 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TempSAL -- Uncovering Temporal Information for Deep Saliency Prediction
Jan 05, 2023



Deep saliency prediction algorithms complement the object recognition features, they typically rely on additional information, such as scene context, semantic relationships, gaze direction, and object dissimilarity. However, none of these models consider the temporal nature of gaze shifts during image observation. We introduce a novel saliency prediction model that learns to output saliency maps in sequential time intervals by exploiting human temporal attention patterns. Our approach locally modulates the saliency predictions by combining the learned temporal maps. Our experiments show that our method outperforms the state-of-the-art models, including a multi-duration saliency model, on the SALICON benchmark. Our code will be publicly available on GitHub.
Artificial intelligence to advance Earth observation: a perspective
May 15, 2023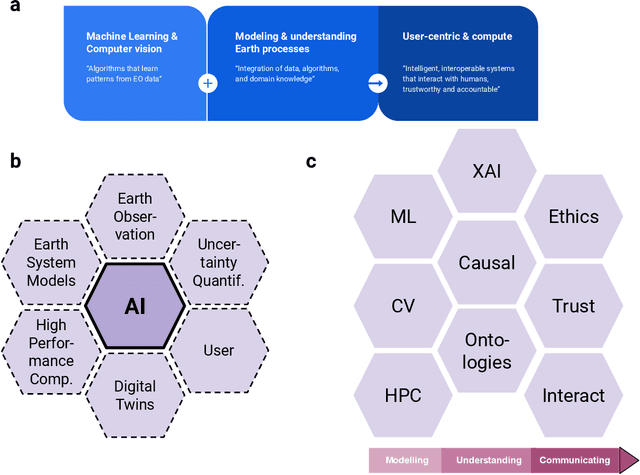
Earth observation (EO) is a prime instrument for monitoring land and ocean processes, studying the dynamics at work, and taking the pulse of our planet. This article gives a bird's eye view of the essential scientific tools and approaches informing and supporting the transition from raw EO data to usable EO-based information. The promises, as well as the current challenges of these developments, are highlighted under dedicated sections. Specifically, we cover the impact of (i) Computer vision; (ii) Machine learning; (iii) Advanced processing and computing; (iv) Knowledge-based AI; (v) Explainable AI and causal inference; (vi) Physics-aware models; (vii) User-centric approaches; and (viii) the much-needed discussion of ethical and societal issues related to the massive use of ML technologies in EO.
Self-Learning Symmetric Multi-view Probabilistic Clustering
May 12, 2023
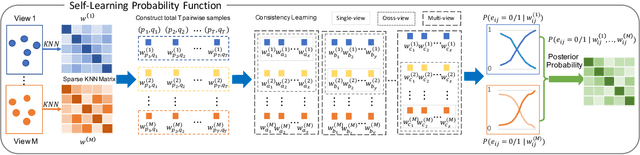
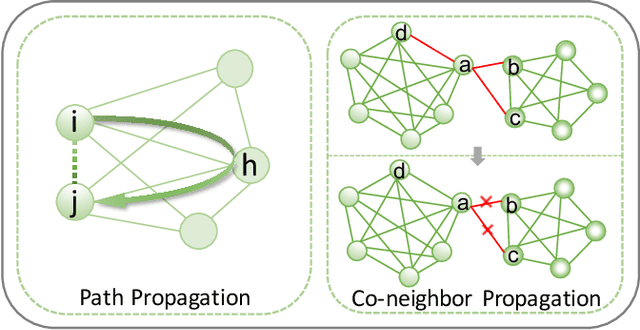
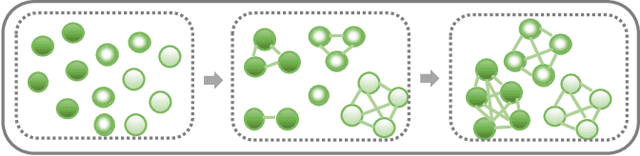
Multi-view Clustering (MVC) has achieved significant progress, with many efforts dedicated to learn knowledge from multiple views. However, most existing methods are either not applicable or require additional steps for incomplete multi-view clustering. Such a limitation results in poor-quality clustering performance and poor missing view adaptation. Besides, noise or outliers might significantly degrade the overall clustering performance, which are not handled well by most existing methods. Moreover, category information is required in most existing methods, which severely affects the clustering performance. In this paper, we propose a novel unified framework for incomplete and complete MVC named self-learning symmetric multi-view probabilistic clustering (SLS-MPC). SLS-MPC proposes a novel symmetric multi-view probability estimation and equivalently transforms multi-view pairwise posterior matching probability into composition of each view's individual distribution, which tolerates data missing and might extend to any number of views. Then, SLS-MPC proposes a novel self-learning probability function without any prior knowledge and hyper-parameters to learn each view's individual distribution from the aspect of consistency in single-view, cross-view and multi-view. Next, graph-context-aware refinement with path propagation and co-neighbor propagation is used to refine pairwise probability, which alleviates the impact of noise and outliers. Finally, SLS-MPC proposes a probabilistic clustering algorithm to adjust clustering assignments by maximizing the joint probability iteratively, in which category information is not required. Extensive experiments on multiple benchmarks for incomplete and complete MVC show that SLS-MPC significantly outperforms previous state-of-the-art methods.
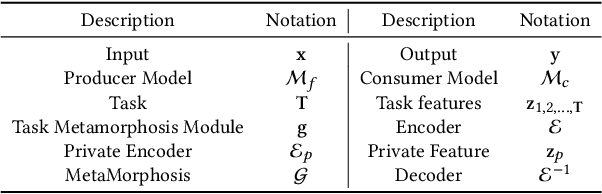
MetaMorphosis: Task-oriented Privacy Cognizant Feature Generation for Multi-task Learning
May 13, 2023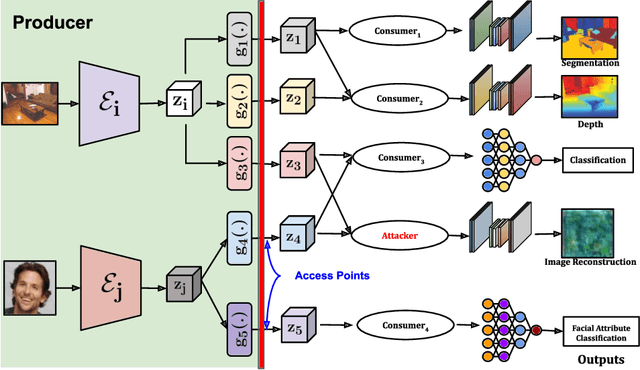

With the growth of computer vision applications, deep learning, and edge computing contribute to ensuring practical collaborative intelligence (CI) by distributing the workload among edge devices and the cloud. However, running separate single-task models on edge devices is inefficient regarding the required computational resource and time. In this context, multi-task learning allows leveraging a single deep learning model for performing multiple tasks, such as semantic segmentation and depth estimation on incoming video frames. This single processing pipeline generates common deep features that are shared among multi-task modules. However, in a collaborative intelligence scenario, generating common deep features has two major issues. First, the deep features may inadvertently contain input information exposed to the downstream modules (violating input privacy). Second, the generated universal features expose a piece of collective information than what is intended for a certain task, in which features for one task can be utilized to perform another task (violating task privacy). This paper proposes a novel deep learning-based privacy-cognizant feature generation process called MetaMorphosis that limits inference capability to specific tasks at hand. To achieve this, we propose a channel squeeze-excitation based feature metamorphosis module, Cross-SEC, to achieve distinct attention of all tasks and a de-correlation loss function with differential-privacy to train a deep learning model that produces distinct privacy-aware features as an output for the respective tasks. With extensive experimentation on four datasets consisting of diverse images related to scene understanding and facial attributes, we show that MetaMorphosis outperforms recent adversarial learning and universal feature generation methods by guaranteeing privacy requirements in an efficient way for image and video analytics.
Dynamic User Segmentation and Usage Profiling
May 27, 2023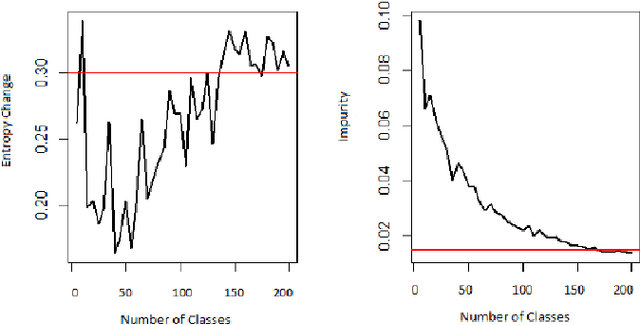
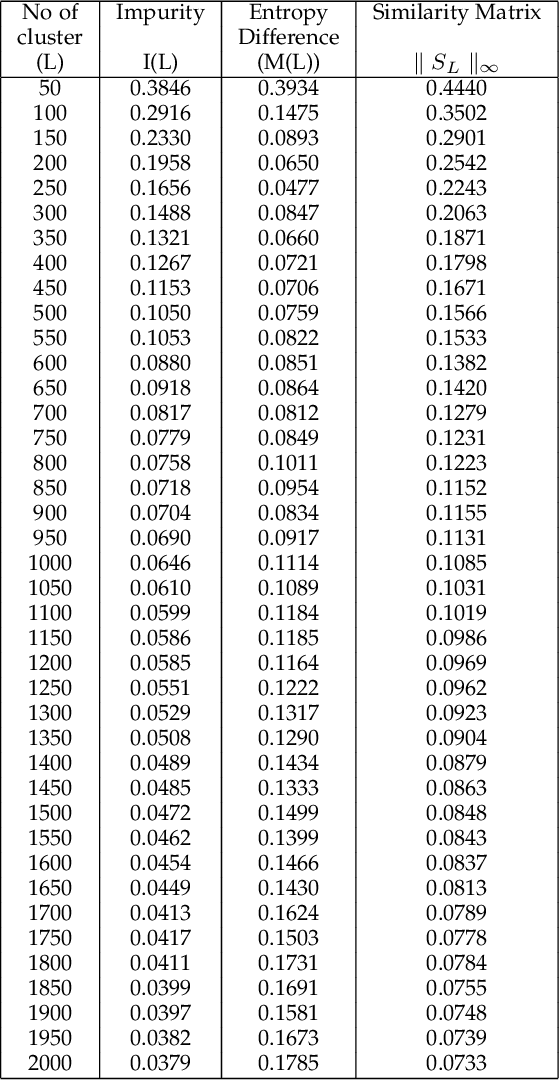
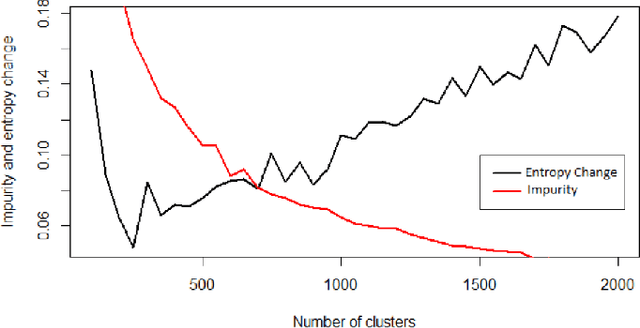
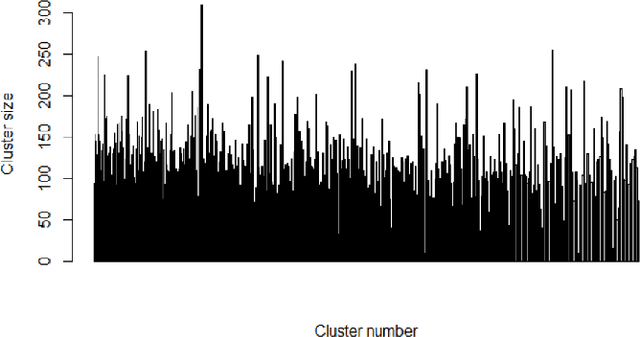
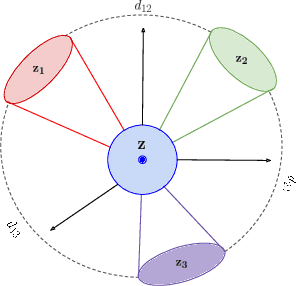
Usage data of a group of users distributed across a number of categories, such as songs, movies, webpages, links, regular household products, mobile apps, games, etc. can be ultra-high dimensional and massive in size. More often this kind of data is categorical and sparse in nature making it even more difficult to interpret any underlying hidden patterns such as clusters of users. However, if this information can be estimated accurately, it will have huge impacts in different business areas such as user recommendations for apps, songs, movies, and other similar products, health analytics using electronic health record (EHR) data, and driver profiling for insurance premium estimation or fleet management. In this work, we propose a clustering strategy of such categorical big data, utilizing the hidden sparsity of the dataset. Most traditional clustering methods fail to give proper clusters for such data and end up giving one big cluster with small clusters around it irrespective of the true structure of the data clusters. We propose a feature transformation, which maps the binary-valued usage vector to a lower dimensional continuous feature space in terms of groups of usage categories, termed as covariate classes. The lower dimensional feature representations in terms of covariate classes can be used for clustering. We implemented the proposed strategy and applied it to a large sized very high-dimensional song playlist dataset for the performance validation. The results are impressive as we achieved similar-sized user clusters with minimal between-cluster overlap in the feature space (8%) on average). As the proposed strategy has a very generic framework, it can be utilized as the analytic engine of many of the above-mentioned business use cases allowing an intelligent and dynamic personal recommendation system or a support system for smart business decision-making.
Online Learning in Multi-unit Auctions
May 27, 2023
We consider repeated multi-unit auctions with uniform pricing, which are widely used in practice for allocating goods such as carbon licenses. In each round, $K$ identical units of a good are sold to a group of buyers that have valuations with diminishing marginal returns. The buyers submit bids for the units, and then a price $p$ is set per unit so that all the units are sold. We consider two variants of the auction, where the price is set to the $K$-th highest bid and $(K+1)$-st highest bid, respectively. We analyze the properties of this auction in both the offline and online settings. In the offline setting, we consider the problem that one player $i$ is facing: given access to a data set that contains the bids submitted by competitors in past auctions, find a bid vector that maximizes player $i$'s cumulative utility on the data set. We design a polynomial time algorithm for this problem, by showing it is equivalent to finding a maximum-weight path on a carefully constructed directed acyclic graph. In the online setting, the players run learning algorithms to update their bids as they participate in the auction over time. Based on our offline algorithm, we design efficient online learning algorithms for bidding. The algorithms have sublinear regret, under both full information and bandit feedback structures. We complement our online learning algorithms with regret lower bounds. Finally, we analyze the quality of the equilibria in the worst case through the lens of the core solution concept in the game among the bidders. We show that the $(K+1)$-st price format is susceptible to collusion among the bidders; meanwhile, the $K$-th price format does not have this issue.
Fully Automatic Gym Exercises Recording: An IoT Solution
May 27, 2023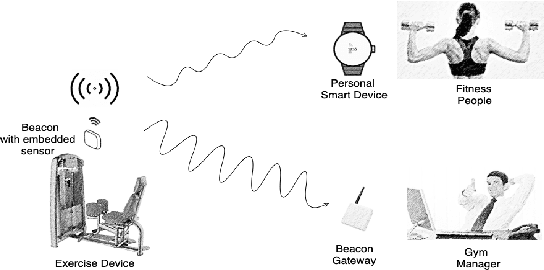
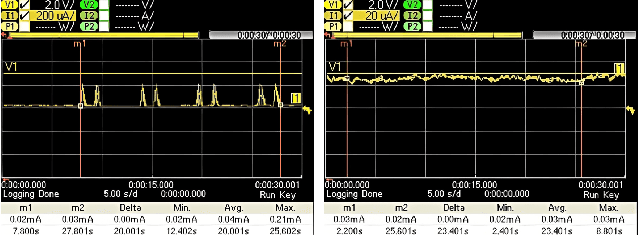
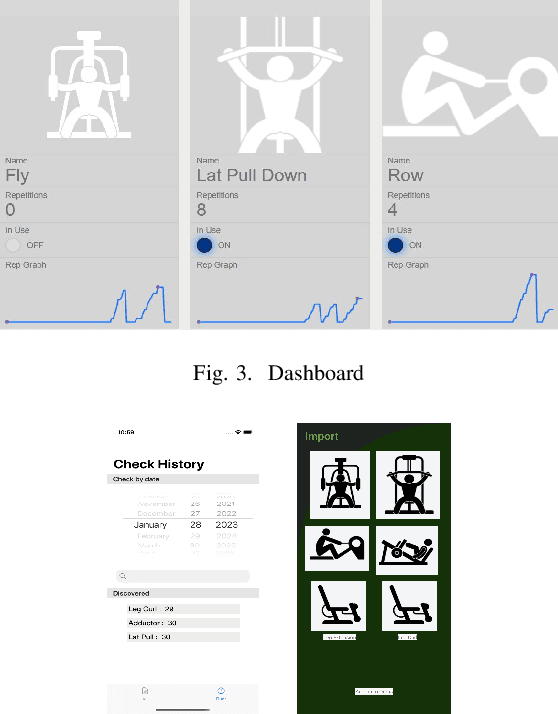
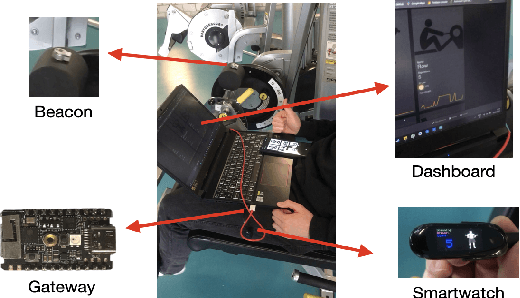
In recent years, working out in the gym has gotten increasingly more data-focused and many gym enthusiasts are recording their exercises to have a better overview of their historical gym activities and to make a better exercise plan for the future. As a side effect, this recording process has led to a lot of time spent painstakingly operating these apps by plugging in used types of equipment and repetitions. This project aims to automate this process using an Internet of Things (IoT) approach. Specifically, beacons with embedded ultra-low-power inertial measurement units (IMUs) are attached to the types of equipment to recognize the usage and transmit the information to gym-goers and managers. We have created a small ecosystem composed of beacons, a gateway, smartwatches, android/iPhone applications, a firebase cloud server, and a dashboard, all communicating over a mixture of Bluetooth and Wifi to distribute collected data from machines to users and gym managers in a compact and meaningful way. The system we have implemented is a working prototype of a bigger end goal and is supposed to initialize progress toward a smarter, more efficient, and still privacy-respect gym environment in the future. A small-scale real-life test shows 94.6\% accuracy in user gym session recording, which can reach up to 100\% easily with a more suitable assembling of the beacons. This promising result shows the potential of a fully automatic exercise recording system, which enables comprehensive monitoring and analysis of the exercise sessions and frees the user from manual recording. The estimated battery life of the beacon is 400 days with a 210 mAh coin battery. We also discussed the shortcoming of the current demonstration system and the future work for a reliable and ready-to-deploy automatic gym workout recording system.
Joint Sensing, Communication, and AI: A Trifecta for Resilient THz User Experiences
Apr 29, 2023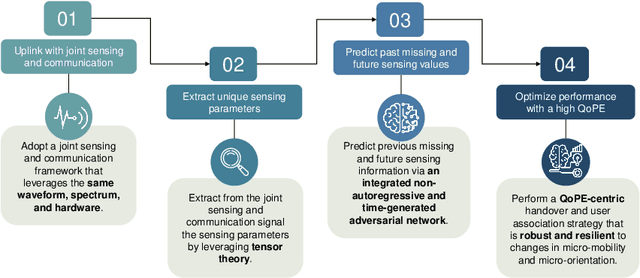
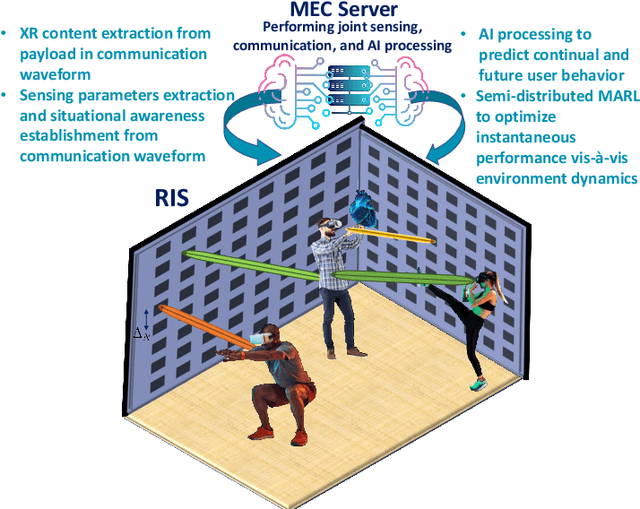
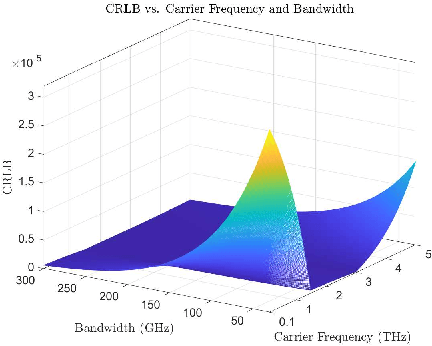
In this paper a novel joint sensing, communication, and artificial intelligence (AI) framework is proposed so as to optimize extended reality (XR) experiences over terahertz (THz) wireless systems. The proposed framework consists of three main components. First, a tensor decomposition framework is proposed to extract unique sensing parameters for XR users and their environment by exploiting then THz channel sparsity. Essentially, THz band's quasi-opticality is exploited and the sensing parameters are extracted from the uplink communication signal, thereby allowing for the use of the same waveform, spectrum, and hardware for both communication and sensing functionalities. Then, the Cramer-Rao lower bound is derived to assess the accuracy of the estimated sensing parameters. Second, a non-autoregressive multi-resolution generative artificial intelligence (AI) framework integrated with an adversarial transformer is proposed to predict missing and future sensing information. The proposed framework offers robust and comprehensive historical sensing information and anticipatory forecasts of future environmental changes, which are generalizable to fluctuations in both known and unforeseen user behaviors and environmental conditions. Third, a multi-agent deep recurrent hysteretic Q-neural network is developed to control the handover policy of reconfigurable intelligent surface (RIS) subarrays, leveraging the informative nature of sensing information to minimize handover cost, maximize the individual quality of personal experiences (QoPEs), and improve the robustness and resilience of THz links. Simulation results show a high generalizability of the proposed unsupervised generative AI framework to fluctuations in user behavior and velocity, leading to a 61 % improvement in instantaneous reliability compared to schemes with known channel state information.
Deep Learning-based Data-aided Activity Detection with Extraction Network in Grant-free Sparse Code Multiple Access Systems
May 13, 2023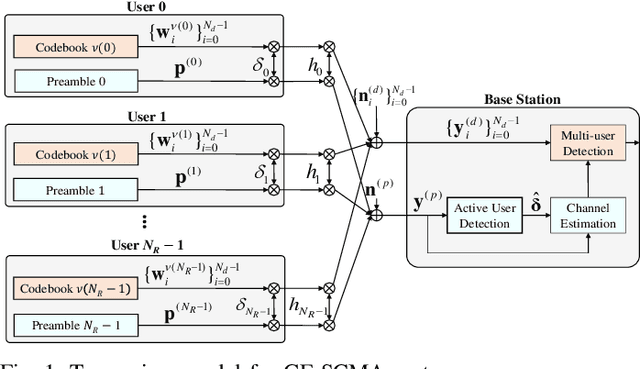
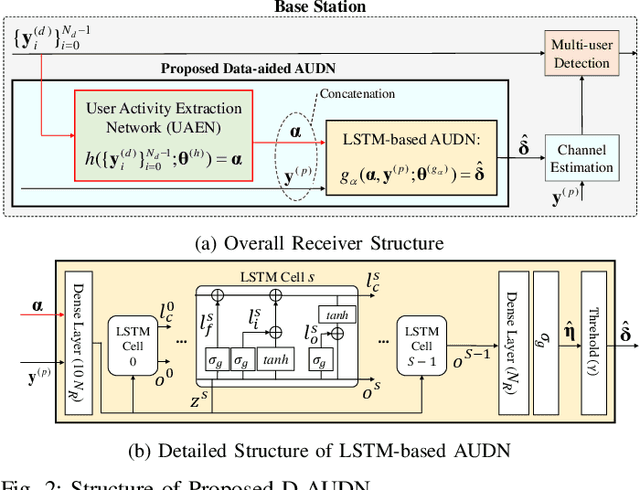
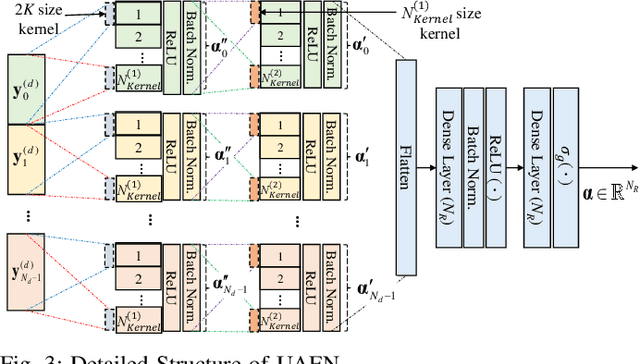
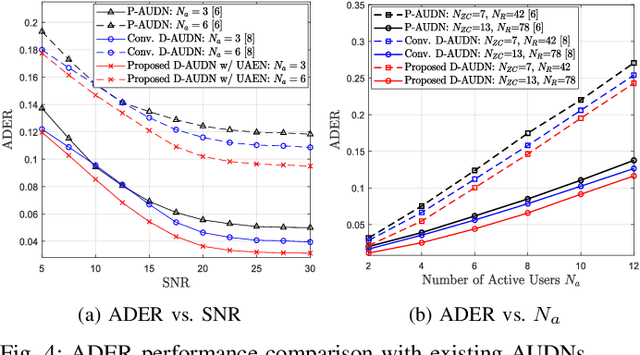
This letter proposes a deep learning-based data-aided active user detection network (D-AUDN) for grant-free sparse code multiple access (SCMA) systems that leverages both SCMA codebook and Zadoff-Chu preamble for activity detection. Due to disparate data and preamble distribution as well as codebook collision, existing D-AUDNs experience performance degradation when multiple preambles are associated with each codebook. To address this, a user activity extraction network (UAEN) is integrated within the D-AUDN to extract a-priori activity information from the codebook, improving activity detection of the associated preambles. Additionally, efficient SCMA codebook design and Zadoff-Chu preamble association are considered to further enhance performance.
CHIC: Corporate Document for Visual question Answering
May 01, 2023
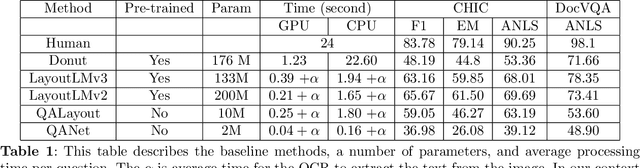
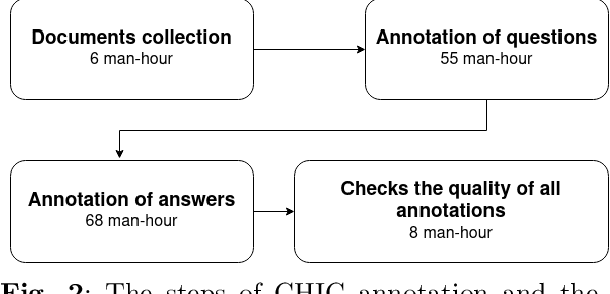

The massive use of digital documents due to the substantial trend of paperless initiatives confronted some companies to find ways to process thousands of documents per day automatically. To achieve this, they use automatic information retrieval (IR) allowing them to extract useful information from large datasets quickly. In order to have effective IR methods, it is first necessary to have an adequate dataset. Although companies have enough data to take into account their needs, there is also a need for a public database to compare contributions between state-of-the-art methods. Public data on the document exists as DocVQA[2] and XFUND [10], but these do not fully satisfy the needs of companies. XFUND contains only form documents while the company uses several types of documents (i.e. structured documents like forms but also semi-structured as invoices, and unstructured as emails). Compared to XFUND, DocVQA has several types of documents but only 4.5% of them are corporate documents (i.e. invoice, purchase order, etc). All of this 4.5% of documents do not meet the diversity of documents required by the company. We propose CHIC a visual question-answering public dataset. This dataset contains different types of corporate documents and the information extracted from these documents meet the right expectations of companies.