 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
READMem: Robust Embedding Association for a Diverse Memory in Unconstrained Video Object Segmentation
May 22, 2023

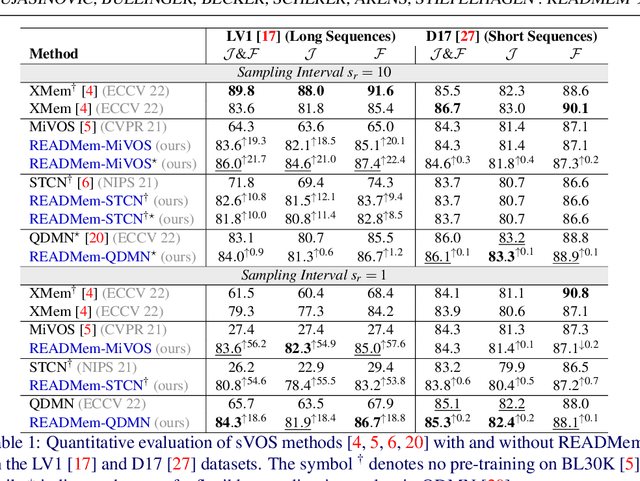
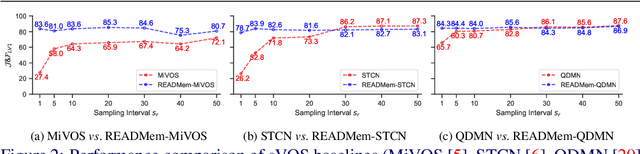

We present READMem (Robust Embedding Association for a Diverse Memory), a modular framework for semi-automatic video object segmentation (sVOS) methods designed to handle unconstrained videos. Contemporary sVOS works typically aggregate video frames in an ever-expanding memory, demanding high hardware resources for long-term applications. To mitigate memory requirements and prevent near object duplicates (caused by information of adjacent frames), previous methods introduce a hyper-parameter that controls the frequency of frames eligible to be stored. This parameter has to be adjusted according to concrete video properties (such as rapidity of appearance changes and video length) and does not generalize well. Instead, we integrate the embedding of a new frame into the memory only if it increases the diversity of the memory content. Furthermore, we propose a robust association of the embeddings stored in the memory with query embeddings during the update process. Our approach avoids the accumulation of redundant data, allowing us in return, to restrict the memory size and prevent extreme memory demands in long videos. We extend popular sVOS baselines with READMem, which previously showed limited performance on long videos. Our approach achieves competitive results on the Long-time Video dataset (LV1) while not hindering performance on short sequences. Our code is publicly available.
MADNet: Maximizing Addressee Deduction Expectation for Multi-Party Conversation Generation
May 22, 2023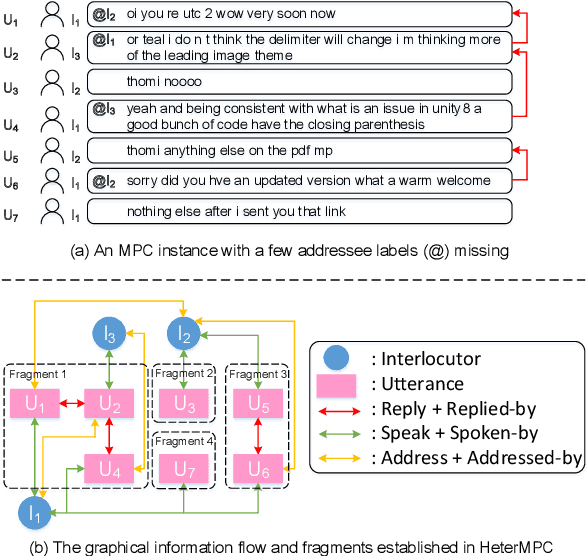
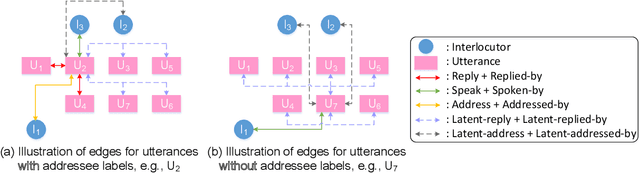
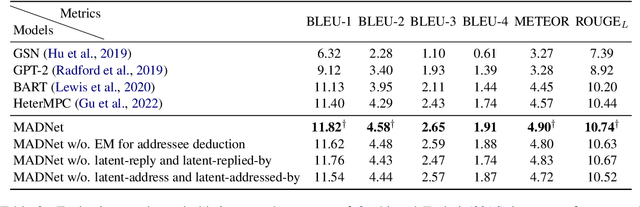
Modeling multi-party conversations (MPCs) with graph neural networks has been proven effective at capturing complicated and graphical information flows. However, existing methods rely heavily on the necessary addressee labels and can only be applied to an ideal setting where each utterance must be tagged with an addressee label. To study the scarcity of addressee labels which is a common issue in MPCs, we propose MADNet that maximizes addressee deduction expectation in heterogeneous graph neural networks for MPC generation. Given an MPC with a few addressee labels missing, existing methods fail to build a consecutively connected conversation graph, but only a few separate conversation fragments instead. To ensure message passing between these conversation fragments, four additional types of latent edges are designed to complete a fully-connected graph. Besides, to optimize the edge-type-dependent message passing for those utterances without addressee labels, an Expectation-Maximization-based method that iteratively generates silver addressee labels (E step), and optimizes the quality of generated responses (M step), is designed. Experimental results on two Ubuntu IRC channel benchmarks show that MADNet outperforms various baseline models on the task of MPC generation, especially under the more common and challenging setting where part of addressee labels are missing.
Deep Learning-based Data-aided Activity Detection with Extraction Network in Grant-free Sparse Code Multiple Access Systems
May 13, 2023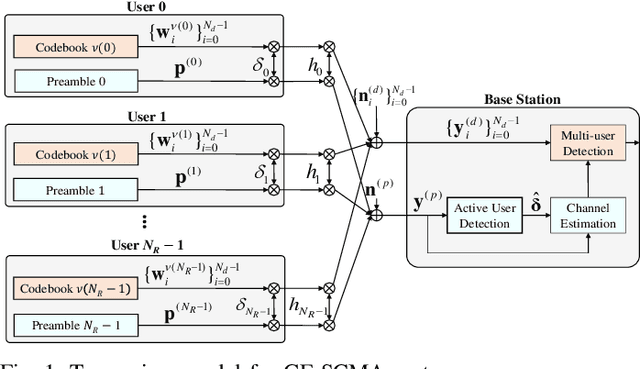
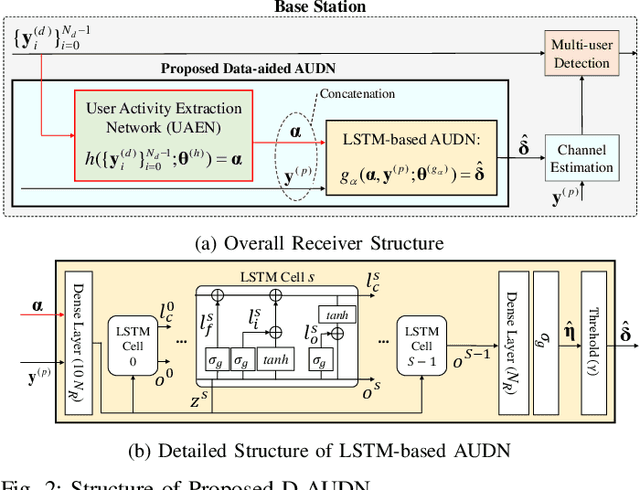
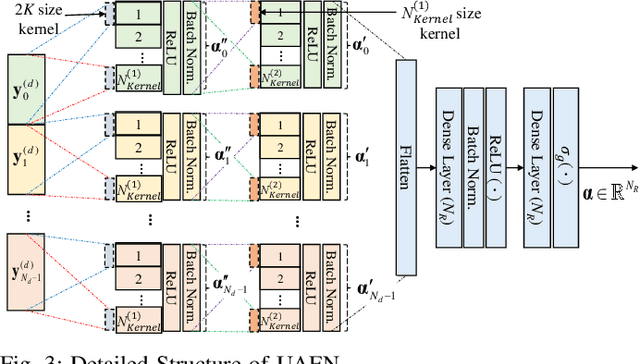
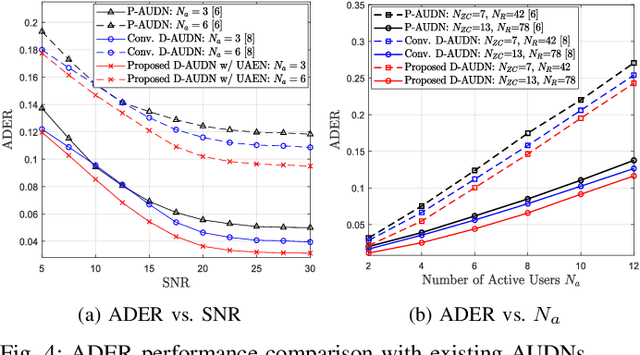
This letter proposes a deep learning-based data-aided active user detection network (D-AUDN) for grant-free sparse code multiple access (SCMA) systems that leverages both SCMA codebook and Zadoff-Chu preamble for activity detection. Due to disparate data and preamble distribution as well as codebook collision, existing D-AUDNs experience performance degradation when multiple preambles are associated with each codebook. To address this, a user activity extraction network (UAEN) is integrated within the D-AUDN to extract a-priori activity information from the codebook, improving activity detection of the associated preambles. Additionally, efficient SCMA codebook design and Zadoff-Chu preamble association are considered to further enhance performance.
Debiasing NLP Models Without Demographic Information
Dec 20, 2022

Models trained from real-world data tend to imitate and amplify social biases. Although there are many methods suggested to mitigate biases, they require a preliminary information on the types of biases that should be mitigated (e.g., gender or racial bias) and the social groups associated with each data sample. In this work, we propose a debiasing method that operates without any prior knowledge of the demographics in the dataset, detecting biased examples based on an auxiliary model that predicts the main model's success and down-weights them during the training process. Results on racial and gender bias demonstrate that it is possible to mitigate social biases without having to use a costly demographic annotation process.
CHIC: Corporate Document for Visual question Answering
May 01, 2023
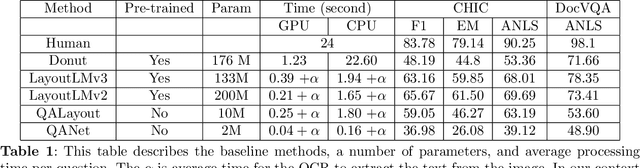

The massive use of digital documents due to the substantial trend of paperless initiatives confronted some companies to find ways to process thousands of documents per day automatically. To achieve this, they use automatic information retrieval (IR) allowing them to extract useful information from large datasets quickly. In order to have effective IR methods, it is first necessary to have an adequate dataset. Although companies have enough data to take into account their needs, there is also a need for a public database to compare contributions between state-of-the-art methods. Public data on the document exists as DocVQA[2] and XFUND [10], but these do not fully satisfy the needs of companies. XFUND contains only form documents while the company uses several types of documents (i.e. structured documents like forms but also semi-structured as invoices, and unstructured as emails). Compared to XFUND, DocVQA has several types of documents but only 4.5% of them are corporate documents (i.e. invoice, purchase order, etc). All of this 4.5% of documents do not meet the diversity of documents required by the company. We propose CHIC a visual question-answering public dataset. This dataset contains different types of corporate documents and the information extracted from these documents meet the right expectations of companies.
Discriminative Co-Saliency and Background Mining Transformer for Co-Salient Object Detection
May 06, 2023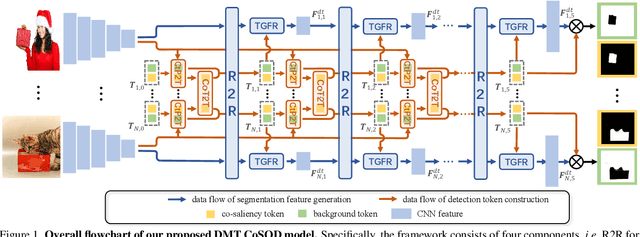
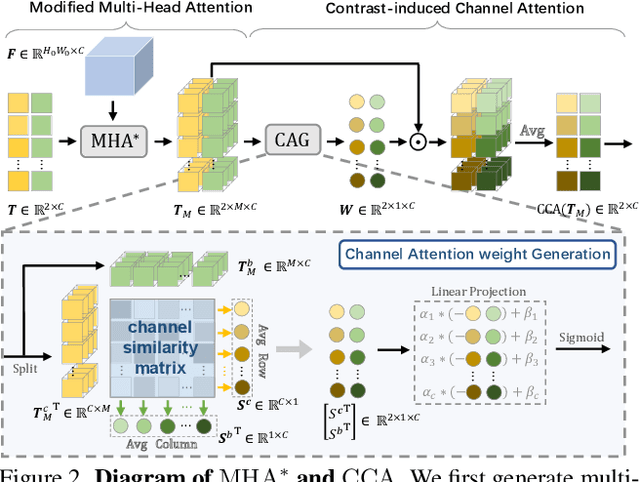
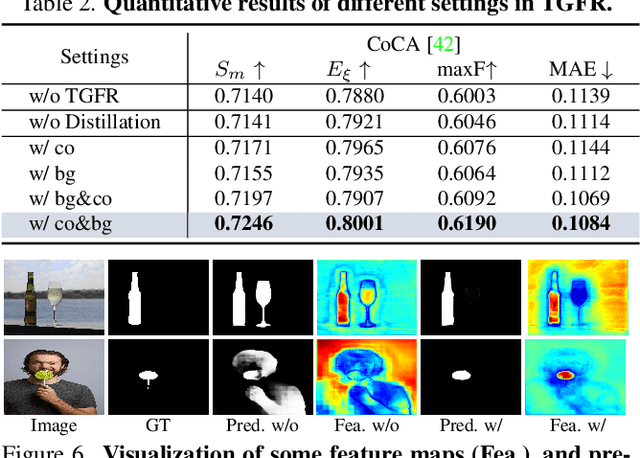
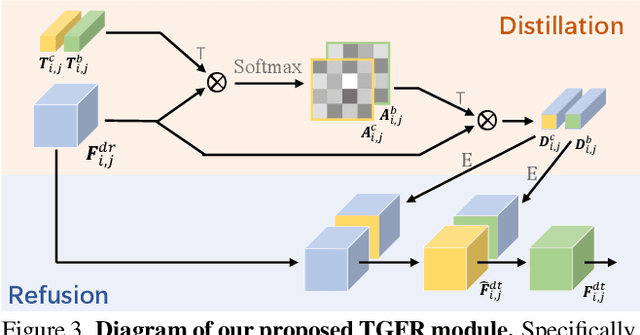
Most previous co-salient object detection works mainly focus on extracting co-salient cues via mining the consistency relations across images while ignoring explicit exploration of background regions. In this paper, we propose a Discriminative co-saliency and background Mining Transformer framework (DMT) based on several economical multi-grained correlation modules to explicitly mine both co-saliency and background information and effectively model their discrimination. Specifically, we first propose a region-to-region correlation module for introducing inter-image relations to pixel-wise segmentation features while maintaining computational efficiency. Then, we use two types of pre-defined tokens to mine co-saliency and background information via our proposed contrast-induced pixel-to-token correlation and co-saliency token-to-token correlation modules. We also design a token-guided feature refinement module to enhance the discriminability of the segmentation features under the guidance of the learned tokens. We perform iterative mutual promotion for the segmentation feature extraction and token construction. Experimental results on three benchmark datasets demonstrate the effectiveness of our proposed method. The source code is available at: https://github.com/dragonlee258079/DMT.
Playing repeated games with Large Language Models
May 26, 2023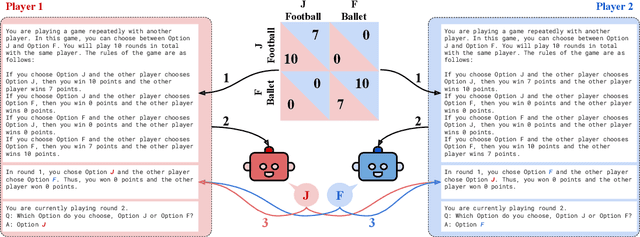
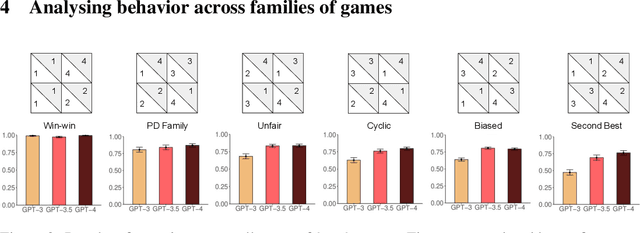
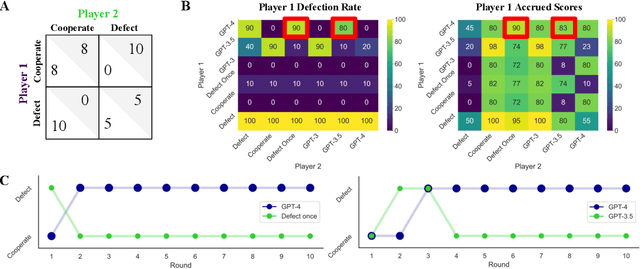
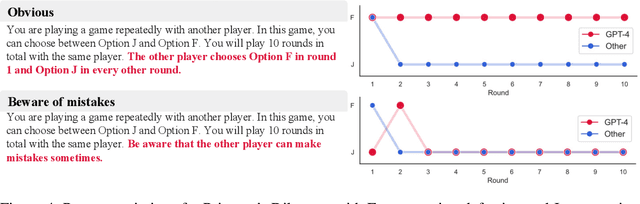
Large Language Models (LLMs) are transforming society and permeating into diverse applications. As a result, LLMs will frequently interact with us and other agents. It is, therefore, of great societal value to understand how LLMs behave in interactive social settings. Here, we propose to use behavioral game theory to study LLM's cooperation and coordination behavior. To do so, we let different LLMs (GPT-3, GPT-3.5, and GPT-4) play finitely repeated games with each other and with other, human-like strategies. Our results show that LLMs generally perform well in such tasks and also uncover persistent behavioral signatures. In a large set of two players-two strategies games, we find that LLMs are particularly good at games where valuing their own self-interest pays off, like the iterated Prisoner's Dilemma family. However, they behave sub-optimally in games that require coordination. We, therefore, further focus on two games from these distinct families. In the canonical iterated Prisoner's Dilemma, we find that GPT-4 acts particularly unforgivingly, always defecting after another agent has defected only once. In the Battle of the Sexes, we find that GPT-4 cannot match the behavior of the simple convention to alternate between options. We verify that these behavioral signatures are stable across robustness checks. Finally, we show how GPT-4's behavior can be modified by providing further information about the other player as well as by asking it to predict the other player's actions before making a choice. These results enrich our understanding of LLM's social behavior and pave the way for a behavioral game theory for machines.
GRAtt-VIS: Gated Residual Attention for Auto Rectifying Video Instance Segmentation
May 26, 2023
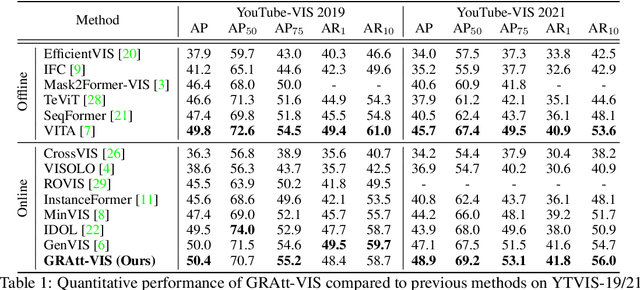
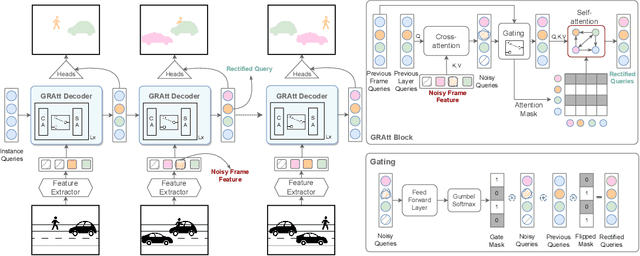
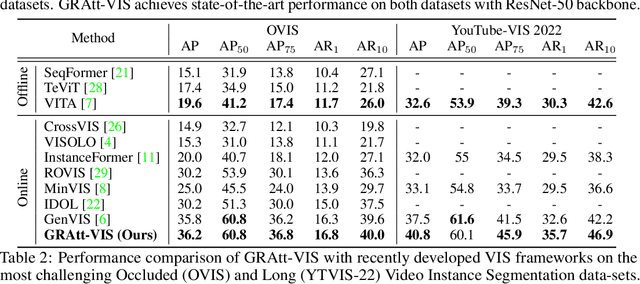
Recent trends in Video Instance Segmentation (VIS) have seen a growing reliance on online methods to model complex and lengthy video sequences. However, the degradation of representation and noise accumulation of the online methods, especially during occlusion and abrupt changes, pose substantial challenges. Transformer-based query propagation provides promising directions at the cost of quadratic memory attention. However, they are susceptible to the degradation of instance features due to the above-mentioned challenges and suffer from cascading effects. The detection and rectification of such errors remain largely underexplored. To this end, we introduce \textbf{GRAtt-VIS}, \textbf{G}ated \textbf{R}esidual \textbf{Att}ention for \textbf{V}ideo \textbf{I}nstance \textbf{S}egmentation. Firstly, we leverage a Gumbel-Softmax-based gate to detect possible errors in the current frame. Next, based on the gate activation, we rectify degraded features from its past representation. Such a residual configuration alleviates the need for dedicated memory and provides a continuous stream of relevant instance features. Secondly, we propose a novel inter-instance interaction using gate activation as a mask for self-attention. This masking strategy dynamically restricts the unrepresentative instance queries in the self-attention and preserves vital information for long-term tracking. We refer to this novel combination of Gated Residual Connection and Masked Self-Attention as \textbf{GRAtt} block, which can easily be integrated into the existing propagation-based framework. Further, GRAtt blocks significantly reduce the attention overhead and simplify dynamic temporal modeling. GRAtt-VIS achieves state-of-the-art performance on YouTube-VIS and the highly challenging OVIS dataset, significantly improving over previous methods. Code is available at \url{https://github.com/Tanveer81/GRAttVIS}.
MolXPT: Wrapping Molecules with Text for Generative Pre-training
May 18, 2023
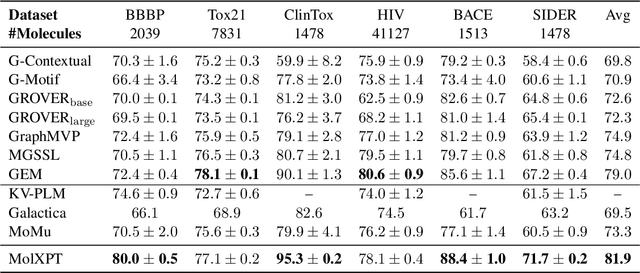
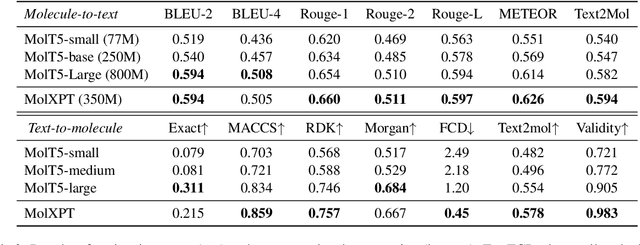

Generative pre-trained Transformer (GPT) has demonstrates its great success in natural language processing and related techniques have been adapted into molecular modeling. Considering that text is the most important record for scientific discovery, in this paper, we propose MolXPT, a unified language model of text and molecules pre-trained on SMILES (a sequence representation of molecules) wrapped by text. Briefly, we detect the molecule names in each sequence and replace them to the corresponding SMILES. In this way, the SMILES could leverage the information from surrounding text, and vice versa. The above wrapped sequences, text sequences from PubMed and SMILES sequences from PubChem are all fed into a language model for pre-training. Experimental results demonstrate that MolXPT outperforms strong baselines of molecular property prediction on MoleculeNet, performs comparably to the best model in text-molecule translation while using less than half of its parameters, and enables zero-shot molecular generation without finetuning.
Discriminative Diffusion Models as Few-shot Vision and Language Learners
May 18, 2023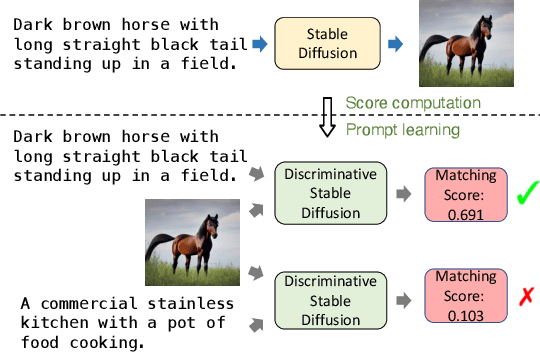
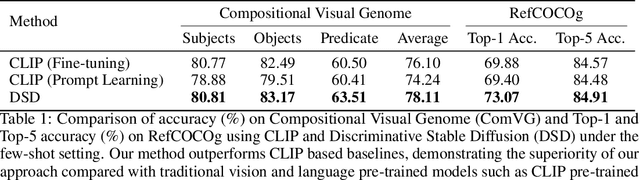
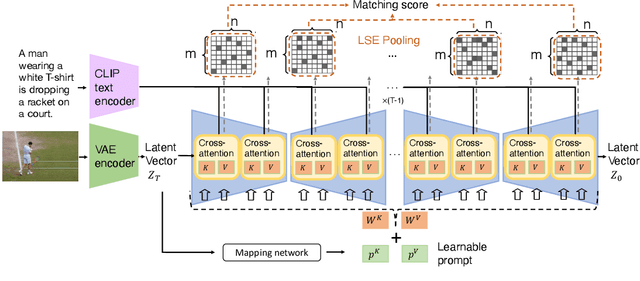
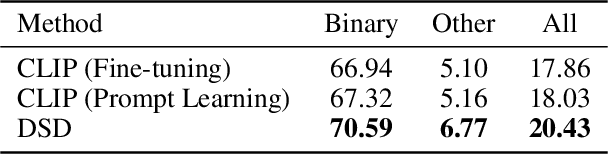
Diffusion models, such as Stable Diffusion, have shown incredible performance on text-to-image generation. Since text-to-image generation often requires models to generate visual concepts with fine-grained details and attributes specified in text prompts, can we leverage the powerful representations learned by pre-trained diffusion models for discriminative tasks such as image-text matching? To answer this question, we propose a novel approach, Discriminative Stable Diffusion (DSD), which turns pre-trained text-to-image diffusion models into few-shot discriminative learners. Our approach uses the cross-attention score of a Stable Diffusion model to capture the mutual influence between visual and textual information and fine-tune the model via attention-based prompt learning to perform image-text matching. By comparing DSD with state-of-the-art methods on several benchmark datasets, we demonstrate the potential of using pre-trained diffusion models for discriminative tasks with superior results on few-shot image-text matching.