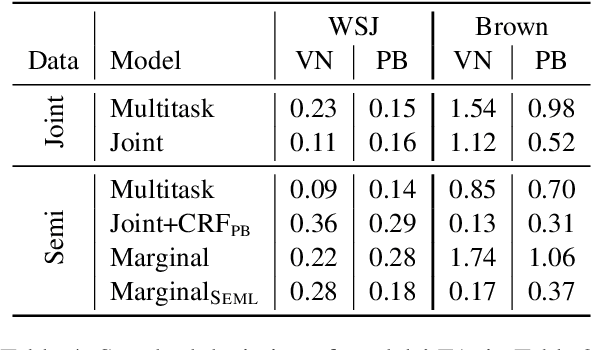
This paper addresses the question of how to efficiently learn from disjoint, compatible label sequences. We argue that the compatible structures between disjoint label sets help model learning and inference. We verify this hypothesis on the task of semantic role labeling (SRL), specifically, tagging a sentence with two role sequences: VerbNet arguments and PropBank arguments. Prior work has shown that cross-task interaction improves performance. However, the two tasks are still separately decoded, running the risk of generating structurally inconsistent label sequences (as per lexicons like SEMLINK). To eliminate this issue, we first propose a simple and effective setup that jointly handles VerbNet and PropBank labels as one sequence. With this setup, we show that enforcing SEMLINK constraints during decoding constantly improves the overall F1. With special input constructions, our joint model infers VerbNet arguments from PropBank arguments with over 99% accuracy. We also propose a constrained marginal model that uses SEMLINK information during training to further benefit from the large amounts of PropBank-only data. Our models achieve state-of-the-art F1's on VerbNet and PropBank argument labeling on the CoNLL05 dataset with strong out-of-domain generalization.
Radiomap Inpainting for Restricted Areas based on Propagation Priority and Depth Map
May 24, 2023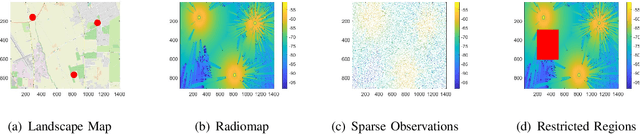
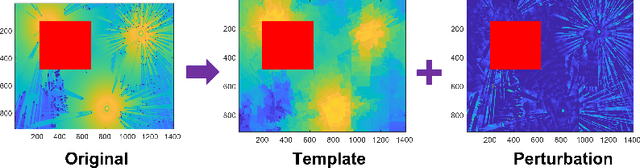
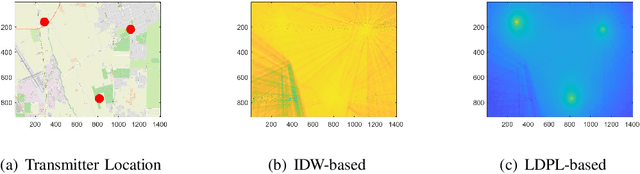
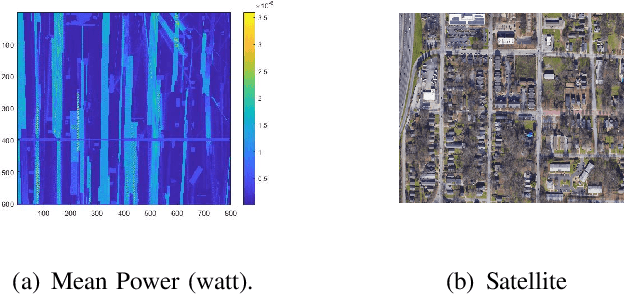
Providing rich and useful information regarding spectrum activities and propagation channels, radiomaps characterize the detailed distribution of power spectral density (PSD) and are important tools for network planning in modern wireless systems. Generally, radiomaps are constructed from radio strength measurements by deployed sensors and user devices. However, not all areas are accessible for radio measurements due to physical constraints and security consideration, leading to non-uniformly spaced measurements and blanks on a radiomap. In this work, we explore distribution of radio spectrum strengths in view of surrounding environments, and propose two radiomap inpainting approaches for the reconstruction of radiomaps that cover missing areas. Specifically, we first define a propagation-based priority and integrate exemplar-based inpainting with radio propagation model for fine-resolution small-size missing area reconstruction on a radiomap. Then, we introduce a novel radio depth map and propose a two-step template-perturbation approach for large-size restricted region inpainting. Our experimental results demonstrate the power of the proposed propagation priority and radio depth map in capturing the PSD distribution, as well as the efficacy of the proposed methods for radiomap reconstruction.
Localizing Multiple Radiation Sources Actively with a Particle Filter
May 24, 2023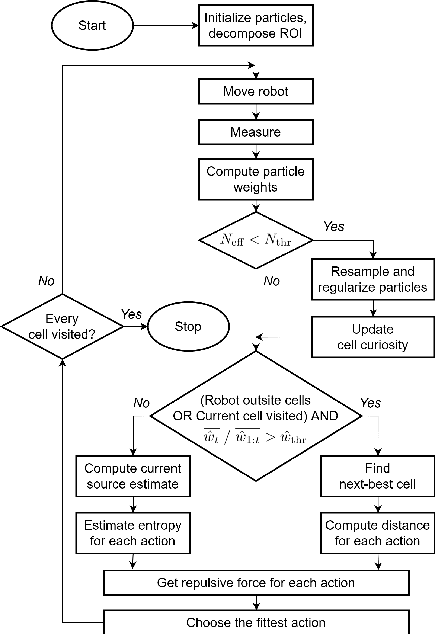
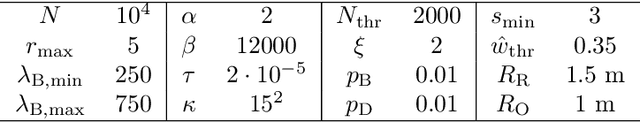
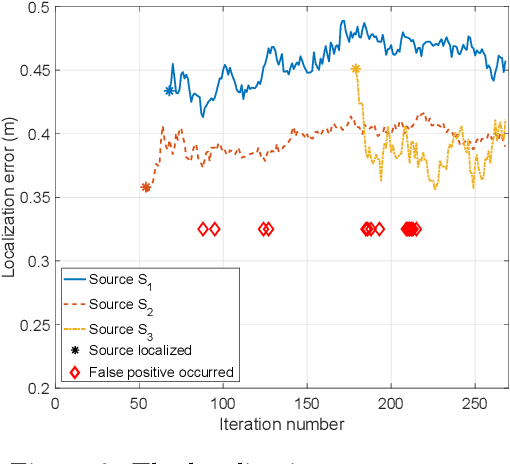
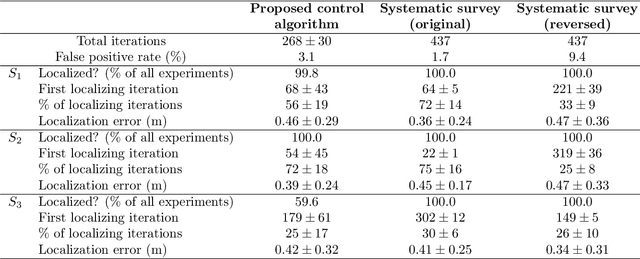
The article discusses the localization of radiation sources whose number and other relevant parameters are not known in advance. The data collection is ensured by an autonomous mobile robot that performs a survey in a defined region of interest populated with static obstacles. The measurement trajectory is information-driven rather than pre-planned. The localization exploits a regularized particle filter estimating the sources' parameters continuously. The dynamic robot control switches between two modes, one attempting to minimize the Shannon entropy and the other aiming to reduce the variance of expected measurements in unexplored parts of the target area; both of the modes maintain safe clearance from the obstacles. The performance of the algorithms was tested in a simulation study based on real-world data acquired previously from three radiation sources exhibiting various activities. Our approach reduces the time necessary to explore the region and to find the sources by approximately 40 %; at present, however, the method is unable to reliably localize sources that have a relatively low intensity. In this context, additional research has been planned to increase the credibility and robustness of the procedure and to improve the robotic platform autonomy.
ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers
May 24, 2023
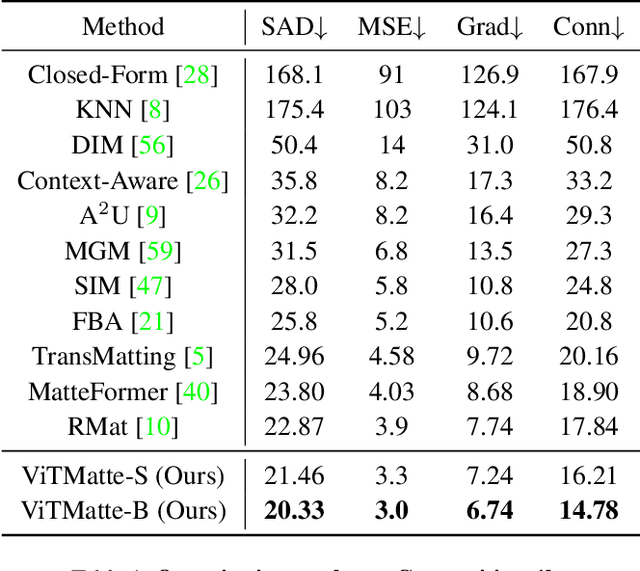
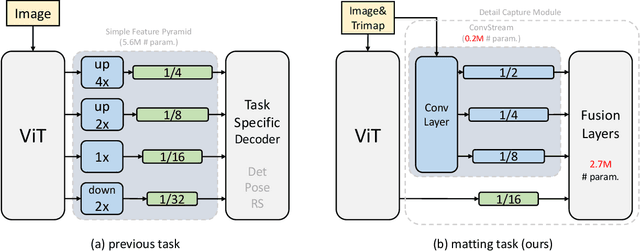
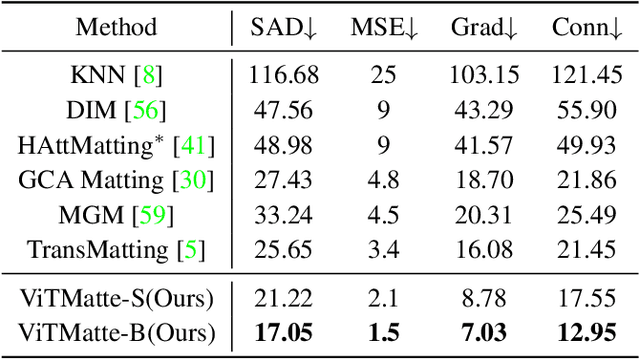
Recently, plain vision Transformers (ViTs) have shown impressive performance on various computer vision tasks, thanks to their strong modeling capacity and large-scale pretraining. However, they have not yet conquered the problem of image matting. We hypothesize that image matting could also be boosted by ViTs and present a new efficient and robust ViT-based matting system, named ViTMatte. Our method utilizes (i) a hybrid attention mechanism combined with a convolution neck to help ViTs achieve an excellent performance-computation trade-off in matting tasks. (ii) Additionally, we introduce the detail capture module, which just consists of simple lightweight convolutions to complement the detailed information required by matting. To the best of our knowledge, ViTMatte is the first work to unleash the potential of ViT on image matting with concise adaptation. It inherits many superior properties from ViT to matting, including various pretraining strategies, concise architecture design, and flexible inference strategies. We evaluate ViTMatte on Composition-1k and Distinctions-646, the most commonly used benchmark for image matting, our method achieves state-of-the-art performance and outperforms prior matting works by a large margin.
Guided Focal Stack Refinement Network for Light Field Salient Object Detection
May 09, 2023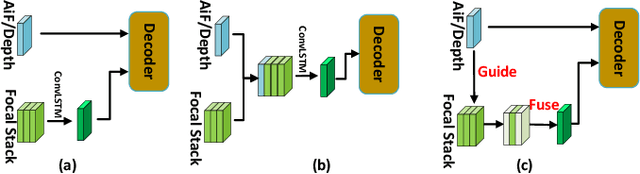
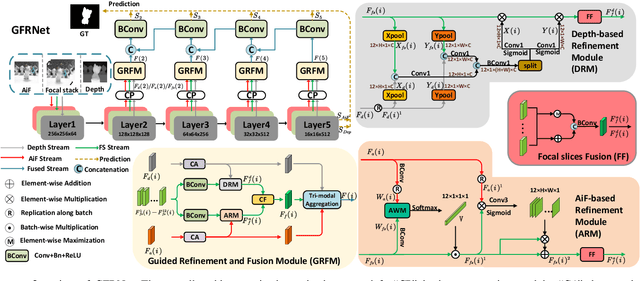
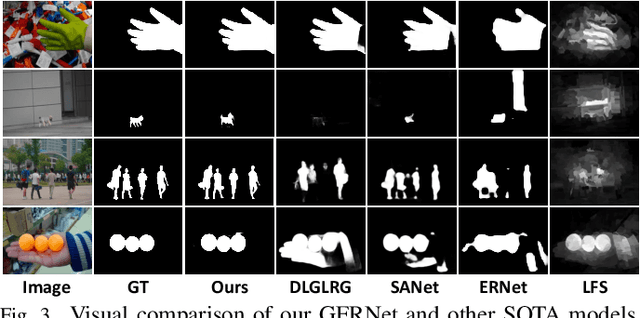
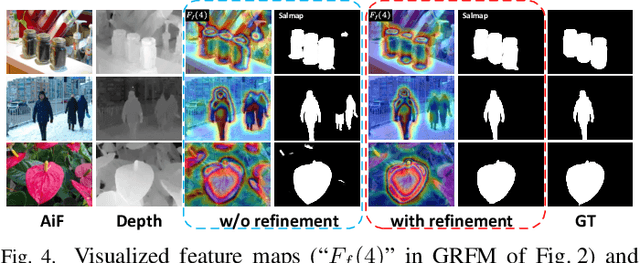
Light field salient object detection (SOD) is an emerging research direction attributed to the richness of light field data. However, most existing methods lack effective handling of focal stacks, therefore making the latter involved in a lot of interfering information and degrade the performance of SOD. To address this limitation, we propose to utilize multi-modal features to refine focal stacks in a guided manner, resulting in a novel guided focal stack refinement network called GFRNet. To this end, we propose a guided refinement and fusion module (GRFM) to refine focal stacks and aggregate multi-modal features. In GRFM, all-in-focus (AiF) and depth modalities are utilized to refine focal stacks separately, leading to two novel sub-modules for different modalities, namely AiF-based refinement module (ARM) and depth-based refinement module (DRM). Such refinement modules enhance structural and positional information of salient objects in focal stacks, and are able to improve SOD accuracy. Experimental results on four benchmark datasets demonstrate the superiority of our GFRNet model against 12 state-of-the-art models.
SRIL: Selective Regularization for Class-Incremental Learning
May 09, 2023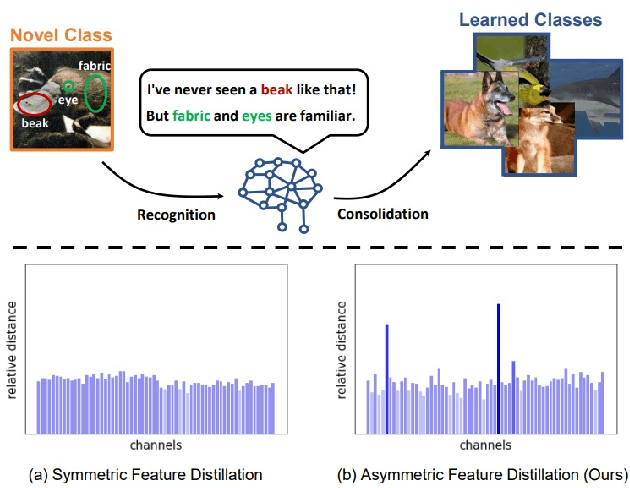
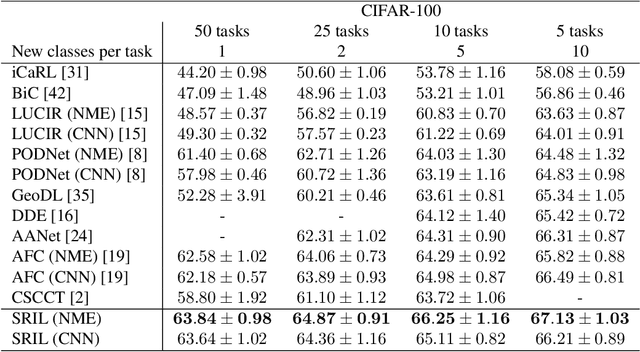
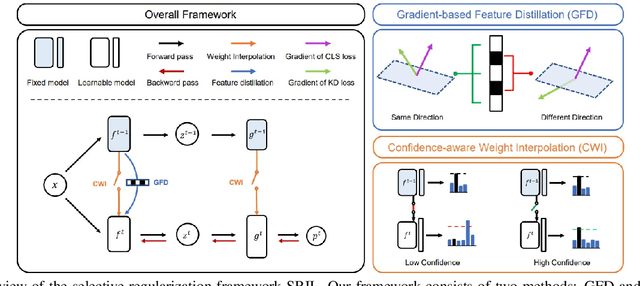
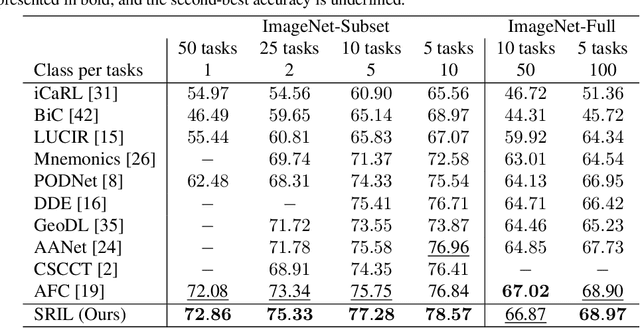
Human intelligence gradually accepts new information and accumulates knowledge throughout the lifespan. However, deep learning models suffer from a catastrophic forgetting phenomenon, where they forget previous knowledge when acquiring new information. Class-Incremental Learning aims to create an integrated model that balances plasticity and stability to overcome this challenge. In this paper, we propose a selective regularization method that accepts new knowledge while maintaining previous knowledge. We first introduce an asymmetric feature distillation method for old and new classes inspired by cognitive science, using the gradient of classification and knowledge distillation losses to determine whether to perform pattern completion or pattern separation. We also propose a method to selectively interpolate the weight of the previous model for a balance between stability and plasticity, and we adjust whether to transfer through model confidence to ensure the performance of the previous class and enable exploratory learning. We validate the effectiveness of the proposed method, which surpasses the performance of existing methods through extensive experimental protocols using CIFAR-100, ImageNet-Subset, and ImageNet-Full.
Connected Hidden Neurons (CHNNet): An Artificial Neural Network for Rapid Convergence
May 17, 2023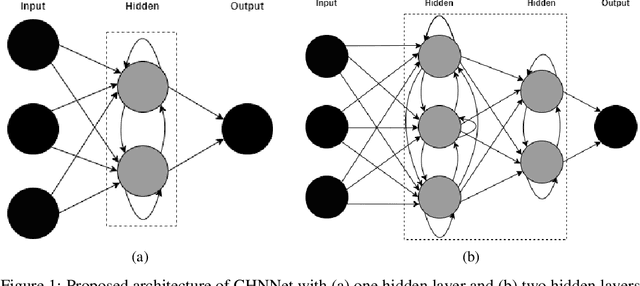
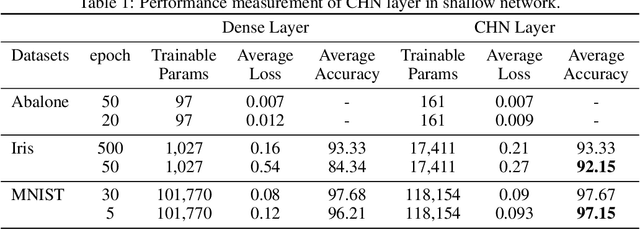
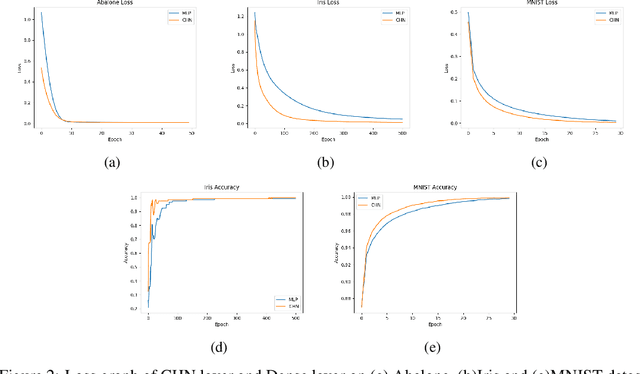
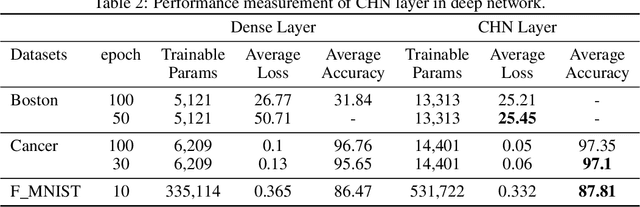
The core purpose of developing artificial neural networks was to mimic the functionalities of biological neural networks. However, unlike biological neural networks, traditional artificial neural networks are often structured hierarchically, which can impede the flow of information between neurons as the neurons in the same layer have no connections between them. Hence, we propose a more robust model of artificial neural networks where the hidden neurons, residing in the same hidden layer, are interconnected, enabling the neurons to learn complex patterns and speeding up the convergence rate. With the experimental study of our proposed model as fully connected layers in shallow and deep networks, we demonstrate that the model results in a significant increase in convergence rate.
Mining Themes in Clinical Notes to Identify Phenotypes and to Predict Length of Stay in Patients admitted with Heart Failure
May 30, 2023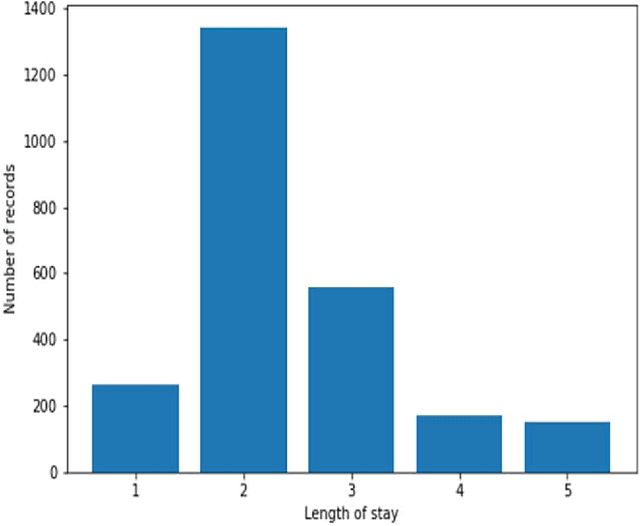
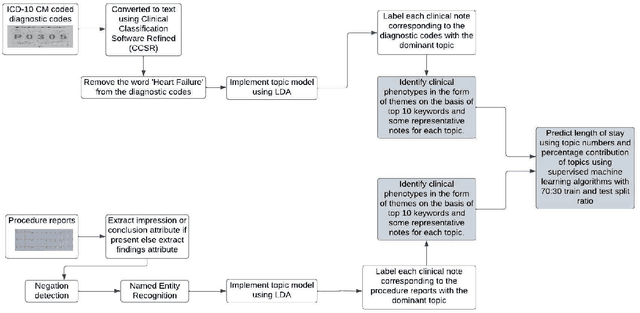

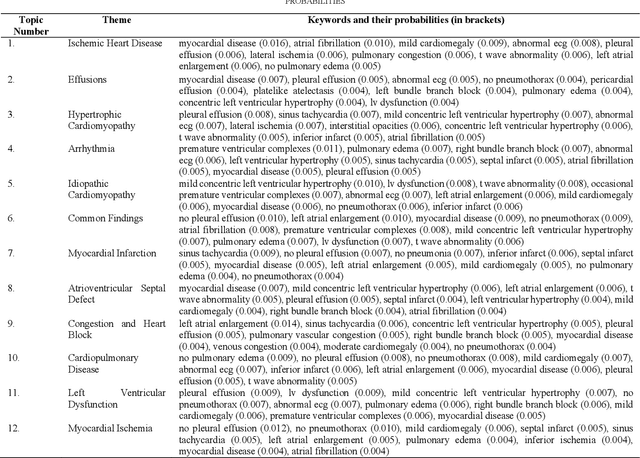
Heart failure is a syndrome which occurs when the heart is not able to pump blood and oxygen to support other organs in the body. Identifying the underlying themes in the diagnostic codes and procedure reports of patients admitted for heart failure could reveal the clinical phenotypes associated with heart failure and to group patients based on their similar characteristics which could also help in predicting patient outcomes like length of stay. These clinical phenotypes usually have a probabilistic latent structure and hence, as there has been no previous work on identifying phenotypes in clinical notes of heart failure patients using a probabilistic framework and to predict length of stay of these patients using data-driven artificial intelligence-based methods, we apply natural language processing technique, topic modeling, to identify the themes present in diagnostic codes and in procedure reports of 1,200 patients admitted for heart failure at the University of Illinois Hospital and Health Sciences System (UI Health). Topic modeling identified twelve themes each in diagnostic codes and procedure reports which revealed information about different phenotypes related to various perspectives about heart failure, to study patients' profiles and to discover new relationships among medical concepts. Each theme had a set of keywords and each clinical note was labeled with two themes - one corresponding to its diagnostic code and the other corresponding to its procedure reports along with their percentage contribution. We used these themes and their percentage contribution to predict length of stay. We found that the themes discovered in diagnostic codes and procedure reports using topic modeling together were able to predict length of stay of the patients with an accuracy of 61.1% and an Area under the Receiver Operating Characteristic Curve (ROC AUC) value of 0.828.
PanoGen: Text-Conditioned Panoramic Environment Generation for Vision-and-Language Navigation
May 30, 2023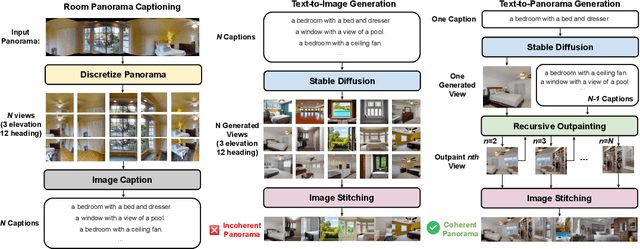
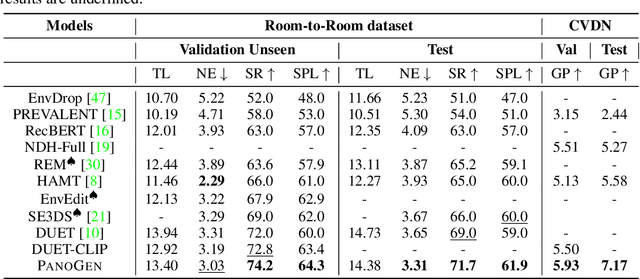
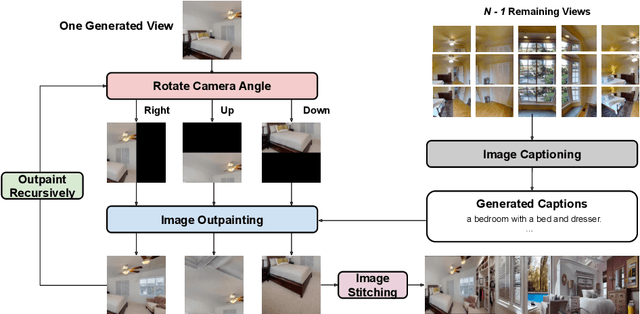
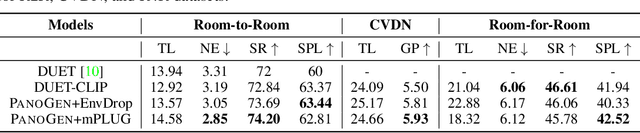
Vision-and-Language Navigation (VLN) requires the agent to follow language instructions to navigate through 3D environments. One main challenge in VLN is the limited availability of photorealistic training environments, which makes it hard to generalize to new and unseen environments. To address this problem, we propose PanoGen, a generation method that can potentially create an infinite number of diverse panoramic environments conditioned on text. Specifically, we collect room descriptions by captioning the room images in existing Matterport3D environments, and leverage a state-of-the-art text-to-image diffusion model to generate the new panoramic environments. We use recursive outpainting over the generated images to create consistent 360-degree panorama views. Our new panoramic environments share similar semantic information with the original environments by conditioning on text descriptions, which ensures the co-occurrence of objects in the panorama follows human intuition, and creates enough diversity in room appearance and layout with image outpainting. Lastly, we explore two ways of utilizing PanoGen in VLN pre-training and fine-tuning. We generate instructions for paths in our PanoGen environments with a speaker built on a pre-trained vision-and-language model for VLN pre-training, and augment the visual observation with our panoramic environments during agents' fine-tuning to avoid overfitting to seen environments. Empirically, learning with our PanoGen environments achieves the new state-of-the-art on the Room-to-Room, Room-for-Room, and CVDN datasets. Pre-training with our PanoGen speaker data is especially effective for CVDN, which has under-specified instructions and needs commonsense knowledge. Lastly, we show that the agent can benefit from training with more generated panoramic environments, suggesting promising results for scaling up the PanoGen environments.