 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
UL-DL duality for cell-free massive MIMO with per-AP power and information constraints
Jan 16, 2023
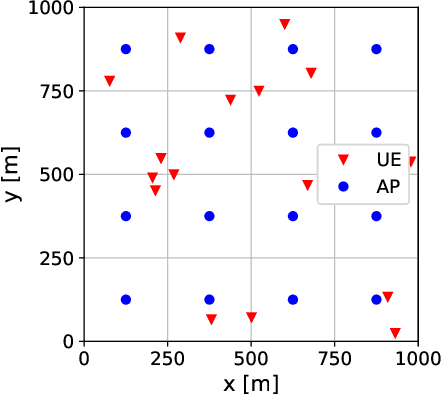
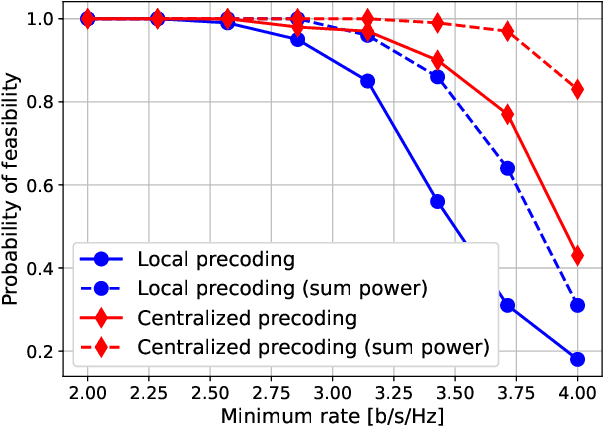
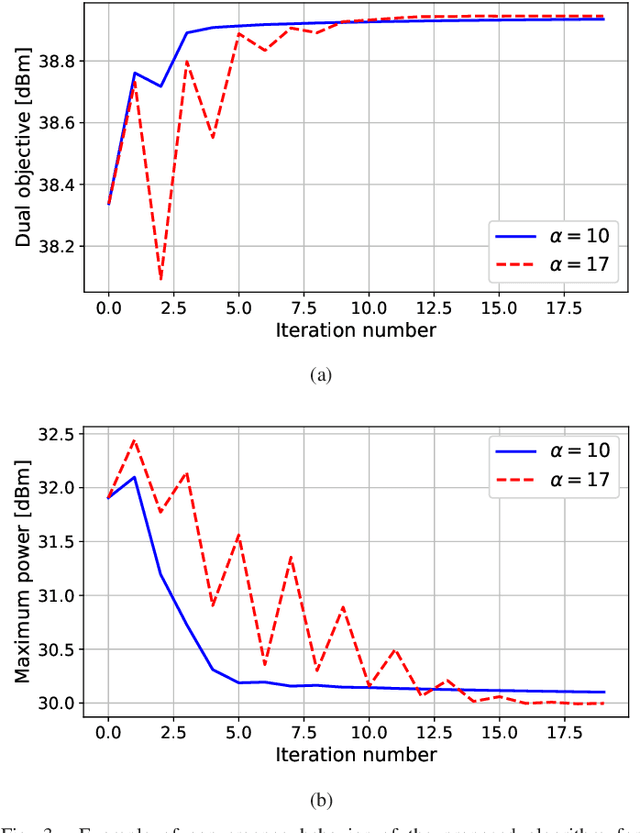
We derive a novel uplink-downlink duality principle for optimal joint precoding design under per-transmitter power and information constraints in fading channels. The main application is to cell-free networks, where each access point (AP) must typically satisfy an individual power constraint and form its transmit signal on the basis of possibly partial sharing of data bearing signals and channel state information. Our duality principle applies to ergodic achievable rates given by the popular hardening bound, and it can be interpreted as a nontrivial generalization of a previous result by Yu and Lan for deterministic channels. This generalization allows us to cover more involved information constraints, and to show that optimal joint precoders can be obtained using a variation of the recently developed team minimum mean-square error method. As particular examples, we solve the problems of optimal centralized and local precoding design in user-centric cell-free massive MIMO networks subject to per-AP power constraints.
Model Debiasing via Gradient-based Explanation on Representation
May 20, 2023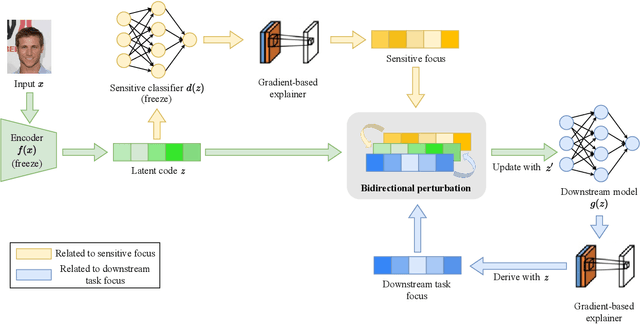



Machine learning systems produce biased results towards certain demographic groups, known as the fairness problem. Recent approaches to tackle this problem learn a latent code (i.e., representation) through disentangled representation learning and then discard the latent code dimensions correlated with sensitive attributes (e.g., gender). Nevertheless, these approaches may suffer from incomplete disentanglement and overlook proxy attributes (proxies for sensitive attributes) when processing real-world data, especially for unstructured data, causing performance degradation in fairness and loss of useful information for downstream tasks. In this paper, we propose a novel fairness framework that performs debiasing with regard to both sensitive attributes and proxy attributes, which boosts the prediction performance of downstream task models without complete disentanglement. The main idea is to, first, leverage gradient-based explanation to find two model focuses, 1) one focus for predicting sensitive attributes and 2) the other focus for predicting downstream task labels, and second, use them to perturb the latent code that guides the training of downstream task models towards fairness and utility goals. We show empirically that our framework works with both disentangled and non-disentangled representation learning methods and achieves better fairness-accuracy trade-off on unstructured and structured datasets than previous state-of-the-art approaches.
YOLO: An Efficient Terahertz Band Integrated Sensing and Communications Scheme with Beam Squint
May 20, 2023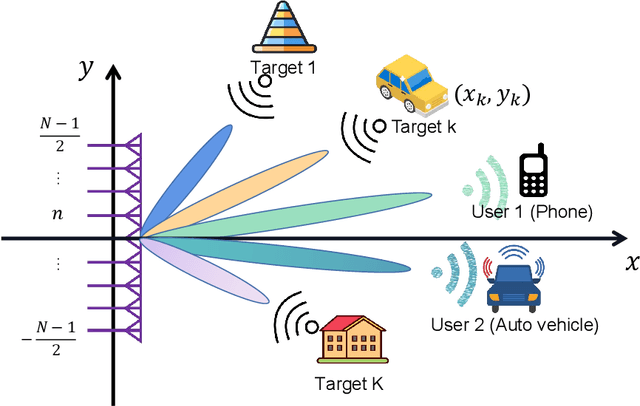
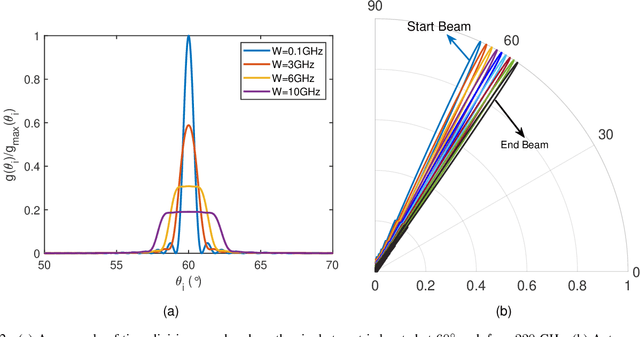
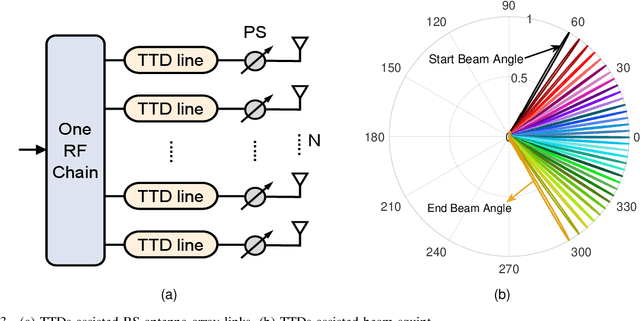
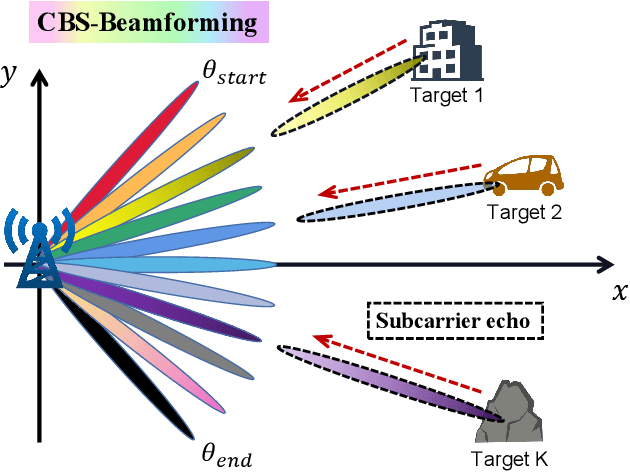
Using communications signals for localization is an important component of integrated sensing and communications (ISAC). In this paper, we propose to utilize the beam squint phenomenon to realize fast non-cooperative target localization in massive MIMO Terahertz band communications systems. Specifically, we construct the wideband channel model of the echo signal, and design a beamforming scheme that controls the range of beam squint by adjusting the values of phase shifters and true time delay lines (TTDs). By doing this, beams at different subcarriers can be aligned along different directions in a planned way. The received echo signals of different subcarriers will carry target information in different directions, based on which the targets' angles can be estimated through sophisticatedly designed algorithm. Moreover, we propose a supporting OFDM ranging algorithm that can estimate the targets' distances by comparing the theoretical phases and measured phases of the echo signals. Interestingly, the proposed localization method only needs the base station to transmit and receive the signals once, which can be termed You Only Listen Once (YOLO). Compared with the traditional ISAC method that requires multiple times beam sweeping, the proposed one greatly reduces the sensing overhead. Simulation results are provided to demonstrate the effectiveness of the proposed scheme.
Mitigating Catastrophic Forgetting in Task-Incremental Continual Learning with Adaptive Classification Criterion
May 20, 2023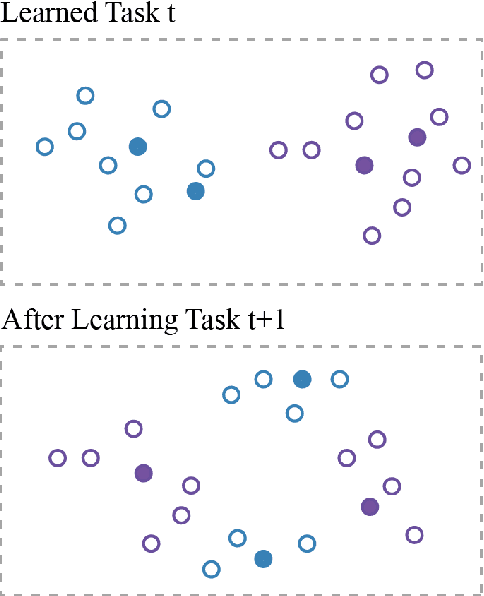

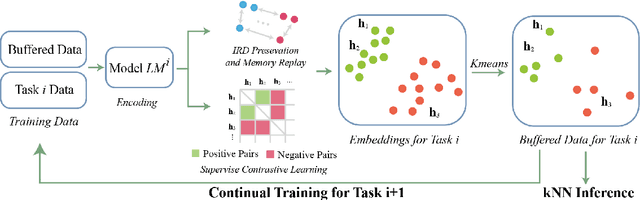
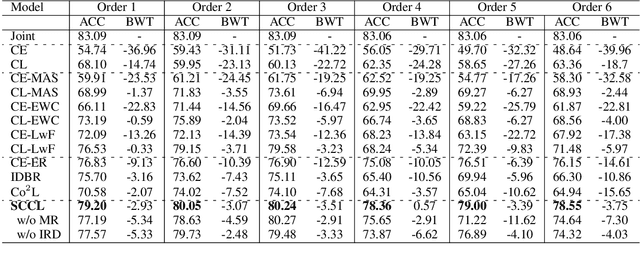
Task-incremental continual learning refers to continually training a model in a sequence of tasks while overcoming the problem of catastrophic forgetting (CF). The issue arrives for the reason that the learned representations are forgotten for learning new tasks, and the decision boundary is destructed. Previous studies mostly consider how to recover the representations of learned tasks. It is seldom considered to adapt the decision boundary for new representations and in this paper we propose a Supervised Contrastive learning framework with adaptive classification criterion for Continual Learning (SCCL), In our method, a contrastive loss is used to directly learn representations for different tasks and a limited number of data samples are saved as the classification criterion. During inference, the saved data samples are fed into the current model to obtain updated representations, and a k Nearest Neighbour module is used for classification. In this way, the extensible model can solve the learned tasks with adaptive criteria of saved samples. To mitigate CF, we further use an instance-wise relation distillation regularization term and a memory replay module to maintain the information of previous tasks. Experiments show that SCCL achieves state-of-the-art performance and has a stronger ability to overcome CF compared with the classification baselines.
Controlled illumination for perception and manipulation of Lambertian objects
Apr 24, 2023Controlling illumination can generate high quality information about object surface normals and depth discontinuities at a low computational cost. In this work we demonstrate a robot workspace-scaled controlled illumination approach that generates high quality information for table top scale objects for robotic manipulation. With our low angle of incidence directional illumination approach we can precisely capture surface normals and depth discontinuities of Lambertian objects. We demonstrate three use cases of our approach for robotic manipulation. We show that 1) by using the captured information we can perform general purpose grasping with a single point vacuum gripper, 2) we can visually measure the deformation of known objects, and 3) we can estimate pose of known objects and track unknown objects in the robot's workspace. Additional demonstrations of the results presented in the work can be viewed on the project webpage https://anonymousprojectsite.github.io/.
Cross-Modal Global Interaction and Local Alignment for Audio-Visual Speech Recognition
May 16, 2023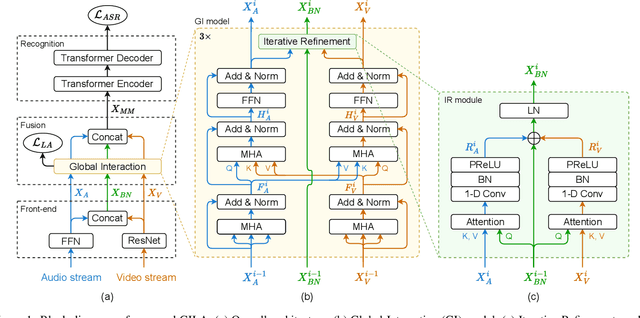
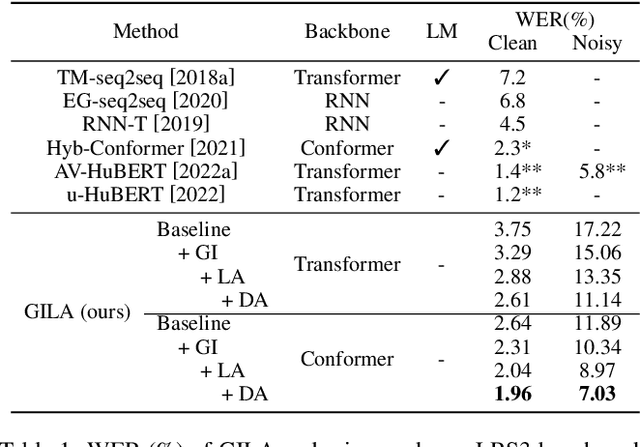
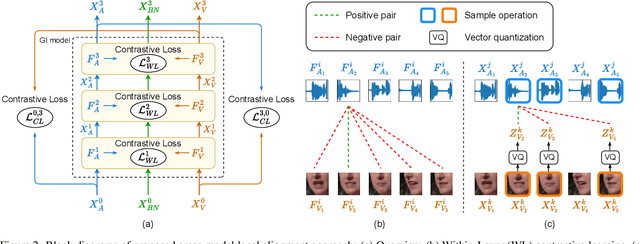
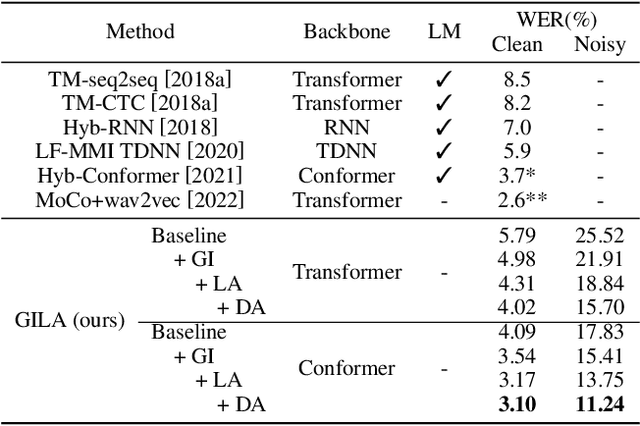
Audio-visual speech recognition (AVSR) research has gained a great success recently by improving the noise-robustness of audio-only automatic speech recognition (ASR) with noise-invariant visual information. However, most existing AVSR approaches simply fuse the audio and visual features by concatenation, without explicit interactions to capture the deep correlations between them, which results in sub-optimal multimodal representations for downstream speech recognition task. In this paper, we propose a cross-modal global interaction and local alignment (GILA) approach for AVSR, which captures the deep audio-visual (A-V) correlations from both global and local perspectives. Specifically, we design a global interaction model to capture the A-V complementary relationship on modality level, as well as a local alignment approach to model the A-V temporal consistency on frame level. Such a holistic view of cross-modal correlations enable better multimodal representations for AVSR. Experiments on public benchmarks LRS3 and LRS2 show that our GILA outperforms the supervised learning state-of-the-art.
UniS-MMC: Multimodal Classification via Unimodality-supervised Multimodal Contrastive Learning
May 16, 2023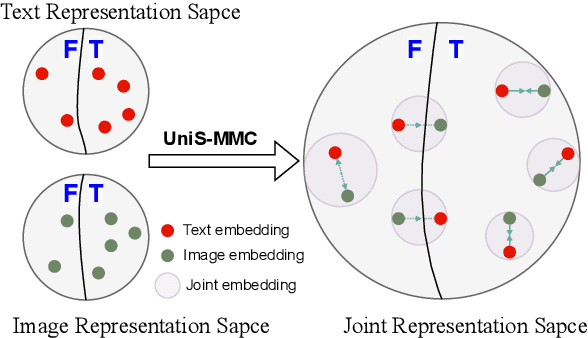
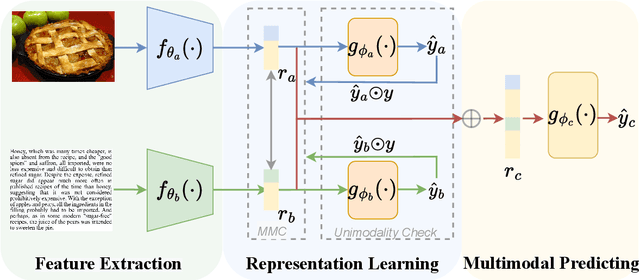
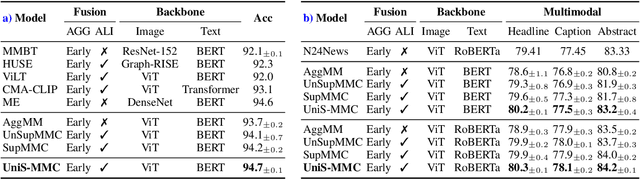
Multimodal learning aims to imitate human beings to acquire complementary information from multiple modalities for various downstream tasks. However, traditional aggregation-based multimodal fusion methods ignore the inter-modality relationship, treat each modality equally, suffer sensor noise, and thus reduce multimodal learning performance. In this work, we propose a novel multimodal contrastive method to explore more reliable multimodal representations under the weak supervision of unimodal predicting. Specifically, we first capture task-related unimodal representations and the unimodal predictions from the introduced unimodal predicting task. Then the unimodal representations are aligned with the more effective one by the designed multimodal contrastive method under the supervision of the unimodal predictions. Experimental results with fused features on two image-text classification benchmarks UPMC-Food-101 and N24News show that our proposed Unimodality-Supervised MultiModal Contrastive UniS-MMC learning method outperforms current state-of-the-art multimodal methods. The detailed ablation study and analysis further demonstrate the advantage of our proposed method.
Dual-Alignment Pre-training for Cross-lingual Sentence Embedding
May 16, 2023
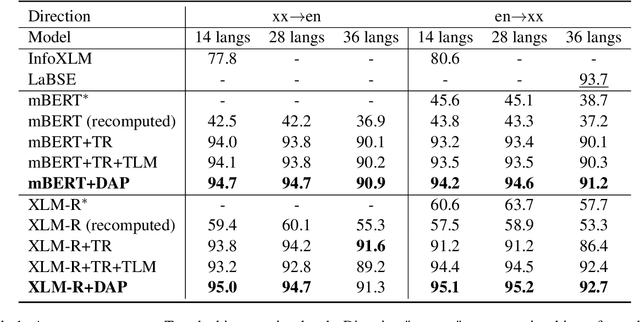
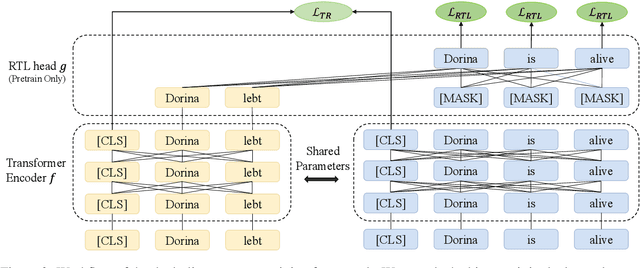
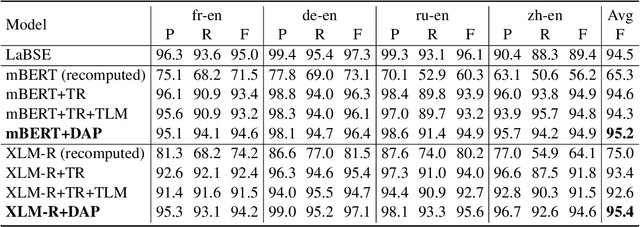
Recent studies have shown that dual encoder models trained with the sentence-level translation ranking task are effective methods for cross-lingual sentence embedding. However, our research indicates that token-level alignment is also crucial in multilingual scenarios, which has not been fully explored previously. Based on our findings, we propose a dual-alignment pre-training (DAP) framework for cross-lingual sentence embedding that incorporates both sentence-level and token-level alignment. To achieve this, we introduce a novel representation translation learning (RTL) task, where the model learns to use one-side contextualized token representation to reconstruct its translation counterpart. This reconstruction objective encourages the model to embed translation information into the token representation. Compared to other token-level alignment methods such as translation language modeling, RTL is more suitable for dual encoder architectures and is computationally efficient. Extensive experiments on three sentence-level cross-lingual benchmarks demonstrate that our approach can significantly improve sentence embedding. Our code is available at https://github.com/ChillingDream/DAP.
PanelNet: Understanding 360 Indoor Environment via Panel Representation
May 16, 2023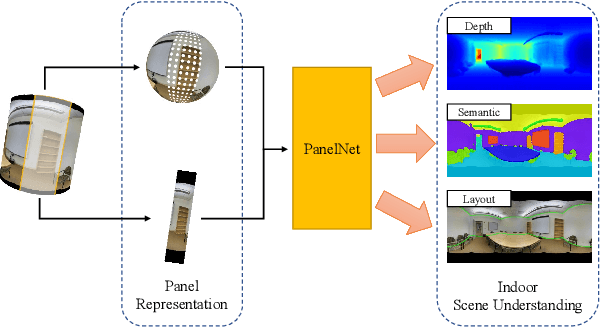
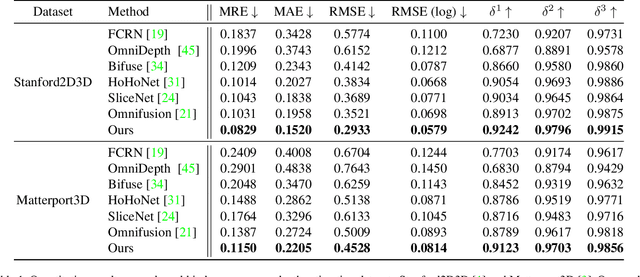
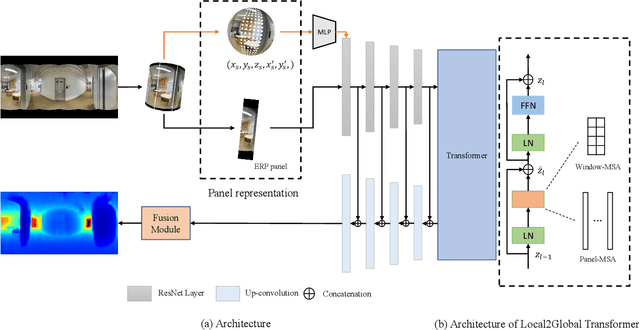

Indoor 360 panoramas have two essential properties. (1) The panoramas are continuous and seamless in the horizontal direction. (2) Gravity plays an important role in indoor environment design. By leveraging these properties, we present PanelNet, a framework that understands indoor environments using a novel panel representation of 360 images. We represent an equirectangular projection (ERP) as consecutive vertical panels with corresponding 3D panel geometry. To reduce the negative impact of panoramic distortion, we incorporate a panel geometry embedding network that encodes both the local and global geometric features of a panel. To capture the geometric context in room design, we introduce Local2Global Transformer, which aggregates local information within a panel and panel-wise global context. It greatly improves the model performance with low training overhead. Our method outperforms existing methods on indoor 360 depth estimation and shows competitive results against state-of-the-art approaches on the task of indoor layout estimation and semantic segmentation.
pTSE: A Multi-model Ensemble Method for Probabilistic Time Series Forecasting
May 16, 2023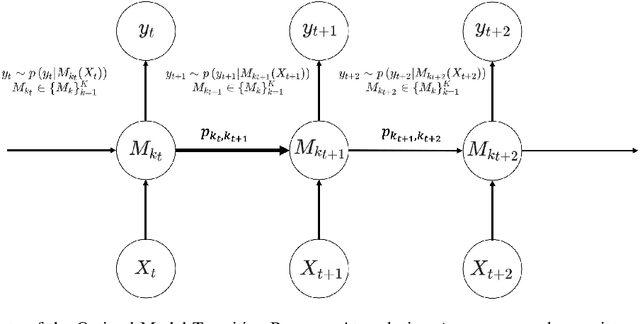
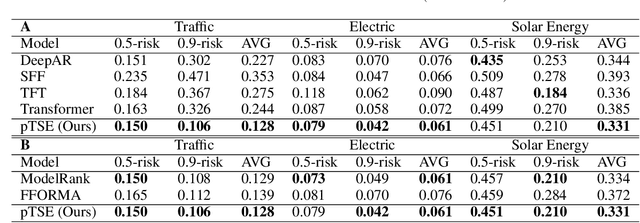
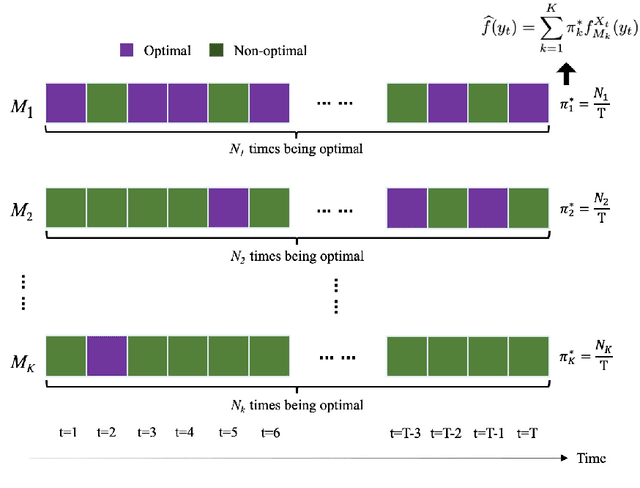
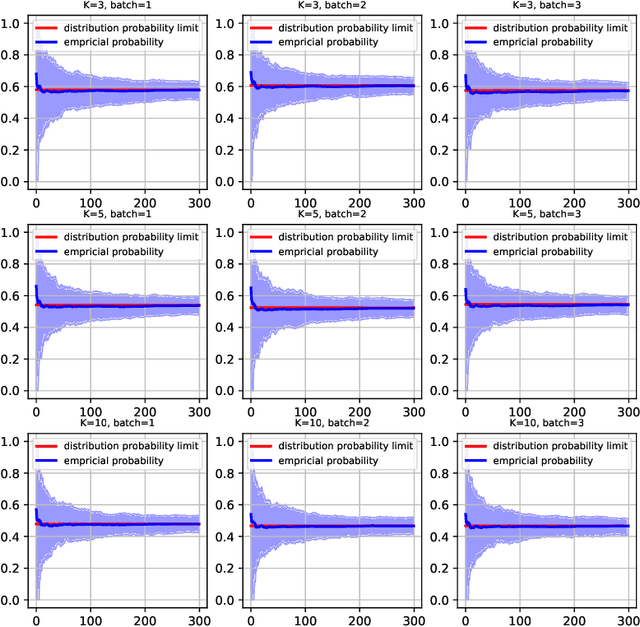
Various probabilistic time series forecasting models have sprung up and shown remarkably good performance. However, the choice of model highly relies on the characteristics of the input time series and the fixed distribution that the model is based on. Due to the fact that the probability distributions cannot be averaged over different models straightforwardly, the current time series model ensemble methods cannot be directly applied to improve the robustness and accuracy of forecasting. To address this issue, we propose pTSE, a multi-model distribution ensemble method for probabilistic forecasting based on Hidden Markov Model (HMM). pTSE only takes off-the-shelf outputs from member models without requiring further information about each model. Besides, we provide a complete theoretical analysis of pTSE to prove that the empirical distribution of time series subject to an HMM will converge to the stationary distribution almost surely. Experiments on benchmarks show the superiority of pTSE overall member models and competitive ensemble methods.