 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Diffusion-Based Mel-Spectrogram Enhancement for Personalized Speech Synthesis with Found Data
May 18, 2023
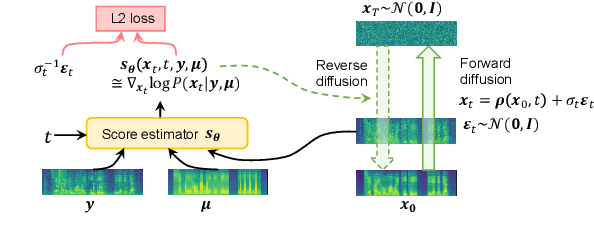
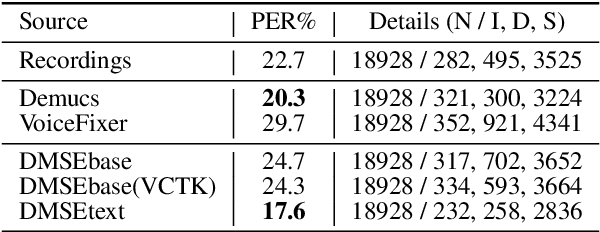
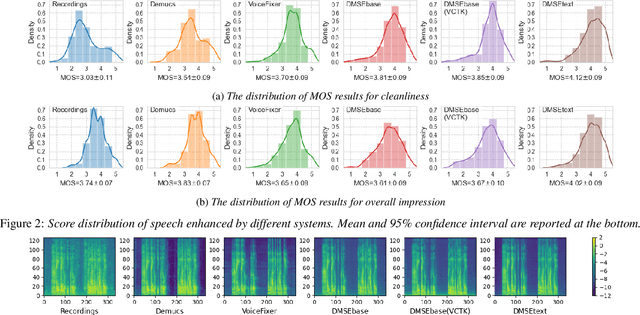
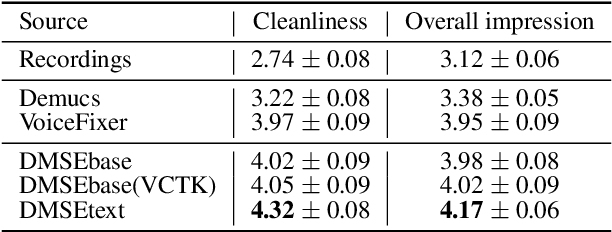
Creating synthetic voices with found data is challenging, as real-world recordings often contain various types of audio degradation. One way to address this problem is to pre-enhance the speech with an enhancement model and then use the enhanced data for text-to-speech (TTS) model training. Ideally, the enhancement model should be able to tackle multiple types of audio degradation simultaneously. This paper investigates the use of conditional diffusion models for generalized speech enhancement. The enhancement is performed on the log Mel-spectrogram domain to align with the TTS training objective. Text information is introduced as an additional condition to improve the model robustness. Experiments on real-world recordings demonstrate that the synthetic voice built on data enhanced by the proposed model produces higher-quality synthetic speech, compared to those trained on data enhanced by strong baselines. Audio samples are available at \url{https://dmse4tts.github.io/}.
TempSAL -- Uncovering Temporal Information for Deep Saliency Prediction
Jan 05, 2023
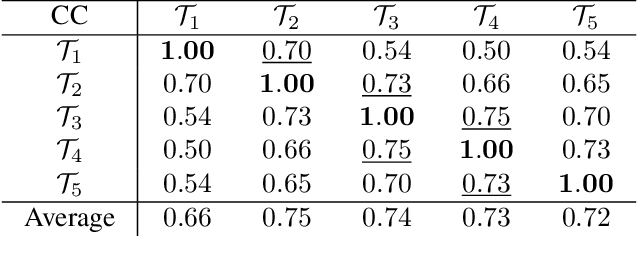


Deep saliency prediction algorithms complement the object recognition features, they typically rely on additional information, such as scene context, semantic relationships, gaze direction, and object dissimilarity. However, none of these models consider the temporal nature of gaze shifts during image observation. We introduce a novel saliency prediction model that learns to output saliency maps in sequential time intervals by exploiting human temporal attention patterns. Our approach locally modulates the saliency predictions by combining the learned temporal maps. Our experiments show that our method outperforms the state-of-the-art models, including a multi-duration saliency model, on the SALICON benchmark. Our code will be publicly available on GitHub.
Lifelong Language Pretraining with Distribution-Specialized Experts
May 20, 2023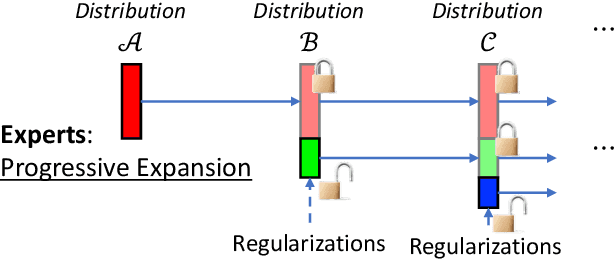
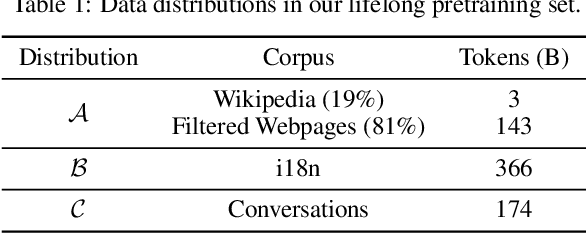
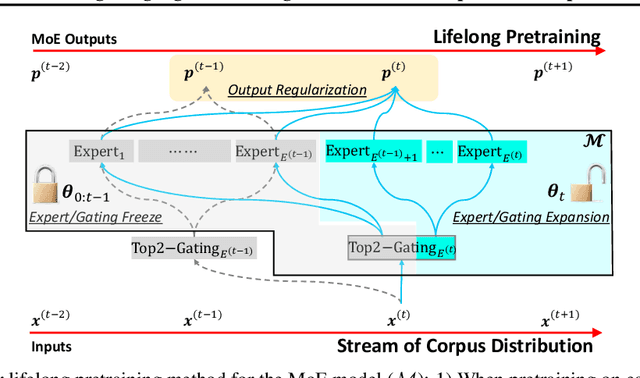
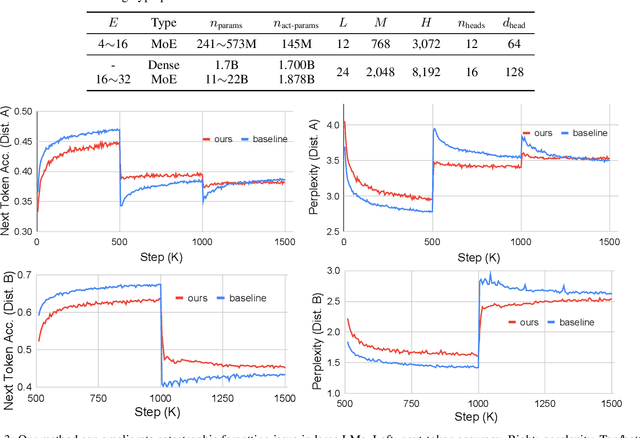
Pretraining on a large-scale corpus has become a standard method to build general language models (LMs). Adapting a model to new data distributions targeting different downstream tasks poses significant challenges. Naive fine-tuning may incur catastrophic forgetting when the over-parameterized LMs overfit the new data but fail to preserve the pretrained features. Lifelong learning (LLL) aims to enable information systems to learn from a continuous data stream across time. However, most prior work modifies the training recipe assuming a static fixed network architecture. We find that additional model capacity and proper regularization are key elements to achieving strong LLL performance. Thus, we propose Lifelong-MoE, an extensible MoE (Mixture-of-Experts) architecture that dynamically adds model capacity via adding experts with regularized pretraining. Our results show that by only introducing a limited number of extra experts while keeping the computation cost constant, our model can steadily adapt to data distribution shifts while preserving the previous knowledge. Compared to existing lifelong learning approaches, Lifelong-MoE achieves better few-shot performance on 19 downstream NLP tasks.
Reward-agnostic Fine-tuning: Provable Statistical Benefits of Hybrid Reinforcement Learning
May 17, 2023This paper studies tabular reinforcement learning (RL) in the hybrid setting, which assumes access to both an offline dataset and online interactions with the unknown environment. A central question boils down to how to efficiently utilize online data collection to strengthen and complement the offline dataset and enable effective policy fine-tuning. Leveraging recent advances in reward-agnostic exploration and model-based offline RL, we design a three-stage hybrid RL algorithm that beats the best of both worlds -- pure offline RL and pure online RL -- in terms of sample complexities. The proposed algorithm does not require any reward information during data collection. Our theory is developed based on a new notion called single-policy partial concentrability, which captures the trade-off between distribution mismatch and miscoverage and guides the interplay between offline and online data.
Clustering-Aware Negative Sampling for Unsupervised Sentence Representation
May 17, 2023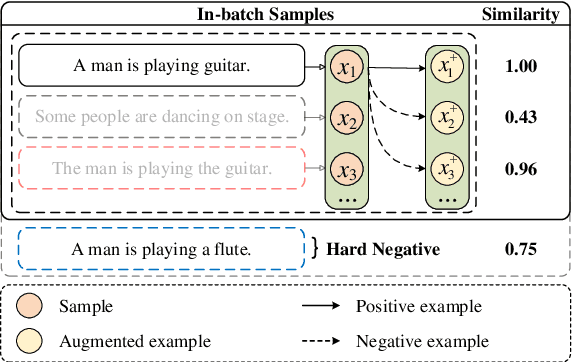
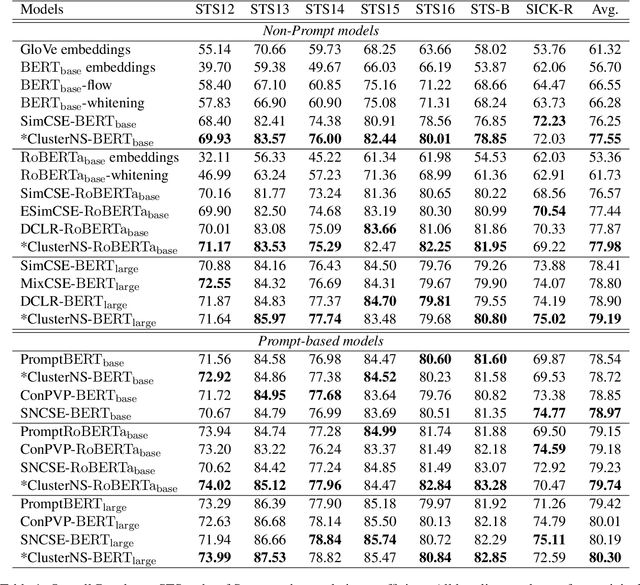
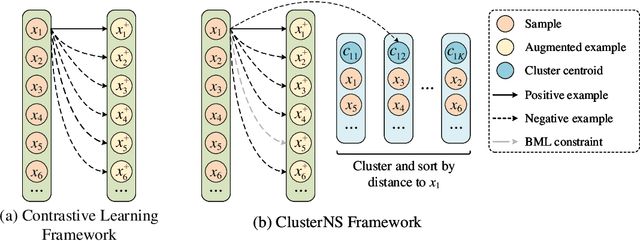
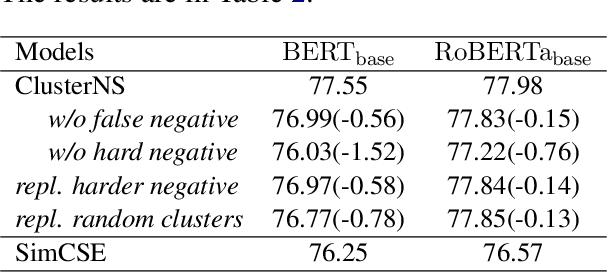
Contrastive learning has been widely studied in sentence representation learning. However, earlier works mainly focus on the construction of positive examples, while in-batch samples are often simply treated as negative examples. This approach overlooks the importance of selecting appropriate negative examples, potentially leading to a scarcity of hard negatives and the inclusion of false negatives. To address these issues, we propose ClusterNS (Clustering-aware Negative Sampling), a novel method that incorporates cluster information into contrastive learning for unsupervised sentence representation learning. We apply a modified K-means clustering algorithm to supply hard negatives and recognize in-batch false negatives during training, aiming to solve the two issues in one unified framework. Experiments on semantic textual similarity (STS) tasks demonstrate that our proposed ClusterNS compares favorably with baselines in unsupervised sentence representation learning. Our code has been made publicly available.
T-SciQ: Teaching Multimodal Chain-of-Thought Reasoning via Large Language Model Signals for Science Question Answering
May 09, 2023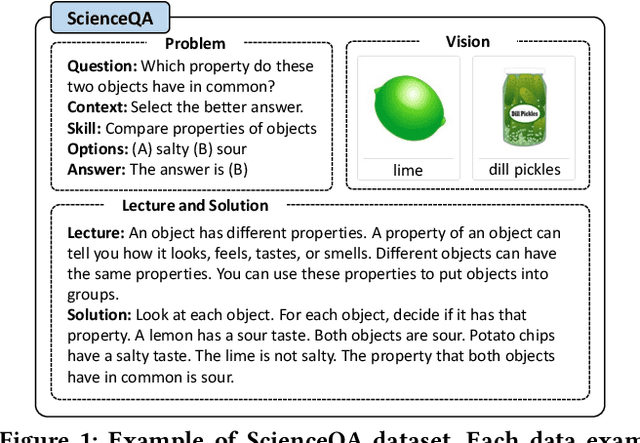
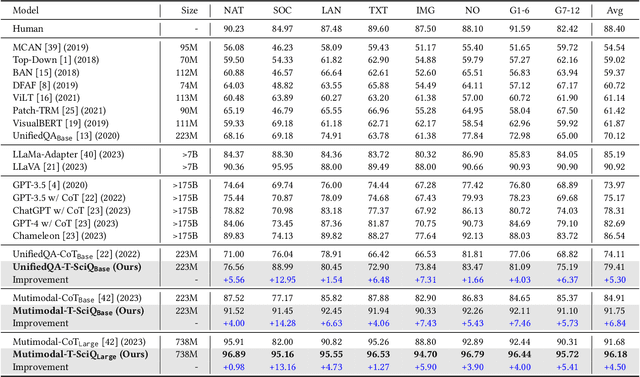
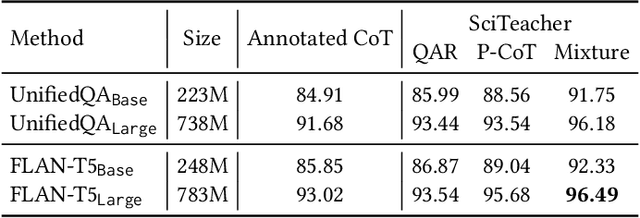
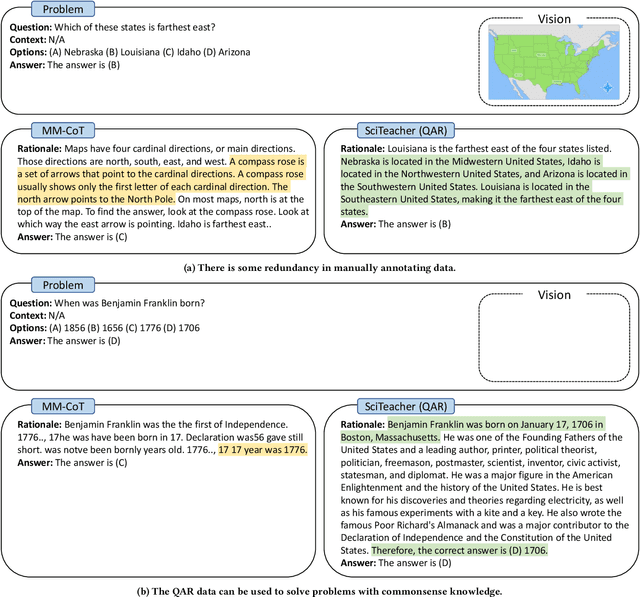
Large Language Models (LLMs) have recently demonstrated exceptional performance in various Natural Language Processing (NLP) tasks. They have also shown the ability to perform chain-of-thought (CoT) reasoning to solve complex problems. Recent studies have explored CoT reasoning in complex multimodal scenarios, such as the science question answering task, by fine-tuning multimodal models with high-quality human-annotated CoT rationales. However, collecting high-quality COT rationales is usually time-consuming and costly. Besides, the annotated rationales are hardly accurate due to the redundant information involved or the essential information missed. To address these issues, we propose a novel method termed \emph{T-SciQ} that aims at teaching science question answering with LLM signals. The T-SciQ approach generates high-quality CoT rationales as teaching signals and is advanced to train much smaller models to perform CoT reasoning in complex modalities. Additionally, we introduce a novel data mixing strategy to produce more effective teaching data samples for simple and complex science question answer problems. Extensive experimental results show that our T-SciQ method achieves a new state-of-the-art performance on the ScienceQA benchmark, with an accuracy of 96.18%. Moreover, our approach outperforms the most powerful fine-tuned baseline by 4.5%.
IR2Net: Information Restriction and Information Recovery for Accurate Binary Neural Networks
Oct 06, 2022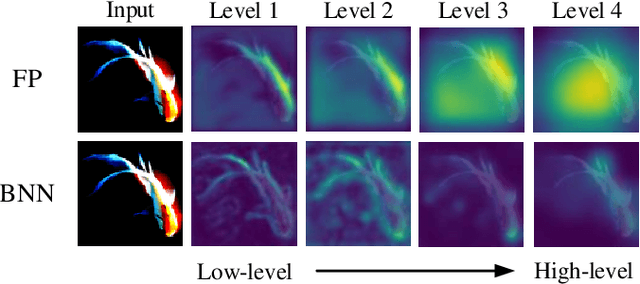
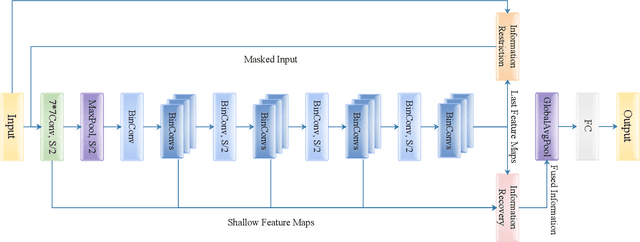
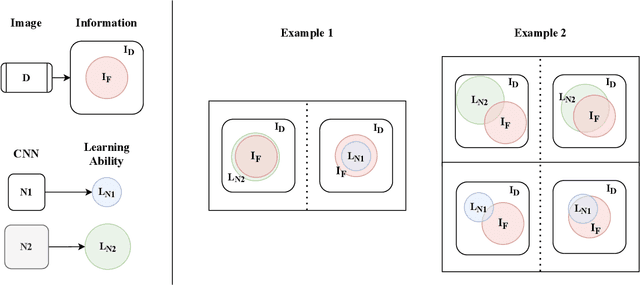
Weight and activation binarization can efficiently compress deep neural networks and accelerate model inference, but cause severe accuracy degradation. Existing optimization methods for binary neural networks (BNNs) focus on fitting full-precision networks to reduce quantization errors, and suffer from the trade-off between accuracy and computational complexity. In contrast, considering the limited learning ability and information loss caused by the limited representational capability of BNNs, we propose IR$^2$Net to stimulate the potential of BNNs and improve the network accuracy by restricting the input information and recovering the feature information, including: 1) information restriction: for a BNN, by evaluating the learning ability on the input information, discarding some of the information it cannot focus on, and limiting the amount of input information to match its learning ability; 2) information recovery: due to the information loss in forward propagation, the output feature information of the network is not enough to support accurate classification. By selecting some shallow feature maps with richer information, and fusing them with the final feature maps to recover the feature information. In addition, the computational cost is reduced by streamlining the information recovery method to strike a better trade-off between accuracy and efficiency. Experimental results demonstrate that our approach still achieves comparable accuracy even with $ \sim $10x floating-point operations (FLOPs) reduction for ResNet-18. The models and code are available at https://github.com/pingxue-hfut/IR2Net.
On the Effectiveness of Equivariant Regularization for Robust Online Continual Learning
May 05, 2023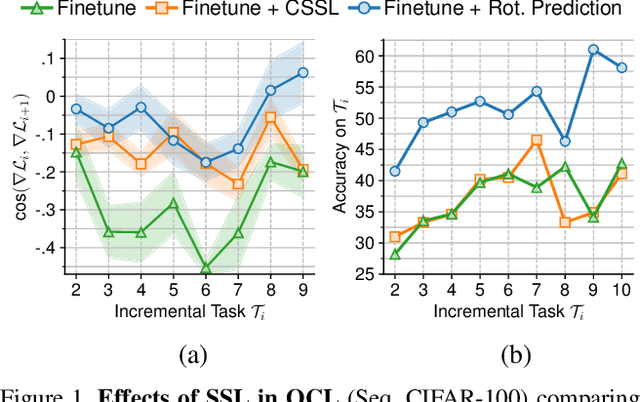
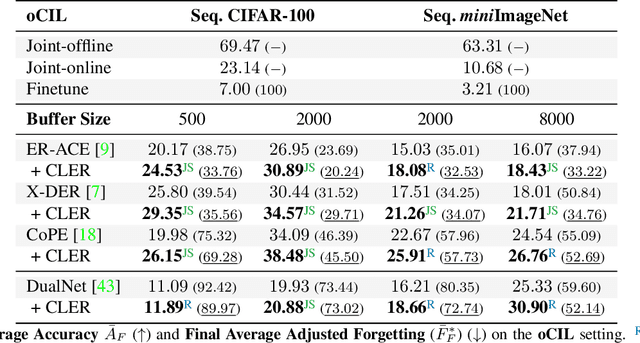
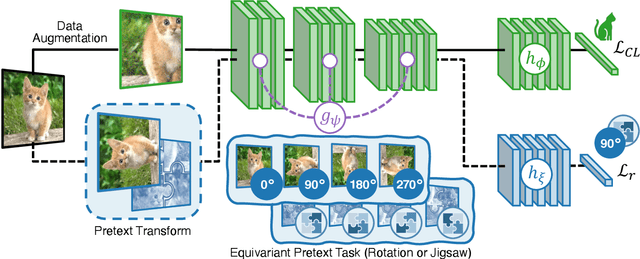
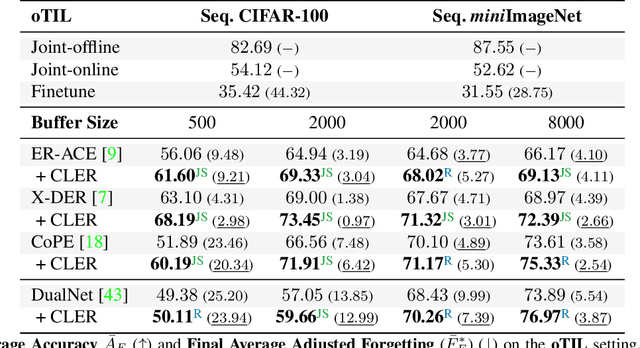
Humans can learn incrementally, whereas neural networks forget previously acquired information catastrophically. Continual Learning (CL) approaches seek to bridge this gap by facilitating the transfer of knowledge to both previous tasks (backward transfer) and future ones (forward transfer) during training. Recent research has shown that self-supervision can produce versatile models that can generalize well to diverse downstream tasks. However, contrastive self-supervised learning (CSSL), a popular self-supervision technique, has limited effectiveness in online CL (OCL). OCL only permits one iteration of the input dataset, and CSSL's low sample efficiency hinders its use on the input data-stream. In this work, we propose Continual Learning via Equivariant Regularization (CLER), an OCL approach that leverages equivariant tasks for self-supervision, avoiding CSSL's limitations. Our method represents the first attempt at combining equivariant knowledge with CL and can be easily integrated with existing OCL methods. Extensive ablations shed light on how equivariant pretext tasks affect the network's information flow and its impact on CL dynamics.
TransESC: Smoothing Emotional Support Conversation via Turn-Level State Transition
May 05, 2023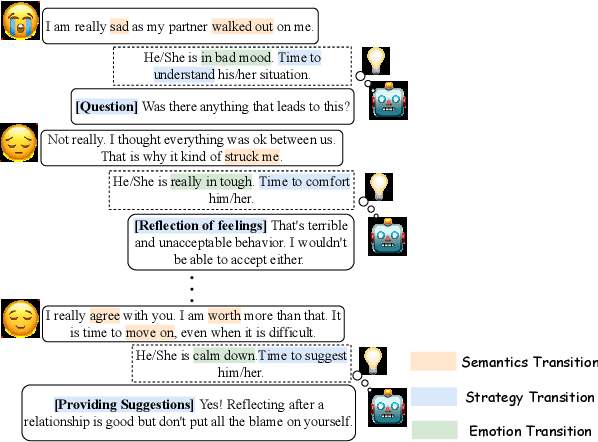
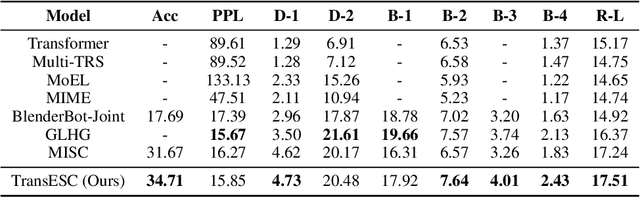
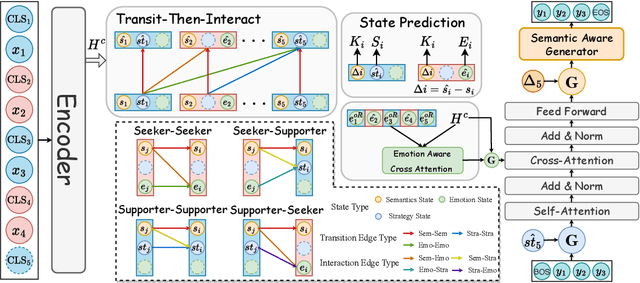
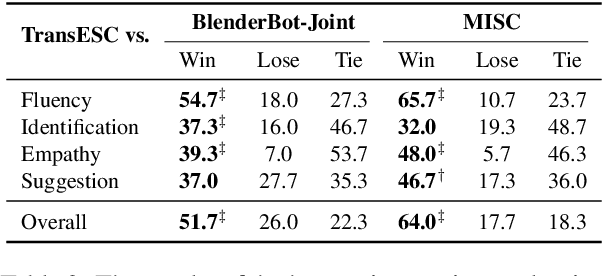
Emotion Support Conversation (ESC) is an emerging and challenging task with the goal of reducing the emotional distress of people. Previous attempts fail to maintain smooth transitions between utterances in ESC because they ignore to grasp the fine-grained transition information at each dialogue turn. To solve this problem, we propose to take into account turn-level state \textbf{Trans}itions of \textbf{ESC} (\textbf{TransESC}) from three perspectives, including semantics transition, strategy transition and emotion transition, to drive the conversation in a smooth and natural way. Specifically, we construct the state transition graph with a two-step way, named transit-then-interact, to grasp such three types of turn-level transition information. Finally, they are injected into the transition-aware decoder to generate more engaging responses. Both automatic and human evaluations on the benchmark dataset demonstrate the superiority of TransESC to generate more smooth and effective supportive responses. Our source code is available at \url{https://github.com/circle-hit/TransESC}.
Matrix Approximation with Side Information: When Column Sampling is Enough
Dec 11, 2022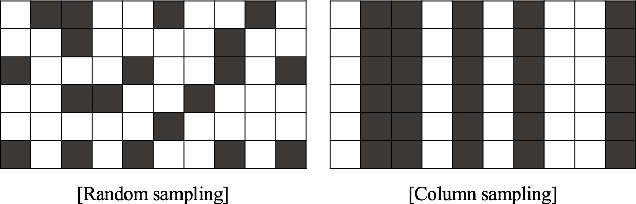
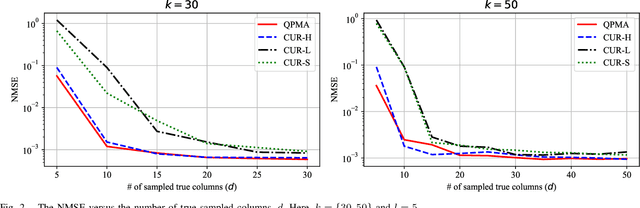
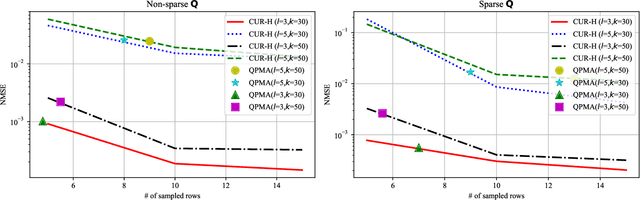
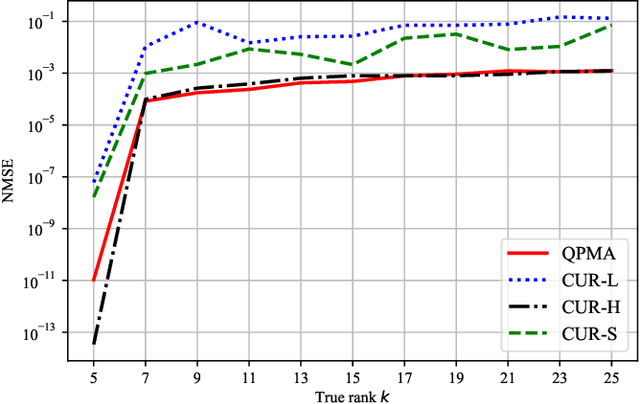
A novel matrix approximation problem is considered herein: observations based on a few fully sampled columns and quasi-polynomial structural side information are exploited. The framework is motivated by quantum chemistry problems wherein full matrix computation is expensive, and partial computations only lead to column information. The proposed algorithm successfully estimates the column and row-space of a true matrix given a priori structural knowledge of the true matrix. A theoretical spectral error bound is provided, which captures the possible inaccuracies of the side information. The error bound proves it scales in its signal-to-noise (SNR) ratio. The proposed algorithm is validated via simulations which enable the characterization of the amount of information provided by the quasi-polynomial side information.