 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Language-Guided 3D Object Detection in Point Cloud for Autonomous Driving
May 25, 2023
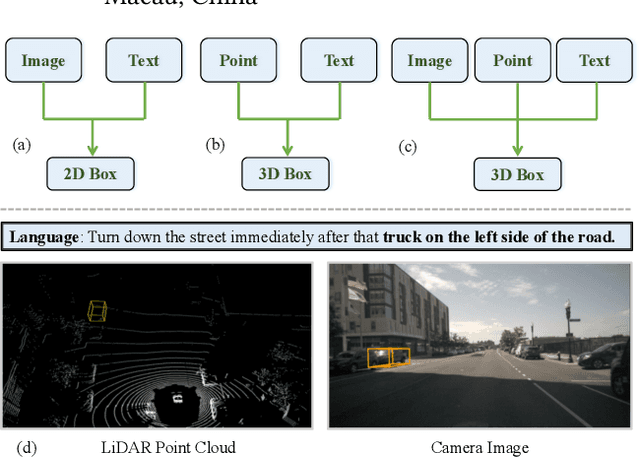
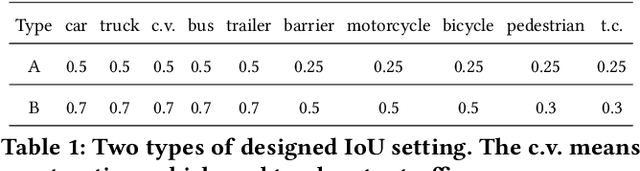
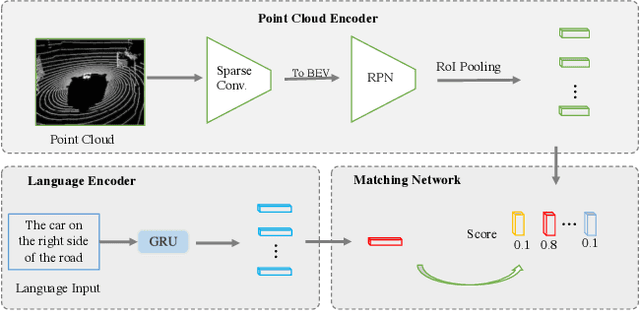
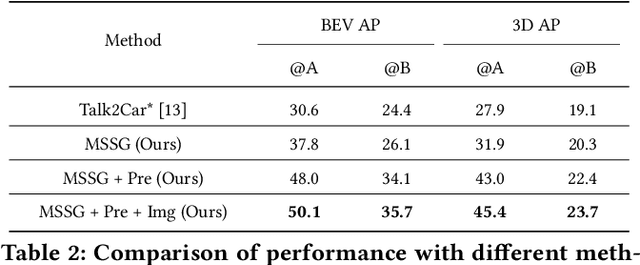
This paper addresses the problem of 3D referring expression comprehension (REC) in autonomous driving scenario, which aims to ground a natural language to the targeted region in LiDAR point clouds. Previous approaches for REC usually focus on the 2D or 3D-indoor domain, which is not suitable for accurately predicting the location of the queried 3D region in an autonomous driving scene. In addition, the upper-bound limitation and the heavy computation cost motivate us to explore a better solution. In this work, we propose a new multi-modal visual grounding task, termed LiDAR Grounding. Then we devise a Multi-modal Single Shot Grounding (MSSG) approach with an effective token fusion strategy. It jointly learns the LiDAR-based object detector with the language features and predicts the targeted region directly from the detector without any post-processing. Moreover, the image feature can be flexibly integrated into our approach to provide rich texture and color information. The cross-modal learning enforces the detector to concentrate on important regions in the point cloud by considering the informative language expressions, thus leading to much better accuracy and efficiency. Extensive experiments on the Talk2Car dataset demonstrate the effectiveness of the proposed methods. Our work offers a deeper insight into the LiDAR-based grounding task and we expect it presents a promising direction for the autonomous driving community.
RoLA: A Real-Time Online Lightweight Anomaly Detection System for Multivariate Time Series
May 25, 2023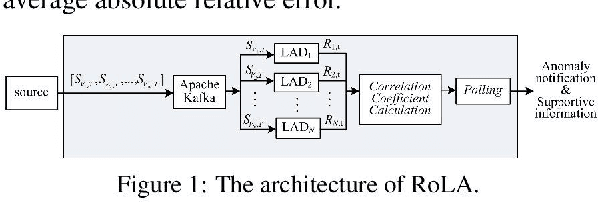


A multivariate time series refers to observations of two or more variables taken from a device or a system simultaneously over time. There is an increasing need to monitor multivariate time series and detect anomalies in real time to ensure proper system operation and good service quality. It is also highly desirable to have a lightweight anomaly detection system that considers correlations between different variables, adapts to changes in the pattern of the multivariate time series, offers immediate responses, and provides supportive information regarding detection results based on unsupervised learning and online model training. In the past decade, many multivariate time series anomaly detection approaches have been introduced. However, they are unable to offer all the above-mentioned features. In this paper, we propose RoLA, a real-time online lightweight anomaly detection system for multivariate time series based on a divide-and-conquer strategy, parallel processing, and the majority rule. RoLA employs multiple lightweight anomaly detectors to monitor multivariate time series in parallel, determine the correlations between variables dynamically on the fly, and then jointly detect anomalies based on the majority rule in real time. To demonstrate the performance of RoLA, we conducted an experiment based on a public dataset provided by the FerryBox of the One Ocean Expedition. The results show that RoLA provides satisfactory detection accuracy and lightweight performance.
SketchOGD: Memory-Efficient Continual Learning
May 25, 2023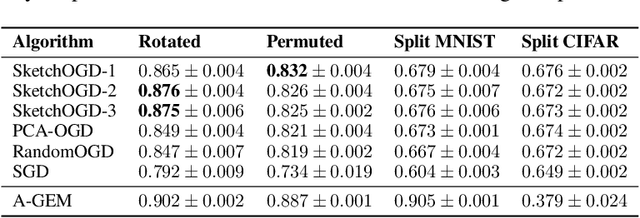
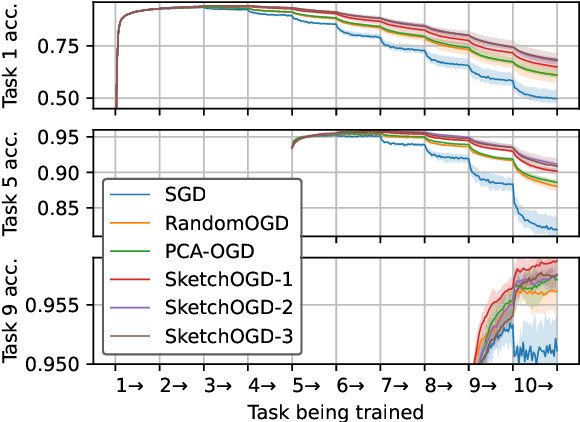
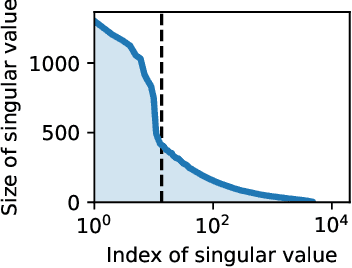
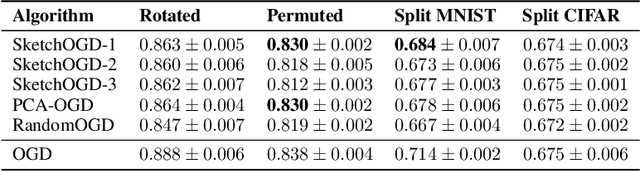
When machine learning models are trained continually on a sequence of tasks, they are liable to forget what they learned on previous tasks -- a phenomenon known as catastrophic forgetting. Proposed solutions to catastrophic forgetting tend to involve storing information about past tasks, meaning that memory usage is a chief consideration in determining their practicality. This paper proposes a memory-efficient solution to catastrophic forgetting, improving upon an established algorithm known as orthogonal gradient descent (OGD). OGD utilizes prior model gradients to find weight updates that preserve performance on prior datapoints. However, since the memory cost of storing prior model gradients grows with the runtime of the algorithm, OGD is ill-suited to continual learning over arbitrarily long time horizons. To address this problem, this paper proposes SketchOGD. SketchOGD employs an online sketching algorithm to compress model gradients as they are encountered into a matrix of a fixed, user-determined size. In contrast to existing memory-efficient variants of OGD, SketchOGD runs online without the need for advance knowledge of the total number of tasks, is simple to implement, and is more amenable to analysis. We provide theoretical guarantees on the approximation error of the relevant sketches under a novel metric suited to the downstream task of OGD. Experimentally, we find that SketchOGD tends to outperform current state-of-the-art variants of OGD given a fixed memory budget.
Union Subgraph Neural Networks
May 25, 2023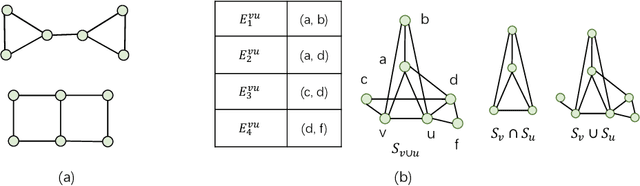
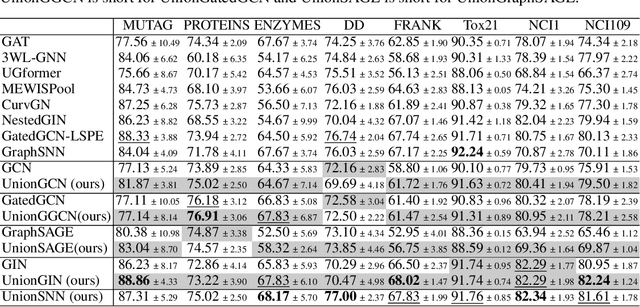

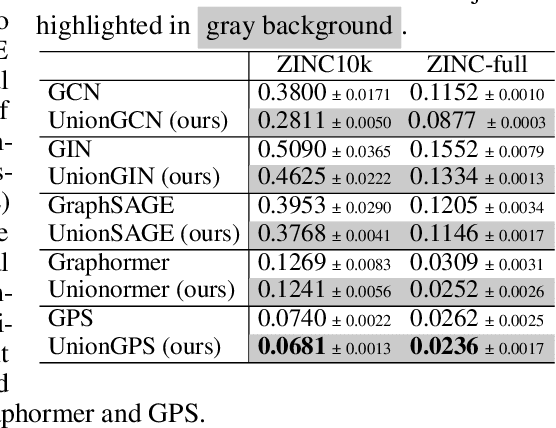
Graph Neural Networks (GNNs) are widely used for graph representation learning in many application domains. The expressiveness of vanilla GNNs is upper-bounded by 1-dimensional Weisfeiler-Leman (1-WL) test as they operate on rooted subtrees through iterative message passing. In this paper, we empower GNNs by injecting neighbor-connectivity information extracted from a new type of substructure. We first investigate different kinds of connectivities existing in a local neighborhood and identify a substructure called union subgraph, which is able to capture the complete picture of the 1-hop neighborhood of an edge. We then design a shortest-path-based substructure descriptor that possesses three nice properties and can effectively encode the high-order connectivities in union subgraphs. By infusing the encoded neighbor connectivities, we propose a novel model, namely Union Subgraph Neural Network (UnionSNN), which is proven to be strictly more powerful than 1-WL in distinguishing non-isomorphic graphs. Additionally, the local encoding from union subgraphs can also be injected into arbitrary message-passing neural networks (MPNNs) and Transformer-based models as a plugin. Extensive experiments on 17 benchmarks of both graph-level and node-level tasks demonstrate that UnionSNN outperforms state-of-the-art baseline models, with competitive computational efficiency. The injection of our local encoding to existing models is able to boost the performance by up to 11.09%.
PromptNER: A Prompting Method for Few-shot Named Entity Recognition via k Nearest Neighbor Search
May 20, 2023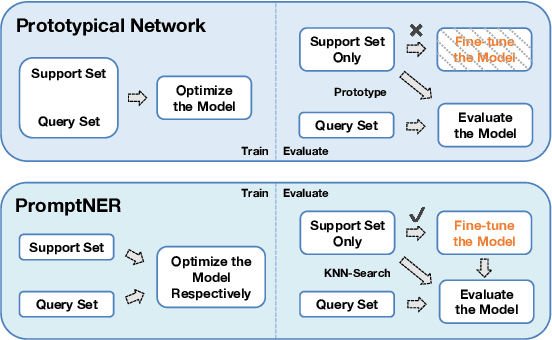
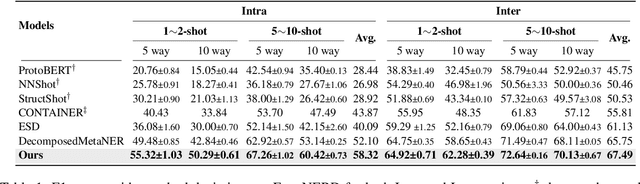

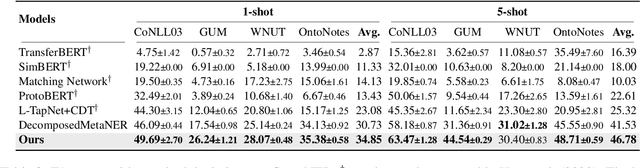
Few-shot Named Entity Recognition (NER) is a task aiming to identify named entities via limited annotated samples. Recently, prototypical networks have shown promising performance in few-shot NER. Most of prototypical networks will utilize the entities from the support set to construct label prototypes and use the query set to compute span-level similarities and optimize these label prototype representations. However, these methods are usually unsuitable for fine-tuning in the target domain, where only the support set is available. In this paper, we propose PromptNER: a novel prompting method for few-shot NER via k nearest neighbor search. We use prompts that contains entity category information to construct label prototypes, which enables our model to fine-tune with only the support set. Our approach achieves excellent transfer learning ability, and extensive experiments on the Few-NERD and CrossNER datasets demonstrate that our model achieves superior performance over state-of-the-art methods.
Patton: Language Model Pretraining on Text-Rich Networks
May 20, 2023
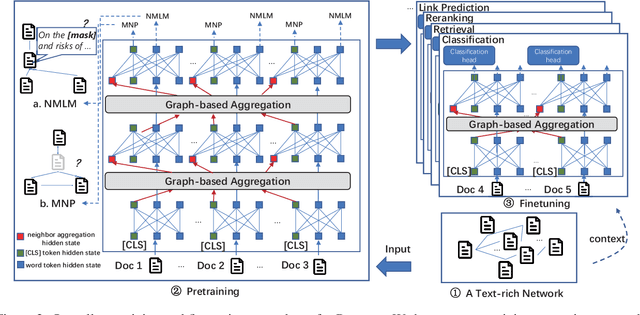
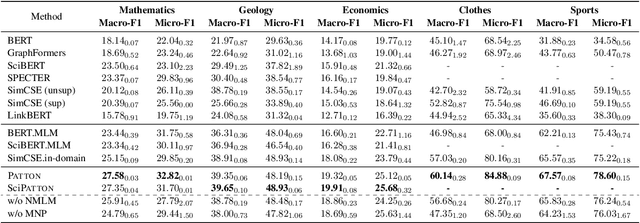
A real-world text corpus sometimes comprises not only text documents but also semantic links between them (e.g., academic papers in a bibliographic network are linked by citations and co-authorships). Text documents and semantic connections form a text-rich network, which empowers a wide range of downstream tasks such as classification and retrieval. However, pretraining methods for such structures are still lacking, making it difficult to build one generic model that can be adapted to various tasks on text-rich networks. Current pretraining objectives, such as masked language modeling, purely model texts and do not take inter-document structure information into consideration. To this end, we propose our PretrAining on TexT-Rich NetwOrk framework Patton. Patton includes two pretraining strategies: network-contextualized masked language modeling and masked node prediction, to capture the inherent dependency between textual attributes and network structure. We conduct experiments on four downstream tasks in five datasets from both academic and e-commerce domains, where Patton outperforms baselines significantly and consistently.
Learning to Rank the Importance of Nodes in Road Networks Based on Multi-Graph Fusion
May 20, 2023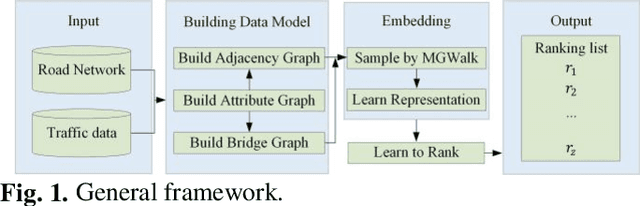
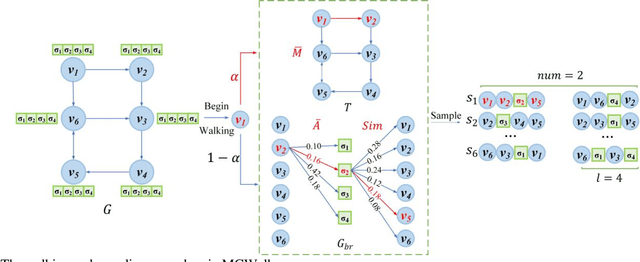
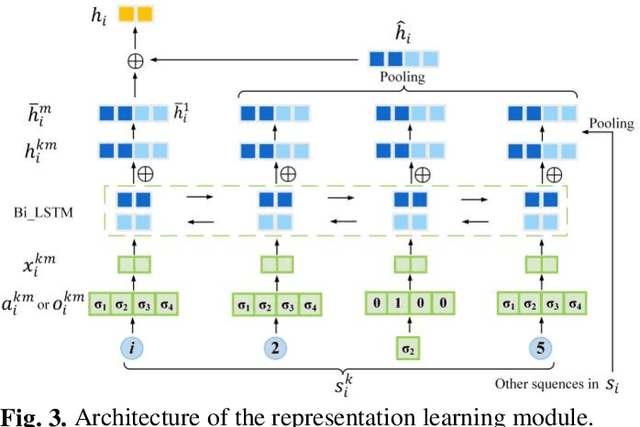
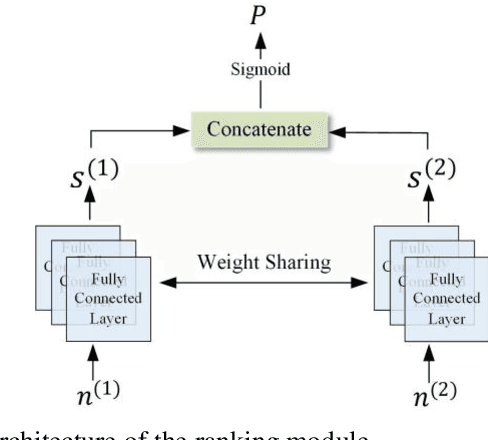
Identifying important nodes with strong propagation capabilities in road networks is a significant topic in the field of urban planning. However, existing methods for evaluating nodes importance consider only topological information and traffic volumes, ignoring the diversity of characteristics in road networks, such as the number of lanes and average speed of road segments, limiting their performance. To address this issue, this paper proposes a graph learning-based node ranking method (MGL2Rank) that integrates the rich characteristics of the road network. In this method, we first develop a sampling algorithm (MGWalk) that utilizes multi-graph fusion to establish association between road segments based on their attributes. Then, an embedding module is proposed to learn latent representation for each road segment. Finally, the obtained node representation is used to learn importance ranking of road segments. We conduct simulation experiments on the regional road network of Shenyang city and demonstrate the effectiveness of our proposed method. The data and source code of MGL2Rank are available at https://github.com/ZJ726.
An Asynchronous Wireless Network for Capturing Event-Driven Data from Large Populations of Autonomous Sensors
May 20, 2023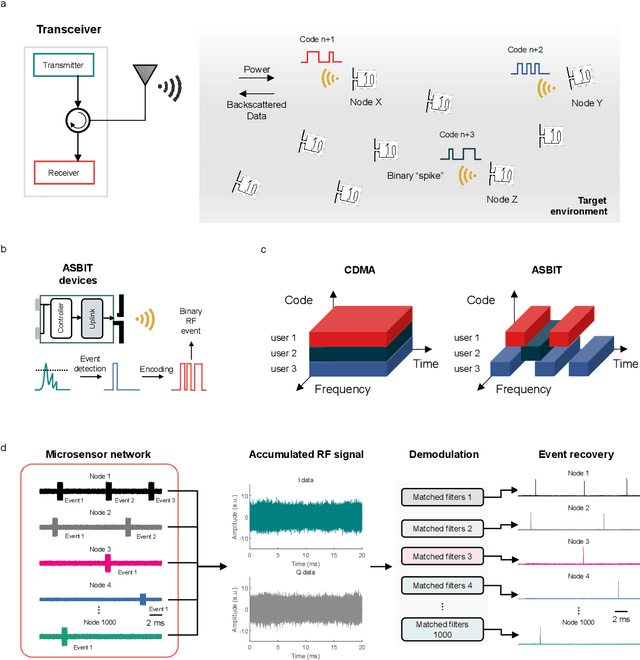
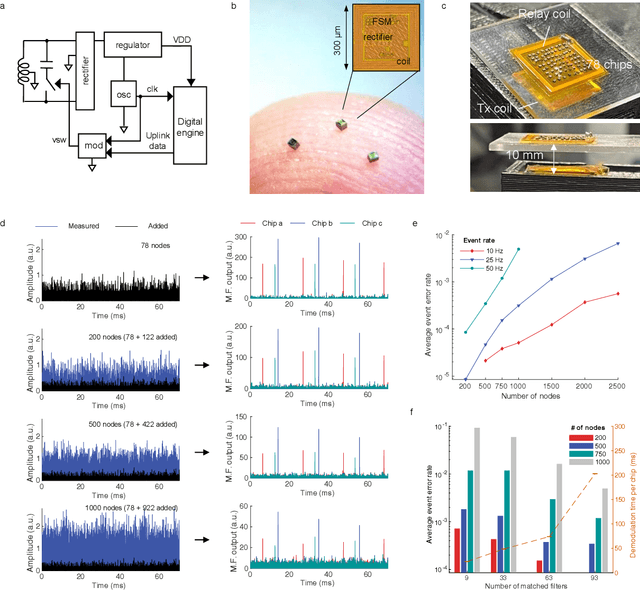
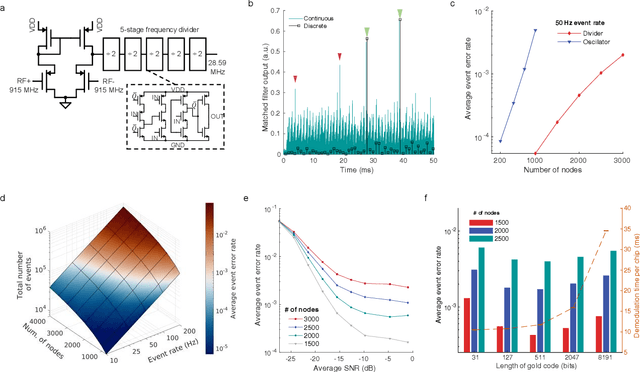
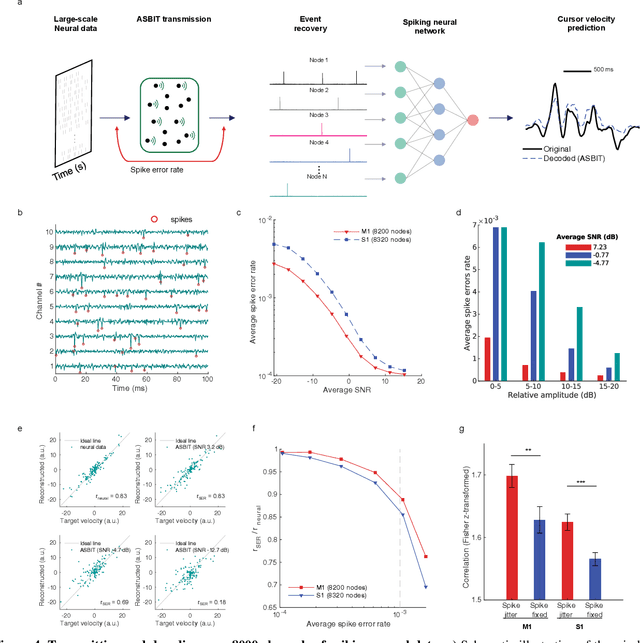
We introduce a wireless RF network concept for capturing sparse event-driven data from large populations of spatially distributed autonomous microsensors, possibly numbered in the thousands. Each sensor is assumed to be a microchip capable of event detection in transforming time-varying inputs to spike trains. Inspired by brain information processing, we have developed a spectrally efficient, low-error rate asynchronous networking concept based on a code-division multiple access method. We characterize the network performance of several dozen submillimeter-size silicon microchips experimentally, complemented by larger scale in silico simulations. A comparison is made between different implementations of on-chip clocks. Testing the notion that spike-based wireless communication is naturally matched with downstream sensor population analysis by neuromorphic computing techniques, we then deploy a spiking neural network (SNN) machine learning model to decode data from eight thousand spiking neurons in the primate cortex for accurate prediction of hand movement in a cursor control task.
GFDC: A Granule Fusion Density-Based Clustering with Evidential Reasoning
May 20, 2023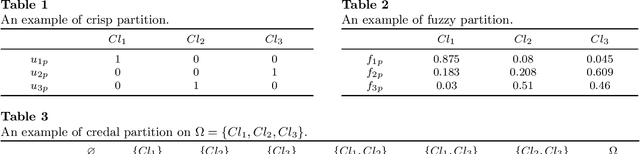
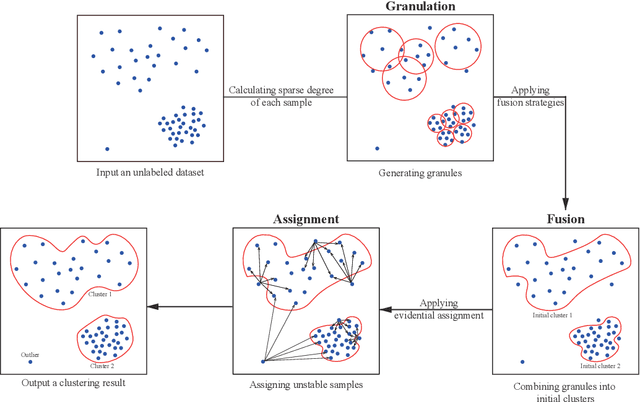
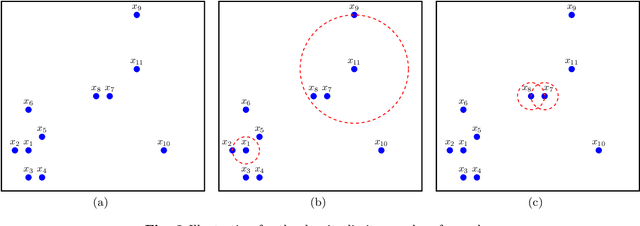

Currently, density-based clustering algorithms are widely applied because they can detect clusters with arbitrary shapes. However, they perform poorly in measuring global density, determining reasonable cluster centers or structures, assigning samples accurately and handling data with large density differences among clusters. To overcome their drawbacks, this paper proposes a granule fusion density-based clustering with evidential reasoning (GFDC). Both local and global densities of samples are measured by a sparse degree metric first. Then information granules are generated in high-density and low-density regions, assisting in processing clusters with significant density differences. Further, three novel granule fusion strategies are utilized to combine granules into stable cluster structures, helping to detect clusters with arbitrary shapes. Finally, by an assignment method developed from Dempster-Shafer theory, unstable samples are assigned. After using GFDC, a reasonable clustering result and some identified outliers can be obtained. The experimental results on extensive datasets demonstrate the effectiveness of GFDC.
Automatic Surround Camera Calibration Method in Road Scene for Self-driving Car
May 26, 2023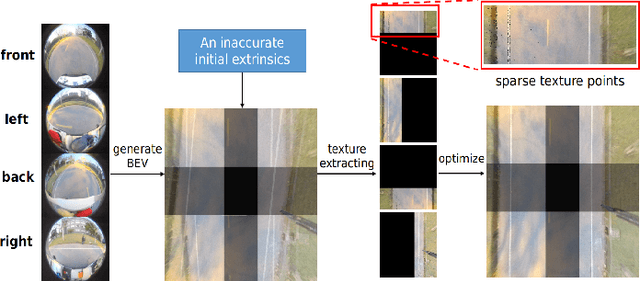

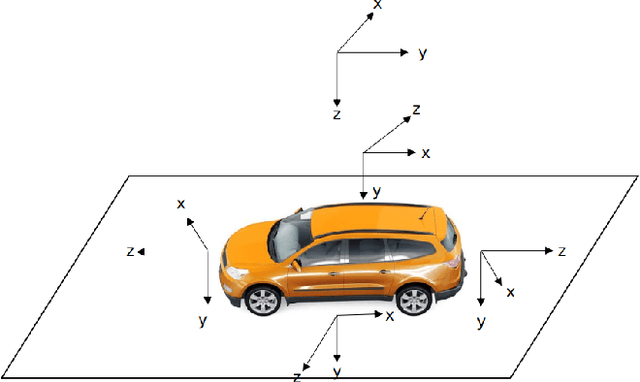

With the development of autonomous driving technology, sensor calibration has become a key technology to achieve accurate perception fusion and localization. Accurate calibration of the sensors ensures that each sensor can function properly and accurate information aggregation can be achieved. Among them, camera calibration based on surround view has received extensive attention. In autonomous driving applications, the calibration accuracy of the camera can directly affect the accuracy of perception and depth estimation. For online calibration of surround-view cameras, traditional feature extraction-based methods will suffer from strong distortion when the initial extrinsic parameters error is large, making these methods less robust and inaccurate. More existing methods use the sparse direct method to calibrate multi-cameras, which can ensure both accuracy and real-time performance and is theoretically achievable. However, this method requires a better initial value, and the initial estimate with a large error is often stuck in a local optimum. To this end, we introduce a robust automatic multi-cameras (pinhole or fisheye cameras) calibration and refinement method in the road scene. We utilize the coarse-to-fine random-search strategy, and it can solve large disturbances of initial extrinsic parameters, which can make up for falling into optimal local value in nonlinear optimization methods. In the end, quantitative and qualitative experiments are conducted in actual and simulated environments, and the result shows the proposed method can achieve accuracy and robustness performance. The open-source code is available at https://github.com/OpenCalib/SurroundCameraCalib.