 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Versatile and Efficient Visual Knowledge Injection into Pre-trained Language Models with Cross-Modal Adapters
May 12, 2023
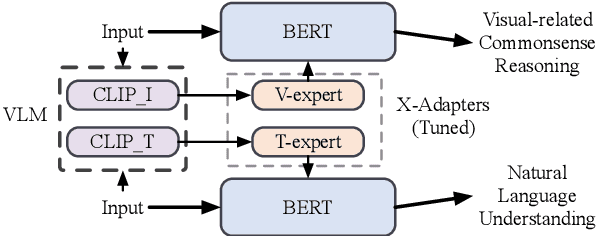
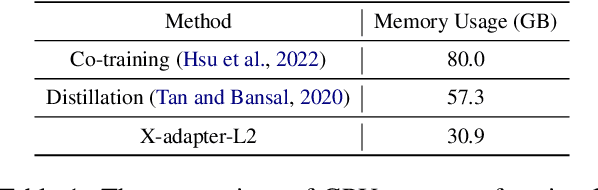
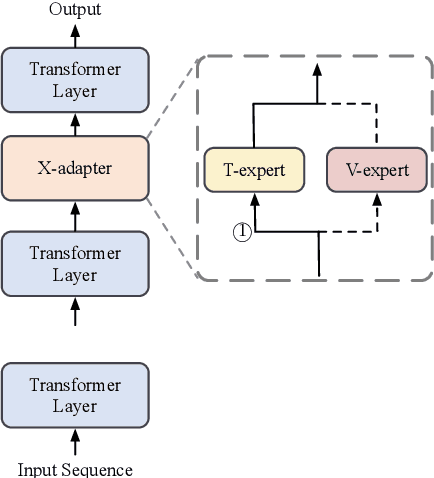

Humans learn language via multi-modal knowledge. However, due to the text-only pre-training scheme, most existing pre-trained language models (PLMs) are hindered from the multi-modal information. To inject visual knowledge into PLMs, existing methods incorporate either the text or image encoder of vision-language models (VLMs) to encode the visual information and update all the original parameters of PLMs for knowledge fusion. In this paper, we propose a new plug-and-play module, X-adapter, to flexibly leverage the aligned visual and textual knowledge learned in pre-trained VLMs and efficiently inject them into PLMs. Specifically, we insert X-adapters into PLMs, and only the added parameters are updated during adaptation. To fully exploit the potential in VLMs, X-adapters consist of two sub-modules, V-expert and T-expert, to fuse VLMs' image and text representations, respectively. We can opt for activating different sub-modules depending on the downstream tasks. Experimental results show that our method can significantly improve the performance on object-color reasoning and natural language understanding (NLU) tasks compared with PLM baselines.
Unlocking the Potential of Medical Imaging with ChatGPT's Intelligent Diagnostics
May 12, 2023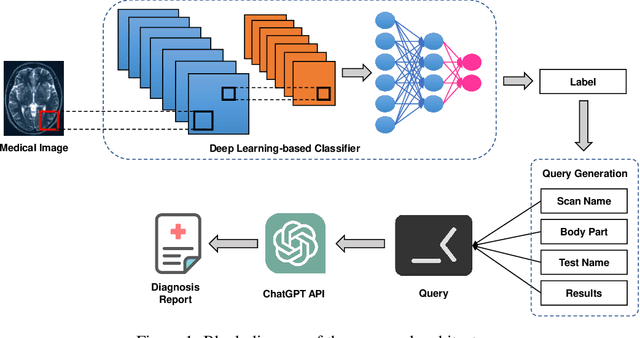
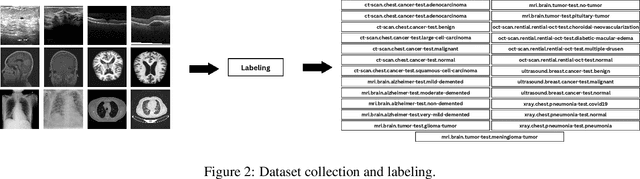
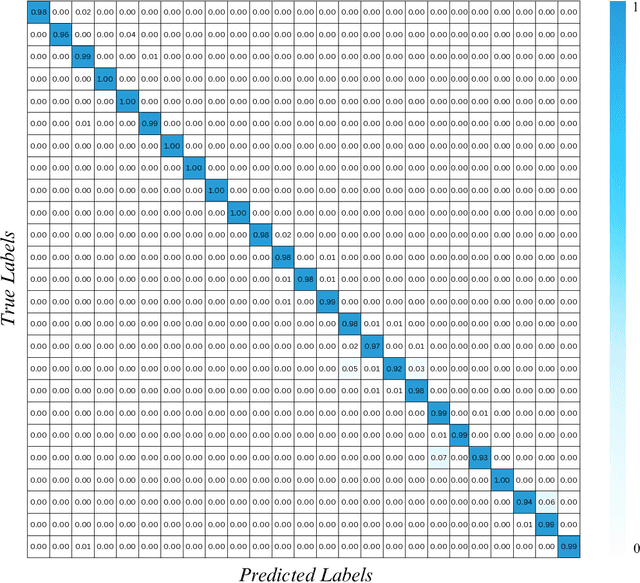
Medical imaging is an essential tool for diagnosing various healthcare diseases and conditions. However, analyzing medical images is a complex and time-consuming task that requires expertise and experience. This article aims to design a decision support system to assist healthcare providers and patients in making decisions about diagnosing, treating, and managing health conditions. The proposed architecture contains three stages: 1) data collection and labeling, 2) model training, and 3) diagnosis report generation. The key idea is to train a deep learning model on a medical image dataset to extract four types of information: the type of image scan, the body part, the test image, and the results. This information is then fed into ChatGPT to generate automatic diagnostics. The proposed system has the potential to enhance decision-making, reduce costs, and improve the capabilities of healthcare providers. The efficacy of the proposed system is analyzed by conducting extensive experiments on a large medical image dataset. The experimental outcomes exhibited promising performance for automatic diagnosis through medical images.
Knowledge Refinement via Interaction Between Search Engines and Large Language Models
May 12, 2023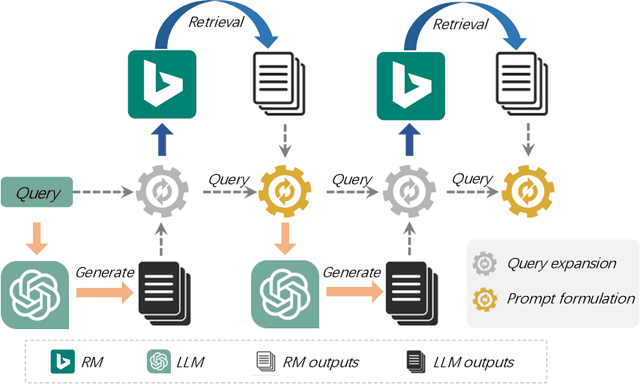
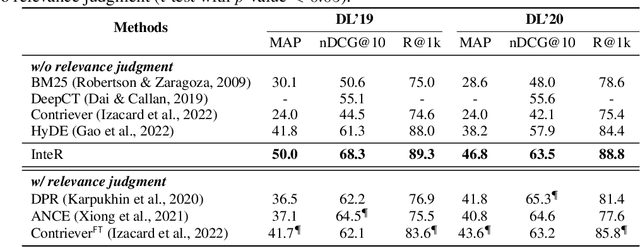
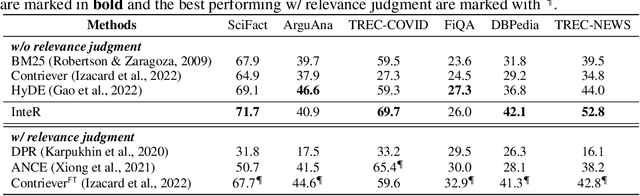
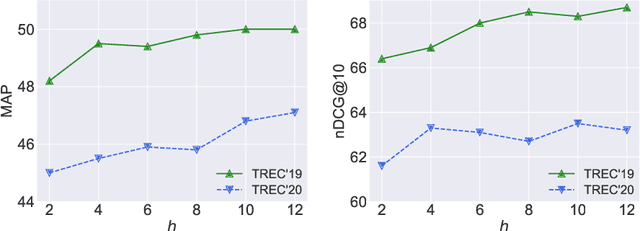
Information retrieval (IR) plays a crucial role in locating relevant resources from vast amounts of data, and its applications have evolved from traditional knowledge bases to modern search engines (SEs). The emergence of large language models (LLMs) has further revolutionized the field by enabling users to interact with search systems in natural language. In this paper, we explore the advantages and disadvantages of LLMs and SEs, highlighting their respective strengths in understanding user-issued queries and retrieving up-to-date information. To leverage the benefits of both paradigms while circumventing their limitations, we propose InteR, a novel framework that facilitates knowledge refinement through interaction between SEs and LLMs. InteR allows SEs to refine knowledge in query using LLM-generated summaries and enables LLMs to enhance prompts using SE-retrieved documents. This iterative refinement process augments the inputs of SEs and LLMs, leading to more accurate retrieval. Experimental evaluations on two large-scale retrieval benchmarks demonstrate that InteR achieves superior zero-shot document retrieval performance compared to state-of-the-art methods, regardless of the use of relevance judgement.
Explicit Feature Interaction-aware Uplift Network for Online Marketing
Jun 01, 2023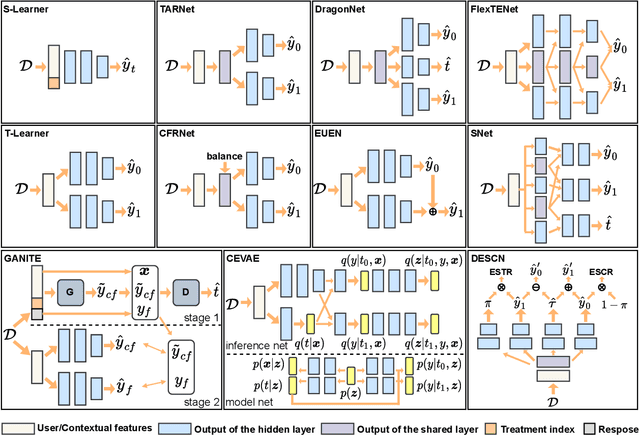
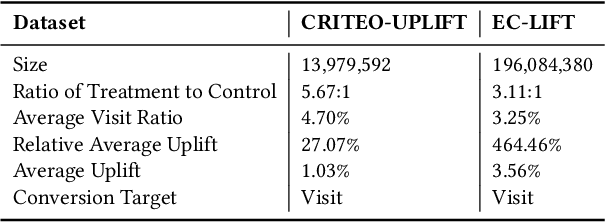
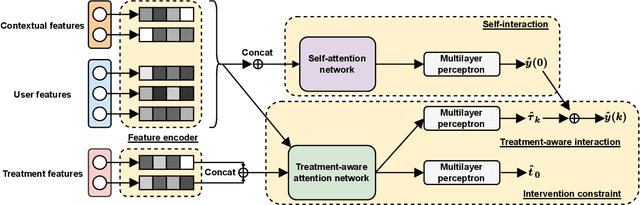
As a key component in online marketing, uplift modeling aims to accurately capture the degree to which different treatments motivate different users, such as coupons or discounts, also known as the estimation of individual treatment effect (ITE). In an actual business scenario, the options for treatment may be numerous and complex, and there may be correlations between different treatments. In addition, each marketing instance may also have rich user and contextual features. However, existing methods still fall short in both fully exploiting treatment information and mining features that are sensitive to a particular treatment. In this paper, we propose an explicit feature interaction-aware uplift network (EFIN) to address these two problems. Our EFIN includes four customized modules: 1) a feature encoding module encodes not only the user and contextual features, but also the treatment features; 2) a self-interaction module aims to accurately model the user's natural response with all but the treatment features; 3) a treatment-aware interaction module accurately models the degree to which a particular treatment motivates a user through interactions between the treatment features and other features, i.e., ITE; and 4) an intervention constraint module is used to balance the ITE distribution of users between the control and treatment groups so that the model would still achieve a accurate uplift ranking on data collected from a non-random intervention marketing scenario. We conduct extensive experiments on two public datasets and one product dataset to verify the effectiveness of our EFIN. In addition, our EFIN has been deployed in a credit card bill payment scenario of a large online financial platform with a significant improvement.
Reverse Engineering Self-Supervised Learning
May 24, 2023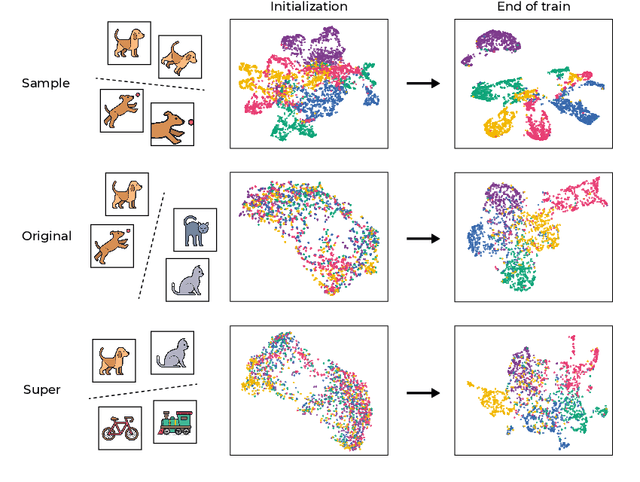
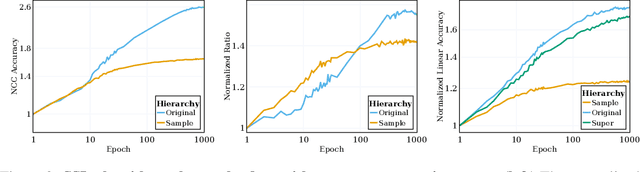
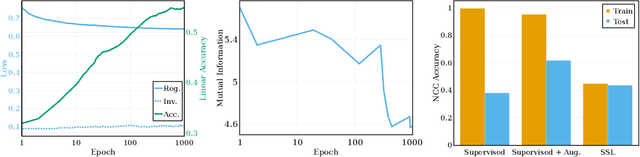
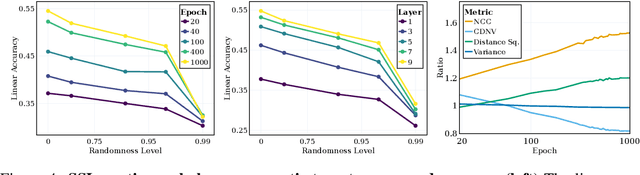
Self-supervised learning (SSL) is a powerful tool in machine learning, but understanding the learned representations and their underlying mechanisms remains a challenge. This paper presents an in-depth empirical analysis of SSL-trained representations, encompassing diverse models, architectures, and hyperparameters. Our study reveals an intriguing aspect of the SSL training process: it inherently facilitates the clustering of samples with respect to semantic labels, which is surprisingly driven by the SSL objective's regularization term. This clustering process not only enhances downstream classification but also compresses the data information. Furthermore, we establish that SSL-trained representations align more closely with semantic classes rather than random classes. Remarkably, we show that learned representations align with semantic classes across various hierarchical levels, and this alignment increases during training and when moving deeper into the network. Our findings provide valuable insights into SSL's representation learning mechanisms and their impact on performance across different sets of classes.
Optical Integrated Sensing and Communication
May 24, 2023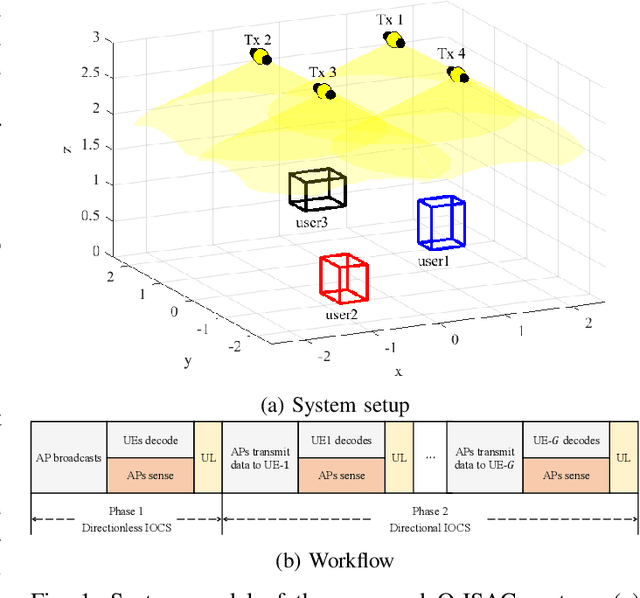
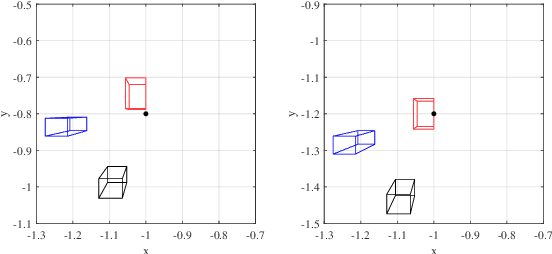
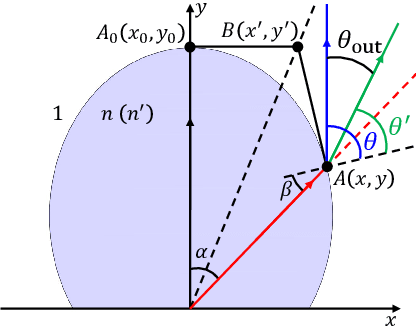
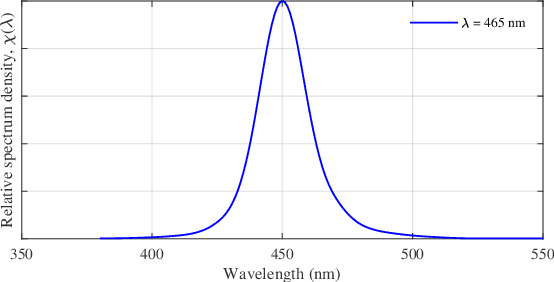
This paper explores a new paradigm of optical integrated sensing and communication (O-ISAC). Our investigation reveals that optical communication and optical sensing are two inherently complementary technologies. On the one hand, optical communication provides the necessary illumination for optical sensing. On the other hand, optical sensing provides environmental information for optical communication. These insights form the foundation of a directionless integrated system, which constitutes the first phase of O-ISAC. We further put forth the concept of optical beamforming using the collimating lens, whereby the light emitted by optical sources is concentrated onto the target device. This greatly improves communication rate and sensing accuracy, thanks to remarkably increased light intensity. Simulation results confirm the significant performance gains of our O-ISAC system over a separated sensing and communication system. With the collimating lens, the light intensity arrived at the target object is increased from 1.09% to 78.06%. The sensing accuracy and communication BER are improved by 62.06dB and 65.52dB, respectively.
Sparse4D v2: Recurrent Temporal Fusion with Sparse Model
May 24, 2023
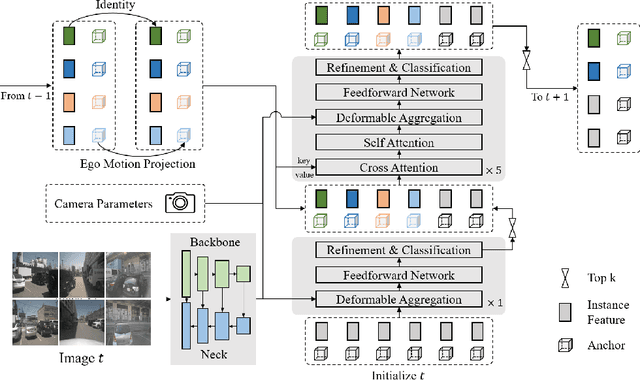
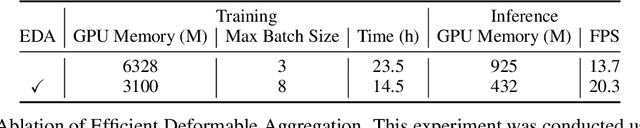

Sparse algorithms offer great flexibility for multi-view temporal perception tasks. In this paper, we present an enhanced version of Sparse4D, in which we improve the temporal fusion module by implementing a recursive form of multi-frame feature sampling. By effectively decoupling image features and structured anchor features, Sparse4D enables a highly efficient transformation of temporal features, thereby facilitating temporal fusion solely through the frame-by-frame transmission of sparse features. The recurrent temporal fusion approach provides two main benefits. Firstly, it reduces the computational complexity of temporal fusion from $O(T)$ to $O(1)$, resulting in significant improvements in inference speed and memory usage. Secondly, it enables the fusion of long-term information, leading to more pronounced performance improvements due to temporal fusion. Our proposed approach, Sparse4Dv2, further enhances the performance of the sparse perception algorithm and achieves state-of-the-art results on the nuScenes 3D detection benchmark. Code will be available at \url{https://github.com/linxuewu/Sparse4D}.
Robust Imaging Sonar-based Place Recognition and Localization in Underwater Environments
May 24, 2023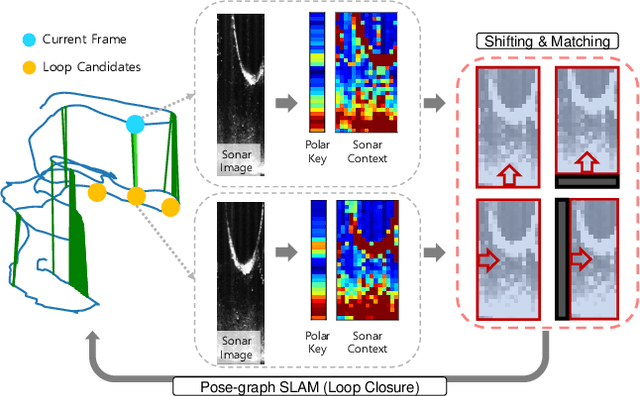

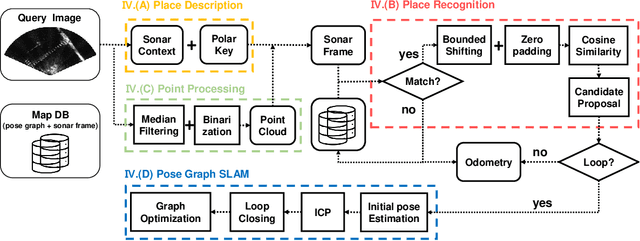
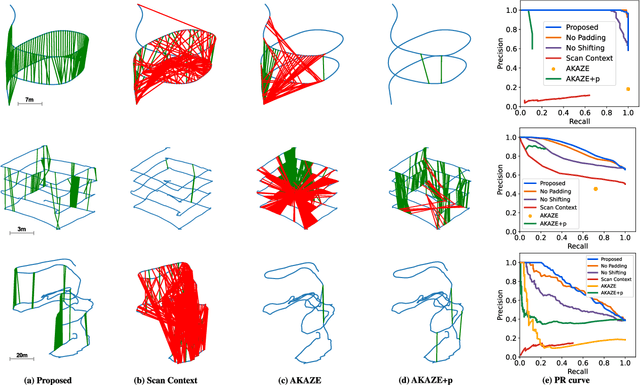
Place recognition using SOund Navigation and Ranging (SONAR) images is an important task for simultaneous localization and mapping(SLAM) in underwater environments. This paper proposes a robust and efficient imaging SONAR based place recognition, SONAR context, and loop closure method. Unlike previous methods, our approach encodes geometric information based on the characteristics of raw SONAR measurements without prior knowledge or training. We also design a hierarchical searching procedure for fast retrieval of candidate SONAR frames and apply adaptive shifting and padding to achieve robust matching on rotation and translation changes. In addition, we can derive the initial pose through adaptive shifting and apply it to the iterative closest point (ICP) based loop closure factor. We evaluate the performance of SONAR context in the various underwater sequences such as simulated open water, real water tank, and real underwater environments. The proposed approach shows the robustness and improvements of place recognition on various datasets and evaluation metrics. Supplementary materials are available at https://github.com/sparolab/sonar_context.git.
STAR: Boosting Low-Resource Event Extraction by Structure-to-Text Data Generation with Large Language Models
May 24, 2023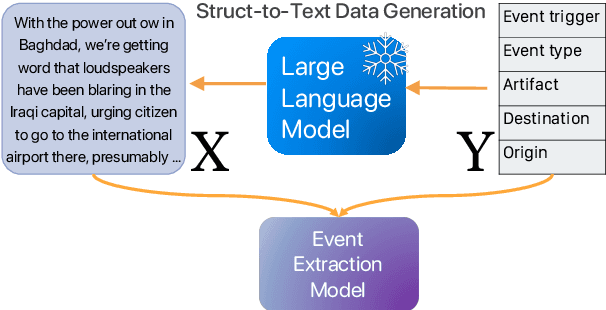
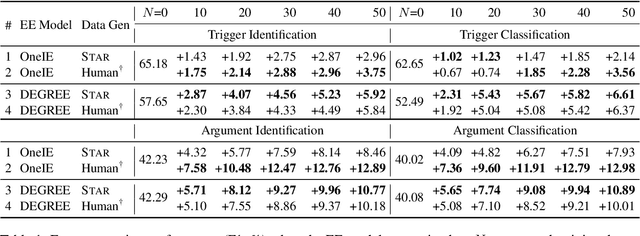
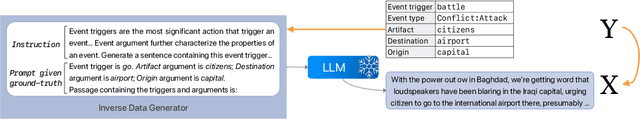

Structure prediction tasks such as event extraction require an in-depth understanding of the output structure and sub-task dependencies, thus they still heavily rely on task-specific training data to obtain reasonable performance. Due to the high cost of human annotation, low-resource event extraction, which requires minimal human cost, is urgently needed in real-world information extraction applications. We propose to synthesize data instances given limited seed demonstrations to boost low-resource event extraction performance. We propose STAR, a structure-to-text data generation method that first generates complicated event structures (Y) and then generates input passages (X), all with Large Language Models. We design fine-grained step-by-step instructions and the error cases and quality issues identified through self-reflection can be self-refined. Our experiments indicate that data generated by STAR can significantly improve the low-resource event extraction performance and they are even more effective than human-curated data points in some cases.
Another Dead End for Morphological Tags? Perturbed Inputs and Parsing
May 24, 2023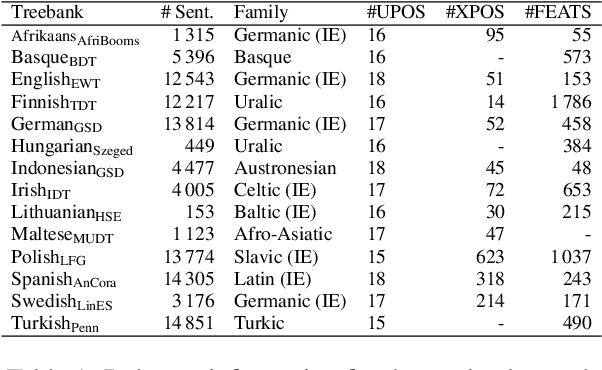
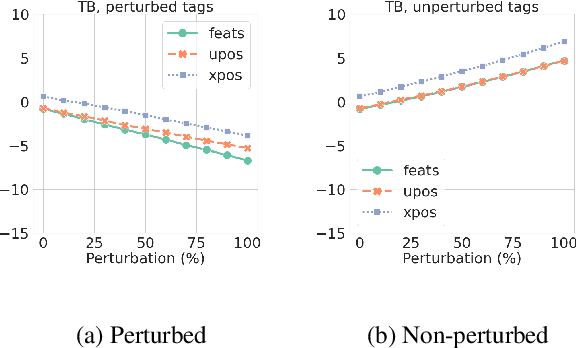
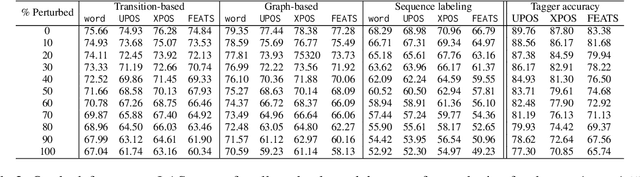
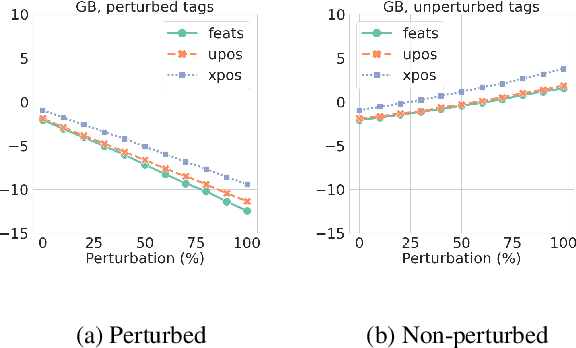
The usefulness of part-of-speech tags for parsing has been heavily questioned due to the success of word-contextualized parsers. Yet, most studies are limited to coarse-grained tags and high quality written content; while we know little about their influence when it comes to models in production that face lexical errors. We expand these setups and design an adversarial attack to verify if the use of morphological information by parsers: (i) contributes to error propagation or (ii) if on the other hand it can play a role to correct mistakes that word-only neural parsers make. The results on 14 diverse UD treebanks show that under such attacks, for transition- and graph-based models their use contributes to degrade the performance even faster, while for the (lower-performing) sequence labeling parsers they are helpful. We also show that if morphological tags were utopically robust against lexical perturbations, they would be able to correct parsing mistakes.