 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning-augmented Online Minimization of Age of Information and Transmission Costs
Mar 05, 2024
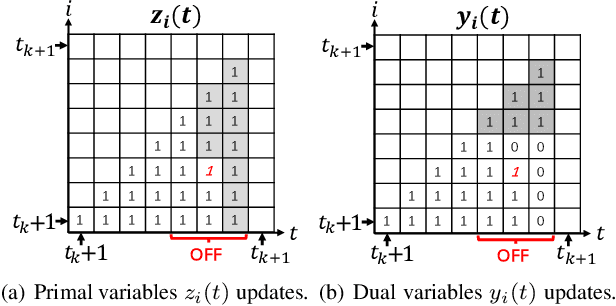
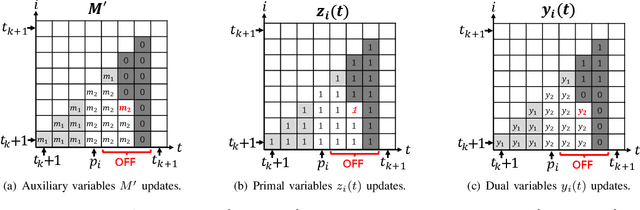
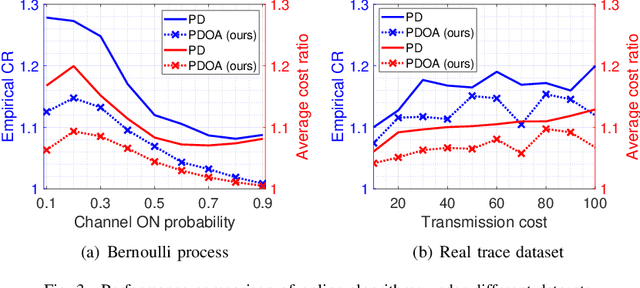
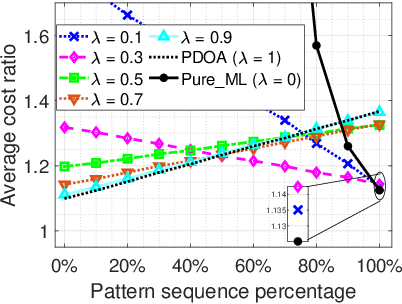
We consider a discrete-time system where a resource-constrained source (e.g., a small sensor) transmits its time-sensitive data to a destination over a time-varying wireless channel. Each transmission incurs a fixed transmission cost (e.g., energy cost), and no transmission results in a staleness cost represented by the Age-of-Information. The source must balance the tradeoff between transmission and staleness costs. To address this challenge, we develop a robust online algorithm to minimize the sum of transmission and staleness costs, ensuring a worst-case performance guarantee. While online algorithms are robust, they are usually overly conservative and may have a poor average performance in typical scenarios. In contrast, by leveraging historical data and prediction models, machine learning (ML) algorithms perform well in average cases. However, they typically lack worst-case performance guarantees. To achieve the best of both worlds, we design a learning-augmented online algorithm that exhibits two desired properties: (i) consistency: closely approximating the optimal offline algorithm when the ML prediction is accurate and trusted; (ii) robustness: ensuring worst-case performance guarantee even ML predictions are inaccurate. Finally, we perform extensive simulations to show that our online algorithm performs well empirically and that our learning-augmented algorithm achieves both consistency and robustness.
Universal Feature Selection for Simultaneous Interpretability of Multitask Datasets
Mar 21, 2024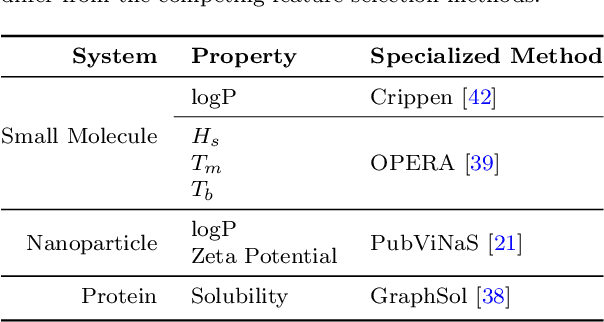
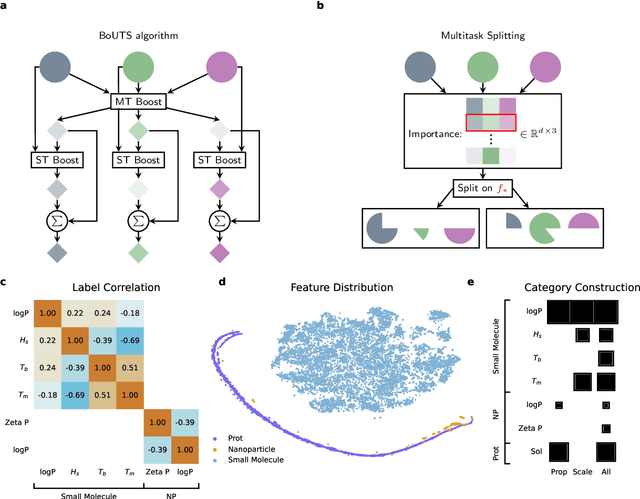
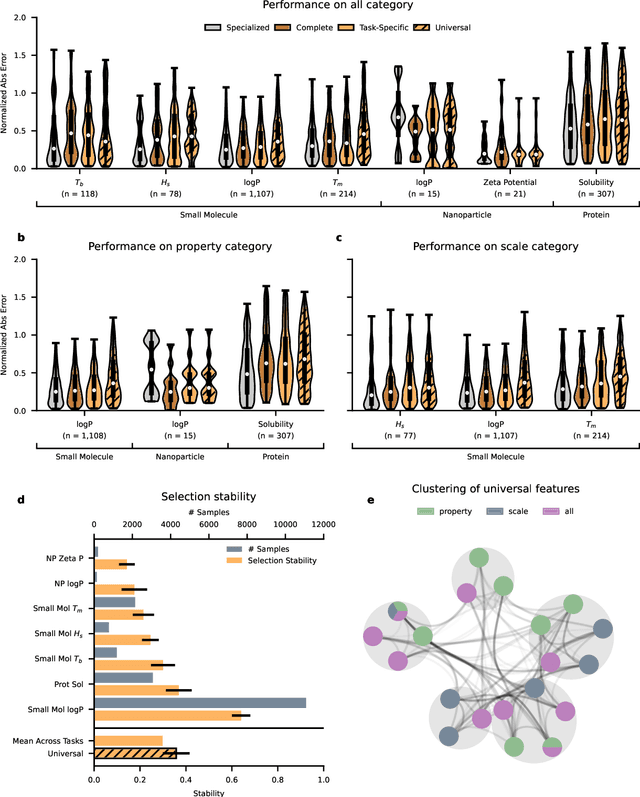
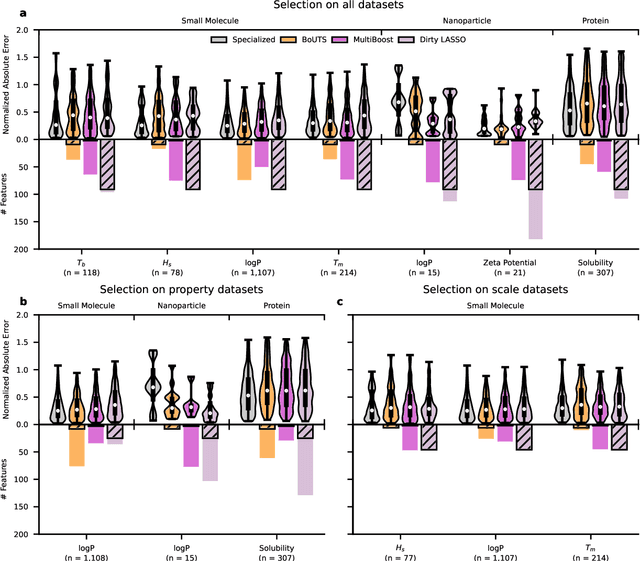
Extracting meaningful features from complex, high-dimensional datasets across scientific domains remains challenging. Current methods often struggle with scalability, limiting their applicability to large datasets, or make restrictive assumptions about feature-property relationships, hindering their ability to capture complex interactions. BoUTS's general and scalable feature selection algorithm surpasses these limitations to identify both universal features relevant to all datasets and task-specific features predictive for specific subsets. Evaluated on seven diverse chemical regression datasets, BoUTS achieves state-of-the-art feature sparsity while maintaining prediction accuracy comparable to specialized methods. Notably, BoUTS's universal features enable domain-specific knowledge transfer between datasets, and suggest deep connections in seemingly-disparate chemical datasets. We expect these results to have important repercussions in manually-guided inverse problems. Beyond its current application, BoUTS holds immense potential for elucidating data-poor systems by leveraging information from similar data-rich systems. BoUTS represents a significant leap in cross-domain feature selection, potentially leading to advancements in various scientific fields.
Scene-Graph ViT: End-to-End Open-Vocabulary Visual Relationship Detection
Mar 21, 2024
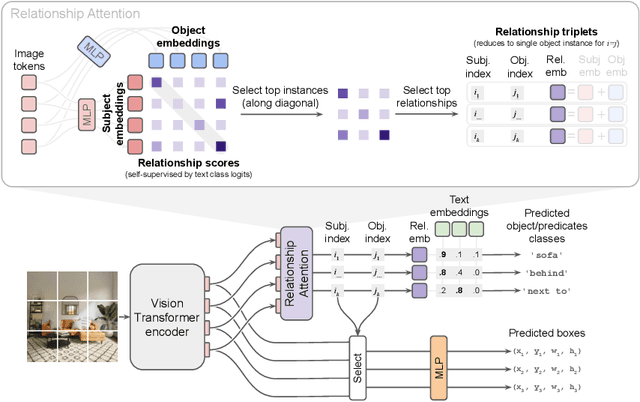

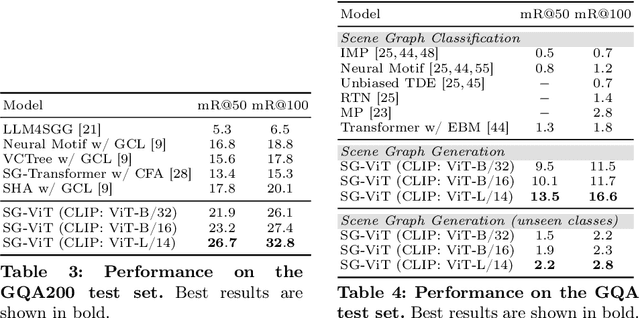
Visual relationship detection aims to identify objects and their relationships in images. Prior methods approach this task by adding separate relationship modules or decoders to existing object detection architectures. This separation increases complexity and hinders end-to-end training, which limits performance. We propose a simple and highly efficient decoder-free architecture for open-vocabulary visual relationship detection. Our model consists of a Transformer-based image encoder that represents objects as tokens and models their relationships implicitly. To extract relationship information, we introduce an attention mechanism that selects object pairs likely to form a relationship. We provide a single-stage recipe to train this model on a mixture of object and relationship detection data. Our approach achieves state-of-the-art relationship detection performance on Visual Genome and on the large-vocabulary GQA benchmark at real-time inference speeds. We provide analyses of zero-shot performance, ablations, and real-world qualitative examples.
AdaProj: Adaptively Scaled Angular Margin Subspace Projections for Anomalous Sound Detection with Auxiliary Classification Tasks
Mar 21, 2024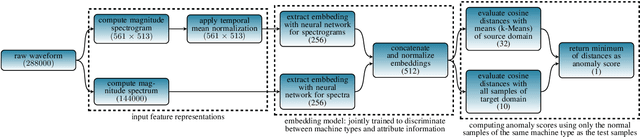

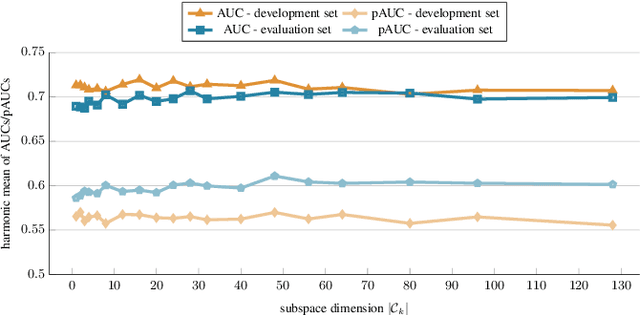
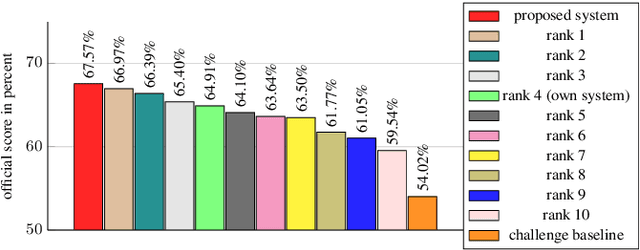
The state-of-the-art approach for semi-supervised anomalous sound detection is to first learn an embedding space by using auxiliary classification tasks based on meta information or self-supervised learning and then estimate the distribution of normal data. In this work, AdaProj a novel loss function is presented. In contrast to commonly used angular margin losses, which project data of each class as close as possible to their corresponding class centers, AdaProj learns to project data onto class-specific subspaces. By doing so, the resulting distributions of embeddings belonging to normal data are not required to be as restrictive as other loss functions allowing a more detailed view on the data. In experiments conducted on the DCASE2022 and DCASE2023 datasets, it is shown that using AdaProj to learn an embedding space significantly outperforms other commonly used loss functions and results in a state-of-the-art performance on the DCASE2023 dataset.
Powerful Lossy Compression for Noisy Images
Mar 21, 2024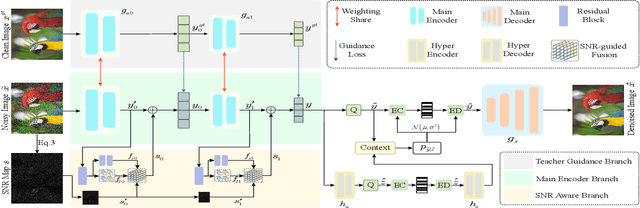
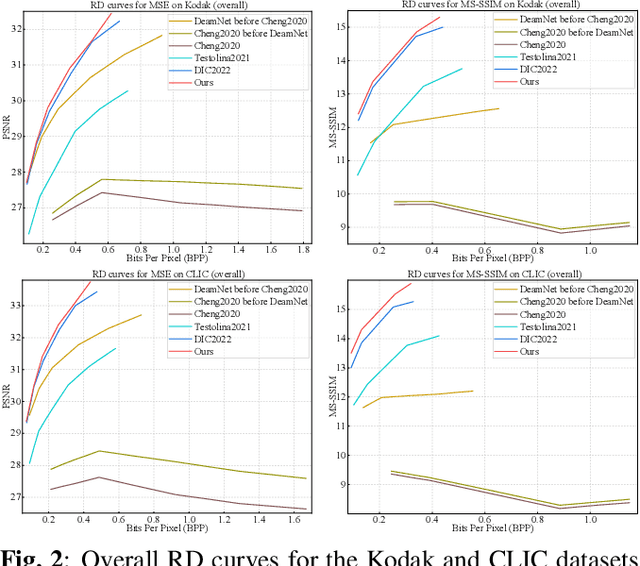
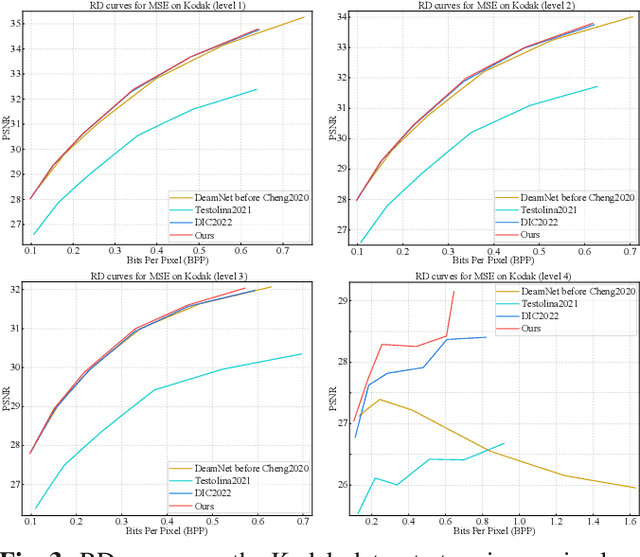
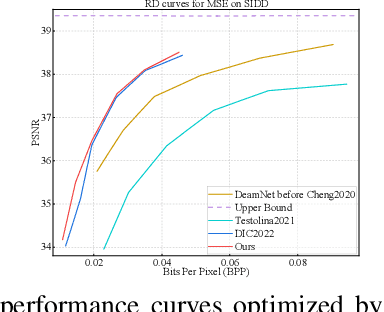
Image compression and denoising represent fundamental challenges in image processing with many real-world applications. To address practical demands, current solutions can be categorized into two main strategies: 1) sequential method; and 2) joint method. However, sequential methods have the disadvantage of error accumulation as there is information loss between multiple individual models. Recently, the academic community began to make some attempts to tackle this problem through end-to-end joint methods. Most of them ignore that different regions of noisy images have different characteristics. To solve these problems, in this paper, our proposed signal-to-noise ratio~(SNR) aware joint solution exploits local and non-local features for image compression and denoising simultaneously. We design an end-to-end trainable network, which includes the main encoder branch, the guidance branch, and the signal-to-noise ratio~(SNR) aware branch. We conducted extensive experiments on both synthetic and real-world datasets, demonstrating that our joint solution outperforms existing state-of-the-art methods.
DouRN: Improving DouZero by Residual Neural Networks
Mar 21, 2024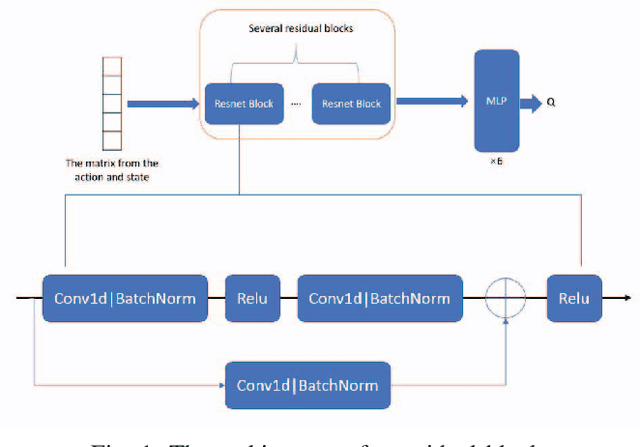
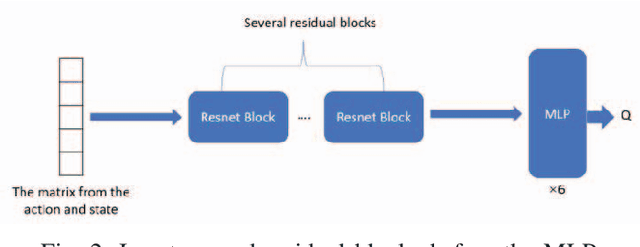
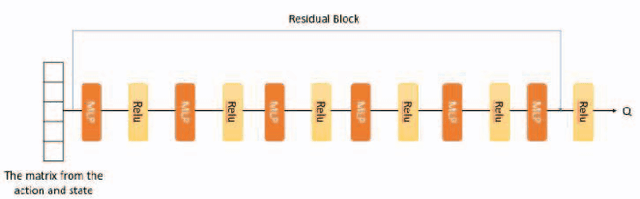
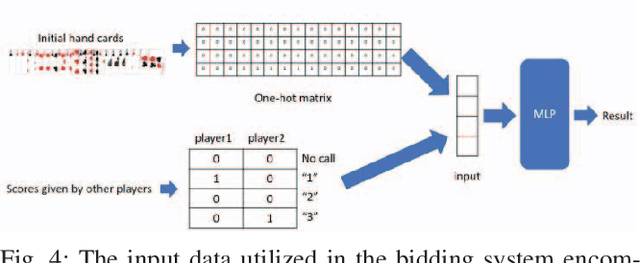
Deep reinforcement learning has made significant progress in games with imperfect information, but its performance in the card game Doudizhu (Chinese Poker/Fight the Landlord) remains unsatisfactory. Doudizhu is different from conventional games as it involves three players and combines elements of cooperation and confrontation, resulting in a large state and action space. In 2021, a Doudizhu program called DouZero\cite{zha2021douzero} surpassed previous models without prior knowledge by utilizing traditional Monte Carlo methods and multilayer perceptrons. Building on this work, our study incorporates residual networks into the model, explores different architectural designs, and conducts multi-role testing. Our findings demonstrate that this model significantly improves the winning rate within the same training time. Additionally, we introduce a call scoring system to assist the agent in deciding whether to become a landlord. With these enhancements, our model consistently outperforms the existing version of DouZero and even experienced human players. \footnote{The source code is available at \url{https://github.com/Yingchaol/Douzero_Resnet.git.}
FlowerFormer: Empowering Neural Architecture Encoding using a Flow-aware Graph Transformer
Mar 21, 2024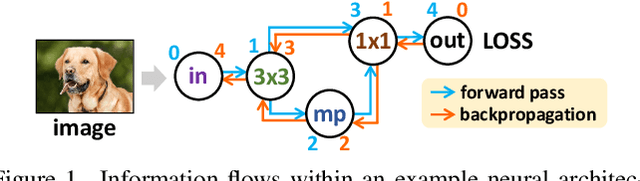
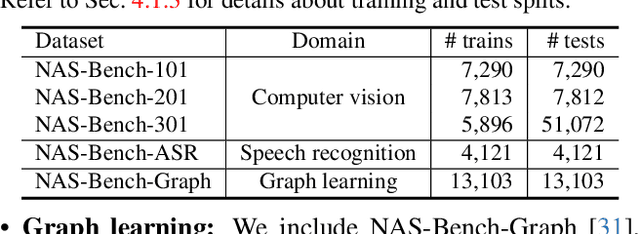
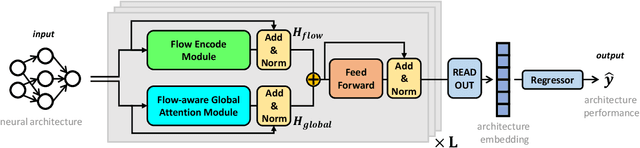
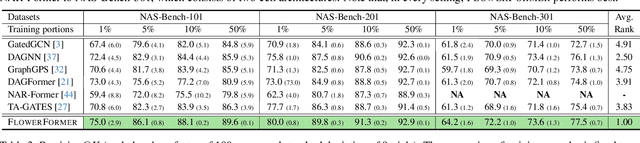
The success of a specific neural network architecture is closely tied to the dataset and task it tackles; there is no one-size-fits-all solution. Thus, considerable efforts have been made to quickly and accurately estimate the performances of neural architectures, without full training or evaluation, for given tasks and datasets. Neural architecture encoding has played a crucial role in the estimation, and graphbased methods, which treat an architecture as a graph, have shown prominent performance. For enhanced representation learning of neural architectures, we introduce FlowerFormer, a powerful graph transformer that incorporates the information flows within a neural architecture. FlowerFormer consists of two key components: (a) bidirectional asynchronous message passing, inspired by the flows; (b) global attention built on flow-based masking. Our extensive experiments demonstrate the superiority of FlowerFormer over existing neural encoding methods, and its effectiveness extends beyond computer vision models to include graph neural networks and auto speech recognition models. Our code is available at http://github.com/y0ngjaenius/CVPR2024_FLOWERFormer.
Discrete Semantic Tokenization for Deep CTR Prediction
Mar 21, 2024Incorporating item content information into click-through rate (CTR) prediction models remains a challenge, especially with the time and space constraints of industrial scenarios. The content-encoding paradigm, which integrates user and item encoders directly into CTR models, prioritizes space over time. In contrast, the embedding-based paradigm transforms item and user semantics into latent embeddings, subsequently caching them to optimize processing time at the expense of space. In this paper, we introduce a new semantic-token paradigm and propose a discrete semantic tokenization approach, namely UIST, for user and item representation. UIST facilitates swift training and inference while maintaining a conservative memory footprint. Specifically, UIST quantizes dense embedding vectors into discrete tokens with shorter lengths and employs a hierarchical mixture inference module to weigh the contribution of each user--item token pair. Our experimental results on news recommendation showcase the effectiveness and efficiency (about 200-fold space compression) of UIST for CTR prediction.
Lexicon-Level Contrastive Visual-Grounding Improves Language Modeling
Mar 21, 2024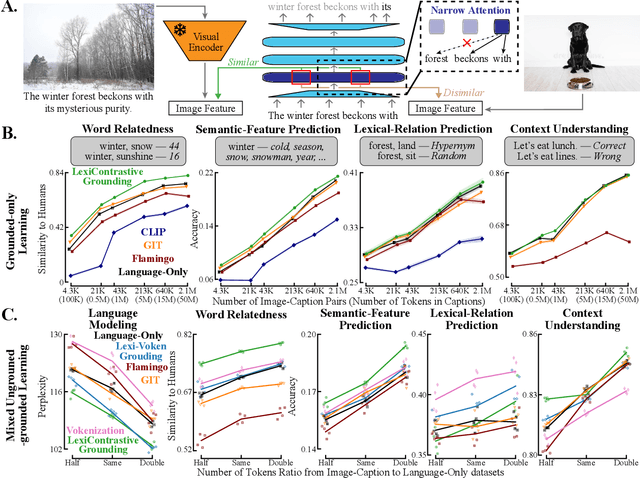
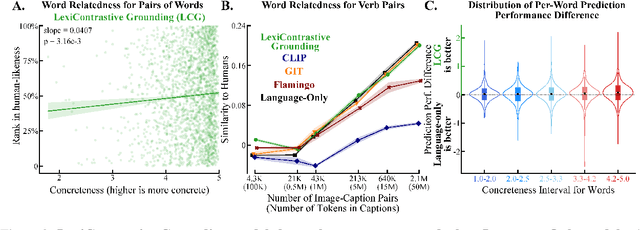
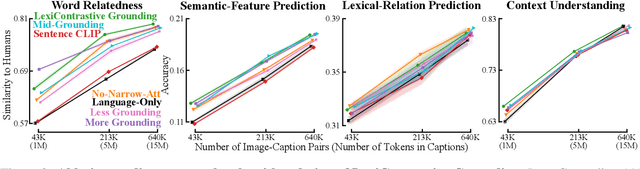
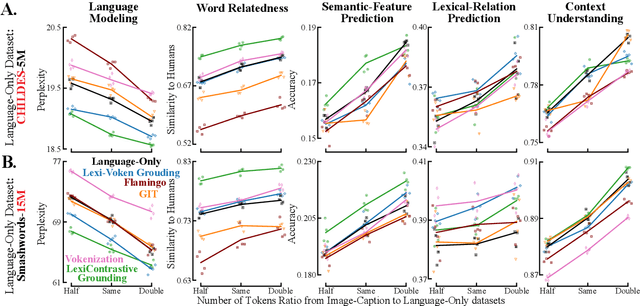
Today's most accurate language models are trained on orders of magnitude more language data than human language learners receive - but with no supervision from other sensory modalities that play a crucial role in human learning. Can we make LMs' representations and predictions more accurate (and more human-like) with more ecologically plausible supervision? This paper describes LexiContrastive Grounding (LCG), a grounded language learning procedure that leverages visual supervision to improve textual representations. LexiContrastive Grounding combines a next token prediction strategy with a contrastive visual grounding objective, focusing on early-layer representations that encode lexical information. Across multiple word-learning and sentence-understanding benchmarks, LexiContrastive Grounding not only outperforms standard language-only models in learning efficiency, but also improves upon vision-and-language learning procedures including CLIP, GIT, Flamingo, and Vokenization. Moreover, LexiContrastive Grounding improves perplexity by around 5% on multiple language modeling tasks. This work underscores the potential of incorporating visual grounding into language models, aligning more closely with the multimodal nature of human language acquisition.
An Efficient Rate Splitting Precoding Approach in Multi-User MISO FDD Systems
Mar 21, 2024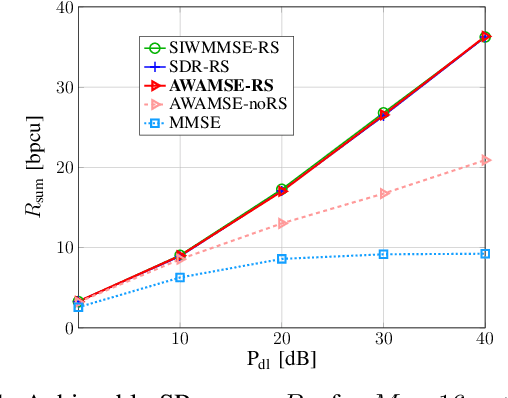
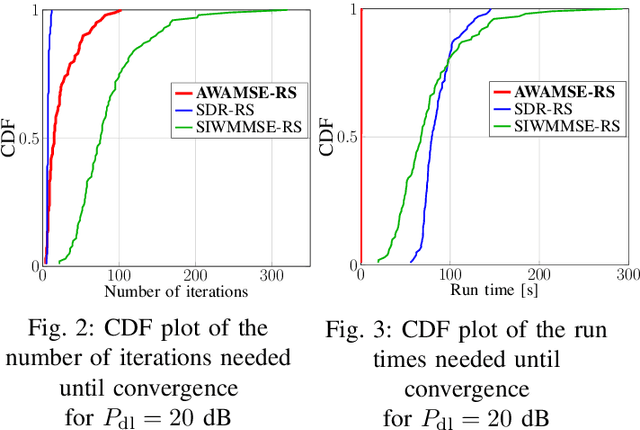
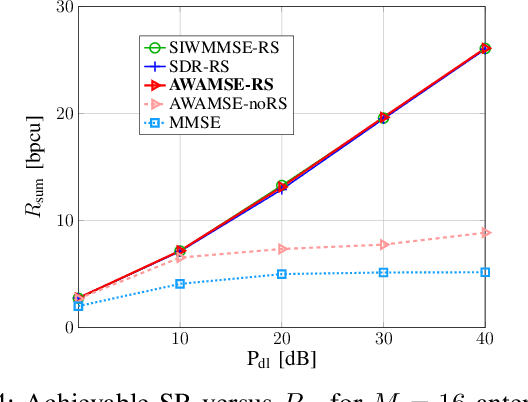
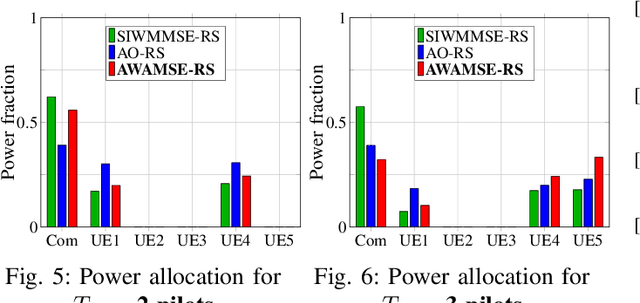
In this work, we develop an efficient precoding strategy for a multi-user multiple-input-single output (MU MISO) system operating in frequency-division-duplex (FDD) mode, where rate splitting multiple access (RSMA) is implemented. To this end, we consider one-layer RS and show its significant impact on the system performance, specifically in the case where the channel state information (CSI) is incomplete at the transmitter. Based on a lower bound on the achievable rate that takes into account the CSI errors, we establish an augmented weighted average mean squared error (AWAMSE) algorithm for the RS setup denoted by AWAMSE-RS, where even the updates for the common and the private precoders are computed via analytical expressions, hence circumventing the need for interior-point methods. Simulation results validate the efficiency of our approach in terms of computational time and its competitiveness in terms of the achievable system throughput compared to state-of-the-art methods and non-RS setups.