 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Locate and Beamform: Two-dimensional Locating All-neural Beamformer for Multi-channel Speech Separation
May 18, 2023

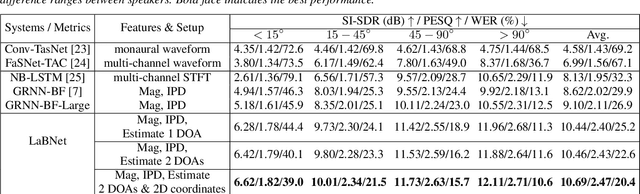
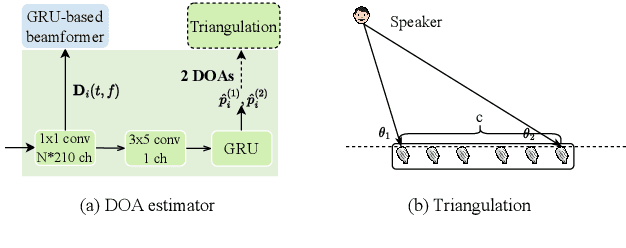
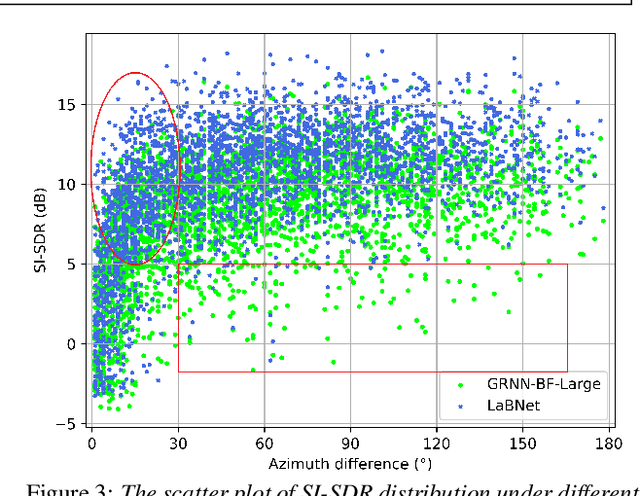
Recently, stunning improvements on multi-channel speech separation have been achieved by neural beamformers when direction information is available. However, most of them neglect to utilize speaker's 2-dimensional (2D) location cues contained in mixture signal, which limits the performance when two sources come from close directions. In this paper, we propose an end-to-end beamforming network for 2D location guided speech separation merely given mixture signal. It first estimates discriminable direction and 2D location cues, which imply directions the sources come from in multi views of microphones and their 2D coordinates. These cues are then integrated into location-aware neural beamformer, thus allowing accurate reconstruction of two sources' speech signals. Experiments show that our proposed model not only achieves a comprehensive decent improvement compared to baseline systems, but avoids inferior performance on spatial overlapping cases.
Information-Based Sensor Placement for Data-Driven Estimation of Unsteady Flows
Mar 22, 2023Estimation of unsteady flow fields around flight vehicles may improve flow interactions and lead to enhanced vehicle performance. Although flow-field representations can be very high-dimensional, their dynamics can have low-order representations and may be estimated using a few, appropriately placed measurements. This paper presents a sensor-selection framework for the intended application of data-driven, flow-field estimation. This framework combines data-driven modeling, steady-state Kalman Filter design, and a sparsification technique for sequential selection of sensors. This paper also uses the sensor selection framework to design sensor arrays that can perform well across a variety of operating conditions. Flow estimation results on numerical data show that the proposed framework produces arrays that are highly effective at flow-field estimation for the flow behind and an airfoil at a high angle of attack using embedded pressure sensors. Analysis of the flow fields reveals that paths of impinging stagnation points along the airfoil's surface during a shedding period of the flow are highly informative locations for placement of pressure sensors.
Privileged Prior Information Distillation for Image Matting
Nov 25, 2022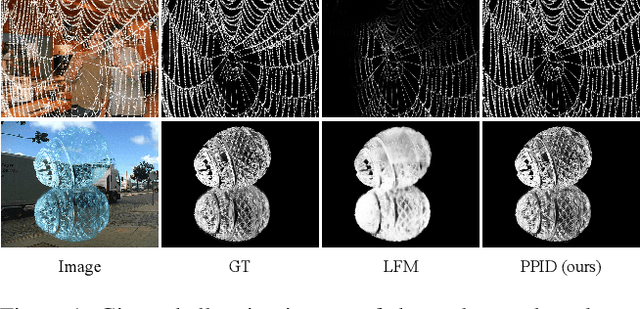
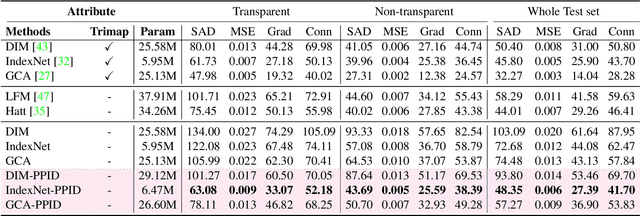
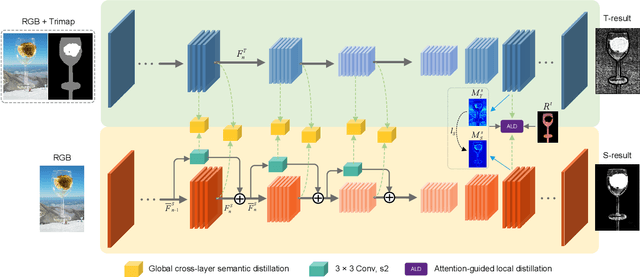
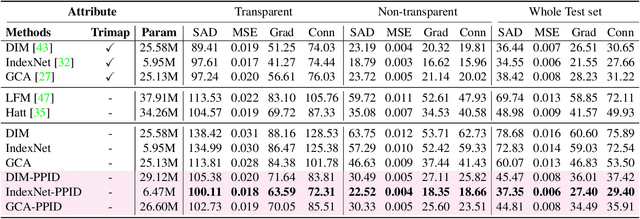
Performance of trimap-free image matting methods is limited when trying to decouple the deterministic and undetermined regions, especially in the scenes where foregrounds are semantically ambiguous, chromaless, or high transmittance. In this paper, we propose a novel framework named Privileged Prior Information Distillation for Image Matting (PPID-IM) that can effectively transfer privileged prior environment-aware information to improve the performance of students in solving hard foregrounds. The prior information of trimap regulates only the teacher model during the training stage, while not being fed into the student network during actual inference. In order to achieve effective privileged cross-modality (i.e. trimap and RGB) information distillation, we introduce a Cross-Level Semantic Distillation (CLSD) module that reinforces the trimap-free students with more knowledgeable semantic representations and environment-aware information. We also propose an Attention-Guided Local Distillation module that efficiently transfers privileged local attributes from the trimap-based teacher to trimap-free students for the guidance of local-region optimization. Extensive experiments demonstrate the effectiveness and superiority of our PPID framework on the task of image matting. In addition, our trimap-free IndexNet-PPID surpasses the other competing state-of-the-art methods by a large margin, especially in scenarios with chromaless, weak texture, or irregular objects.
Low Complexity Detection of Spatial Modulation Aided OTFS in Doubly-Selective Channels
May 17, 2023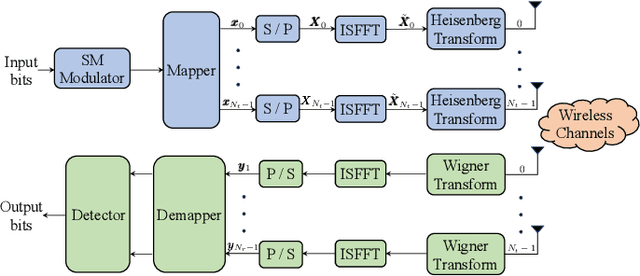
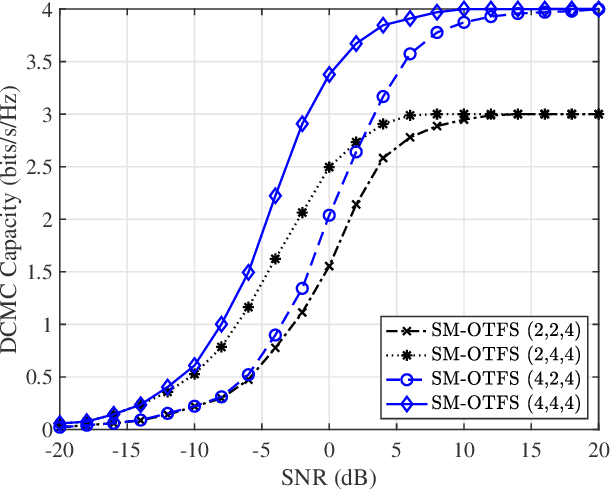
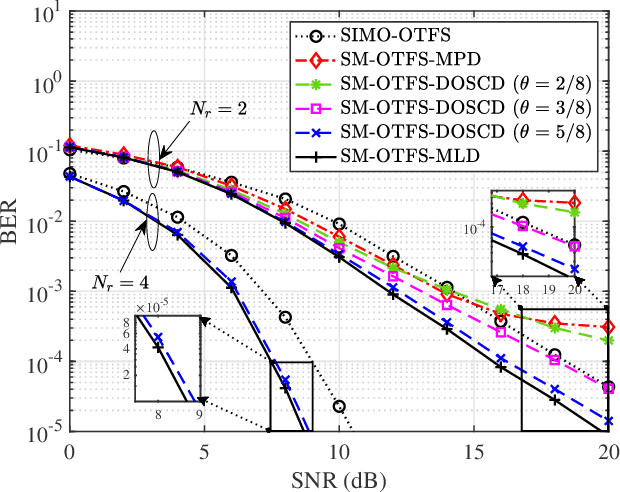
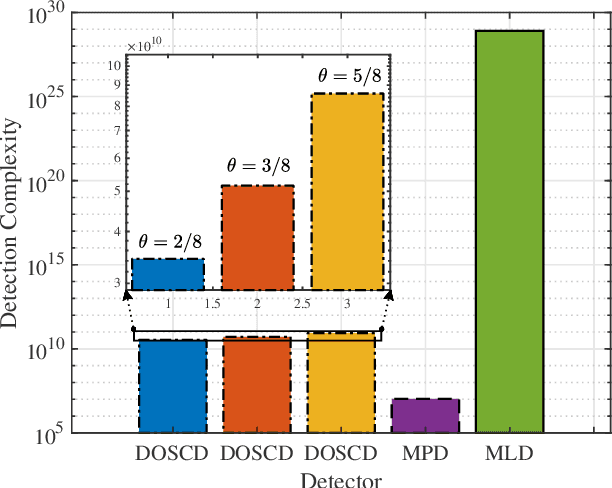
A spatial modulation-aided orthogonal time frequency space (SM-OTFS) scheme is proposed for high-Doppler scenarios, which relies on a low-complexity distance-based detection algorithm. We first derive the delay-Doppler (DD) domain input-output relationship of our SM-OTFS system by exploiting an SM mapper, followed by characterizing the doubly-selective channels considered. Then we propose a distance-based ordering subspace check detector (DOSCD) exploiting the \emph{a priori} information of the transmit symbol vector. Moreover, we derive the discrete-input continuous-output memoryless channel (DCMC) capacity of the system. Finally, our simulation results demonstrate that the proposed SM-OTFS system outperforms the conventional single-input-multiple-output (SIMO)-OTFS system, and that the DOSCD conceived is capable of striking an attractive bit error ratio (BER) vs. complexity trade-off.
RelationMatch: Matching In-batch Relationships for Semi-supervised Learning
May 17, 2023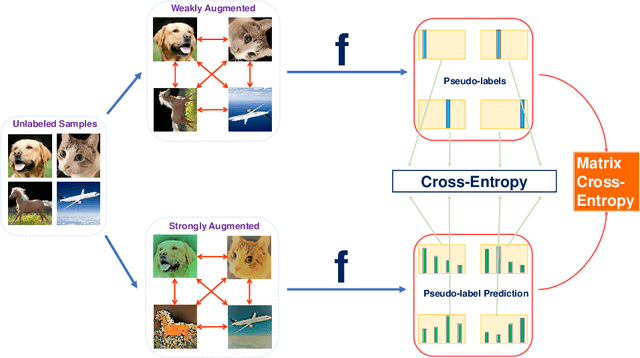

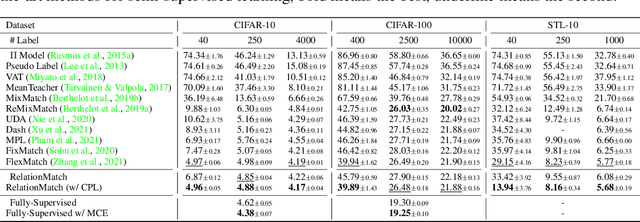
Semi-supervised learning has achieved notable success by leveraging very few labeled data and exploiting the wealth of information derived from unlabeled data. However, existing algorithms usually focus on aligning predictions on paired data points augmented from an identical source, and overlook the inter-point relationships within each batch. This paper introduces a novel method, RelationMatch, which exploits in-batch relationships with a matrix cross-entropy (MCE) loss function. Through the application of MCE, our proposed method consistently surpasses the performance of established state-of-the-art methods, such as FixMatch and FlexMatch, across a variety of vision datasets. Notably, we observed a substantial enhancement of 15.21% in accuracy over FlexMatch on the STL-10 dataset using only 40 labels. Moreover, we apply MCE to supervised learning scenarios, and observe consistent improvements as well.
FlowText: Synthesizing Realistic Scene Text Video with Optical Flow Estimation
May 05, 2023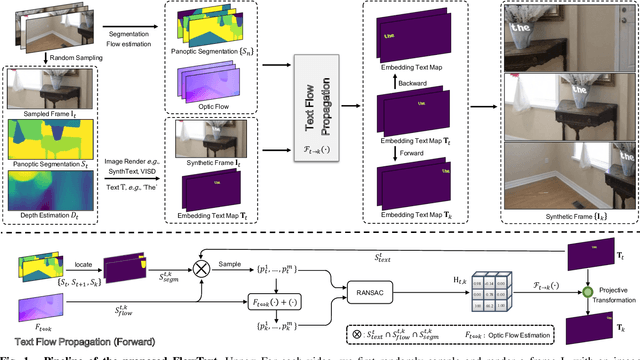
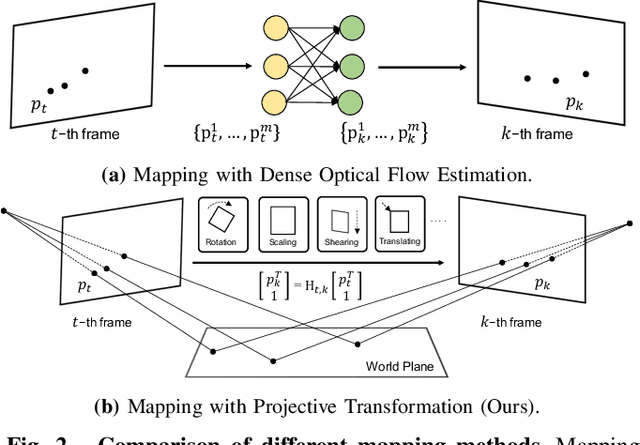

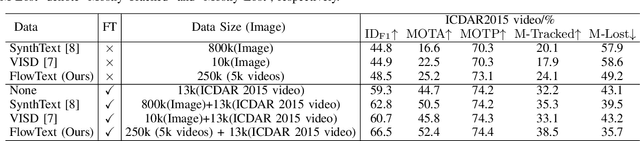
Current video text spotting methods can achieve preferable performance, powered with sufficient labeled training data. However, labeling data manually is time-consuming and labor-intensive. To overcome this, using low-cost synthetic data is a promising alternative. This paper introduces a novel video text synthesis technique called FlowText, which utilizes optical flow estimation to synthesize a large amount of text video data at a low cost for training robust video text spotters. Unlike existing methods that focus on image-level synthesis, FlowText concentrates on synthesizing temporal information of text instances across consecutive frames using optical flow. This temporal information is crucial for accurately tracking and spotting text in video sequences, including text movement, distortion, appearance, disappearance, shelter, and blur. Experiments show that combining general detectors like TransDETR with the proposed FlowText produces remarkable results on various datasets, such as ICDAR2015video and ICDAR2013video. Code is available at https://github.com/callsys/FlowText.
FedNC: A Secure and Efficient Federated Learning Method Inspired by Network Coding
May 05, 2023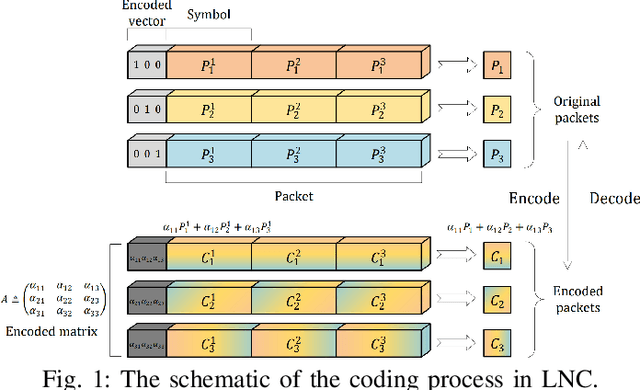
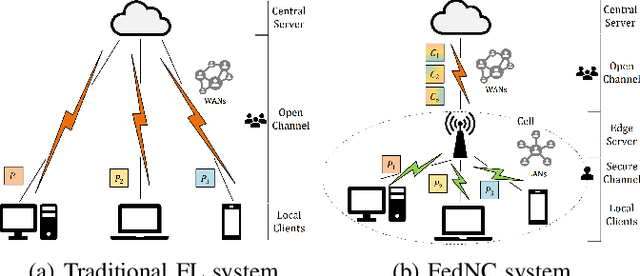
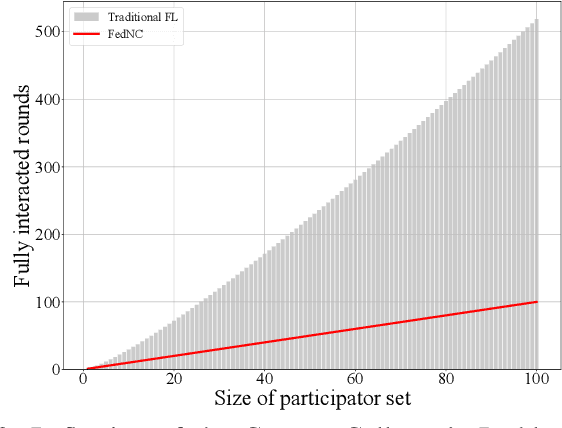
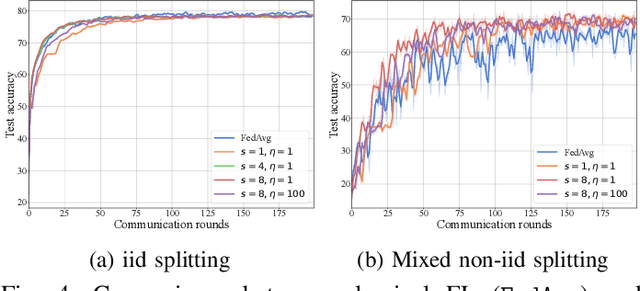
Federated Learning (FL) is a promising distributed learning mechanism which still faces two major challenges, namely privacy breaches and system efficiency. In this work, we reconceptualize the FL system from the perspective of network information theory, and formulate an original FL communication framework, FedNC, which is inspired by Network Coding (NC). The main idea of FedNC is mixing the information of the local models by making random linear combinations of the original packets, before uploading for further aggregation. Due to the benefits of the coding scheme, both theoretical and experimental analysis indicate that FedNC improves the performance of traditional FL in several important ways, including security, throughput, and robustness. To the best of our knowledge, this is the first framework where NC is introduced in FL. As FL continues to evolve within practical network frameworks, more applications and variants can be further designed based on FedNC.
Predicting COVID-19 pandemic by spatio-temporal graph neural networks: A New Zealand's study
May 12, 2023
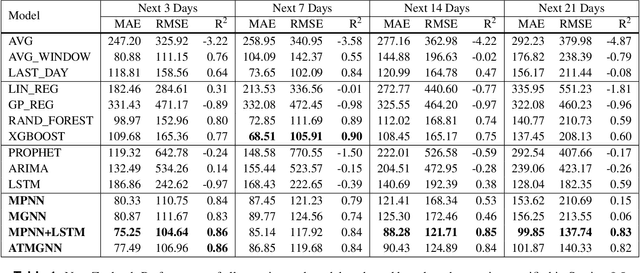
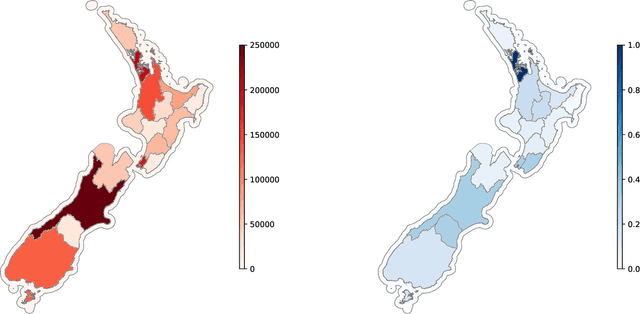
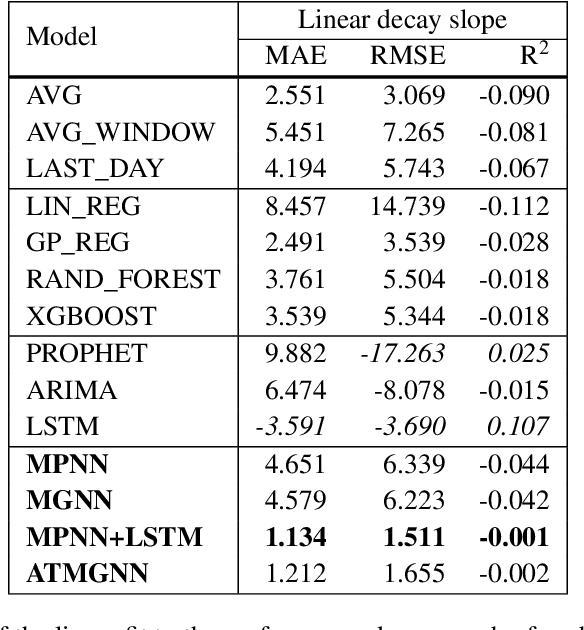
Modeling and simulations of pandemic dynamics play an essential role in understanding and addressing the spreading of highly infectious diseases such as COVID-19. In this work, we propose a novel deep learning architecture named Attention-based Multiresolution Graph Neural Networks (ATMGNN) that learns to combine the spatial graph information, i.e. geographical data, with the temporal information, i.e. timeseries data of number of COVID-19 cases, to predict the future dynamics of the pandemic. The key innovation is that our method can capture the multiscale structures of the spatial graph via a learning to cluster algorithm in a data-driven manner. This allows our architecture to learn to pick up either local or global signals of a pandemic, and model both the long-range spatial and temporal dependencies. Importantly, we collected and assembled a new dataset for New Zealand. We established a comprehensive benchmark of statistical methods, temporal architectures, graph neural networks along with our spatio-temporal model. We also incorporated socioeconomic cross-sectional data to further enhance our prediction. Our proposed model have shown highly robust predictions and outperformed all other baselines in various metrics for our new dataset of New Zealand along with existing datasets of England, France, Italy and Spain. For a future work, we plan to extend our work for real-time prediction and global scale. Our data and source code are publicly available at https://github.com/HySonLab/pandemic_tgnn
Assessment of few-hits machine learning classification algorithms for low energy physics in liquid argon detectors
May 16, 2023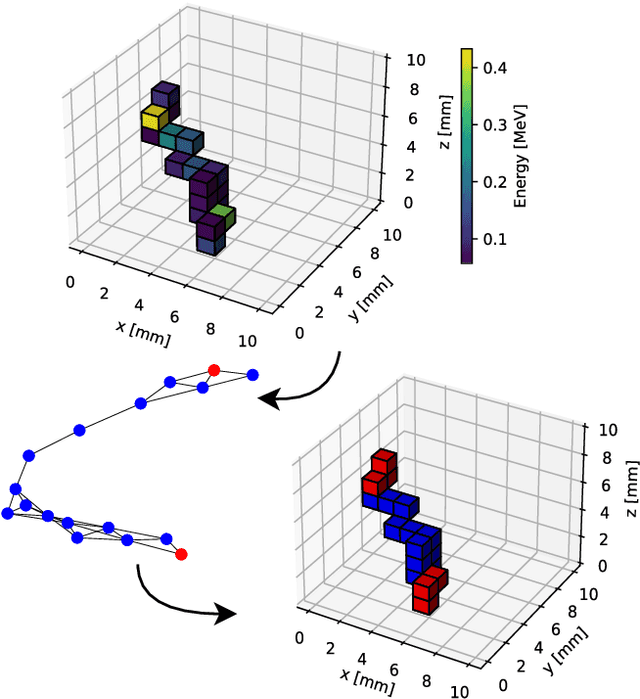
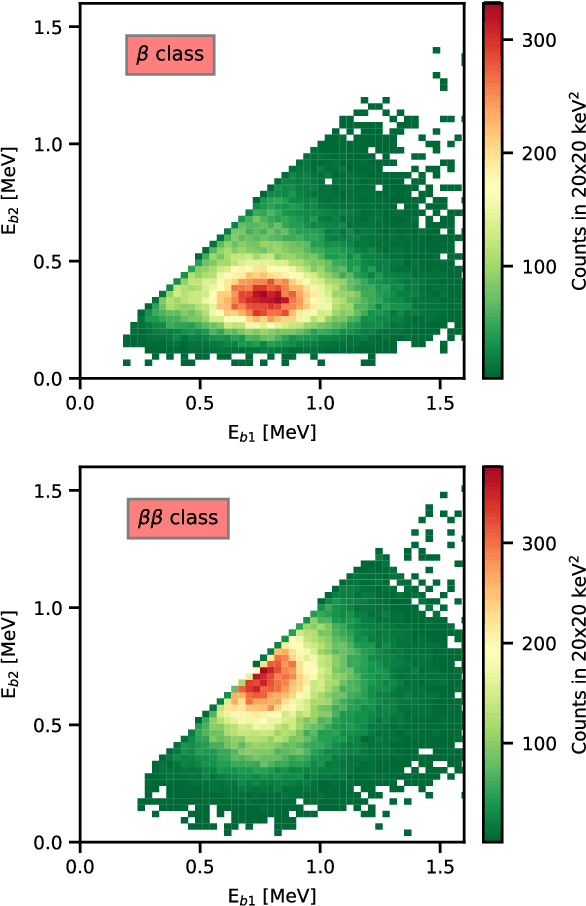
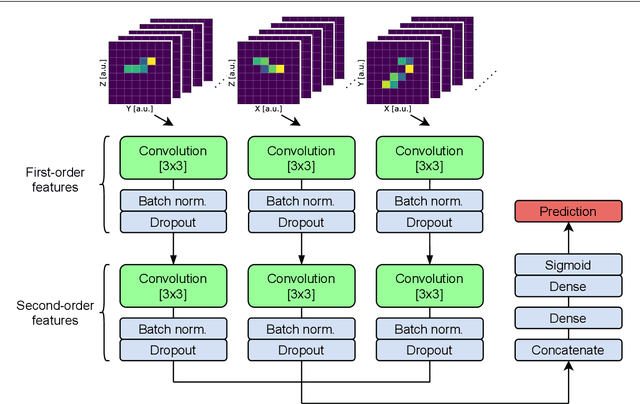
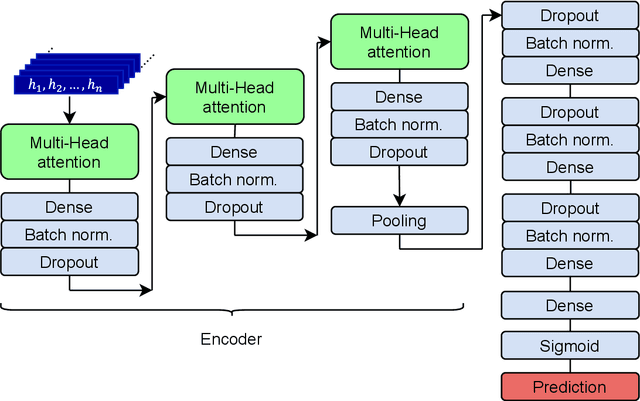
The physics potential of massive liquid argon TPCs in the low-energy regime is still to be fully reaped because few-hits events encode information that can hardly be exploited by conventional classification algorithms. Machine learning (ML) techniques give their best in these types of classification problems. In this paper, we evaluate their performance against conventional (deterministic) algorithms. We demonstrate that both Convolutional Neural Networks (CNN) and Transformer-Encoder methods outperform deterministic algorithms in one of the most challenging classification problems of low-energy physics (single- versus double-beta events). We discuss the advantages and pitfalls of Transformer-Encoder methods versus CNN and employ these methods to optimize the detector parameters, with an emphasis on the DUNE Phase II detectors ("Module of Opportunity").
Vehicle Detection and Classification without Residual Calculation: Accelerating HEVC Image Decoding with Random Perturbation Injection
May 14, 2023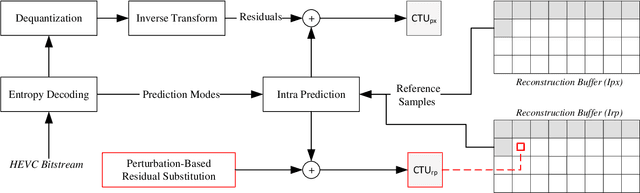


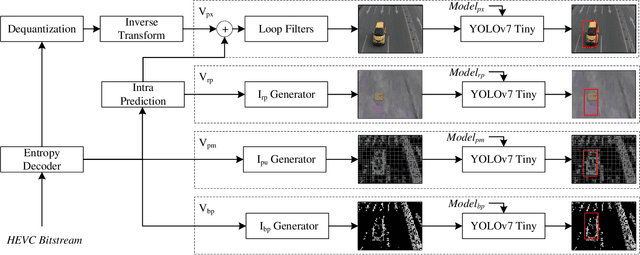
In the field of video analytics, particularly traffic surveillance, there is a growing need for efficient and effective methods for processing and understanding video data. Traditional full video decoding techniques can be computationally intensive and time-consuming, leading researchers to explore alternative approaches in the compressed domain. This study introduces a novel random perturbation-based compressed domain method for reconstructing images from High Efficiency Video Coding (HEVC) bitstreams, specifically designed for traffic surveillance applications. To the best of our knowledge, our method is the first to propose substituting random perturbations for residual values, creating a condensed representation of the original image while retaining information relevant to video understanding tasks, particularly focusing on vehicle detection and classification as key use cases. By not using residual data, our proposed method significantly reduces the data needed in the image reconstruction process, allowing for more efficient storage and transmission of information. This is particularly important when considering the vast amount of video data involved in surveillance applications. Applied to the public BIT-Vehicle dataset, we demonstrate a significant increase in the reconstruction speed compared to the traditional full decoding approach, with our proposed method being approximately 56% faster than the pixel domain method. Additionally, we achieve a detection accuracy of 99.9%, on par with the pixel domain method, and a classification accuracy of 96.84%, only 0.98% lower than the pixel domain method. Furthermore, we showcase the significant reduction in data size, leading to more efficient storage and transmission. Our research establishes the potential of compressed domain methods in traffic surveillance applications, where speed and data size are critical factors.