 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
V2X-Seq: A Large-Scale Sequential Dataset for Vehicle-Infrastructure Cooperative Perception and Forecasting
May 10, 2023
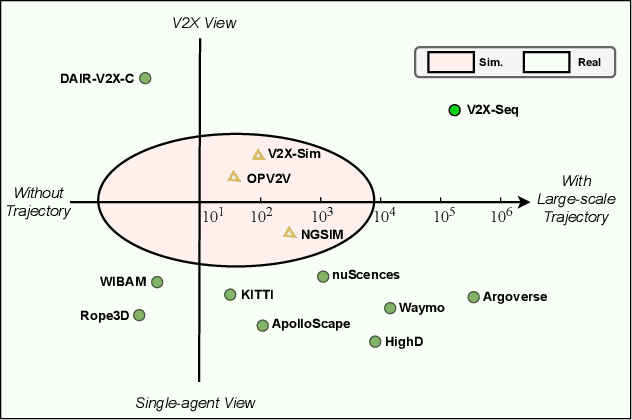
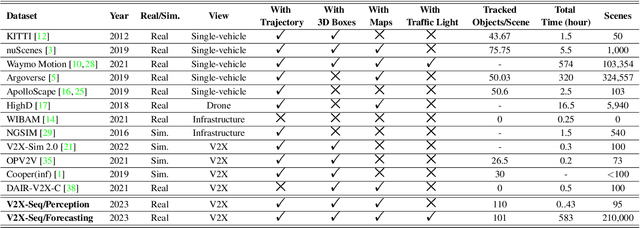
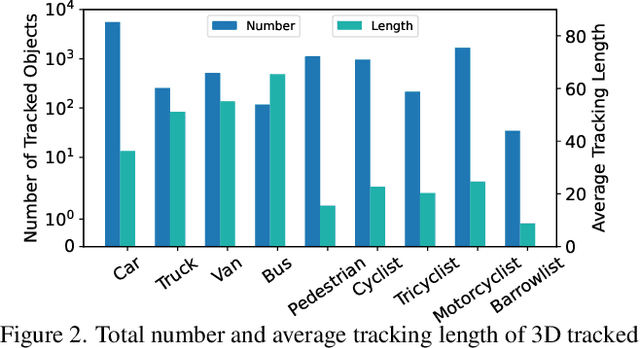
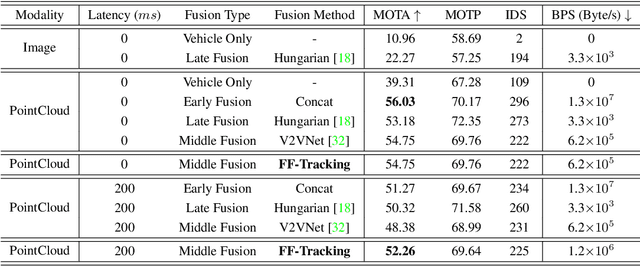
Utilizing infrastructure and vehicle-side information to track and forecast the behaviors of surrounding traffic participants can significantly improve decision-making and safety in autonomous driving. However, the lack of real-world sequential datasets limits research in this area. To address this issue, we introduce V2X-Seq, the first large-scale sequential V2X dataset, which includes data frames, trajectories, vector maps, and traffic lights captured from natural scenery. V2X-Seq comprises two parts: the sequential perception dataset, which includes more than 15,000 frames captured from 95 scenarios, and the trajectory forecasting dataset, which contains about 80,000 infrastructure-view scenarios, 80,000 vehicle-view scenarios, and 50,000 cooperative-view scenarios captured from 28 intersections' areas, covering 672 hours of data. Based on V2X-Seq, we introduce three new tasks for vehicle-infrastructure cooperative (VIC) autonomous driving: VIC3D Tracking, Online-VIC Forecasting, and Offline-VIC Forecasting. We also provide benchmarks for the introduced tasks. Find data, code, and more up-to-date information at \href{https://github.com/AIR-THU/DAIR-V2X-Seq}{https://github.com/AIR-THU/DAIR-V2X-Seq}.
Shape-Net: Room Layout Estimation from Panoramic Images Robust to Occlusion using Knowledge Distillation with 3D Shapes as Additional Inputs
Apr 25, 2023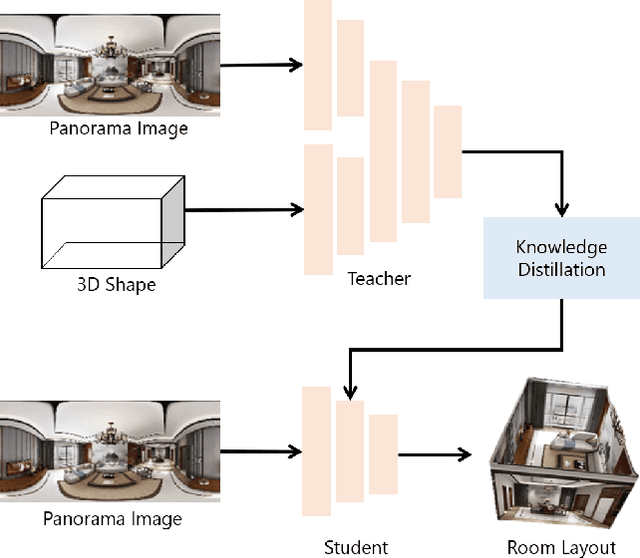

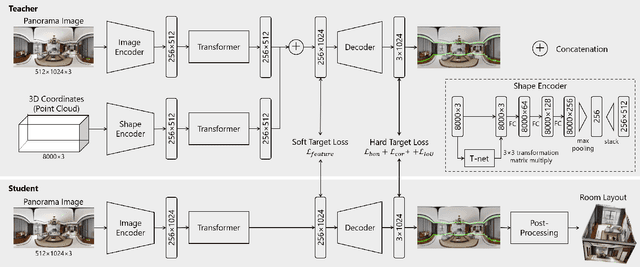

Estimating the layout of a room from a single-shot panoramic image is important in virtual/augmented reality and furniture layout simulation. This involves identifying three-dimensional (3D) geometry, such as the location of corners and boundaries, and performing 3D reconstruction. However, occlusion is a common issue that can negatively impact room layout estimation, and this has not been thoroughly studied to date. It is possible to obtain 3D shape information of rooms as drawings of buildings and coordinates of corners from image datasets, thus we propose providing both 2D panoramic and 3D information to a model to effectively deal with occlusion. However, simply feeding 3D information to a model is not sufficient to utilize the shape information for an occluded area. Therefore, we improve the model by introducing 3D Intersection over Union (IoU) loss to effectively use 3D information. In some cases, drawings are not available or the construction deviates from a drawing. Considering such practical cases, we propose a method for distilling knowledge from a model trained with both images and 3D information to a model that takes only images as input. The proposed model, which is called Shape-Net, achieves state-of-the-art (SOTA) performance on benchmark datasets. We also confirmed its effectiveness in dealing with occlusion through significantly improved accuracy on images with occlusion compared with existing models.
SGED: A Benchmark dataset for Performance Evaluation of Spiking Gesture Emotion Recognition
Apr 28, 2023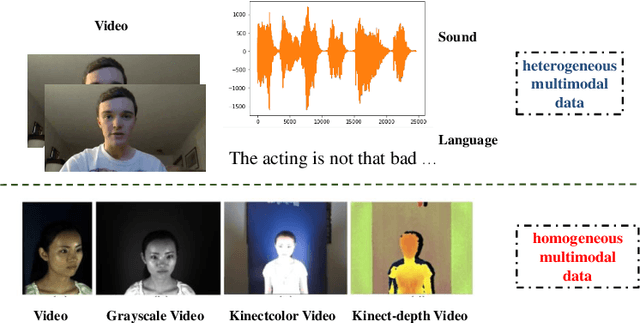
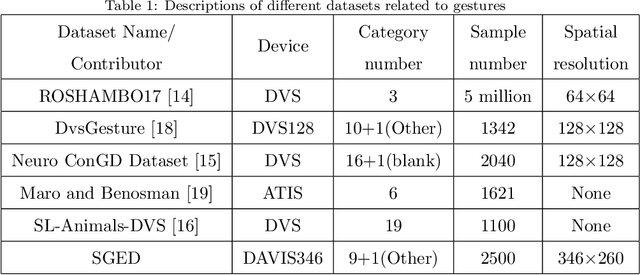
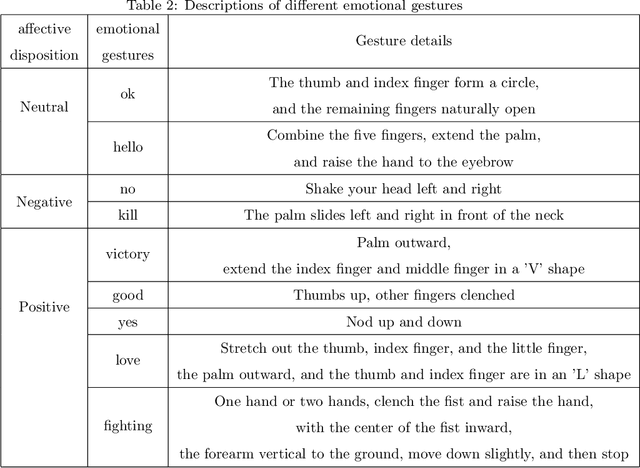
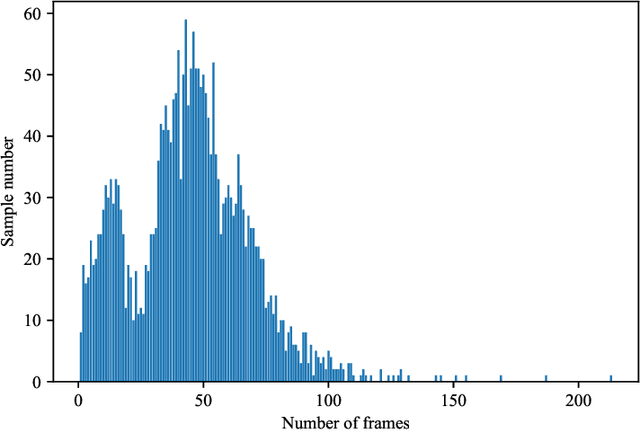
In the field of affective computing, researchers in the community have promoted the performance of models and algorithms by using the complementarity of multimodal information. However, the emergence of more and more modal information makes the development of datasets unable to keep up with the progress of existing modal sensing equipment. Collecting and studying multimodal data is a complex and significant work. In order to supplement the challenge of partial missing of community data. We collected and labeled a new homogeneous multimodal gesture emotion recognition dataset based on the analysis of the existing data sets. This data set complements the defects of homogeneous multimodal data and provides a new research direction for emotion recognition. Moreover, we propose a pseudo dual-flow network based on this dataset, and verify the application potential of this dataset in the affective computing community. The experimental results demonstrate that it is feasible to use the traditional visual information and spiking visual information based on homogeneous multimodal data for visual emotion recognition.The dataset is available at \url{https://github.com/201528014227051/SGED}
Semi-Supervised Object Detection for Sorghum Panicles in UAV Imagery
May 16, 2023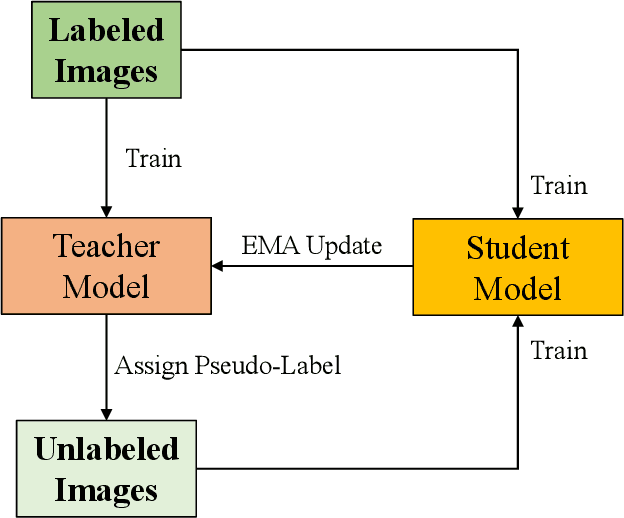
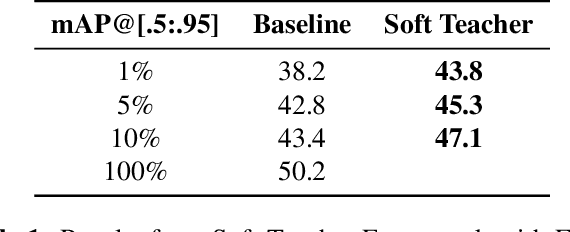

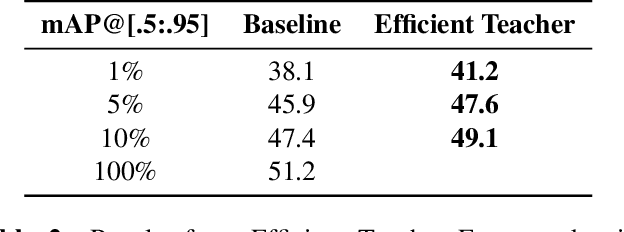
The sorghum panicle is an important trait related to grain yield and plant development. Detecting and counting sorghum panicles can provide significant information for plant phenotyping. Current deep-learning-based object detection methods for panicles require a large amount of training data. The data labeling is time-consuming and not feasible for real application. In this paper, we present an approach to reduce the amount of training data for sorghum panicle detection via semi-supervised learning. Results show we can achieve similar performance as supervised methods for sorghum panicle detection by only using 10\% of original training data.
Correcting for Selection Bias and Missing Response in Regression using Privileged Information
Mar 29, 2023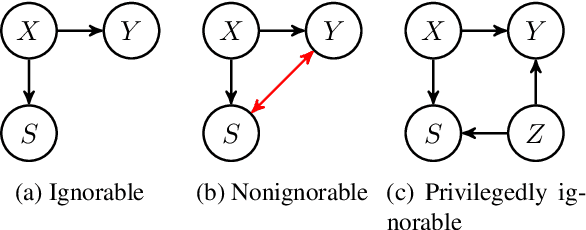
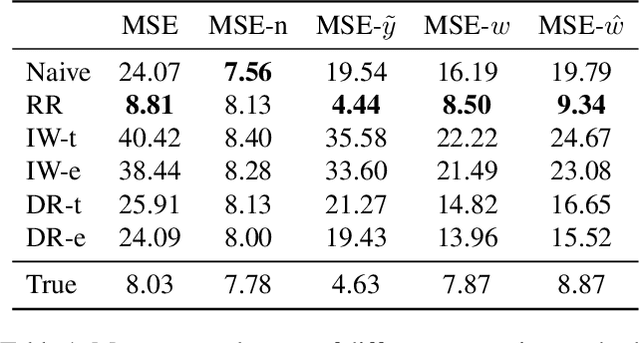
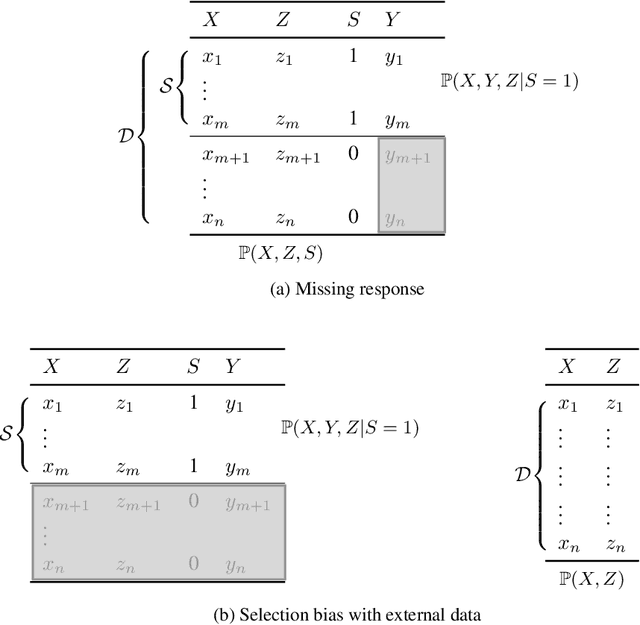
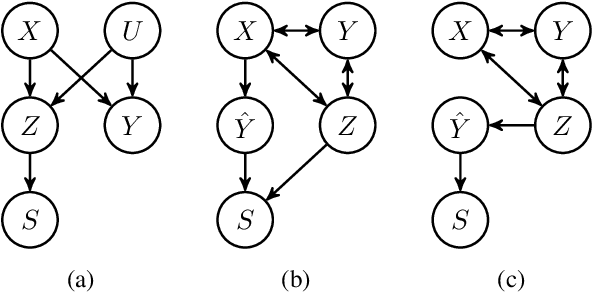
When estimating a regression model, we might have data where some labels are missing, or our data might be biased by a selection mechanism. When the response or selection mechanism is ignorable (i.e., independent of the response variable given the features) one can use off-the-shelf regression methods; in the nonignorable case one typically has to adjust for bias. We observe that privileged data (i.e. data that is only available during training) might render a nonignorable selection mechanism ignorable, and we refer to this scenario as Privilegedly Missing at Random (PMAR). We propose a novel imputation-based regression method, named repeated regression, that is suitable for PMAR. We also consider an importance weighted regression method, and a doubly robust combination of the two. The proposed methods are easy to implement with most popular out-of-the-box regression algorithms. We empirically assess the performance of the proposed methods with extensive simulated experiments and on a synthetically augmented real-world dataset. We conclude that repeated regression can appropriately correct for bias, and can have considerable advantage over weighted regression, especially when extrapolating to regions of the feature space where response is never observed.
OpenViVQA: Task, Dataset, and Multimodal Fusion Models for Visual Question Answering in Vietnamese
May 07, 2023

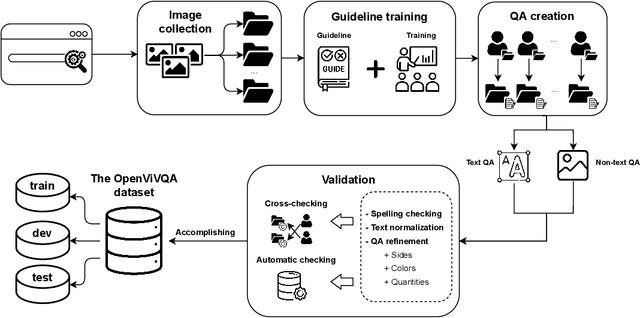
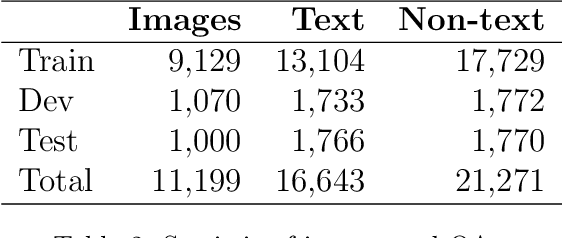
In recent years, visual question answering (VQA) has attracted attention from the research community because of its highly potential applications (such as virtual assistance on intelligent cars, assistant devices for blind people, or information retrieval from document images using natural language as queries) and challenge. The VQA task requires methods that have the ability to fuse the information from questions and images to produce appropriate answers. Neural visual question answering models have achieved tremendous growth on large-scale datasets which are mostly for resource-rich languages such as English. However, available datasets narrow the VQA task as the answers selection task or answer classification task. We argue that this form of VQA is far from human ability and eliminates the challenge of the answering aspect in the VQA task by just selecting answers rather than generating them. In this paper, we introduce the OpenViVQA (Open-domain Vietnamese Visual Question Answering) dataset, the first large-scale dataset for VQA with open-ended answers in Vietnamese, consists of 11,000+ images associated with 37,000+ question-answer pairs (QAs). Moreover, we proposed FST, QuMLAG, and MLPAG which fuse information from images and answers, then use these fused features to construct answers as humans iteratively. Our proposed methods achieve results that are competitive with SOTA models such as SAAA, MCAN, LORA, and M4C. The dataset is available to encourage the research community to develop more generalized algorithms including transformers for low-resource languages such as Vietnamese.
Quantified Semantic Comparison of Convolutional Neural Networks
Apr 30, 2023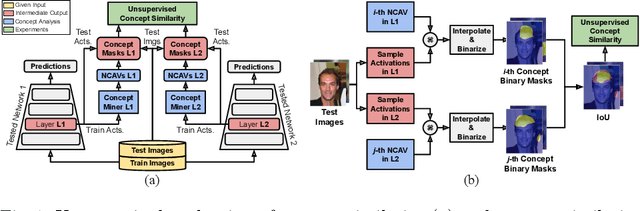
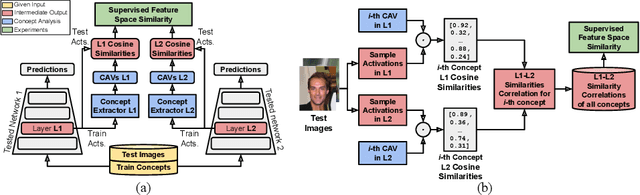

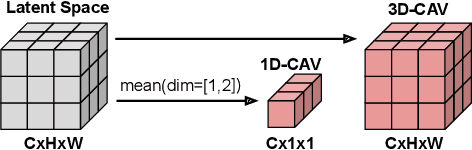
The state-of-the-art in convolutional neural networks (CNNs) for computer vision excels in performance, while remaining opaque. But due to safety regulations for safety-critical applications, like perception for automated driving, the choice of model should also take into account how candidate models represent semantic information for model transparency reasons. To tackle this yet unsolved problem, our work proposes two methods for quantifying the similarity between semantic information in CNN latent spaces. These allow insights into both the flow and similarity of semantic information within CNN layers, and into the degree of their similitude between different networks. As a basis, we use renown techniques from the field of explainable artificial intelligence (XAI), which are used to obtain global vector representations of semantic concepts in each latent space. These are compared with respect to their activation on test inputs. When applied to three diverse object detectors and two datasets, our methods reveal the findings that (1) similar semantic concepts are learned \emph{regardless of the CNN architecture}, and (2) similar concepts emerge in similar \emph{relative} layer depth, independent of the total number of layers. Finally, our approach poses a promising step towards informed model selection and comprehension of how CNNs process semantic information.
Fourier-DeepONet: Fourier-enhanced deep operator networks for full waveform inversion with improved accuracy, generalizability, and robustness
May 26, 2023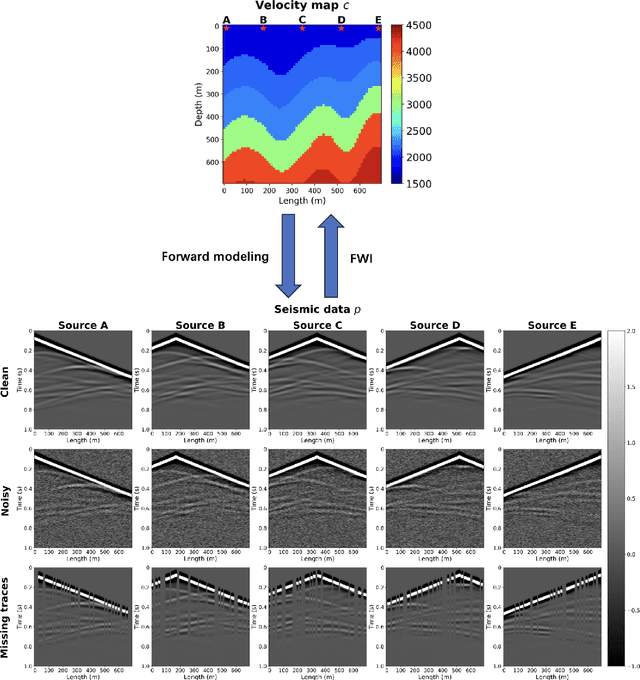

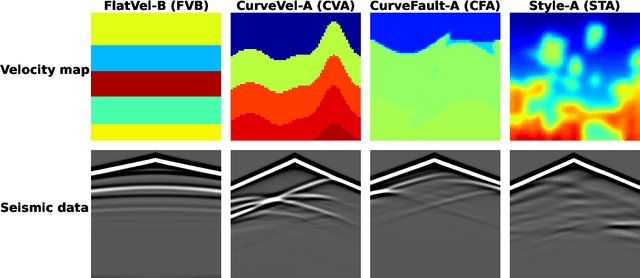

Full waveform inversion (FWI) infers the subsurface structure information from seismic waveform data by solving a non-convex optimization problem. Data-driven FWI has been increasingly studied with various neural network architectures to improve accuracy and computational efficiency. Nevertheless, the applicability of pre-trained neural networks is severely restricted by potential discrepancies between the source function used in the field survey and the one utilized during training. Here, we develop a Fourier-enhanced deep operator network (Fourier-DeepONet) for FWI with the generalization of seismic sources, including the frequencies and locations of sources. Specifically, we employ the Fourier neural operator as the decoder of DeepONet, and we utilize source parameters as one input of Fourier-DeepONet, facilitating the resolution of FWI with variable sources. To test Fourier-DeepONet, we develop two new and realistic FWI benchmark datasets (FWI-F and FWI-L) with varying source frequencies and locations. Our experiments demonstrate that compared with existing data-driven FWI methods, Fourier-DeepONet obtains more accurate predictions of subsurface structures in a wide range of source parameters. Moreover, the proposed Fourier-DeepONet exhibits superior robustness when dealing with noisy inputs or inputs with missing traces, paving the way for more reliable and accurate subsurface imaging across diverse real conditions.
Parameter-Efficient Fine-Tuning without Introducing New Latency
May 26, 2023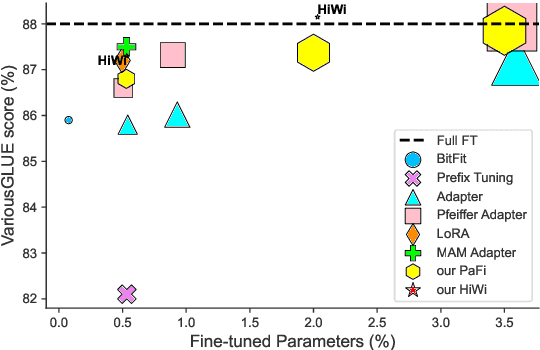
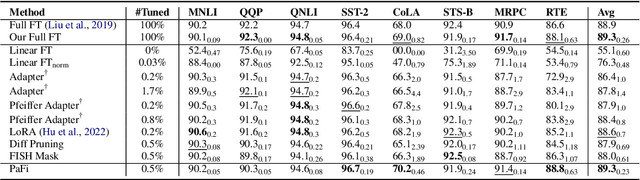
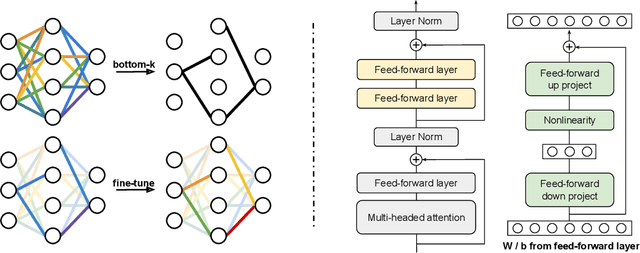
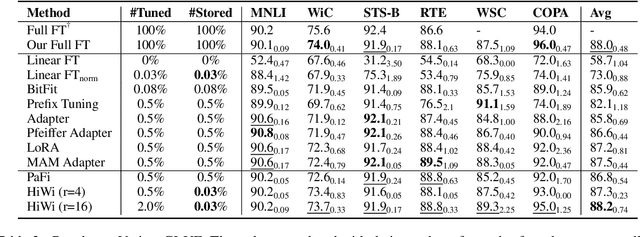
Parameter-efficient fine-tuning (PEFT) of pre-trained language models has recently demonstrated remarkable achievements, effectively matching the performance of full fine-tuning while utilizing significantly fewer trainable parameters, and consequently addressing the storage and communication constraints. Nonetheless, various PEFT methods are limited by their inherent characteristics. In the case of sparse fine-tuning, which involves modifying only a small subset of the existing parameters, the selection of fine-tuned parameters is task- and domain-specific, making it unsuitable for federated learning. On the other hand, PEFT methods with adding new parameters typically introduce additional inference latency. In this paper, we demonstrate the feasibility of generating a sparse mask in a task-agnostic manner, wherein all downstream tasks share a common mask. Our approach, which relies solely on the magnitude information of pre-trained parameters, surpasses existing methodologies by a significant margin when evaluated on the GLUE benchmark. Additionally, we introduce a novel adapter technique that directly applies the adapter to pre-trained parameters instead of the hidden representation, thereby achieving identical inference speed to that of full fine-tuning. Through extensive experiments, our proposed method attains a new state-of-the-art outcome in terms of both performance and storage efficiency, storing only 0.03% parameters of full fine-tuning.
Conjunct Resolution in the Face of Verbal Omissions
May 26, 2023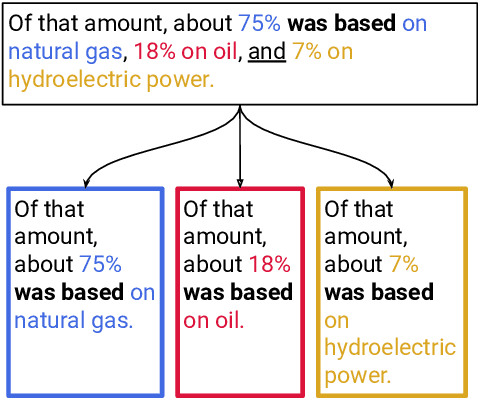
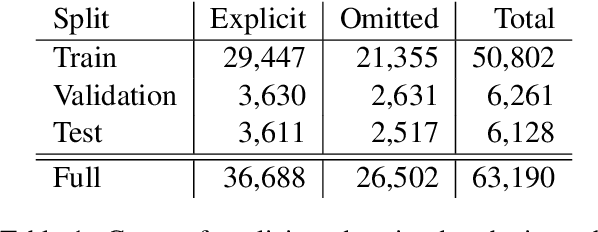
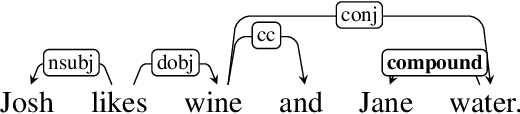
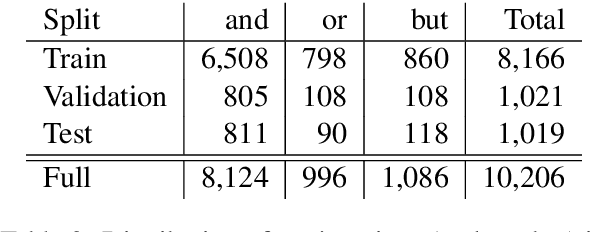
Verbal omissions are complex syntactic phenomena in VP coordination structures. They occur when verbs and (some of) their arguments are omitted from subsequent clauses after being explicitly stated in an initial clause. Recovering these omitted elements is necessary for accurate interpretation of the sentence, and while humans easily and intuitively fill in the missing information, state-of-the-art models continue to struggle with this task. Previous work is limited to small-scale datasets, synthetic data creation methods, and to resolution methods in the dependency-graph level. In this work we propose a conjunct resolution task that operates directly on the text and makes use of a split-and-rephrase paradigm in order to recover the missing elements in the coordination structure. To this end, we first formulate a pragmatic framework of verbal omissions which describes the different types of omissions, and develop an automatic scalable collection method. Based on this method, we curate a large dataset, containing over 10K examples of naturally-occurring verbal omissions with crowd-sourced annotations of the resolved conjuncts. We train various neural baselines for this task, and show that while our best method obtains decent performance, it leaves ample space for improvement. We propose our dataset, metrics and models as a starting point for future research on this topic.