 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Deep Reinforcement Learning Approach for Autonomous Reconfigurable Intelligent Surfaces
Mar 19, 2024
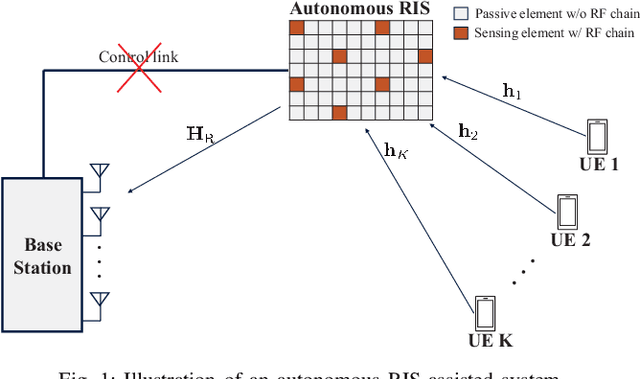
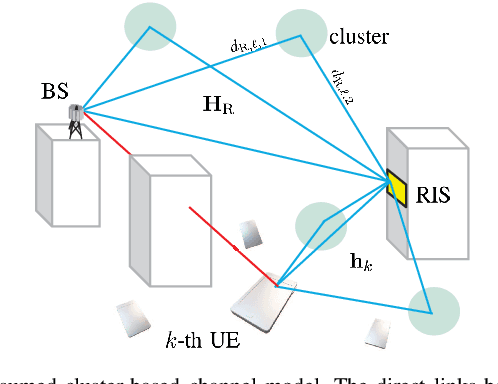
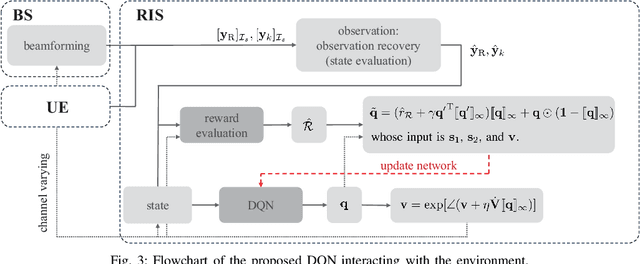
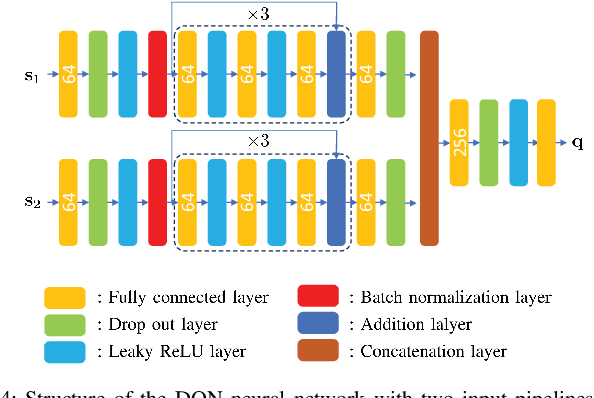
A reconfigurable intelligent surface (RIS) is a prospective wireless technology that enhances wireless channel quality. An RIS is often equipped with passive array of elements and provides cost and power-efficient solutions for coverage extension of wireless communication systems. Without any radio frequency (RF) chains or computing resources, however, the RIS requires control information to be sent to it from an external unit, e.g., a base station (BS). The control information can be delivered by wired or wireless channels, and the BS must be aware of the RIS and the RIS-related channel conditions in order to effectively configure its behavior. Recent works have introduced hybrid RIS structures possessing a few active elements that can sense and digitally process received data. Here, we propose the operation of an entirely autonomous RIS that operates without a control link between the RIS and BS. Using a few sensing elements, the autonomous RIS employs a deep Q network (DQN) based on reinforcement learning in order to enhance the sum rate of the network. Our results illustrate the potential of deploying autonomous RISs in wireless networks with essentially no network overhead.
Locomotion Generation for a Rat Robot based on Environmental Changes via Reinforcement Learning
Mar 19, 2024
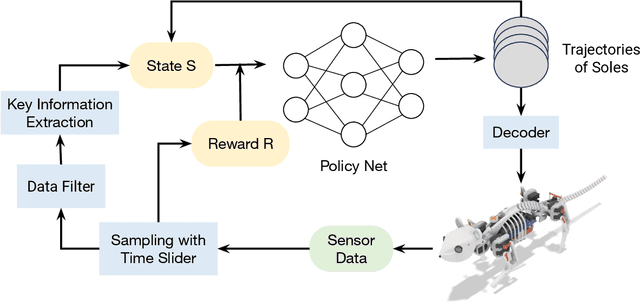
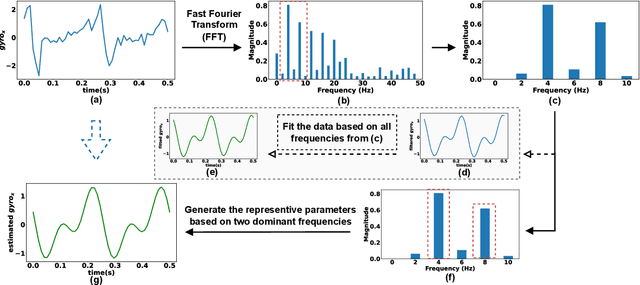
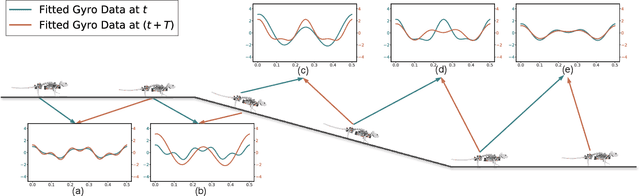
This research focuses on developing reinforcement learning approaches for the locomotion generation of small-size quadruped robots. The rat robot NeRmo is employed as the experimental platform. Due to the constrained volume, small-size quadruped robots typically possess fewer and weaker sensors, resulting in difficulty in accurately perceiving and responding to environmental changes. In this context, insufficient and imprecise feedback data from sensors makes it difficult to generate adaptive locomotion based on reinforcement learning. To overcome these challenges, this paper proposes a novel reinforcement learning approach that focuses on extracting effective perceptual information to enhance the environmental adaptability of small-size quadruped robots. According to the frequency of a robot's gait stride, key information of sensor data is analyzed utilizing sinusoidal functions derived from Fourier transform results. Additionally, a multifunctional reward mechanism is proposed to generate adaptive locomotion in different tasks. Extensive simulations are conducted to assess the effectiveness of the proposed reinforcement learning approach in generating rat robot locomotion in various environments. The experiment results illustrate the capability of the proposed approach to maintain stable locomotion of a rat robot across different terrains, including ramps, stairs, and spiral stairs.
Teaching MLP More Graph Information: A Three-stage Multitask Knowledge Distillation Framework
Mar 02, 2024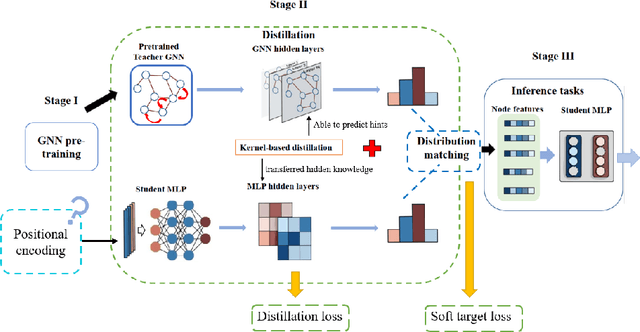
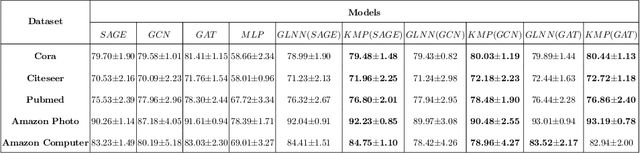
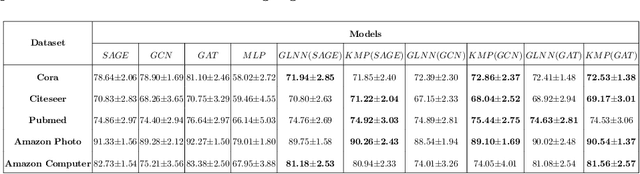
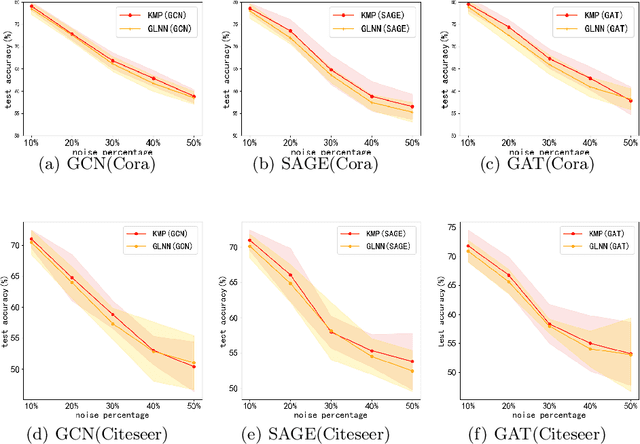
We study the challenging problem for inference tasks on large-scale graph datasets of Graph Neural Networks: huge time and memory consumption, and try to overcome it by reducing reliance on graph structure. Even though distilling graph knowledge to student MLP is an excellent idea, it faces two major problems of positional information loss and low generalization. To solve the problems, we propose a new three-stage multitask distillation framework. In detail, we use Positional Encoding to capture positional information. Also, we introduce Neural Heat Kernels responsible for graph data processing in GNN and utilize hidden layer outputs matching for better performance of student MLP's hidden layers. To the best of our knowledge, it is the first work to include hidden layer distillation for student MLP on graphs and to combine graph Positional Encoding with MLP. We test its performance and robustness with several settings and draw the conclusion that our work can outperform well with good stability.
Updating the Minimum Information about CLinical Artificial Intelligence (MI-CLAIM) checklist for generative modeling research
Mar 05, 2024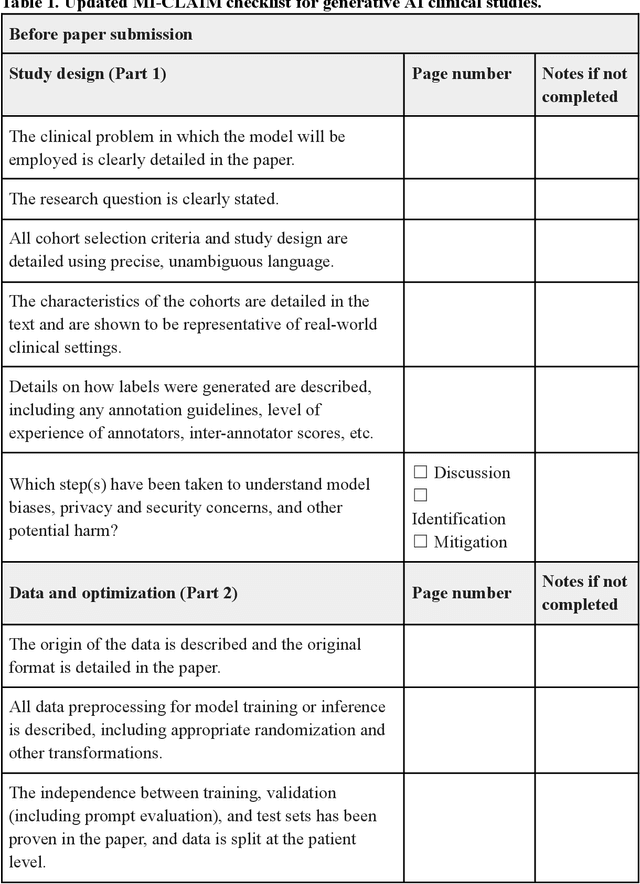
Recent advances in generative models, including large language models (LLMs), vision language models (VLMs), and diffusion models, have accelerated the field of natural language and image processing in medicine and marked a significant paradigm shift in how biomedical models can be developed and deployed. While these models are highly adaptable to new tasks, scaling and evaluating their usage presents new challenges not addressed in previous frameworks. In particular, the ability of these models to produce useful outputs with little to no specialized training data ("zero-" or "few-shot" approaches), as well as the open-ended nature of their outputs, necessitate the development of updated guidelines in using and evaluating these models. In response to gaps in standards and best practices for the development of clinical AI tools identified by US Executive Order 141103 and several emerging national networks for clinical AI evaluation, we begin to formalize some of these guidelines by building on the "Minimum information about clinical artificial intelligence modeling" (MI-CLAIM) checklist. The MI-CLAIM checklist, originally developed in 2020, provided a set of six steps with guidelines on the minimum information necessary to encourage transparent, reproducible research for artificial intelligence (AI) in medicine. Here, we propose modifications to the original checklist that highlight differences in training, evaluation, interpretability, and reproducibility of generative models compared to traditional AI models for clinical research. This updated checklist also seeks to clarify cohort selection reporting and adds additional items on alignment with ethical standards.
Enhancing Multivariate Time Series Forecasting with Mutual Information-driven Cross-Variable and Temporal Modeling
Mar 01, 2024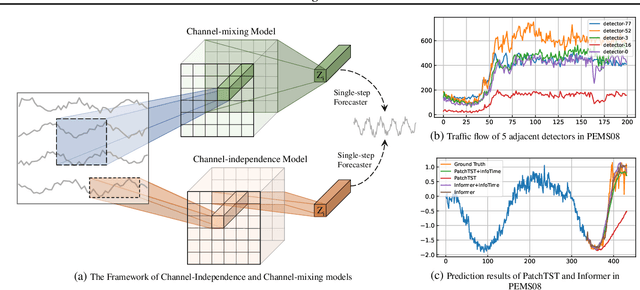
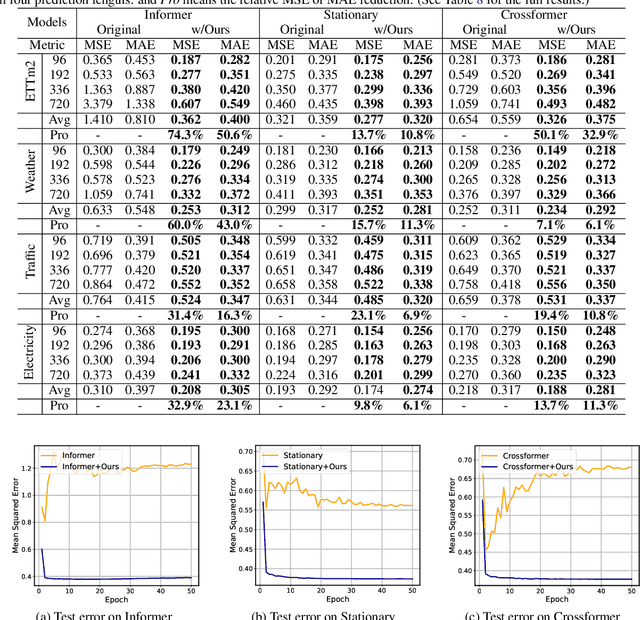
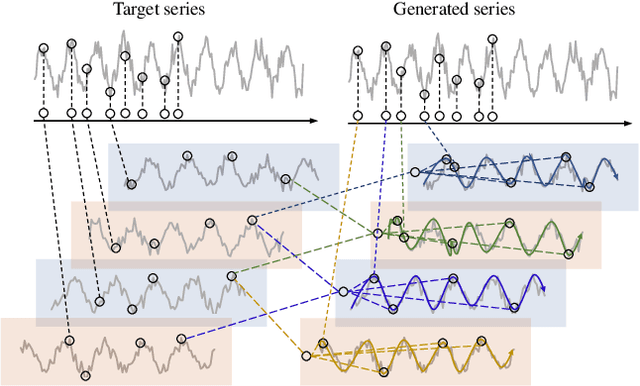
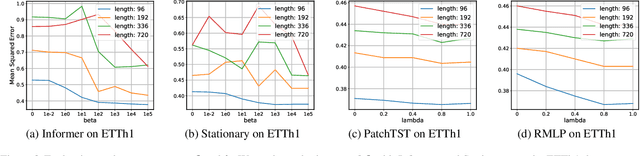
Recent advancements have underscored the impact of deep learning techniques on multivariate time series forecasting (MTSF). Generally, these techniques are bifurcated into two categories: Channel-independence and Channel-mixing approaches. Although Channel-independence methods typically yield better results, Channel-mixing could theoretically offer improvements by leveraging inter-variable correlations. Nonetheless, we argue that the integration of uncorrelated information in channel-mixing methods could curtail the potential enhancement in MTSF model performance. To substantiate this claim, we introduce the Cross-variable Decorrelation Aware feature Modeling (CDAM) for Channel-mixing approaches, aiming to refine Channel-mixing by minimizing redundant information between channels while enhancing relevant mutual information. Furthermore, we introduce the Temporal correlation Aware Modeling (TAM) to exploit temporal correlations, a step beyond conventional single-step forecasting methods. This strategy maximizes the mutual information between adjacent sub-sequences of both the forecasted and target series. Combining CDAM and TAM, our novel framework significantly surpasses existing models, including those previously considered state-of-the-art, in comprehensive tests.
Visibility-Aware Keypoint Localization for 6DoF Object Pose Estimation
Mar 21, 2024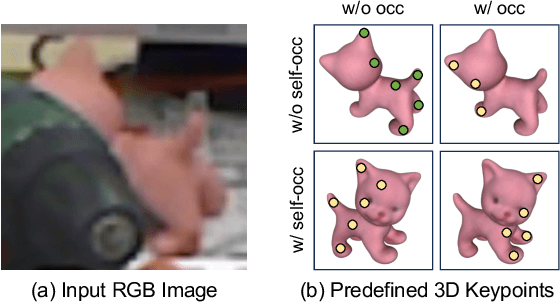
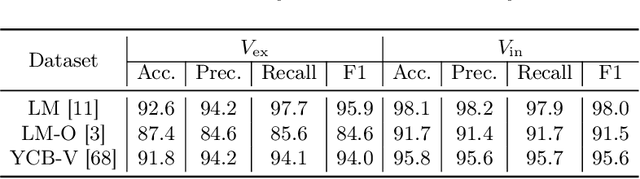
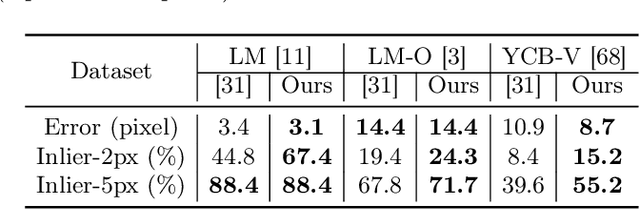
Localizing predefined 3D keypoints in a 2D image is an effective way to establish 3D-2D correspondences for 6DoF object pose estimation. However, unreliable localization results of invisible keypoints degrade the quality of correspondences. In this paper, we address this issue by localizing the important keypoints in terms of visibility. Since keypoint visibility information is currently missing in dataset collection process, we propose an efficient way to generate binary visibility labels from available object-level annotations, for keypoints of both asymmetric objects and symmetric objects. We further derive real-valued visibility-aware importance from binary labels based on PageRank algorithm. Taking advantage of the flexibility of our visibility-aware importance, we construct VAPO (Visibility-Aware POse estimator) by integrating the visibility-aware importance with a state-of-the-art pose estimation algorithm, along with additional positional encoding. Extensive experiments are conducted on popular pose estimation benchmarks including Linemod, Linemod-Occlusion, and YCB-V. The results show that, VAPO improves both the keypoint correspondences and final estimated poses, and clearly achieves state-of-the-art performances.
Exosense: A Vision-Centric Scene Understanding System For Safe Exoskeleton Navigation
Mar 21, 2024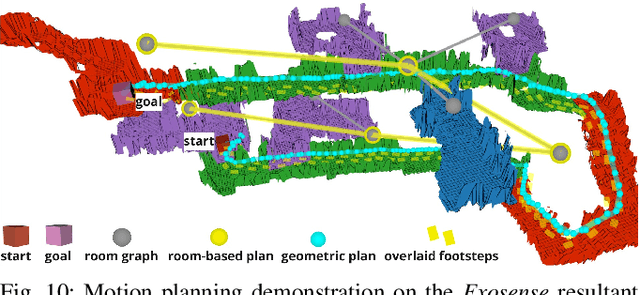

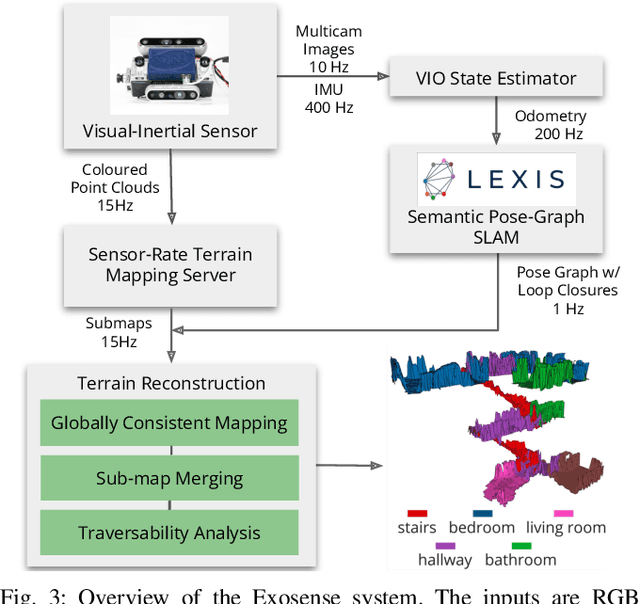
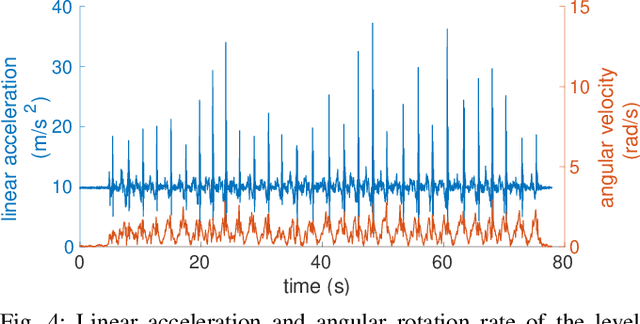
Exoskeletons for daily use by those with mobility impairments are being developed. They will require accurate and robust scene understanding systems. Current research has used vision to identify immediate terrain and geometric obstacles, however these approaches are constrained to detections directly in front of the user and are limited to classifying a finite range of terrain types (e.g., stairs, ramps and level-ground). This paper presents Exosense, a vision-centric scene understanding system which is capable of generating rich, globally-consistent elevation maps, incorporating both semantic and terrain traversability information. It features an elastic Atlas mapping framework associated with a visual SLAM pose graph, embedded with open-vocabulary room labels from a Vision-Language Model (VLM). The device's design includes a wide field-of-view (FoV) fisheye multi-camera system to mitigate the challenges introduced by the exoskeleton walking pattern. We demonstrate the system's robustness to the challenges of typical periodic walking gaits, and its ability to construct accurate semantically-rich maps in indoor settings. Additionally, we showcase its potential for motion planning -- providing a step towards safe navigation for exoskeletons.
Zero123-6D: Zero-shot Novel View Synthesis for RGB Category-level 6D Pose Estimation
Mar 21, 2024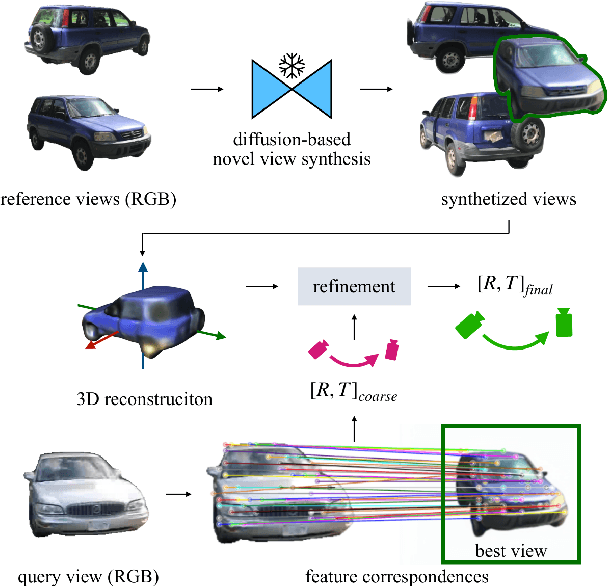
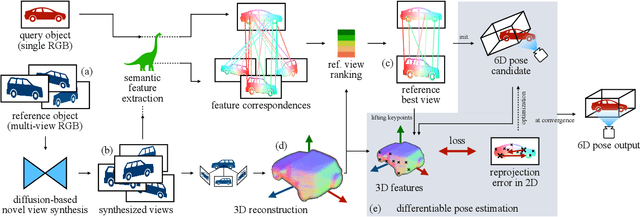


Estimating the pose of objects through vision is essential to make robotic platforms interact with the environment. Yet, it presents many challenges, often related to the lack of flexibility and generalizability of state-of-the-art solutions. Diffusion models are a cutting-edge neural architecture transforming 2D and 3D computer vision, outlining remarkable performances in zero-shot novel-view synthesis. Such a use case is particularly intriguing for reconstructing 3D objects. However, localizing objects in unstructured environments is rather unexplored. To this end, this work presents Zero123-6D to demonstrate the utility of Diffusion Model-based novel-view-synthesizers in enhancing RGB 6D pose estimation at category-level by integrating them with feature extraction techniques. The outlined method exploits such a novel view synthesizer to expand a sparse set of RGB-only reference views for the zero-shot 6D pose estimation task. Experiments are quantitatively analyzed on the CO3D dataset, showcasing increased performance over baselines, a substantial reduction in data requirements, and the removal of the necessity of depth information.
PECI-Net: Bolus segmentation from video fluoroscopic swallowing study images using preprocessing ensemble and cascaded inference
Mar 21, 2024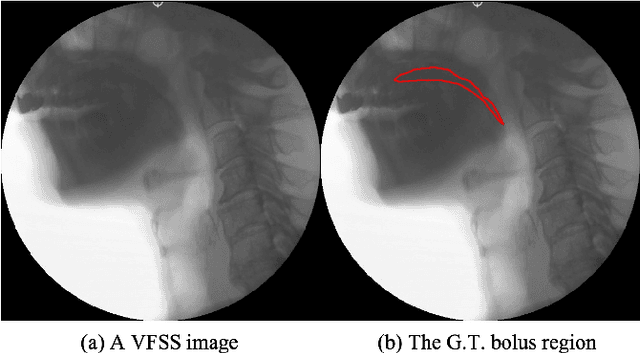

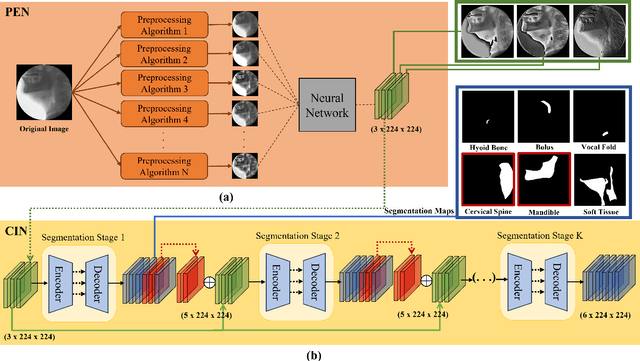
Bolus segmentation is crucial for the automated detection of swallowing disorders in videofluoroscopic swallowing studies (VFSS). However, it is difficult for the model to accurately segment a bolus region in a VFSS image because VFSS images are translucent, have low contrast and unclear region boundaries, and lack color information. To overcome these challenges, we propose PECI-Net, a network architecture for VFSS image analysis that combines two novel techniques: the preprocessing ensemble network (PEN) and the cascaded inference network (CIN). PEN enhances the sharpness and contrast of the VFSS image by combining multiple preprocessing algorithms in a learnable way. CIN reduces ambiguity in bolus segmentation by using context from other regions through cascaded inference. Moreover, CIN prevents undesirable side effects from unreliably segmented regions by referring to the context in an asymmetric way. In experiments, PECI-Net exhibited higher performance than four recently developed baseline models, outperforming TernausNet, the best among the baseline models, by 4.54\% and the widely used UNet by 10.83\%. The results of the ablation studies confirm that CIN and PEN are effective in improving bolus segmentation performance.
* 20 pages, 8 figures,
M$^3$AV: A Multimodal, Multigenre, and Multipurpose Audio-Visual Academic Lecture Dataset
Mar 21, 2024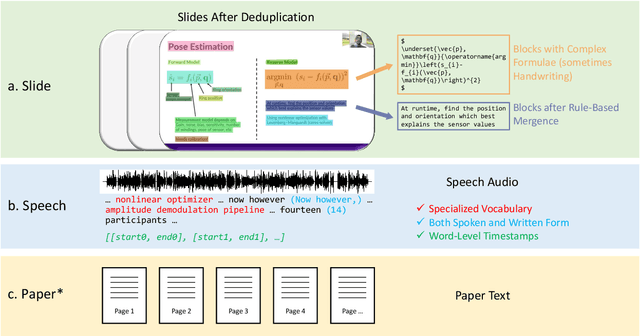
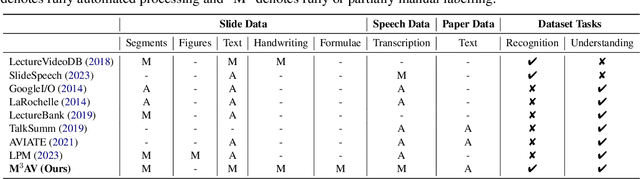
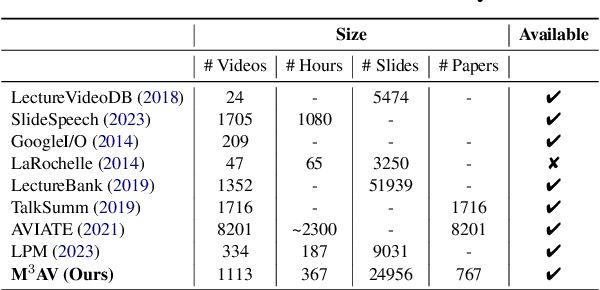
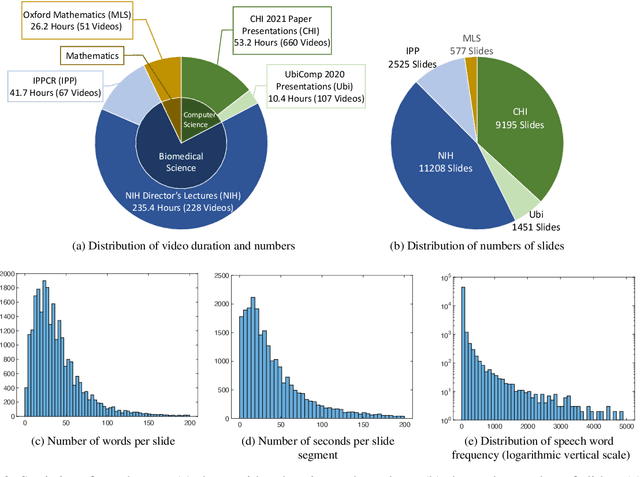
Publishing open-source academic video recordings is an emergent and prevalent approach to sharing knowledge online. Such videos carry rich multimodal information including speech, the facial and body movements of the speakers, as well as the texts and pictures in the slides and possibly even the papers. Although multiple academic video datasets have been constructed and released, few of them support both multimodal content recognition and understanding tasks, which is partially due to the lack of high-quality human annotations. In this paper, we propose a novel multimodal, multigenre, and multipurpose audio-visual academic lecture dataset (M$^3$AV), which has almost 367 hours of videos from five sources covering computer science, mathematics, and medical and biology topics. With high-quality human annotations of the spoken and written words, in particular high-valued name entities, the dataset can be used for multiple audio-visual recognition and understanding tasks. Evaluations performed on contextual speech recognition, speech synthesis, and slide and script generation tasks demonstrate that the diversity of M$^3$AV makes it a challenging dataset.