 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Element-aware Summarization with Large Language Models: Expert-aligned Evaluation and Chain-of-Thought Method
May 22, 2023

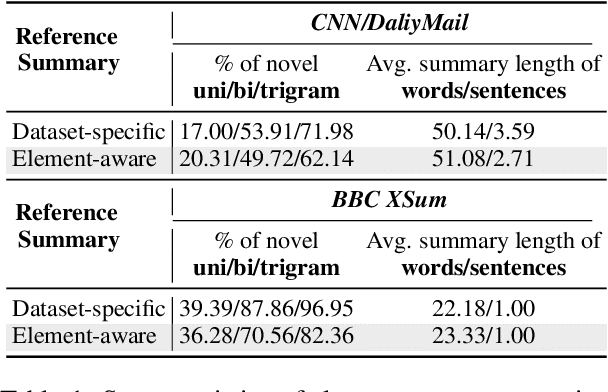

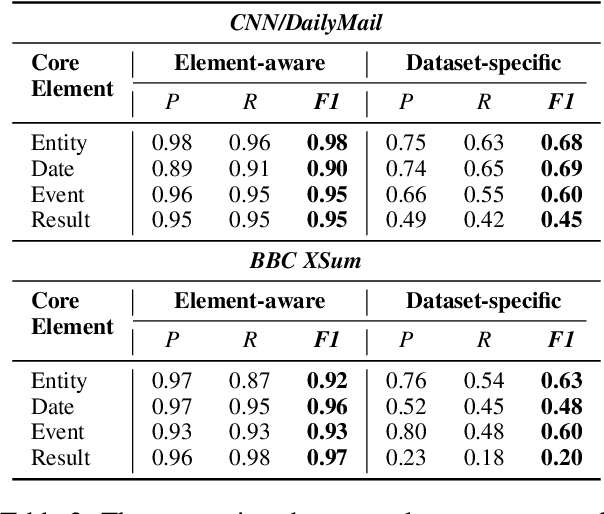
Automatic summarization generates concise summaries that contain key ideas of source documents. As the most mainstream datasets for the news sub-domain, CNN/DailyMail and BBC XSum have been widely used for performance benchmarking. However, the reference summaries of those datasets turn out to be noisy, mainly in terms of factual hallucination and information redundancy. To address this challenge, we first annotate new expert-writing Element-aware test sets following the "Lasswell Communication Model" proposed by Lasswell (1948), allowing reference summaries to focus on more fine-grained news elements objectively and comprehensively. Utilizing the new test sets, we observe the surprising zero-shot summary ability of LLMs, which addresses the issue of the inconsistent results between human preference and automatic evaluation metrics of LLMs' zero-shot summaries in prior work. Further, we propose a Summary Chain-of-Thought (SumCoT) technique to elicit LLMs to generate summaries step by step, which helps them integrate more fine-grained details of source documents into the final summaries that correlate with the human writing mindset. Experimental results show our method outperforms state-of-the-art fine-tuned PLMs and zero-shot LLMs by +4.33/+4.77 in ROUGE-L on the two datasets, respectively. Dataset and code are publicly available at https://github.com/Alsace08/SumCoT.
Enhancing Short-Term Wind Speed Forecasting using Graph Attention and Frequency-Enhanced Mechanisms
May 22, 2023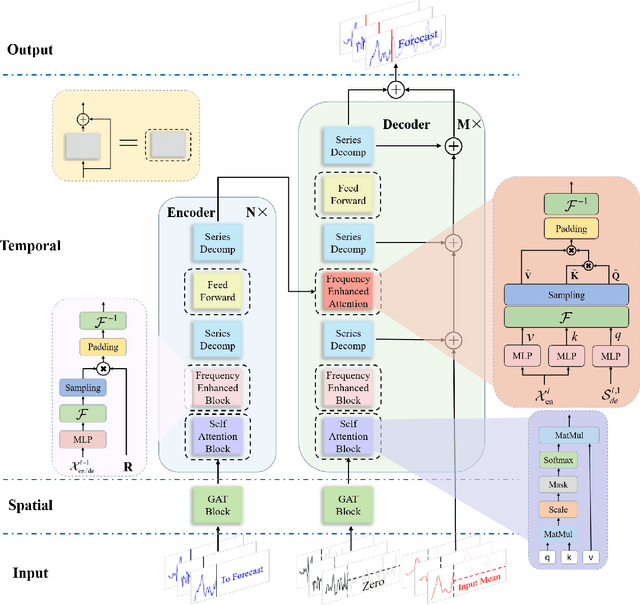
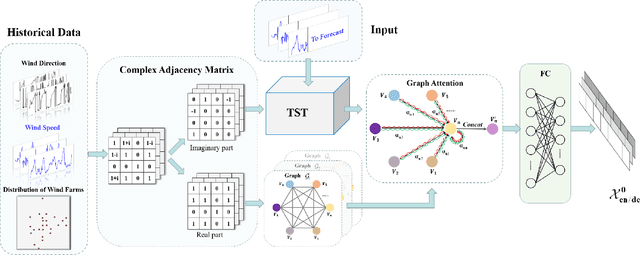
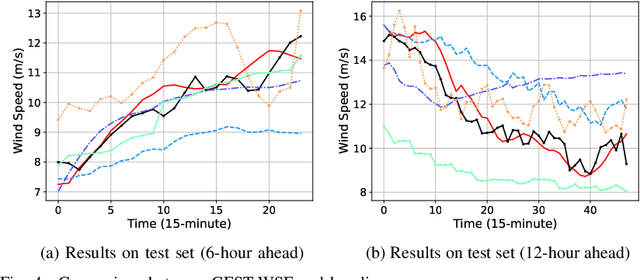
The safe and stable operation of power systems is greatly challenged by the high variability and randomness of wind power in large-scale wind-power-integrated grids. Wind power forecasting is an effective solution to tackle this issue, with wind speed forecasting being an essential aspect. In this paper, a Graph-attentive Frequency-enhanced Spatial-Temporal Wind Speed Forecasting model based on graph attention and frequency-enhanced mechanisms, i.e., GFST-WSF, is proposed to improve the accuracy of short-term wind speed forecasting. The GFST-WSF comprises a Transformer architecture for temporal feature extraction and a Graph Attention Network (GAT) for spatial feature extraction. The GAT is specifically designed to capture the complex spatial dependencies among wind speed stations to effectively aggregate information from neighboring nodes in the graph, thus enhancing the spatial representation of the data. To model the time lag in wind speed correlation between adjacent wind farms caused by geographical factors, a dynamic complex adjacency matrix is formulated and utilized by the GAT. Benefiting from the effective spatio-temporal feature extraction and the deep architecture of the Transformer, the GFST-WSF outperforms other baselines in wind speed forecasting for the 6-24 hours ahead forecast horizon in case studies.
FIT: Far-reaching Interleaved Transformers
May 22, 2023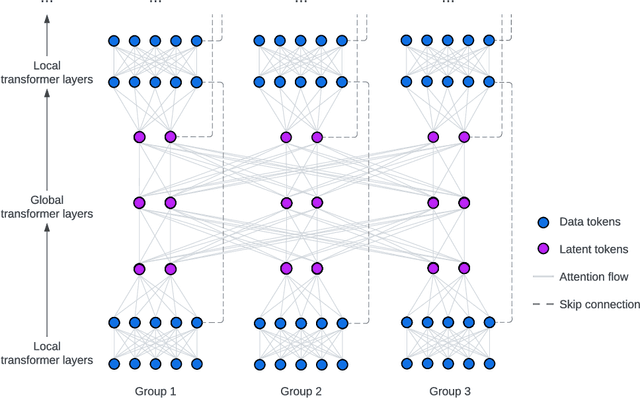
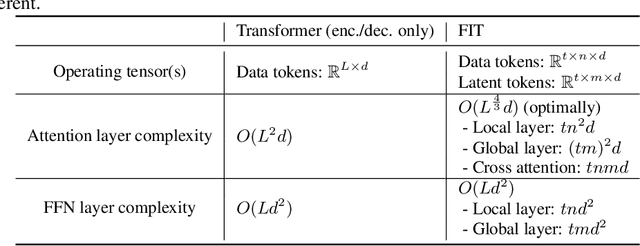
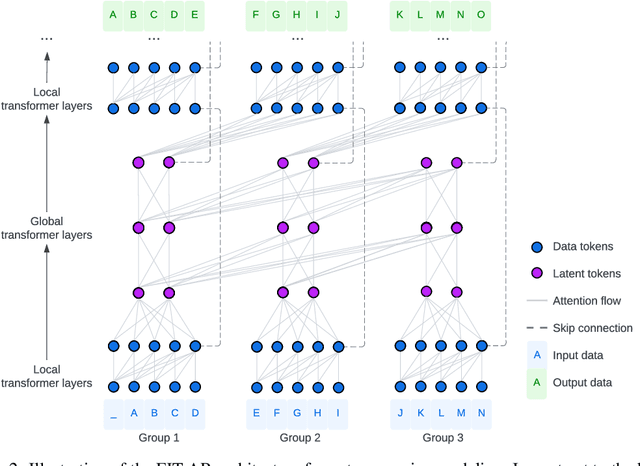
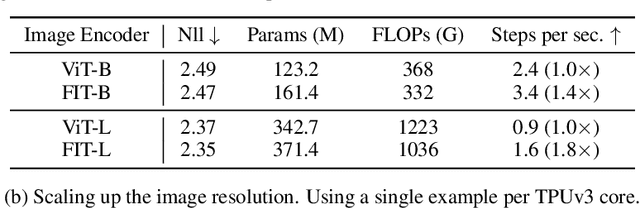
We present FIT: a transformer-based architecture with efficient self-attention and adaptive computation. Unlike original transformers, which operate on a single sequence of data tokens, we divide the data tokens into groups, with each group being a shorter sequence of tokens. We employ two types of transformer layers: local layers operate on data tokens within each group, while global layers operate on a smaller set of introduced latent tokens. These layers, comprising the same set of self-attention and feed-forward layers as standard transformers, are interleaved, and cross-attention is used to facilitate information exchange between data and latent tokens within the same group. The attention complexity is $O(n^2)$ locally within each group of size $n$, but can reach $O(L^{{4}/{3}})$ globally for sequence length of $L$. The efficiency can be further enhanced by relying more on global layers that perform adaptive computation using a smaller set of latent tokens. FIT is a versatile architecture and can function as an encoder, diffusion decoder, or autoregressive decoder. We provide initial evidence demonstrating its effectiveness in high-resolution image understanding and generation tasks. Notably, FIT exhibits potential in performing end-to-end training on gigabit-scale data, such as 6400$\times$6400 images, even without specific optimizations or model parallelism.
Joint Device-Edge Digital Semantic Communication with Adaptive Network Split and Learned Non-Linear Quantization
May 22, 2023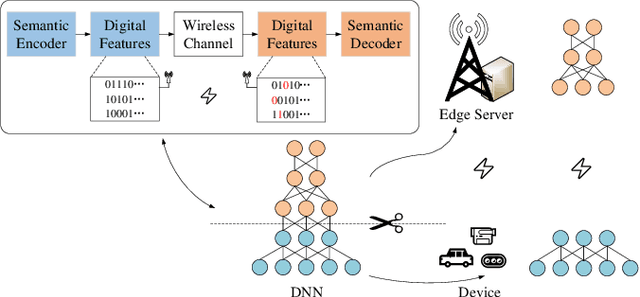
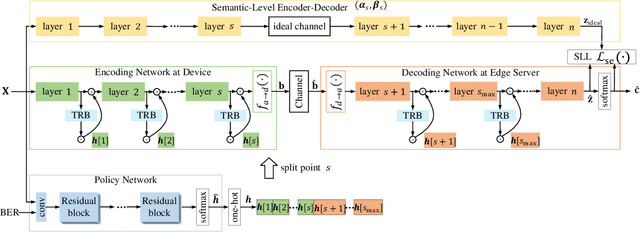
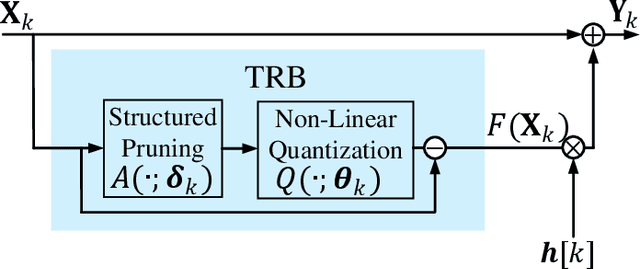
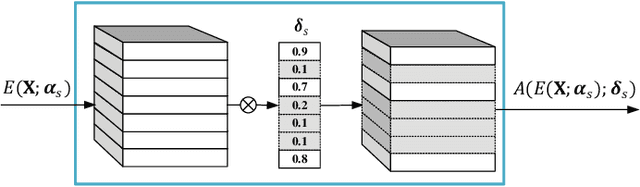
Semantic communication, an intelligent communication paradigm that aims to transmit useful information in the semantic domain, is facilitated by deep learning techniques. Although robust semantic features can be learned and transmitted in an analog fashion, it poses new challenges to hardware, protocol, and encryption. In this paper, we propose a digital semantic communication system, which consists of an encoding network deployed on a resource-limited device and a decoding network deployed at the edge. To acquire better semantic representation for digital transmission, a novel non-linear quantization module is proposed with the trainable quantization levels that efficiently quantifies semantic features. Additionally, structured pruning by a sparse scaling vector is incorporated to reduce the dimension of the transmitted features. We also introduce a semantic learning loss (SLL) function to reduce semantic error. To adapt to various channel conditions and inputs under constraints of communication and computing resources, a policy network is designed to adaptively choose the split point and the dimension of the transmitted semantic features. Experiments using the CIFAR-10 dataset for image classification are employed to evaluate the proposed digital semantic communication network, and ablation studies are conducted to assess the proposed modules including the quantization module, structured pruning and SLL.
Logical Reasoning for Natural Language Inference Using Generated Facts as Atoms
May 22, 2023
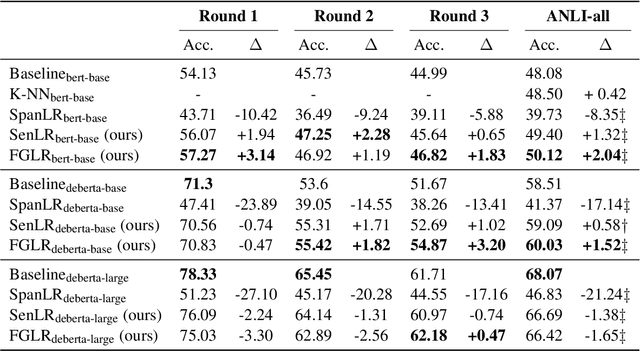
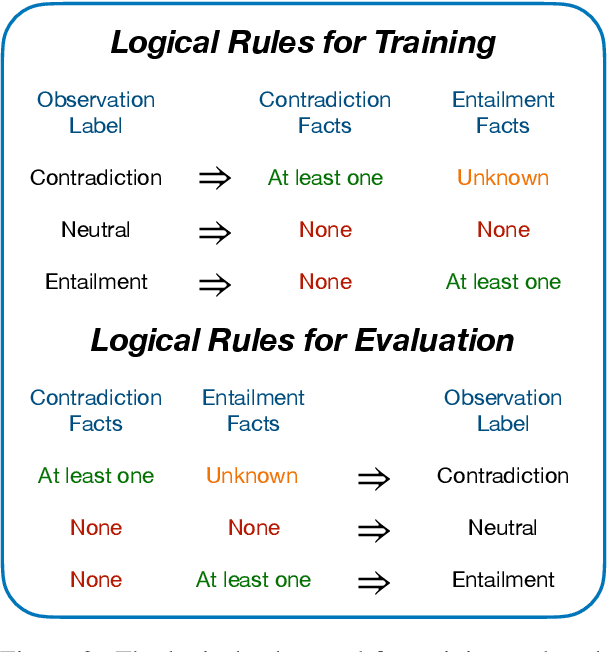
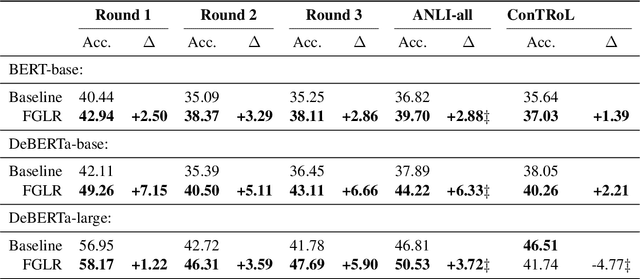
State-of-the-art neural models can now reach human performance levels across various natural language understanding tasks. However, despite this impressive performance, models are known to learn from annotation artefacts at the expense of the underlying task. While interpretability methods can identify influential features for each prediction, there are no guarantees that these features are responsible for the model decisions. Instead, we introduce a model-agnostic logical framework to determine the specific information in an input responsible for each model decision. This method creates interpretable Natural Language Inference (NLI) models that maintain their predictive power. We achieve this by generating facts that decompose complex NLI observations into individual logical atoms. Our model makes predictions for each atom and uses logical rules to decide the class of the observation based on the predictions for each atom. We apply our method to the highly challenging ANLI dataset, where our framework improves the performance of both a DeBERTa-base and BERT baseline. Our method performs best on the most challenging examples, achieving a new state-of-the-art for the ANLI round 3 test set. We outperform every baseline in a reduced-data setting, and despite using no annotations for the generated facts, our model predictions for individual facts align with human expectations.
READMem: Robust Embedding Association for a Diverse Memory in Unconstrained Video Object Segmentation
May 22, 2023
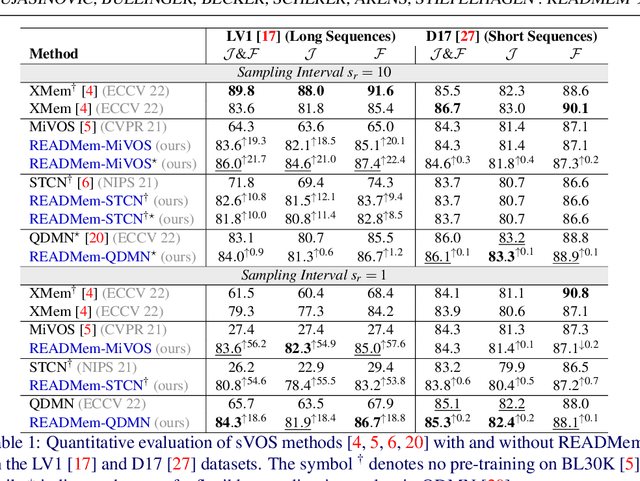
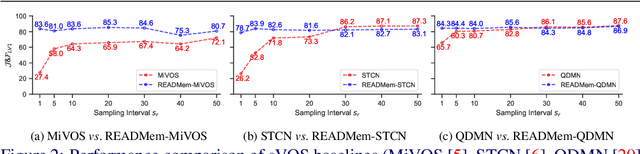

We present READMem (Robust Embedding Association for a Diverse Memory), a modular framework for semi-automatic video object segmentation (sVOS) methods designed to handle unconstrained videos. Contemporary sVOS works typically aggregate video frames in an ever-expanding memory, demanding high hardware resources for long-term applications. To mitigate memory requirements and prevent near object duplicates (caused by information of adjacent frames), previous methods introduce a hyper-parameter that controls the frequency of frames eligible to be stored. This parameter has to be adjusted according to concrete video properties (such as rapidity of appearance changes and video length) and does not generalize well. Instead, we integrate the embedding of a new frame into the memory only if it increases the diversity of the memory content. Furthermore, we propose a robust association of the embeddings stored in the memory with query embeddings during the update process. Our approach avoids the accumulation of redundant data, allowing us in return, to restrict the memory size and prevent extreme memory demands in long videos. We extend popular sVOS baselines with READMem, which previously showed limited performance on long videos. Our approach achieves competitive results on the Long-time Video dataset (LV1) while not hindering performance on short sequences. Our code is publicly available.
MADNet: Maximizing Addressee Deduction Expectation for Multi-Party Conversation Generation
May 22, 2023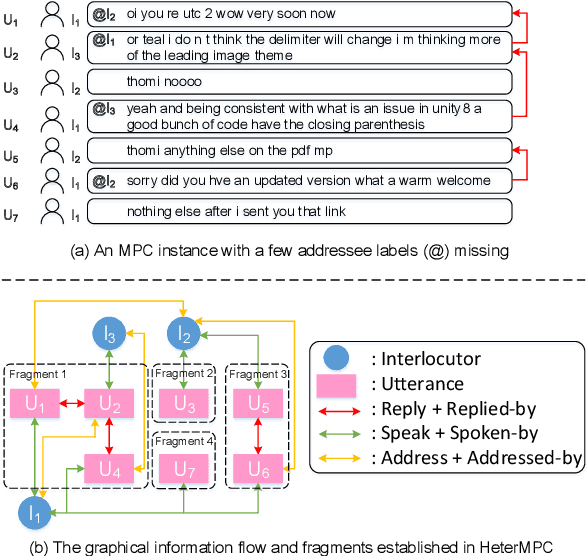
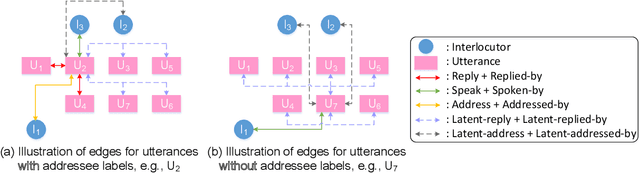
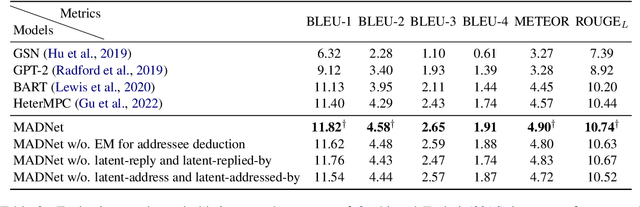
Modeling multi-party conversations (MPCs) with graph neural networks has been proven effective at capturing complicated and graphical information flows. However, existing methods rely heavily on the necessary addressee labels and can only be applied to an ideal setting where each utterance must be tagged with an addressee label. To study the scarcity of addressee labels which is a common issue in MPCs, we propose MADNet that maximizes addressee deduction expectation in heterogeneous graph neural networks for MPC generation. Given an MPC with a few addressee labels missing, existing methods fail to build a consecutively connected conversation graph, but only a few separate conversation fragments instead. To ensure message passing between these conversation fragments, four additional types of latent edges are designed to complete a fully-connected graph. Besides, to optimize the edge-type-dependent message passing for those utterances without addressee labels, an Expectation-Maximization-based method that iteratively generates silver addressee labels (E step), and optimizes the quality of generated responses (M step), is designed. Experimental results on two Ubuntu IRC channel benchmarks show that MADNet outperforms various baseline models on the task of MPC generation, especially under the more common and challenging setting where part of addressee labels are missing.
Playing repeated games with Large Language Models
May 26, 2023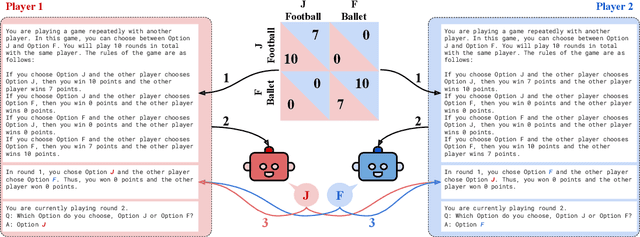
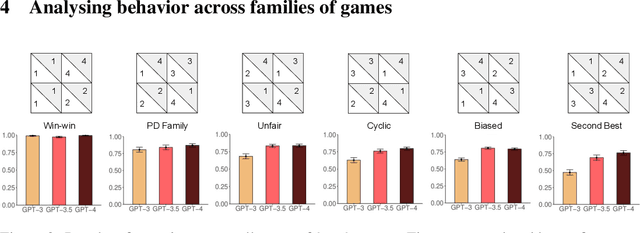
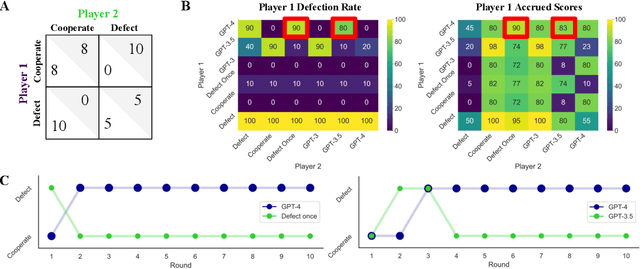
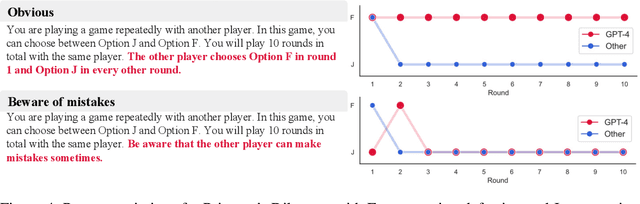
Large Language Models (LLMs) are transforming society and permeating into diverse applications. As a result, LLMs will frequently interact with us and other agents. It is, therefore, of great societal value to understand how LLMs behave in interactive social settings. Here, we propose to use behavioral game theory to study LLM's cooperation and coordination behavior. To do so, we let different LLMs (GPT-3, GPT-3.5, and GPT-4) play finitely repeated games with each other and with other, human-like strategies. Our results show that LLMs generally perform well in such tasks and also uncover persistent behavioral signatures. In a large set of two players-two strategies games, we find that LLMs are particularly good at games where valuing their own self-interest pays off, like the iterated Prisoner's Dilemma family. However, they behave sub-optimally in games that require coordination. We, therefore, further focus on two games from these distinct families. In the canonical iterated Prisoner's Dilemma, we find that GPT-4 acts particularly unforgivingly, always defecting after another agent has defected only once. In the Battle of the Sexes, we find that GPT-4 cannot match the behavior of the simple convention to alternate between options. We verify that these behavioral signatures are stable across robustness checks. Finally, we show how GPT-4's behavior can be modified by providing further information about the other player as well as by asking it to predict the other player's actions before making a choice. These results enrich our understanding of LLM's social behavior and pave the way for a behavioral game theory for machines.
GRAtt-VIS: Gated Residual Attention for Auto Rectifying Video Instance Segmentation
May 26, 2023
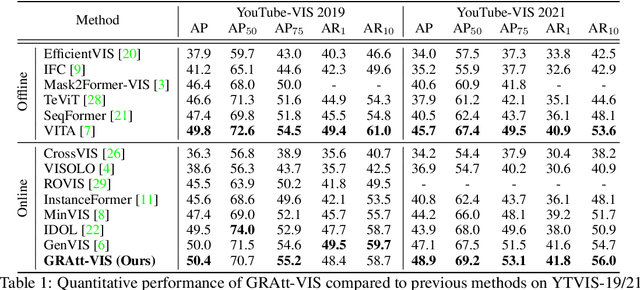
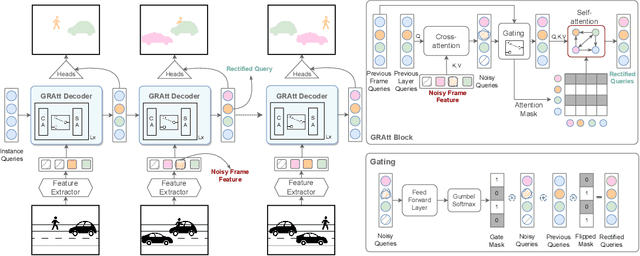
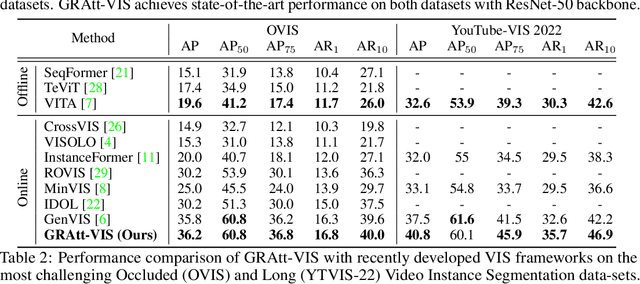
Recent trends in Video Instance Segmentation (VIS) have seen a growing reliance on online methods to model complex and lengthy video sequences. However, the degradation of representation and noise accumulation of the online methods, especially during occlusion and abrupt changes, pose substantial challenges. Transformer-based query propagation provides promising directions at the cost of quadratic memory attention. However, they are susceptible to the degradation of instance features due to the above-mentioned challenges and suffer from cascading effects. The detection and rectification of such errors remain largely underexplored. To this end, we introduce \textbf{GRAtt-VIS}, \textbf{G}ated \textbf{R}esidual \textbf{Att}ention for \textbf{V}ideo \textbf{I}nstance \textbf{S}egmentation. Firstly, we leverage a Gumbel-Softmax-based gate to detect possible errors in the current frame. Next, based on the gate activation, we rectify degraded features from its past representation. Such a residual configuration alleviates the need for dedicated memory and provides a continuous stream of relevant instance features. Secondly, we propose a novel inter-instance interaction using gate activation as a mask for self-attention. This masking strategy dynamically restricts the unrepresentative instance queries in the self-attention and preserves vital information for long-term tracking. We refer to this novel combination of Gated Residual Connection and Masked Self-Attention as \textbf{GRAtt} block, which can easily be integrated into the existing propagation-based framework. Further, GRAtt blocks significantly reduce the attention overhead and simplify dynamic temporal modeling. GRAtt-VIS achieves state-of-the-art performance on YouTube-VIS and the highly challenging OVIS dataset, significantly improving over previous methods. Code is available at \url{https://github.com/Tanveer81/GRAttVIS}.
An End-to-End Approach for Online Decision Mining and Decision Drift Analysis in Process-Aware Information Systems: Extended Version
Mar 07, 2023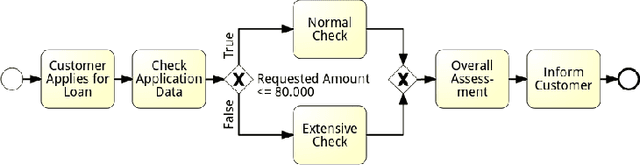
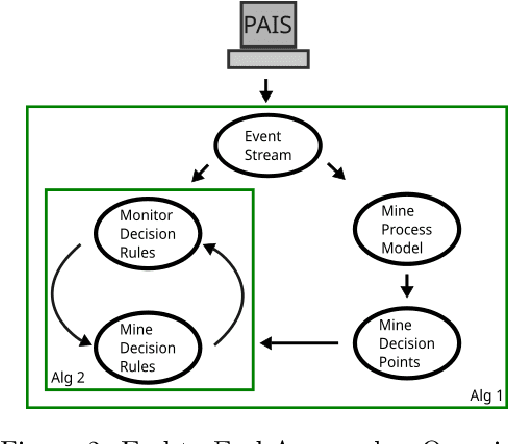
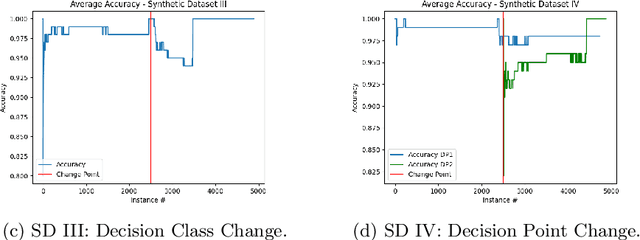
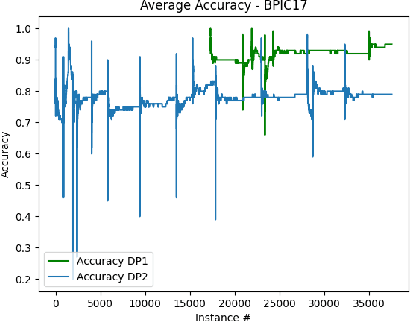
Decision mining enables the discovery of decision rules from event logs or streams, and constitutes an important part of in-depth analysis and optimisation of business processes. So far, decision mining has been merely applied in an ex-post way resulting in a snapshot of decision rules for the given chunk of log data. Online decision mining, by contrast, enables continuous monitoring of decision rule evolution and decision drift. Hence this paper presents an end-to-end approach for the discovery as well as monitoring of decision points and the corresponding decision rules during runtime, bridging the gap between online control flow discovery and decision mining. The approach provides automatic decision support for process-aware information systems with efficient decision drift discovery and monitoring. For monitoring, not only the performance, in terms of accuracy, of decision rules is taken into account, but also the occurrence of data elements and changes in branching frequency. The paper provides two algorithms, which are evaluated on four synthetic and one real-life data set, showing feasibility and applicability of the approach. Overall, the approach fosters the understanding of decisions in business processes and hence contributes to an improved human-process interaction.